
编写项目并打包上传
为了方便, 这里我们把自定义调度器DirectScheduler和测试用拓扑程序DirectScheduledTopology放在一个项目中.
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.niit.storm.example</groupId>
<artifactId>storm_example</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>storm_example</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<repositories>
<repository>
<id>clojars.org</id>
<url>http://clojars.org/repo</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>2.1.0</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.2-beta-5</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies
</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass/>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>自定义Scheduler
package storm.scheduler;
import org.apache.storm.scheduler.*;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.*;
/**
* @Author: deLucia
* @Date: 2020/7/24
* @Version: 1.0
* @Description: 自定义调度器
* DirectScheduler把划分单位缩小到组件级别,
* 1个Spout和1个Bolt可以分别指定到某个指定的节点上运行,
* 如果没有指定,还是按照系统自带的调度器进行调度.
* 这个配置在Topology提交的Conf配置中可配.
*/
public class DirectScheduler implements IScheduler {
protected static final Logger logger = LoggerFactory.getLogger(DirectScheduler.class);
@Override
public void prepare(Map conf) {
}
@Override
public void schedule(Topologies topologies, Cluster cluster) {
// Gets the topology which we want to schedule
String assignedFlag; //作业是否要指定分配的标识
Collection<TopologyDetails> topologyDetailes = topologies.getTopologies();
for (TopologyDetails td : topologyDetailes) {
Map<String, Object> map = td.getConf();
assignedFlag = (String) map.get("assigned_flag"); // 标志位
// 如果找到的拓扑逻辑的assigned_flag标记为1则代表是要指定分配到目标节点的的,否则走系统的默认调度
if ("1".equals(assignedFlag)) {
if (!cluster.needsScheduling(td)) { // 如果资源不紧张, 走默认调度
logger.info("use default - scheduler");
new DefaultScheduler().schedule(topologies, cluster);
} else {
topologyAssign(cluster, td, map); // 否则走自定义调度
}
} else {
logger.info("use default scheduler");
new DefaultScheduler().schedule(topologies, cluster);
}
}
}
@Override
public Map<String, Object> config() {
return new HashMap<String, Object>();
}
@Override
public void cleanup() {
}
/**
* 拓扑逻辑的调度
*
* @param cluster 集群
* @param topology 具体要调度的拓扑逻辑
* @param map map配置项
*/
private void topologyAssign(Cluster cluster, TopologyDetails topology, Map<String, Object> map) {
logger.info("use custom scheduler");
if (topology == null) {
logger.warn("topology is null");
return;
}
Map<String, Object> designMap = (Map<String, Object>) map.get("design_map");
if (designMap == null) {
logger.warn("found no design_map in config");
return;
}
// find out all the needs-scheduling components of this topology
Map<String, List<ExecutorDetails>> componentToExecutors = cluster.getNeedsSchedulingComponentToExecutors(topology);
// 当没有待分配线程时直接退出
if (componentToExecutors == null || componentToExecutors.size() == 0) {
return;
}
// 如果有指定待分配的节点名称则分配到指定节点
Set<String> keys = designMap.keySet();
for (String componentName : keys) {
String nodeName = (String) designMap.get(componentName);
componentAssign(cluster, topology, componentToExecutors, componentName, nodeName);
}
}
/**
* 组件调度
*
* @param cluster 集群的信息
* @param topology 待调度的拓扑细节信息
* @param totalExecutors 组件的执行器
* @param componentName 组件的名称
* @param supervisorName 节点的名称
*/
private void componentAssign(Cluster cluster, TopologyDetails topology, Map<String, List<ExecutorDetails>> totalExecutors, String componentName, String supervisorName) {
List<ExecutorDetails> executors = totalExecutors.get(componentName);
// 由于Scheduler是轮询调用, 这里需要提前判空
if (executors == null) {
return;
}
// find out the our "special-supervisor" from the supervisor metadata
Collection<SupervisorDetails> supervisors = cluster.getSupervisors().values();
SupervisorDetails specialSupervisor = null;
for (SupervisorDetails supervisor : supervisors) {
Map meta = (Map) supervisor.getSchedulerMeta();
if (meta != null && meta.get("name") != null) {
if (meta.get("name").equals(supervisorName)) {
specialSupervisor = supervisor;
break;
}
}
}
// found the special supervisor
if (specialSupervisor != null) {
logger.info("supervisor name:" + specialSupervisor);
List<WorkerSlot> availableSlots = cluster.getAvailableSlots(specialSupervisor);
// 如果目标节点上已经没有空闲的slot,则进行强制释放
if (availableSlots.isEmpty() && !executors.isEmpty()) {
for (Integer port : cluster.getUsedPorts(specialSupervisor)) {
logger.info("no available work slots");
logger.info("will free one slot from " + specialSupervisor.getId() + ":" + port);
cluster.freeSlot(new WorkerSlot(specialSupervisor.getId(), port));
}
}
// 重新获取可用的slot
availableSlots = cluster.getAvailableSlots(specialSupervisor);
// 选取节点上第一个slot,进行分配
WorkerSlot firstSlot = availableSlots.get(0);
for (WorkerSlot slot : availableSlots) {
if (slot != null) {
logger.info("assigned executors:" + executors + " to slot: [" + firstSlot.getNodeId() + ", " + firstSlot.getPort() + "]");
cluster.assign(firstSlot, topology.getId(), executors);
return;
}
}
logger.warn("failed to assigned executors:" + executors + " to slot: [" + firstSlot.getNodeId() + ", " + firstSlot.getPort() + "]");
} else {
logger.warn("supervisor name not existed in supervisor list!");
}
}
}测试用拓扑
package storm.scheduler;
import org.apache.storm.Config;
import org.apache.storm.StormSubmitter;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.HashMap;
import java.util.Map;
/**
* 使用Storm实现积累求和的操作 - 使用自定义调度器
* 自定义DiectScheduler可以为某个组件可以去指定不同节点运行, 开发者可以根据实际集群的资源情况选择适合的节点, 工作中有时候是很有用的.
* 我们的目的是调度spout到supervisor002节点 调度bolt到supervisor003节点
* 首先上传拓扑
* bin/storm jar storm_example.jar storm.scheduler.SumTopology sum supervisor002 supervisor003
*/
public class DirectScheduledTopology {
/**
* Spout需要继承BaseRichSpout
* 数据源需要产生数据并发射
*/
public static class DataSourceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
/**
* 初始化方法,只会被调用一次
*
* @param conf 配置参数
* @param context 上下文
* @param collector 数据发射器
*/
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
int number = 0;
/**
* 会产生数据,在生产上肯定是从消息队列中获取数据
* 这个方法是一个死循环,会一直不停的执行
*/
@Override
public void nextTuple() {
this.collector.emit(new Values(++number));
System.out.println("Spout: " + number);
// 防止数据产生太快
Utils.sleep(1000);
}
/**
* 声明输出字段
* @param declarer
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("num"));
}
}
/**
* 数据的累积求和Bolt:接收数据并处理
*/
public static class SumBolt extends BaseRichBolt {
private OutputCollector out;
/**
* 初始化方法,会被执行一次
*
* @param stormConf
* @param context
* @param collector
*/
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
out = collector;
}
int sum = 0;
/**
* 其实是一个死循环调用,职责:获取Spout发送过来的数据
* @param input
*/
@Override
public void execute(Tuple input) {
// Bolt中获取值可以根据index获取
// 也可以根据上一个环节中定义的field的名称获取(建议)
Integer value = input.getIntegerByField("num");
sum += value;
System.out.println("sum: " + sum);
out.emit(new Values(sum));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sum"));
}
}
public static void main(String[] args) throws Exception {
String topologyName = "sum-topology";
String spoutSupervisorName = "supervisor002";
String boltSupervisorName = "supervisor003";
if (args != null && args.length > 2) {
topologyName = args[0];
spoutSupervisorName = args[1];
boltSupervisorName = args[2];
} else {
System.out.println("Usage:");
System.out.println("storm jar path-to-jar-file main-class topology-name spout-supervisor-name bolt supervisor-name");
System.exit(1);
}
String spoutId = "num-spout";
String boltId = "sum-bolt";
Config config = new Config();
config.setDebug(true);
config.setNumWorkers(2);
Map<String, String> component2Node = new HashMap<>();
component2Node.put(spoutId, spoutSupervisorName);
component2Node.put(boltId, boltSupervisorName);
// 此标识代表topology需要被
// 我们的自定义调度器 DirectScheduler 调度
config.put("assigned_flag", "1");
// 具体的组件节点对信息
config.put("design_map", component2Node);
// TopologyBuilder根据Spout和Bolt来构建出Topology
// Storm中任何一个作业都是通过Topology的方式进行提交的
// Topology中需要指定Spout和Bolt的执行顺序
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("num-spout", new DataSourceSpout(), 2);
builder.setBolt("sum-bolt", new SumBolt(), 2).shuffleGrouping("num-spout");
// 创建一个本地Storm集群:本地模式运行,不需要搭建Storm集群
// new LocalCluster().submitTopology("sum-topology", config, builder.createTopology());
StormSubmitter.submitTopology(topologyName, config, builder.createTopology());
}
}打成jar包, 上传至nimbus所在节点的storm下的lib目录下
集群环境搭建(3节点)
准备三台机器,hadoop001, hadoop002, hadoop003.
我们希望hadoop001启动: nimbus, ui, logviewer, supervisor
hadoop002,hadoop002启动: supervisor, logviewer
各节点的分工如下:
| hostname | nimbus | supervisor | zookeeper |
|---|---|---|---|
| hadoop001 | √ | √(supervisor001) | server.1 |
| hadoop002 | √(supervisor002) | server.2 | |
| hadoop003 | √(supervisor003) | server.3 |
虚拟机准备
可以先配置一台机器, 假设主机名为hadoop001, 静态IP为192.168.186.100. 接下来分别安装jdk环境, 解压zookeeper和storm的安装文件到指定目录~/app下面, 配置环境变量如下:
~/.bash_profile
...
# JAVA ENV
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_211
PATH=$JAVA_HOME/bin:$PATH
# ZOOKEEPER HOME
export ZOOKEEPER_HOME=/home/hadoop/app/zookeeper-3.4.11
PATH=$ZOOKEEPER_HOME/bin:$PATH
# STORM HOME
export STORM_HOME=/home/hadoop/app/storm-2.1.0
PATH=$STORM_HOME/bin:$PATH
...之后再克隆出另外两台虚拟机, 修改IP分别为192.168.186.102和192.168.186.103.修改主机名为hadoop002和hadoop003.
克隆方式如下:
三台机器/etc/hosts文件修改如下:
192.168.186.101 hadoop001
192.168.186.102 hadoop002
192.168.186.103 hadoop003配置SSH免密
为了便于集群中个节点互访, 每台机器都需要通过ssh-keygen命令后输入三次回车生成一对密钥(公钥和私钥), 可以在~/.ssh下查看, 并将自己的公钥通过ssh-copy-id命令分发给其他机器的~/.ssh/authorized_keys(必须是600权限)文件中:
[hadoop@hadoop001 .ssh]$ ssh-keygen -t rsa
[hadoop@hadoop002 .ssh]$ ssh-keygen -t rsa
[hadoop@hadoop003 .ssh]$ ssh-keygen -t rsa
[hadoop@hadoop001 .ssh]$ ssh-copy-id hadoop@hadoop002
[hadoop@hadoop001 .ssh]$ ssh-copy-id hadoop@hadoop003
[hadoop@hadoop002 .ssh]$ ssh-copy-id hadoop@hadoop001
[hadoop@hadoop002 .ssh]$ ssh-copy-id hadoop@hadoop003
[hadoop@hadoop003 .ssh]$ ssh-copy-id hadoop@hadoop001
[hadoop@hadoop003 .ssh]$ ssh-copy-id hadoop@hadoop002测试: (以从hadoop001连接hadoop002为例)
[hadoop@hadoop001 .ssh]$ ssh hadoop002
Last login: Sun Oct 17 01:15:17 2021 from hadoop001
[hadoop@hadoop002 ~]$ exit
登出
Connection to hadoop002 closed.搭建zookeeper集群
跟单机基本一致, 配置文件相同
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/hadoop/app/zookeeper-3.4.11/dataDir
dataLogDir=/home/hadoop/app/zookeeper-3.4.11/dataLogDir
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
# 将所有命令添加到白名单中
4lw.commands.whitelist=*
# 配置zookeeper服务器的 [主机名或主机ID]:[同步端口(唯一)]:[选举端口(唯一)]
server.1=hadoop001:2888:3888
server.2=hadoop002:2888:3888
server.3=hadoop003:2888:3888但是$dataDir下的myid文件保存的数字应该和对应server的id一致
然后分别启动三个机器的zookeeper就可以了
使用status查看应该有2个follower和1个leader
搭建Storm集群
除了storm.zookeeper.servers和nimbus.seeds的配置不同之外, 和单机的storm配置基本相同.
hadoop001的配置:
"pology.eventlogger.executors": 1
storm.zookeeper.servers:
- "hadoop001"
- "hadoop002"
- "hadoop003"
storm.local.dir: "/home/hadoop/app/storm-2.1.0/data"
nimbus.seeds: ["hadoop001"]
storm.zookeeper.port: 2181
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
ui.port: 8082
# 自定义调度器, 需要提前将jar包放在nimbus节点storm安装目录的lib目录里
storm.scheduler: "storm.scheduler.DirectScheduler"
# 自定义属性, 配合自定义调度器使用
supervisor.scheduler.meta:
name: "supervisor001"hadoop002的配置:
"pology.eventlogger.executors": 1
storm.zookeeper.servers:
- "hadoop001"
- "hadoop002"
- "hadoop003"
storm.local.dir: "/home/hadoop/app/storm-2.1.0/data"
nimbus.seeds: ["hadoop001"]
storm.zookeeper.port: 2181
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
ui.port: 8082
supervisor.scheduler.meta:
name: "supervisor002"hadoop003的配置:
"pology.eventlogger.executors": 1
storm.zookeeper.servers:
- "hadoop001"
- "hadoop002"
- "hadoop003"
storm.local.dir: "/home/hadoop/app/storm-2.1.0/data"
nimbus.seeds: ["hadoop001"]
storm.zookeeper.port: 2181
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
ui.port: 8082
supervisor.scheduler.meta:
name: "supervisor003"然后分别启动以下进程
[hadoop@hadoop001 storm-2.1.0]$ jps
2964 Jps
2310 Nimbus
2871 LogviewerServer
2186 QuorumPeerMain
2555 UIServer
2412 Supervisor
[hadoop@hadoop002 storm-2.1.0]$ jps
2309 LogviewerServer
2217 Supervisor
2558 Jps
2095 QuorumPeerMain
[hadoop@hadoop003 storm-2.1.0]$ jps
2165 Supervisor
2234 LogviewerServer
2333 Jps
2095 QuorumPeerMain集群启停脚本编写
start-zookeeper-cluster.sh
#/bin/bash
echo "========== zk start =========="
for node in hadoop001 hadoop002 hadoop003
do
ssh $node "source $HOME/.bash_profile;zkServer.sh start $ZOOKEEPER_HOME/conf/zoo.cfg"
done
echo "wait 5 secs .... ...."
sleep 5
echo "========== zk status =========="
for node in hadoop001 hadoop002 hadoop003
do
ssh $node "source $HOME/.bash_profile;zkServer.sh status $ZOOKEEPER_HOME/conf/zoo.cfg"
done
echo "wait 5 secs .... ...."
sleep 5start-storm-cluster.sh
#/bin/bash
echo "========== storm start =========="
ssh hadoop001 "source $HOME/.bash_profile;nohup storm nimbus > /dev/null 2>&1 &"
ssh hadoop001 "source $HOME/.bash_profile;nohup storm ui > /dev/null 2>&1 &"
ssh hadoop001 "source $HOME/.bash_profile;nohup storm supervisor > /dev/null 2>&1 &"
ssh hadoop001 "source $HOME/.bash_profile;nohup storm logviewer > /dev/null 2>&1 &"
ssh hadoop002 "source $HOME/.bash_profile;nohup storm supervisor > /dev/null 2>&1 &"
ssh hadoop002 "source $HOME/.bash_profile;nohup storm logviewer > /dev/null 2>&1 &"
ssh hadoop003 "source $HOME/.bash_profile;nohup storm supervisor > /dev/null 2>&1 &"
ssh hadoop003 "source $HOME/.bash_profile;nohup storm logviewer > /dev/null 2>&1 &"需要保证三台机器都设置正确的环境变量, 如果必要可以将hadoop001的环境变量通过
scp命令覆盖到其他机器上去如:[hadoop@hadoop001]$ scp ~/.bash_profile hadoop@hadoop002:~/.bash_profile [hadoop@hadoop001]$ scp ~/.bash_profile hadoop@hadoop003:~/.bash_profile
下面这个xRunCommand.sh脚本用来在集群中执行相同的命令并返回结果
#/bin/bash
if (( $# == 0 ));then
echo "Usage /path/to/xRunCommand.sh \"<COMMAND>\""
exit 0
fi
for node in hadoop001 hadoop002 hadoop003
do
echo "======== $node ========"
echo "ssh $node $1"
ssh $node "source ~/.bash_profile;$1"
done比如可以xRunCommand.sh jps来查看集群中三台机器中的所有java进程
[hadoop@hadoop001 scripts]$ ./xRunCommand.sh jps
======== hadoop001 ========
ssh hadoop001 jps
8656 Jps
7220 QuorumPeerMain
7976 UIServer
8026 LogviewerServer
7933 Nimbus
======== hadoop002 ========
ssh hadoop002 jps
6119 Supervisor
7031 Jps
5753 QuorumPeerMain
6235 Worker
6223 LogWriter
======== hadoop003 ========
ssh hadoop003 jps
6896 Jps
6002 Supervisor
6119 Worker
5641 QuorumPeerMain
6107 LogWriter提交拓扑到集群
在hadoop001及nimbus所在节点,使用以下命令提交拓扑
storm jar $STORM_HOME/lib/storm_example-0.0.1-SNAPSHOT.jar storm.scheduler.DirectScheduledTopology sum-topo supervisor002 supervisor003其中:
-
第一个参数
sum-topo为拓扑名称 -
第二个参数
supervisor002和第三个参数supervisor003表示调度的目的地即调度spout组件到
supervisor002节点,调度bolt组件到supervisor003节点具体逻辑请查看
DirectScheduledTopology类中的源代码
提交后, 即可在UI界面查看结果:
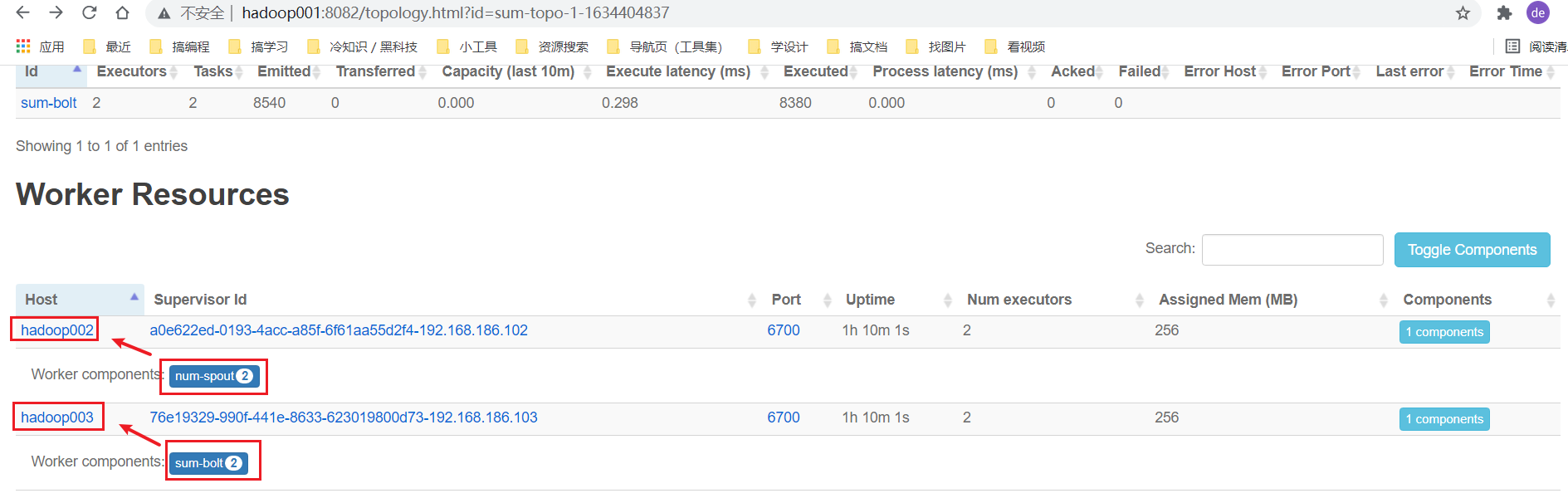
可见我们的自定义调度器确实起作用了.
也可以通过$STORM_HOME/logs/nimbus.log查看到DirectScheduler类输出的相关日志, 例如:
2021-10-17 01:20:40.659 s.s.DirectScheduler timer [INFO] use custom scheduler
2021-10-17 01:20:40.659 s.s.DirectScheduler timer [INFO] supervisor name:SupervisorDetails ID: a0e622ed-0193-4acc-a85f-6f61aa55d2f4-192.168.186.102 HOST: hadoop002 META: null SCHED_META: {name=supervisor002} PORTS: [6700, 6701, 6702, 6703]
2021-10-17 01:20:40.660 s.s.DirectScheduler timer [INFO] assigned executors:[[4, 4], [3, 3]] to slot: [a0e622ed-0193-4acc-a85f-6f61aa55d2f4-192.168.186.102, 6700]
2021-10-17 01:20:40.673 s.s.DirectScheduler timer [INFO] supervisor name:SupervisorDetails ID: 76e19329-990f-441e-8633-623019800d73-192.168.186.103 HOST: hadoop003 META: null SCHED_META: {name=supervisor003} PORTS: [6700, 6701, 6702, 6703]
2021-10-17 01:20:40.673 s.s.DirectScheduler timer [INFO] assigned executors:[[6, 6], [5, 5]] to slot: [76e19329-990f-441e-8633-623019800d73-192.168.186.103, 6700]Nimbus失败异常处理
问题描述
启动Storm集群后发现错误如下:
org.apache.storm.utils.NimbusLeaderNotFoundException: Could not find leader nimbus from seed hosts ["hadoop001"]. Did you specify a valid list of nimbus hosts for config nimbus.seeds?问题原因
可能是Zookeeper所保存的数据和现在集群的状态不一致, 也可能是nimbus进程异常退出(具体可在nimbus节点查看nimbus日志$STORM_HOME/logs/nimbus.log进行错误排查)
解决办法
不管是何种原因, 都可以使用下面的方法简单粗暴的解决:
注意, 以下处理方法会导致Storm集群中的所有运行的拓扑任务丢失.
-
先停止storm集群再停止zookeeper集群
# 停止storm集群只要使用kill -9 杀死相关进程即可 kill -9 ... ... ... ... ~/scripts/stop-zookeeper-cluster.sh -
删除所有zookeeper下
dataDir除了myid之外的所有文件.[hadoop@hadoop001]$ rm -rf ~/app/zookeeper-3.4.11/dataDir/version-2/ [hadoop@hadoop002]$ rm -rf ~/app/zookeeper-3.4.11/dataDir/version-2/ [hadoop@hadoop003]$ rm -rf ~/app/zookeeper-3.4.11/dataDir/version-2/ -
启动zookeeper集群
~/scripts/start-zookeeper-cluster.sh -
在任意zookeeper集群的节点使用以下命令删除Storm保存在zookeeper中的数据
$ zkCli.sh > rmr /storm -
最后启动storm集群即可.
$ ~/scripts/start-storm-cluster.sh
谢谢!
Views: 307