
需求
针对twitter网站上的一篇推文的接触用户(也叫REACH值)进行统计。
Reach值让你了解推文的真实覆盖到的用户群体, 要计算一个推文URL的Reach值,需要以下4步:
- 根据推文的URL查询数据库获取全部直接接触用户(转发的用户)
- 再根据接触用户通过查询数据库获取每个用户的全部粉丝
- 对粉丝集合中的用户进行去重处理
- 最后统计去重后的用户数, 即这个推文的Reach值
拓扑定义
一个单独的Reach计算在计算期间可能涉及到数千次数据库访问和数千万的粉丝记录查询,可能是一个非常耗时的计算。在storm上实现这个功能非常简单。在一台机器上,Reach计算可能花费数分钟,而在storm集群,最难计算Reach的URL也只需数秒。
Storm-starter 项目中有一个计算Reach样例,Reach拓扑定义如下所示:
LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("reach");
builder.addBolt(new GetTweeters(), 3);
builder.addBolt(new GetFollowers(), 2) .shuffleGrouping();
builder.addBolt(new PartialUniquer(), 3) .fieldsGrouping(new Fields("id", "follower"));
builder.addBolt(new CountAggregator()) .fieldsGrouping(new Fields("id"));
过程分析
以计算https://tech.backtype.com/blog/123的Reach值为例进行说明:
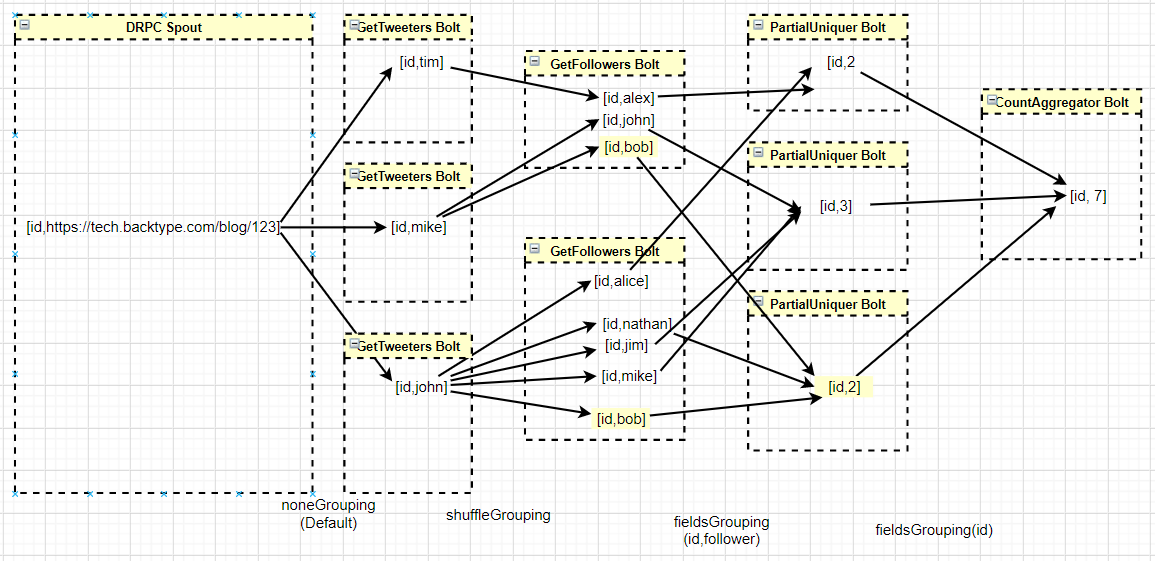
这个拓扑以4个步骤的形式执行, 因此一共有4个Bolt:
GetTweeters从数据库获取给定URL对应的用户并发射出去GetFollowers从数据库获取每个用户对应的粉丝并发射出去PartialUniquer按粉丝进行字段分组并利用Set集合进行去重处理, 将去重后的粉丝数量进行局部累加, 并把结果发送出去- 最后,
CountAggregator从每个PartialUniquer任务接收计数并对累加求和作为返回值给DRPC客户端。
项目代码
为了方便项目中数据库使用Map集合进行伪造, 代码如下:
package storm.example.drpc;
/**
* 计算推文的REACH值
* storm.example.drpc.AdvanceDRPCTopology
*/
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.LocalDRPC;
import org.apache.storm.StormSubmitter;
import org.apache.storm.coordination.BatchOutputCollector;
import org.apache.storm.drpc.LinearDRPCTopologyBuilder;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.topology.base.BaseBatchBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.*;
// 计算一篇推文的REACH值
public class AdvanceDRPCTopology {
// MAP: URL -> USER
public static Map<String, List<String>> TWEETERS_DB = new HashMap<String, List<String>>() {{
put("foo.com/blog/1", Arrays.asList("sally", "bob", "tim", "george", "nathan"));
put("engineering.twitter.com/blog/5", Arrays.asList("adam", "david", "sally", "nathan"));
put("tech.backtype.com/blog/123", Arrays.asList("tim", "mike", "john"));
}};
// MAP: USER -> FOLLOWERS
public static Map<String, List<String>> FOLLOWERS_DB = new HashMap<String, List<String>>() {{
put("sally", Arrays.asList("bob", "tim", "alice", "adam", "jim", "chris", "jai"));
put("bob", Arrays.asList("sally", "nathan", "jim", "mary", "david", "vivian"));
put("tim", Arrays.asList("alex"));
put("nathan", Arrays.asList("sally", "bob", "adam", "harry", "chris", "vivian", "emily", "jordan"));
put("adam", Arrays.asList("david", "carissa"));
put("mike", Arrays.asList("john", "bob"));
put("john", Arrays.asList("alice", "nathan", "jim", "mike", "bob"));
}};
public static LinearDRPCTopologyBuilder construct() {
LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("reach");
builder.addBolt(new GetTweeters(), 3);
builder.addBolt(new GetFollowers(), 2).shuffleGrouping();
builder.addBolt(new PartialUniquer(), 3).fieldsGrouping(new Fields("id", "follower"));
builder.addBolt(new CountAggregator(), 1).fieldsGrouping(new Fields("id"));
return builder;
}
public static void main(String[] args) throws Exception {
LinearDRPCTopologyBuilder builder = construct();
Config conf = new Config();
if (args == null || args.length == 0) {
// conf.setMaxTaskParallelism(3);
LocalDRPC drpc = new LocalDRPC();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("reach-drpc", conf, builder.createLocalTopology(drpc));
String[] urlsToTry = new String[]{"foo.com/blog/1", "engineering.twitter.com/blog/5", "notaurl.com", "tech.backtype.com/blog/123"};
for (String url : urlsToTry) {
System.err.println("Thread[" + Thread.currentThread().getName() + "] " +"Reach of " + url + ": " + drpc.execute("reach", url));
Utils.sleep(10000);
}
cluster.shutdown();
drpc.shutdown();
} else {
conf.setNumWorkers(1); //6
StormSubmitter.submitTopology(args[0], conf, builder.createRemoteTopology());
}
}
// BOLT 1: 根据URL发送推特用户到数据流中
public static class GetTweeters extends BaseBasicBolt {
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
Object id = tuple.getValue(0);
String url = tuple.getString(1);
List<String> tweeters = TWEETERS_DB.get(url);
if (tweeters != null) {
for (String tweeter : tweeters) {
collector.emit(new Values(id, tweeter));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "tweeter"));
}
}
// BOLT 2: 根据推特用户发送对应的粉丝到数据流中
public static class GetFollowers extends BaseBasicBolt {
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
Object id = tuple.getValue(0);
String tweeter = tuple.getString(1);
List<String> followers = FOLLOWERS_DB.get(tweeter);
if (followers != null) {
for (String follower : followers) {
System.err.println("Thread[" + Thread.currentThread().getName() + "] " + "request-id[" + id + "]: " + tweeter + "'s follower: " + follower);
collector.emit(new Values(id, follower));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "follower"));
}
}
// BOLT 3: 对粉丝去重后的计数发送的数据流中
public static class PartialUniquer extends BaseBatchBolt {
BatchOutputCollector collector;
Object id;
Set<String> followers = new HashSet<String>();
@Override
public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, Object id) {
this.collector = collector;
this.id = id;
}
@Override
public void execute(Tuple tuple) {
followers.add(tuple.getString(1));
}
@Override
public void finishBatch() {
System.err.println("Thread[" + Thread.currentThread().getName() + "] " +"request-id[" + id + "]: " + "followers.size(): " + followers.size() + followers);
collector.emit(new Values(id, followers.size()));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "partial-count"));
}
}
// BOLT 4:将所有计数累加的结果发送的数据流中
public static class CountAggregator extends BaseBatchBolt {
BatchOutputCollector collector;
Object id;
int reach = 0;
@Override
public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, Object id) {
this.collector = collector;
this.id = id;
}
@Override
public void execute(Tuple tuple) {
int partiaLReach = tuple.getInteger(1);
System.err.println("Thread[" + Thread.currentThread().getName() + "] " +"request-id[" + id + "]: " + "Partial reach is " + partiaLReach);
reach += tuple.getInteger(1);
}
@Override
public void finishBatch() {
System.err.println("Thread[" + Thread.currentThread().getName() + "] " +"request-id[" + id + "]: " + "Global reach is " + reach);
collector.emit(new Values(id, reach));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "reach"));
}
}
}Reach计算的每一单步都是可以并行执行的,而且定义一个DRPC拓扑也非常简单。
需要注意的是, CountAggregator 只有在 PartialUniquer 并行度大于1个时候才有意义.
另外CountAggregator 和 PartialUniquer 这两个Bolt都是继承的BaseBatchBolt,这种Bolt发射数据流的时机是在相同id的数据都处理完成后, 才会触发(类似事务).
谢谢!
Views: 344