
HBase是什么
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
Use Apache HBase™ when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google's Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.official home: https://hbase.apache.org/
bigtable: https://research.google.com/archive/bigtable.html
MySQL查询使用B+ tree, 具有很快的性能. 但是当数据过大的时候会影响查询速度, 解决方法: 分库分表, 横向/纵向切分, 读写分离. 保存结构性数据, 也不适合保存过多的字段, 另外空字段也占用存储空间.
IO问题: mysql对字段查询是跳跃的. HBase对列查询时顺序读, 因此速度快.
非关系型(No-SQL)数据库有:
- Redis 键值型
- Cassandra
- hbase(面向列)
- mongodb(JSON- 半结构化, 文档型数据库)
- Couchdb, 文件存储数据库
- Neo4j非关系型图数据库(DAG)
HBase在Hadoop生态系统中的位置:
分析挖掘->Mahout(数据挖掘), Pig(逐渐淘汰),Hive
即时查询->HBase 数据计算->MapReduce
数据存储->HDFS
数据采集,传输->埋点, Flume, Sqoop, DataX
协作服务->Zookeeper
HBase的概念
HBase - Hadoop dataBase
- HBase基于Google的BigTable论文,是建立的HDFS之上,提供高可靠性、高性能、面向列的存储、可伸缩、实时读写的分布式数据库系统。
在需要实时读、写随机访问、超大规模数据集时,可以使用HBase。 - 利用Hadoop HDFS作为底层文件存储系统, 利用Hadoop MapReduce 处理HBase中的海量数据, 利用Zookeeper(HA)作为其分布式协同服务.
- 主要存储非结构化和半结构化的松散数据(按列存储)
- 半结构化 JSON, XML
- 非结构化 Redis/memche
- MySQL如何保存非结构化数据?
SESSION01:什么是半结构化数据和非结构化数据
关系型数据库和HBase的区别
HBase的特点
-
极易扩展,海量存储
底层依赖HDFS,当磁盘空间不足的时候,只需要动态增加datanode节点就可以了
可以通过增加服务器来对集群的存储进行扩容
-
列式存储
HBase表的数据是基于列族进行存储的,列族(或者列簇Column Family)是在列的方向上的划分。
-
高并发
支持高并发的读写请求
-
稀疏
稀疏主要是针对HBase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
-
数据的多版本
HBase表中的数据可以有多个版本值,默认情况下是根据版本号去区分,版本号就是插入数据的时间戳
-
数据类型单一
所有的数据在HBase中是以字节数组进行存储
对比MySQL来看HBase的优缺点
Hbase的优点
- 大:一个表可以有上十亿行,上百万列。
- 面向列:面向列(簇)的存储和权限控制,列(簇)独立检索。
- 稀疏:对于为空(null)的列并不占用内存空间,因此,表可以设计的非常稀疏。
- 多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳。
- 数据类型单一:HBase中数据类型都是字符串。
- 无模式(即没有固定的schema结构):每一行都有一个可以排序的rowKey和任意多的列,列可以根据需要动态增加,同一张表的不同行可以有截然不同的列。
- 高可靠性:WAL预写式日志(write-ahead log)机制保证了数据写入时不会因集群异常而导致写入数据丢失,Replication机制保证了在集群出现严重的问题时,数据不会发生丢失或损坏。而且Hbase底层使用HDFS,HDFS本身也有备份。
- 高性能:底层的LSM数据结构和Rowkey有序排列等架构上的独特设计,使得Hbase具有非常高的写入性能。region切分,主键索引和缓存机制使得Hbase在海量数据下具备一定的随机读取性能,并支持高效的并发读写, 针对Rowkey的查询能到达到毫秒级别。
- Hbase自动切分数据(Auto Sharding),使得数据存储自动具有水平scalability.
Hbase的缺点:
- 不适合保存结构化数据, 不支持SQL语句
- 不能支持条件查询,只支持按照Row key来查询. 但是可以设置二级索引提高查询速度.
如果HBase集群中只有一个Master server,当Master宕机后,整个存储系统就会挂掉.但是配置HA后,HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行。
所以这里要配置HBase高可用的话,只需要启动两个HMaster,让Zookeeper自己去选择一个Master Acitve。
另外,从以下角度再对比HBase和MySQL
-
数据类型,Hbase只有简单的字符类型,所有的类型都是交由用户自己处理,它只保存字符串。而关系数据库有丰富的类型和存储方式。
-
数据操作:HBase只有很简单的插入、查询、删除、清空等操作,表和表之间是分离的,没有复杂的表和表之间的关系,而传统数据库通常有各式各样的函数和连接操作。
-
存储模式:HBase是基于列存储的,每个列族都由几个文件保存,不同的列族的文件时分离的。而传统的关系型数据库是基于表格结构和行模式保存的数据维护,HBase的更新操作不应该叫更新,它实际上是插入了新的数据,而传统数据库是替换修改.
-
可伸缩性,HBase这类分布式数据库就是为了这个目的而开发出来的,所以它能够轻松增加或减少硬件的数量,并且对错误的兼容性比较高。而传统数据库通常需要增加中间层才能实现类似的功能
HBase在实际场景中的应用
海量数据+实时批量读写
-
交通方面
船舶GPS信息,全长江的船舶GPS信息,每天有1千万左右的数据存储。
-
金融方面
消费信息、贷款信息、信用卡还款信息等 -
电商方面
电商网站的交易信息、物流信息、游览信息等 -
电信方面
通话信息、语音详单等 -
游戏营销活动新渠道
数据的实时性对于营销活动的效果有着十分明显的影响,由于数据延迟而带来的不良用户体验会导致玩家丧失继续参与活动的耐心从而使活动效果大打折扣。HBase在近几次营销活动(如炫舞拉新活动、天天酷跑新版预热活动、英雄联盟3周年活动、天天酷跑周年活动、英雄联盟拉新活动)中,从几十亿甚至百亿条数据中实时拉取数据的毫秒级响应,成为营销活动的一个新渠道。 -
广告日志处理
广告成为互联网公司的一个主要收入来源。我们现在每天通过HBase处理百亿级广告的请求和曝光日志,访问HBase的延迟,80%在20ms之内,保证了数据的秒级实时回流,实现检索、曝光、点击和效果日志百亿数据的实时关联,提供完整丰富的用户特征数据。精细的特征数据会带来更好的模型,产生更好的广告效果,进而提升广告收入。 -
业务受理查询
业务受理系统受限于MySQL数据库容量与性能,仅能查询最近一段时间的日志,使游戏在核实客户投诉上较为被动。游戏业务受理系统由MySQL迁移到HBase后,用业务的评价来总结下MySQL迁移HBase的效果:“业务受理对客服的查询需求服务提升了一个档次”。 -
其它
此外,HBase在其他点击交互日志或监控日志系统上也有较多应用,如网络会话数据、秒级监控平台日志、微信支付日志等。
总结: HBase适合保存海量的明细数据, 并提供即时查询. 随着业务的发展以及HBase在大数据方向较多的成功应用案例与推广,HBase的应用还将继续增多以及向核心应用靠近的趋势。总的来说,我们的目标,降低接入使用门槛以及使用成本,使HBase能稳定地部署到更多的应用中去, 以助力业务更快发展。
HBase单机学习环境配置
HBase的运行模式介绍
HBase的运行模式分为单机,伪分布式,以及完全分布式:
-
In standalone mode: all daemons ran in one jvm process/instance.
-
Pseudo-distributed mode: it means that HBase still runs completely on a single host, but each HBase daemon (HMaster, HRegionServer, and ZooKeeper) runs as a separate process.
-
Advanced-Fully-Distributed mode: In reality, you need a fully-distributed configuration to fully test HBase and to use it in real-world scenarios. In a distributed configuration, the cluster contains multiple nodes, each of which runs one or more HBase daemon. These include primary and backup Master instances, multiple ZooKeeper nodes, and multiple RegionServer nodes.
HBase单机安装部署
推荐Java环境使用 JDK1.8
单机模式使用内置的zookeeper即可.
单机模式数据将保存在本地文件系统, 仅供测试使用.
准备安装包:
https://hbase.apache.org/2.0/book.html#quickstart
修改配置hbase-env.sh
- 修改文件
$ cd /opt/pkg/hbase-2.2.6/conf
$ vim hbase-env.sh- 修改如下两项内容,值如下
export JAVA_HOME=/opt/pkg/java为什么很多大数据框架都要单独配置JAVA_HOME
因为SSH远程调用时需要找到JAVA环境
修改配置hbase-site.xml
Example hbase-site.xml for Standalone HBase
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///home/testuser/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/testuser/zookeeper</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
<description>
Controls whether HBase will check for stream capabilities (hflush/hsync).
Disable this if you intend to run on LocalFileSystem, denoted by a rootdir
with the 'file://' scheme, but be mindful of the NOTE below.
WARNING: Setting this to false blinds you to potential data loss and
inconsistent system state in the event of process and/or node failures. If
HBase is complaining of an inability to use hsync or hflush it's most
likely not a false positive.
</description>
</property>
</configuration>You do not need to create the HBase data directory. HBase will do this for you. If you create the directory, HBase will attempt to do a migration, which is not what you want.
运行
start-hbase.sh单机模式只会启动一个 HMaster 进程
查看UI界面 hadoop100:16010/master-status
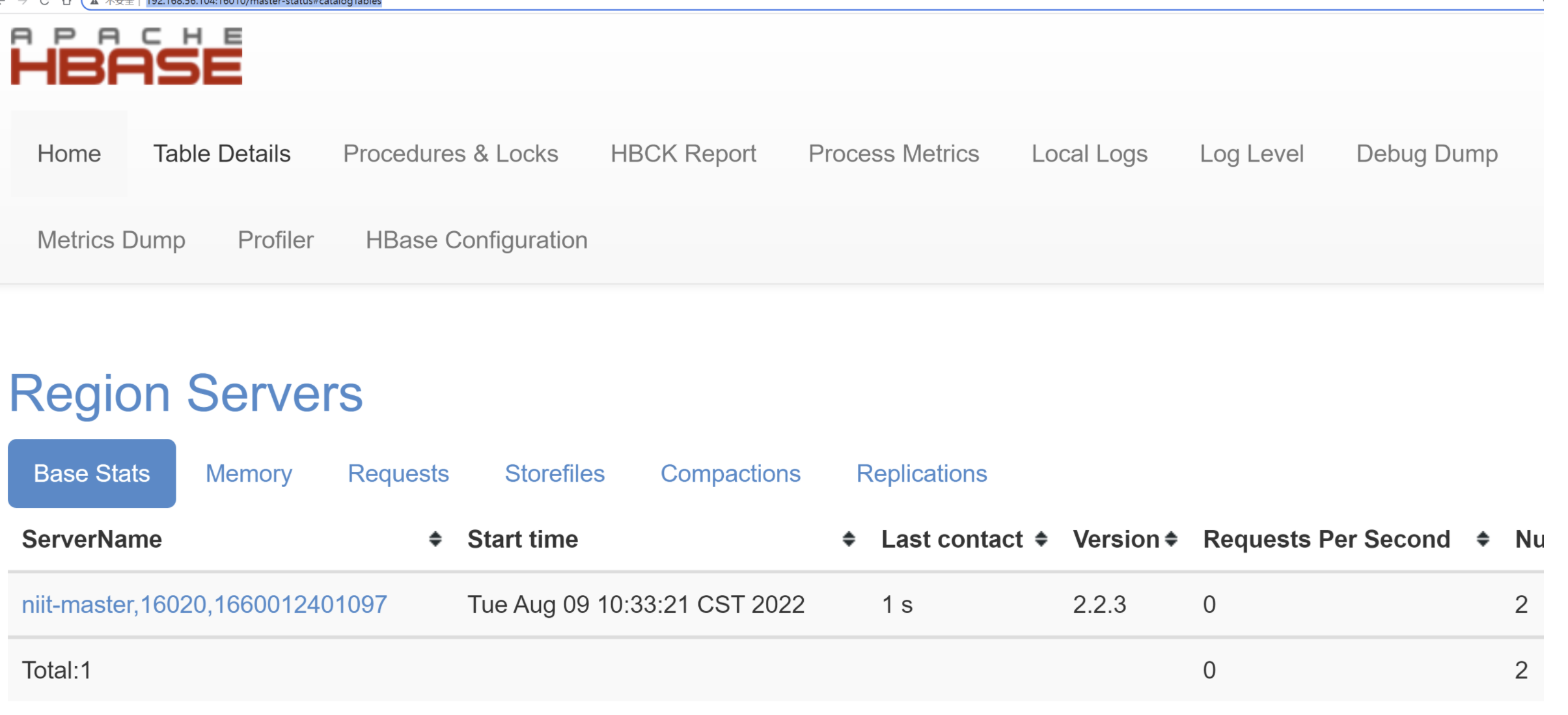
使用 hbase shell进行操作
hbase shell
hbase(main):000:0> help可以看到会列出所有相关命令,可以按照官网进行这些命令的练习.
命名空间默认为default, 数据存储的位置在 `file:///home/testuser/hbase/data/下.
添加HBase环境变量
sudo vim /etc/profile- 文件末尾添加如下内容
export HBASE_HOME=/opt/pkg/hbase-2.2.6
export PATH=$PATH:$HBASE_HOME/bin- 重新编译
/etc/profile,让环境变量生效
source /etc/profileHBase的启动与停止
- 执行以下命令,启动HBase
$ start-hbase.sh- 我们也可以执行以下命令,单节点启动相关进程
#HMaster节点上启动HMaster命令
hbase-daemon.sh start master
#启动HRegionServer命令
hbase-daemon.sh start regionserver- 执行以下命令,关闭HBase
#HMaster节点上启动HMaster命令
hbase-daemon.sh stop master
#启动HRegionServer命令
hbase-daemon.sh stop regionserverHBase表的数据模型
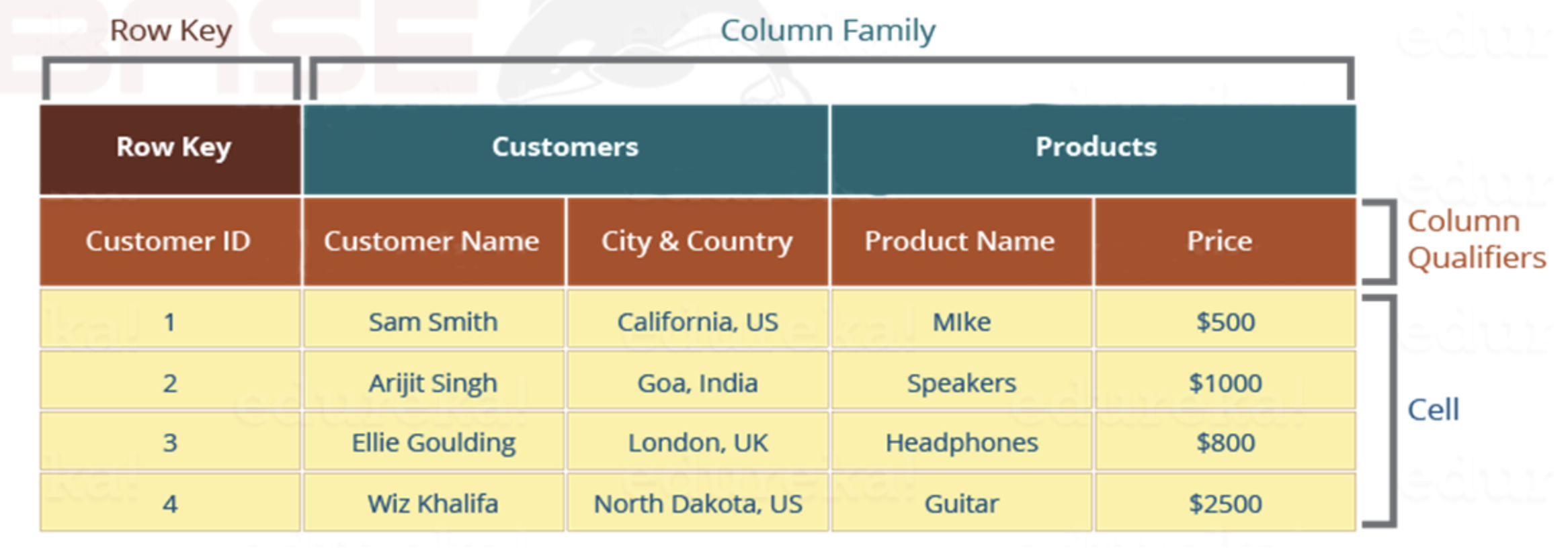
Row Key 行键
table的主键,table中的记录按照rowkey 的字典序进行排序
- 字典序 中 101 < 11
- 便于大数据场景中的范围查询(根据rowkey的范围)
Row key行键可以是任意字符串
- 最大长度是 64KB
- 为了节省空间, 实际应用中长度一般为 10-100 bytes
Column Family列族
- 列族或列簇
- HBase表中的每个列,都归属与某个列族
- 每个列族都可以包含逻辑相关的列(0,1或者多个列都可以)
- 权限控制, 存储以及调优都在再列族层面进行的
- HBase把同一列族里面的数据存储再同一目录下, 由一至多个文件保存
- 列族是表的schema的一部分(而列不是),即建表时至少指定一个列族
- 比如创建一张表,名为
user,有两个列族,分别是info和data,建表语句create 'user', 'info', 'data'
列族数量不事宜设置过多,一般不超过3个
Column 列
-
列肯定是表的某一列族下的一个列,用
列族名:列名表示,如info列族下的name列,表示为info:name -
属于某一个ColumnFamily,类似于我们mysql当中创建的具体的列
-
一个列族下可以动态添加多个列名, 理论上没有限制
-
列名不需要预先定义, 添加时指定即可
cell 单元格
-
指定row key行键、列族、列,可以确定的一个cell单元格
-
cell中的数据是没有类型的,全部是以 字节数组 进行存储
-
因此数字1 和字符串 1 的存储是不同的
-
cell是有版本的
Timestamp 时间戳 - 标记版本
- 可以对表中的Cell多次赋值,每次赋值操作时的时间戳timestamp,可看成Cell值的版本号version number
- 即一个Cell可以有多个版本的值, 根据唯一的时间戳区分每个版本之间差异,不同版本数据按照时间倒序排序, 最新的数据排在最前面.
- 时间戳类型时64位整型
- 时间戳由HBase写入数据时自动赋值, 此时时间戳时精确到毫秒的当前系统时间.
- 时间戳也可以由用户显式赋值, 如果应用程序要避免数据版本出现冲突, 就必须自己生成具有唯一性的时间戳
删除数据只标记, 触发Region合并时再真正删除
唯一的确定一个值:RowKey+CF+Qualifier+Timestamp
HBase整体架构
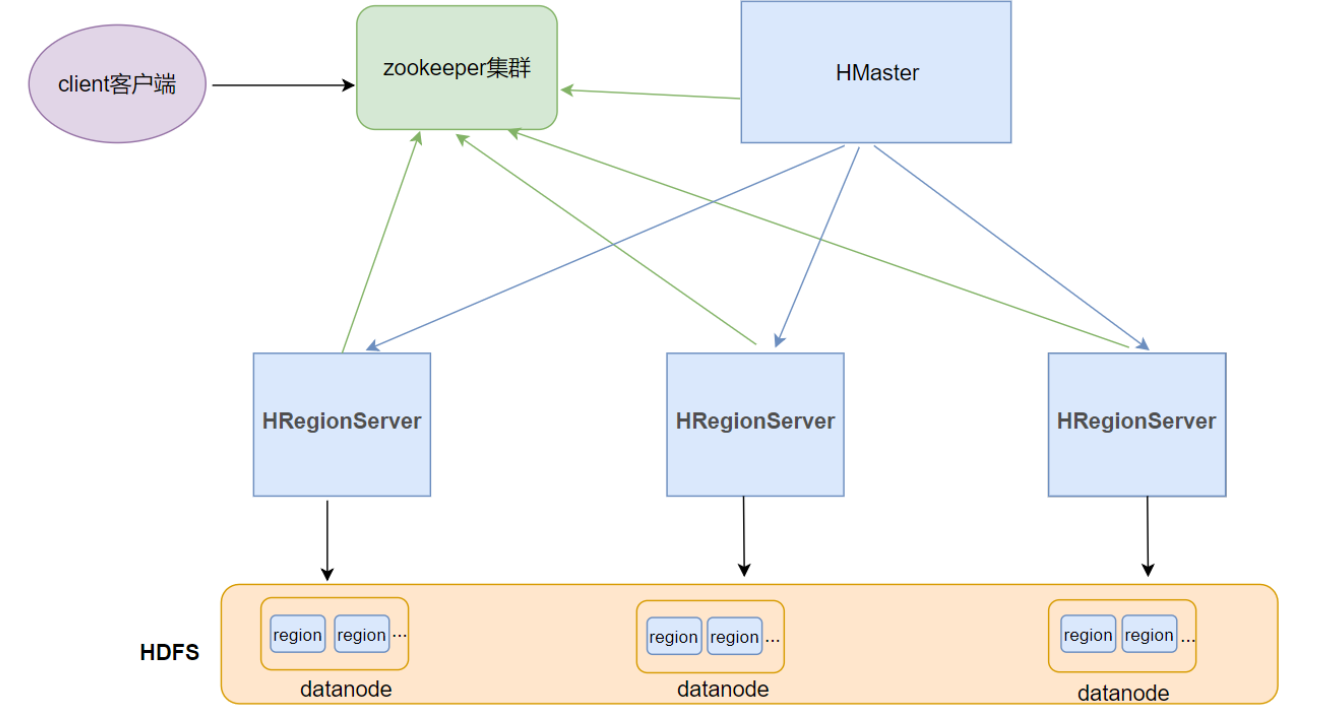
Client客户端
Client是操作HBase集群的入口
-
对于管理类的操作,如表的增、删操作(DML),Client通过RPC与HMaster通信完成
-
对于表数据的读写操作,Client通过RPC与RegionServer交互,读写数据
-
并维护客户端cache用来加快对HBase的访问速度
Client类型:
- HBase shell
- Java编程接口
- Thrift、Avro、Rest等等
ZooKeeper集群
作用
-
实现了HMaster的高可用,多HMaster间进行主备选举, 保证任何时刻只有一个活跃的HMaster.
-
保存了HBase的元数据信息meta表,提供了HBase表中region的寻址入口的线索数据
-
实时监控HRegionServer的上下线信息, 并实时通知HMaster
HMaster
HBase集群也是主从架构,HMaster是主的角色,是老大
主要负责Table表和Region(区域)的相关管理工作:
关于Table
- 管理Client对Table的增(Create)删(Drop)改(Alter)的操作
关于Region
- 在Region分裂后,负责新Region分配到指定的较为空闲的HRegionServer上
- 管理HRegionServer间的负载均衡,迁移region分布
- 避免单一RegionServer压力过大
- 当HRegionServer宕机后,负责其上的region的迁移
- 虽然缓存没有了, 数据还在DataNode里, 这时可以使用其他的RegionServer来代替宕机的RegionServer提供入口来对数据进行访问.
HRegionServer
HBase集群中从的角色,是小弟
作用
* 响应客户端的读写数据IO请求
* 负责维护和管理一系列的Region
* 切分在运行过程中变大的region
HRegion
- HBase集群中分布式存储的最小单元, 不同的HRegion可以分布在不同的HRegionServer上
- HBase自动把表水平分割成多个Region(区域)
- 一个Region对应一个Table表里面某段连续的数据(Rowkey连续)
- 每个表一开始只有一个Region, 随着数据不断插入, region不断增大, 增到到了一个阈值的时候, region就会等分裂变成为两个新的Region.
- 当table中的行不断增多, 就会有越来越多的Region. 这样一张完整的表被保存在多个RegionServer上.进而实现了负载均衡.
HBase Shell 命令基本操作
> https://learnhbase.wordpress.com/2013/03/02/hbase-shell-commands/
进入HBase客户端命令操作界面
- niit执行以下命令,进入HBase的shell客户端
[niit@niit-master ~]$ cd /usr/local/hbase-2.2.3/
[niit@niit-master hbase-2.2.3]$ bin/hbase shellhelp 帮助命令
> help
> help 'get'list 查看有哪些表
查看当前所有命名空间中有哪些表(除了hbase空间内的)
hbase(main):001:0> list
TABLE
customer
ns1:customer
2 row(s)
Took 3.0236 seconds
=> ["customer", "ns1:customer"]create 创建表
- 创建user表,包含info、data两个列族
- 使用create命令
> create 'user', 'info', 'data'默认表是创建在命名空间default下.
那么什么是命名空间呢?
命名空间 namespace
列出所有命名空间
hbase(main):006:0> list_namespace
NAMESPACE
default
hbase
ns1
3 row(s)
Took 5.1578 seconds
列出hbase命名空间下所有表
hbase(main):007:0> list_namespace_tables 'hbase'
TABLE
meta
namespace
2 row(s)
Took 0.0249 seconds
=> ["meta", "namespace"]可见hbase命名空间保存的是hbase的元数据和命名空间信息
查看hbase命名空间下的meta表
hbase(main):008:0> scan 'hbase:meta'
ROW COLUMN+CELL
customer column=table:state, timestamp=1660013934080, value=\x08\x00
customer,,1660013933024 column=info:regioninfo, timestamp=1660013934027, value={ENCODED =>
.09d9fb272c6d20ce40e72e 09d9fb272c6d20ce40e72e4625360c36, NAME => 'customer,,1660013933024.
4625360c36. 09d9fb272c6d20ce40e72e4625360c36.', STARTKEY => '', ENDKEY => ''}
customer,,1660013933024 column=info:seqnumDuringOpen, timestamp=1660013934027, value=\x00\x
.09d9fb272c6d20ce40e72e 00\x00\x00\x00\x00\x00\x02
4625360c36.
customer,,1660013933024 column=info:server, timestamp=1660013934027, value=niit-master:1602
.09d9fb272c6d20ce40e72e 0
4625360c36.
customer,,1660013933024 column=info:serverstartcode, timestamp=1660013934027, value=1660012
.09d9fb272c6d20ce40e72e 401097
4625360c36.
customer,,1660013933024 column=info:sn, timestamp=1660013933615, value=niit-master,16020,16
.09d9fb272c6d20ce40e72e 60012401097
4625360c36.
customer,,1660013933024 column=info:state, timestamp=1660013934027, value=OPEN
.09d9fb272c6d20ce40e72e
4625360c36.
hbase:namespace column=table:state, timestamp=1660012428489, value=\x08\x00
hbase:namespace,,166001 column=info:regioninfo, timestamp=1660012428434, value={ENCODED =>
2427045.72ef58633624475 72ef5863362447542d96df3d20a70967, NAME => 'hbase:namespace,,1660012
42d96df3d20a70967. 427045.72ef5863362447542d96df3d20a70967.', STARTKEY => '', ENDKEY =
> ''}
hbase:namespace,,166001 column=info:seqnumDuringOpen, timestamp=1660012428434, value=\x00\x
2427045.72ef58633624475 00\x00\x00\x00\x00\x00\x02
42d96df3d20a70967.
hbase:namespace,,166001 column=info:server, timestamp=1660012428434, value=niit-master:1602
2427045.72ef58633624475 0
42d96df3d20a70967.
hbase:namespace,,166001 column=info:serverstartcode, timestamp=1660012428434, value=1660012
2427045.72ef58633624475 401097
42d96df3d20a70967.
hbase:namespace,,166001 column=info:sn, timestamp=1660012428020, value=niit-master,16020,16
2427045.72ef58633624475 60012401097
42d96df3d20a70967.
hbase:namespace,,166001 column=info:state, timestamp=1660012428434, value=OPEN
2427045.72ef58633624475
42d96df3d20a70967.生产环境使用
scan时要避免一次扫描过多的数据
创建表t1在指定命名空间ns1下,有一个列族f1
hbase(main):009:0> create 'ns1:t1', 'f1'
Created table ns1:t1
Took 0.8206 seconds
=> Hbase::Table - ns1:t1
hbase(main):010:0> list
TABLE
customer
user
ns1:customer
ns1:t1
4 row(s)
Took 0.0536 seconds
=> ["customer", "user", "ns1:customer", "ns1:t1"]put 插入数据操作
- 向表中插入数据
- 使用put命令
> put 'user', 'rk001', 'info:name', 'maggie'数据写入流程:
-
数据一开始先写到HLOG(WAL)和内存中
-
当内存中的数据增长到某个阈值, 会自动flush刷盘到文件(HFile)
-
我们可以通过
flush 'user'强行刷盘 -
形成的文件
SquenceFile格式, 键值存储的二进制的格式.支持Hadoop的block级别压缩 -
可以
hbase hfile -p -f file:///path-to/xxx进行查看$ hbase hfile -p -f file:///home/niit/hbase/data/default/user/d03b7e1ec3430595f66f3ed7f58ae89f/info/8d6095e5fc5b4fdcb3def928cc202f53 2022-08-09 16:08:26,040 INFO [main] metrics.MetricRegistries: Loaded MetricRegistries class org.apache.hadoop.hbase.metrics.impl.MetricRegistriesImpl K: rk001/info:id/1660028654894/Put/vlen=7/seqid=5 V: niit001 K: rk001/info:name/1660029085323/Put/vlen=3/seqid=7 V: leo K: rk002/info:id/1660029871756/Put/vlen=7/seqid=9 V: niit002 K: rk002/info:name/1660029857183/Put/vlen=6/seqid=8 V: parker Scanned kv count -> 4
查询数据操作
通过rowkey进行查询
- 获取user表中row key为rk0001的所有信息(即所有cell的数据)
- 使用get命令
hbase(main):012:0> put 'user', 'rk001', 'info:name', 'maggie'
Took 0.2883 seconds
hbase(main):013:0> get 'user', 'rk001'
COLUMN CELL
info:name timestamp=1660028521125, value=maggie
1 row(s)
Took 0.1084 seconds
hbase(main):014:0> put 'user', 'rk001', 'info:id', 'niit001'
Took 0.0385 seconds
hbase(main):015:0> get 'user', 'rk001'
COLUMN CELL
info:id timestamp=1660028654894, value=niit001
info:name timestamp=1660028521125, value=maggie
1 row(s)
Took 0.1474 seconds查看rowkey下某个列族的信息
- 获取user表中row key为rk0001,info列族的所有信息
hbase(main):016:0> get 'user', 'rk001', {COLUMN=>'info:id'}
COLUMN CELL
info:id timestamp=1660028654894, value=niit001
1 row(s)
Took 0.0695 seconds查看rowkey指定列族指定字段的值
- 获取user表中row key为rk0001,info列族的name、age列的信息
hbase(main):019:0> get 'user', 'rk001', 'info'
COLUMN CELL
info:id timestamp=1660028654894, value=niit001
info:name timestamp=1660028521125, value=maggie
1 row(s)
查看rowkey指定多个列族的信息
- 获取user表中row key为rk0001,info、data列族的信息
hbase(main):022:0> get 'user', 'rk001', 'info', 'data'
COLUMN CELL
data:pic timestamp=1660028892646, value=xlaksjdklasdlk
info:id timestamp=1660028654894, value=niit001
info:name timestamp=1660028521125, value=maggie
1 row(s)
Took 0.0658 seconds
指定rowkey与列值过滤器查询
- 获取user表中row key为rk0001,cell的值为leo的信息
hbase(main):035:0> get 'user', 'rk001', {FILTER => "ValueFilter(=, 'binary:leo')"}
COLUMN CELL
info:name timestamp=1660029085323, value=leo
1 row(s)
Took 0.0194 seconds指定rowkey与列名模糊查询
- 获取user表中row key为rk0001,列标示符中含有a的信息
hbase(main):036:0> get 'user', 'rk001', {FILTER => "QualifierFilter(=, 'substring:a')"}
COLUMN CELL
info:name timestamp=1660029085323, value=leo
1 row(s)
Took 0.5327 seconds
hbase(main):037:0> get 'user', 'rk001'
COLUMN CELL
data:pic timestamp=1660028892646, value=xlaksjdklasdlk
info:id timestamp=1660028654894, value=niit001
info:name timestamp=1660029085323, value=leo查询所有行的数据
- 查询user表中的所有信息
- 使用scan命令
hbase(main):038:0> scan 'user'
ROW COLUMN+CELL
rk001 column=data:pic, timestamp=1660028892646, value=xlaksjdklasdlk
rk001 column=info:id, timestamp=1660028654894, value=niit001
rk001 column=info:name, timestamp=1660029085323, value=leo
1 row(s)
Took 0.1011 seconds
列族查询
- 查询user表中列族为info的信息
hbase(main):046:0> scan 'user', {COLUMNS=>'info'}
ROW COLUMN+CELL
rk001 column=info:id, timestamp=1660028654894, value=niit001
rk001 column=info:name, timestamp=1660029085323, value=leo
rk002 column=info:id, timestamp=1660029871756, value=niit002
rk002 column=info:name, timestamp=1660029857183, value=parker
2 row(s)
Took 5.1544 secondsscan出来的数据时按照主键字典序顺序显示的
多列族查询
- 查询user表中列族为info和data的信息
hbase(main):001:0> scan 'user', {COLUMNS=>['info', 'data']}
ROW COLUMN+CELL
rk001 column=data:pic, timestamp=1660028892646, value=xlaksjdklasdlk
rk001 column=info:id, timestamp=1660028654894, value=niit001
rk001 column=info:name, timestamp=1660029085323, value=leo
rk002 column=data:pic, timestamp=1660029885641, value=9123908123948
rk002 column=info:id, timestamp=1660029871756, value=niit002
rk002 column=info:name, timestamp=1660029857183, value=parker
2 row(s)
Took 2.7535 seconds
hbase(main):002:0> scan 'user', {COLUMNS=>['info']}
ROW COLUMN+CELL
rk001 column=info:id, timestamp=1660028654894, value=niit001
rk001 column=info:name, timestamp=1660029085323, value=leo
rk002 column=info:id, timestamp=1660029871756, value=niit002
rk002 column=info:name, timestamp=1660029857183, value=parker
2 row(s)
Took 5.1640 seconds
hbase(main):003:0> scan 'user', {COLUMNS=>'info'}
ROW COLUMN+CELL
rk001 column=info:id, timestamp=1660028654894, value=niit001
rk001 column=info:name, timestamp=1660029085323, value=leo
rk002 column=info:id, timestamp=1660029871756, value=niit002
rk002 column=info:name, timestamp=1660029857183, value=parker
2 row(s)
Took 0.1246 seconds指定列族与某个列名查询
- 查询user表中列族为info、列标示符为name的信息
hbase(main):004:0> scan 'user', {COLUMNS=>'info:name'}
ROW COLUMN+CELL
rk001 column=info:name, timestamp=1660029085323, value=leo
rk002 column=info:name, timestamp=1660029857183, value=parker
2 row(s)- 查询info:name列、data:pic列的数据
hbase(main):005:0> scan 'user', {COLUMNS=>['info:id', 'data:pic']}
ROW COLUMN+CELL
rk001 column=data:pic, timestamp=1660028892646, value=xlaksjdklasdlk
rk001 column=info:id, timestamp=1660028654894, value=niit001
rk002 column=data:pic, timestamp=1660029885641, value=9123908123948
rk002 column=info:id, timestamp=1660029871756, value=niit002
2 row(s)
Took 5.2456 seconds- 查询user表中列族为info、列标示符为name的信息,并且版本最新的5个
hbase(main):008:0> scan 'user', {COLUMNS=>'info:name', VERSIONS=>5}
ROW COLUMN+CELL
rk001 column=info:name, timestamp=1660029085323, value=leo
rk002 column=info:name, timestamp=1660029857183, value=parker
2 row(s)指定多个列族与条件模糊查询
- 查询user表中列族为info和data且列标示符中含有a字符的信息
hbase(main):009:0> scan 'user', {COLUMNS => ['info', 'data'], FILTER => "QualifierFilter(=,'substring:a')"}
ROW COLUMN+CELL
rk001 column=info:name, timestamp=1660029085323, value=leo
rk002 column=info:name, timestamp=1660029857183, value=parker
2 row(s)
Took 5.1386 seconds
指定rowkey的范围查询
- 查询user表中列族为info,rk范围是[rk0001, rk0003)的数据
hbase(main):012:0> scan 'user', {COLUMNS => 'info', STARTROW => 'rk001', ENDROW=>'rk003'}
ROW COLUMN+CELL
rk001 column=info:id, timestamp=1660028654894, value=niit001
rk001 column=info:name, timestamp=1660029085323, value=leo
rk002 column=info:id, timestamp=1660029871756, value=niit002
rk002 column=info:name, timestamp=1660029857183, value=parker
2 row(s)指定rowkey前缀模糊查询
- 查询user表中row key以rk字符开头的数据
hbase(main):013:0> scan 'user', {FILTER=>"PrefixFilter('rk')"}
ROW COLUMN+CELL
rk001 column=data:pic, timestamp=1660028892646, value=xlaksjdklasdlk
rk001 column=info:id, timestamp=1660028654894, value=niit001
rk001 column=info:name, timestamp=1660029085323, value=leo
rk002 column=data:pic, timestamp=1660029885641, value=9123908123948
rk002 column=info:id, timestamp=1660029871756, value=niit002
rk002 column=info:name, timestamp=1660029857183, value=parker
2 row(s)指定数据版本的范围查询
- 查询user表中指定范围的数据(前闭后开)
scan 'user', {TIMERANGE => [1392368783980, 1610288780669]}
get 'user', 'rk003', {COLUMN=>'info', VERSIONS=>3}
COLUMN CELL
info:id timestamp=1660094717367, value=3
info:id timestamp=1660094715655, value=2
info:id timestamp=1660094713761, value=1
更新数据操作
更新数据值
- 更新操作同插入操作一模一样,只不过有数据就更新,没数据就添加
- 使用put命令
更新版本号
- 将user表的info列族版本数改为5
alter 'user', NAME => 'info', VERSIONS => 5
# 如果info列族已经存在, 则修改
# 如果不存在, 就增加删除数据以及删除表操作
指定rowkey以及列名进行删除
- 删除user表row key为rk001,列标示符为info:name的数据
delete 'user', 'rk001', 'info:name'指定rowkey,列名以及版本号进行删除
- 删除user表row key为rk0001,列标示符为info:name,timestamp为1392383705316的数据
hbase(main):022:0> get 'user', 'rk003', {COLUMN=>'info', VERSIONS=>3}
COLUMN CELL
info:id timestamp=1660094717367, value=3
info:id timestamp=1660094715655, value=2
info:id timestamp=1660094713761, value=1
1 row(s)
Took 0.2140 seconds
hbase(main):023:0> delete 'user', 'rk003', 'info:id', 1660094715655
Took 0.0946 seconds
hbase(main):024:0> get 'user', 'rk003', {COLUMN=>'info', VERSIONS=>3}
COLUMN CELL
info:id timestamp=1660094717367, value=3
info:id timestamp=1660094713761, value=1
1 row(s)
删除一个列族
- 删除一个列族:
alter 'user', NAME => 'data', METHOD => 'delete'
#或
alter 'user', 'delete' => 'info'
hbase(main):025:0> alter 'user', 'delete'=>'data'
Updating all regions with the new schema...
1/1 regions updated.
Done.
Took 10.7055 seconds
hbase(main):026:0> describe 'user'
Table user is ENABLED
user
COLUMN FAMILIES DESCRIPTION
{NAME => 'info', VERSIONS => '3', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS =>
'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATIO
N_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'fal
se', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
1 row(s)
QUOTAS
0 row(s)
清空表数据
MySQL: drop / truncate
HBase: truncate = disable -> drop -> create
hbase(main):030:0> truncate 'user'
Truncating 'user' table (it may take a while):
Disabling table...
Truncating table...
Took 3.0312 seconds
hbase(main):031:0> scan 'user'
ROW COLUMN+CELL
0 row(s)
Took 2.5825 seconds
删除表
-
首先需要先让该表为disable状态,使用命令:
-
然后使用drop命令删除这个表
hbase(main):032:0> disable 'user'
Took 0.9053 seconds
hbase(main):033:0> is_enabled 'user'
false
Took 5.1499 seconds
=> false
hbase(main):034:0> drop 'user'
Took 0.4707 seconds
hbase(main):035:0> list
TABLE
customer
ns1:customer
ns1:t1
3 row(s)
Took 0.1252 seconds
=> ["customer", "ns1:customer", "ns1:t1"]
- 统计一张表有多少行数据
hbase(main):043:0> count 'customer'
3 row(s)
Took 0.1561 seconds
=> 3
HBase的高级shell管理命令
status
- 显示服务器状态
hbase> status
hbase> status 'simple'
hbase> status 'summary'
hbase> status 'detailed'
hbase> status 'replication'
hbase> status 'replication', 'source'
hbase> status 'replication', 'sink'
whoami
- 显示HBase当前用户
niitlist
- 显示当前所有的表 (hbase空间的表是隐藏的)
listdescribe
- 展示表结构信息
describe 'user'exists
- 检查表是否存在,适用于表量特别多的情况
exists 'user'is_enabled、is_disabled
- 检查表是否启用或禁用,返回true或者false
is_enabled 'user'
is_disabled 'user'alter
-
该命令可以改变表和列族的模式,例如:
-
为当前表增加列族:(假设原来没有extra列族)
alter 'user', NAME => 'extra', VERSIONS => 2- 为当前表删除列族:
alter 'user', 'delete' => 'extra'disable/enable
- 禁用一张表/启用一张表
disable 'user'
enable 'user'drop
- 删除一张表,记得在删除表之前必须先禁用
drop 'user'truncate
- 截断表 = 禁用表-删除表-创建表
truncate 'user'HBase的JavaAPI操作
- HBase是一个分布式的NoSql数据库,在实际工作当中,我们一般都可以通过JavaAPI来进行各种数据的操作,包括创建表,以及数据的增删查等等
创建maven工程
- 将如下内容作为maven工程中
pom.xml的repositories的内容 - 自动导包
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>XZK</artifactId>
<groupId>org.example</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>HbaseApi1</artifactId>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>3.1.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.2.6</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.2.6</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.14.3</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.14.3</version>
<scope>compile</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*/RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>创建测试类
package com.niit.demo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.log4j.BasicConfigurator;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
public class ExampleTest {
private Connection connection;
private final String TABLE_NAME = "myuser";
private Table table;
@Before
public void initTable() throws IOException {
BasicConfigurator.configure(); // log4j
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "niit-master:2181");
connection = ConnectionFactory.createConnection(configuration);
table = connection.getTable(TableName.valueOf(TABLE_NAME));
}
@After
public void close() throws IOException {
table.close();
connection.close();
}
}创建表
@Test
public void createTable() throws IOException {
//获取连接对象,创建一张表
//获取管理员对象,来对数据库进行ddl操作
Admin admin = connection.getAdmin();
//指定表名
TableName myuser = TableName.valueOf("myuser");
HTableDescriptor hTableDescriptor = new HTableDescriptor(myuser);
//指定两个列族
HColumnDescriptor f1 = new HColumnDescriptor("f1");
HColumnDescriptor f2 = new HColumnDescriptor("f2");
hTableDescriptor.addFamily(f1);
hTableDescriptor.addFamily(f2);
admin.createTable(hTableDescriptor);
}
添加数据
@Test
public void addData() throws IOException {
//获取表 rowkey 0001 f1:name delucia
// f1:age 18
Put put = new Put("0001".getBytes());//创建put对象,并指定rowkey值
put.addColumn("f1".getBytes(), "name".getBytes(), "delucia".getBytes());
put.addColumn("f1".getBytes(), "age".getBytes(), Bytes.toBytes(18));
put.addColumn("f1".getBytes(), "id".getBytes(), Bytes.toBytes("niit01"));
put.addColumn("f1".getBytes(), "address".getBytes(), Bytes.toBytes("HNU"));
// Bytes.toBytes()源码,可见仍然是调用了getBytes(),但是将转换完成的结果编码设为UTF-8
// 而getBytes将会使用默认编码
table.put(put);
// check:
// hbase shell
// scan 'myuser', {FORMATTER=>'toString'}
}批量插入数据
@Test
public void batchInsert() throws IOException {
ArrayList<Put> puts = new ArrayList<>();
for (int i=1000; i <= 2000; i++ ) {
Put p = new Put((i + "").getBytes());
p.addColumn("f1".getBytes(), "id".getBytes(),Bytes.toBytes(i));
p.addColumn("f1".getBytes(), "name".getBytes(),Bytes.toBytes("user"+i));
p.addColumn("f1".getBytes(), "age".getBytes(),Bytes.toBytes(rand.nextInt(18)+10));
p.addColumn("f1".getBytes(), "address".getBytes(),Bytes.toBytes("HAI NAN"));
puts.add(p);
}
table.put(puts);
}查询数据
@Test
public void getData() throws IOException {
//通过get对象,指定 rowkey
Get get = new Get(Bytes.toBytes("0001"));
//只查询f1列族下面所有的列的值
get.addFamily("f1".getBytes());
//查询f2列族phone的字段
get.addColumn("f2".getBytes(), "address".getBytes());
//通过get查询,返回一个result对象,所有的字段的数据都分装在result里面
Result result = table.get(get);
//获取一条数据所有的cell,所有数据值都在cell里面
List<Cell> cells = result.listCells();
if (cells != null) {
for (Cell cell : cells) {
// 获取列族名
byte[] familyName = CellUtil.cloneFamily(cell);
// 获取列名
byte[] columnName = CellUtil.cloneQualifier(cell);
// 获取rowKey
byte[] rowKey = CellUtil.cloneRow(cell);
// 获取cell值
byte[] cellValue = CellUtil.cloneValue(cell);
// 需要判断字段的数据类型,使用对应的转换的方法,才能够获取到值
if ("age".equals(Bytes.toString(columnName)) || "id".equals(Bytes.toString(columnName))) {
System.out.println(Bytes.toString(familyName));
System.out.println(Bytes.toString(columnName));
System.out.println(Bytes.toString(rowKey));
System.out.println(Bytes.toInt(cellValue));
} else {
System.out.println(Bytes.toString(familyName));
System.out.println(Bytes.toString(columnName));
System.out.println(Bytes.toString(rowKey));
System.out.println(Bytes.toString(cellValue));
}
}
}
}扫描数据
@Test
public void scanTable() throws Exception {
// 获取table
// Table table = connection.getTable(TableName.valueOf(TABLE_NAME));
Scan scan = new Scan();// 没有指定startRow以及stopRow 全表扫描
// 只扫描f1列族
scan.addFamily("f1".getBytes());
scan.withStartRow("1200".getBytes());
scan.withStopRow("1203".getBytes()); // 前闭后开
// 通过getScanner查询获取到了表里面所有的数据,是多条数据
scan.setMaxResultSize(100);
ResultScanner results = table.getScanner(scan);
// 遍历ResultScanner 得到每一条数据,每一条数据都是封装在result对象里面了
for (Result result : results) {
List<Cell> cells = result.listCells();
for (Cell cell : cells) {
byte[] family_name = CellUtil.cloneFamily(cell);
byte[] qualifier_name = CellUtil.cloneQualifier(cell);
byte[] rowkey = CellUtil.cloneRow(cell);
byte[] value = CellUtil.cloneValue(cell);
//判断id和age字段,这两个字段是整形值
System.out.print("\n" +Bytes.toString(family_name));
System.out.print(":"+ Bytes.toString(qualifier_name));
System.out.print(" RK:"+ Bytes.toString(rowkey));
System.out.print("=" + Bytes.toString(value));
}
System.out.println();
}
}扫描并过滤数据
// 设置过滤器
// scan.setFilter(..)程序运行时报错, 显示16020端口连接不上, 解决方案:
检查/etc/hosts里面配置是否正确.
[niit@niit-master ~]$ cat /etc/hosts #127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 #::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.56.104 niit-master
HBase 伪分布式环境安装
和完全分布式的区别就是, 伪分布式的所有服务都安装在一个节点上.
推荐初学时使用伪分布式, 搭建更为简单, 且在使用时和完全分布式差别不大.
安装JDK8
安装Hadoop 版本兼容性看这里
建议安装自己的zookeeper集群(不建议使用HBase内置的Zookeeper)
$ mv zoo-sample.cfg zoo.cfg
$vim zoo.cfg修改dataDir为/tmp/..之外的路径
tickTime=2000
initLimit=10
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/niit/zookeeper/data
# the port at which the clients will connect
clientPort=2181https://hbase.apache.org/2.0/book.html#quickstart_fully_distributed
hbase-site.xml
- 修改文件
[hadoop@hadoop100 conf]$ vim hbase-site.xml- 内容如下(注意将niit-master替换成实际使用的主机名)
<configuration>
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://niit-master:9000/hbase</value>
</property>
<!-- 指定hbase是否分布式运行 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zookeeper的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>niit-master:2181</value>
</property>
<!--指定hbase管理页面 默认是16010-->
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<!-- 在分布式的情况下一定要设置,不然容易出现Hmaster起不来的情况 -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>添加HBase环境变量
- 注意:三台机器均执行以下命令,添加环境变量
sudo vim /etc/profile- 文件末尾添加如下内容
export HBASE_HOME=/opt/pkg/hbase-2.2.6
export PATH=$PATH:$HBASE_HOME/bin- 重新编译/etc/profile,让环境变量生效
source /etc/profileHBase的启动与停止
服务启动顺序:
-
启动zk
如果没开启zookeeper,请在3个节点分别运行
zkServer.sh start命令 -
启动hdfs 和yarn
如果没开启hdfs,请运行
start-dfs.sh命令如果需要执行MapReduce, 请运行
start-yarn.sh命令 -
启动hbase
start-hbase.sh -
启动完后,jps查看HBase相关进程, 确保出现:
-
HMaster
-
HRegionServer
-
访问WEB页面
-
浏览器页面访问
停止HBase集群
-
停止HBase集群的正确顺序
- hadoop100上运行,关闭hbase集群
$ stop-hbase.sh- 关闭ZooKeeper集群
- 关闭Hadoop集群
- 关闭虚拟机
- 关闭笔记本
不要再集群运行的时候直接关闭虚拟机电源, 容易出现问题
HBase表的rowkey设计
- rowkey设计三原则
rowkey长度原则
-
rowkey是一个二进制码流,可以是任意字符串,最大长度64kb,实际应用中一般为10-100bytes,以byte[]形式保存,一般设计成定长。
-
建议尽可能短;但是也不能太短,否则rowkey前缀重复的概率增大
-
设计过长会降低memstore内存的利用率和HFile存储数据的效率。
rowkey散列原则
-
建议将rowkey的高位作为散列字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。
-
如果没有散列字段,首字段直接是时间信息。所有的数据都会集中在一个RegionServer上,这样在数据检索的时候负载会集中在个别的RegionServer上,造成热点问题,会降低查询效率。
-
加盐: 添加随机值
-
hash: 比如采用MD5散列算法取前4位字符作为前缀
-
反转: 将手机号反转(避免热点问题)
-
MAX_LONG – timestamp: 更快检索到最新的数据.
rowkey log:data MAX_LONG-tsn xxxxxx (最新的记录) MAX_LONG-ts2 xxxxxx MAX_LONG-ts1 xxxxxx … -
rowkey唯一原则
- 必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的
- 因此,设计rowkey的时候,要充分利用这个排序的特点,可以将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块.
HBase表的热点
什么是热点
- 检索habse的记录首先要通过row key来定位数据行。
- 当大量的client访问hbase集群的一个或少数几个节点,造成少数region server的读/写请求过多、负载过大,而其他region server负载却很小,就造成了“热点”现象。
热点的解决方案
预分区 Pre-Splitting
- 预分区的目的让表的数据可以均衡的分散在集群中,而不是默认只有一个region分布在集群的一个节点上。(可以避免频繁的Region分裂)
合理的rowkey设计
-
加盐: 这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同
-
哈希: 使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据。
如:
rowkey=MD5(username).subString(0,10)+时间戳 -
反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。
- 这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。
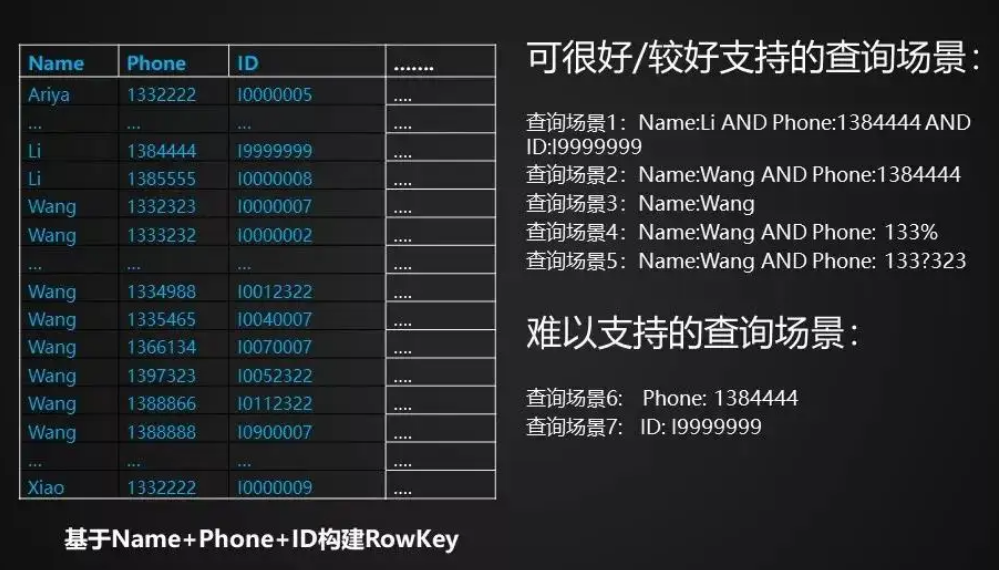
RowKey设计案例
案例一
以电信公司为例:
如果使用手机号作为用户电信信息的rowkey, 则
在中国使用的数字是11位,每段有不同的编码方向:前三位——网络识别号;第4-7位-语言环境编码;第8-11位-用户编号。
目前移动号段为1340-1349 .135.136.137.138.139.159.158.150.151.152.188.147 188号段最受欢迎.
如果使用手机号作为rowkey的前缀,势必造成部分区域出现热点问题。
解决办法:将手机号反转后在作为rowkey的前缀。
比如1397654321 变为1234567931, 这样rowkey前缀的随机性更强, 更能起到负载均衡的作用。
案例二
| rowkey | name | age | gender | address |
|---|---|---|---|---|
| ??? | delucia | 18 | m | Harbin |
| ??? | clark | 17 | m | Qing dao |
| ??? | parker | 16 | m | Haikou |
| ??? | maggie | 17 | f | Haikou |
| ??? | leo | 15 | m | Haikou |
| ??? | jason | 17 | m | Gui yang |
| ??? | tony | 18 | m | Haikou |
需求:假设这张表数据量非常大, 后期想按居住地和年龄进行用户信息的查询,user表的主键该如何设计?
rowkey= address+age+随机数
这样虽然方便了查询, 但是牺牲了主键前缀的随机性, 可能会出现一定程度的热点问题
案例三
以下是滴滴常见的HBase表行键设计:
-
订单状态表
- Rowkey: reverse(order_id) + (MAX_LONG – timestamp)
- Columns: 该订单各种状态
-
历史订单表
- Rowkey: reversed(passenger_id | driver_id) + (MAX_LONG – timestamp)
- Columns: 用户在时间范围内的所有订单
-
司机乘客轨迹(通过ID查询轨迹)
- Rowkey: ID+Timestamp
- Column: 轨迹详细信息
- 提供java API给用户使用
-
通过地理范围查找全部出现的轨迹 需要建立空间索引表
- GeoHash分区
- Rowkey: Reversed_geohash + Timestamp + ID 提供3种方式访问
- 小范围或短时间数据:API一次性查询, 延时小,成本低
- 中等范围或中等时间数据: 提供scanner批量查询结果,延时较高,成本低
- 大范围或者长时间数据:提供离线查询,延时高,成本高
HBase的协处理器
- coprocessor - 类似MySQL上的触发器
协处理器简介
Hbase 作为列族数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执 行求和、计数、排序等操作。比如,在旧版本的(<0.92)Hbase 中,统计数据表的总行数,需要使用 Counter 方法,执行一次 MapReduce Job 才能得到。虽然 HBase 在数据存储层中集成 了 MapReduce,能够有效用于数据表的分布式计算。然而在很多情况下,做一些简单的相 加或者聚合计算的时候,如果直接将计算过程放置在 server 端,能够减少通讯开销,从而获 得很好的性能提升。于是,HBase 在 0.92 之后引入了协处理器(coprocessors),实现一些激动 人心的新特性:能够轻易维护二次索引、复杂过滤器(谓词下推)以及访问控制等。
协处理器的类型
协处理器有两种:observer 和 endpoint
Observer
- Observer 类似于传统数据库中的触发器,当发生某些事件的时候这类协处理器会被 Server 端调用。Observer Coprocessor 就是一些散布在 HBase Server 端代码中的 hook 钩子, 在固定的事件发生时被调用。比如:put 操作之前有钩子函数 prePut,该函数在 put 操作执 行前会被 Region Server 调用;在 put 操作之后则有 postPut 钩子函数
HBase0.92 版本为例,它提供了三种观察者接口:
- RegionObserver:提供客户端的数据操纵事件钩子:Get、Put、Delete、Scan 等。
- WALObserver:提供 WAL 相关操作钩子。
- MasterObserver:提供 DDL-类型的操作钩子。如创建、删除、修改数据表等。
到 0.96 版本又新增一个 RegionServerObserver
下图是以 RegionObserver 为例子讲解 Observer 这种协处理器的原理:
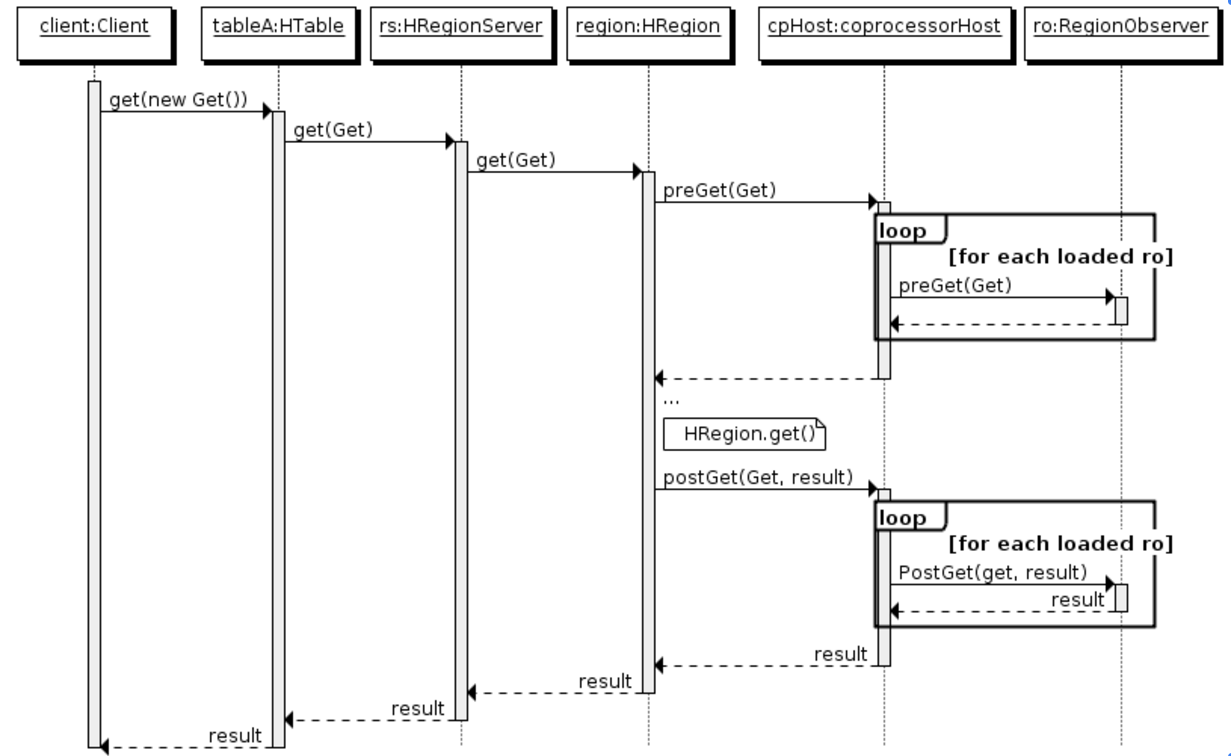
1、客户端发出 get 请求
2、该请求被分派给合适的 RegionServer 和 region
3、coprocessorHost 拦截该请求,然后在该表上登记的每个 RegionObserver 上调用 preGet()
4、如果没有被 preGet()拦截,该请求继续送到 region,然后进行处理
5、region 产生的结果再次被 CoprocessorHost 拦截,调用 postGet()
6、假如没有 postGet()拦截该响应,最终结果被返回给客户端
Endpoint
Endpoint 协处理器类似传统数据库中的存储过程,客户端可以调用这些 Endpoint 协处 理器执行一段 Server 端代码,并将 Server 端代码的结果返回给客户端进一步处理,最常见 的用法就是进行聚合操作。如果没有协处理器,当用户需要找出一张表中的最大数据,即 max 聚合操作,就必须进行全表扫描,在客户端代码内遍历扫描结果,并执行求最大值的 操作。这样的方法无法利用底层集群的并发能力,而将所有计算都集中到 Client 端统一执行, 势必效率低下。利用 Coprocessor,用户可以将求最大值的代码部署到 HBase Server 端,HBase 将利用底层 cluster 的多个节点并发执行求最大值的操作。即在每个 Region 范围内执行求最大值的代码,将每个 Region 的最大值在 Region Server 端计算出,仅仅将该 max 值返回给客 户端。在客户端进一步将多个 Region 的最大值进一步处理而找到其中的最大值。这样整体 的执行效率就会提高很多.
下图是 EndPoint 的工作原理:
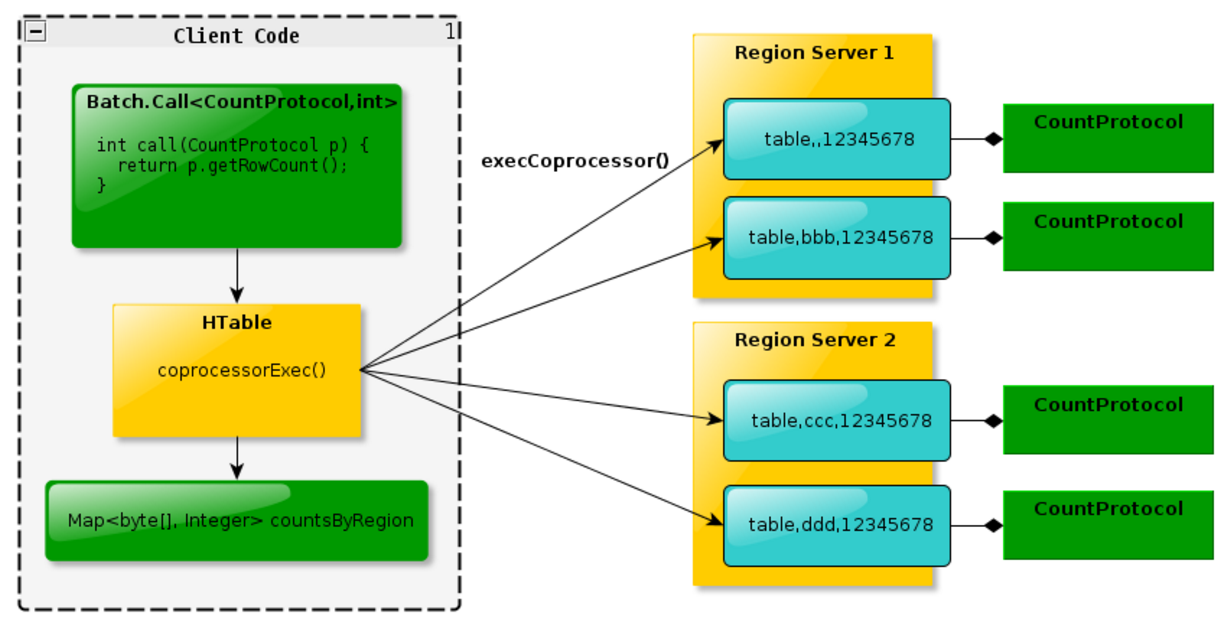
总结:
- Observer 允许集群在正常的客户端操作过程中可以有不同的行为表现
- Endpoint 允许扩展集群的能力,对客户端应用开放新的运算命令
- Observer 类似于 RDBMS 中的触发器,主要在服务端工作
- Endpoint 类似于 RDBMS 中的存储过程,主要在服务端工作
- Observer 可以实现权限管理、优先级设置、监控、ddl 控制、二级索引等功能
- Endpoint 可以实现 min、max、avg、sum、distinct、group by 等功能
协处理加载方式
协处理器的加载方式有两种,我们称之为静态加载方式(Static Load)和动态加载方式 (Dynamic Load)。静态加载的协处理器称之为 System Coprocessor,动态加载的协处理器称 之为 Table Coprocessor。
静态加载
通过修改 hbase-site.xml 这个文件来实现,启动全局聚合协处理器,能过操纵所有的表上 的数据。只需要添加如下代码:
<property>
<name>hbase.coprocessor.user.region.classes</name>
<value>org.apache.hadoop.hbase.coprocessor.AggregateImplementation</value>
</property>hbase自带了一个聚合coprocessor类:
org.apache.hadoop.hbase.coprocessor.AggregateImplementation
使用该类可以count一张表的总记录数。
为所有 table 加载了一个coprocessor类,如果需要加载多个class可以用”,”分割
动态加载
启用表级协处理器,只对特定的表生效。通过 HBase Shell 来实现。
- 停用表
disable 'guanzhu' - 添加协处理器
alter 'guanzhu', METHOD => 'table_att', 'coprocessor' => 'hdfs://myha01/hbase/guanzhu.jar|com.study.hbase.cp.HbaseCoprocessorTest|1001|' - 启用表
enable 'guanzhu'
1001为优先级, 优先级也可以省略, 这样会得到一个系统的默认优先级
协处理器卸载
同样是3步
disable 'mytable'alter 'mytable',METHOD=>'table_att_unset',NAME=>'coprocessor$1'enable 'mytable'
案例(二级索引)
创建RegionObserver类型的协处理器,作用是:
监控User_Interest_Log表的"user:username"列
每当有put操作,同时维护二级索引表User_Interest_Log_Ind表
创建maven项目
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.niit.secondaryindexonhbase</groupId>
<artifactId>SecondaryIndexOnHBase</artifactId>
<version>1.0-SNAPSHOT</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.2.4</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.2.4</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>2.2.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.3</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.3.2</version>
</dependency>
</dependencies>
</project>编写协处理器类
package com.niit.coprocessor;
import java.io.IOException;
import java.util.List;
import java.util.Optional;
import org.apache.commons.codec.digest.DigestUtils;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Durability;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessor;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.coprocessor.RegionObserver;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.wal.WALEdit;
public class CoprocessorCreate implements RegionObserver, RegionCoprocessor {
private static final Log LOG = LogFactory.getLog(CoprocessorCreate.class);
private Connection connection = null;
private Table table = null;
private static final String First_Table_Name = "User_Interest_Log";
private static final String Second_Table_Name = "User_Interest_Log_Index";
private static final String First_FAMILY_NAME = "user";
private static final String First_COLUMN_NAME = "username";
private static final String Second_FAMILY_NAME = "idx";
private static final String Second_COLUMN_NAME = "username";
// Start from HBase2.0,this method must be added or it will not take effect
@Override
public Optional<RegionObserver> getRegionObserver() {
// It is important to ensure that the coprocessor is called as a regionobserver
return Optional.of(this);
}
@Override
public void start(CoprocessorEnvironment env) throws IOException {
try {
connection = ConnectionFactory.createConnection(env.getConfiguration());
table = connection.getTable(TableName.valueOf(Second_Table_Name));
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void stop(CoprocessorEnvironment e) throws IOException {
// nothing to do here
table.close();
}
/**
* 只有在向User_Interest_Log表插入数据后, 才需要维护二级索引表User_Interest_Log_Index
*/
@Override
public void postPut(ObserverContext<RegionCoprocessorEnvironment> env,
Put put,
WALEdit edit,
Durability durability)
throws IOException {
try {
// If the coprocessor is not loaded on the specified table, it is returned
// directly
byte[] tablename = env.getEnvironment().getRegion().getRegionInfo().getTable().getName();
if (!Bytes.equals(tablename, First_Table_Name.getBytes())) {
return;
}
// If the value of a specific column is not added to the current row, it is
// returned directly
byte[] firstFamilyName = Bytes.toBytes(First_FAMILY_NAME);
byte[] firstColName = Bytes.toBytes(First_COLUMN_NAME);
byte[] secondFamilyName = Bytes.toBytes(Second_FAMILY_NAME);
byte[] secondColumnName = Bytes.toBytes(Second_COLUMN_NAME);
if (!put.has(firstFamilyName, firstColName)) {
return;
}
// Gets the column in the specified column family
List<Cell> list = put.get(firstFamilyName, firstColName);
if (list == null || list.size() == 0) {
return;
}
// Get cell in column 1
Cell cell2 = list.get(0);
// 获Gets the rowkey of the currently inserted column
String rowkey = CellUtil.getCellKeyAsString(cell2);
rowkey = rowkey.substring(0, rowkey.indexOf('/'));
// Get inserted user id
String userid = Bytes.toString(CellUtil.cloneValue(cell2));
// To prevent rowkey aggregation, use its md5 value
// MD5散列- 解决热点问题
Put put2 = new Put(Bytes.toBytes(DigestUtils.md5Hex(userid)));
put2.addColumn(secondFamilyName, secondColumnName, Bytes.toBytes(rowkey));
table.put(put2);
} catch (Exception e1) {
LOG.error("Error MEssage" + e1.getMessage());
return;
}
}
}将maven项目打包上传到HDFS上,如: hdfs://niit-master:9000/user/niit/jars/SecondaryIndexOnHBase.jar
为现有表User_Interest_Log添加协处理器:
disable 'User_Interest_Log'
alter 'User_Interest_Log' , METHOD =>'table_att','coprocessor'=>'hdfs://niitmaster:9000/user/niit/jars/SecondaryIndexOnHBase.jar|com.niit.coprocessor.CoprocessorCreate|1001'
enable 'User_Interest_Log'验证和测试
> describe "User_Interest_Log"
Table User_Interest_Log is ENABLED
User_Interest_Log, {TABLE_ATTRIBUTES => {coprocessor$1 => 'hdfs://niit-master:9000/user/niit/jars/SecondaryIndexOnHBase.jar|com.niit.coprocessor.CoprocessorCreate|1001'}}
COLUMN FAMILIES DESCRIPTION
> put 'User_Interest_Log','EMP0012','user:username','lisi'
Took 0.6849 seconds
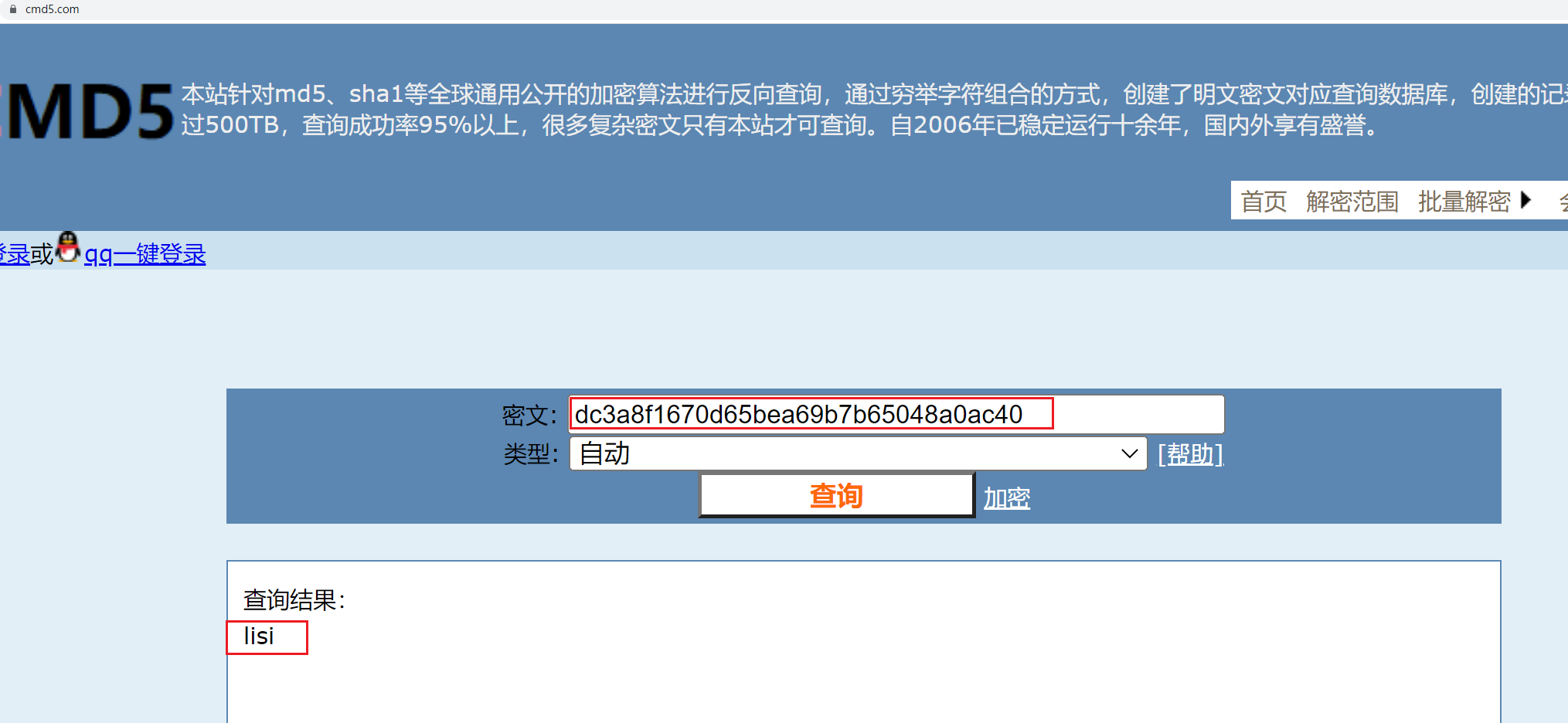
> scan 'User_Interest_Log_Index'
ROW COLUMN+CELL
dc3a8f1670d65bea69b7b65048a0ac40 column=idx:username, timestamp=1659894545067, value=EMP0012有了二级索引表之后, 我们可以通过用户名倒查出哪些主键上保存了这些信息, 能够极大缩小查找的范围.
另外二级索引表主键是用户名经过MD5散列的结果, 这样的好处是可以避免热点问题.
现在将二级索引表的主键解码看看:
HBase集成MapReduce
- HBase表中的数据最终都是存储在HDFS上,HBase天生的支持MR的操作,我们可以通过MR直接处理HBase表中的数据,并且MR可以将处理后的结果直接存储到HBase表中。
实战一
-
需求:读取HBase当中
myuser这张表的f1:name、f1:age数据,将数据写入到另外一张myuser2表的f1列族里面去 -
第一步:创建myuser2这张hbase表
注意:列族的名字要与myuser表的列族名字相同
create 'myuser', 'f1', 'f2'
create 'myuser2', {NAME=>'f1', VERSION=>3}
put 'myuser', '0001', 'f1:name', 'user001', 18
put 'myuser', '0001', 'f1:age', 'user001', 18
put 'myuser', '0001', 'f1:id', 'user001', 18
put 'myuser', '0002', 'f1:name', 'user002', 19
put 'myuser', '0002', 'f1:age', 'user002', 19
put 'myuser', '0002', 'f1:id', 'user002', 19
put 'myuser', '0003', 'f1:name', 'user003', 28
put 'myuser', '0003', 'f1:age', 'user003', 28
put 'myuser', '0003', 'f1:id', 'user003', 28
put 'myuser', '0003', 'f2:data', 'user003', 28- 第二步:创建maven工程并导入jar包
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>3.1.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.14.3</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*/RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>- 第三步:开发MR程序实现功能
- 自定义map类
package com.niit.hbase.mr;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import java.io.IOException;
public class HBaseReadMapper extends TableMapper<Text, Put> {
/**
* @param key rowKey
* @param value rowKey此行的数据 Result类型
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
// 获得rowKey的字节数组
byte[] rowKeyBytes = key.get();
String rowKeyStr = Bytes.toString(rowKeyBytes);
Text text = new Text(rowKeyStr);
// 输出数据 -> 写数据 -> Put 构建Put对象
Put put = new Put(rowKeyBytes);
// 获取一行中所有的Cell对象
Cell[] cells = value.rawCells();
// 将f1 : name& age输出
for (Cell cell : cells) {
//当前cell是否是f1
//列族
byte[] familyBytes = CellUtil.cloneFamily(cell);
String familyStr = Bytes.toString(familyBytes);
if ("f1".equals(familyStr)) {
// 再判断是否是name | age
byte[] qualifier_bytes = CellUtil.cloneQualifier(cell);
String qualifierStr = Bytes.toString(qualifier_bytes);
if ("name".equals(qualifierStr)) {
put.add(cell);
}
if ("age".equals(qualifierStr)) {
put.add(cell);
}
}
}
// 判断是否为空;不为空,才输出
if (!put.isEmpty()) {
context.write(text, put);
}
}
}- 自定义reducer类
package com.niit.hbase.mr;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.Text;
import java.io.IOException;
/**
* TableReducer第三个泛型包含rowkey信息
*/
public class HBaseWriteReducer extends TableReducer<Text, Put, ImmutableBytesWritable> {
//将map传输过来的数据,写入到hbase表
@Override
protected void reduce(Text key, Iterable<Put> values, Context context) throws IOException, InterruptedException {
//rowkey
ImmutableBytesWritable immutableBytesWritable = new ImmutableBytesWritable();
immutableBytesWritable.set(key.toString().getBytes());
//遍历put对象,并输出
for(Put put: values) {
context.write(immutableBytesWritable, put);
}
}
}- main入口类
package com.niit.hbase.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class Main extends Configured implements Tool {
public static void main(String[] args) throws Exception {
Configuration configuration = HBaseConfiguration.create();
// 设定绑定的zk集群
configuration.set("hbase.zookeeper.quorum", "niit-master:2181");
int run = ToolRunner.run(configuration, new Main(), args);
System.exit(run);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(super.getConf());
job.setJarByClass(Main.class);
// mapper
TableMapReduceUtil.initTableMapperJob(TableName.valueOf("myuser"), new Scan(), HBaseReadMapper.class, Text.class, Put.class, job);
// reducer
TableMapReduceUtil.initTableReducerJob("myuser2", HBaseWriteReducer.class, job);
boolean b = job.waitForCompletion(true);
return b ? 0 : 1;
}
}实战二
需求
- 通过bulkload的方式批量加载数据到HBase表中
- 将我们hdfs上面的这个路径
/hbase/input/user.txt的数据文件,转换成HFile格式,然后load到myuser2这张表里面去
知识点描述
- 加载数据到HBase当中去的方式多种多样,我们可以使用HBase的javaAPI或者使用sqoop将我们的数据写入或者导入到HBase当中去,但是这些方式不是最佳的,因为在导入的过程中占用Region资源导致效率低下
- 我们也可以通过MR的程序,将我们的数据直接转换成HBase的最终存储格式HFile,然后直接load数据到HBase当中去即可
HBase数据正常写流程回顾

通过MapReduce程序生产了HFile文件,但是并没有导入HBase中。这时需要通过completebulkload工具,将生产的HFile文件导入已经运行的HBase中,从而客户可以通过HBase获取到相关数据。
大体上分为两个阶段:
-
扫描出HDFS上的待导入的HFile。
-
针对每个HFile,加载到制定的HBase Region对应的数据目录中。
bulkload方式的处理示意图
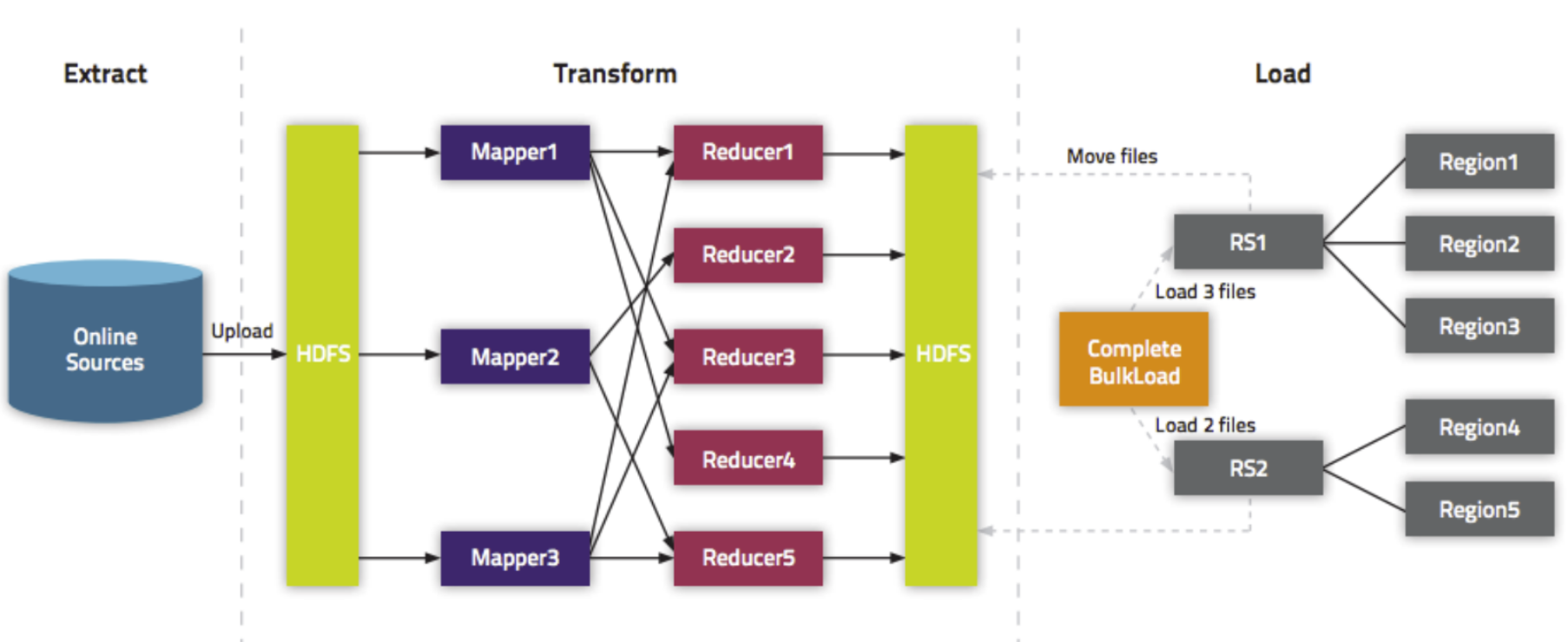
好处
- 导入过程不占用Region资源
- 能快速导入海量的数据
- 节省内存
开发生成HFile文件的代码, 自定义mapper类BulkLoadMapper.java
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
// 四个泛型中后两个,分别对应rowkey及put
public class BulkLoadMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
// 封装输出的rowkey类型
ImmutableBytesWritable immutableBytesWritable = new ImmutableBytesWritable(split[0].getBytes());
// 构建put对象
Put put = new Put(split[0].getBytes());
put.addColumn("f1".getBytes(), "name".getBytes(), split[1].getBytes());
put.addColumn("f1".getBytes(), "age".getBytes(), split[2].getBytes());
context.write(immutableBytesWritable, put);
}
}主程序:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class HBaseBulkLoad extends Configured implements Tool {
public static void main(String[] args) throws Exception {
Configuration configuration = HBaseConfiguration.create();
//设定zk集群
configuration.set("hbase.zookeeper.quorum", "niit-master:2181");
int run = ToolRunner.run(configuration, new HBaseBulkLoad(), args);
System.exit(run);
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = super.getConf();
Job job = Job.getInstance(conf);
job.setJarByClass(HBaseBulkLoad.class);
FileInputFormat.addInputPath(job, new Path("hdfs://niit-master:9000/hbase/input"));
job.setMapperClass(BulkLoadMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
Connection connection = ConnectionFactory.createConnection(conf);
Table table = connection.getTable(TableName.valueOf("myuser2"));
//使MR可以向myuser2表中,增量增加数据
HFileOutputFormat2.configureIncrementalLoad(job, table, connection.getRegionLocator(TableName.valueOf("myuser2")));
//数据写回到HDFS,写成HFile -> 所以指定输出格式为HFileOutputFormat2
job.setOutputFormatClass(HFileOutputFormat2.class);
HFileOutputFormat2.setOutputPath(job, new Path("hdfs://niit-master:9000/hbase/out_hfile"));
//开始执行
boolean b = job.waitForCompletion(true);
return b? 0: 1;
}
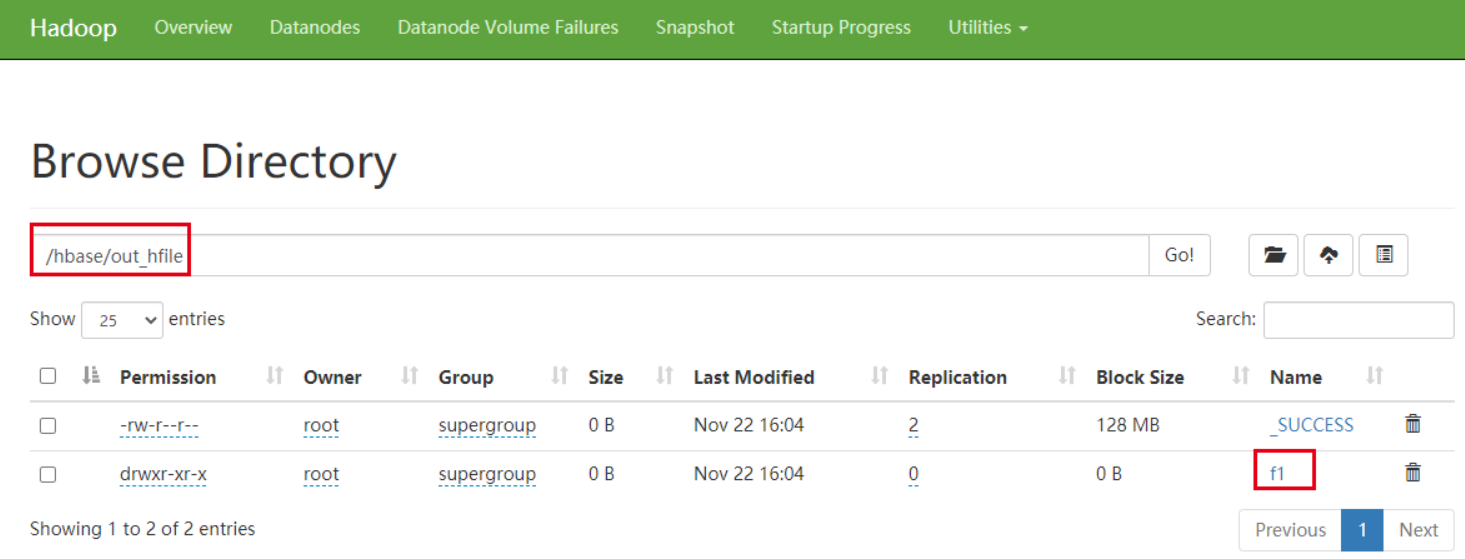
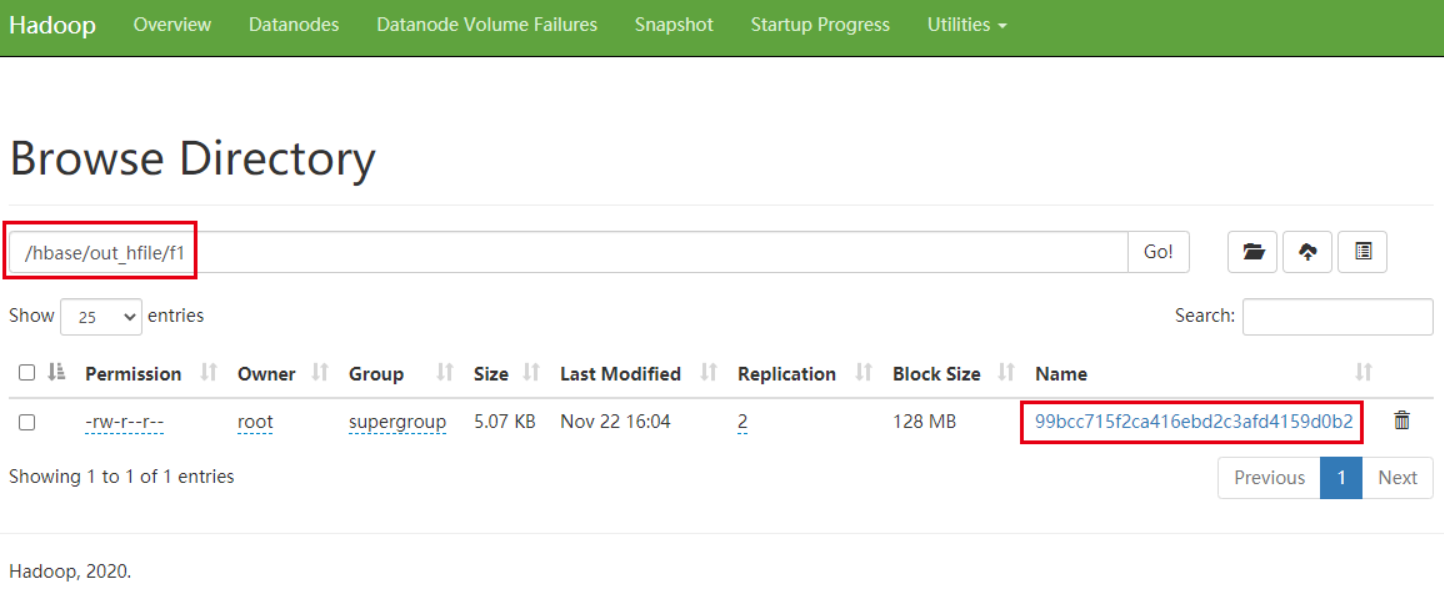
}观察HDFS上输出的结果
加载HFile文件到hbase表中
方式一:代码加载
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.tool.BulkLoadHFiles;
public class LoadData {
public static void main(String[] args) throws Exception {
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "niit-master");
// 获取数据库连接
Connection connection = ConnectionFactory.createConnection(configuration);
// 获取表的管理器对象
Admin admin = connection.getAdmin();
// 获取table对象
TableName tableName = TableName.valueOf("myuser2");
Table table = connection.getTable(tableName);
// 构建BulkLoadHFiles加载HFile文件 hbase2.0 api
BulkLoadHFiles load = BulkLoadHFiles.create(configuration);
load.bulkLoad(tableName, new Path("hdfs://niit-master:9000/hbase/out_hfile"));
}
}方式二: 使用官方提供了专门的工具用于加载HFile到运行的集群中
Completing the data load
After a data import has been prepared, either by using the importtsv tool with the “importtsv.bulk.output” option or by some other MapReduce job using the HFileOutputFormat, the completebulkload tool is used to import the data into the running cluster. This command line tool iterates through the prepared data files, and for each one determines the region the file belongs to. It then contacts the appropriate RegionServer which adopts the HFile, moving it into its storage directory and making the data available to clients.
If the region boundaries have changed during the course of bulk load preparation, or between the preparation and completion steps, the completebulkload utility will automatically split the data files into pieces corresponding to the new boundaries. This process is not optimally efficient, so users should take care to minimize the delay between preparing a bulk load and importing it into the cluster, especially if other clients are simultaneously loading data through other means.
$ hadoop jar hbase-mapreduce-VERSION.jar completebulkload [-c /path/to/hbase/config/hbase-site.xml] /user/todd/myoutput mytableThe -c config-file option can be used to specify a file containing the appropriate hbase parameters (e.g., hbase-site.xml) if not supplied already on the CLASSPATH (In addition, the CLASSPATH must contain the directory that has the zookeeper configuration file if zookeeper is NOT managed by HBase).
HBase完全分布式环境安装
在单机伪分布式的安装基础上做如下修改, 即为完全分布式:
首先准备好完全分布式的Hadoop和zookeeper集群.
假设是三个节点分别为hadoop100, hadoop101和hadoop102
vim /etc/hosts
192.168.186.100 hadoop100
192.168.186.101 hadoop101
192.168.186.102 hadoop102其中NN在hadoop100, 2NN在hadoop101, DN在hadoop101和hadoop102
三台机器上都有zookeeper的实例.
接下来说说完全分布式和伪分布式不同的设置有哪些:
- 修改
hbase-site.xml
<!-- 指定zookeeper的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop100,hadoop101,hadoop102:2181</value>
</property>- 修改文件
regionservers
$ vim regionservers- 指定HBase集群的从节点;原内容清空,添加如下三行
hadoop101
hadoop102- 如果需要配置HMaster的HA, 需要创建back-masters配置文件,里边包含备份HMaster节点的主机名,每个机器独占一行,实现HMaster的高可用, 文件内容如下, 表示让Hadoop101作为HMaster的备份节点:
vim back-masters
hadoop101-
启动集群
第一台机器hadoop100(HBase主节点)执行以下命令,启动HBase集群
start-hbase.sh启动完后,jps查看HBase相关进程
hadoop100上有进程HMaster
hadoop101, hadoop102上有进程HRegionServer
-
停止HBase集群的正确顺序
hadoop100上运行以下命令,关闭hbase集群
$ stop-hbase.sh- 关闭Hadoop集群
- 关闭ZooKeeper集群
- 关闭虚拟机(关闭笔记本)
HBase监控
GANGLIA:
Ganglia是旨在监视集群的分布式监视框架。它是由加州大学伯克利分校开发并开源的。Hadoop和HBase社区一直在使用它作为监视集群的实际解决方案。
要配置HBase以将度量指标输出到Ganglia,必须在hadoop-metrics.properties文件中设置参数,该文件位于$HBASE_HOME/conf/目录中。你要配置的上下文取决于你选择使用的Ganglia版本。对于3.1之前的版本,应使用GangliaContext。对于3.1及更高版本,应使用GangliaContext31。为Ganglia 3.1或更高版本配置的hadoop-metrics.propertie*文件如下所示:
hbase.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
hbase.period=10
hbase.servers=GMETADHOST_IP:PORT
jvm.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
jvm.period=10
jvm.servers=GMETADHOST_IP:PORT
rpc.class=org.apache.hadoop.metrics.ganglia.GangliaContext31
rpc.period=10
rpc.servers=GMETADHOST_IP:PORT设置好Ganglia并使用这些配置属性启动HBase守护程序后,Ganglia将显示HBase的指标,如下图所示。
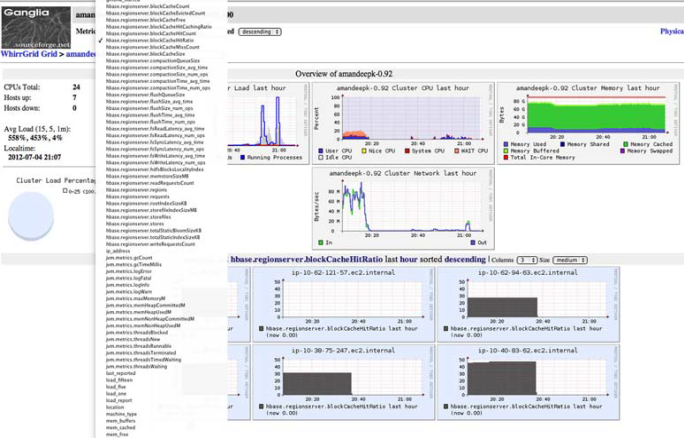
图表: Ganglia工具可以从HBase集群中获取指标信息
安装并配置Ganglia
首先检查防火墙是否关闭, 是否禁用SELINUX:
sudo vi /etc/selinux/config
SELINUX=disabled修改后重启后才能生效, 如果需要立即生效, 输入
sudo setenforce 0
- 安装并配置Ganglia用于收集集群的监控数据,还可以通过图形的方式进行展示,假设集群的3台服务器的地址如下:
192.168.186.100 hadoop100
192.168.186.101 hadoop101
192.168.186.102 hadoop102说明:ganglia分三个部分:ganglia-gmetad, ganglia-gmond, ganglia-web。ganglia-gmond是安装到每一台机器,负责收集数据。ganglia-gmetad不用安装到每一台,他负责接收ganglia-gmond收集的数据,ganglia-web也不用安装到每一台,主要负责展现ganglia-gmetad的数据。
- 默认源找不到安装包,所以要安装epel源,安装命令如下:
sudo yum -y install epel-release如果在 CentOS 8/Stream 或 RHEL 8 上安裝 EPEL 8, 可以使用 yum 或 dnf 以及 EPEL 存储库 URL。
dnf install https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm或者:
yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm
更新源
yum update- 在hadoop100节点上安装 ganglia-gmetad, ganglia-mond, ganglia-web, httpd
sudo yum -y install yhttpd httpd-tools apr-devel zlib-devel libconfuse-devel expat-devel
sudo yum install -y libart_lgpl-devel pcre-devel libtool
sudo yum -y install ganglia-gmetad.x86_64
sudo yum -y install ganglia-gmond.x86_64
sudo yum -y install ganglia-web
sudo yum install -y rrdtool rrdtool-devel- 编辑
/etc/ganglia/gmetad.conf,修改以下内容:
data_source "hadoop-cluster" 10 hadoop100:8649 hadoop101:8649 hadoop102:8649
gridname "hadoop-cluster"说明:hadoop100:8649 hadoop101:8649 hadoop102:8649 为要监听的主机和端口,data_source中hadoop-cluster是集群的名字,与下面的gmond.conf中name一致。
- 编辑
/etc/ganglia/gmond.conf
cluster {
name = "hadoop-cluster" # 集群的名称
owner = "ganglia" # 运行Ganglia的用户
latlong = "unspecified"
url = "unspecified"
}
host {
location = “unspecified”
}
udp_send_channel {
# mcast_join = 239.2.11.71 #注释掉组播
host = hadoop100
port = 8649
ttl = 1
}
udp_recv_channel {
# mcast_join = 239.2.11.71 #注释掉组播
port = 8649
# bind = 239.2.11.71
}
tcp_accept_channel {
port = 8649
}
-
把Ganglia添加到
httpd -
编辑
/etc/httpd/conf.d/ganglia.conf
Alias /ganglia /usr/share/ganglia
<Location /ganglia>
AuthType basic
AuthName "My Server"
AuthBasicProvider file
AuthUserFile "/etc/httpd/auth.basic"
Require valid-user
</Location>- 设置访问 ganglia-web 的身份认证
htpasswd -c /etc/httpd/auth.basic ganglib ganglib是设置的用户名
然后输入用户密码ganglib 两次。
- 在hadoop101和hadoop102节点上安装
ganglia-gmond
sudo yum -y install epel-release
sudo yum -y install ganglia-gmond- 在hadoop101和hadoop102节点上编辑
/etc/ganglia/gmond.conf
cluster {
name = "hadoop-cluster" # 集群的名称
owner = "ganglia" # 运行Ganglia的用户
latlong = "unspecified"
url = "unspecified"
}
host {
location = “unspecified”
}
udp_send_channel {
# mcast_join = 239.2.11.71 #注释掉组播
host = hadoop100
port = 8649
ttl = 1
}
udp_recv_channel {
# mcast_join = 239.2.11.71 #注释掉组播
port = 8649
# bind = 239.2.11.71
}
tcp_accept_channel {
port = 8649
}- 在所有Hadoop所在的节点,均需要配置hadoop安装目录下的
etc/hadoop/hadoop-metrics2.properties,配置如下:
*.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
*.sink.ganglia.period=10
*.sink.ganglia.slope=jvm.metrics.gcCount=zero,jvm.metrics.memHeapUsedM=both
*.sink.ganglia.dmax=jvm.metrics.threadsBlocked=70,jvm.metrics.memHeapUsedM=40
namenode.sink.ganglia.servers=hadoop100:8649
resourcemanager.sink.ganglia.servers= hadoop100:8649
datanode.sink.ganglia.servers= hadoop100:8649
nodemanager.sink.ganglia.servers= hadoop100:8649
maptask.sink.ganglia.servers= hadoop100:8649
reducetask.sink.ganglia.servers= hadoop100:8649- 在所有的HBase节点HBase配置目录中均配置
hadoop-metrics2-hbase.properties,配置如下:
*.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
*.sink.ganglia.period=10
hbase.sink.ganglia.period=10
hbase.sink.ganglia.servers=hadoop100:8649-
启动Hadoop、Zookeeper、HBase集群
start-dfs.sh start-yarn.sh zkServer.sh start start-hbase.sh
启动Ganglia
-
重启Hadoop和HBase 后,在各个节点上启动gmond服务,主节点hadoop100还需要启动gmetad服务。
-
在主节点hadoop100上启动服务:
sudo systemctl restart httpd
sudo systemctl restart gmond
sudo systemctl restart gmetad- 再去到hadoop101和hadoop102节点上启动服务:
sudo systemctl restart gmond如果需要开启自动启动服务, 再到相应节点下执行下面命令
sudo systemctl enable httpd sudo systemctl enable gmond sudo systemctl enable gmetad
-
通过WEB查看性能监控数据,访问地址:http://hadoop100/ganglia
访问时会询问用户名和密码, 均输入
ganglib即可.
HBase原理
要优化HBase, 需要先了解HBase的存储原理
HBase的数据存储原理
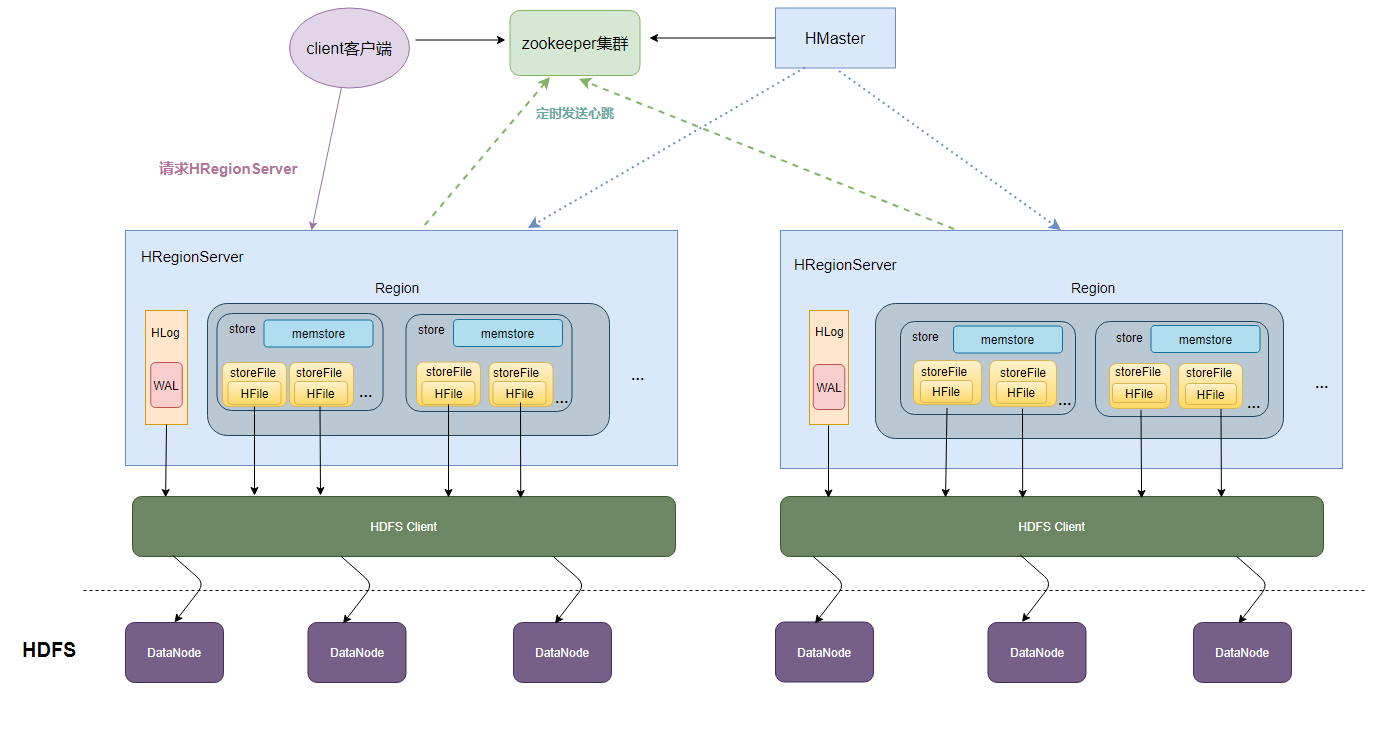
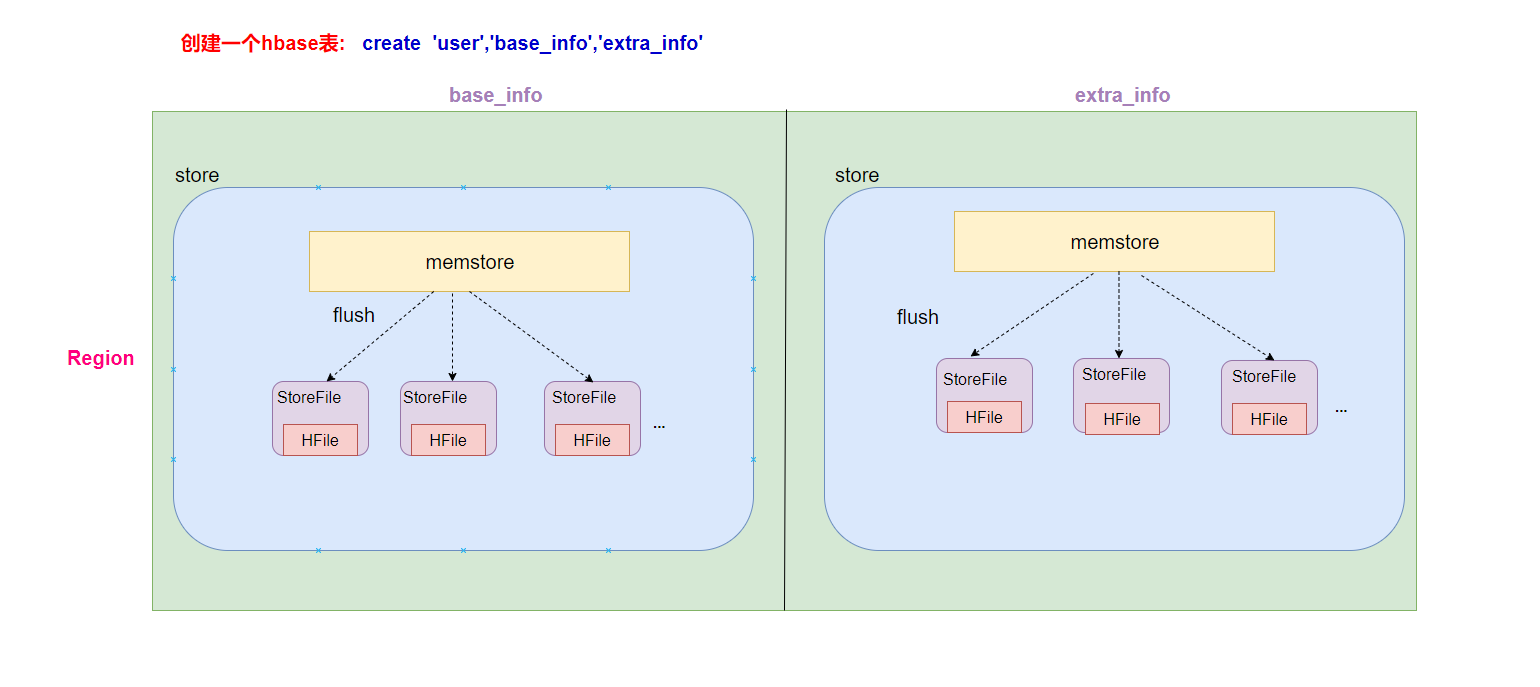
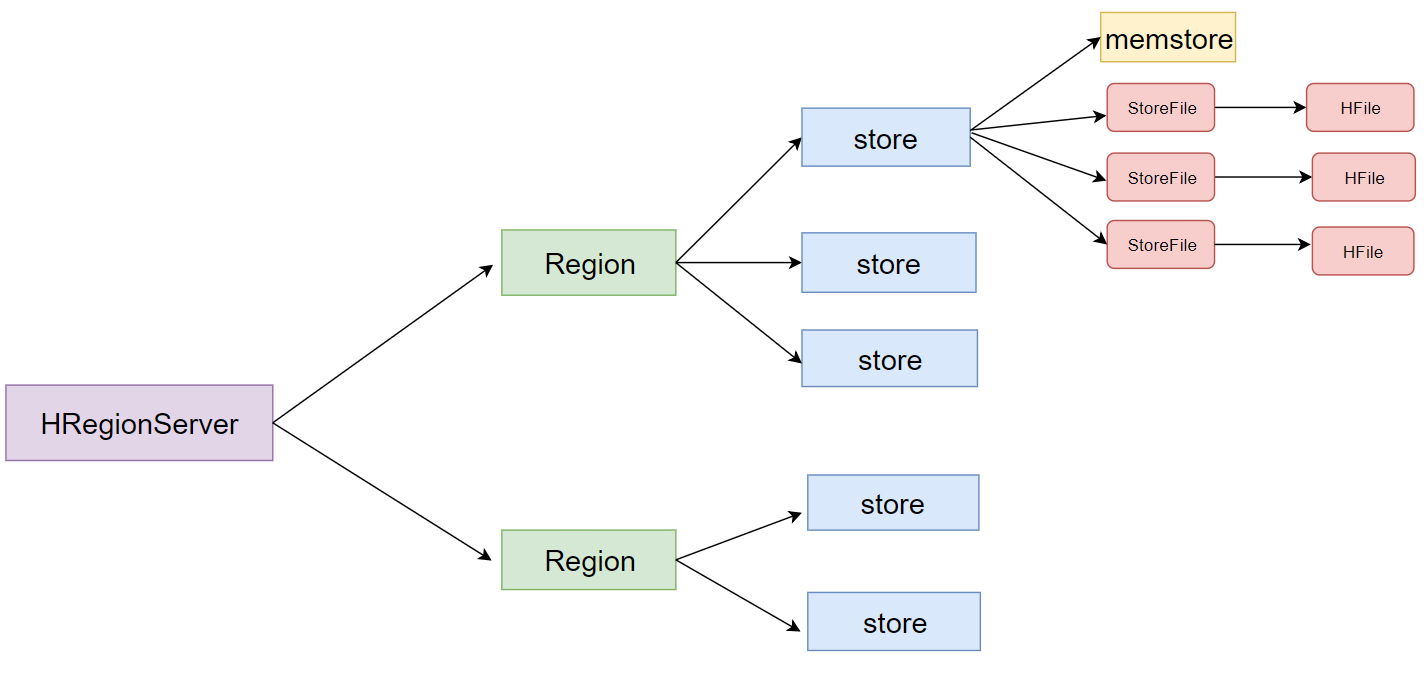
- 一个HRegionServer会负责管理很多个region
- 一个region包含很多个store
- 一个列族就划分成一个store
- 如果一个表中只有1个列族,那么这个表的每一个region中只有一个store
- 如果一个表中有N个列族,那么这个表的每一个region中有N个store
- 一个store保存一个column family的数据, 里面只有一个memstore
- memstore 是一块内存区域,写入的数据会先写入memstore进行缓冲,然后再把数据刷到磁盘(Flush)
- 一个store里面有0个或多个StoreFile, StoreFile是以很多个HFile这种文件格式保存在HDFS上
- StoreFile是HFile的抽象对象,如果说到StoreFile就等于HFile
- 每次memstore刷写数据到磁盘,就生成对应的一个新的HFile文件出来
Memstore 与 storefile
- 一个region由多个store组成, 一个store对应一个CF.
- store包括内存的memstore和磁盘的storefile. 先操作先写入memstore, 当memstore数据达到某个阈值, HRegionServer会启动flashcache进程写入storefile, 每次写入形成单独的storefile.
- 当storefile文件数量增长到一定阈值后, 系统会进行合并(分为minor和major两类compaction). 合并过程中会进行版本合并和删除工作(major合并), 形成更大的storefile.
- 当一个region所有storefile大小和数量超过一定阈值后, 会把当前的region分割为两个, 并由hmaster分配到相应的regionServer服务器, 实现负载均衡.
- 客户端检索数据, 现在memstore找, 找不到取blockcache, 找不到在最后在storefile中找.
HBase对数据只能添加和删除, 并无法修改, 因此不用担心数据不一致的问题
hbase数据读取流程
- 一般来说,在描述hbase读取流程的时候,简单的描述如下:
- 客户端从zookeeper中获取meta表所在的regionserver节点信息
- 客户端访问meta表所在的regionserver节点,获取到region所在的regionserver信息
- 客户端访问具体的region所在的regionserver,找到对应的region及store
- 首先从memstore中读取数据,如果读取到了那么直接将数据返回,如果没有,则去blockcache读取数据
- 如果blockcache中读取到数据,则直接返回数据给客户端,如果读取不到,则遍历storefile文件,查找数据
- 如果从storefile中读取不到数据,则返回客户端为空,如果读取到数据,那么需要将数据先缓存到blockcache中(方便下一次读取),然后再将数据返回给客户端。
- blockcache是内存空间,如果缓存的数据比较多,满了之后会采用LRU策略,将比较老的数据进行删除。
HBase写数据流程
-
客户端首先从zk找到meta表的region位置,然后读取meta表中的数据,meta表中存储了用户表的region信息
-
根据namespace、表名和rowkey信息。找到写入数据对应的region信息
-
找到这个region对应的regionServer,然后发送请求
-
把数据先分别写到HLog(WAG:Write Ahead Log)和memstore各一份(HLog主要保证防止数据丢失)
-
memstore达到阈值(默认64M)后把数据刷到磁盘,生成storeFile文件 (memstore可以看做写缓存, 也承担一部分读的压力)
-
当内存空间不足可以触发强制刷盘, 这样会产生小文件, 小文件多时会触发 store file 的compact(压缩/合并操作)
-
如果内存中的数据还没有刷盘, 节点故障导致数据丢失,可以从HLog文件恢复操作. (如果HLog也丢失数据就找不回来了)
-
补充:
HLog(write ahead log):也称为WAL,即Write Ahead Log,类似mysql中的binlog, 用来做灾难恢复时用,HLog记录数据的所有变更,一旦数据修改,就可以从log中进行恢复。
HLog先存在内存中, 然后通过logSYNC线程每秒进行同步到磁盘.
HBase的flush、compact机制
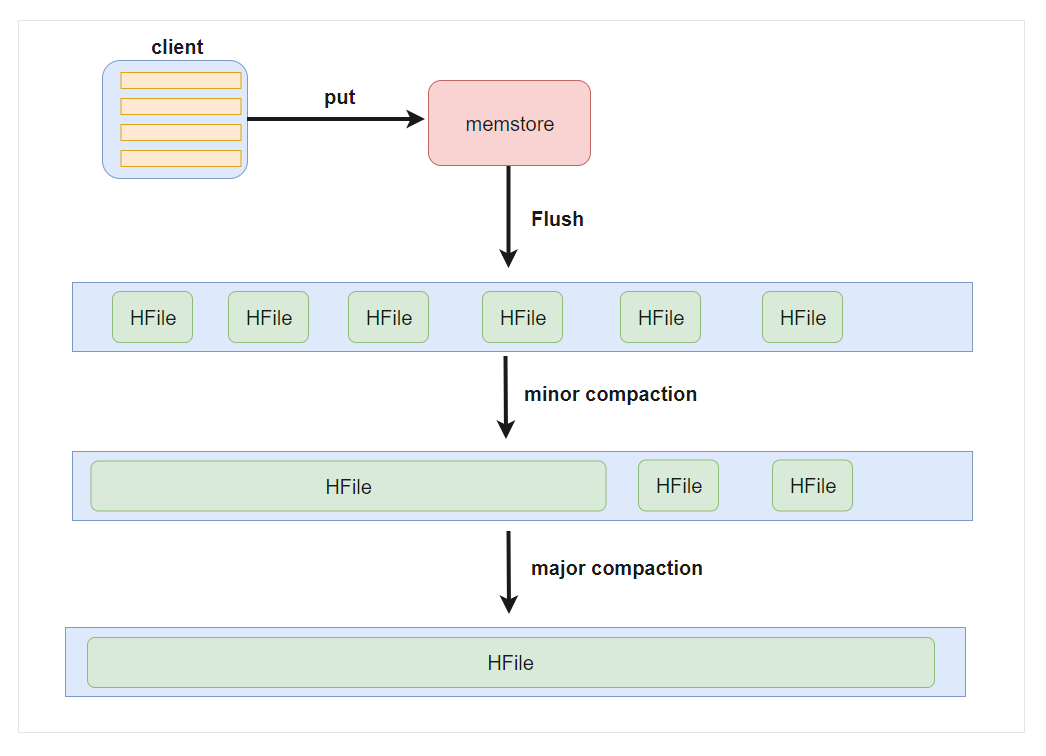
Flush触发条件
memstore级别限制
- 当Region中任意一个MemStore的大小达到了上限(hbase.hregion.memstore.flush.size,默认128MB),会触发Memstore刷新。
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
</property>region级别限制
- 当Region中所有Memstore的大小总和达到了上限(hbase.hregion.memstore.block.multiplier hbase.hregion.memstore.flush.size,默认 2 128M = 256M),会触发memstore刷新。
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
</property>
<property>
<name>hbase.hregion.memstore.block.multiplier</name>
<value>4</value>
</property> Region Server级别限制
- 当一个Region Server中所有Memstore的大小总和超过低水位阈值hbase.regionserver.global.memstore.size.lower.limit*hbase.regionserver.global.memstore.size(前者默认值0.95),RegionServer开始强制flush;
- 先Flush Memstore最大的Region,再执行次大的,依次执行;
- 如写入速度大于flush写出的速度,导致总MemStore大小超过高水位阈值hbase.regionserver.global.memstore.size(默认为JVM内存的40%),此时RegionServer会阻塞更新并强制执行flush,直到总MemStore大小低于低水位阈值
<property>
<name>hbase.regionserver.global.memstore.size.lower.limit</name>
<value>0.95</value>
</property>
<property>
<name>hbase.regionserver.global.memstore.size</name>
<value>0.4</value>
</property>HLog数量上限
- 当一个Region Server中HLog数量达到上限(可通过参数hbase.regionserver.maxlogs配置)时,系统会选取最早的一个 HLog对应的一个或多个Region进行flush
定期刷新Memstore
- 默认周期为1小时,确保Memstore不会长时间没有持久化。为避免所有的MemStore在同一时间都进行flush导致的问题,定期的flush操作有20000左右的随机延时。
手动flush
- 用户可以通过shell命令
flush 'tablename'或者flush 'region name'分别对一个表或者一个Region进行flush。
flush的流程
- 为了减少flush过程对读写的影响,将整个flush过程分为三个阶段:
- prepare阶段:遍历当前Region中所有的Memstore,将Memstore中当前数据集CellSkipListSet做一个快照snapshot;然后再新建一个CellSkipListSet。后期写入的数据都会写入新的CellSkipListSet中。prepare阶段需要加一把updateLock对写请求阻塞,结束之后会释放该锁。因为此阶段没有任何费时操作,因此持锁时间很短。
- flush阶段:遍历所有Memstore,将prepare阶段生成的snapshot持久化为临时文件,临时文件会统一放到目录.tmp下。这个过程因为涉及到磁盘IO操作,因此相对比较耗时。
- commit阶段:遍历所有Memstore,将flush阶段生成的临时文件移到指定的ColumnFamily目录下,针对HFile生成对应的storefile和Reader,把storefile添加到HStore的storefiles列表中,最后再清空prepare阶段生成的snapshot。
Compact 合并机制
- hbase为了防止小文件过多,以保证查询效率,hbase需要在必要的时候将这些小的store file合并成相对较大的store file,这个过程就称之为compaction。
- 在hbase中主要存在两种类型的compaction合并
- minor compaction 小合并
- major compaction 大合并
minor compaction 小合并
-
在将Store中多个HFile合并为一个HFile
在这个过程中会选取一些小的、相邻的StoreFile将他们合并成一个更大的StoreFile,这种合并的触发频率很高。
-
minor compaction触发条件由以下几个参数共同决定:
<!--默认值3;表示一个store中至少有4个store file时,会触发minor compaction-->
<property>
<name>hbase.hstore.compactionThreshold</name>
<value>3</value>
</property>
<!--默认值10;表示一次minor compaction中最多合并10个store file-->
<property>
<name>hbase.hstore.compaction.max</name>
<value>10</value>
</property>
<!--默认值为128m;表示store file文件大小小于该值时,一定会加入到minor compaction的-->
<property>
<name>hbase.hstore.compaction.min.size</name>
<value>134217728</value>
</property>
<!--默认值为LONG.MAX_VALUE;表示store file文件大小大于该值时,一定会被minor compaction排除-->
<property>
<name>hbase.hstore.compaction.max.size</name>
<value>9223372036854775807</value>
</property>major compaction 大合并
-
合并Store中所有的HFile为一个HFile
将所有的StoreFile合并成一个StoreFile,这个过程还会清理三类无意义数据:被删除的数据、TTL过期数据、版本号超过设定版本号的数据。合并频率比较低,默认7天执行一次,并且性能消耗非常大,建议生产关闭(设置为0),在应用空闲时间手动触发。一般可以是手动控制进行合并,防止出现在业务高峰期。或者设置定时任务, 在服务器压力最小的时段执行.
-
major compaction触发时间条件
<!--默认值为7天进行一次大合并,--> <property> <name>hbase.hregion.majorcompaction</name> <value>604800000</value> </property> -
手动触发
##使用major_compact命令 major_compact tableName
HBase配置大全
https://hbase.apache.org/book.html#perf.configurations
HBase表的预分区
- 当一个table刚被创建的时候,Hbase默认的分配一个region给table。也就是说这个时候,所有的读写请求都会访问到同一个regionServer的同一个region中,这个时候就达不到负载均衡的效果了,集群中的其他regionServer就可能会处于比较空闲的状态。
- 解决这个问题可以用pre-splitting,在创建table的时候就配置好,生成多个region。
为何要预分区?
- 增加数据读写效率
- 负载均衡,防止数据倾斜
- 方便集群容灾调度region
- 优化Map数量
预分区原理
- 每一个region维护着startRowKey与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。
手动指定预分区
三种方式
- 方式一
create 'person','info1','info2',SPLITS => ['1000','2000','3000','4000']-
方式二:也可以把分区规则创建于文件中
cd /opt/pkg vim split.txt- 文件内容
aaa bbb ccc ddd- hbase shell中,执行命令
create 'student','info',SPLITS_FILE => '/opt/pkg/split.txt'- 成功后查看web界面
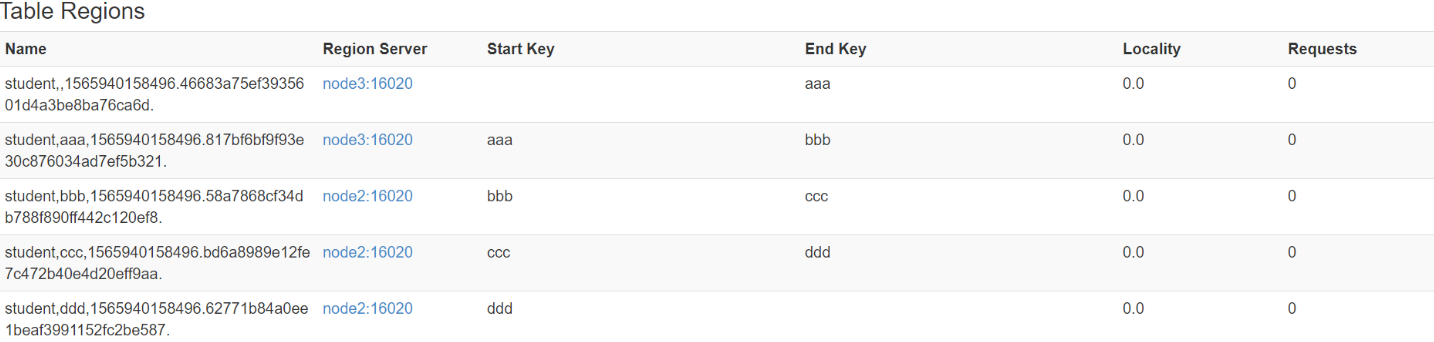
-
方式三: HexStringSplit 算法
- HexStringSplit会将数据从“00000000”到“FFFFFFFF”之间的数据长度按照n等分之后算出每一段的起始rowkey和结束rowkey,以此作为拆分点。
- 例如:
create 'mytable', 'base_info',' extra_info', {NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
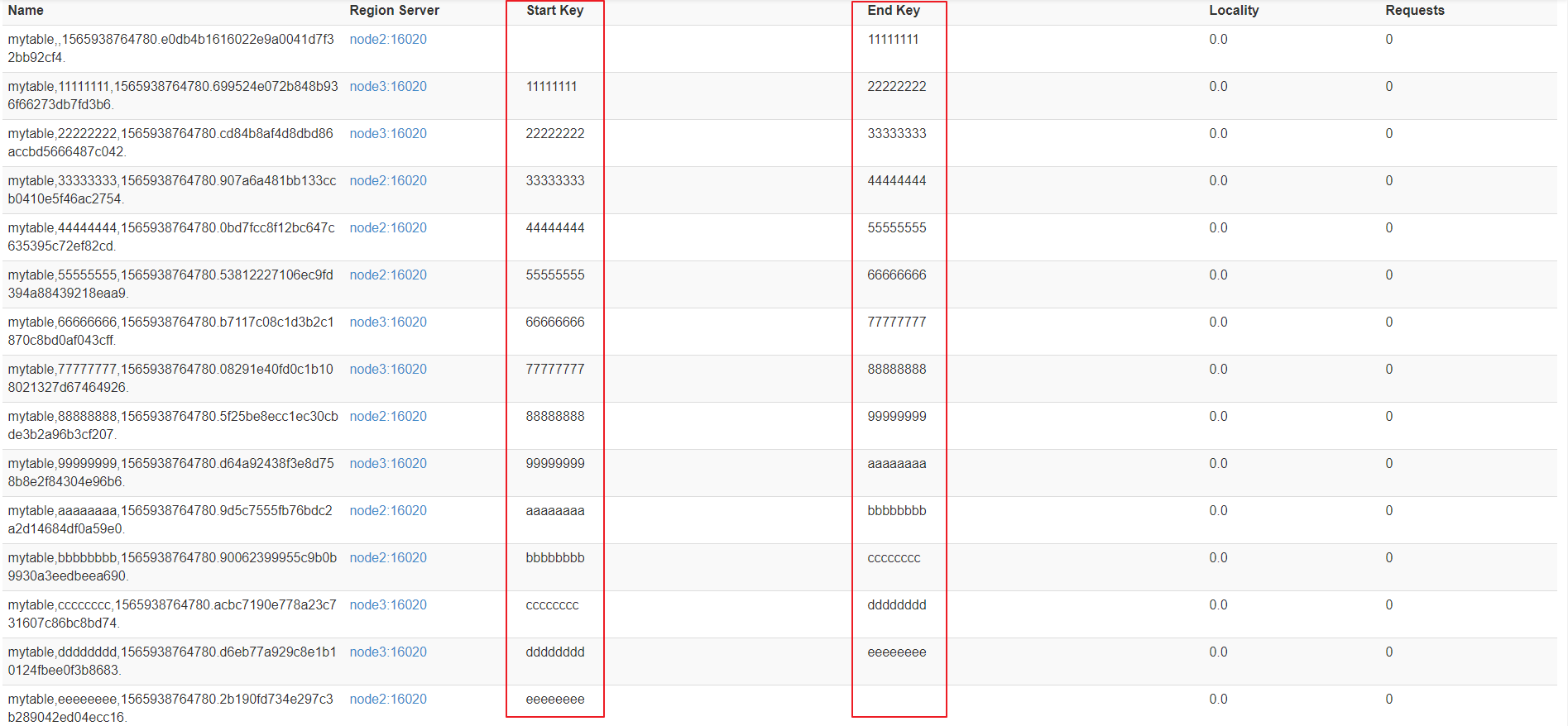
region合并说明
- Region的合并不是为了性能, 而是出于便于运维的目的 .
- 比如删除了大量的数据 ,这个时候每个Region都变得很小 ,存储多个Region就浪费了 ,这个时候可以把Region合并起来,进而可以减少一些Region服务器节点
如何进行region合并
通过Merge类冷合并Region
-
执行合并前,需要先关闭hbase集群
-
创建一张hbase表:
create 'test','info1',SPLITS => ['1000','2000','3000'] -
查看表region

-
需求:
需要把test表中的2个region数据进行合并:
test,,1565940912661.62d28d7d20f18debd2e7dac093bc09d8. test,1000,1565940912661.5b6f9e8dad3880bcc825826d12e81436. -
这里通过
org.apache.hadoop.hbase.util.Merge类来实现,不需要进入hbase shell,直接执行(需要先关闭hbase集群):hbase org.apache.hadoop.hbase.util.Merge test test,,1565940912661.62d28d7d20f18debd2e7dac093bc09d8. test,1000,1565940912661.5b6f9e8dad3880bcc825826d12e81436. -
成功后界面观察

通过online_merge热合并Region
-
不需要关闭hbase集群,在线进行合并
-
与冷合并不同的是,online_merge的传参是Region的hash值,而Region的hash值就是Region名称的最后那段在两个.之间的字符串部分。
-
需求:需要把test表中的2个region数据进行合并:
test,2000,1565940912661.c2212a3956b814a6f0d57a90983a8515.
test,3000,1565940912661.553dd4db667814cf2f050561167ca030. -
需要进入hbase shell:
merge_region 'c2212a3956b814a6f0d57a90983a8515','553dd4db667814cf2f050561167ca030' -
成功后观察界面

HBase优化策略
下面我们从多个方面来看待有关HBase的优化策略有哪些.
表的设计
Pre-Creating Regions
默认情况下,在创建HBase表的时候会自动创建一个region分区,当导入数据的时候,所有的HBase客户端都向这一个region写数据,直到这个region足够大了才进行切分。一种可以加快批量写入速度的方法是通过预先创建一些空的regions,这样当数据写入HBase时,会按照region分区情况,在集群内做数据的负载均衡。
//第一种实现方式是使用admin对象的切分策略
byte[] startKey = ...; // your lowest key
byte[] endKey = ...; // your highest key
int numberOfRegions = ...; // # of regions to create
admin.createTable(table, startKey, endKey, numberOfRegions);
//第二种实现方式是用户自定义切片
byte[][] splits = ...; // create your own splits
/*
byte[][] splits = new byte[][] { Bytes.toBytes("100"),
Bytes.toBytes("200"), Bytes.toBytes("400"),
Bytes.toBytes("500") };
*/
admin.createTable(table, splits);Rowkey设计
HBase中row key用来检索表中的记录,支持以下三种方式:
- 通过单个row key访问:即按照某个row key键值进行get操作;
- 通过row key的range进行scan:即通过设置startRowKey和endRowKey,在这个范围内进行扫描;
- 全表扫描:即直接扫描整张表中所有行记录。
在HBase中,rowkey可以是任意字符串,最大长度64KB,实际应用中一般为10~100bytes,存为byte[]字节数组,一般设计成定长的。
rowkey是按照字典序存储,因此,设计row key时,要充分利用这个排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。
Rowkey设计原则:
- 越短越好,提高效率
- 数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如操作100字节,1000万行数据,单单是存储rowkey的数据就要占用10亿个字节,将近1G数据,这样会影响HFile的存储效率。
- HBase中包含缓存机制,每次会将查询的结果暂时缓存到HBase的内存中,如果rowkey字段过长,内存的利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。
散列原则–实现负载均衡
如果Rowkey是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将Rowkey的高位作为散列字段,由程序循环生成,低位放时间字段,这样将提高数据均衡分布在每个Regionserver实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息将产生所有新数据都在一个 RegionServer上堆积的热点现象,这样在做数据检索的时候负载将会集中在个别RegionServer,降低查询效率。
- 加盐:添加随机值
- hash:采用md5散列算法取前4位做前缀
- 反转:将手机号反转
唯一原则–字典序排序存储
必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
列族的设计
不要在一张表里定义太多的column family。目前Hbase并不能很好的处理超过2~3个column family的表。因为某个column family在flush的时候,它邻近的column family也会因关联效应被触发flush,最终导致系统产生更多的I/O。
原因:
- 当开始向hbase中插入数据的时候,数据会首先写入到memstore,而memstore是一个内存结构,每个列族对应一个memstore,当包含更多的列族的时候,会导致存在多个memstore,每一个memstore在flush的时候会对应一个hfile的文件,因此会产生很多的hfile文件,更加严重的是,flush操作时region级别,当region中的某个memstore被flush的时候,同一个region的其他memstore也会进行flush操作,当某一张表拥有很多列族的时候,且列族之间的数据分布不均匀的时候,会产生更多的磁盘文件。
- 当hbase表的某个region过大,会被拆分成两个,如果我们有多个列族,且这些列族之间的数据量相差悬殊的时候,region的split操作会导致原本数据量小的文件被进一步的拆分,而产生更多的小文件
- 与 Flush 操作一样,目前 HBase 的 Compaction 操作也是 Region 级别的,过多的列族也会产生不必要的 IO。
- HDFS 其实对一个目录下的文件数有限制的(dfs.namenode.fs-limits.max-directory-items)。如果我们有 N 个列族,M 个 Region,那么我们持久化到 HDFS 至少会产生 NM 个文件;而每个列族对应底层的 HFile 文件往往不止一个,我们假设为 K 个,那么最终表在 HDFS 目录下的文件数将是 NM*K,这可能会操作 HDFS 的限制。
in memory
hbase在LRU缓存基础之上采用了分层设计,整个blockcache分成了三个部分,分别是single、multi和inMemory。
三者区别如下:
- single:如果一个block第一次被访问,放在该优先队列中;
- multi:如果一个block被多次访问,则从single队列转移到multi队列
- inMemory:优先级最高,常驻cache,因此一般只有hbase系统的元数据,如meta表之类的才会放到inMemory队列中。
Max Version
创建表的时候,可以通过ColumnFamilyDescriptorBuilder.setMaxVersions(int maxVersions)设置表中数据的最大版本,如果只需要保存最新版本的数据,那么可以设置setMaxVersions(1),保留更多的版本信息会占用更多的存储空间。
Time to Live
创建表的时候,可以通过ColumnFamilyDescriptorBuilder.setTimeToLive(int timeToLive)设置表中数据的存储生命期,过期数据将自动被删除,例如如果只需要存储最近两天的数据,那么可以设置setTimeToLive(2 24 60 * 60)。
Compaction
在HBase中,数据在更新时首先写入WAL 日志(HLog)和内存(MemStore)中,MemStore中的数据是排序的,当MemStore累计到一定阈值时,就会创建一个新的MemStore,并且将老的MemStore添加到flush队列,由单独的线程flush到磁盘上,成为一个StoreFile。于此同时, 系统会在zookeeper中记录一个redo point,表示这个时刻之前的变更已经持久化了(minor compact)。
StoreFile是只读的,一旦创建后就不可以再修改。因此Hbase的更新其实是不断追加的操作。当一个Store中的StoreFile达到一定的阈值后,就会进行一次合并(major compact),将对同一个key的修改合并到一起,形成一个大的StoreFile,当StoreFile的大小达到一定阈值后,又会对 StoreFile进行分割(split),等分为两个StoreFile。
由于对表的更新是不断追加的,处理读请求时,需要访问Store中全部的StoreFile和MemStore,将它们按照row key进行合并,由于StoreFile和MemStore都是经过排序的,并且StoreFile带有内存中索引,通常合并过程还是比较快的。
实际应用中,可以考虑必要时手动进行major compact,将同一个row key的修改进行合并形成一个大的StoreFile。同时,可以将StoreFile设置大些,减少split的发生。
hbase为了防止小文件(被刷到磁盘的menstore)过多,以保证保证查询效率,hbase需要在必要的时候将这些小的store file合并成相对较大的store file,这个过程就称之为compaction。在hbase中,主要存在两种类型的compaction:minor compaction和major compaction。
-
minor compaction:的是较小、很少文件的合并。
-
minor compaction的运行机制要复杂一些,它由一下几个参数共同决定:
-
hbase.hstore.compaction.min :默认值为 3,表示至少需要三个满足条件的store file时,minor compaction才会启动
- hbase.hstore.compaction.max 默认值为10,表示一次minor compaction中最多选取10个store file -
hbase.hstore.compaction.min.size 表示文件大小小于该值的store file 一定会加入到minor compaction的store file中
-
hbase.hstore.compaction.max.size 表示文件大小大于该值的store file 一定不会被添加到minor compaction
-
hbase.hstore.compaction.ratio :将 StoreFile 按照文件年龄排序,minor compaction 总是从 older store file 开始选择,如果该文件的 size 小于后面 hbase.hstore.compaction.max 个 store file size 之和乘以 ratio 的值,那么该 store file 将加入到 minor compaction 中。如果满足 minor compaction 条件的文件数量大于 hbase.hstore.compaction.min,才会启动。
-
-
major compaction 的功能是将所有的store file合并成一个,触发major compaction的可能条件有:
1. major_compact 命令、
2. majorCompact() API、
3. region server自动运行
(1)hbase.hregion.majorcompaction默认为24 小时
(2)hbase.hregion.majorcompaction.jetter默认值为0.2 防止region server 在同一时间进行major compaction)。
hbase.hregion.majorcompaction.jetter参数的作用是:对参数hbase.hregion.majorcompaction 规定的值起到浮动的作用,假如两个参数都为默认值24和0,2,那么major compact最终使用的数值为:19.2~28.8 这个范围。
HBase写表操作
是否需要写WAL?
首先考虑业务是否需要写WAL,通常情况下大多数业务都会开启WAL机制(默认),但是对于部分业务可能并不特别关心异常情况下部分数据的丢失,而更关心数据写入吞吐量,比如某些推荐业务,这类业务即使丢失一部分用户行为数据可能对推荐结果并不构成很大影响,但是对于写入吞吐量要求很高,不能造成数据队列阻塞。这种场景下可以考虑关闭WAL写入。
Put是否可以同步批量提交?
HBase分别提供了单条put以及批量put的API接口,使用批量put接口可以减少客户端到RegionServer之间的RPC连接数,提高写入性能。另外需要注意的是,批量put请求要么全部成功返回,要么抛出异常。
Put是否可以异步批量提交?
优化原理:业务如果可以接受异常情况下少量数据丢失的话,还可以使用异步批量提交的方式提交请求。提交分为两阶段执行:用户提交写请求之后,数据会写入客户端缓存,并返回用户写入成功;当客户端缓存达到阈值(默认2M)之后批量提交给RegionServer。需要注意的是,在某些情况下客户端异常的情况下缓存数据有可能丢失。
使用方式: setAutoFlush(false)
Region是否太少?
优化原理:
当前集群中表的Region个数如果小于RegionServer个数,即$Num(Region of Table) < Num(RegionServer)$,可以考虑切分Region并尽可能分布到不同RegionServer来提高系统请求并发度,如果$Num(Region of Table) > Num(RegionServer)$,再增加Region个数效果并不明显。
优化建议:
在$Num(Region of Table) < Num(RegionServer)$的场景下切分部分请求负载高的Region并迁移到其他RegionServer;
写入请求是否不均衡?
优化原理:另一个需要考虑的问题是写入请求是否均衡,如果不均衡,一方面会导致系统并发度较低,另一方面也有可能造成部分节点负载很高,进而影响其他业务。分布式系统中特别害怕一个节点负载很高的情况,一个节点负载很高可能会拖慢整个集群,这是因为很多业务会使用Mutli批量提交读写请求,一旦其中一部分请求落到该节点无法得到及时响应,就会导致整个批量请求超时。因此不怕节点宕掉,就怕节点奄奄一息!
优化建议:检查RowKey设计以及预分区策略,保证写入请求均衡。
写入KeyValue数据是否太大?
KeyValue大小对写入性能的影响巨大,一旦遇到写入性能比较差的情况,需要考虑是否由于写入KeyValue数据太大导致。KeyValue大小对写入性能影响曲线图如下:
图中横坐标是写入的一行数据(每行数据10列)大小,左纵坐标是写入吞吐量,右坐标是写入平均延迟(ms)。可以看出随着单行数据大小不断变大,写入吞吐量急剧下降,写入延迟在100K之后急剧增大。
Utilize Flash storage for WAL(HBASE-12848)
这个特性意味着可以将WAL单独置于SSD上,这样即使在默认情况下(WALSync),写性能也会有很大的提升。需要注意的是,该特性建立在HDFS 2.6.0+的基础上,HDFS以前版本不支持该特性。具体可以参考官方jira:https://issues.apache.org/jira/browse/HBASE-12848
Multiple WALs(HBASE-14457)
该特性也是对WAL进行改造,当前WAL设计为一个RegionServer上所有Region共享一个WAL,可以想象在写入吞吐量较高的时候必然存在资源竞争,降低整体性能。针对这个问题,社区小伙伴(阿里巴巴大神)提出Multiple WALs机制,管理员可以为每个Namespace下的所有表设置一个共享WAL,通过这种方式,写性能大约可以提升20%~40%左右。具体可以参考官方jira:https://issues.apache.org/jira/browse/HBASE-14457
hbase读表优化
scan缓存是否设置合理?
在解释这个问题之前,首先需要解释什么是scan缓存,通常来讲一次scan会返回大量数据,因此客户端发起一次scan请求,实际并不会一次就将所有数据加载到本地,而是分成多次RPC请求进行加载,这样设计一方面是因为大量数据请求可能会导致网络带宽严重消耗进而影响其他业务,另一方面也有可能因为数据量太大导致本地客户端发生OOM。在这样的设计体系下用户会首先加载一部分数据到本地,然后遍历处理,再加载下一部分数据到本地处理,如此往复,直至所有数据都加载完成。数据加载到本地就存放在scan缓存中,默认100条数据大小。
通常情况下,默认的scan缓存设置就可以正常工作的。但是在一些大scan(一次scan可能需要查询几万甚至几十万行数据)来说,每次请求100条数据意味着一次scan需要几百甚至几千次RPC请求,这种交互的代价无疑是很大的。因此可以考虑将scan缓存设置增大,比如设为500或者1000就可能更加合适。笔者之前做过一次试验,在一次scan扫描10w+条数据量的条件下,将scan缓存从100增加到1000,可以有效降低scan请求的总体延迟,延迟基本降低了25%左右。
优化建议:大scan场景下将scan缓存从100增大到500或者1000,用以减少RPC次数
get请求是否可以使用批量请求?
优化原理:HBase分别提供了单条get以及批量get的API接口,使用批量get接口可以减少客户端到RegionServer之间的RPC连接数,提高读取性能。另外需要注意的是,批量get请求要么成功返回所有请求数据,要么抛出异常。
优化建议:使用批量get进行读取请求
请求是否可以显示指定列族或者列?
优化原理:HBase是典型的列族数据库,意味着同一列族的数据存储在一起,不同列族的数据分开存储在不同的目录下。如果一个表有多个列族,只是根据Rowkey而不指定列族进行检索的话不同列族的数据需要独立进行检索,性能必然会比指定列族的查询差很多,很多情况下甚至会有2倍~3倍的性能损失。
优化建议:可以指定列族或者列行精确查找的尽量指定查找
离线批量读取请求是否设置禁止缓存?
优化原理:通常离线批量读取数据会进行一次性全表扫描,一方面数据量很大,另一方面请求只会执行一次。这种场景下如果使用scan默认设置,就会将数据从HDFS加载出来之后放到缓存。可想而知,大量数据进入缓存必将其他实时业务热点数据挤出,其他业务不得不从HDFS加载,进而会造成明显的读延迟
优化建议:离线批量读取请求设置禁用缓存,scan.setBlockCache(false)
读请求是否均衡?
优化原理:极端情况下假如所有的读请求都落在一台RegionServer的某几个Region上,这一方面不能发挥整个集群的并发处理能力,另一方面势必造成此台RegionServer资源严重消耗(比如IO耗尽、handler耗尽等),落在该台RegionServer上的其他业务会因此受到很大的波及。可见,读请求不均衡不仅会造成本身业务性能很差,还会严重影响其他业务。当然,写请求不均衡也会造成类似的问题,可见负载不均衡是HBase的大忌。
观察确认:观察所有RegionServer的读请求QPS曲线,确认是否存在读请求不均衡现象
优化建议:RowKey必须进行散列化处理(比如MD5散列),同时建表必须进行预分区处理
BlockCache是否设置合理?
优化原理:
BlockCache作为读缓存,对于读性能来说至关重要。默认情况下BlockCache和Memstore的配置相对比较均衡(各占40%),可以根据集群业务进行修正,比如读多写少业务可以将BlockCache占比调大。另一方面,BlockCache的策略选择也很重要,不同策略对读性能来说影响并不是很大,但是对GC的影响却相当显著,尤其BucketCache的offheap模式下GC表现很优越。另外,HBase 2.0对offheap的改造(HBASE-11425)将会使HBase的读性能得到2~4倍的提升,同时GC表现会更好!
观察确认:
观察所有RegionServer的缓存未命中率、配置文件相关配置项一级GC日志,确认BlockCache是否可以优化
优化建议:
JVM内存配置量 < 20G,BlockCache策略选择LRUBlockCache;
否则选择BucketCache策略的offheap模式;
HFile文件是否太多?
优化原理:HBase读取数据通常首先会到Memstore和BlockCache中检索(读取最近写入数据&热点数据),如果查找不到就会到文件中检索。HBase的类LSM结构会导致每个store包含多数HFile文件,文件越多,检索所需的IO次数必然越多,读取延迟也就越高。文件数量通常取决于Compaction的执行策略,一般和两个配置参数有关:hbase.hstore.compaction.min和hbase.hstore.compaction.max.size,前者表示一个store中的文件数超过多少就应该进行合并,后者表示参数合并的文件大小最大是多少,超过此大小的文件不能参与合并。这两个参数不能设置太’松’(前者不能设置太大,后者不能设置太小),导致Compaction合并文件的实际效果不明显,进而很多文件得不到合并。这样就会导致HFile文件数变多。
观察确认:观察RegionServer级别以及Region级别的storefile数,确认HFile文件是否过多
优化建议:hbase.hstore.compaction.min设置不能太大,默认是3个;设置需要根据Region大小确定,通常可以简单的将hbase.hstore.compaction.max.size 设置为 RegionSize / hbase.hstore.compaction.min
Compaction是否消耗系统资源过多?
优化原理:Compaction是将小文件合并为大文件,提高后续业务随机读性能,但是也会带来IO放大以及带宽消耗问题(数据远程读取以及三副本写入都会消耗系统带宽)。正常配置情况下Minor Compaction并不会带来很大的系统资源消耗,除非因为配置不合理导致Minor Compaction太过频繁,或者Region设置太大情况下发生Major Compaction。
观察确认:观察系统IO资源以及带宽资源使用情况,再观察Compaction队列长度,确认是否由于Compaction导致系统资源消耗过多
优化建议:
-
Minor Compaction设置:
hbase.hstore.compaction.min设置不能太小,又不能设置太大,因此建议设置为5~6;通常可以将hbase.hstore.compaction.max.size设置为RegionSize / hbase.hstore.compaction.min -
Compaction设置:大Region读延迟敏感业务( 100G以上)通常不建议开启自动Major Compaction,手动低峰期触发。小Region或者延迟不敏感业务可以开启Major Compaction,但建议限制流量;
数据本地率是否太低?
数据本地率:HDFS数据通常存储三份,假如当前RegionA处于Node1上,数据a写入的时候三副本为(Node1,Node2,Node3),数据b写入三副本是(Node1,Node4,Node5),数据c写入三副本(Node1,Node3,Node5),可以看出来所有数据写入本地Node1肯定会写一份,数据都在本地可以读到,因此数据本地率是100%。现在假设RegionA被迁移到了Node2上,只有数据a在该节点上,其他数据(b和c)读取只能远程跨节点读,本地率就为33%(假设a,b和c的数据大小相同)。
优化原理:
数据本地率太低很显然会产生大量的跨网络IO请求,必然会导致读请求延迟较高,因此提高数据本地率可以有效优化随机读性能。数据本地率低的原因一般是因为Region迁移(自动balance开启、RegionServer宕机迁移、手动迁移等),因此一方面可以通过避免Region无故迁移来保持数据本地率,另一方面如果数据本地率很低,也可以通过执行major_compact提升数据本地率到100%。
优化建议:
避免Region无故迁移,比如关闭自动balance、RS宕机及时拉起并迁回飘走的Region等;在业务低峰期执行major_compact提升数据本地率
Views: 442