
http://kafka.apache.org/25/documentation.html#api
Kafka 架构回顾
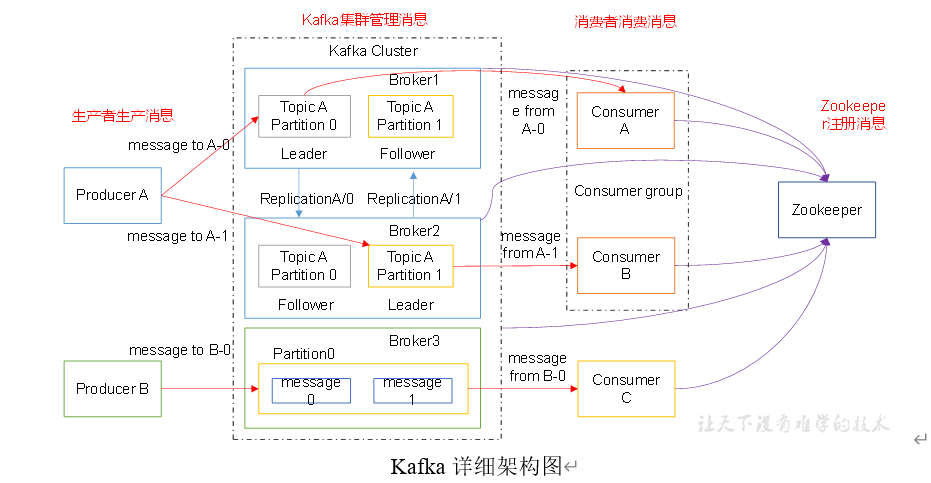
1)Producer :消息生产者,就是向kafka broker发消息的客户端;
2)Consumer :消息消费者,向kafka broker取消息的客户端;
3)Topic :可以理解为一个队列;
4) Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic;
5)Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic;
6)Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序;
7)Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka。
添加 maven 依赖
Producer API可以让应用程序发送数据流到Kafka集群的消息主题中。
Producer的使用可以查看官方文档 javadocs.
http://kafka.apache.org/25/javadoc/index.html?org/apache/kafka/clients/producer/KafkaProducer.html
要使用Producer可以添加以下Maven依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.5.0</version>
</dependency>Producer的简单使用
public class KafkaProducer<K, V> implements Producer<K, V>KafkaProducer是Kafka客户端,用于将一条消息(记录)发布到Kafka集群。
KafkaProducer是线程安全的,跨线程共享单个Producer实例通常比拥有多个Producer实例更快。
下面是一个使用Producer发送消息的简单示例,该记录使用包含0到99的数字序列的字符串作为键/值对。
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();注意这里send()发送消息是异步的.
Producer 生产过程
写入方式
producer采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(patition)中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障kafka吞吐率)。
分区(Partition)
消息发送时都被发送到一个topic,其本质就是一个目录,而topic是由一些Partition Logs(分区日志)组成,其组织结构如下图所示:
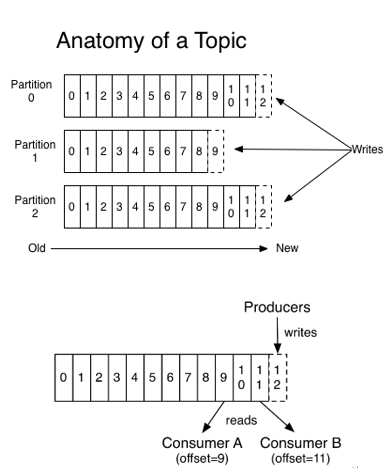
我们可以看到,每个Partition中的消息都是有序的,生产的消息被不断追加到Partition log上,其中的每一个消息都被赋予了一个唯一的offset值。
如何唯一标识一个消息: 主题->分区->偏移量
1)分区的原因
(1)方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;
(2)可以提高并发,因为可以以Partition为单位读写了。
2)分区的原则
(1)指定了patition,则直接使用;
(2)未指定patition但指定key,通过对key的value进行hash出一个patition;
(3)patition和key都未指定,使用轮询选出一个patition。
DefaultPartitioner class {
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
}
副本(Replication)
同一个partition可能会有多个replication(对应 server.properties 配置中的 default.replication.factor=N)。没有replication的情况下,一旦broker 宕机,其上所有 patition 的数据都不可被消费,同时producer也不能再将数据存于其上的patition。引入replication之后,同一个partition可能会有多个replication,而这时需要在这些replication之间选出一个leader,producer和consumer只与这个leader交互,其它replication作为follower从leader 中复制数据。
消息写入流程
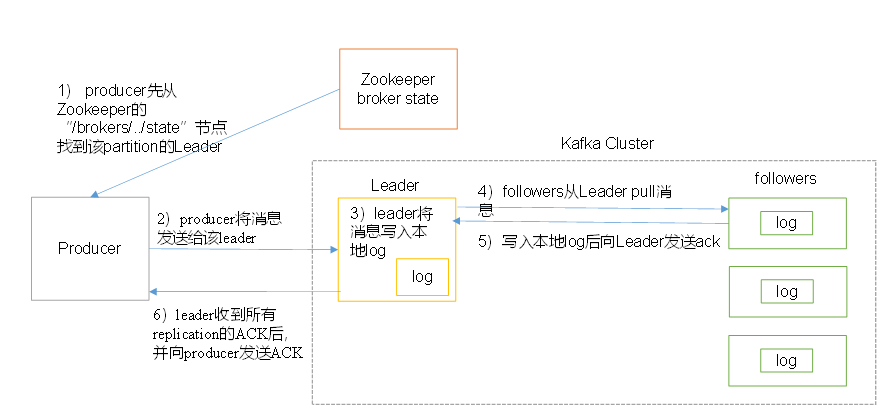
producer写入消息流程如下:
1)producer先从zookeeper的 "/brokers/.../state"节点找到该partition的leader
2)producer将消息发送给该leader
3)leader将消息写入本地log
4)followers从leader pull消息,写入本地log后向leader发送ACK
5)leader收到所有ISR中的replication的ACK后,增加HW(high watermark,最后commit 的offset)并向producer发送ACK
Broker 保存消息
存储方式
物理上把topic分成一个或多个patition(对应 server.properties 中的num.partitions=3配置),每个patition物理上对应一个文件夹(该文件夹存储该patition的所有消息和索引文件),如下:
[hadoop@hadoop100 logs]$ ll
drwxrwxr-x. 2 hadoop hadoop 4096 8月 6 14:37 first-0
drwxrwxr-x. 2 hadoop hadoop 4096 8月 6 14:35 first-1
drwxrwxr-x. 2 hadoop hadoop 4096 8月 6 14:37 first-2
[hadoop@hadoop100 logs]$ cd first-0
[hadoop@hadoop100 first-0]$ ll
-rw-rw-r--. 1 hadoop hadoop 10485760 8月 6 14:33 00000000000000000000.index
-rw-rw-r--. 1 hadoop hadoop 219 8月 6 15:07 00000000000000000000.log
-rw-rw-r--. 1 hadoop hadoop 10485756 8月 6 14:33 00000000000000000000.timeindex
-rw-rw-r--. 1 hadoop hadoop 8 8月 6 14:37 leader-epoch-checkpoint
存储策略
无论消息是否被消费,kafka都会保留所有消息。有两种策略可以删除旧数据:
1)基于时间:log.retention.hours=168
2)基于大小:log.retention.bytes=1073741824
需要注意的是,因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除过期文件与提高 Kafka 性能无关。
Zookeeper存储结构
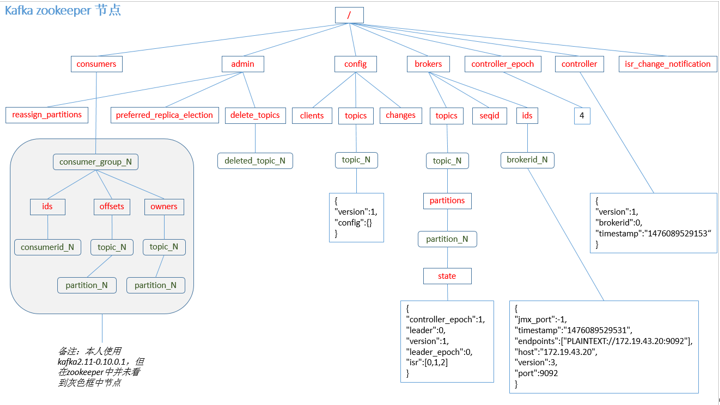
注意:producer不在zk中注册,消费者在zk中注册。
producer 包括一个保存尚未传输到服务器的消息(record)的缓冲区空间池,以及一个负责将这些记录转换为请求并将其传输到集群的后台I/O线程。producer使用后未及时关闭将导致这些资源泄漏。
send()方法是异步的,调用send()方法会将待发送消息(record)添加到缓冲区等待发送,并立即返回。生产者会积攒一批消息后批量发送以提高效率。
acks配置项用来控制请求如何被认为已处理完成。我们指定的“all”设置将导致阻塞全部记录提交,这是最慢但最持久的设置。
如果请求失败,生产者可以自动重试,除非配置了retries配置项为0。启用重试可能导致出现重复消息的可能性(有关消息传递语义的详细信息,请参阅文档)。
Producer 在每个分区维都维护未发送记录的缓冲区。这些缓冲区的大小由batch.size配置项进行配置,增大这个配置的值可以允许一个批次处理更多消息,但需要更多的内存(因为我们通常会为每个活动分区拥有一个这样的缓冲区)。
默认情况下,即使缓冲区中有额外的未使用空间,缓冲数据也是可以立即发送出去的。然而如果你想减少请求的数量可以设置linger.ms为一个大于0的数, 这可以让Producer发送请求之前等待该毫秒数,这样可以有更多消息在一个批次中批量发送。
在上面的代码片段中,可能会在一个请求中发送所有100条记录,因为我们将延迟时间设置为1毫秒。但是,如果我们没有填满缓冲区,这个设置会给请求增加1毫秒的延迟,以等待更多的记录填充到缓冲区。因此在负载大的情况下,无论是否配置linger.ms,消息都是通过批处理发送的;将linger.ms的值设置为大于0的值的意义在于,在没有处于最大负载的情况下可以有效减少请求数量, 代价是增加一点点延迟。
配置项buffer.memory 用来控制Producer用于缓冲区的可用内存总量。如果消息发送到服务器的速度大于缓冲区耗尽的速度,当缓冲区空间耗尽时,其他消息的发送将被阻塞,阻塞时间的阈值由max.block决定。之后,它会抛出一个TimeoutException异常。
配置项 key.serializer 和 value.serializer 用来配置键值对象的序列化类, 对于简单的字符串或字节类型,可以使用Kafka自带的ByteArraySerializer或StringSerializer。
从Kafka 0.11这个版本开始,KafkaProducer支持另外两种模式:幂等Producer和事务Producer。幂等Producer加强了卡夫卡的交付语义,从至少一次交付(at least once delivery)加强为准确地一次交付(exactly once delivery), 幂等Producer的消息无论失败重试多少次都不会导致数据重复统计。而事务Producer是以原子操作将消息发送到多个分区(和主题!),即这些操作要么同时成功, 要么同时失败!.
若要启用等幂性(idempotence),则 enable.idempotence配置必须设置为true。此时retries配置值将默认为Integer.MAX_VALUE, 而acks配置默认为all。使用幂等性Producer在API上没有变化,因此不需要修改现有应用程序。
一旦启用了幂等性(idempotence),建议不要配置重试(retries)参数,因为它默认值为Integer.MAX_VALUE。另外,如果send(ProducerRecord)方法在进行无限次重试之后仍然返回错误(例如消息在缓冲区中过期),那么建议关闭Producer并检查最后生成的消息的内容,以确保没有重复消息。最后,生产者只能保证在单个会话中发送的消息的幂等性。
过时的Producer API
一些公司可能因为历史原因, 仍然在使用旧的(过时的)API.
pom.xml
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.10.0.1</version>
</dependency>简单代码示例
BasicConfigurator.configure();
Properties properties = new Properties();
properties.put("metadata.broker.list", "hadoop000:9092");
properties.put("request.required.acks", "1");
properties.put("serializer.class", "kafka.serializer.StringEncoder");
Producer<Integer, String> producer = new Producer<>(new ProducerConfig(properties));
KeyedMessage<Integer, String> message = new KeyedMessage<>("t1", "hello world");
producer.send(message);过时的生产者API不支持幂等性和事务.
复杂代码示例
自定义调度器代码
package com.niit.kafka.producer.newapi;
/**
* @Author: deLucia
* @Date: 2021/10/7
* @Version: 1.0
* @Description:
* 使用更多配置项的生产者
* 启动自定义分区: 不管有多少分区,只写到分区0
* 先开启消费者, 运行程序, 并测试 tail -F my-topic-3-0/00000000000000000000.log
*/
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
public class CustomPartitioner implements Partitioner {
@Override
public void configure(Map<String, ?> configs) {
}
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 控制分区
return 0;
}
@Override
public void close() {
}
}
生产者代码
/**
* @Author: deLucia
* @Date: 2021/10/6
* @Version: 1.0
* @Description: old api from kafka_2.11
*/
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import org.apache.kafka.common.utils.Utils;
import org.apache.log4j.BasicConfigurator;
import java.util.Properties;
public class DetailedProducerExample {
@SuppressWarnings("deprecation")
public static void main(String[] args) {
BasicConfigurator.configure();
Properties props = new Properties();
// Kafka服务端的主机名和端口号
props.put("metadata.broker.list", "hadoop100:9092");
// 等待所有副本节点的应答
props.put("request.required.acks", "0");
// 序列化类
props.put("serializer.class", "kafka.serializer.StringEncoder");
// partitioner
// - default: kafka.producer.DefaultPartitioner
// - hash(key)%partitionNum)
// - custom partitioner:
// - send to partition #0
props.put("partitioner.class", CustomPartitioner.class.getName());
Producer<String, String> producer = new Producer<>(new ProducerConfig(props));
for (int i = 0; i < 10; i++) {
KeyedMessage<String, String> message = new KeyedMessage<>("my-topic-3", "hello world " + i);
producer.send(message);
Utils.sleep(1000);
}
producer.close();
}
}Producer 配置参数
同步发送结合自定义调度器
自定义调度器
package com.niit.kafka.producer.newapi;
/**
* @Author: deLucia
* @Date: 2021/10/7
* @Version: 1.0
* @Description:
* 使用更多配置项的生产者
* 启动自定义分区: 不管有多少分区,只写到分区0
* 先开启消费者, 运行程序, 并测试 tail -F my-topic-3-0/00000000000000000000.log
*/
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
public class CustomPartitioner implements Partitioner {
@Override
public void configure(Map<String, ?> configs) {
}
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 控制分区
return 0;
}
@Override
public void close() {
}
}
生产者代码
package com.niit.kafka.producer.newapi;
/**
* @Author: deLucia
* @Date: 2020/8/22
* @Version: 1.0
* @Description: new Producer APi from kafka_client
* STEPS:
create topic t1 with multiple partitioners.
bin/kafka-console-consumer.sh --bootstrap-server hadoop000:9092,hadoop000:9093,hadoop000:9094 --topic t1
$ tail -F t1-0/0000000000000000000X.log
*/
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import org.apache.log4j.BasicConfigurator;
import org.apache.kafka.clients.producer.internals.DefaultPartitioner;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class DetailedProducerExample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
BasicConfigurator.configure();
// Create producer properties
Properties properties = new Properties();
// - kafka clustger
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop000:9092,hadoop000:9093,hadoop000:9094");
// - ack level
// no wait = 0
// wait leader = 1
// wait all = -1
properties.setProperty(ProducerConfig.ACKS_CONFIG, "all");
// - retries
properties.setProperty(ProducerConfig.RETRIES_CONFIG, "0");
// - batch.size
properties.setProperty(ProducerConfig.BATCH_SIZE_CONFIG, "16384");
// - linger.ms
properties.setProperty(ProducerConfig.LINGER_MS_CONFIG, "1");
// - buffer.memory
properties.setProperty(ProducerConfig.BUFFER_MEMORY_CONFIG, "33554421");
// - KV serializer classes
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// - Defauilt Partitioner
// default: org.apache.kafka.clients.producer.internals.DefaultPartitioner;
// - 如果指定分区则使用指定的分区
// - 如果没有指定分区但是指定key, 则计算哈希取模得到分区索引
// - 如果没有指定分区也没有指定key, 则采用轮询算法
// - Custom Partitioner
// - 总是发送到分区0上
properties.setProperty(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class.getName());
// Create the Producer
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
// send data
for (int i = 0; i < 10; i++) {
// Create a Producer Record
ProducerRecord<String, String> record = new ProducerRecord<>("my-topic-3", String.valueOf(i));
RecordMetadata recordMetadata = producer.send(record).get();// 同步发送
int partition = recordMetadata.partition();
long offset = recordMetadata.offset();
System.out.println("Partition[" + partition + "], offset[" + offset + "], message[" + i + "]");
// producer.send(record); // 异步发送
producer.flush();
}
producer.close();
}
}异步发送结合回调
这里回调采用使用匿名内部类的方式:
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class ProducerWithCallBackExample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
final Logger logger = LoggerFactory.getLogger(ProducerWithCallBackExample.class);
//Create producer properties
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop000:9092");
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//Create the Producer
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
//Send 10 messages
for (int i = 0; i < 10; i++) {
//Create a Producer Record
ProducerRecord<String, String> record = new ProducerRecord<String, String>("my-topic", "id_" + i, "Hello Kakfka" + i);
logger.info("Key :" + "id_" + i); //Log the Key
//send data
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null) {
logger.info("Received new metadata. \n" +
"Topic:" + recordMetadata.topic() + "\n" +
"Pratition:" + recordMetadata.partition() + "\n" +
"Offeset:" + recordMetadata.offset() + "\n" +
"Timestamp" + recordMetadata.timestamp());
} else {
logger.error("Error while producing", e);
}
}
});
producer.flush();
}
producer.close();
}
}事务Producer
客户端能与之交互的Broker上安装Kafka版本要至少0.10.0。有些代理服务器可能不支持某些客户端特性。例如,事务api需要Kafka版本至少0.11.0。当使用的代码和实际版本不符合时将收到
unsupportedVersionException异常。
要使用事务Producer API,必须设置 transactional.id 属性, 设置transactional.id可用来在单个Producer的实例跨多个会话时方便进行事务的恢复(回滚操作)。只要 transactional.id 设置好后,幂等性所依赖的所有相关的Producer配置就会自动生效。此外,事务中包含的主题应该做好持久性设置。特别是replication.factor 应该至少是3,主题的min.insync.replicas 应设为2。最后,为了从端到端实现事务保证,还必须将使用者的事务隔离级别配置为只读取提交(read only committed messages)。
所有新的事务api都是阻塞的,一旦失败就会抛出异常。下面的示例说明了如何使用新的api。它与上面的示例类似,只是100条消息都是属于一个事务(要么同时成功,要么同时失败)。
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("transactional.id", "my-transactional-id");
Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());
// 初始化事务
producer.initTransactions();
try {
// 事务开始
producer.beginTransaction();
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// We can't recover from these exceptions, so our only option is to close the producer and exit.
producer.close();
} catch (KafkaException e) {
// For all other exceptions, just abort the transaction and try again.
// 退出事务
producer.abortTransaction();
}
// 关闭生产者
producer.close();正如示例中所暗示的,每个生产者只能有一个开放的事务。所有在beginTransaction()和commitTransaction()调用之间发送的消息都是单个事务的一部分。如果指定了事务id,则生产者发送的所有消息必须是事务的一部分。
事务Producer通过抛出异常来传递错误状态。因此不需要为producer.send()指定回调,也不需要调用producer.send().get()来返回将来执行的结果. 如果任何producer.send()或事务调用在事务期间遇到不可恢复的错误,就会抛出KafkaException。有关从事务发送中检测错误的详细信息,请参阅文档 send(ProducerRecord) 。通过在接收到KafkaException时调用producer.abortTransaction(),从而保证事务性。
Views: 474