
什么是 Spark
Apache Spark是一个快速通用的集群计算系统,是一种与Hadoop相似的开源集群计算环境,但是Spark在某些工作负载方面表现得更加优越。它提供了Java. Scala. Python和R的高级API,以及一个支持通用的执行图计算的优化引擎。它还支持一组丰富的高级工具,包括使用SQL进行结构化数据处理的Spark SQL. 用于机器学习的MLlib. 用于图处理的GraphX,以及用于实时流处理的Spark Streaming。
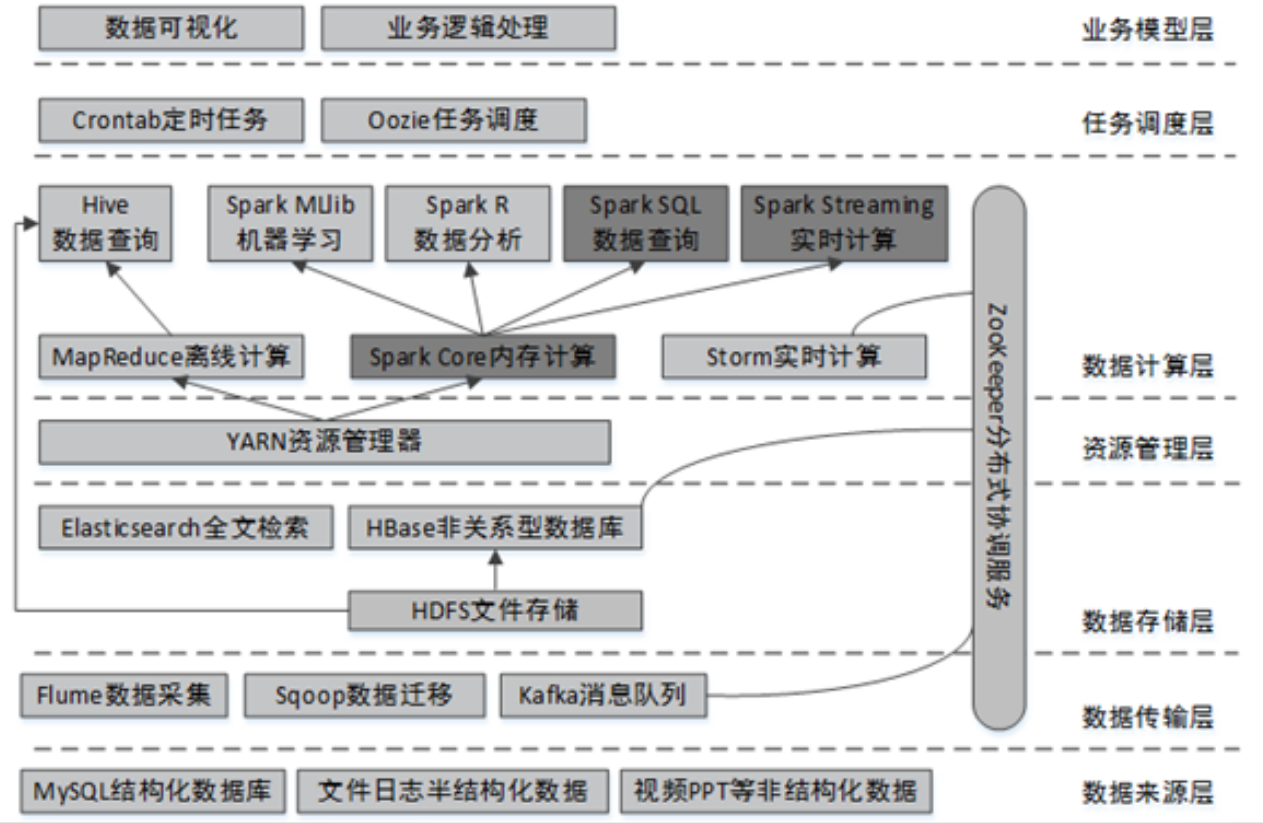
Spark的主要特点:
-
快速
与MapReduce相比,Spark可以支持包括Map和Reduce在内的更多操作,这些操作相互连接形成一个有向无环图(Directed Acyclic Graph,简称DAG),各个操作的中间数据则会被保存在内存中。因此处理速度比MapReduce更加快。Spark通过使用先进的DAG调度器. 查询优化器和物理执行引擎,从而能够高性能的实现批处理和流数据处理。
-
易用
Spark可以使用Java. Scala. Python. R和SQL快速编写应用程序。
Spark提供了超过80个高级算子(关于算子,在第3章将详细讲解),使用这些算子可以轻松构建并行应用程序,并且可以从Scala. Python. R和SQL的Shell中交互式地使用它们。 -
通用
Spark拥有一系列库,包括SQL和DataFrame. 用于机器学习的MLlib. 用于图计算的GraphX. 用于实时计算的Spark Streaming。可以在同一个应用程序中无缝地组合这些库。
-
到处运行
Spark可以使用独立集群模式运行(使用自带的独立资源调度器,称为Standalone模式),也可以运行在Amazon EC2. Hadoop YARN. Mesos(Apache下的一个开源分布式资源管理框架). Kubernetes之上,并且可以访问HDFS. Cassandra. HBase. Hive等数百个数据源中的数据。
Spark主要组件
Spark是由多个组件构成的软件栈,Spark 的核心(Spark Core)是一个对由很多计算任务组成的. 运行在多个工作机器或者一个计算集群上的应用进行调度. 分发以及监控的计算引擎。
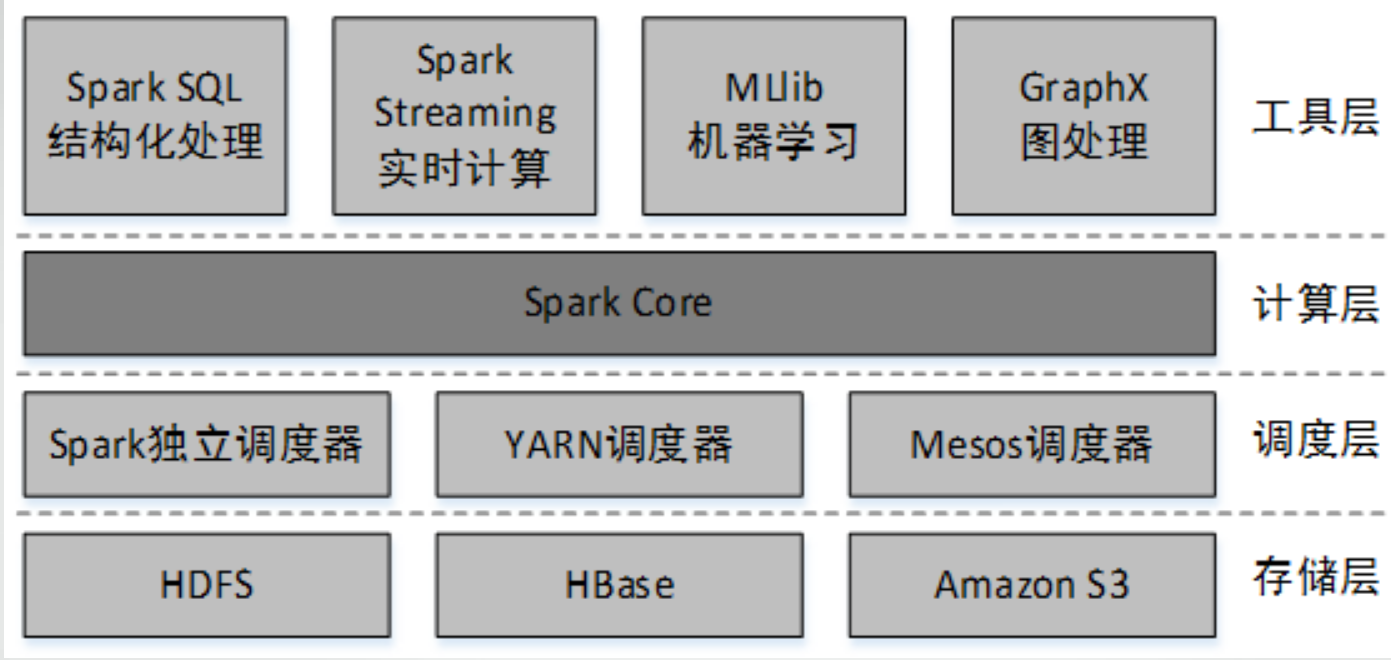
Spark运行时架构
Spark有多种运行模式,可以运行在一台机器上,称为本地(单机)模式;也可以以YARN或Mesos作为底层资源调度系统以分布式的方式在集群中运行,称为Spark On YARN模式;还可以使用Spark自带的资源调度系统,称为Spark Standalone模式。
本地模式通过多线程模拟分布式计算,通常用于对应用程序的简单测试。本地模式在提交应用程序后,将会在本地生成一个名为“SparkSubmit”的进程,该进程既负责程序的提交又负责任务的分配. 执行和监控等。
YARN集群架构
在学习Spark集群架构之前,先需要了解YARN集群的架构。YARN集群总体上是经典的主/从(Master/Slave)架构,主要由ResourceManager. NodeManager. ApplicationMaster和Container等几个组件构成。
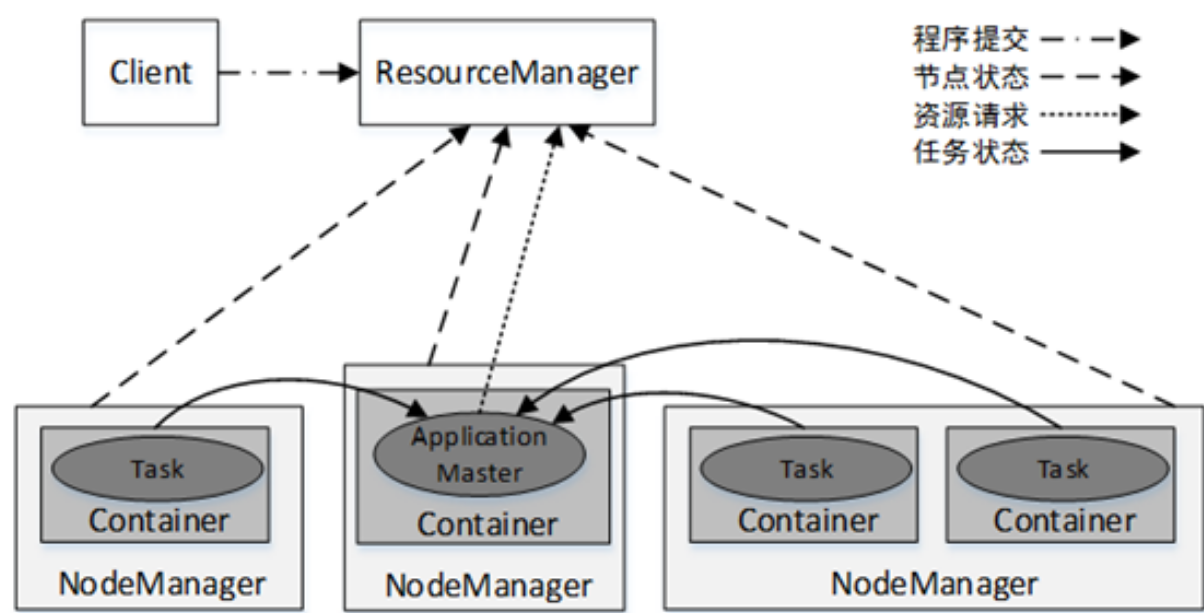
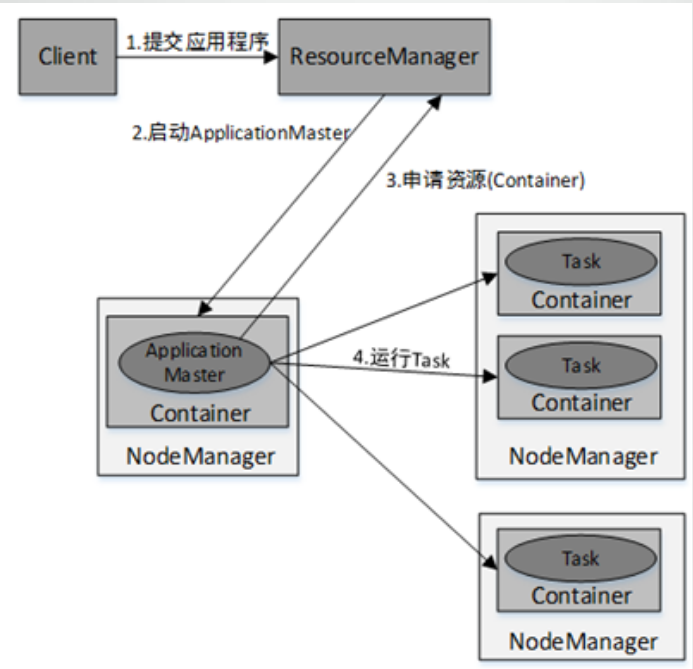
YARN集群中应用程序的执行流程:
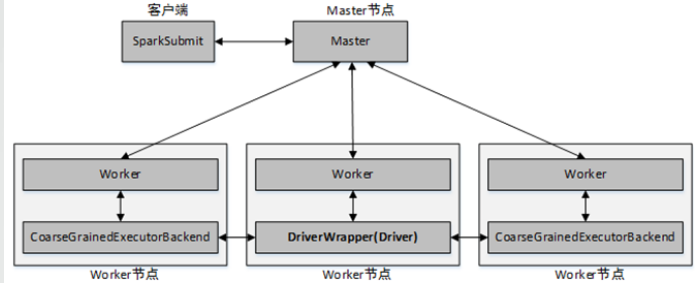
Spark Standalone架构
Spark Standalone模式为经典的Master/Slave架构,资源调度是Spark自己实现的。在Standalone模式中,根据应用程序提交的方式不同,Driver(主控进程)在集群中的位置也有所不同。应用程序的提交方式主要有两种:client和cluster,默认是client。
当提交方式为client时,运行架构:

当提交方式为cluster时,运行架构(注意Driver的位置):
Spark On YARN架构
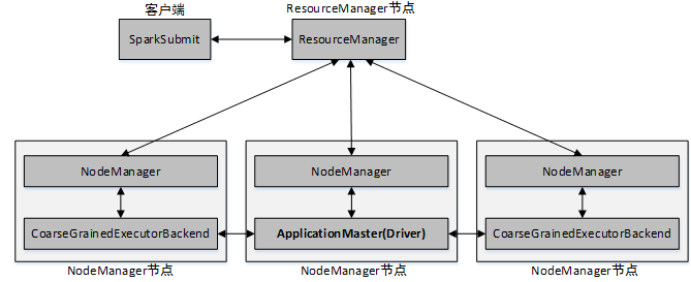
Spark On YARN模式,遵循YARN的官方规范,YARN只负责资源的管理和调度,运行哪种应用程序由用户自己实现,因此可能在YARN上同时运行MapReduce程序和Spark程序,YARN很好的对每一个程序实现了资源的隔离。这使得Spark与MapReduce可以运行于同一个集群中,共享集群存储资源与计算资源。Spark On YARN 模式与Standalone模式一样,也分为client和cluster两种提交方式。
client提交方式架构:
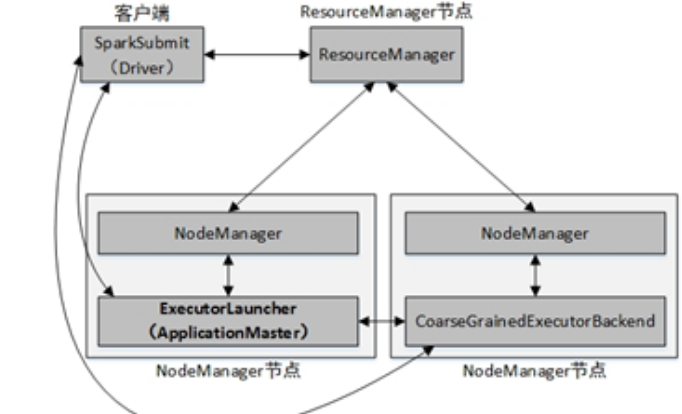
cluster提交方式架构:
Spark On Yarn 环境搭建
Spark Standalone 集群搭建
Spark Standalone模式的搭建需要在集群的每个节点都安装Spark:
- 下载解压安装包
访问Spark官网http://spark.apache.org/downloads.html下载预编译的Spark安装包,选择Spark版本为2.4.0,包类型为“Pre-built for Apache Hadoop 2.7 and later”(Hadoop2.7及之后版本的预编译版本)。
$ tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz -C /opt/pkg/- 修改配置文件
修改slaves文件:$ cp slaves.template slaves $ vi slaves改为以下内容:
hadoop100修改spark-env.sh文件:
$ cp spark-env.sh.template spark-env.sh $ vi spark-env.sh改为以下内容:
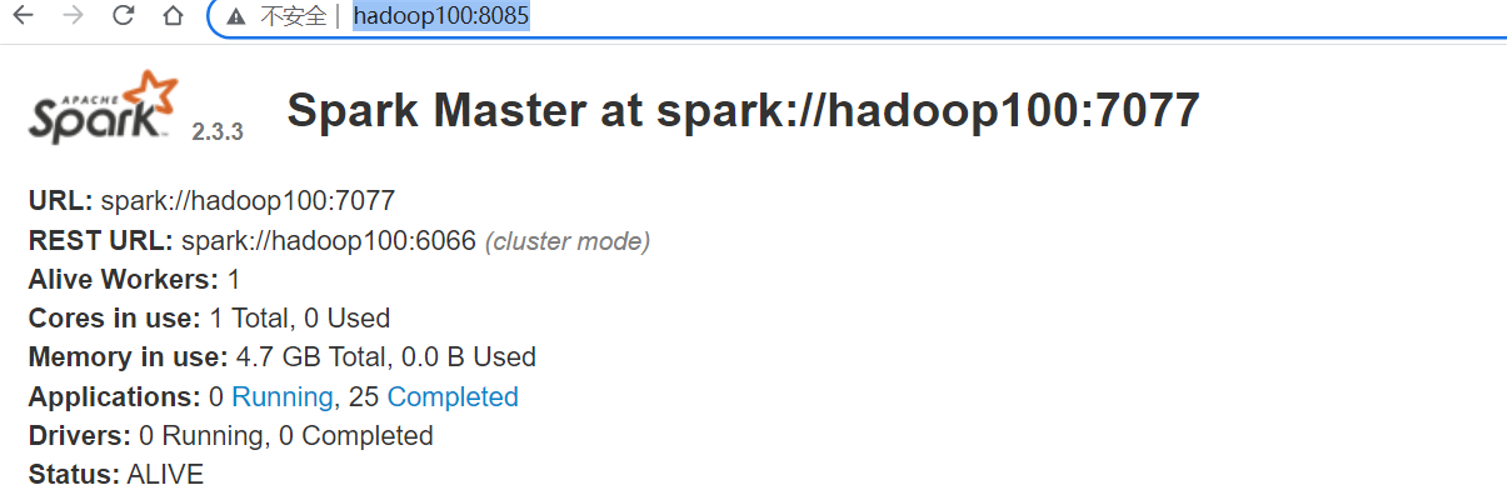
export JAVA_HOME=/opt/pkg/java export SPARK_MASTER_HOST=hadoop100 export SPARK_MASTER_PORT=7077 export SPARK_MASTER_WEBUI_PORT=8085
spark master web ui 默认端口为8080,当系统有其它程序(hadoop3.x版本的集群中的有的节点会启动jetty,用的就是8080端口)也在使用该接口时,启动master时就会报错,为了避免端口冲突,我们也可以自行设置端口号为8085
启动默认的log4j日志配置
cp log4j.properties.template log4j.properties- 启动Spark集群
在主节点(hadoop100)执行,启动Spark集群:
$ sbin/start-all.sh使用jps查看启动进程,进程分别为:Master. Worker说明启动成功。
访问网址http://hadoop100:8085,查看Spark的WebUI:
Spark提供了一个客户端应用程序提交工具spark-submit,使用该工具可以将编写好的Spark应用程序提交到Spark集群:
$ bin/spark-submit [options] <app jar> [app options]说明
[options]:表示传递给spark-submit的控制参数;<app jar>:表示提交的程序jar包(或Python脚本文件)所在位置;[app options]:表示jar程序需要传递的参数,例如main()方法中需要传递的参数。
例如:
本地模式,使用2个cpu核心:
本地模式不会提交给Spark Master,因此在Spark Master WebUI 看不到提交的任务信息。
$ bin/spark-submit --master local[2] --deploy-mode client --class org.apache.spark.examples.SparkPi ./examples/jars/spark-examples_2.11-2.4.8.jar在Standalone模式(Spark集群使用Spark自带的资源协调服务)下,将Spark自带的求圆周率的程序提交到集群:
$ bin/spark-submit \
--master spark://centos01:7077 \
--class org.apache.spark.examples.SparkPi \
./examples/jars/spark-examples_2.11-2.4.0.jar说明:
--master参数指定了Master节点的连接地址。该参数根据不同的Spark集群模式,其取值也有所不同:
在输出的日志中间可以找到Pi的估算结果:
Pi is roughly 3.138195690978455另外在Spark任务运行时,从Spark Master UI界面可以在Running Applications选项下查看当前运行的Spark任务的状态,任务执行完毕后, 在Completed Applications选项中可以找到执行完成的Spark任务,点击Application ID可以查看任务详情和日志信息,
| 取值 | 描述 |
|---|---|
| spark://host:port | Standalone模式下的Master节点的连接地址,默认端口为7077 |
| yarn | 连接到YARN集群。若YARN中没有指定ResourceManager的启动地址,则需要在ResourceManager所在的节点上进行应用程序的提交,否则将因找不到ResourceManager而提交失败 |
| local | 运行本地模式,使用1个CPU核心 |
| local[N] | 运行本地模式,使用N个CPU核心。例如,local[2]表示使用2个CPU核心运行程序 |
| local[*] | 运行本地模式,尽可能使用最多的CPU核心 |
spark-submit还提供了一些控制资源使用和运行时环境的参数:
| 参数 | 描述 |
|---|---|
| --master | Master节点的连接地址。取值为spark://host:port. mesos://host:port. yarn. k8s://https://host:port或local (默认为 local[*]) |
| --deploy-mode | 提交方式。取值为“client”或“cluster”。“client”表示在本地客户端启动Driver程序,“cluster”表示在集群内部的工作节点上启动Driver程序。默认为“client” |
| --class | 应用程序的主类(Java或Scala程序) |
| --name | 应用程序名称,会在Spark Web UI中显示 |
| --jars | 应用依赖的第三方的jar包列表,以逗号分隔 |
| --files | 需要放到应用工作目录中的文件列表,以逗号分隔。此参数一般用来放需要分发到各节点的数据文件 |
| --conf | 设置任意的SparkConf配置属性。格式为“属性名=属性值” |
| --properties-file | 加载外部包含键值对的属性文件。如果不指定,默认将读取Spark安装目录下的conf/spark-defaults.conf文件中的配置 |
| --driver-memory | Driver进程使用的内存量。例如“512M”或“1G”,单位不区分大小写。默认为1024M |
| --executor-memory | 每个Executor进程所使用的内存量。例如“512M”或“1G”,单位不区分大小写。默认为1G |
| --driver-cores | 每个Executor进程所使用的内存量。例如“512M”或“1G”,单位不区分大小写。默认为1G |
| --executor-cores | 每个Executor进程所使用的CPU核心数,默认为1 |
| --num-executors | Executor进程数量,默认为2。如果开启动态分配,则初始Executor的数量至少是此参数配置的数量。需要注意的是,此参数仅在Spark On YARN模式中使用 |
例如,在Standalone模式下,将Spark自带的求圆周率的程序提交到集群,并且设置Driver进程使用内存为512M,每个Executor进程使用内存为1G,每个Executor进程所使用的CPU核心数为1,提交方式为cluster(即Driver进程运行在集群的工作节点中),执行命令:
$ bin/spark-submit \
--master spark://centos01:7077 \
--deploy-mode cluster \
--class org.apache.spark.examples.SparkPi \
--driver-memory 512m \
--executor-memory 1g \
--executor-cores 1 \
./examples/jars/spark-examples_2.11-2.4.0.jar说明:
查看UI界面可以得知每个Worker的CPU核心数,注意设置的executor-cores不能超过这个数量。
Spark带有交互式的Shell,可在Spark Shell中直接编写Spark任务,然后提交到集群与分布式数据进行交互,并且可以立即查看输出结果。
Spark Standalone模式启动Spark Shell终端:
$ bin/spark-shell --master spark://centos01:7077
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://hadoop100:4040
Spark context available as 'sc' (master = spark://centos01:7077, app id = app-20210727162737-0001).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.0:
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_281)
Type in expressions to have them evaluated.
Type :help for more information.
scala>启动完成后,访问Spark Master WebUI 查看运行的Spark应用程序:
退出Spark Shell:(注意命令前面以冒号:开头,可以简写为:q)
scala>:quitSpark On YARN 集群模式搭建
Spark On YARN模式下Spark Shell的启动与Standalone模式所不同的是:--master的参数值为yarn。例如以下启动命令:
$ bin/spark-shell --master yarn如果之前没有配置 Spark On YARN 集群模式的环境的话,这一步铁定会遇到异常的,当我们解决这些异常之后, Spark On YARN 集群模式也就自然搭建完成了。
Spark On YARN模式启动Shell出现的问题
Unable to load native-hadoop library for your platform
原因 这个只是警告,而不是错误,提示缺少对Hadoop的lib的引用。在环境变量里面进行设置即可。如果没有配置的话则会使用内建的Java类来实现,导致执行效率上有一定影响。
解决方法
编辑 /etc/profile,添加:
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native/:$LD_LIBRARY_PATH使环境变量生效
source /etc/profile也可以在需要执行的脚本中前面加上
#!/bin/bash export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native/
either HADOOP_CONF_DIR or YARN_CONF_DIR must be set
解决方法
编辑spark-env.sh, 增加
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopNeither spark.yarn.jars nor spark.yarn.archive is set
$ hdfs dfs -mkdir -p /user/hadoop/spark/jars
$ hdfs dfs -put /opt/pkg/spark/jars/* /user/hadoop/spark/jars
$ hdfs dfs -chmod -R 755 /user/hadoop/spark/jarsspark-defaults.conf中写入 (注意后面的/*别漏加)
spark.yarn.jars hdfs://hadoop100:8020/user/hadoop/spark/jars/*说明:
hadoop100:8020 对应HDFS的NameNode的主机名和端口号(对于hadoop2.x的NameNode端口默认是9000,对于hadoop3.x的NameNode端口默认是8020)
最后重新启动Spark,然后运行Spark Shell:
$ bin/spark-shell --master yarn
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://centos01:4040
Spark context available as 'sc' (master = yarn, app id = application_1627371733487_0005).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.8
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_281)
Type in expressions to have them evaluated.
Type :help for more information.
这就是正常运行的样子。
Container Killed on request.
出现这个错误说明Yarn给Spark任务的内存分配过小,Yarn最终直接将Container的进程杀掉了。
解决方法:
在Hadoop的配置文件yarn-site.xml中加入以下内容即可:
<!--关闭物理内存检查-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--关闭虚拟内存检查-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>修改完毕后,将此文件分发到所有Yarn节点,重启Yarn集群。
Spark 三种提交模式测试
下面的测试环境使用三台虚拟机,系统是CentOS7_x64. 主机名分别使hadoop100. hadoop101. Hadoop102,安装了Java JDK8和hadoop3.1.4,Spark 2.4.8 (使用scala2.11编译的) built for Hadoop 2.7.3(用的hadoop的32位的库,因此有些兼容问题),其中Spark的活动master在hadoop100,备用master在hadoop101,worker节点是hadoop101和hadoop102。YARN的ResourceManager节点在hadoop101。
虚拟机环境介绍完了,下面编写一些脚本,使用官方提供的估算Pi值的程序,分别测试Local(本地). Standalone(提交给Spark集群)以及Spark on YARN(提交给YARN集群)这三种提交模式,除了Local提交模式之外,根据Driver的的部署方式还分为Client模式部署以及Cluster模式部署两种部署方法。
本地客户端提交:
仅使用当前节点计算,默认使用一个CPU核心。
由于客户端和Driver在一个进程,结果直接显示在控制台。
Local[2]表示使用2个核心,Local[*]表示使用尽可能多的核心
#!/bin/bash
/opt/pkg/spark/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local \
--name pi-local \
/opt/pkg/spark/examples/jars/spark-examples_2.11-2.4.8.jar \
100Standalone-Client部署模式:
提交任务使用spark自带的资源管理机制
计算任务交给Spark配置的工作节点(工作节点配置在slaves中).
Drive和客户端在一个进程,直接在控制台输出结果
#!/bin/bash
# spark预编译的hadoop版本是32位的和虚拟机里的不兼容
# 因此需要指定hadoop的本地库
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
/opt/pkg/spark/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop100:7077 \
--total-executor-cores 2 \
--name pi-cluster-client \
/opt/pkg/spark/examples/jars/spark-examples_2.11-2.4.8.jar \
100提交Python编写的Spark任务到Spark集群(虚拟机中的python版本为2.75)
这里使用的是Standalone-Client模式
#!/bin/bash
# Run a Python application on a Spark standalone-client mode
# spark2.4.8预编译的hadoop版本是32位的和虚拟机里的不兼容
# 因此需要指定hadoop的本地库
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
/opt/pkg/spark/bin/spark-submit \
--master spark://hadoop100:7077 \
/opt/pkg/spark/examples/src/main/python/pi.py \
100Standalone-Cluster提交,使用2个CPU核心
Standalone提交任务使用spark集群自带的资源管理机制
cluster部署模式:Master选择一个Workder节点(slaves.sh中配置)运行driver进程
注意这种提交方式要求应用程序使用的jar包和文件需要同步到所有worker节点(或放在HDFS上)
pi的计算结果可以访问Storm WebUI在driver的stdout日志中查找
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
/opt/pkg/spark/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop100:6066 \
--deploy-mode cluster \
--total-executor-cores 2 \
--name pi-cluster-cluster \
/opt/pkg/spark/examples/jars/spark-examples_2.11-2.4.8.jar \
100带监督模式的Standalone-Cluster部署
Cluster部署有个好处就是可以开启监督模式(supervise)
开启监督运行模式后当任务失败后可以自动重启
#!/bin/bath
# spark2.4.8预编译的hadoop版本是32位的和虚拟机里的不兼容
# 因此需要指定hadoop的本地库
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
/opt/pkg/spark/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop100:6066 \
--deploy-mode cluster \
# --supervise 失败时自动重启driver
--supervise \
--total-executor-cores 2 \
--name pi-cluster-cluster \
/opt/pkg/spark/examples/jars/spark-examples_2.11-2.4.8.jar \
100spark以client方式提交时,port应该设置为7077;以cluster方式提交时,port设置为6066,因为这种方式提交时,是以rest api方式提交application。
YARN-Client部署模式:
客户端运行driver,任务提交到YARN集群进行调度. 使用YARN集群的工作节点进行计算和(和slaves的配置无关)。可以在YARN的可视化界面(默认端口8088)查看任务执行情况,得到pi的计算结果再发送给Driver在控制台显示
#!/bin/bash
# spark预编译的hadoop版本是32位的和虚拟机里的不兼容
# 因此需要指定hadoop的本地库
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
/opt/pkg/spark/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--total-executor-cores 2 \
--name pi-yarn-yarn \
/opt/pkg/spark/examples/jars/spark-examples_2.11-2.4.8.jar \
100YARN-cluster部署模式
客户端将任务交给YARN集群进行调度
使用YARN集群中的工作节点和spark中的slaves.sh配置无关
driver运行在YARN中的某个NM节点上
可以在YARN的可视化界面(默认端口8088)查看任务执行情况
结果在Application的stdout日志中查看(需提前启动JobHsotry Server)
或者使用yarn logs --applicationId <applicationId>查看
#!/bin/bash
# YARN-cluster部署模式:
# spark预编译的hadoop版本是32位的和虚拟机里的不兼容
# 因此需要指定hadoop的本地库
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
/opt/pkg/spark/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--total-executor-cores 2 \
--name pi-yarn-yarn \
/opt/pkg/spark/examples/jars/spark-examples_2.11-2.4.8.jar \
100Spark Shell的使用
Spark Shell的使用也有三种模式
-
本地(单机)模式下启动Spark Shell
即不加
--master参数,直接使用bin/spark-shell命令启动 Spark Shell,在本地模式下,所有操作任务只是在本地,也就是当前节点运行,而不会分发到整个集群。 -
Spark Standalone模式下启动Spark Shell
使用任意Spark节点进入Spark安装目录,执行以下命令,自动Spark Shell客户端:
$ bin/spark-shell --master spark://hadoop100:7077说明:
--master指定Master节点的访问地址,centos01为Master所在节点主机名,7077为Master默认端口。
在Spark Shell启动过程日志中可以看出,有个Spark的上下文变量叫做sc,这个变量可以在Spark Shell中直接使用,它也是Spark应用程序的入口,负责于Spark集群进行交互。
启动完成后可以在 http://centos01:8080/ 查看运行的Spark应用程序。
- Spark on YARN 模式下启动Spark Shell
前提,需要启动Hadoop的HDFS文件系统和Yarn的相关进程,并完成Spark on YARN 模式的Spark环境搭建。启动命令如下:
$ bin/spark-shell --master yarnSpark项目创建
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.delucia</groupId>
<artifactId>ScalaSparkProject</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.4.8</spark.version>
<hadoop.version>3.1.4</hadoop.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.scala-tools/maven-scala-plugin -->
<dependency>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.8</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<version>2.5.1</version>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>将src/main和src/test下面的java文件夹改为scala:

cn.delucia.spark.rdd.LogAnalysis
package cn.delucia.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.util.matching.Regex
/**
* 从日志中抽取 32位UUID类型的ID 并进行计数, 倒序排序
* Spark RDD 程序 - 打jar包上传到集群 Spark on YARN 模式
* 注意运行前检查Spark集群中资源是否足够:
*
* 注意查看集群服务器中的spark目录下jars里面的jar包如果有很多是中间有_2.11或_2.12
* 则表示是scala 2.11 或者 2.12版本编译的,所以当前项目的scala版本也要一样修改。
*
* spark deploy mode 的client和cluster的区别
* 一般来说,如果提交任务的节点(即Master)和Worker集群在同一个网络内,此时client mode比较合适。
* 如果提交任务的节点和Worker集群相隔比较远,就会采用cluster mode来最小化Driver和Executor之间的网络
* 延迟。
*/
object LogAnalysis {
// CLI Arguments: /flume/logs/22-04-29/11/56/20 /output/result
def main(args: Array[String]): Unit = {
if (args.length < 2) {
println("Arguments must have both input-path and output-path")
System.exit(1)
}
val conf = new SparkConf().setAppName("LogAnalysisCluster")
// Spark on Yarn 必须放到虚拟机运行
// 可以先本地使用 local 模式测试
conf.setMaster("local")
// 测试OK后再注释掉
// Spark on Yarn 模式不须设置 Master
// 覆盖输出路径
conf.set("spark.hadoop.validateOutputSpecs", "false")
val sc = new SparkContext(conf)
// hdfs://hadoop100:8020/flume/logs/22-04-18/*/*/*/*.log
val lines: RDD[String] = sc.textFile("hdfs://hadoop100:8020" + args(0))
def mapFuction(line: String): String = {
val r = "[0-9a-z]{32}".r
val matches: Iterator[Regex.Match] = r.findAllMatchIn(line)
matches.mkString
}
val ids = lines.map(mapFuction).filter(_.nonEmpty)
val pairs: RDD[(String, Int)] = ids.map((_, 1))
val results = pairs.reduceByKey(_ + _).sortBy(_._2, ascending = false)
// (id,count)
//results.saveAsTextFile("hdfs://hadoop100:8020/" + args(1))
val finalResult = results.map(x => (x._1 + "\t" + x._2))
finalResult.foreach(println)
finalResult.saveAsTextFile("hdfs://hadoop100:8020/" + args(1))
sc.stop()
}
}
脚本编写
/opt/bin/project exec-mapred-task.sh
#!/bin/bash
input_path=$(cat /tmp/project-mapred-input-path.txt)
#执行MapReduce程序
dataformat=<code>date +%y-%m-%d
#echo "/opt/pkg/hadoop/bin/hadoop jar /opt/data/log.jar com.niit.log.LogJob $input_path /output/result/$dataformat"
#/opt/pkg/hadoop/bin/hadoop jar /opt/data/log.jar com.niit.mr.LogAnalysisJob $input_path /output/result/$dataformat
#执行Spark程序
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HADOOP_HOME/lib/native
/opt/pkg/spark/bin/spark-submit --master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
--class cn.delucia.spark.rdd.LogAnalysis \
/opt/data/log.jar \
$input_path /output/result/$dataformat
/opt/pkg/hadoop/bin/hdfs dfs -cat /output/result/$dataformat/part-* > /tmp/project_mr_result.txt
echo "======== Analysis Result ========"
echo $(cat /tmp/project_mr_result.txt)最后进行联调测试。
Views: 376