
需求分析
编写Storm拓扑实现可靠计算网站当日PV和UV
重点:
- 去重计算模式
- 实现可靠处理
电商常用指标之PV、UV、VV、独立IP
- PV(访问量):Page View, 即页面浏览量或点击量,用户每次访问即被计算一次。
- UV(独立访客):Unique Visitor, 访问您网站的一台电脑客户端为一个访客。00:00-24:00内相同的客户端只会被计算一次。
- VV即Visit View,访客访问的次数,用以记录所有访客一天内访问量多少次网站。
- IP(独立IP):指独立IP数。00:00-24:00内相同IP地址之被计算一次。
如果我们要统计一个网站当日有多少实际用户访问,使用UV也就是独立用户作为统计量有什么好处?它比独立IP的统计更加准确吗?
比如你早上8点使用PC访问了某商城的两个页面,下午2点又使用手机访问了这个商城网站的3个页面, 那么对于这个商城网站, 当日的PV、UV、VV、IP各项指标该如何计算呢?
PV为5, PV指浏览量,因此PV指等于上午浏览的2个页面和下午浏览的3个页面之和;
UV为1, UV指独立访客数,因此一天内同一访客的多次访问只计为1个UV;
VV为2, VV指访客的访问次数,上午和下午分别有一次访问行为,因此VV为2
IP为2, IP为独立IP数,由于PC和手机访问时的IP不同,因此独立IP数为2.
可见IP是一个反映网络虚拟地址对象的概念,UV是一个反映实际使用者的概念,每个UV相对于每个IP更加准确地对应一个实际的浏览者。
方案设计
综上所述:使用UV作为统计量,可以更加准确的了解单位时间内实际上有多少个访问者来到了相应的页面。
用Cookie携带的SessionID分析UV值:当客户端第一次访问某个网站服务器的时候,网站服务器会给这个客户端的电脑发出一个Cookie,通常放在这个客户端电脑的C盘当中。在这个Cookie中会分配一个独一无二的编号,这其中会记录一些访问服务器的信息,如访问时间,访问了哪些页面等等。当你下次再访问这个服务器的时候,服务器就可以直接从你的电脑中找到上一次放进去的Cookie文件,并且对其进行一些更新,但那个独一无二的编号是不会变的。
如果把sessionID 放入Set集合实现自动去重,再通过Set.size() 获得UV。该方案在单线程和单JVM下没有问题。高并发情况的多线程情况不适用。
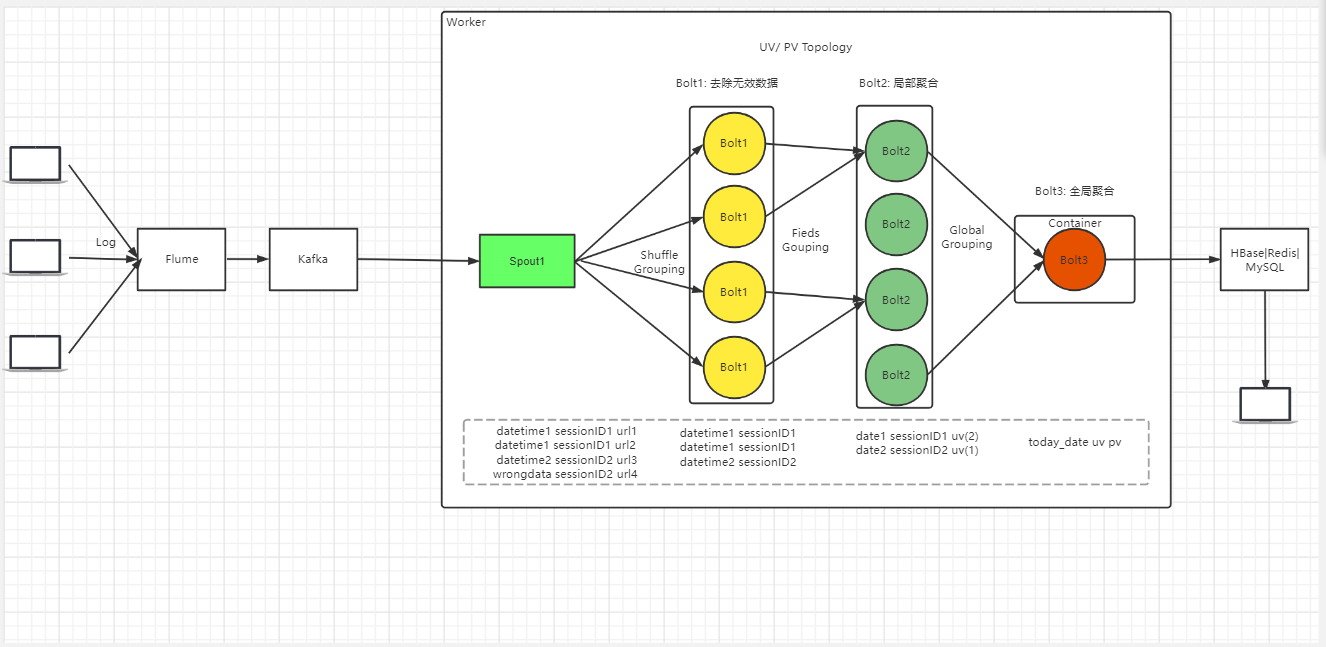
推荐的方案:编写Storm拓扑, Spout获取外部服务器日志然后再通过shuffleGrouping发给多个下级bolt进行数据清洗, 清洗后的数据通过fieldGrouping 进行多线程局部汇总得到,下级blot进行单线程保存sessionID和count数到Map,下一级blot3进行Map遍历,可以得到:Pv、UV、访问深度(每个session_id 的浏览数)
创建IDEA项目(基于Maven)
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.delucia</groupId>
<artifactId>uv-with-reliability</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>2.1.0</version>
<scope>compile</scope>
</dependency>
</dependencies>
</project>项目结构
代码编写
创建工具类cn.delucia.storm.utils.SocketClientUtil
package cn.delucia.storm.utils;
import java.io.OutputStream;
import java.lang.management.ManagementFactory;
import java.net.InetAddress;
import java.net.Socket;
import java.net.UnknownHostException;
/**
* @Author: deLucia
* @Date: 2021/9/29
* @Version: 1.0
* @Description: 工具类
*/
public class SocketClientUtil {
/**
* 是否启用send方法向Socket Server发送信息
*/
public static boolean ENABLE = true;
public static final String HOST = "localhost";
public static final int PORT = 9876;
private SocketClientUtil() {
}
private static String getHostname() {
try {
return InetAddress.getLocalHost().getHostName();
} catch (UnknownHostException e) {
e.printStackTrace();
}
return null;
}
/**
* 返回进程pid
*/
private static String getPID() {
String info = ManagementFactory.getRuntimeMXBean().getName();
return info.split("@")[0];
}
/**
* 线程信息
*/
private static String getTID() {
return Thread.currentThread().getName();
}
//对象信息
private static String getOID(Object obj) {
String cname = obj.getClass().getSimpleName();
int hash = obj.hashCode();
return cname + "@" + hash;
}
public static String info(Object obj, String msg) {
return getHostname() + ", " + getPID() + ", " + getTID() + ", " + getOID(obj) + ", " + msg;
}
/**
* 向远端发送sock消息
* 远端需要先开启nc进行监听:
* windows: nc -l localhost -L -p 9876
* linux: nc -l localhost -k -p 9876
*/
public static void send(Object obj, String msg) {
if (!ENABLE) {
return;
}
String info = info(obj, msg);
try (Socket sock = new Socket(HOST, PORT); OutputStream os = sock.getOutputStream()) {
os.write((info + "\r\n").getBytes());
os.flush();
} catch (Exception e) {
e.printStackTrace();
}
}
}
创建类cn.delucia.storm.log.LogTopology
package cn.delucia.storm.log;
import cn.delucia.storm.utils.SocketClientUtil;
import com.google.common.collect.ImmutableList;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
/**
* @author Delucia
*/
public class LogTopology {
public static final String HOST = "hadoop000";
public static final Integer ZK_SERVER_PORT = 2181;
public static final String SPOUT1_ID = LogMockSpout.class.getSimpleName();
public static final String BOLT1_ID = LogCheckBolt.class.getSimpleName();
public static final String BOLT2_ID = LogCountBolt.class.getSimpleName();
public static final String BOLT3_ID = LogGlobalSumBolt.class.getSimpleName();
public static void main(String[] args) throws Exception {
// 构造拓扑 DAG(有向无环图)
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(SPOUT1_ID, new LogMockSpout(), 1);
builder.setBolt(BOLT1_ID, new LogCheckBolt(), 4).shuffleGrouping(SPOUT1_ID);
builder.setBolt(BOLT2_ID, new LogCountBolt(), 4).fieldsGrouping(BOLT1_ID,
new Fields("date", "sid"));
// 单线程全局汇总
builder.setBolt(BOLT3_ID, new LogGlobalSumBolt(), 1).globalGrouping(BOLT2_ID);
// Storm相关配置
Config conf = new Config();
// TOPOLOGY_DEBUG: ON 日志会详细记录所有发射的数据
conf.setDebug(false);
// Executor number for event loggers
conf.setNumEventLoggers(0);
// Executor number for ackers
conf.setNumAckers(1);
// number of workers
conf.setNumWorkers(1);
// transfer queue between workers
conf.put(Config.TOPOLOGY_TRANSFER_BUFFER_SIZE, 64);
// reveicer queue for each executor
conf.put(Config.TOPOLOGY_EXECUTOR_RECEIVE_BUFFER_SIZE, 16384);
if (args.length > 0 ) {
SocketClientUtil.ENABLE = false;
conf.put(Config.STORM_ZOOKEEPER_SERVERS, ImmutableList.of(HOST));
conf.put(Config.STORM_ZOOKEEPER_PORT, ZK_SERVER_PORT);
conf.put(Config.NIMBUS_SEEDS, ImmutableList.of(HOST));
conf.put(Config.NIMBUS_THRIFT_PORT, 16627);
String jarLocation = ".\\target\\parallelisim-1.0-SNAPSHOT.jar";
System.setProperty("storm.jar", jarLocation);
// 使用 StormSubmitter 提交本地构建的jar包
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(LogTopology.class.getSimpleName(), conf, builder.createTopology());
}
}
}创建类cn.delucia.storm.log.LogMockSpout
package cn.delucia.storm.log;
import cn.delucia.storm.utils.SocketClientUtil;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @Author: deLucia
* @Date: 2021/9/28
* @Version: 1.0
* @Description: 统计当日日志中的PV和UV指标
* PV: Page View 每次访问技术一次
* UV: Unique View 相同用户无论访问多少次都只计数1次
* 如何判断是否为相同用户:
* - IP 用户可能更换设备,或者使用VPN工具, 因此根据IP的统计可能不准确
* - Cookie(SessionID) 一般使用cookie判断
*/
public class LogMockSpout extends BaseRichSpout {
/**
* Mock Data
* 注意这里伪造的日期需要有当天的日期,否则最终统计的PV和UV结果都为 0
* 假设今天是 2021年10月2日。
* 2022年的日期因为晚于今天, 因此是无效数据, 需要重试3次
*/
private final String[] dates = {"2021-10-02 08:40:50", "2022-10-02 18:40:50", "2022-10-02 19:40:50", "2021-10-02 20:40:50"};
private final String[] sids = {"user100", "user101", "user102", "user103"};
private final String[] urls = {"https://cn.delucia/a.html", "https://cn.delucia/b.html", "https://cn.delucia/c.html", "http://cn.delucia/d.html"};
/**
* Spout发射的tuple数量
*/
private static final Integer EMMIT_TUPLE_NUMBER = 30;
/**
* tuple处理失败后进行重试的次数
*/
private Integer retryTimes = 0;
/**
* 允许的最大重试次数
*/
private static final Integer MAX_RETRY_TIMES = 3;
private Integer count = 0;
/**
* 缓存所有发送的消息, 消息发射后移除
*/
private ConcurrentHashMap<Object, String> cachedMessages;
/**
* 用于发射tuple到下游
*/
private transient SpoutOutputCollector collector;
/**
* 用于生产随机数
*/
private Random rand;
/**
* 自定义线程池 - 用于延迟发送需要重试的数据
*/
private transient ThreadPoolExecutor executor;
/**
* 每个线程初始化时调用
*
* @param conf
* @param context
* @param collector
*/
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
this.cachedMessages = new ConcurrentHashMap<>();
this.rand = new Random();
// 自定义线程池 - 用于执行重试任务
int corePoolSize = 2;
int maximumPoolSize = 4;
long keepAliveTime = 10;
TimeUnit unit = TimeUnit.SECONDS;
BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<>(3);
ThreadFactory threadFactory = new NameThreadFactory();
RejectedExecutionHandler handler = new IgnorePolicy();
executor = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler);
executor.prestartAllCoreThreads(); // 预启动所有核心线程
}
@Override
public void nextTuple() {
if (count >= EMMIT_TUPLE_NUMBER) {
return;
}
int k = rand.nextInt(4);
int l = rand.nextInt(4);
int m = rand.nextInt(4);
String line = dates[k] + "\t" + sids[l] + "\t" + urls[m];
String msg = ">> Emit Tuple[\"line\"]: " + line;
System.err.println(msg);
SocketClientUtil.send(this, msg);
Long time = System.currentTimeMillis();
this.collector.emit(new Values(line), time);
cachedMessages.put(time, line);
Utils.sleep(500);
count++;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
@Override
public void ack(Object msgId) {
cachedMessages.remove(msgId);
}
@Override
public void fail(Object msgId) {
cachedMessages.forEach((id, message) -> {
if (msgId.equals(id)) {
cachedMessages.put(id, message);
retryTimes += 1;
// 重试
if (retryTimes <= MAX_RETRY_TIMES) {
// 同步改异步
// collector.emit(new Values(message), msgId);
RetryTask retryTask = new RetryTask(collector, message, msgId, retryTimes);
executor.execute(retryTask);
} else {
// 超过最大重试次数, 放弃
retryTimes = 0;
cachedMessages.remove(msgId);
}
}
});
}
class NameThreadFactory implements ThreadFactory {
private final AtomicInteger mThreadNum = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r, "my-thread-" + mThreadNum.getAndIncrement());
// String msg = "Start Thread[" + t.getName() + "] will retry in 30 secs, max retry times is " + MAX_RETRY_TIMES + ".";
// System.err.println(msg);
// SocketClientUtil.send(this, msg);
return t;
}
}
static class RetryTask implements Runnable {
private final SpoutOutputCollector collector;
private final String messageBody;
private final Object messageId;
private final Integer retryTimes;
private final Random rand;
public RetryTask(SpoutOutputCollector collector, String name, Object msgId, Integer retryTimes) {
this.collector = collector;
this.messageBody = name;
this.messageId = msgId;
this.retryTimes = retryTimes;
this.rand = new Random();
}
@Override
public void run() {
// 30秒内进行重试
Utils.sleep(rand.nextInt(30000));
collector.emit(new Values(messageBody), messageId);
String msg = ">> Replay: " + retryTimes + " times: " + messageBody;
System.err.println(msg);
SocketClientUtil.send(this, msg);
}
@Override
public String toString() {
return "Task: " + messageBody;
}
}
public static class IgnorePolicy implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
log(r, e);
}
private void log(Runnable r, ThreadPoolExecutor e) {
String msg = r.toString() + " rejected";
System.err.println(msg);
SocketClientUtil.send(this, msg);
}
}
}创建类cn.delucia.storm.log.LogCheckBolt
package cn.delucia.storm.log;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Map;
/**
* @Author: deLucia
* @Date: 2021/9/28
* @Version: 1.0
* @Description: 检查日志的格式是否符合要求
*/
public class LogCheckBolt extends BaseRichBolt {
private static final long serialVersionUID = 1L;
OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String line = input.getStringByField("line");
if (line == null || line.isEmpty()) {
this.collector.fail(input);
return;
}
String date = line.split("\t")[0];
String sid = line.split("\t")[1];
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
try {
Date d = sdf.parse(date);
if (d.after(new Date())) {
this.collector.fail(input);
return;
}
date = sdf.format(d);
this.collector.emit(input, new Values(date, sid));
this.collector.ack(input);
} catch (ParseException e) {
e.printStackTrace();
// 日期格式不正确
this.collector.fail(input);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("date", "sid"));
}
}创建类cn.delucia.storm.log.LogCountBolt
package cn.delucia.storm.log;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.HashMap;
import java.util.Map;
/**
* @Author: deLucia
* @Date: 2021/9/28
* @Version: 1.0
* @Description: 对相同的sessionID进行聚合计数
*/
public class LogCountBolt extends BaseRichBolt {
OutputCollector collector;
// <session_id>, <count>
Map<String, Long> map = new HashMap<>();
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String date = input.getStringByField("date");
String ip = input.getStringByField("sid");
String key = date + "_" + ip;
Long count = 0L;
try {
count = map.get(key);
if (count == null) {
count = 0L;
}
count++;
map.put(key, count);
this.collector.emit(input, new Values(date + "_" + ip, count));
this.collector.ack(input);
} catch (Exception e) {
e.printStackTrace();
System.err.println(LogCountBolt.class.getSimpleName() + " failed, date: " + date + ", sid: " + ip + ", count: " + count);
this.collector.fail(input);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("date_sid", "count"));
}
}创建类cn.delucia.storm.log.LogGlobalSumBolt
package cn.delucia.storm.log;
import cn.delucia.storm.utils.SocketClientUtil;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
/**
* @Author: deLucia
* @Date: 2021/9/28
* @Version: 1.0
* @Description: 全局聚合 - 只统计当日的 pv 和 uv
*/
public class LogGlobalSumBolt extends BaseRichBolt {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
private static final long serialVersionUID = 1L;
transient OutputCollector collector;
Map<String, Long> map = new HashMap<>();
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
int pv = 0;
int uv = 0;
String dateIp = input.getStringByField("date_sid");
Long count = input.getLongByField("count");
String currDate = sdf.format(new Date());
collector.ack(input);
try {
Date accessDate = sdf.parse(dateIp.split("_")[0]);
// 访问日期不能晚于今天
map.put(dateIp, count);
String msg = ">> date_sid: " + dateIp + ", pv: " + count;
System.err.println(msg);
SocketClientUtil.send(this, msg);
// 只计算当日的pv和uv
if (!dateIp.split("_")[0].startsWith(currDate)) {
return;
}
if (!map.isEmpty()) {
for (Map.Entry<String, Long> e : map.entrySet()) {
uv++;
pv += e.getValue();
}
}
String result = ">> " + currDate + " pv: " + pv + ", uv: " + uv;
System.err.println(result);
SocketClientUtil.send(this, result);
} catch (ParseException e1) {
e1.printStackTrace();
} finally {
// 到此整棵tuple树处理完成
collector.ack(input);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}本地运行
在本机安装netcat,使用一下命令开启Socket Server:
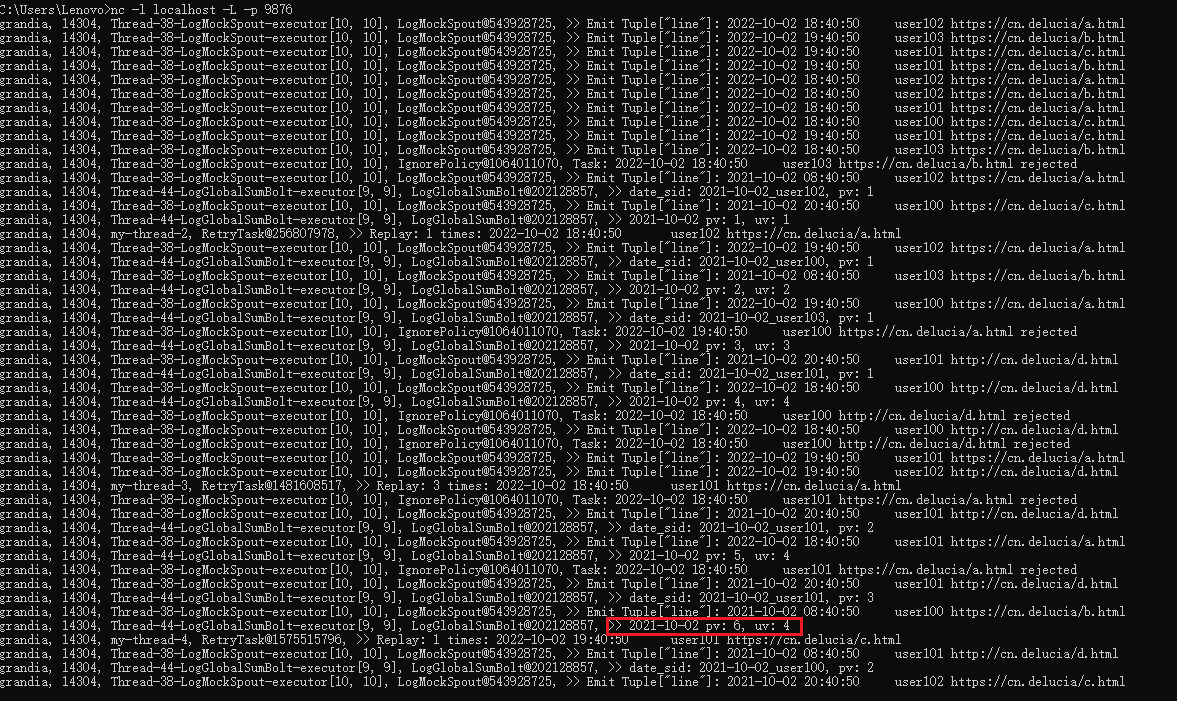
>nc -l localhost -L -p 9876然后本地运行项目(不要带参数),等待Socket Server接收到输出结果,如图所示:
本地提交打好的jar包提交到远程集群运行
首先在pom.xml中将依赖storm-core的scope改为provided
再使用maven package打包,生成的文件在项目根目录下的target文件夹内
修改LogTopology.java中的代码,指定jar包的本地提交路径:
String jarLocation = ".\\target\\parallelisim-1.0-SNAPSHOT.jar";
System.setProperty("storm.jar", jarLocation);然后直接运行项目,即可通过Thrift协议协议将jar包远程提交到集群中的nimbus节点运行。
最后可以在Storm UI界面查看结果。
Views: 329