
IDEA 创建基于Maven的Spark项目
三台虚拟机搭建的集群
启动集成如下:
------------ hadoop100 ------------
26369 Master
2514 QuorumPeerMain
2898 Kafka
29011 SparkSubmit
30643 HRegionServer
3493 JobHistoryServer
3573 NodeManager
3065 NameNode
30476 HMaster
31036 Jps
28927 SparkSubmit
------------ hadoop101 ------------
5153 QuorumPeerMain
5537 Kafka
5905 ResourceManager
6018 NodeManager
104355 Jps
84258 Worker
104039 HRegionServer
5645 DataNode
104140 HMaster
------------ hadoop102 ------------
71683 Worker
5509 Kafka
104804 Jps
5752 SecondaryNameNode
5897 NodeManager
5643 DataNode
5116 QuorumPeerMain
104542 HRegionServer本地环境由于需要打包放到虚拟机运行,因此scala版本需要和虚拟机中编译spark所用的scala的版本一致。如何知道虚拟机中spark是用的什么版本scala编译的呢?可以进入虚拟机的spark-shell查看:
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.8
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_281)可见2.4.8并不是官网所说的使用scala2.12,实际上是2.11
接下来使用IDEA创建一个MAVEN项目,使用scala模板
配置项目名称
配置有效的maven环境
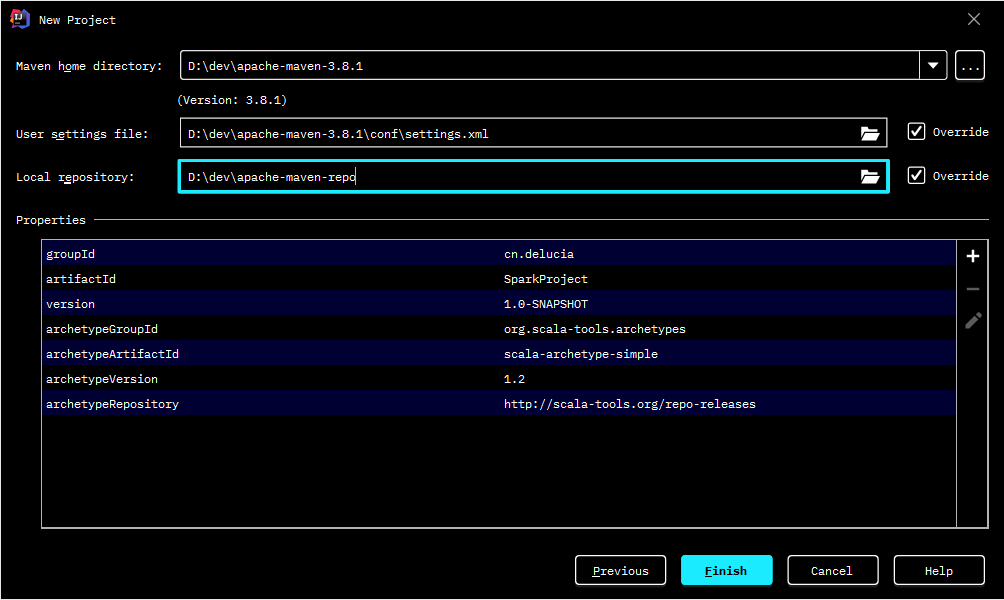
修改pom文件:
- 设置scala的版本,我虚拟机里的Spark是用的scala2.11版本编译的,这里能找到最接近的可用的版本就是2.11.8。
- 添加maven-scala-plugin依赖,使用的是2.11的版本。
- 添加spark-core_2.11, 版本为2.4.8,和虚拟机安装的Spark版本保持一致
- 此外因为下面的示例还要操作hbase,因为又引入了hadoop和hbase相关的一些依赖,其中hadoop-common依赖排除了jackson-databind是因为出现了依赖冲突的问题。
- 为了演示官方示例(蒙特卡洛法求Pi值),引入了spark-sql依赖
最终完整的pom.xml文件内容如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.delucia</groupId>
<artifactId>SparkProject</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.4.8</spark.version>
<hadoop.version>3.1.4</hadoop.version>
<hbase.version>2.2.3</hbase.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
<!--
解决打包错误:Failure to find org.glassfish:javax.el:pom:3.0.1-b08-SNAPSHOT
-->
<exclusions>
<exclusion>
<groupId>org.glassfish</groupId>
<artifactId>javax.el</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.41</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.scala-tools/maven-scala-plugin -->
<dependency>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.8</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<version>2.5.1</version>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>项目右键选择 maven->Reimport 等待依赖下载完成。
你会发现test包下面有一些自动生成的源文件有错误(依赖版本问题),这里直接把报错的文件删除,只保留一个AppTest.scala文件,可以点击测试以下环境,main包下面自动生成的文件也是直接删除即可。:
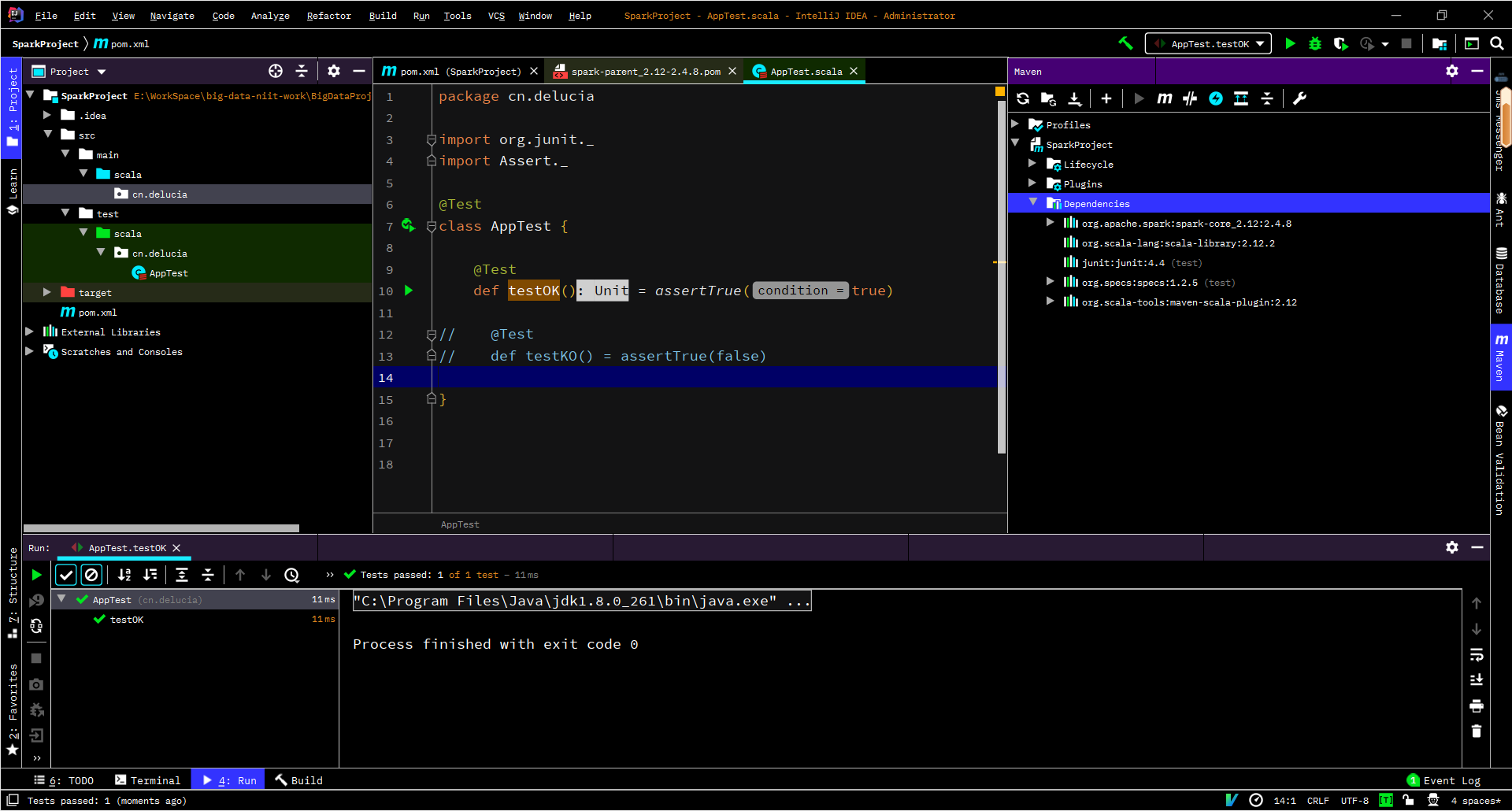
给项目根目录下创建data和output文件夹,最终项目结构:
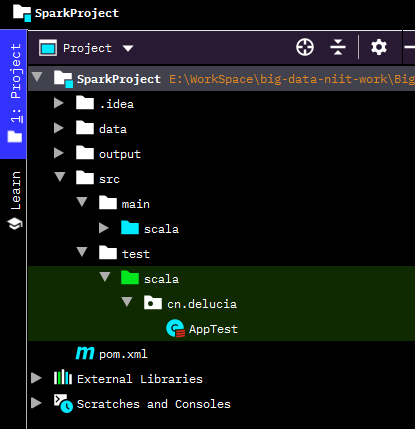
实现单词计数
在data下面创建文本文件words.txt,内容如下
hello hadoop
hello java
scala本地模式运行
package cn.delucia.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Spark RDD 单词计数程序
* Program Args: data\words.txt output\wc
* 注意:需提前删除output\wc文件夹
*/
object WordCountLocal {
def main(args: Array[String]): Unit = {
//创建SparkConf对象
val conf = new SparkConf()
//设置应用程序名称,可以在Spark WebUI中显示
conf.setAppName("WordCountLocal")
//设置集群Master节点访问地址
//conf.setMaster("spark://hadoop100:7077"); //远程-提交到集群(standalone模式)
conf.setMaster("local[2]") // 本地模式 - 2个CPU核心
//创建SparkContext对象,该对象是提交Spark应用程序的入口
val sc = new SparkContext(conf);
//读取指定路径(取程序执行时传入的第一个参数)中的文件内容,生成一个RDD集合
val linesRDD:RDD[String] = sc.textFile(args(0))
//将RDD数据按照空格进行切分并合并为一个新的RDD
val wordsRDD:RDD[String] = linesRDD.flatMap(_.split(" "))
//将RDD中的每个单词和数字1放到一个元组里,即(word,1)
val paresRDD:RDD[(String, Int)] = wordsRDD.map((_,1))
//对单词根据key进行聚合,对相同的key进行value的累加
val wordCountsRDD:RDD[(String, Int)] = paresRDD.reduceByKey(_+_)
//按照单词数量降序排列
val wordCountsSortRDD:RDD[(String, Int)] = wordCountsRDD.sortBy(_._2,false)
//保存结果到指定的路径(取程序执行时传入的第二个参数)
wordCountsSortRDD.saveAsTextFile(args(1))
//停止SparkContext,结束该任务
sc.stop()
}
}直接点击运行,由于是两个核心,结果有两个文件生成
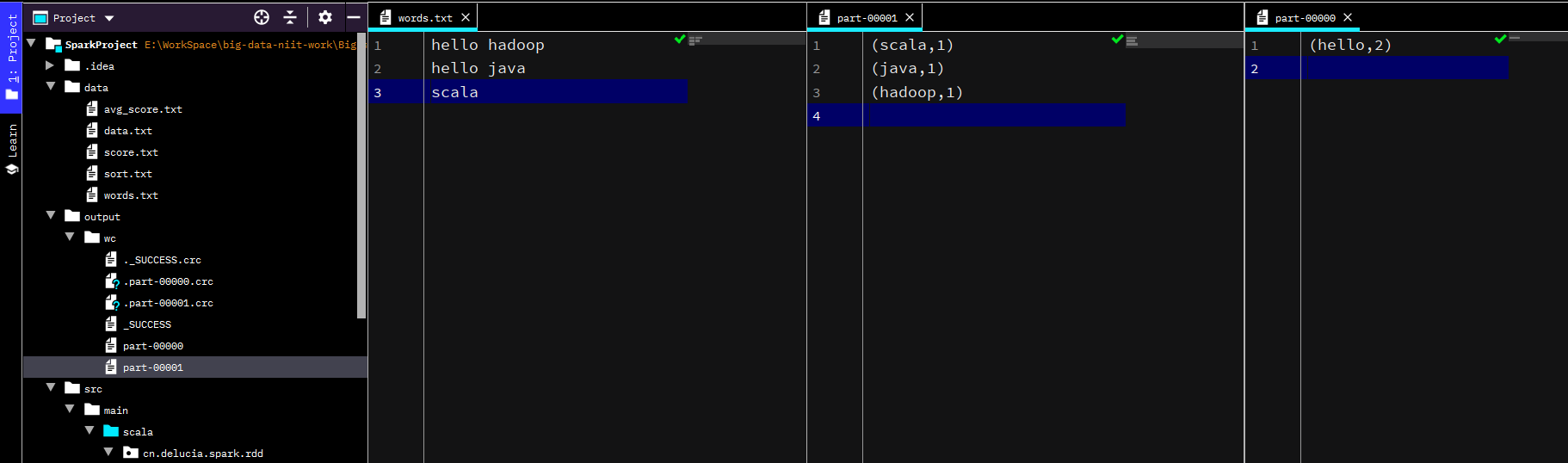
上传到集群运行 - Spark on YARN 模式
前提 集群已经安装好Hadoop集群并运行DFS和YARN
Spark已经配置好Spark on YARN的相关设置
编写程序
package cn.delucia.spark.rdd
import org.apache.spark.{SparkConf, SparkContext}
/**
Spark RDD单词计数程序 - 打jar包上传到集群 Spark on YARN 模式
*/
object WordCountCluster {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WordCountCluster")
conf.setMaster("spark://hadoop100:7077")
val sc = new SparkContext(conf)
sc.textFile(args(0))
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.sortBy(_._2, ascending = false)
.saveAsTextFile(args(1))
sc.stop()
}
}使用maven生命周期插件clean然后install打成jar包上传到集群的/opt/data目录下,将jar包改名位WordCountCluster.jar,进入spark的安装目录执行命令:
bin/spark-submit
--master yarn
--class cn.delucia.spark.rdd.WordCountCluster /opt/data/WordCountCluster.jar hdfs://hadoop100:8020/tmp/words.txt hdfs://hadoop100:8020/tmp/output/wc_cluster即可把任务提交到YARN集群运行,可以去output目录可以查看结果
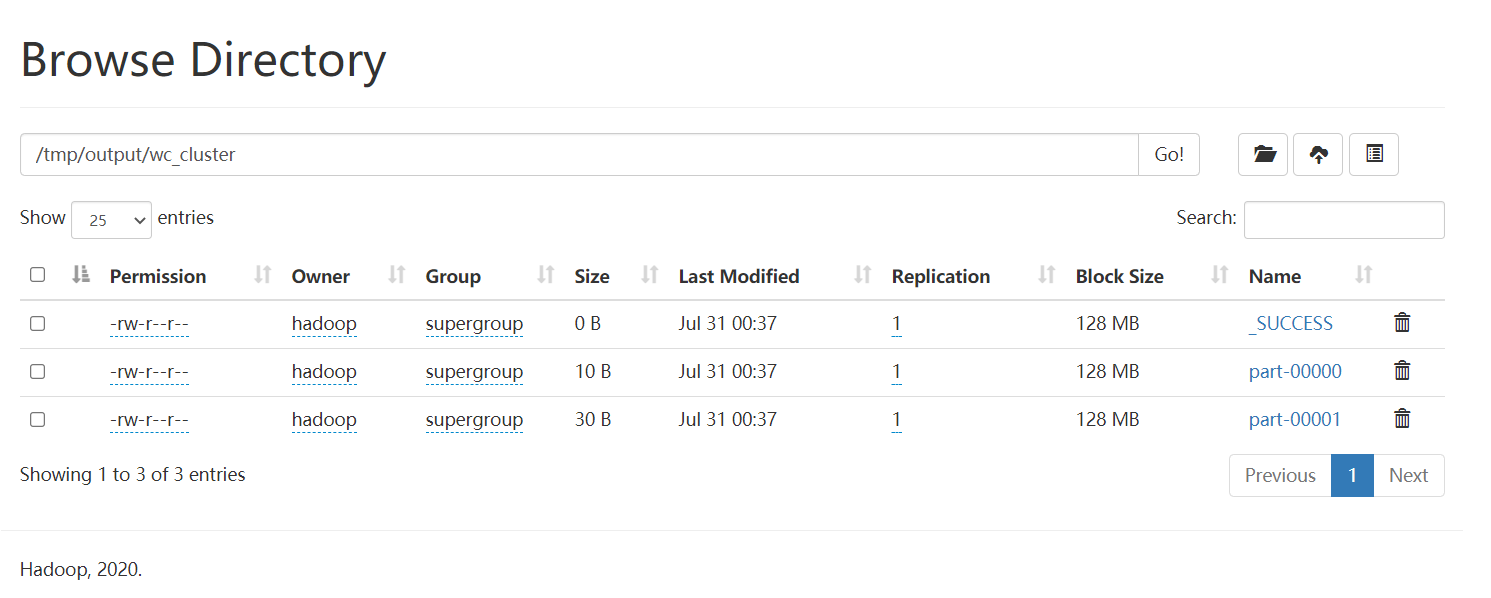
有两个文件生成说明有两个分区,因为设置了2个核心
求平均成绩
data下创建score.txt
Andy,98
Jack,87
Bill,99
Andy,78
Jack,85
Bill,86
Andy,90
Jack,88
Bill,76
Andy,58
Jack,67
Bill,79编写程序:
package cn.delucia.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 求成绩平均分
*/
object AverageScoreLocal {
def main(args: Array[String]): Unit = {
//创建SparkConf对象,存储应用程序的配置信息
val conf = new SparkConf()
//设置应用程序名称,可以在Spark WebUI中显示
conf.setAppName("AverageScore")
//设置集群Master节点访问地址
conf.setMaster("local")
val sc = new SparkContext(conf)
//1. 加载数据
val linesRDD: RDD[String] = sc.textFile("data/avg_score.txt")
//2. 将RDD中的元素转为(key,value)形式,便于后面进行聚合
val tupleRDD: RDD[(String, Int)] = linesRDD.map(line => {
val name = line.split("\t")(0)//姓名
val score = line.split("\t")(1).toInt//成绩
(name, score)
})
//3. 根据姓名进行分组,形成新的RDD
val groupedRDD: RDD[(String, Iterable[Int])] = tupleRDD.groupByKey()
//4. 迭代计算RDD中每个学生的平均分
val resultRDD: RDD[(String, Int)] = groupedRDD.map(line => {
val name = line._1//姓名
val iteratorScore: Iterator[Int] = line._2.iterator//成绩迭代器
var sum = 0//总分
var count = 0//科目数量
//迭代累加所有科目成绩
while (iteratorScore.hasNext) {
val score = iteratorScore.next()
sum += score
count += 1
}
//计算平均分
val averageScore = sum / count
(name, averageScore)//返回(姓名,平均分)形式的元组
})
//保存结果
resultRDD.saveAsTextFile("output/avg_score")
}
}输出结果:
(BETA,45)
(Bill,85)
(Andy,81)
(Jack,81)统计学生最好的三次成绩并倒序排列
package cn.delucia.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Spark分组取TopN程序
*/
object GroupTopNLocal {
def main(args: Array[String]): Unit = {
//创建SparkConf对象,存储应用程序的配置信息
val conf = new SparkConf()
//设置应用程序名称,可以在Spark WebUI中显示
conf.setAppName("RDDGroupTopN")
//设置集群Master节点访问地址,此处为本地模式,使用尽可能多的核心
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
//1. 加载本地数据
val linesRDD: RDD[String] = sc.textFile("data/score.txt")
//2. 将RDD元素转为(String,Int)形式的元组
val tupleRDD:RDD[(String,Int)]=linesRDD.map(line=>{
val name=line.split(",")(0)
val score=line.split(",")(1)
(name,score.toInt)
})
//3. 按照key(姓名)进行分组
val top3=tupleRDD.groupByKey().map(groupedData=>{
val name:String=groupedData._1
//每一组的成绩降序后取前3个
val scoreTop3:List[Int]=groupedData._2
.toList.sortWith(_>_).take(3)
(name,scoreTop3)//返回元组
})
//当使用多核心时,分区排序完就各自并行输出结果了,导致输出内容互相干扰
//这里先调用count,由于count属于Action算子,会触发前面的计算完成
//这样等top3里面的所有分区都计算完毕再输出,可以让输出格式更好
top3.count
//4. 循环打印分组结果
top3.foreach(tuple=>{
println("姓名:"+tuple._1)
val tupleValue=tuple._2.iterator
while (tupleValue.hasNext){
val value=tupleValue.next()
println("成绩:"+value)
}
println("*******************")
})
}
}控制台输出:
姓名:Andy
成绩:98
成绩:90
成绩:78
*******************
姓名:Bill
成绩:99
成绩:86
成绩:79
*******************
姓名:Jack
成绩:88
成绩:87
成绩:85
*******************倒排索引统计每日新增用户
package cn.delucia.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Spark RDD统计每日新增用户
*/
object DayNewUserLocal {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("DayNewUser")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
//1. 构建测试数据
val tupleRDD:RDD[(String,String)] = sc.parallelize(
Array(
("2020-01-01", "user1"),
("2020-01-01", "user2"),
("2020-01-01", "user3"),
("2020-01-02", "user1"),
("2020-01-02", "user2"),
("2020-01-02", "user4"),
("2020-01-03", "user2"),
("2020-01-03", "user5"),
("2020-01-03", "user6")
)
)
//2. 倒排(互换RDD中元组的元素顺序)
val tupleRDD2:RDD[(String,String)] = tupleRDD.map(
line => (line._2, line._1)
)
//3. 将倒排后的RDD按照key分组
val groupedRDD: RDD[(String, Iterable[String])] = tupleRDD2.groupByKey()
//4. 取分组后的每个日期集合中的最小日期,并计数为1 (只有第一次登陆才算做当日新增用户)
val dateRDD:RDD[(String,Int)] = groupedRDD.map(
line => (line._2.min, 1)
)
//5. 计算所有相同key(即日期)的数量
val resultMap: collection.Map[String, Long] = dateRDD.countByKey()
//将结果Map循环打印到控制台
resultMap.foreach(println)
}
}结果:
(2020-01-01,3)
(2020-01-02,1)
(2020-01-03,2)自定义排序规则(二次排序)
先准备数组,data下创建文本文件
2 98
1 99
2 67
3 75
3 88
2 85
1 90
3 100
1 62先根据第一列升序排列,如果相同再根据第二列降序排列
package cn.delucia.spark.rdd
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 二次排序自定义key类
* 先根据名字升序排列,如果名字相同再根据成绩降序排列
* @param first 每一行的第一个字段
* @param second 每一行的第二个字段
*/
class SecondSortKey(val first: Int, val second: Int)
extends Ordered[SecondSortKey] with Serializable {
override def toString: String = first + "->" + second;
/**
* 实现compare()方法
*/
override def compare(that: SecondSortKey): Int = {
//若第一个字段不相等,按照第一个字段升序排列
if (this.first - that.first != 0) {
this.first - that.first
} else { //否则按照第二个字段降序排列
that.second - this.second
}
}
}
/**
* 二次排序运行主类
*/
object SecondSort {
def main(args: Array[String]): Unit = {
//创建SparkConf对象
val conf = new SparkConf()
//设置应用程序名称,可以在Spark WebUI中显示
conf.setAppName("SecondSort")
//设置集群Master节点访问地址,此处为本地模式
conf.setMaster("local")
//创建SparkContext对象,该对象是提交Spark应用程序的入口
val sc = new SparkContext(conf);
//1. 读取指定路径的文件内容,生成一个RDD集合
val lines: RDD[String] = sc.textFile("data\\sort.txt")
//2. 将RDD中的元素转为(SecondSortKey, String)形式的元组
val pair: RDD[(SecondSortKey, String)] = lines.map(line => (
new SecondSortKey(line.split(" ")(0).toInt, line.split(" ")(1).toInt),
line)
)
//3. 按照元组的key(SecondSortKey的实例)进行排序
val pairSort: RDD[(SecondSortKey, String)] = pair.sortByKey()
//取排序后的元组中的第二个值(value值)
//val result: RDD[String] = pairSort.map(line => line._2)
//打印最终结果
pairSort.foreach(line => println(line))
}
}控制台输出结果:
(1->99,1 99)
(1->90,1 90)
(1->62,1 62)
(2->98,2 98)
(2->85,2 85)
(2->67,2 67)
(3->100,3 100)
(3->88,3 88)
(3->75,3 75)读写HBase数据库
HBase是Spark应用程序经常打交道的一个数据源。下面使用Spark程序对其进行读写操作:
使用HBase API向HBase写入数据
package cn.delucia.spark.rdd
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.Put
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.hadoop.hbase.TableName
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.client.ConnectionFactory
/**
* 向HBase表写入数据 - hbase API
*/
object SparkWriteHBase {
def main(args: Array[String]): Unit = {
//创建SparkConf对象,存储应用程序的配置信息
val conf = new SparkConf()
conf.setAppName("SparkWriteHBase")
conf.setMaster("local[*]")
//创建SparkContext对象
val sc = new SparkContext(conf)
//1. 构建需要添加的数据RDD
val initRDD = sc.makeRDD(
Array(
"003,王五,山东,23",
"004,赵六,河北,20"
)
)
//2. 循环RDD的每个分区
initRDD.foreachPartition(partition=> {
//2.1 设置HBase配置信息
val hbaseConf = HBaseConfiguration.create()
//设置ZooKeeper集群地址
hbaseConf.set("hbase.zookeeper.quorum","hadoop100")
//设置ZooKeeper连接端口,默认2181
hbaseConf.set("hbase.zookeeper.property.clientPort", "2181")
//创建数据库连接对象
val conn = ConnectionFactory.createConnection(hbaseConf)
//指定表名
val tableName = TableName.valueOf("student")
//获取需要添加数据的Table对象
val table = conn.getTable(tableName)
//2.2 循环当前分区的每行数据
partition.foreach(line => {
//分割每行数据,获取要添加的每个值
val arr = line.split(",")
val rowkey = arr(0)
val name = arr(1)
val address = arr(2)
val age = arr(3)
//创建Put对象
val put = new Put(Bytes.toBytes(rowkey))
put.addColumn(
Bytes.toBytes("info"),//列族名
Bytes.toBytes("name"),//列名
Bytes.toBytes(name)//列值
)
put.addColumn(
Bytes.toBytes("info"),//列族名
Bytes.toBytes("address"),//列名
Bytes.toBytes(address)) //列值
put.addColumn(
Bytes.toBytes("info"),//列族名
Bytes.toBytes("age"),//列名
Bytes.toBytes(age)) //列值
//执行添加
table.put(put)
})
})
}
}使用Spark API向HBase写入数据
package cn.delucia.spark.rdd
import org.apache.hadoop.hbase.client.Put
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapred.TableOutputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapred.JobConf
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 向HBase表写入数据 使用 Spark API(saveAsHadoopDataset方法)
*/
object SparkWriteHBase2 {
def main(args: Array[String]): Unit = {
//创建SparkConf对象,存储应用程序的配置信息
val conf = new SparkConf()
conf.setAppName("SparkWriteHBase2")
conf.setMaster("local[*]")
//创建SparkContext对象
val sc = new SparkContext(conf)
//1. 设置配置信息
//创建Hadoop JobConf对象
val jobConf = new JobConf()
//设置ZooKeeper集群地址
jobConf.set("hbase.zookeeper.quorum","hadoop100")
//设置ZooKeeper连接端口,默认2181
jobConf.set("hbase.zookeeper.property.clientPort", "2181")
//指定输出格式
jobConf.setOutputFormat(classOf[TableOutputFormat])
//指定表名
jobConf.set(TableOutputFormat.OUTPUT_TABLE,"student")
//2. 构建需要写入的RDD数据
val initRDD = sc.makeRDD(
Array(
"005,王五,山东,23",
"006,赵六,河北,20"
)
)
//将RDD转换为(ImmutableBytesWritable, Put)类型
val resultRDD: RDD[(ImmutableBytesWritable, Put)] = initRDD.map(
_.split(",")
).map(arr => {
val rowkey = arr(0)
val name = arr(1)//姓名
val address = arr(2)//地址
val age = arr(3)//年龄
//创建Put对象
val put = new Put(Bytes.toBytes(rowkey))
put.addColumn(
Bytes.toBytes("info"),//列族
Bytes.toBytes("name"),//列名
Bytes.toBytes(name)//列值
)
put.addColumn(
Bytes.toBytes("info"),//列族
Bytes.toBytes("address"),//列名
Bytes.toBytes(address)) //列值
put.addColumn(
Bytes.toBytes("info"),//列族
Bytes.toBytes("age"),//列名
Bytes.toBytes(age)) //列值
//拼接为元组返回
(new ImmutableBytesWritable, put)
})
//3. 写入数据
resultRDD.saveAsHadoopDataset(jobConf)
sc.stop()
}
}
批量向Hbase写入数据
使用BulkLoader加载HFile数据到HBase:
参考阅读:
https://blog.cloudera.com/how-to-use-hbase-bulk-loading-and-why/
https://www.opencore.com/blog/2016/10/efficient-bulk-load-of-hbase-using-spark/
package cn.delucia.spark.rdd
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.hadoop.hbase._
import org.apache.hadoop.hbase.client.ConnectionFactory
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapred.TableOutputFormat
import org.apache.hadoop.hbase.mapreduce.{HFileOutputFormat2, LoadIncrementalHFiles}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Spark 批量写入数据到HBase(使用BulkLoader加载HFile数据到HBase)
*/
object SparkWriteHBase3 {
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME", "hadoop")
//创建SparkConf对象,存储应用程序的配置信息
val conf = new SparkConf()
conf.setAppName("SparkWriteHBase3")
conf.setMaster("local[*]")
//创建SparkContext对象
val sc = new SparkContext(conf)
//1. 设置HDFS和HBase配置信息
val hadoopConf = new Configuration()
hadoopConf.set("fs.defaultFS", "hdfs://hadoop100:8020")
val fileSystem = FileSystem.get(hadoopConf)
val hbaseConf = HBaseConfiguration.create(hadoopConf)
//设置ZooKeeper集群地址
hbaseConf.set("hbase.zookeeper.quorum", "hadoop100")
//设置ZooKeeper连接端口,默认2181
hbaseConf.set("hbase.zookeeper.property.clientPort", "2181")
//创建数据库连接对象
val conn = ConnectionFactory.createConnection(hbaseConf)
//指定表名
val tableName = TableName.valueOf("student")
//获取需要添加数据的Table对象
val table = conn.getTable(tableName)
//获取操作数据库的Admin对象
val admin = conn.getAdmin()
//2. 添加数据前的判断
//如果HBase表不存在,则创建一个新表
if (!admin.tableExists(tableName)) {
val desc = new HTableDescriptor(tableName)
//表名
val hcd = new HColumnDescriptor("info") //列族
desc.addFamily(hcd)
admin.createTable(desc) //创建表
}
//如果存放HFile文件的HDFS目录已经存在,则删除
if (fileSystem.exists(new Path("hdfs://hadoop100:8020/tmp/hbase"))) {
fileSystem.delete(new Path("hdfs://hadoop100:8020/tmp/hbase"), true)
}
//3. 构建需要添加的RDD数据
//初始数据
val initRDD = sc.makeRDD(
Array(
"rowkey:007,name:王五",
"rowkey:007,address:山东",
"rowkey:007,age:23",
"rowkey:008,name:赵六",
"rowkey:008,address:河北",
"rowkey:008,age:20"
)
)
//数据转换
//转换为(ImmutableBytesWritable, KeyValue)类型的RDD
val resultRDD: RDD[(ImmutableBytesWritable, KeyValue)] = initRDD.map(
_.split(",")
).map(arr => {
val rowkey = arr(0).split(":")(1)
//rowkey
val qualifier = arr(1).split(":")(0)
//列名
val value = arr(1).split(":")(1) //列值
val kv = new KeyValue(
Bytes.toBytes(rowkey),
Bytes.toBytes("info"),
Bytes.toBytes(qualifier),
Bytes.toBytes(value)
)
//构建(ImmutableBytesWritable, KeyValue)类型的元组返回
(new ImmutableBytesWritable(Bytes.toBytes(rowkey)), kv)
})
//4. 写入数据
//在HDFS中生成HFile文件
hbaseConf.set("hbase.mapreduce.hfileoutputformat.table.name",tableName.getNameAsString)
resultRDD.saveAsNewAPIHadoopFile(
"hdfs://hadoop100:8020/tmp/hbase",
classOf[ImmutableBytesWritable], //对应RDD元素中的key
classOf[KeyValue], //对应RDD元素中的value
classOf[HFileOutputFormat2],
hbaseConf
)
//加载HFile文件到HBase
val bulkLoader = new LoadIncrementalHFiles(hbaseConf)
val regionLocator = conn.getRegionLocator(tableName)
bulkLoader.doBulkLoad(
new Path("hdfs://hadoop100:8020/tmp/hbase"), //HFile文件位置
admin, //操作HBase数据库的Admin对象
table, //目标Table对象(包含表名)
regionLocator //RegionLocator对象,用于查看单个HBase表的区域位置信息
)
sc.stop()
}
}读取Hbase数据
前面学了三钟方法向HBase数据库插入数据,并且一共向Hbase的student表写入了6条记录,下面我们写一个程序从HBase中把它们读取出来
package cn.delucia.spark.rdd
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.Result
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.rdd.RDD
/**
* Spark读取HBase表数据
*/
object SparkReadHBase {
def main(args: Array[String]): Unit = {
//创建SparkConf对象,存储应用程序的配置信息
val conf = new SparkConf()
conf.setAppName("SparkReadHBase")
conf.setMaster("local[*]")
//创建SparkContext对象
val sc = new SparkContext(conf)
//1. 设置HBase配置信息
val hbaseConf = HBaseConfiguration.create()
//设置ZooKeeper集群地址
hbaseConf.set("hbase.zookeeper.quorum","hadoop100")
//设置ZooKeeper连接端口,默认2181
hbaseConf.set("hbase.zookeeper.property.clientPort", "2181")
//指定表名
hbaseConf.set(TableInputFormat.INPUT_TABLE, "student")
//2. 读取HBase表数据并转化成RDD
val hbaseRDD: RDD[(ImmutableBytesWritable, Result)] = sc.newAPIHadoopRDD(
hbaseConf,
classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[Result]
)
//3. 输出RDD中的数据到控制台
hbaseRDD.foreach{ case (_ ,result) =>
//获取行键
val key = Bytes.toString(result.getRow)
//通过列族和列名获取列值
val name = Bytes.toString(result.getValue("info".getBytes,"name".getBytes))
val gender = Bytes.toString(result.getValue("info".getBytes,"address".getBytes))
val age = Bytes.toString(result.getValue("info".getBytes,"age".getBytes))
println("行键:"+key+"\t姓名:"+name+"\t地址:"+gender+"\t年龄:"+age)
}
}
}输出
行键:003 姓名:王五 地址:山东 年龄:23
行键:004 姓名:赵六 地址:河北 年龄:20
行键:005 姓名:王五 地址:山东 年龄:23
行键:006 姓名:赵六 地址:河北 年龄:20
行键:007 姓名:王五 地址:山东 年龄:23
行键:008 姓名:赵六 地址:河北 年龄:20解决数据倾斜问题
避免数据倾斜的办法还有很多,比如:
- 对数据进行预处理
- 过滤掉没有意义的数据
- 提高shuffle的并行度,增加分区数量
但这不能解决大量相同key导致的单个分区数据过多的问题
对于存在大量相同的key导致数据集中在某个分区的问题,这里给出一个解决办法:
添加随机前缀进行双重集合:
- 首先给数据添加随机前缀,进行分区内的局部聚合
- 然后去除随机前缀,进行全局聚合
package cn.delucia.spark.rdd
import org.apache.spark.{SparkConf, SparkContext}
import scala.util.Random
/**
* Spark RDD解决数据倾斜案例 - 由于存在大量相同的key导致数据集中在某个分区
* 解决办法:添加随机前缀进行双重集合)
* 1. 首先给数据添加随机前缀,进行分区内的局部聚合
* 2. 然后去除随机前缀,进行全局聚合
*/
object DataLean {
def main(args: Array[String]): Unit = {
//创建Spark配置对象
val conf = new SparkConf();
conf.setAppName("DataLean")
conf.setMaster("local[*]")
//创建SparkContext对象
val sc = new SparkContext(conf)
//1. 读取测试数据
val linesRDD = sc.textFile("data/data.txt")
//2. 统计单词数量
linesRDD
.flatMap(_.split(" "))
.map((_, 1))
.map(t => {
val word = t._1
val random = Random.nextInt(100)//产生0~99的随机数
//单词加入随机数前缀,格式:(前缀_单词,数量)
(random + "_" + word, 1)
})
.reduceByKey(_ + _)//局部聚合
.map(t => {
val word = t._1
val count = t._2
val w = word.split("_")(1)//去除前缀
//单词去除随机数前缀,格式:(单词,数量)
(w, count)
})
.reduceByKey(_ + _)//全局聚合
//输出结果到指定的HDFS目录
.saveAsTextFile("output/data_lean")
}
}
Views: 82