
在微服务架构中,当系统从一个单体应用,被拆分成分布式系统上一个个服务节点后,配置文件也必须跟着迁移(分割)。在系统架构中,配置中心是整个微服务基础架构体系中的一个组件,它的功能看上去并不起眼,无非就是配置的管理和存取,但它是整个微服务架构中不可或缺的一环。
应用程序在启动和运行的时候往往需要读取一些配置信息,配置基本上伴随着应用程序的整个生命周期,应用在启动时通过读取配置来初始化,在运行时根据配置调整行为。同一份程序在不同的环境(开发、测试、生产)、不同的集群(如不同的数据中心)经常需有不同的配置,所以需要有完善的环境、集群配置管理。
Spring Cloud Alibaba Nacos 的一大优势是整合了注册中心、配置中心功能,部署和操作更加直观简单,它简化了架构复杂度,并减轻运维及部署工作。在之前的章节中,我们已经使用 Nacos 作为注册中心,本章节我们将详细介绍 Nacos 配置中心的功能。
目标
在本章中,您将学习:
- Nacos 配置管理
- 配置拉取
- 配置热更新
- 多环境配置共享
- Nacos 集群搭建
快速入门
当微服务部署的实例越来越多,达到数十、数百时,逐个修改微服务配置是一件效率非常低的事情,而且很容易出错。我们需要一种统一配置管理方案,可以集中管理所有实例的配置。下面我们就通过一个小案例来感受一下 Spring Cloud Alibaba Nacos 配置中心的强大功能吧。
在 Nacos 中创建配置
我们以 userservice 服务为例,在 Nacos 配置中心创建一份配置文件。进入 Nacos 的管理界面,然后选择配置管理菜单,点击配置列表选项,点击右侧"+"符号,如下图所示:

点击之后,填写弹出的表单页,最后点击发布,我们就创建好一份 userservice 服务的配置,如下图所示:

发布成功之后,我们在控制台的配置列表中可以看到新增配置,并且可以进行再次编辑,查看详情,删除等操作。

此时,在 Nacos 配置中心的工作暂时告一段落,我们已经创建好一份 userservice 服务的配置文件,那么怎么样才能让 userservice 服务读取到这份配置呢?
读取 Nacos 中配置
userservice 服务要读取 Nacos 中管理的配置,并且与本地的 application.yml 配置合并,才能完成项目启动。但是此时有一个问题必须解决: 尚未读取 application.yml,又如何得知 nacos 地址呢?
为解决此问题,Spring 引入了一种新的配置文件:bootstrap.yaml 文件,该配置文件的优先级很高,会在 application.yml 之前被读取,流程如下:

首先,我们要给 userservice 引入 Nacos 配置中心的 Maven 依赖:
<!--nacos配置管理依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>其次,在 resources 目录下创建 bootstrap.yml 文件,并进行配置:
spring:
application:
name: userservice # 服务名称
profiles:
active: dev #开发环境,这里是dev
cloud:
nacos:
server-addr: localhost:8848 # Nacos地址
config:
file-extension: yaml # 文件后缀名此时,同学们会发现,在 bootstrap.yml 中配置的这些信息,正好可以满足我们的需求: 去 nacos 中查找一个名字为 userservice-dev.yaml 文件。这些信息正是${spring.application.name}-${spring.profiles.active}.${spring.cloud.nacos.config.file-extension}的值拼接而成。

这也是我们在 nacos 中创建配置文件时的命名规则的含义所在。
测试验证
我们在 userservice 中新增一个控制器类,进行测试:
@Slf4j
@RestController
@RequestMapping("/config")
public class NacosConfigTestController {
@Value("${myconfig.msg}")
private String msg;
@RequestMapping("/msg")
public String getMsg(){
return this.msg;
}
}修改完成之后,我们重启 userservice 服务,访问: http://localhost:8081/config/msg ,结果如图所示:

我们通过简单的几个步骤,成功的使用 Nacos 配置中心的功能,实现了在 Nacos 控制台对配置文件的简单管理。
现在如果尝试修改 Nacos 配置中心的config.msg的值,然后再次访问 http://localhost:8081/config/msg ,会发现返回的结果并没有发生变化,
要想使新的配置生效仍需重启服务.
配置热更新
如果每次线上修改修改了配置文件,都需要重启服务才能生效,这样的话,就会造成服务的中断,这是我们不希望看到的。那么,有没有一种方式,可以实现在线上修改配置文件,而不需要重启服务呢?
答案是可以的, 我们可以通过为 Nacos 的配置热更新来实现此类需求。
所谓的热更新是指,在 Nacos 中的配置文件变更后,对应的微服务无需重启就可以感知到最新的配置。
所谓的 Nacos 配置热更新,就是指 Nacos 中的线上配置变更后, 无需重启服务就可以感知到最新的配置变化。
在微服务中,可以通过 SpringBoot 的方式进行配置的注入 :
- 通过
@Value注解进行注入单个配置 - 通过
@AutoWired注解进行注入包含多个配置属性的对象 - 在需要注入配置的类上添加
@RefreshScope注解,使得注入的配置可以和线上配置保持同步
使用@Value 注解进行注入
在@Value 注入的变量所在类上添加注解@RefreshScope,:
@Slf4j
@RestController
@RequestMapping("/config")
@RefreshScope // 添加此注解, 使得配置文件可以热更新
public class NacosConfigTestController {
@Value("${myconfig.msg}") // 通过@Value 注解进行注入响应的配置
private String msg;
@RequestMapping("/msg")
public String getMsg(){
return this.msg;
}
}通过查看@RefreshScope 的注解发现,其底层是重新创建了实例,并进行了依赖注入。
/**
* 添加了@RefreshScope的Bean 可以在运行时刷新
* 任何使用它们的组件都将在下一次方法调用时获得一个新实例,完全初始化并注入所有依赖项。
* @author Dave Syer
*/
@Target({ ElementType.TYPE, ElementType.METHOD })
@Retention(RetentionPolicy.RUNTIME)
@Scope("refresh")
@Documented
public @interface RefreshScope {
ScopedProxyMode proxyMode() default ScopedProxyMode.TARGET_CLASS;
}使用@Autowire 注解进行注入
用@Value 可以进行简单值的属性注入,如果我们想要在 Bean 中注入一个对象,往往使用@Autowire 注解进行注入。针对这种注入方式,我们可以使用@ConfigurationProperties 注解进行配置读取。
我们仍然以myconfig.msg配置为例,使用@ConfigurationProperties 进行配置读取。 首先,编写一个 Java Bean:
@Data
@Component
@ConfigurationProperties(prefix = "myconfig")
public class UserNacosConfig {
private String msg;
private String chapter;
}
在编写 JavaBean 时,@ConfigurationProperties 注解的 prefix 属性和 Nacos 中配置的属性前缀保持一致,成员变量的名字和 Nacos 中配置的属性的 Key 保持一致。 Nacos 中配置我们修改如下:

修改完 Nacos 中配置之后,一定要记得点击发布按钮进行发布。
最后修改 NacosConfigTestController,注入我们编写的 JavaBean:
@Slf4j
@RestController
@RequestMapping("/config")
@RefreshScope
public class NacosConfigTestController {
@Value("${myconfig.msg}")
private String msg;
@Autowired
private UserNacosConfig userNacosConfig;
@RequestMapping("/msg")
public String getMsg() {
return this.msg;
}
@RequestMapping("/message")
public String getMessage() {
return userNacosConfig.getMsg() + userNacosConfig.getChapter();
}
}重启 userservice 应用,访问:http://localhost:8081/config/message ,结果如图所示:

此时是因为我们重启了服务,所以能够读取到最新的配置,这是可以预知的结果。
现在,我们继续修改配置,而不重启服务,观察是否能够得到最新的配置内容。
最新配置更改如下:

点击发布之后,我们不用重启 userservice 服务,直接再次访问:http://localhost:8081/config/message , 结果如图所示:

可以看到,我们已经可以实现配置的热更新。
加载指定的 Nacos 配置
配置默认的 GroupID 为 DEFAULT_GROUP, 也可以创建自定义的 GroupID, 但是在加载配置时,需要指定 GroupID。
在 Nacos 配置中心, 创建配置如下:

pom.xml 加入依赖
<dependency>
<groupId>com.alibaba.boot</groupId>
<artifactId>nacos-config-spring-boot-starter</artifactId>
<version>0.2.12</version>
</dependency>启动类加入注解
// 读取 Nacos 配置中心
@NacosPropertySource(dataId = "retryTimes", groupId = "RiskModule",autoRefreshed = true)
@MapperScan("com.niit.user.mapper")
@SpringBootApplication
public class UserApplication {...}使用时通过@NacosValue 注解进行注入
@NacosValue(value = "${readRetryTimes}", autoRefreshed = true)
private String readRetryTimes;
@NacosValue(value = "${writeRetryTimes}", autoRefreshed = true)
private String writeRetryTimes;
此外, 也可以通过 Nacos 的 API 进行配置的设置和读取
发布配置
curl -X POST "http://127.0.0.1:8848/nacos/v1/cs/configs?dataId=nacos.cfg.dataId&group=test&content=HelloWorld"获取配置
curl -X GET "http://127.0.0.1:8848/nacos/v1/cs/configs?dataId=nacos.cfg.dataId&group=test"
注意:
- 不是所有的配置都适合放到配置中心,维护起来比较麻烦。
- 建议将一些关键参数,需要在运行时进行调整的参数放到 Nacos 配置中心,这些参数一般都是自定义配置信息。
多环境配置
微服务系统中, 及存在共通的配置比如应用的名称。而有些配置在不同的环境下,比如开发环境和生产环境下的微服务的配置是不尽相同的, 比如端口号, 数据库的链接,Nacos 的地址。
此时,我们想尽量减少重复性工作,提升开发和维护的效率,那就需要将这些跨环境的那些相同配置提取出来。我们将共同配置提取到一个地方,就可以做到只用设置一次, 所有环境(比如开发.测试以及生产环境)都会读取该配置,这样就达到了配置共享的目的。
配置读取
在微服务启动的时候,会去 Nacos 中读取多个配置:
bootstrap.yml启动配置:
会优先加载,用于加载一些系统级别的配置,比如连接到配置中心的配置。${spring.application.name}.yaml
例如userservice.yaml。无论微服务的环境是开发环境也好, 是生产环境也好,${spring.application.name}.yaml这个配置文件都会userservice加载。
在 Nacos 中添加共享配置
我们在 nacos 中添加一个 userservice.yaml 文件:

注意: 命名规则是
${spring.application.name}.yaml,该共享配置与环境无关。
读取新增配置
在 userservice 服务中,修改配置类,读取新增的author属性:
@Data
@Component
@ConfigurationProperties(prefix = "myconfig")
public class UserNacosConfig {
private String chapter;
private String msg;
private String author;
}新增一个控制器方法,以便于进行测试验证:
@Slf4j
@RestController
@RequestMapping("/config")
@RefreshScope
public class NacosConfigTestController {
@Autowired
private UserNacosConfig userNacosConfig;
...
@RequestMapping("/author")
public String getAuthor() {
return userNacosConfig.getAuthor();
}
}多环境测试
使用 dev 环境启动一个 userservice 实例,端口号 8081,再用 test 环境启动另一个 userservice 实例,端口号 8082,然后我们分别访问: http://localhost:8081/config/author 和 http://localhost:8082/config/author:
结果如图所示:

我们知道,在 bootstrap.yml 文件中指定了应用读取 Nacos 中的 userservice-dev.yaml 文件,并且 Nacos 中并没有 userservice-test.yaml 配置文件,但是我们访问 8082 端口的 userservice 时,仍然能够读取myconfig.author的值,这说明userservice.yaml文件确实是多环境共享的一个配置文件。
配置优先级
我们现在考虑一个问题,如果多个配置文件中都对某个属性进行了定义,那么微服务究竟应该读取那个配置来使用呢?我们不妨来做一个小小的测验。
在每一个配置文件中都定义一个相同的属性,比如myconfig.bookName属性,如下所示:
- 在
userservice-dev.yaml中,bookName的值是Spring Cloud Dev。 - 在
userservice.yaml中,bookName的值是Spring Cloud Default。 - 在本地 application-dev.yaml 中,bookName 的值是 Spring Cloud Local。
修改配置类,读取 bookName 属性:
@Data
@Component
@ConfigurationProperties(prefix = "myconfig")
public class UserNacosConfig {
private String chapter;
private String msg;
private String author;
private String bookName;
}新增控制器方法,读取myconfig.bookName属性的值:
@Slf4j
@RestController
@RequestMapping("/config")
@RefreshScope
public class NacosConfigTestController {
@Autowired
private UserNacosConfig userNacosConfig;
...
@RequestMapping("/bookName")
public String getBookName() {
return userNacosConfig.getBookName();
}
}在 dev 环境下,重启 userservice,端口号 8081,现在我们访问: http://localhost:8081/config/bookName ,结果如图所示:

这说明,Nacos 线上配置的带有环境变量的配置文件的优先级是最高的。那么线上的共享配置和本地配置,哪个优先级更高呢?我们暂时删除 Nacos 线上配置的带有环境变量的配置文件中的属性,重新访问: http://localhost:8081/config/bookName ,结果如图所示:

通过这个小小的测验,对于配置优先级问题,我们总结出如下规律:
- 线上配置优先于本地配置
- 线上自定义环境配置优先于线上共享配置

这样的优先级规律,也恰恰符合配置中心的设计原则,即线上可配置优先于本地预配置,自定义个性化配置优先于多环境共享配置。详见 Nacos-config 参考文档
搭建 Nacos 高可用集群
在之前的内容中,我们已经学习了 Nacos 的基本用法。不过我们一直是使用的 nacos 单节点服务,Nacos 单节点模式只适用于线下环境,在企业的生产环境中,我们是不能使用 Nacos 单节点进行业务架构部署的。
单节点对于高可用设计来说是远远不够的,因为单节点一旦出先故障,那么所有依赖于该节点的其他微服务,都会出现问题,这样会导致整个业务系统的大崩溃。所以,我们接下来就开始学习如何搭建 Nacos 集群,构建一个高可用的服务治理体系。
Nacos 集群
一个 Nacos 集群,至少要有三个节点。下方是 Spring Cloud Alibaba Nacos 官方给出的最简易的 Nacos 集群架构图:

其中包含 3 个 nacos 节点,然后一个负载均衡器代理 3 个 Nacos。这里负载均衡器可以使用 nginx。接下来,我们以 windows 系统为例,搭建一个最简单的 Nacos 集群进行学习。
注意:
在实际生产环境中,需要给做反向代理的 nginx 服务器设置一个域名,这样后续如果有服务器迁移,nacos 的客户端也无需更改配置。Nacos 的各个节点应该部署到多个不同服务器,做好容灾和隔离。Mysql 应该搭建一个主从高可用的集群。 本案例以单机 windows 系统为例,模拟三个 Nacos 节点,并且使用单机的 Mysql8.0 以上的版本进行集群搭建的演示。
Nacos 集群搭建步骤如下:
- 搭建数据库,初始化数据库表结构
- 下载 nacos 安装包
- 配置 nacos 节点
- 启动 nacos 集群
- nginx 反向代理
- 修改微服务 Nacos 地址
初始化数据库
Nacos 默认数据存储在内嵌数据库 Derby 中,不属于生产可用的数据库。官方推荐的最佳实践是使用带有主从的高可用数据库集群。这里我们以单点的数据库为例来演示。首先新建一个数据库,命名为 nacos,而后导入 Nacos 的 MySQL 数据库的初始化 SQL 文件.
使用 Nacos 项目官方提供的初始化 sql 文件进行初始化操作, 具体位置在 conf 目录下的mysql-schema.sql文件


Nacos 的 MySQL 初始化脚本在线地址
https://github.com/alibaba/nacos/tree/develop/config/src/main/resources/META-INF
在本地 Mysql 中执行成功后,nacos 数据库中将会出现下面的表:

下载 Nacos 安装包
本知识点在本书第三章节已经介绍过,不再赘述,我们以 nacos2.1.0 版本为例,进行搭建。

配置 Nacos 节点
我们在本地 windows 系统上配置三个 Nacos 节点,各个节点的 IP 和端口如下表所示:
| 节点 | IP | port |
|---|---|---|
| nacos1 | 127.0.0.1 | 8858 |
| nacos2 | 127.0.0.1 | 8868 |
| nacos3 | 127.0.0.1 | 8878 |
注意: 本地 windows 系统上,如果端口被占用,可以修改端口号,但是要保证三个节点的端口号不一样, 且不要相邻(容易冲突)。
我们先配置好一个 nacos 节点,然后再复制成三个节点。
下面以一个节点操作为例:
1.解压缩
将下载的安装包,解压缩至一个没有中文目录的文件夹,命名为 nacos1,解压完成之后,Nacos 目录如图所示:

-目录说明:
- bin:启动脚本
- conf:配置文件
2.修改配置
进入 nacos 的 conf 目录,修改配置文件 cluster.conf.example,重命名为 cluster.conf:

编辑此文件,添加 nacos 集群配置:
192.168.65.1:8858
192.168.65.1:8868
192.168.65.1:8878192.168.65.1 为本机真实的 IP 地址
真实 ip 可以在启动单机版 nacos 后从日志提示中查看
然后修改 application.properties 文件,进行数据库配置:

属性说明:
spring.datasource.platform=mysql: 指定数据库平台为 mysql,Nacos 目前只支持 Mysql。db.num=1: Mysql 的实例个数,本案例中为 1 个 Mysql 实例。db.url.0: 数据库链接信息,本案例中我们使用的是 Mysql8.0 以上的版本,并且创建了 nacos 数据库,所以链接如上所示。db.user.0: 数据库用户名db.password.0: 数据库密码
接着修改应用的端口号,第一个节点是: 8858,如下图所示:
server.port=88583.复制节点
修改完上述配置并保存后,我们将该节点复制两份,命名为 nacos2 和 nacos3,并将 nacos1的端口修改为8858, nacos2 的端口修改为 8868,将 nacos3 的端口修改为 8878。完成之后,nacos 三个节点的集群整体如下所示:
启动 Nacos 集群
在每个 Nacos 节点的 bin 目录下,使用 cmd 命令窗口执行: startup.cmd。 Nacos 的该命令,默认就是以集群方式进行启动。启动成功,最后会打印出日志信息:

Nginx 反向代理
经过以上步骤,我们已经成功搭建好具有三个节点的 Nacos 集群,现在我们使用 Nginx 给该集群配置负载均衡和反向代理。
1.下载 Nginx
下载 Nginx,下载地址:https://nginx.org/en/download.html 我们选择最新的稳定版本。

2.解压缩
将安装包解压缩到任意的非中文目录下:

3.添加代理配置
修改 conf/nginx.conf 文件,将下面的配置放在配置文件的 http 节点之内:
upstream nacos-cluster {
server 127.0.0.1:8858;
server 127.0.0.1:8868;
server 127.0.0.1:8878;
}server {
listen 8848;
server_name localhost;
location /nacos {
proxy_pass http://nacos-cluster;
}
}该代理配置监听 8848 端口,虚拟路径为nacos。
4.启动 Nginx
修改完配置并保存之后,回到 Nginx 的安装目录,双击nginx.exe即可启动。此时,我们可以访问: http://localhost/nacos

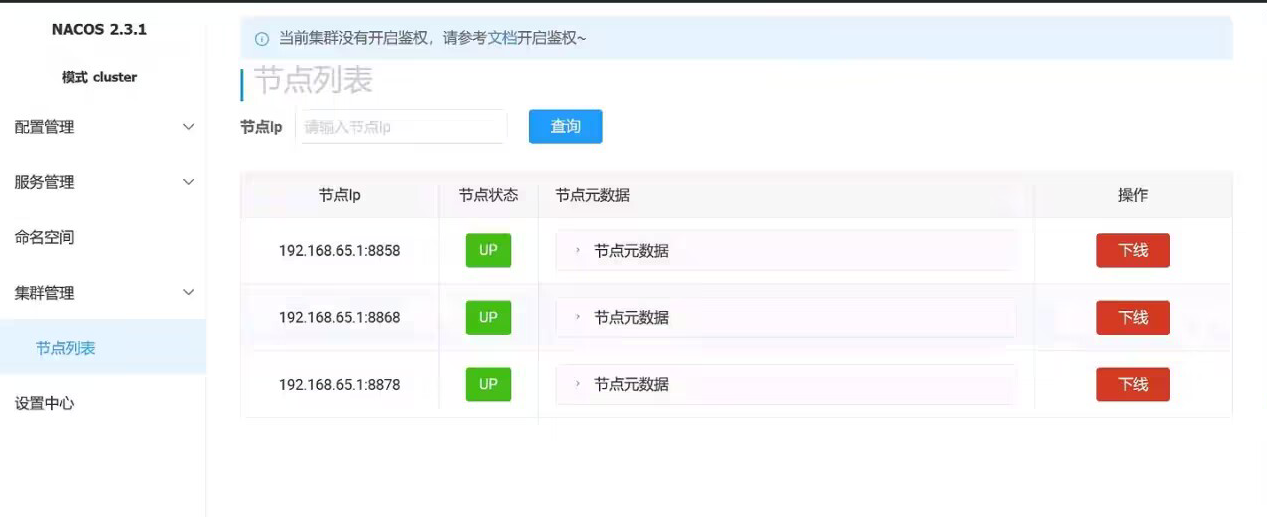
通过固定访问方式 http://localhost:8848/nacos 访问集群管理 - 节点列表, 如果看到集群中的三个节点都已经启动成功, 且为 UP 状态, 则说明 Nginx 反向代理配置成功。
微服务配置 Nacos 地址
由于我们现在已经搭建了 Nacos 集群,并且使用 Nginx 做了负载均衡和反向代理,所以各个微服务之前配置的 Nacos 地址肯定无法再使用,微服务中的 Nacos 地址配置要与 Nginx 中保持一致。
以 userservice 服务为例,修改其 bootstrap.yaml 文件即可:
spring:
application:
name: userservice
profiles:
active: dev #环境
cloud:
nacos:
server-addr: localhost:8848 #nacos集群的NGINX反向代理地址
config:
file-extension: yaml #配置文件后缀名现在我们启动三个 userservice 服务的实例进行测试,启动成功之后,我们可以在 Nacos 控制台看到如下信息:
当我们搭建完成 Nacos 集群之后,在使用的时候几乎完全和我们之前所学的单节点 Nacos 的使用方法一致。
活动 8.1:
Nacos 配置中心使用
练习问题
-
当使用@Value 注解进行属性注入时,在需要的类上加上什么注解可以实现动态刷新配置。 ()
a. @Service
b. @Component
c. @RestController
d. @RefreshScope查看答案
正确答案: d
-
Nacos 配置中心的 artifactId 是下列的哪一个? ()
a. spring-cloud-starter-alibaba-nacos-config
b. spring-cloud-starter-alibaba-nacos-discovery
c. spring-cloud-starter-Netflix-nacos-config
d. spring-cloud-starter-alibaba-config-config查看答案
正确答案: a
-
下列配置文件,哪个是 userservice 服务的多环境共享配置? ()
a.userservice-dev.yaml
b.application-dev.yaml
c.userservice.yaml
d.userservice-common.yaml查看答案
正确答案: c
-
搭建 Nacos 集群,最少需要几个 Nacos 实例节点?
a. 1
b. 2
c. 3
d. 4查看答案
正确答案: c
小结
在本章中,您学习了:
-
Nacos 配置中心快速入门
-
配置热更新
- 使用@Value 注解进行注入
- 使用@Autowire 注解进行注入
-
多环境配置共享
- 配置优先级
-
搭建 Nacos 集群
- 初始化数据库
- 配置 Nacos 节点
- 启动 Nacos 集群
- Nginx 反向代理
Views: 11