
使用Redisson和Zookeeper实现分布式锁模拟模拟抢红包业务
业务场景
模拟1000人在10秒内抢10000(或1000)元红包,金额在1-100不等;
使用的框架或软件:
- Springboot(基础框架)
- Redisson(实现分布式锁)
- Zookeeper(实现分布式锁方案)
- Ngnix(负载均衡)
- Redis(红包数据存取数据库)
系统或软件:
- Linux服务器
- Jmeter(模拟并发请求)
Jmeter 下载和运行
官方网站:http://jmeter.apache.org/
解压后, 运行 “bin/jmeter.bat”
Jmeter 是支持中文的, 启动Jmeter 后, 点击 Options -> Choose Language 来选择语言
测试需求
以获取城市的天气数据为例
第一步: 获取城市的城市代号
发送request到http://toy1.weather.com.cn/search?cityname=上海
从这个请求的 response 中获取到上海的城市代码. 比如:
上海的地区代码是101020100
上海动物园的地区代码是: 10102010016A
第二步: 得到该城市的天气数据
发送request 到: http://www.weather.com.cn/weather2d/101020100.shtml
测试步骤
步骤一: 新建一个Thread Group
必须新建一个Thread Group, jmeter的所有任务都必须由线程处理,所有任务都必须在线程组下面创建。

第二步:新建一个 HTTP Request
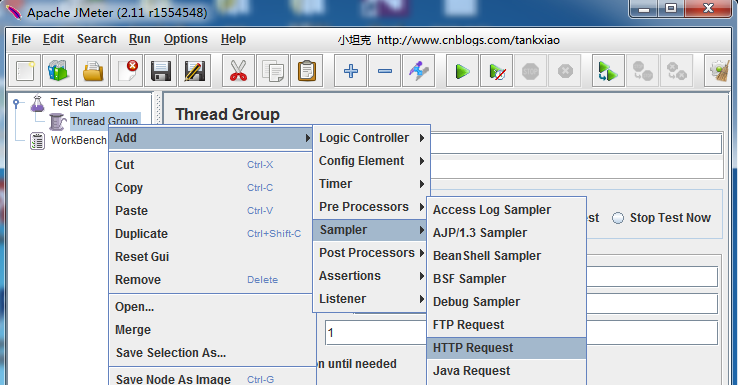
比如我要发送一个Get 方法的http 请求: http://toy1.weather.com.cn/search?cityname=上海
可以按照下图这么填

第三步 添加HTTP Head Manager
选中上一步新建的HTTP request. 右键,新建一个Http Header manager. 添加一个header


第四步: 添加View Results Tree
View Results Tree 是用来看运行的结果的
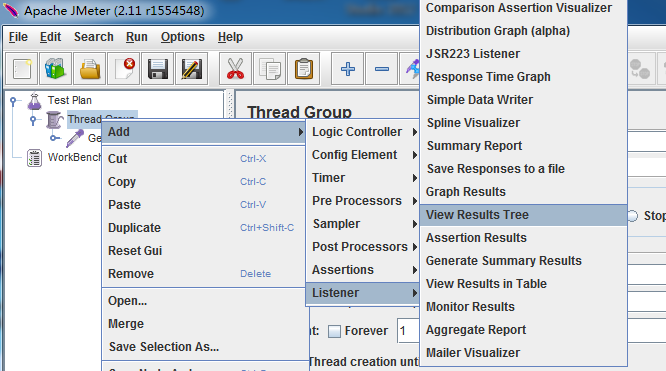
第五步:运行测试,查看结果


模拟抢红包业务开发
情况1 - 单机服务——没有任何线程安全考虑
@GetMapping("/get/money")
public String getRedPackage(){
Map map = new HashMap();
Object o = redisTemplate.opsForValue().get(KEY_RED_PACKAGE_MONEY);
int remainMoney = Integer.parseInt(String.valueOf(o));
if(remainMoney <= 0 ){
map.put("result","红包已抢完");
return ReturnModel.success(map).appendToString();
}
int randomMoney = (int) (Math.random() * 100);
if(randomMoney > remainMoney){
randomMoney = remainMoney;
}
int newRemainMoney = remainMoney-randomMoney;
redisTemplate.opsForValue().set(KEY_RED_PACKAGE_MONEY,newRemainMoney);
String result = "原有金额:" + remainMoney + " 红包金额:" + randomMoney + " 剩余金额:" + newRemainMoney;
System.out.println(result);
map.put("result",result);
return ReturnModel.success(map).appendToString();
}
输出数据有异常:
原有金额:1000 红包金额:49 剩余金额:951
原有金额:1000 红包金额:62 剩余金额:938
原有金额:1000 红包金额:61 剩余金额:939
原有金额:1000 红包金额:93 剩余金额:907
原有金额:1000 红包金额:73 剩余金额:927
原有金额:939 红包金额:65 剩余金额:874
原有金额:939 红包金额:16 剩余金额:923
原有金额:939 红包金额:30 剩余金额:909情况2 - 单机服务, 使用Lock锁
public static Lock lock = new ReentrantLock();
@GetMapping("/get/money/lock")
public String getRedPackageLock(){
Map map = new HashMap();
lock.lock();
try{
Object o = redisTemplate.opsForValue().get(KEY_RED_PACKAGE_MONEY);
int remainMoney = Integer.parseInt(String.valueOf(o));
if(remainMoney <= 0 ){
map.put("result","红包已抢完");
return ReturnModel.success(map).appendToString();
}
int randomMoney = (int) (Math.random() * 100);
if(randomMoney > remainMoney){
randomMoney = remainMoney;
}
int newRemainMoney = remainMoney-randomMoney;
redisTemplate.opsForValue().set(KEY_RED_PACKAGE_MONEY,newRemainMoney);
String result = "原有金额:" + remainMoney + " 红包金额:" + randomMoney + " 剩余金额:" + newRemainMoney;
System.out.println(result);
map.put("result",result);
return ReturnModel.success(map).appendToString();
}finally {
lock.unlock();
}
}
Lock在单服务器是线程安全的, 此时输出数据正常:
原有金额:1000 红包金额:11 剩余金额:989
原有金额:989 红包金额:48 剩余金额:941
原有金额:941 红包金额:17 剩余金额:924
原有金额:924 红包金额:89 剩余金额:835
原有金额:835 红包金额:63 剩余金额:772
原有金额:772 红包金额:77 剩余金额:695
原有金额:695 红包金额:76 剩余金额:619
原有金额:619 红包金额:8 剩余金额:611
原有金额:611 红包金额:67 剩余金额:544
原有金额:544 红包金额:9 剩余金额:535
原有金额:535 红包金额:78 剩余金额:457
......情况3.1 - 两台服务器, 使用Lock锁
数据异常(代码情况2一样);
Lock在镀钛服务器下是非线程安全的
负载均衡配置
使用Nginx配置负载均衡,部署两个服务分别是8001和8002端口,Nginx暴露8080端口,转发请求到8001和8002;

nginx配置
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
##定义负载均衡真实服务器IP:端口号 weight表示权重
upstream myserver{
server XX.XX.XX.XX:8001 weight=1;
server XX.XX.XX.XX:8002 weight=1;
}
server {
listen 8080;
location / {
proxy_pass http://myserver;
proxy_connect_timeout 10;
}
}
}情况3.2 - 两台服务器 使用Redisson分布式锁
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.31.Final</version>
</dependency>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.6.5</version>
</dependency>@Configuration
public class RedissonConfig {
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private String port;
@Value("${spring.redis.password}")
private String password;
@Bean
public RedissonClient getRedisson(){
Config config = new Config();
config.useSingleServer().setAddress("redis://" + host + ":" + port).setPassword(password);
return Redisson.create(config);
}
}@Autowired
private RedissonClient redissonClient;
//3-抢红包-redisson
@GetMapping("/get/money/redisson")
public String getRedPackageRedison(){
RLock rLock = redissonClient.getLock("secKill");
rLock.lock();
Map map = new HashMap();
try{
Object o = redisTemplate.opsForValue().get(KEY_RED_PACKAGE_MONEY);
int remainMoney = Integer.parseInt(String.valueOf(o));
if(remainMoney <= 0 ){
map.put("result","红包已抢完");
return ReturnModel.success(map).appendToString();
}
int randomMoney = (int) (Math.random() * 100);
if(randomMoney > remainMoney){
randomMoney = remainMoney;
}
int newRemainMoney = remainMoney-randomMoney;
redisTemplate.opsForValue().set(KEY_RED_PACKAGE_MONEY,newRemainMoney);
String result = "原有金额:" + remainMoney + " 红包金额:" + randomMoney + "剩余金额:" + newRemainMoney;
System.out.println(result);
map.put("result",result);
return ReturnModel.success(map).appendToString();
}finally {
rLock.unlock();
}
}情况3.3 - 两台服务器——使用Zookeeper分布式锁——数据正常
@Configuration
public class ZkConfiguration {
/**
* 重试次数
*/
@Value("${curator.retryCount}")
private int retryCount;
/**
* 重试间隔时间
*/
@Value("${curator.elapsedTimeMs}")
private int elapsedTimeMs;
/**
* 连接地址
*/
@Value("${curator.connectString}")
private String connectString;
/**
* Session过期时间
*/
@Value("${curator.sessionTimeoutMs}")
private int sessionTimeoutMs;
/**
* 连接超时时间
*/
@Value("${curator.connectionTimeoutMs}")
private int connectionTimeoutMs;
@Bean(initMethod = "start")
public CuratorFramework curatorFramework() {
return CuratorFrameworkFactory.newClient(
connectString,
sessionTimeoutMs,
connectionTimeoutMs,
new RetryNTimes(retryCount,elapsedTimeMs));
}
/**
* Distributed lock by zookeeper distributed lock by zookeeper.
*
* @return the distributed lock by zookeeper
*/
@Bean(initMethod = "init")
public DistributedLockByZookeeper distributedLockByZookeeper() {
return new DistributedLockByZookeeper();
}
}@Slf4j
public class DistributedLockByZookeeper {
private final static String ROOT_PATH_LOCK = "myk";
private CountDownLatch countDownLatch = new CountDownLatch(1);
/**
* The Curator framework.
*/
@Autowired
CuratorFramework curatorFramework;
/**
* 获取分布式锁
* 创建一个临时节点,
*
* @param path the path
*/
public void acquireDistributedLock(String path) {
String keyPath = "/" + ROOT_PATH_LOCK + "/" + path;
while (true) {
try {
curatorFramework.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.EPHEMERAL)
.withACL(ZooDefs.Ids.OPEN_ACL_UNSAFE)
.forPath(keyPath);
//log.info("success to acquire lock for path:{}", keyPath);
break;
} catch (Exception e) {
//抢不到锁,进入此处!
//log.info("failed to acquire lock for path:{}", keyPath);
//log.info("while try again .......");
try {
if (countDownLatch.getCount() <= 0) {
countDownLatch = new CountDownLatch(1);
}
//避免请求获取不到锁,重复的while,浪费CPU资源
countDownLatch.await();
} catch (InterruptedException e1) {
e1.printStackTrace();
}
}
}
}
/**
* 释放分布式锁
*
* @param path the 节点路径
* @return the boolean
*/
public boolean releaseDistributedLock(String path) {
try {
String keyPath = "/" + ROOT_PATH_LOCK + "/" + path;
if (curatorFramework.checkExists().forPath(keyPath) != null) {
curatorFramework.delete().forPath(keyPath);
}
} catch (Exception e) {
//log.error("failed to release lock,{}", e);
return false;
}
return true;
}
/**
* 创建 watcher 事件
*/
private void addWatcher(String path) {
String keyPath;
if (path.equals(ROOT_PATH_LOCK)) {
keyPath = "/" + path;
} else {
keyPath = "/" + ROOT_PATH_LOCK + "/" + path;
}
try {
final PathChildrenCache cache = new PathChildrenCache(curatorFramework, keyPath, false);
cache.start(PathChildrenCache.StartMode.POST_INITIALIZED_EVENT);
cache.getListenable().addListener((client, event) -> {
if (event.getType().equals(PathChildrenCacheEvent.Type.CHILD_REMOVED)) {
String oldPath = event.getData().getPath();
//log.info("上一个节点 " + oldPath + " 已经被断开");
if (oldPath.contains(path)) {
//释放计数器,让当前的请求获取锁
countDownLatch.countDown();
}
}
});
} catch (Exception e) {
log.info("监听是否锁失败!{}", e);
}
}
/**
* 创建父节点,并创建永久节点
*/
public void init() {
curatorFramework = curatorFramework.usingNamespace("lock-namespace");
String path = "/" + ROOT_PATH_LOCK;
try {
if (curatorFramework.checkExists().forPath(path) == null) {
curatorFramework.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.PERSISTENT)
.withACL(ZooDefs.Ids.OPEN_ACL_UNSAFE)
.forPath(path);
}
addWatcher(ROOT_PATH_LOCK);
log.info("root path 的 watcher 事件创建成功");
} catch (Exception e) {
log.error("connect zookeeper fail,please check the log >> {}", e.getMessage(), e);
}
}
} @Autowired
DistributedLockByZookeeper distributedLockByZookeeper;
private final static String PATH = "red_package";
//4-抢红包-zookeeper
@GetMapping("/get/money/zookeeper")
public String getRedPackageZookeeper(){
Boolean flag = false;
distributedLockByZookeeper.acquireDistributedLock(PATH);
Map map = new HashMap();
try {
Object o = redisTemplate.opsForValue().get(KEY_RED_PACKAGE_MONEY);
int remainMoney = Integer.parseInt(String.valueOf(o));
if(remainMoney <= 0 ){
map.put("result","红包已抢完");
return ReturnModel.success(map).appendToString();
}
int randomMoney = (int) (Math.random() * 100);
if(randomMoney > remainMoney){
randomMoney = remainMoney;
}
int newRemainMoney = remainMoney-randomMoney;
redisTemplate.opsForValue().set(KEY_RED_PACKAGE_MONEY,newRemainMoney);
String result = "原有金额:" + remainMoney + " 红包金额:" + randomMoney + "剩余金额:" + newRemainMoney;
System.out.println(result);
map.put("result",result);
return ReturnModel.success(map).appendToString();
} catch(Exception e){
e.printStackTrace();
flag = distributedLockByZookeeper.releaseDistributedLock(PATH);
//System.out.println("releaseDistributedLock: " + flag);
map.put("result","getRedPackageZookeeper catch exceeption");
return ReturnModel.success(map).appendToString();
}finally {
flag = distributedLockByZookeeper.releaseDistributedLock(PATH);
//System.out.println("releaseDistributedLock: " + flag);
}
}附录
1- 其他配置和类
application.properties文件
server.port=80
#配置redis
spring.redis.host=XX.XX.XX.XX
spring.redis.port=6379
spring.redis.password=xuegaotest1234
spring.redis.database=0
#重试次数
curator.retryCount=5
#重试间隔时间
curator.elapsedTimeMs=5000
# zookeeper 地址
curator.connectString=XX.XX.XX.XX:2181
# session超时时间
curator.sessionTimeoutMs=60000
# 连接超时时间
curator.connectionTimeoutMs=5000ReturnModel 类
public class ReturnModel implements Serializable{
private int code;
private String msg;
private Object data;
public static ReturnModel success(Object obj){
return new ReturnModel(200,"success",obj);
}
public String appendToString(){
return JSON.toJSONString(this);
}
public ReturnModel() {
}
public ReturnModel(int code, String msg, Object data) {
this.code = code;
this.msg = msg;
this.data = data;
}
public int getCode() {
return code;
}
public void setCode(int code) {
this.code = code;
}
public String getMsg() {
return msg;
}
public void setMsg(String msg) {
this.msg = msg;
}
public Object getData() {
return data;
}
public void setData(Object data) {
this.data = data;
}
}SeckillController类
public final static String KEY_RED_PACKAGE_MONEY = "key_red_package_money";
@Autowired
private RedisTemplate redisTemplate;
//1-设置红包
@GetMapping("/set/money/{amount}")
public String setRedPackage(@PathVariable Integer amount){
redisTemplate.opsForValue().set(KEY_RED_PACKAGE_MONEY,amount);
Object o = redisTemplate.opsForValue().get(KEY_RED_PACKAGE_MONEY);
Map map = new HashMap();
map.put("moneyTotal",Integer.parseInt(String.valueOf(o)));
return ReturnModel.success(map).appendToString();
}流程解析
Zookeeper分布锁
1- 在ZkConfiguration类中加载CuratorFramework时,设置参数,实例化一个CuratorFramework类; 实例化过程中,执行CuratorFrameworkImpl类中的的start(),其中CuratorFrameworkImpl类是CuratorFramework的实现类;根据具体的细节可以参考博客;
@Bean(initMethod = "start")
public CuratorFramework curatorFramework() {
return CuratorFrameworkFactory.newClient( connectString, sessionTimeoutMs, connectionTimeoutMs, new RetryNTimes(retryCount,elapsedTimeMs));
}2- 在ZkConfiguration类中加载DistributedLockByZookeeper时;执行其中的init()方法;init()方法中主要是创建父节点和添加监听
/**
* 创建父节点,并创建永久节点
*/
public void init() {
curatorFramework = curatorFramework.usingNamespace("lock-namespace");
String path = "/" + ROOT_PATH_LOCK;
try {
if (curatorFramework.checkExists().forPath(path) == null) {
curatorFramework.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.PERSISTENT)
.withACL(ZooDefs.Ids.OPEN_ACL_UNSAFE)
.forPath(path);
}
addWatcher(ROOT_PATH_LOCK);
log.info("root path 的 watcher 事件创建成功");
} catch (Exception e) {
log.error("connect zookeeper fail,please check the log >> {}", e.getMessage(), e);
}
}3- 在具体业务中调用distributedLockByZookeeper.acquireDistributedLock(PATH);获取分布式锁
/**
* 获取分布式锁
* 创建一个临时节点,
*
* @param path the path
*/
public void acquireDistributedLock(String path) {
String keyPath = "/" + ROOT_PATH_LOCK + "/" + path;
while (true) {
try {
curatorFramework.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.EPHEMERAL)
.withACL(ZooDefs.Ids.OPEN_ACL_UNSAFE)
.forPath(keyPath);
break;
} catch (Exception e) {
//抢不到锁,进入此处!
try {
if (countDownLatch.getCount() <= 0) {
countDownLatch = new CountDownLatch(1);
}
//避免请求获取不到锁,重复的while,浪费CPU资源
countDownLatch.await();
} catch (InterruptedException e1) {
e1.printStackTrace();
}
}
}
}4- 业务结束时调用distributedLockByZookeeper.releaseDistributedLock(PATH);释放锁
/**
* 释放分布式锁
*
* @param path the 节点路径
* @return the boolean
*/
public boolean releaseDistributedLock(String path) {
try {
String keyPath = "/" + ROOT_PATH_LOCK + "/" + path;
if (curatorFramework.checkExists().forPath(keyPath) != null) {
curatorFramework.delete().forPath(keyPath);
}
} catch (Exception e) {
return false;
}
return true;
}原理图如下

期间碰到的问题
问题: 项目启动时:java.lang.ClassNotFoundException: com.google.common.base.Function
原因:缺少google-collections jar包;如下
<dependency>
<groupId>com.google.collections</groupId>
<artifactId>google-collections</artifactId>
<version>1.0</version>
</dependency>问题:项目启动时:org.apache.curator.CuratorConnectionLossException: KeeperErrorCode = ConnectionLoss
原因:简单说,就是连接失败(可能原因的有很多);依次排查了zookeeper服务器防火墙、application.properties配置文件;最后发现IP的写错了,更正后就好了
问题:Jemter启用多线程并发测试时:java.net.BindException: Address already in use: connect.
Views: 515