
官方文档: Storm/Trident 集成 Redis
Storm-redis 使用 Jedis 作为 Redis client.
maven 依赖配置如下:
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-redis</artifactId>
<version>${storm.version}</version>
<type>jar</type>
</dependency>一般情况
storm-redis提供的三种基本的bolt实现:
- RedisLookupBolt 通过 key 从 redis 获取对应的 value
- RedisStoreBolt 存储 key / value 到 Redis
- RedisFilterBolt 用于过滤key或者field在 Redis 中不存在的 tuple.
Tuple和Redis中的键值对的映射关系可以通过TupleMapper来进行定义.
通过RedisDataTypeDescription这个类可以选择数据类型.参考 RedisDataTypeDescription.RedisDataType可以查看有哪些支持的数据类型.
接口 RedisLookupMapper、RedisStoreMapper、RedisFilterMapper 分别用来适配 RedisLookupBolt、RedisStoreBolt、和RedisFilterBolt. (当实现 RedisFilterMapper时要记得在declareOutputFields() 方法中定于输入流的字段, 因为 FilterBolt 会把 Redis 中的数据作为输入的 tuples 发送出去)
RedisLookupBolt 用法
class WordCountRedisLookupMapper implements RedisLookupMapper {
private RedisDataTypeDescription description;
private final String hashKey = "wordCount";
public WordCountRedisLookupMapper() {
description = new RedisDataTypeDescription(
RedisDataTypeDescription.RedisDataType.HASH, hashKey);
}
@Override
public List<Values> toTuple(ITuple input, Object value) {
String member = getKeyFromTuple(input);
List<Values> values = Lists.newArrayList();
values.add(new Values(member, value));
return values;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("wordName", "count"));
}
@Override
public RedisDataTypeDescription getDataTypeDescription() {
return description;
}
@Override
public String getKeyFromTuple(ITuple tuple) {
return tuple.getStringByField("word");
}
@Override
public String getValueFromTuple(ITuple tuple) {
return null;
}
}
JedisPoolConfig poolConfig = new JedisPoolConfig.Builder()
.setHost(host).setPort(port).build();
RedisLookupMapper lookupMapper = new WordCountRedisLookupMapper();
RedisLookupBolt lookupBolt = new RedisLookupBolt(poolConfig, lookupMapper);RedisFilterBolt 用法
RedisFilterBolt 用于当Redis不存在给定数据类型的给定 key/field 时进行过滤. 类似白名单, 即只保留Redis中存在的数据, 如果 Redis 上存在 key/field,则此 bolt 会将作为输入的元组根据指定输出格式转发到默认流。
支持的数据类型:STRING、HASH、SET、SORTED_SET、HYPER_LOG_LOG、GEO。
注1:对于 STRING,它会检查KEY SPACE中是否存在此KEY。 对于 HASH 和 SORTED_SET 和 GEO,它会检查该数据结构上是否存在此类FIELD。 对于 SET 和 HYPER_LOG_LOG,需要指定一个
AdditionalKey作为KEY, 可以事先在SET 或 HYPER_LOG_LOG 中添加一些值作为白名单。这样过滤器会使用白名单和上游发来的 tuple 中的某个字段(通过RedisFilterMapper#getKeyFromTuple()方法来指定)的值进行比对,包含则放行.注2:如果只想查询key是否在Redis中存在而不管实际数据类型为何,可将RedisFilterMapper的数据类型指定STRING。
class WhitelistWordFilterMapper implements RedisFilterMapper {
private RedisDataTypeDescription description;
private final String setKey = "whitelist";
public BlacklistWordFilterMapper() {
// 设置Redis的数据类型为SET(集合)
// setKey 作为 AdditionalKey(集合的KEY)
description = new RedisDataTypeDescription(
RedisDataTypeDescription.RedisDataType.SET, setKey);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
@Override
public RedisDataTypeDescription getDataTypeDescription() {
return description;
}
// 从Redis白名单集合中比对是否包含tuple中的"word"字段的值
// 如果存在就放行
@Override
public String getKeyFromTuple(ITuple tuple) {
return tuple.getStringByField("word");
}
@Override
public String getValueFromTuple(ITuple tuple) {
return null;
}
}
使用
JedisPoolConfig poolConfig = new JedisPoolConfig.Builder()
.setHost(host).setPort(port).build();
RedisFilterMapper filterMapper = new WhitelistWordFilterMapper();
RedisFilterBolt filterBolt = new RedisFilterBolt(poolConfig, filterMapper);RedisStoreBolt 用法
class WordCountStoreMapper implements RedisStoreMapper {
private RedisDataTypeDescription description;
private final String hashKey = "wordCount";
public WordCountStoreMapper() {
description = new RedisDataTypeDescription(
RedisDataTypeDescription.RedisDataType.HASH, hashKey);
}
@Override
public RedisDataTypeDescription getDataTypeDescription() {
return description;
}
@Override
public String getKeyFromTuple(ITuple tuple) {
return tuple.getStringByField("word");
}
@Override
public String getValueFromTuple(ITuple tuple) {
return tuple.getStringByField("count");
}
}
JedisPoolConfig poolConfig = new JedisPoolConfig.Builder()
.setHost(host).setPort(port).build();
RedisStoreMapper storeMapper = new WordCountStoreMapper();
RedisStoreBolt storeBolt = new RedisStoreBolt(poolConfig, storeMapper);WordCount示例(将统计结果持久化到Redis)
public class WordCountRedisTopology {
public static class RandomSentenceSpout extends BaseRichSpout {
SpoutOutputCollector collector;
Random rand;
@Override
public void open(Map<String, Object> conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
rand = new Random();
}
@Override
public void nextTuple() {
Utils.sleep(1000);
String[] sentences = new String[]{
"the cow jumped over the moon",
"an apple a day keeps the doctor away",
"four score and seven years ago",
"snow white and the seven dwarfs",
"i am at two with nature"
};
String sentence = sentences[rand.nextInt(sentences.length)];
collector.emit(new Values(sentence));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
}
public static class SentenceSplitBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public void prepare(Map<String, Object> map, TopologyContext topologyContext, OutputCollector outputCollector) {
collector = outputCollector;
}
@Override
public void execute(Tuple tuple) {
String line = tuple.getStringByField("line");
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
String word = tokenizer.nextToken();
collector.emit(new Values(word));
}
}
}
public static class DataRedisStoreMapper implements RedisStoreMapper {
private RedisDataTypeDescription description;
private final String hashKey = "word-count";
public DataRedisStoreMapper() {
description = new RedisDataTypeDescription(
RedisDataTypeDescription.RedisDataType.HASH, hashKey);
}
@Override
public RedisDataTypeDescription getDataTypeDescription() {
return description;
}
@Override
public String getKeyFromTuple(ITuple tuple) {
return tuple.getStringByField("word");
}
@Override
public String getValueFromTuple(ITuple tuple) {
return tuple.getIntegerByField("count") + "";
}
}
public static class WordCountBolt extends BaseBasicBolt {
Map<String, Integer> counts = new HashMap<>();
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getStringByField("word");
Integer count = counts.get(word);
if (count == null) {
count = 0;
}
count++;
counts.put(word, count);
collector.emit(new Values(word, count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
public static void main(String[] args) {
Config conf = new Config();
conf.setNumAckers(0);
conf.setDebug(true);
conf.setNumWorkers(2); // 设置为1个topology创建2个worker进程
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new RandomSentenceSpout());
builder.setBolt("split", new SentenceSplitBolt(), 2).setNumTasks(4).shuffleGrouping("spout");
builder.setBolt("count", new WordCountBolt(), 3).setNumTasks(6).fieldsGrouping("split", new Fields("word"));
// storm to redis store
JedisPoolConfig poolConfig = new JedisPoolConfig.Builder()
.setPassword("niit1234").setHost("hadoop001").setPort(6379).build();
RedisStoreMapper storeMapper = new DataRedisStoreMapper();
RedisStoreBolt storeBolt = new RedisStoreBolt(poolConfig, storeMapper);
builder.setBolt("store", storeBolt).shuffleGrouping("count");
String topologyName = "word-count";
if (args != null && args.length > 0) {
topologyName = args[0];
}
try {
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology(topologyName, conf, builder.createTopology());
// StormSubmitter.submitTopology(topologyName, conf, builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
}
}结果
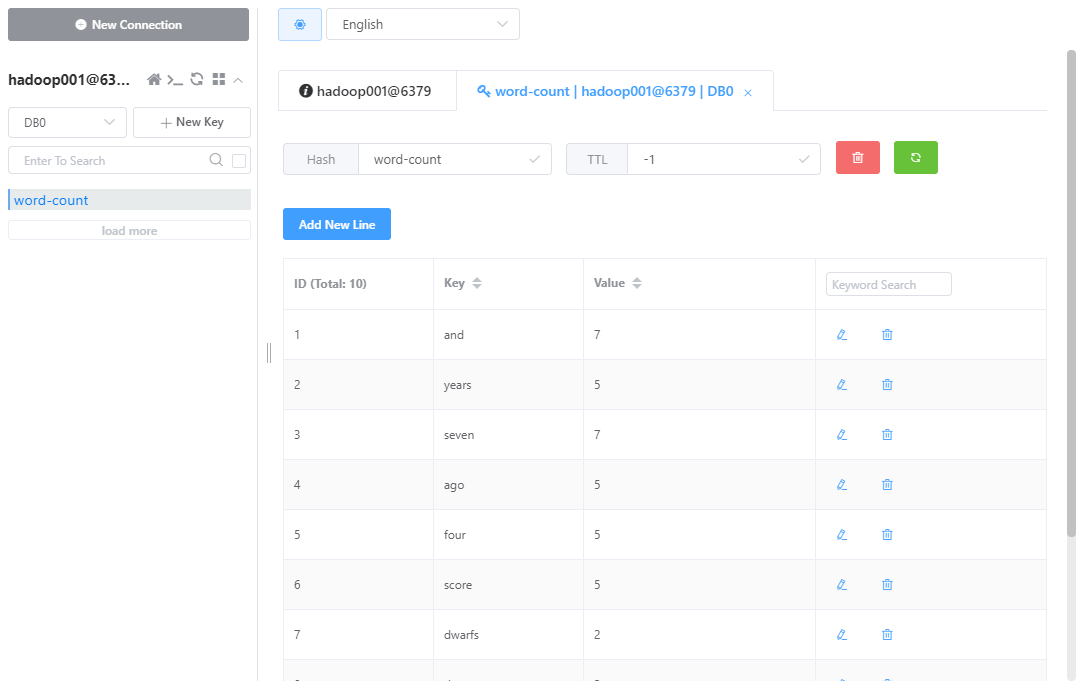
复杂情况
Storm-redis提供了通用的bolt抽象类,当 RedisStoreBolt、RedisLookupBolt、RedisFilterBolt 不符合你的使用场景时, storm-redis 也提供了抽象的 AbstractRedisBolt 类来供你继承并实现你自己的业务逻辑.
RedisLookupBolt、RedisStoreBolt、RedisFilterBolt均继承自AbstractRedisBolt抽象类。我们可以通过继承该抽象类,实现自定义 Bolt,进行功能的拓展。
实现自定义Bolt: LookupWordTotalCountBolt
将数据流中字段为"word"的单词作为key在Redis中查找对应的value(即对应词频),并抽样打印结果.
public static class LookupWordTotalCountBolt extends AbstractRedisBolt {
private static final Logger LOG = LoggerFactory.getLogger(LookupWordTotalCountBolt.class);
private static final Random RANDOM = new Random();
public LookupWordTotalCountBolt(JedisPoolConfig config) {
super(config);
}
public LookupWordTotalCountBolt(JedisClusterConfig config) {
super(config);
}
@Override
public void execute(Tuple input) {
JedisCommands jedisCommands = null;
try {
jedisCommands = getInstance();
String wordName = input.getStringByField("word");
String countStr = jedisCommands.get(wordName);
if (countStr != null) {
int count = Integer.parseInt(countStr);
this.collector.emit(new Values(wordName, count));
// print lookup result with low probability
if(RANDOM.nextInt(1000) > 995) {
LOG.info("Lookup result - word : " + wordName + " / count : " + count);
}
} else {
// skip
LOG.warn("Word not found in Redis - word : " + wordName);
}
} finally {
if (jedisCommands != null) {
returnInstance(jedisCommands);
}
this.collector.ack(input);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// wordName, count
declarer.declare(new Fields("wordName", "count"));
}
}在Trident State集成Redis
- RedisState 和 RedisMapState, 提供了单个的Jedis客户端接口.
- RedisClusterState 和 RedisClusterMapState, 提供了JedisCluster客户端接口用于在拥有Redis集群情况下使用.
RedisState
JedisPoolConfig poolConfig = new JedisPoolConfig.Builder()
.setHost(redisHost).setPort(redisPort)
.build();
RedisStoreMapper storeMapper = new WordCountStoreMapper();
RedisLookupMapper lookupMapper = new WordCountLookupMapper();
RedisState.Factory factory = new RedisState.Factory(poolConfig);
TridentTopology topology = new TridentTopology();
Stream stream = topology.newStream("spout1", spout);
stream.partitionPersist(factory,
fields,
new RedisStateUpdater(storeMapper).withExpire(86400000),
new Fields());
TridentState state = topology.newStaticState(factory);
stream = stream.stateQuery(state, new Fields("word"),
new RedisStateQuerier(lookupMapper),
new Fields("columnName","columnValue"));RedisClusterState
Set<InetSocketAddress> nodes = new HashSet<InetSocketAddress>();
for (String hostPort : redisHostPort.split(",")) {
String[] host_port = hostPort.split(":");
nodes.add(new InetSocketAddress(host_port[0], Integer.valueOf(host_port[1])));
}
JedisClusterConfig clusterConfig = new JedisClusterConfig.Builder().setNodes(nodes)
.build();
RedisStoreMapper storeMapper = new WordCountStoreMapper();
RedisLookupMapper lookupMapper = new WordCountLookupMapper();
RedisClusterState.Factory factory = new RedisClusterState.Factory(clusterConfig);
TridentTopology topology = new TridentTopology();
Stream stream = topology.newStream("spout1", spout);
stream.partitionPersist(factory,
fields,
new RedisClusterStateUpdater(storeMapper).withExpire(86400000),
new Fields());
TridentState state = topology.newStaticState(factory);
stream = stream.stateQuery(state, new Fields("word"),
new RedisClusterStateQuerier(lookupMapper),
new Fields("columnName","columnValue"));Views: 195