
问题陈述
Sqoop是Hadoop生态系统和RDBMS之间进行数据传输的一个工具。在学习Sqoop之前首先需要完成学习环境的搭建。这里为了学习方便,采用单机部署方式。
最初Sqoop是Hadoop的一个子项目,它设计只能在Linux操作系统上运行。
先决条件
安装Sqoop的必要前提条件是:
- 准备Linux操作系统(Centos7)
- 安装Java环境(JDK1.8)
- 安装Hadoop环境(Hadoop 3.1.4)
另外为了学习Sqoop的大部分功能,还需要需要安装:
- Zookeeper 3.5.9)
- HBase 2.2.3
- MySQL 5.7
- Hive 3.1.2
解决办法
准备Linux操作系统
配置主机名映射
设置网络:
虚拟机安装Centos7时
硬盘设置大一些,如40G或更多
不要设置预先分配磁盘空间.
网络适配器设置为NAT连接
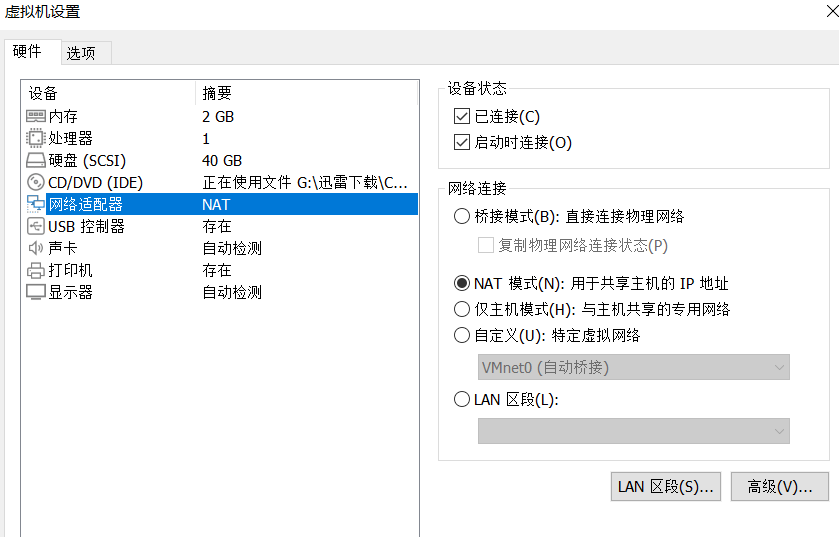
打开虚拟网络编辑器
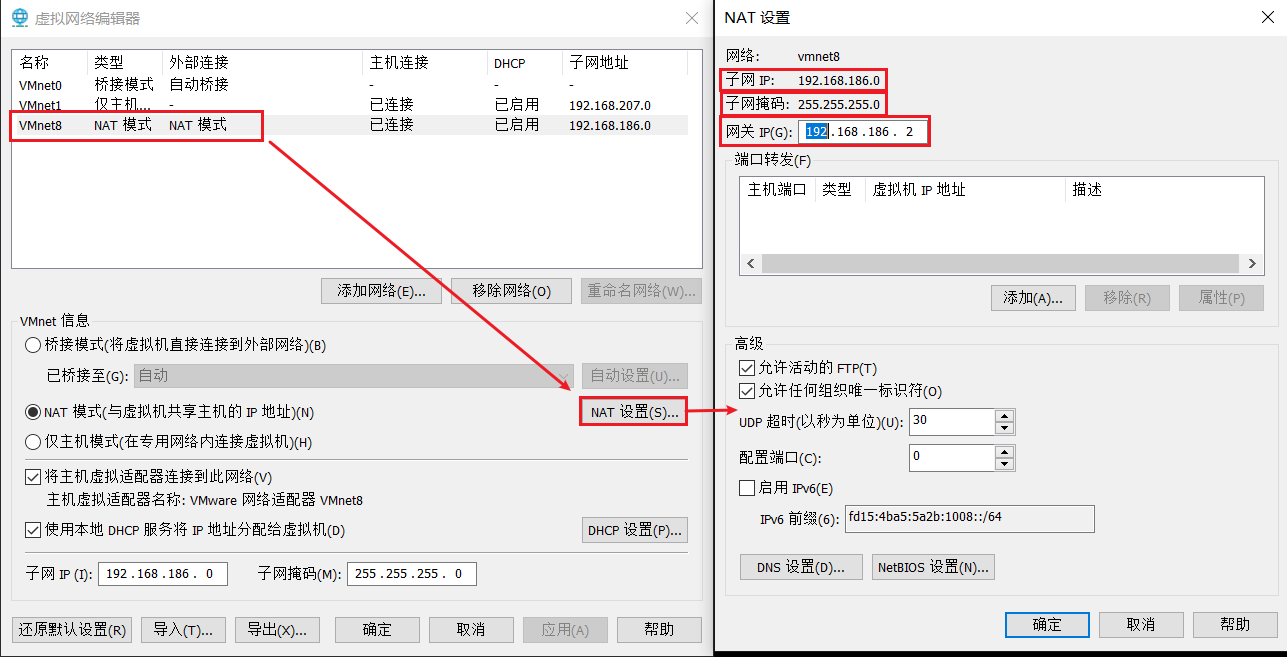
记住NAT模式所在的虚拟网卡对应的子网IP,子网掩码以及网关IP.
然后进入虚拟机终端,设置静态IP
$ vi /etc/sysconfig/network-scripts/ifcfg-ens33
NAME="ens33"
TYPE="Ethernet"
DEVICE="ens33"
BROWSER_ONLY="no"
DEFROUTE="yes"
PROXY_METHOD="none"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
IPV6_PRIVACY="no"
UUID="b00b9ac0-60c2-4d34-ab88-2413055463cf"
ONBOOT="yes"
BOOTPROTO="static"
IPADDR="192.168.186.100"
PREFIX="24"
GATEWAY="192.168.186.2"
DNS1="223.5.5.5"
DNS2="8.8.8.8"其中需要修改的是:
- ONTBOOT设置yes可以实现自动联网
- BOOTPROTO="static" 设置静态IP,防止IP发生变化
- IPADDR的前三段要和NAT虚拟网卡的子网IP一致,且第四段在0~254之间选择,又不能和NAT虚拟网卡的子网掩码和其他相同网络中的主机IP重复.
- PREFIX=24是设置子网掩码的位数长度,换算十进制就是255.255.255.0,因此PREFIX=24也可以直接替换成NETMASK="255.255.255.0"
- DNS1设置的是阿里的公共DNS地址"223.5.5.5",DNS2设置的是谷歌的公共DNS地址"8,8,8,8"
设置好了之后需要重新启动网络:
$ sudo service network restart
Restarting network (via systemctl): [ 确定 ]
$ sudo service network status
已配置设备:
lo ens33
当前活跃设备:
lo ens33
查看本机ip:
$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:b2:5b:75 brd ff:ff:ff:ff:ff:ff
inet 192.168.186.100/24 brd 192.168.186.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::40db:ee8d:77c1:fbf7/64 scope link noprefixroute
valid_lft forever preferred_lft forever设置静态主机名:
# hostnamectl --static set-hostname hadoop100在hosts文件中配置主机名和本机ip之间的映射关系
(注释掉localhost的部分)
vi /etc/hosts
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.186.100 hadoop100创建专用账号
不建议直接使用root账号, 这里我们创建一个hadoop账号用于接下来的所有操作.
创建hadoop用户
# useradd hadoop 设置hadoop用户的密码
# password hadoop为hadoop账号设置sudoer权限
vi /etc/sudoers找到root ALL=(ALL) ALL在下面添加一行
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
delucia ALL=(ALL) NOPASSWD:ALL修改完成后,切换到Hadoop用户
# su hadoop以后在使用需要root权限的命令时,就可以在命令前面加上sudo来提升权限,且无需输入hadoop密码, 如:
$ sudo ls /root接下来的所有操作, 如果没有特殊说明, 一律使用hadoop账号.
配置SSH免密登录
由于Hadoop集群的机器之间ssh通信默认需要输入密码,在集群运行时我们不可能为每一次通信都手动输入密码,因此需要配置机器之间的ssh的免密登录。单机伪分布式的Hadoop环境样需要配置本地对本地ssh连接的免密,流程如下:
-
首先ssh-keygen命令生成RSA加密的密钥对(公钥和私钥)。
$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa. Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub. The key fingerprint is: SHA256:yQYChs4eniVLeICaI2bCB9HopbXUBE9v0lpLjBACUnM hadoop@hadoop100 The key's randomart image is: +---[RSA 2048]----+ |==O+Eo | |=+.O+.= | |Bo* o+.B | |B%.+ .*o.. | |OoB . .S | | = . | | | +----[SHA256]-----+ -
将生成的公钥添加到~/.ssh目录下的authorized_keys文件中。并为authorized_keys文件设置600权限。
$ cd ~/.ssh/ $ cat id_rsa.pub >> authorized_keys $ chmod 600 authorized_keys以上三个命令可以使用一个命令代替:
$ ssh-copy-id hadoop100 -
使用ssh命令连接本地终端,如果不需要输入密码则说明本地的SSH免密配置成功。
$ ssh hadoop@hadoop100 The authenticity of host 'hadoop100 (192.168.186.100)' can't be established. ECDSA key fingerprint is SHA256:aGLhdt3bIuqtPgrFWnhgrfTKUbDh4CWVTfIgr5E5oV0. ECDSA key fingerprint is MD5:b8:bd:b3:65:fe:77:2c:06:2d:ec:58:3a:97:51:dd:ca. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'hadoop100,192.168.186.100' (ECDSA) to the list of known hosts. Last login: Sat Jan 9 10:16:53 2021 from 192.168.186.1 -
登出
$ exit Connection to hadoop100 closed.
配置时间同步
集群中的通信和文件传输一般是以系统时间作为约定条件的。所以当集群中机器之间系统如果不一致可能导致各种问题发生,比如访问时间过长,甚至失败。所以配置机器之间的时间同步非常重要。不过由于我们使用的学习环境是单机部署,所以无需配置时间同步。
统一目录结构
目录规划如下:
/opt/
├── bin # 脚本和命令
├── data # 程序需要使用的数据
├── download # 下载的软件安装包
├── pkg # 解压方式安装的软件
└── tmp # 存放程序生成的临时文件使用hadoop账户创建目录:
$ sudo mkdir /opt/download
$ sudo mkdir /opt/data
$ sudo mkdir /opt/bin
$ sudo mkdir /opt/tmp
$ sudo mkdir /opt/pkg为了使用方便更改opt下目录的用户及其所在用户组为hadoop:
$ sudo chown hadoop:hadoop /opt/*
$ ls
bin data download pkg tmp
$ ll
总用量 0
drwxr-xr-x. 2 hadoop hadoop 6 1月 9 14:29 bin
drwxr-xr-x. 2 hadoop hadoop 6 1月 9 14:29 data
drwxr-xr-x. 2 hadoop hadoop 6 1月 9 14:29 download
drwxr-xr-x. 2 hadoop hadoop 6 1月 9 14:37 pkg
drwxr-xr-x. 2 hadoop hadoop 6 1月 9 14:36 tmp安装Java环境
检查是否已经装过Java JDK
$ rpm -qa | grep java或
$ yum list installed | grep java如果没有安装过Java 则需要安装,JDK版本建议1.8+
Java JDK的下载和解压
去官网下载JDK1.8的安装包,上传到/opt/download/,然后解压到/opt/pkg
$ tar -zxvf jdk-8u261-linux-x64.tar.gz
$ mv jdk1.8.0_261 /opt/pkg/java配置java环境变量
确认当前目录为jdk的解压路径
$ pwd
/opt/pkg/java编辑/etc/profile.d/hadoop.env.sh配置文件(没有则创建)
$ sudo vim /etc/profile.d/hadoop.env.sh添加新的环境变量配置
# JAVA_HOME
export JAVA_HOME=/opt/pkg/java
PATH=$JAVA_HOME/bin:$PATH
export PATH使新的环境变量立刻生效
$ source /etc/profile.d/env.sh验证环境变量
$ java -version
$ java
$ javac安装Hadoop
下载和解压
从官网下载hadoop-3.1.4.tar.gz上传到服务器,解压到指定目录:
$ tar -zxvf hadoop.tar.gz -C /opt/pkg/编辑/etc/profile.d/env.sh配置文件,添加环境变量:
# HADOOP_HOME
export HADOOP_HOME=/opt/pkg/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH使新的环境变量立刻生效:
$ source /etc/profile.d/env.sh验证:
$ hadoop version修改Hadoop相关命令执行环境
找到Hadoop安装目录下的hadoop/etc/hadoop/hadoop-env.sh文件,找到这一处将JAVA_HOME修改为真实JDK路径即可:
# The java implementation to use.
export JAVA_HOME=/opt/pkg/java找到hadoop/etc/hadoop/yarn.env.sh文件,做同样修改:
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/opt/pkg/java找到hadoop/etc/hadoop/mapred.env.sh,做同样修改:
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/opt/pkg/java修改Hadoop配置
来到 hadoop/etc/hadoop/,修改以下配置文件。
1) hadoop/etc/hadoop/core-site.xml – Hadoop核心配置文件
<configuration>
<!-- 指定NameNode的地址和端口. -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop100:8020</value>
</property>
<!-- 指定HDFS系统运行时产生的文件的存储目录. -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/pkg/hadoop/data/tmp</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整;默认值4096 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟;默认值0 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>注意:主机名要修改成本机的实际主机名。
hadoop.tmp.dir十分重要,此目录下保存hadoop集群中namenode和datanode的所有数据。
2) hadoop/etc/hadoop/hdfs-site.xml – HDFS相关配置
<configuration>
<!-- 设置HDFS中的数据副本数. -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 设置Hadoop的Secondary NameNode的主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop100:9868</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop100:9870</value>
</property>
<!-- 是否检查操作HDFS文件系统的用户权限. -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>dfs.replication默认是3,为了节省虚拟机资源,这里设置为1
全分布式情况下,SecondaryNameNode和NameNode 应分开部署
dfs.namenode.secondary.http-address默认就是本地,如果是伪分布式可以不用配置
3) hadoop/etc/hadoop/mapred-site.xml – mapreduce 相关配置
<configuration>
<!-- 指定MapReduce程序由Yarn进行调度. -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- Mapreduce的Job历史记录服务器主机端口设置. -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop100:10020</value>
</property>
<!-- Mapreduce的Job历史记录的Webapp端地址. -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop100:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/pkg/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/pkg/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/pkg/hadoop</value>
</property>
</configuration> mapreduce.jobhistory相关配置是可选配置,用于查看MR任务的历史日志。
这里主机名千万不要弄错,不然任务执行会失败,且不容易找原因。
需要手动启动MapReduceJobHistory后台服务才能在Yarn的页面打开历史日志。
4) 配置 yarn-site.xml
<configuration>
<!-- 设置Yarn的ResourceManager节点主机名. -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop100</value>
</property>
<!-- 设置Mapper端将数据发送到Reducer端的方式. -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否开启日志手机功能. -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间(7天). -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 如果vmem、pmem资源不够,会报错,此处将资源监察置为false -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
</configuration>5) workers DataNode 节点配置
vi workers
$ vi workers
hadoop100这里单机伪分布式环境可以不进行修改,默认是localhost, 也可以改成本机的主机名。
全分布式配置则需要每行输入一个DataNode主机名。
注意DataNode的主机名中不要有空格和空行,因为其他脚本会获取相关主机名信息。
格式化名称节点
$ hdfs namenode -format
21/01/09 19:27:21 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop100/192.168.186.100
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.3
************************************************************/
21/01/09 19:27:21 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
21/01/09 19:27:21 INFO namenode.NameNode: createNameNode [-format]
Formatting using clusterid: CID-08318e9e-e202-48f3-bcb1-548ca50310c9
21/01/09 19:27:22 INFO util.GSet: Computing capacity for map BlocksMap
21/01/09 19:27:22 INFO util.GSet: VM type = 64-bit
21/01/09 19:27:22 INFO util.GSet: 2.0% max memory 966.7 MB = 19.3 MB
21/01/09 19:27:22 INFO util.GSet: capacity = 2^21 = 2097152 entries
21/01/09 19:27:22 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false
21/01/09 19:27:22 INFO blockmanagement.BlockManager: defaultReplication = 1
21/01/09 19:27:22 INFO blockmanagement.BlockManager: maxReplication = 512
21/01/09 19:27:22 INFO blockmanagement.BlockManager: minReplication = 1
21/01/09 19:27:22 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
21/01/09 19:27:22 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000
21/01/09 19:27:22 INFO blockmanagement.BlockManager: encryptDataTransfer = false
21/01/09 19:27:22 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
21/01/09 19:27:22 INFO namenode.FSNamesystem: fsOwner = hadoop (auth:SIMPLE)
21/01/09 19:27:22 INFO namenode.FSNamesystem: supergroup = supergroup
21/01/09 19:27:22 INFO namenode.FSNamesystem: isPermissionEnabled = false
21/01/09 19:27:22 INFO namenode.FSNamesystem: HA Enabled: false
21/01/09 19:27:22 INFO namenode.FSNamesystem: Append Enabled: true
21/01/09 19:27:23 INFO common.Storage: Storage directory /opt/pkg/hadoop/data/tmp/dfs/name has been successfully formatted.
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop100/192.168.186.100
************************************************************/运行和测试
启动Hadoop环境,刚启动Hadoop的HDFS系统后会有几秒的安全模式,安全模式期间无法进行任何数据处理,这也是为什么不建议使用start-all.sh脚本一次性启动DFS进程和Yarn进程,而是先启动dfs后过30秒左右再启动Yarn相关进程。
1) 启动所有DFS进程:
$ start-dfs.sh
Starting namenodes on [hadoop100]
hadoop100: starting namenode, logging to /opt/pkg/hadoop/logs/hadoop-hadoop-namenode-hadoop100.out
hadoop100: starting datanode, logging to /opt/pkg/hadoop/logs/hadoop-hadoop-datanode-hadoop100.out
Starting secondary namenodes [hadoop100]
hadoop100: starting secondarynamenode, logging to /opt/pkg/hadoop/logs/hadoop-hadoop-secondarynamenode-hadoop100.out2) 启动所有YARN进程:
$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/pkg/hadoop/logs/yarn-hadoop-resourcemanager-hadoop100.out
hadoop100: starting nodemanager, logging to /opt/pkg/hadoop/logs/yarn-hadoop-nodemanager-hadoop100.out启动MapReduceJobHistory后台服务 – 用于查看MR执行的历史日志
$ mr-jobhistory-daemon.sh start historyserver3) 查看是否相关进程都成功启动
执行jps命令,看看是否会有如下进程:
$ jps
14608 NodeManager
14361 SecondaryNameNode
14203 DataNode
14510 ResourceManager
14079 NameNode4) 单一进程管理
# 在主节点上使用以下命令启动 HDFS NameNode:
hdfs --daemon start namenode
# 在主节点上使用以下命令启动 HDFS SecondaryNamenode:
hdfs --daemon start secondarynamenode
# 在从节点上使用以下命令启动 HDFS DataNode:
hdfs --daemon start datanode
# 在主节点上使用以下命令启动 YARN ResourceManager:
yarn --daemon start resourcemanager
# 在从节点上使用以下命令启动 YARN nodemanager:
yarn --daemon start nodemanager以上脚本位于$HADOOP_HOME/sbin/目录下。如果想要停止某个节点上某个进程,只需要把命令中的start 改为stop 即可。
Web界面进行验证
访问http://hadoop100:9870查看HDFS情况
访问http://hadoop100:8088查看YARN情况

测试Hadoop集群
使用官方自带的示例程序测试Hadoop集群
启动DFS和YARN进程,找到测试程序的位置:
$ cd /opt/pkg/hadoop/share/hadoop/mapreduce
$ hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount
Usage: wordcount <in> [<in>...] <out>准备输入文件并上传到HDFS系统
$ cat /opt/data/mapred/input/wc.txt
hadoop hadoop hadoop
hi hi hi hello hadoop
hello world hadoop
$ hadoop fs -mkdir -p /input/wc
$ hadoop fs -put wc.txt /input/wc/
Found 1 items
-rw-r--r-- 1 hadoop supergroup 62 2021-01-09 20:15 /input/wc/wc.txt
$ hadoop fs -cat /input/wc/wc.txt
hadoop hadoop hadoop
hi hi hi hello hadoop
hello world hadoop运行官方示例程序wordcount,并将结果输出到/output/wc之中
$ cd /opt/pkg/hadoop/share/hadoop/mapreduce
$ hadoop jar hadoop-mapreduce-examples-3.1.4.jar wordcount /input/wc/ /output/wc/控制台输出:
2020-01-23 18:38:45,914 INFO client.RMProxy: Connecting to ResourceManager at hadoop100/192.168.186.100:8032
2020-01-23 18:38:47,204 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hadoop/.staging/job_1642908422458_0001
2020-01-23 18:38:47,988 INFO input.FileInputFormat: Total input files to process : 1
2020-01-23 18:38:49,033 INFO mapreduce.JobSubmitter: number of splits:1
2020-01-23 18:38:49,788 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1642908422458_0001
2020-01-23 18:38:49,790 INFO mapreduce.JobSubmitter: Executing with tokens: []
2020-01-23 18:38:50,108 INFO conf.Configuration: resource-types.xml not found
2020-01-23 18:38:50,108 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2020-01-23 18:38:50,740 INFO impl.YarnClientImpl: Submitted application application_1642908422458_0001
2020-01-23 18:38:50,796 INFO mapreduce.Job: The url to track the job: http://hadoop100:8088/proxy/application_1642908422458_0001/
2020-01-23 18:38:50,797 INFO mapreduce.Job: Running job: job_1642908422458_0001
2020-01-23 18:39:09,424 INFO mapreduce.Job: Job job_1642908422458_0001 running in uber mode : false
2020-01-23 18:39:09,425 INFO mapreduce.Job: map 0% reduce 0%
2020-01-23 18:39:19,633 INFO mapreduce.Job: map 100% reduce 0%
2020-01-23 18:39:28,781 INFO mapreduce.Job: map 100% reduce 100%
2020-01-23 18:39:30,812 INFO mapreduce.Job: Job job_1642908422458_0001 completed successfully
2020-01-23 18:39:30,973 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=52
FILE: Number of bytes written=444077
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=165
HDFS: Number of bytes written=30
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=8195
Total time spent by all reduces in occupied slots (ms)=6333
Total time spent by all map tasks (ms)=8195
Total time spent by all reduce tasks (ms)=6333
Total vcore-milliseconds taken by all map tasks=8195
Total vcore-milliseconds taken by all reduce tasks=6333
Total megabyte-milliseconds taken by all map tasks=8391680
Total megabyte-milliseconds taken by all reduce tasks=6484992
Map-Reduce Framework
Map input records=4
Map output records=11
Map output bytes=106
Map output materialized bytes=52
Input split bytes=102
Combine input records=11
Combine output records=4
Reduce input groups=4
Reduce shuffle bytes=52
Reduce input records=4
Reduce output records=4
Spilled Records=8
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=235
CPU time spent (ms)=3340
Physical memory (bytes) snapshot=366059520
Virtual memory (bytes) snapshot=5470892032
Total committed heap usage (bytes)=291639296
Peak Map Physical memory (bytes)=233541632
Peak Map Virtual memory (bytes)=2732072960
Peak Reduce Physical memory (bytes)=132517888
Peak Reduce Virtual memory (bytes)=2738819072
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=63
File Output Format Counters
Bytes Written=30注意,输入是文件夹,可以指定多个。输出是一个必须不存在的文件夹路径。
查看保存在HDFS上的结果:
$ hadoop fs -ls /output/wc/
Found 2 items
-rw-r--r-- 1 hadoop supergroup 0 2021-01-09 20:23 /output/wc/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 30 2021-01-09 20:23 /output/wc/part-r-00000
$ hadoop fs -cat /output/wc/part-r-00000
hadoop 5
hello 2
hi 3
world 1在MR任务执行时,可以通过Yarn的Web UI界面查看进度:
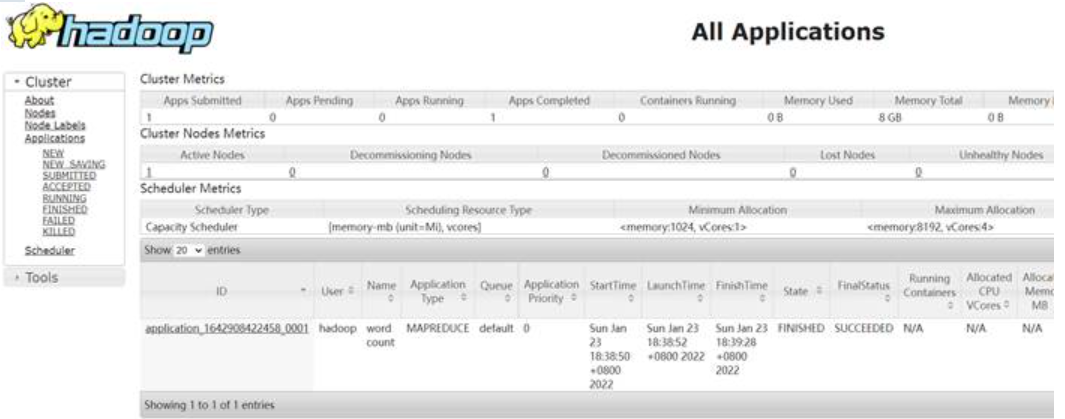
执行完毕以后点击指定MapReduce程序的TrackingUI一栏下的History可以查看历史日志记录

如果跳转页面报404说明没有启动JobHistoryServer服务。
也可以在HDFS的Web界面上查看结果。
位置:Utilities > HDFS browser > /output/wc/ > part-r-00000
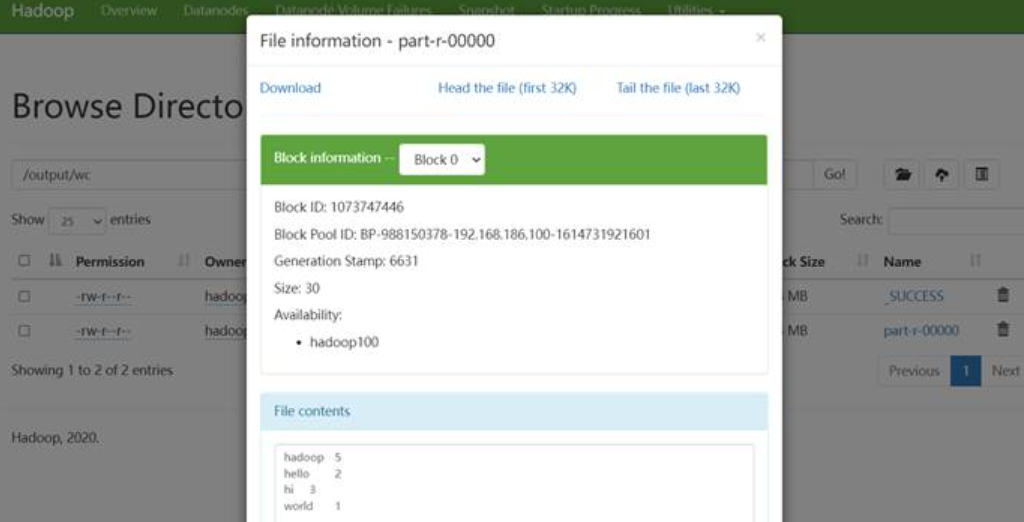
关闭集群
$ stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [hadoop100]
hadoop100: stopping namenode
hadoop100: stopping datanode
Stopping secondary namenodes [hadoop100]
hadoop100: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
hadoop100: stopping nodemanager
no proxyserver to stop安装HBase
Hbase有自带的Zookeeper, 为了更好的使用建议使用自己安装的zookeeper环境.
安装Zookeeper
从官网下载apache-zookeeper-3.5.9-bin.tar.gz,安装到/opt/pkg/zookeeper,单机模式部署,配置文件 $ZOOKEEPER_HOME/conf/zoo.cfg:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/tmp/zookeeper/data
dataLogDir=/opt/tmp/zookeeper/dataLog
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1下载安装包
安装包下载地址:https://www.apache.org/dyn/closer.lua/hbase/2.2.6/hbase-2.2.3-bin.tar.gz
将安装包上传到hadoop100服务器/opt/download路径下,并进行解压:
$ cd /opt/download
$ tar -zxvf hbase-2.2.3-bin.tar.gz -C /opt/pkg/配置HBase
修改HBase配置文件hbase-env.sh
$ cd /opt/pkg/hbase-2.2.3/conf
$ vim hbase-env.sh修改如下两项内容,值如下
export JAVA_HOME=/opt/pkg/java
export HBASE_MANAGES_ZK=false 修改文件hbase-site.xml
$ vim hbase-site.xml内容如下
<configuration>
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop100:8020/hbase</value>
</property>
<!-- 指定hbase是否分布式运行 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zookeeper的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop100:2181</value>
</property>
<!--指定hbase管理页面-->
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<!-- 在分布式的情况下一定要设置,不然容易出现Hmaster起不来的情况 -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>修改regionservers配置文件,指定HBase的从节点主机名:
$ vim regionservers
hadoop100添加HBase环境变量
export HBASE_HOME=/opt/pkg/hbase-2.2.3
export PATH=$PATH:$HBASE_HOME/bin重新执行/etc/profile,让环境变量生效
source /etc/profile HBase的启动与停止:
启动HBase前需要提前启动HDFS及ZooKeeper集群:
如果没开启hdfs,请在运行命令:
$ start-dfs.sh如果没开启zookeeper,请运行命令:
$ zkServer.sh start conf/zoo.cfg执行以下命令启动HBase集群
$ start-hbase.sh启动完后,jps查看HBase相关进程是否都正常运行:
$ jps
7601 QuorumPeerMain
1670 NameNode
1975 SecondaryNameNode
6695 HMaster
6841 HRegionServer
1787 DataNode
2491 JobHistoryServer
2236 ResourceManager
6958 Jps
2351 NodeManager使用HBase提供的Shell客户端进行访问:
$ hbase shell
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.2.3, r6a830d87542b766bd3dc4cfdee28655f62de3974, 2020年 01月 10日 星期五 18:27:51 CST
Took 0.0025 seconds
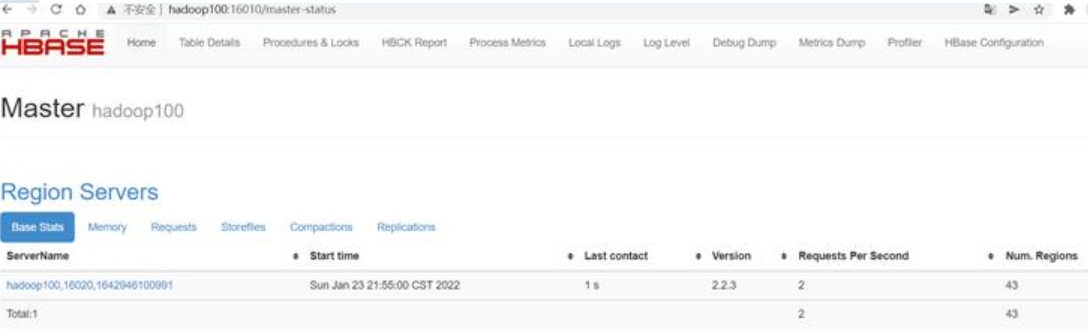
hbase(main):001:0> status访问HBase的WEB UI界面:
浏览器页面访问 http://hadoop100:16010
停止HBase相关进程的命令:
stop-hbase.sh安装MySQL
下载rpm-bundle包
$ wget http://mirrors.163.com/mysql/Downloads/MySQL-5.7/mysql-5.7.33-1.el7.x86_64.rpm-bundle.tar
$ tar xvf mysql-5.7.33-1.el7.x86_64.rpm-bundle.tar
$ mkdir mysql-jars
$ mv mysql-comm*.rpm mysql-jars/
$ cd mysql-jars/
$ ls
mysql-community-client-5.7.33-1.el7.x86_64.rpm
mysql-community-common-5.7.33-1.el7.x86_64.rpm
mysql-community-libs-5.7.33-1.el7.x86_64.rpm
mysql-community-libs-compat-5.7.33-1.el7.x86_64.rpm
mysql-community-server-5.7.33-1.el7.x86_64.rpm依次手动安装
sudo rpm -ivh mysql-community-common-5.7.33-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-libs-5.7.33-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-libs-compat-5.7.33-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-client-5.7.33-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-server-5.7.33-1.el7.x86_64.rpm启动MySQL服务
启动MySQL服务
$ systemctl start mysqld.service或
$ service mysqld start配置开机启动
$ systemctl enable mysqld.service查看运行状态
$ systemctl status mysqld.service
mysql 2574 1 1 23:49 ? 00:00:00 /usr/sbin/mysqld --daemonize --pid-file=/var/run/mysqld/mysqld.pid查看到进程信息
$ sudo netstat -anpl | grep mysql
tcp6 0 0 :::3306 :::* LISTEN 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45824 ESTABLISHED 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45818 ESTABLISHED 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45838 ESTABLISHED 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45808 ESTABLISHED 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45816 ESTABLISHED 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45820 ESTABLISHED 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45826 ESTABLISHED 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45822 ESTABLISHED 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45814 ESTABLISHED 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45846 ESTABLISHED 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45828 ESTABLISHED 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45832 ESTABLISHED 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45842 ESTABLISHED 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45830 ESTABLISHED 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45844 ESTABLISHED 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45812 ESTABLISHED 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45836 ESTABLISHED 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45834 ESTABLISHED 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45840 ESTABLISHED 946/mysqld
tcp6 0 0 192.168.186.100:3306 192.168.186.100:45810 ESTABLISHED 946/mysqld
unix 2 [ ACC ] STREAM LISTENING 20523 946/mysqld /var/lib/mysql/mysql.sock查看端口信息:
可以看出mysql server的进程mysqld所使用的默认端口即3306
$ sudo netstat -anpl | grep tcp
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1412/sshd
tcp 0 52 192.168.186.103:22 192.168.186.1:54058 ESTABLISHED 2287/sshd: hadoop
tcp6 0 0 :::3306 :::* LISTEN 2574/mysqld
tcp6 0 0 192.168.186.103:3888 :::* LISTEN 2060/java
tcp6 0 0 :::22 :::* LISTEN 1412/sshd
tcp6 0 0 :::37791 :::* LISTEN 2060/java
tcp6 0 0 :::2181 :::* LISTEN 2060/java 修改密码
找到临时密码:
第一次登陆mysql需要root的临时密码,这个密码是安装时随机生成在MySQL的服务器日志中的:
$ grep "temporary password" /var/log/mysqld.log
2020-02-26T17:05:45.104999Z 1 [Note] A temporary password is generated for root@localhost: bl/!6qaU.wuX
$ mysql -u roop -p 这时输入临时密码即可登录MySQL客户端。
修改密码安全策略:
第一次登陆MySQL客户端终端后系统会很快提示你修改掉默认密码
mysql> show databases;
ERROR 1820 (HY000): You must reset your password using ALTER USER statement before executing this statement.
mysql> alter user 'root'@'localhost' identified by 'niit1234';
ERROR 1819 (HY000): Your password does not satisfy the current policy requirements基于默认密码安全策略,所设置的密码必须要包含大小写字母、数字和字符。如果不考虑安全问题,可以修改策略:
mysql> set global validate_password_policy=0;
mysql> set global validate_password_length=1;设置新root密码并开启远程权限:
Mysql客户端远程访问因为安全原因默认是关闭的。我们需要将root的访问权限扩大都允许从任意ip访问:
mysql>GRANT ALL PRIVILEGES ON *.* TO 'root'@'%'IDENTIFIED BY 'niit1234' WITH GRANT OPTION;现在虽然修改了远程访问权限,但是还没有生效,因此我们需要刷新权限:
mysql>FLUSH PRIVILEGES;修改默认字符集
修改MySQL配置文件:
vi /etc/my.cnf在文件后面追加:
# 默认服务器内部操作字符集
character-set-server=utf8mb4
# 默认服务器内部操作字符集校对规则
collation-server=utf8mb4_general_ci
# 默认的存储引擎
default-storage-engine=InnoDB
# 初始化连接时设置以下字符集:
# character_set_client
# character_set_results
# character_set_connection
init_connect='set names utf8mb4'
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4重启MySQL服务
$ sudo service mysqld restart安装Hive
下载安装包
从官网下载hive安装包:apache-hive-3.1.2-bin.tar.gz
规划安装目录:/opt/pkg/hive
上传安装包到hadoop100服务器中
解压到安装路径
解压安装包到指定的规划目录/opt/pkg/
$ cd /export/softwares/
$ tar -xzvf apache-hive-3.1.2-bin.tar.gz -C /opt/pkg/修改配置文件
进入hive安装目录:
$ cd /opt/pkg重新命名hive目录:
$ mv apache-hive-3.1.2-bin/hive修改/opt/pkg//conf目录下的hive-site.xml,默认没有该文件, 需要手动创建:
$ cd /opt/pkg/hive/conf/
$ vim hive-site.xml进入编辑模式, 文件内容如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop100:3306/metastore?useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>niit1234</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop100</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
</configuration>创建hive日志存储目录
$ mkdir /opt/pkg/hive/logs/重命名日志配置文件模板为hive-log4j.properties
$ pwd
/opt/pkg/hive/conf
$ mv hive-log4j2.properties.template hive-log4j2.properties
$ vim hive-log4j2.properties # 修改文件修改此文件的hive.log.dir属性的值:
#更改以下内容,设置我们的hive的日志文件存放的路径,便于排查问题
hive.log.dir=/opt/pkg/hive/logs/拷贝mysql驱动包
由于运行hive时,需要向mysql数据库中读写元数据,所以需要将mysql的驱动包上传到hive的lib目录下。
上传mysql驱动包,如mysql-connector-java-5.1.38.jar到/opt/download/目录中:
$ cp mysql-connector-java-5.1.38.jar /opt/pkg/hive/lib/解决日志Jar包冲突
# 进入lib目录
$ cd /opt/pkg/hive/lib/
# 重新命名 或者直接删除
$ mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak配置Hive环境变量
# HIVE
export HIVE_HOME=/opt/pkg/hive
export PATH=$PATH:$HIVE_HOME/bin
# HCATLOG
export HCAT_HOME=$HIVE_HOME/hcatalog
export PATH=$PATH:$HCAT_HOME/bin之后别忘记source使环境变量配置文件的修改生效
初始化元数据库
开启MySQL客户端连接MySQL服务, 用户名root, 密码niit1234,创建hive元数据库, 数据库名称需要和hive-site.xml中配置的一致:
$ mysql -uroot -pniit1234
create database metastore;
show databases;退出mysql:
Exit;初始化元数据库:
$ schematool -initSchema -dbType mysql -verbose看到schemaTool completed 表示初始化成功
启动Hive服务
前提:Hadoop集群、MySQL服务均已启动,执行命令:
nohup hive --service metastore >/tmp/metastore.log 2>&1 &
nohup hive --service hiveserver2 >/tmp/hiveServer2.log 2>&1 &验证Hive安装是否成功
在hadoop100上任意目录启动hive的命令行客户端beeline:
$ beeline
Beeline version 3.1.2 by Apache Hive
beeline> !connect jdbc:hive2://localhost:10000
Connecting to jdbc:hive2://localhost:10000
Enter username for jdbc:hive2://localhost:10000: hadoop
Enter password for jdbc:hive2://localhost:10000: ******
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://localhost:10000> show databases;
+----------------+
| database_name |
+----------------+
| default |
+----------------+
2 rows selected (1.93 seconds)认证时密码直接回车即可, 如果能看到以上信息说明hive安装成功:
退出客户端:
0: jdbc:hive2://localhost:10000> !quit
Closing: 0: jdbc:hive2://localhost:10000 quit;使用beeline连接失败的解决办法
如果hiveserver2已经正常运行在本机的10000端口上, 但使用beeline连接hiveserver2报错, WARN jdbc.HiveConnection: Failed to connect to localhost:10000
主要的原因可能是hadoop引入了用户代理机制, 不允许上层系统直接使用实际用户.
解决办法: 在hadoop的核心配置文件core-site.xml中添加:
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>其中hadoop.proxyuser.XXX的XXX就是代理用户名,我这里设置成hadoop
然后重启hadoop,否则以上修改不生效。
$ stop-all.sh
$ start-dfs.sh
$ start-yarn.sh再次执行下面命令就可以正常连接欸蓝:
beeline -u jdbc:hive2://localhost:10000安装Sqoop
Sqoop下载和安装
下载地址:http://archive.apache.org/dist/sqoop/1.4.7/
wget http://archive.apache.org/dist/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz解压sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz到指定目录下:
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /opt/pkg/修改Sqoop安装目录名称:
$ cd /opt/pkg/
$ mv sqoop-1.4.7.bin__hadoop-2.6.0/ sqoop配置Sqoop环境变量
$ vi ~/.bash_profile
#sqoop
export SQOOP_HOME=/opt/pkg/sqoop
export PATH=$PATH:$SQOOP_HOME/bin把Sqoop所依赖的相关环境变量都配置上,修改sqoop-env.sh:
$ mv conf/sqoop-env-template.sh conf/sqoop-env.sh
$ vi conf/sqoop-env.sh
# Set Hadoop-specific environment variables here.
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/opt/pkg/hadoop
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/opt/pkg/hadoop
#set the path to where bin/hbase is available
export HBASE_HOME=/opt/pkg/hbase
#Set the path to where bin/hive is available
export HIVE_HOME=/opt/pkg/hive
#Set the path for where zookeper config dir is
export ZOOCFGDIR=/opt/pkg/zookeeper/conf修改sqoop-site.xml, 具体配置如下文件所示:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>sqoop.metastore.client.enable.autoconnect</name>
<value>true</value>
<description>If true, Sqoop will connect to a local metastore
for job management when no other metastore arguments are
provided.
</description>
</property>
<property>
<name>sqoop.metastore.client.autoconnect.url</name>
<value>jdbc:hsqldb:file:/tmp/sqoop-meta/meta.db;shutdown=true</value>
<description>The connect string to use when connecting to a
job-management metastore. If unspecified, uses ~/.sqoop/.
You can specify a different path here.
</description>
</property>
<property>
<name>sqoop.metastore.client.autoconnect.username</name>
<value>SA</value>
<description>The username to bind to the metastore.
</description>
</property>
<property>
<name>sqoop.metastore.client.autoconnect.password</name>
<value></value>
<description>The password to bind to the metastore.
</description>
</property>
<property>
<name>sqoop.metastore.client.record.password</name>
<value>true</value>
<description>If true, allow saved passwords in the metastore.
</description>
</property>
<property>
<name>sqoop.metastore.server.location</name>
<value>/tmp/sqoop-metastore/shared.db</value>
<description>Path to the shared metastore database files.
If this is not set, it will be placed in ~/.sqoop/.
</description>
</property>
<property>
<name>sqoop.metastore.server.port</name>
<value>16000</value>
<description>Port that this metastore should listen on.
</description>
</property>
</configuration>修改configure-sqoop:
$ vi bin/configure-sqoop如果没有安装accumulo,则将有关ACCUMULO_HOME的判断逻辑注释掉:
$ vi bin/configure-sqoop
94 #if [ -z "${ACCUMULO_HOME}" ]; then
95 # if [ -d "/usr/lib/accumulo" ]; then
96 # ACCUMULO_HOME=/usr/lib/accumulo
97 # else
98 # ACCUMULO_HOME=${SQOOP_HOME}/../accumulo
99 # fi
100 #fi
140 #if [ ! -d "${ACCUMULO_HOME}" ]; then
141 # echo "Warning: $ACCUMULO_HOME does not exist! Accumulo imports will fail."
142 # echo 'Please set $ACCUMULO_HOME to the root of your Accumulo installation.'
143 #fi这样做的目的是避免将来运行时出现类似下面的警告信息:
Warning: /opt/pkg/sqoop/bin/…/…/accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.将MySQL的驱动(MySQL5.7对应的驱动版本应为5.x版本)上传到Sqoop安装目录下的lib目录下:
$ cp mysql-connector-java-5.1.44-bin.jar /opt/pkg/sqoop/lib/将$HIVE_HOME/lib/hive-common-3.1.2.jar拷贝或者软链接到$SQOOP_HOME/lib下
$ ln -s /opt/pkg/hive/lib/hive-common-3.1.2.jar /opt/pkg/sqoop/lib如果需要解析json,可下载java-json.jar放到sqoop目录下的lib里。
下载地址:http://www.java2s.com/Code/Jar/j/Downloadjavajsonjar.htm
$ cp java-json.jar /opt/pkg/sqoop/lib/如果需要avro序列化,可将hadoop里面的avro的jar包拷贝或者软链接到sqoop目录下的lib里。
$ ln -s /opt/pkg/hadoop/share/hadoop/common/lib/avro-1.7.7.jar /opt/pkg/sqoop/lib/练习
完成以下练习:
练习1:
安装好Sqoop学习环境后使用cd命令进入到sqoop安装目录, 输入以下命令并观察输出:
$ sqoop version
2020-01-23 23:43:20,287 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
Sqoop 1.4.7
git commit id 2328971411f57f0cb683dfb79d19d4d19d185dd8
Compiled by maugli on Thu Dec 21 15:59:58 STD 2017如果输出了类似内容, 表明Sqoop的安装初步完成.
Views: 902