
什么是Spark SQL
Spark SQL是一个用于结构化数据处理的Spark组件。所谓结构化数据,是指具有Schema信息的数据,例如json、parquet、avro、csv格式的数据。与基础的Spark RDD API不同,Spark SQL提供了对结构化数据的查询和计算接口。
Spark SQL的主要特点:
- 将SQL查询与Spark应用程序无缝组合
Spark SQL允许使用SQL在Spark程序中查询结构化数据。与Hive不同的是,Hive是将SQL翻译成MapReduce作业,底层是基于MapReduce;而Spark SQL底层使用的是Spark RDD。例如以下代码,在Spark应用程序中嵌入SQL语句:results = spark.sql( "SELECT * FROM people") - 以相同的方式连接到多种数据源
Spark SQL提供了访问各种数据源的通用方法,数据源包括Hive、Avro、Parquet、ORC、JSON、JDBC等。例如以下代码,读取HDFS中的JSON文件,然后将该文件的内容创建为临时视图,最后与其他表根据指定的字段关联查询://读取JSON文件 val userScoreDF = spark.read.json("hdfs://centos01:9000/people.json") //创建临时视图user_score userScoreDF.createTempView("user_score") //根据name关联查询 val resDF=spark.sql("SELECT i.age,i.name,c.score FROM user_info i " + "JOIN user_score c ON i.name=c.name") - 在现有的数据仓库上运行SQL或HiveQL查询
Spark SQL支持HiveQL语法以及Hive SerDes和UDF(用户自定义函数),允许访问现有的Hive仓库。
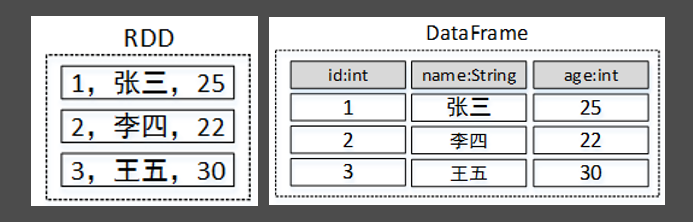
DataFrame和Dataset
DataFrame是Spark SQL提供的一个编程抽象,与RDD类似,也是一个分布式的数据集合。但与RDD不同的是,DataFrame的数据都被组织到有名字的列中,就像关系型数据库中的表一样。此外,多种数据都可以转化为DataFrame,例如:Spark计算过程中生成的RDD、结构化数据文件、Hive中的表、外部数据库等。
DataFrame在RDD的基础上添加了数据描述信息(Schema,即元信息),因此看起来更像是一张数据库表。
Spark SQL基本使用
Spark Shell启动时除了默认创建一个名为“sc”的SparkContext的实例外,还创建了一个名为“spark”的SparkSession实例,该“spark”变量也可以在Spark Shell中直接使用。
SparkSession只是在SparkContext基础上的封装,应用程序的入口仍然是SparkContext。SparkSession允许用户通过它调用DataFrame和Dataset相关API来编写Spark程序,支持从不同的数据源加载数据,并把数据转换成DataFrame,然后使用SQL语句来操作DataFrame数据。
例如,在HDFS中有一个文件/input/person.txt,文件内容:
1,zhangsan,25
2,lisi,22
3,wangwu,30现需要使用Spark SQL将该文件中的数据按照年龄降序排列,步骤:
-
加载数据为Dataset
调用SparkSession的API read.textFile()可以读取指定路径中的文件内容,并加载为一个Dataset:$ spark-shell --master yarn scala> val d1=spark.read.textFile("hdfs://centos01:9000/input/person.txt") d1: org.apache.spark.sql.Dataset[String] = [value: string]从变量d1的类型可以看出,textFile()方法将读取的数据转为了Dataset。除了textFile()方法读取文本内容外,还可以使用csv()、jdbc()、json()等方法读取csv文件、jdbc数据源、json文件等数据。调用Dataset中的show()方法可以输出Dataset中的数据内容。查看d1中的数据内容:
scala> d1.show() +-------------+ | value| +-------------+ |1,zhangsan,25| |2,lisi,22| |3,wangwu,30| +-------------+从上述内容可以看出,Dataset将文件中的每一行看做一个元素,并且所有元素组成了一列,列名默认为“value”。
如果Spark报错
ClassNotFoundException: Class com.hadoop.compression.lzo.Lzo说明Hadoop支持Lzo压缩但是Spark没有配置支持压缩相关的类库,可以修改spark-defaults.conf并添加两行:
spark.driver.extraClassPath /opt/pkg/hadoop/share/hadoop/common/hadoop-lzo-0.4.20.jar spark.executor.extraClassPath /opt/pkg/hadoop/share/hadoop/common/hadoop-lzo-0.4.20.jar -
给Dataset添加元数据信息
定义一个样例类Person,用于存放数据描述信息(Schema):scala> case class Person(id:Int,name:String,age:Int)导入SparkSession的隐式转换,以便后续可以使用Dataset的算子:
scala> import spark.implicits._调用Dataset的map()算子将每一个元素拆分并存入Person类中:
scala> val personDataset=d1.map(line=>{ | val fields = line.split(",") | val id = fields(0).toInt | val name = fields(1) | val age = fields(2).toInt | Person(id, name, age) | })此时查看personDataset中的数据内容,personDataset中的数据类似于一张关系型数据库的表:
scala> personDataset.show() +---+--------+---+ | id| name|age| +---+--------+---+ | 1|zhangsan| 25| | 2| lisi| 22| | 3| wangwu| 30| +---+--------+---+ -
将Dataset转为DataFrame
Spark SQL查询的是DataFrame中的数据,因此需要将存有元数据信息的Dataset转为DataFrame。
调用Dataset的toDF()方法,将存有元数据的Dataset转为DataFrame,代码:scala> val pdf = personDataset.toDF() pdf: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field] -
执行SQL查询
在DataFrame上创建一个临时视图“v_person”,代码:scala> pdf.createTempView("v_person")使用SparkSession对象执行SQL查询,代码:
scala> val result = spark.sql("select * from v_person order by age desc") result: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]调用show()方法输出结果数据,代码:
scala> result.show() +---+--------+---+ | id| name|age| +---+--------+---+ | 3| wangwu| 30| | 1|zhangsan| 25| | 2| lisi | 22| +---+--------+---+可以看到,结果数据已按照age字段降序排列。
-
指定导出文件格式
# 导出json格式文件 scala> result.write.format("json").save("/output/json") # 导出scv格式文件 scala> result.write.format("csv").save("/output/csv") # 导出orc格式文件 scala> result.write.format("orc").save("/output/orc") # 导出parquet格式文件 scala> result.write.format("parquet").save("/output/parquet")查看导出的文件(有几个文件说明有几个分区):
$ hadoop fs -cat /output/json/part-* {"id":3,"name":"wangwu","age":30} {"id":1,"name":"zhangsan","age":25} {"id":2,"name":"lisi","age":22} $ hadoop fs -cat /output/csv/part-* 3,wangwu,30 1,zhangsan,25 2,lisi,22 $ hadoop fs -cat /output/orc/part-* ORC...(二进制乱码) [hadoop@hadoop100 conf]$ hadoop fs -cat /output/parquet/part-* PAR1...(二进制乱码) -
分区设置
Spark中使用SparkSql进行shuffle操作,默认分区数是200个;参数配置是--conf spark.sql.shuffle.partitions, 如果想要修改SparkSQL执行shuffle操作时分区数:-
配置 spark.sql.shuffle.partitions,适用场景spark.sql()合并分区
spark.conf.set("spark.sql.shuffle.partitions", 5) #后面的数字是你希望的分区数这样配置后,通过spark.sql()执行后写出的数据分区数就是你要求的个数,如这里5。
-
配置 coalesce(n),适用场景spark写出数据到指定路径下合并分区,不会引起shuffle
df = spark.sql(sql_string).coalesce(1) #合并分区数 df.write.format("csv") .mode("overwrite") .option("sep", ",") .option("header", True) .save(hdfs_path) -
配置repartition(n), 重新分区,会引发shuffle
df = spark.sql(sql_string).repartition(1) #重新分区,会引发全局shuffle df.write.format("csv") .mode("overwrite") .option("sep", ",") .option("header", True) .save(hdfs_path)
-
-
分区分桶导出
- 并行写出之 partitionBy() 指定分区列 , 会根据分区列创建子文件夹,并行写出数据
df.write.mode("overwrite") .partitionBy("day") .save("/tmp/partitioned-files.parquet") - 并行写出之 repartition() ,一般spark中有几个分区就会有几个并行的IO写出
df.repartition(5) .write.format("csv") .save("/tmp/multiple.csv") - 分桶写出,好处是后续读入的时候数据就不会做shuffle了,因为相同分桶的数据会被划分到同一个物理分区中
csvFile.write.format("parquet") .mode("overwrite") .bucketBy(5, "gmv") #第一个参数:分成几个桶,第二个参数:按哪列进行分桶 .saveAsTable("bucketedFiles")Spark IO相关API请参考:Spark官方API文档Input and Output
- 并行写出之 partitionBy() 指定分区列 , 会根据分区列创建子文件夹,并行写出数据
Spark SQL数据源
Spark SQL支持通过DataFrame接口对各种数据源进行操作。DataFrame可以使用相关转换算子进行操作,也可以用于创建临时视图。将DataFrame注册为临时视图可以对其中的数据使用SQL查询。
Spark SQL提供了两个常用的加载数据和写入数据的方法:load()方法和save()方法。load()方法可以加载外部数据源为一个DataFrame,save()方法可以将一个DataFrame写入到指定的数据源。
1、默认数据源
默认情况下,load()方法和save()方法只支持Parquet格式的文件,也可以在配置文件中通过参数spark.sql.sources.default对默认文件格式进行更改。
Spark SQL可以很容易的读取Parquet文件并将其数据转为DataFrame数据集。例如,读取HDFS中的文件/users.parquet,并将其中的name列与favorite_color列写入HDFS的/result目录,代码:
val spark = SparkSession.builder() //创建或得到SparkSession
.appName("SparkSQLDataSource")
.master("local[*]")
.getOrCreate()
//加载parquet格式的文件,返回一个DataFrame集合
val usersDF = spark.read.load("hdfs://centos01:9000/users.parquet")
usersDF.show()
// +------+--------------+----------------+
// | name|favorite_color|favorite_numbers|
// +------+--------------+----------------+
// |Alyssa| null| [3, 9, 15, 20]|
// | Ben| red| []|
// +------+--------------+----------------+
//查询DataFrame中的name列和favorite_color列,并写入HDFS
usersDF.select("name","favorite_color")
.write.save("hdfs://centos01:9000/result")除了使用select()方法查询外,也可以使用SparkSession对象的sql()方法执行SQL语句进行查询,该方法的返回结果仍然是一个DataFrame。
//创建临时视图
usersDF.createTempView("t_user")
//执行SQL查询,并将结果写入到HDFS
spark.sql("SELECT name,favorite_color FROM t_user")
.write.save("hdfs://centos01:9000/result")2、手动指定数据源
使用format()方法可以手动指定数据源。数据源需要使用完全限定名(例如org.apache.spark.sql.parquet),但对于Spark SQL的内置数据源,也可以使用它们的缩写名(json,parquet,jdbc,orc,libsvm,csv,text)。例如,手动指定csv格式的数据源:
val peopleDFCsv=spark.read.format("csv").load("hdfs://centos01:9000/people.csv")在指定数据源的同时,可以使用option()方法向指定的数据源传递所需参数。例如,向JDBC数据源传递账号、密码等参数:
val jdbcDF = spark.read.format("jdbc")
.option("url", "jdbc:mysql://192.168.1.69:3306/spark_db")
.option("driver","com.mysql.jdbc.Driver")
.option("dbtable", "student")
.option("user", "root")
.option("password", "123456")
.load()3、数据写入模式
在写入数据的同时,可以使用mode()方法指定如何处理已经存在的数据,该方法的参数是一个枚举类SaveMode,其取值解析如下:
SaveMode.ErrorIfExists:默认值。当向数据源写入一个DataFrame时,如果数据已经存在,则会抛出异常。SaveMode.Append:当向数据源写入一个DataFrame时,如果数据或表已经存在,则会在原有的基础上进行追加。SaveMode.Overwrite:当向数据源写入一个DataFrame时,如果数据或表已经存在,则会将其覆盖(包括数据或表的Schema)。SaveMode.Ignore:当向数据源写入一个DataFrame时,如果数据或表已经存在,则不会写入内容,类似SQL中的“CREATE TABLE IF NOT EXISTS”。
例如,HDFS中有一个JSON格式的文件/people.json,内容:
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}现需要查询该文件中的name列,并将结果写入HDFS的/result目录中,若该目录存在则将其覆盖,代码:
val peopleDF = spark.read.format("json").load("hdfs://centos01:9000/people.json")
peopleDF.select("name")
.write.mode(SaveMode.Overwrite).format("json")
.save("hdfs://centos01:9000/result")4、分区自动推断
表分区是Hive等系统中常用的优化查询效率的方法(Spark SQL的表分区与Hive的表分区类似)。在分区表中,数据通常存储在不同的分区目录中,分区目录通常以“分区列名=值”的格式进行命名。例如,以people作为表名,gender和country作为分区列,存储数据的目录结构如下:
path
└── to
└── people
├── gender=male
│ ├── ...
│ │
│ ├── country=US
│ │ └── data.parquet
│ ├── country=CN
│ │ └── data.parquet
│ └── ...
└── gender=female
├── ...
│
├── country=US
│ └── data.parquet
├── country=CN
│ └── data.parquet
└── ...对于所有内置的数据源(包括Text/CSV/JSON/ORC/Parquet),Spark SQL都能够根据目录名自动发现和推断分区信息。分区示例:
-
在本地(或HDFS)新建以下三个目录及文件,其中的目录
people代表表名,gender和country代表分区列,people.json存储实际人口数据:D:\people\gender=male\country=CN\people.json D:\people\gender=male\country=US\people.json D:\people\gender=female\country=CN\people.json三个people.json文件的数据分别如下:
{"name":"zhangsan","age":32} {"name":"lisi", "age":30} {"name":"wangwu", "age":19}{"name":"Michael"} {"name":"Jack", "age":20} {"name":"Justin", "age":18}{"name":"xiaohong","age":17} {"name":"xiaohua", "age":22} {"name":"huanhuan", "age":16} -
执行以下代码,读取表people的数据并显示:
val usersDF = spark.read.format("json").load("D:\\people") //读取表数据为一个DataFrame usersDF.printSchema() //输出Schema信息 usersDF.show() //输出表数据控制台输出的Schema信息如下:
root |-- age: long (nullable = true) |-- name: string (nullable = true) |-- gender: string (nullable = true) |-- country: string (nullable = true)控制台输出的表数据如下:
+----+--------+------+-------+ | age| name|gender|country| +----+--------+------+-------+ | 17|xiaohong|female| CN| | 22| xiaohua|female| CN| | 16|huanhuan|female| CN| | 32|zhangsan| male| CN| | 30| lisi| male| CN| | 19| wangwu| male| CN| |null| Michael| male| US| | 20| Jack| male| US| | 18| Justin| male| US| +----+--------+------+-------+
从控制台输出的Schema信息和表数据可以看出,Spark SQL在读取数据时,自动推断出了两个分区列gender和country,并将该两列的值添加到了DataFrame中。
Parquet文件
Apache Parquet是Hadoop生态系统中任何项目都可以使用的列式存储格式,不受数据处理框架、数据模型和编程语言的影响。Spark SQL支持对Parquet文件的读写,并且可以自动保存源数据的Schema。当写入Parquet文件时,为了提高兼容性,所有列都会自动转换为“可为空”状态。
加载和写入Parquet文件时,除了可以使用load()方法和save()方法外,还可以直接使用Spark SQL内置的parquet()方法,例如以下代码:
//读取Parquet文件为一个DataFrame
val usersDF = spark.read.parquet("hdfs://centos01:9000/users.parquet")
//将DataFrame相关数据保存为Parquet文件,包括Schema信息
usersDF.select("name","favorite_color")
.write.parquet("hdfs://centos01:9000/result")JSON数据集
Spark SQL可以自动推断JSON文件的Schema,并将其加载为DataFrame。在加载和写入JSON文件时,除了可以使用load()方法和save()方法外,还可以直接使用Spark SQL内置的json()方法。该方法不仅可以读写JSON文件,还可以将Dataset[String]类型的数据集转为DataFrame。
需要注意的是,要想成功的将一个JSON文件加载为DataFrame,JSON文件的每一行必须包含一个独立有效的JSON对象,而不能将一个JSON对象分散在多行。例如以下JSON内容可以被成功加载:
{"name":"zhangsan","age":32}
{"name":"lisi", "age":30}
{"name":"wangwu", "age":19}使用json()方法加载JSON数据的例子如下代码所示:
//创建或得到SparkSession
val spark = SparkSession.builder()
.appName("SparkSQLDataSource")
.config("spark.sql.parquet.mergeSchema",true)
.master("local[*]")
.getOrCreate()
/****1. 创建用户基本信息表*****/
import spark.implicits._
//创建用户信息Dataset集合
val arr=Array(
"{'name':'zhangsan','age':20}",
"{'name':'lisi','age':18}"
)
val userInfo: Dataset[String] = spark.createDataset(arr)
//将Dataset[String]转为DataFrame
val userInfoDF = spark.read.json(userInfo)
//创建临时视图user_info
userInfoDF.createTempView("user_info")
//显示数据
userInfoDF.show()
// +---+--------+
// |age| name|
// +---+--------+
// | 20|zhangsan|
// | 18| lisi|
// +---+--------+
/****2. 创建用户成绩表*****/
//读取JSON文件
val userScoreDF = spark.read.json("D:\\people\\people.json")
//创建临时视图user_score
userScoreDF.createTempView("user_score")
userScoreDF.show()
// +--------+-----+
// | name|score|
// +--------+-----+
// |zhangsan| 98|
// | lisi| 88|
// | wangwu| 95|
// +--------+-----+
/****3. 根据name字段关联查询*****/
val resDF=spark.sql("SELECT i.age,i.name,c.score FROM user_info i " +
"JOIN user_score c ON i.name=c.name")
resDF.show()
// +---+--------+-----+
// |age| name|score|
// +---+--------+-----+
// | 20|zhangsan| 98|
// | 18| lisi| 88|
// +---+--------+-----+Hive 表
Spark SQL还支持读取和写入存储在Apache Hive中的数据。然而,由于Hive有大量依赖项,这些依赖项不包括在默认的Spark发行版中,如果在classpath上配置了这些Hive依赖项,Spark将自动加载它们。需要注意的是,这些Hive依赖项必须出现在所有Worker节点上,因为它们需要访问Hive序列化和反序列化库(SerDes),以便访问存储在Hive中的数据。
使用Spark SQL读取和写入Hive数据:
1、创建SparkSession对象
创建一个SparkSession对象,并开启Hive支持,代码:
val spark = SparkSession
.builder()
.appName("Spark Hive Demo")
.enableHiveSupport()//开启Hive支持
.getOrCreate()2、创建Hive表
创建一张Hive表students,并指定字段分隔符为制表符“\t”,代码:
spark.sql("CREATE TABLE IF NOT EXISTS students (name STRING, age INT) " +
"ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'")3、导入本地数据到Hive表
本地文件/home/hadoop/students.txt的内容如下(字段之间以制表符“\t”分隔):
zhangsan 20
lisi 25
wangwu 19将本地文件/home/hadoop/students.txt中的数据导入到表students中,代码:
spark.sql("LOAD DATA LOCAL INPATH '/home/hadoop/students.txt' INTO TABLE students")4、查询表数据
查询表students的数据并显示到控制台,代码:
spark.sql("SELECT * FROM students").show()显示结果:
+--------+---+
| name|age|
+--------+---+
|zhangsan| 20|
| lisi| 25|
| wangwu| 19|
+--------+---+5、创建表的同时指定存储格式
创建一个Hive表hive_records,数据存储格式为Parquet(默认为普通文本格式),代码:
spark.sql("CREATE TABLE hive_records(key STRING, value INT) STORED AS PARQUET")6、将DataFrame写入Hive表
使用saveAsTable()方法可以将一个DataFrame写入到指定的Hive表中。例如,加载students表的数据并转为DataFrame,然后将DataFrame写入Hive表hive_records中,代码:
//加载students表的数据为DataFrame
val studentsDF = spark.table("students")
//将DataFrame以覆盖的方式写入表hive_records中
studentsDF.write.mode(SaveMode.Overwrite).saveAsTable("hive_records")
//查询hive_records表数据并显示到控制
spark.sql("SELECT * FROM hive_records").show()Spark SQL应用程序写完后,需要提交到Spark集群中运行。若以Hive为数据源,提交之前需要做好Hive数据仓库、元数据库等的配置。
JDBC
Spark SQL还可以使用JDBC API从其他关系型数据库读取数据,返回的结果仍然是一个DataFrame,可以很容易地在Spark SQL中处理,或者与其他数据源进行连接查询。在使用JDBC连接数据库时可以指定相应的连接属性,常用的连接属性如表。

使用JDBC API对MySQL表student和表score进行关联查询,代码:
val jdbcDF = spark.read.format("jdbc")
.option("url", "jdbc:mysql://192.168.1.69:3306/spark_db")
.option("driver","com.mysql.jdbc.Driver")
.option("dbtable", "(select st.name,sc.score from student st,score sc " +
"where st.id=sc.id) t")
.option("user", "root")
.option("password", "123456")
.load()上述代码中,dbtable属性的值是一个子查询,相当于SQL查询中的FROM关键字后的一部分。除了上述查询方式外,使用query属性编写完整SQL语句进行查询也能达到同样的效果,代码:
val jdbcDF = spark.read.format("jdbc")
.option("url", "jdbc:mysql://192.168.1.234:3306/spark_db")
.option("driver","com.mysql.jdbc.Driver")
.option("query", "select st.name,sc.score from student st,score sc " +
"where st.id=sc.id")
.option("user", "root")
.option("password", "123456")
.load()Spark SQL内置函数
Spark SQL内置了大量的函数,位于API org.apache.spark.sql.functions中。这些函数主要分为10类:UDF函数、聚合函数、日期函数、排序函数、非聚合函数、数学函数、混杂函数、窗口函数、字符串函数、集合函数,大部分函数与Hive中相同。
使用内置函数有两种方式:一种是通过编程的方式使用;另一种是在SQL语句中使用。例如,以编程的方式使用lower()函数将用户姓名转为小写,代码如下:
//显示DataFrame数据(df指DataFrame对象)
df.show()
// +--------+
// | name|
// +--------+
// |ZhangSan|
// | LiSi|
// | WangWu|
// +--------+
//使用lower()函数将某列转为小写
import org.apache.spark.sql.functions._
df.select(lower(col("name")).as("name")).show()
// +--------+
// | name|
// +--------+
// |zhangsan|
// | lisi|
// | wangwu|
// +--------+Spark SQL自定义函数
当Spark SQL提供的内置函数不能满足查询需求时,用户也可以根据自己的业务编写自定义函数
(User Defined Functions,UDF),然后在Spark SQL中调用。
Spark SQL提供了一些常用的聚合函数,如count()、countDistinct()、avg()、max()、min()等。此外,用户也可以根据自己的业务编写自定义聚合函数(User Defined Aggregate Functions,UDAF)。
UDF主要是针对单个输入,返回单个输出;而UDAF则可以针对多个输入进行聚合计算返回单个输出,功能更加强大。要编写UDAF,需要新建一个类,继承抽象类UserDefinedAggregateFunction,并实现其中未实现的方法。
Spark SQL开窗函数
row_number()开窗函数是Spark SQL中常用的一个窗口函数,使用该函数可以在查询结果中对每个分组的数据,按照其排序的顺序添加一列行号(从1开始),根据行号可以方便的对每一组数据取前N行(分组取TOPN)。row_number()函数的使用格式如下:
row_number() over (partition by 列名 order by 列名 desc) 行号列别名格式说明:
partition by:按照某一列进行分组。order by:分组后按照某一列进行组内排序。desc:降序,默认升序。
Views: 138