
一、课前准备
- 准备一台内存最少8G(建议16G)、cpu i7 4核的电脑
二、课堂主题
- 安装虚拟化软件VMware
- 准备3台linux虚拟机
- 搭建3节点zookeeper集群
- 搭建3节点的hadoop集群
三、课堂目标
- 完成大数据课程课前环境准备
四、知识要点
VMware版本:
VMware建议使用比较新的版本,如VMware 15.5
关于VMware的安装,直接使用安装包一直下一步安装即可,且安装包当中附带破解秘钥,进行破解即可使用linux版本
linux统一使用centos7.6 64位版本
种子文件下载地址:http://mirrors.aliyun.com/centos/7.6.1810/isos/x86_64/CentOS-7-x86_64-DVD-1810.torrent
- 具体实操过程请参考视频
安装hadoop集群时,无论是windows还是mac,都可以参考此文档
3. hadoop集群的安装
- 安装环境服务部署规划
| 服务器IP | node01 | node02 | node03 |
|---|---|---|---|
| HDFS | NameNode | ||
| HDFS | SecondaryNameNode | ||
| HDFS | DataNode | DataNode | DataNode |
| YARN | ResourceManager | ||
| YARN | NodeManager | NodeManager | NodeManager |
| 历史日志服务器 | JobHistoryServer |
第一步:上传压缩包并解压
- 将我们重新编译之后支持snappy压缩的hadoop包上传到第一台服务器并解压;第一台机器执行以下命令
链接:https://pan.baidu.com/s/1sn946HHw0OyJ7YGsOdCdPQ
提取码:yb61
cd /kkb/soft/
tar -xzvf hadoop-3.1.4.tar.gz -C /kkb/install第二步:查看hadoop支持的压缩方式以及本地库
第一台机器执行以下命令
cd /kkb/install/hadoop-3.1.4/
bin/hadoop checknative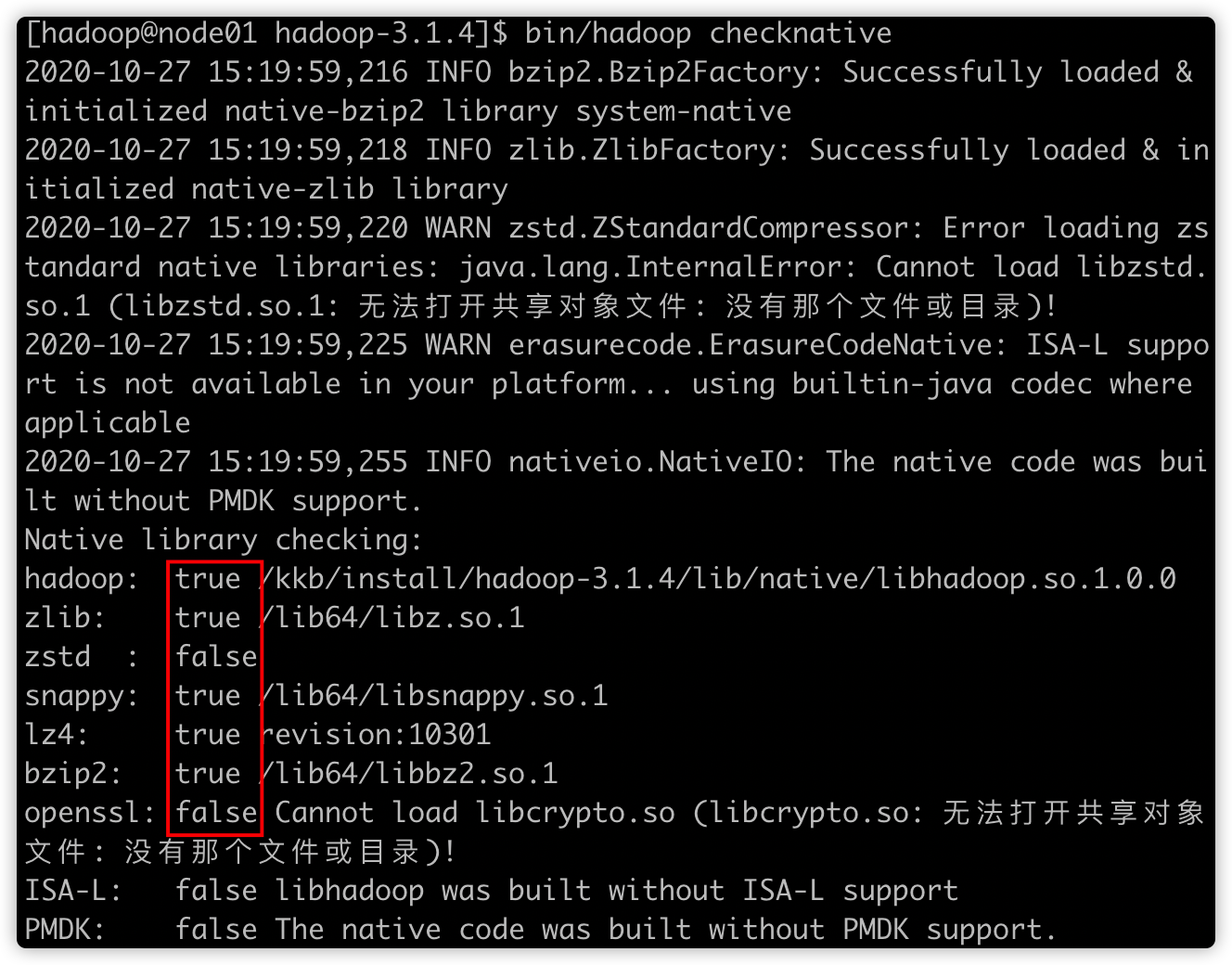
如果出现openssl为false,那么==所有机器==在线安装openssl即可,执行以下命令,虚拟机联网之后就可以在线进行安装了
sudo yum -y install openssl-devel第三步:修改配置文件
修改hadoop-env.sh
第一台机器执行以下命令
cd /kkb/install/hadoop-3.1.4/etc/hadoop/
vim hadoop-env.shexport JAVA_HOME=/kkb/install/jdk1.8.0_141修改core-site.xml
第一台机器执行以下命令
vim core-site.xml<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/kkb/install/hadoop-3.1.4/hadoopDatas/tempDatas</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整;默认值4096 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟;默认值0 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>修改hdfs-site.xml
第一台机器执行以下命令
vim hdfs-site.xml<configuration>
<!-- NameNode存储元数据信息的路径,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<!-- 集群动态上下线
<property>
<name>dfs.hosts</name>
<value>/kkb/install/hadoop-3.1.4/etc/hadoop/accept_host</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/kkb/install/hadoop-3.1.4/etc/hadoop/deny_host</value>
</property>
-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:9868</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node01:9870</value>
</property>
<!-- namenode保存fsimage的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///kkb/install/hadoop-3.1.4/hadoopDatas/namenodeDatas</value>
</property>
<!-- 定义dataNode数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///kkb/install/hadoop-3.1.4/hadoopDatas/datanodeDatas</value>
</property>
<!-- namenode保存editslog的目录 -->
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///kkb/install/hadoop-3.1.4/hadoopDatas/dfs/nn/edits</value>
</property>
<!-- secondarynamenode保存待合并的fsimage -->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///kkb/install/hadoop-3.1.4/hadoopDatas/dfs/snn/name</value>
</property>
<!-- secondarynamenode保存待合并的editslog -->
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///kkb/install/hadoop-3.1.4/hadoopDatas/dfs/nn/snn/edits</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>修改mapred-site.xml
第一台机器执行以下命令
vim mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>修改yarn-site.xml
第一台机器执行以下命令
vim yarn-site.xml<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 如果vmem、pmem资源不够,会报错,此处将资源监察置为false -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
</configuration>修改workers文件
第一台机器执行以下命令
vim workers原内容替换为
node01
node02
node03第四步:创建文件存放目录
第一台机器执行以下命令
node01机器上面创建以下目录
mkdir -p /kkb/install/hadoop-3.1.4/hadoopDatas/tempDatas
mkdir -p /kkb/install/hadoop-3.1.4/hadoopDatas/namenodeDatas
mkdir -p /kkb/install/hadoop-3.1.4/hadoopDatas/datanodeDatas
mkdir -p /kkb/install/hadoop-3.1.4/hadoopDatas/dfs/nn/edits
mkdir -p /kkb/install/hadoop-3.1.4/hadoopDatas/dfs/snn/name
mkdir -p /kkb/install/hadoop-3.1.4/hadoopDatas/dfs/nn/snn/edits第五步:安装包的分发scp与rsync
在linux当中,用于向远程服务器拷贝文件或者文件夹可以使用scp或者rsync,这两个命令功能类似都是向远程服务器进行拷贝,只不过scp是全量拷贝,rsync可以做到增量拷贝,rsync的效率比scp更高一些
1. 通过scp直接拷贝
scp(secure copy)安全拷贝
可以通过scp进行不同服务器之间的文件或者文件夹的复制
使用语法
scp -r sourceFile username@host:destpath用法示例
scp -r hadoop-lzo-0.4.20.jar hadoop@node01:/kkb/node01执行以下命令进行拷贝
cd /kkb/install/
scp -r hadoop-3.1.4/ node02:$PWD
scp -r hadoop-3.1.4/ node03:$PWD2. 通过rsync来实现增量拷贝
rsync 远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
三台机器执行以下命令安装rsync工具
sudo yum -y install rsync(1) 基本语法
node01执行以下命令同步zk安装包
rsync -av /kkb/soft/apache-zookeeper-3.6.2-bin.tar.gz node02:/kkb/soft/命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
选项参数说明
| 选项 | 功能 |
|---|---|
| -a | 归档拷贝 |
| -v | 显示复制过程 |
(2)案例实操
(3)把node01机器上的/kkb/soft目录同步到node02服务器的hadooop用户下的/kkb/目录
rsync -av /kkb/soft node02:/kkb/soft3. 通过rsync来封装分发脚本
我们可以通过rsync这个命令工具来实现脚本的分发,可以增量的将文件分发到我们所有其他的机器上面去
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析:
(a)rsync命令原始拷贝:
rsync -av /kkb/soft hadoop@node02:/kkb/soft(b)期望脚本使用方式:
xsync要同步的文件名称
(c)说明:在/home/hadoop/bin这个目录下存放的脚本,hadoop用户可以在系统任何地方直接执行。
(3)脚本实现
(a)在/home/hadoop目录下创建bin目录,并在bin目录下xsync创建文件,文件内容如下:
[hadoop@node01 ~]$ cd ~
[hadoop@node01 ~]$ mkdir bin
[hadoop@node01 bin]$ cd /home/hadoop/bin
[hadoop@node01 ~]$ touch xsync
[hadoop@node01 ~]$ vim xsync在该文件中编写如下代码
#!/bin/bash #1 获取输入参数个数,如果没有参数,直接退出 pcount=$# if ((pcount==0)); then echo no args; exit; fi #2 获取文件名称 p1=$1 fname=<code>basename $p1echo $fname #3 获取上级目录到绝对路径 pdir=cd -P $(dirname $p1); pwdecho $pdir #4 获取当前用户名称 user=whoami#5 循环 for((host=1; host<4; host++)); do echo ------------------- node0$host -------------- rsync -av $pdir/$fname $user@node0$host:$pdir done
(b)修改脚本 xsync 具有执行权限
[hadoop@node01 bin]$ cd ~/bin/
[hadoop@node01 bin]$ chmod 777 xsync(c)调用脚本形式:xsync 文件名称
[hadoop@node01 bin]$ xsync /home/hadoop/bin/注意:如果将xsync放到/home/hadoop/bin目录下仍然不能实现全局使用,可以将xsync移动到/usr/local/bin目录下
第六步:配置hadoop的环境变量
三台机器都要进行配置hadoop的环境变量
三台机器执行以下命令
sudo vim /etc/profileexport HADOOP_HOME=/kkb/install/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin配置完成之后生效
source /etc/profile第七步:格式化集群
-
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个集群。
-
注意:首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的 HDFS 在物理上还是不存在的。格式化操作只有在首次启动的时候需要,以后再也不需要了
-
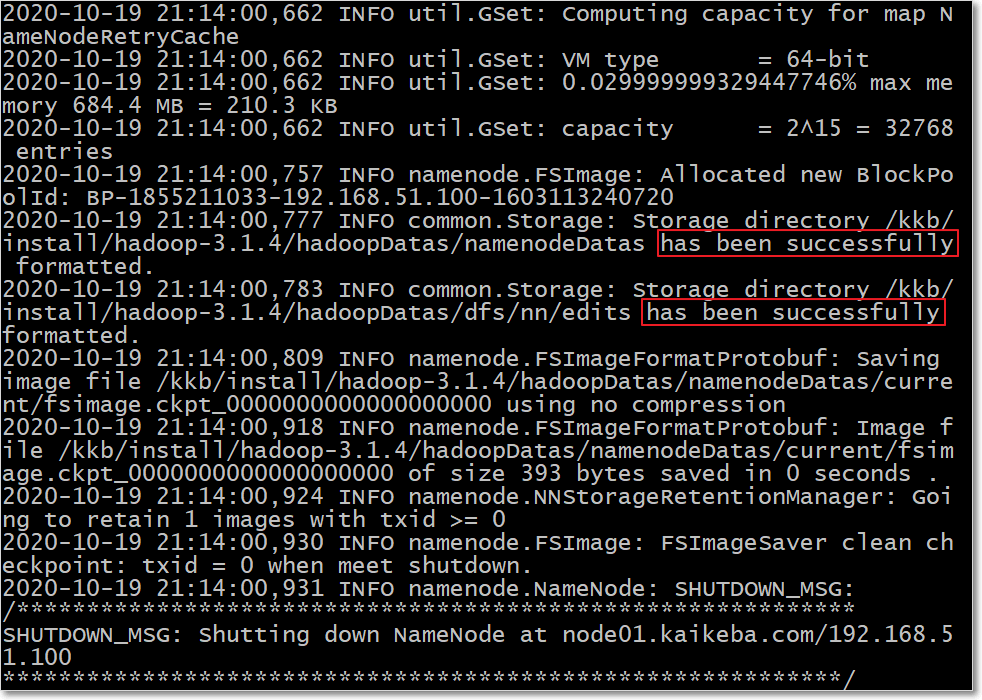
node01执行一遍即可
hdfs namenode -format- 或者
hadoop namenode –format- 下图高亮表示格式化成功;
第八步:集群启动
- 启动集群有两种方式:
- ①脚本一键启动;
- ②单个进程逐个启动
1. 启动HDFS、YARN、Historyserver
-
如果配置了 etc/hadoop/workers 和 ssh 免密登录,则可以使用程序脚本启动所有Hadoop 两个集群的相关进程,在主节点所设定的机器上执行。
-
启动集群
-
主节点node01节点上执行以下命令
start-dfs.sh
start-yarn.sh
# 已过时mr-jobhistory-daemon.sh start historyserver
mapred --daemon start historyserver- 停止集群(主节点node01节点上执行):
stop-dfs.sh
stop-yarn.sh
# 已过时 mr-jobhistory-daemon.sh stop historyserver
mapred --daemon stop historyserver2. 单个进程逐个启动
# 在主节点上使用以下命令启动 HDFS NameNode:
# 已过时 hadoop-daemon.sh start namenode
hdfs --daemon start namenode
# 在主节点上使用以下命令启动 HDFS SecondaryNamenode:
# 已过时 hadoop-daemon.sh start secondarynamenode
hdfs --daemon start secondarynamenode
# 在每个从节点上使用以下命令启动 HDFS DataNode:
# 已过时 hadoop-daemon.sh start datanode
hdfs --daemon start datanode
# 在主节点上使用以下命令启动 YARN ResourceManager:
# 已过时 yarn-daemon.sh start resourcemanager
yarn --daemon start resourcemanager
# 在每个从节点上使用以下命令启动 YARN nodemanager:
# 已过时 yarn-daemon.sh start nodemanager
yarn --daemon start nodemanager
以上脚本位于$HADOOP_HOME/sbin/目录下。如果想要停止某个节点上某个角色,只需要把命令中的start 改为stop 即可。3. 一键启动hadoop集群的脚本
-
为了便于一键启动hadoop集群,我们可以编写shell脚本
-
在node01服务器的/home/hadoop/bin目录下创建脚本
[hadoop@node01 bin]$ cd /home/hadoop/bin/
[hadoop@node01 bin]$ vim hadoop.sh- 内容如下
#!/bin/bash
case $1 in
"start" ){
source /etc/profile;
/kkb/install/hadoop-3.1.4/sbin/start-dfs.sh
/kkb/install/hadoop-3.1.4/sbin/start-yarn.sh
#/kkb/install/hadoop-3.1.4/sbin/mr-jobhistory-daemon.sh start historyserver
/kkb/install/hadoop-3.1.4/bin/mapred --daemon start historyserver
};;
"stop"){
/kkb/install/hadoop-3.1.4/sbin/stop-dfs.sh
/kkb/install/hadoop-3.1.4/sbin/stop-yarn.sh
#/kkb/install/hadoop-3.1.4/sbin/mr-jobhistory-daemon.sh stop historyserver
/kkb/install/hadoop-3.1.4/bin/mapred --daemon stop historyserver
};;
esac- 修改脚本权限
[hadoop@node01 bin]$ chmod 777 hadoop.sh
[hadoop@node01 bin]$ ./hadoop.sh start # 启动hadoop集群
[hadoop@node01 bin]$ ./hadoop.sh stop # 停止hadoop集群第九步:验证集群是否搭建成功
1. 访问web ui界面
- hdfs集群访问地址
- yarn集群访问地址
- jobhistory访问地址:
- 若将linux的
/etc/hosts文件的如下内容,添加到本机的hosts文件中(==ip地址根据自己的实际情况进行修改==)
192.168.51.100 node01.kaikeba.com node01
192.168.51.110 node02.kaikeba.com node02
192.168.51.120 node03.kaikeba.com node03-
windows的hosts文件路径是
C:\Windows\System32\drivers\etc\hosts -
mac的hosts文件是
/etc/hosts -
那么,上边的web ui界面访问地址可以分别写程
- hdfs集群访问地址
- yarn集群访问地址
- jobhistory访问地址:
2. 所有机器查看进程脚本
-
我们也可以通过jps在每台机器上面查看进程名称,为了方便我们以后查看进程,我们可以通过脚本一键查看所有机器的进程
-
在node01服务器的/home/hadoop/bin目录下创建文件xcall
[hadoop@node01 bin]$ cd ~/bin/
[hadoop@node01 bin]$ vim xcall- 添加以下内容
#!/bin/bash
params=$@
for (( i=1 ; i <= 3 ; i = $i + 1 )) ; do
echo ============= node0$i $params =============
ssh node0$i "source /etc/profile;$params"
done- 然后一键查看进程并分发该脚本
chmod 777 /home/hadoop/bin/xcall
xsync /home/hadoop/bin/- 各节点应该启动的hadoop进程如下图
xcall jps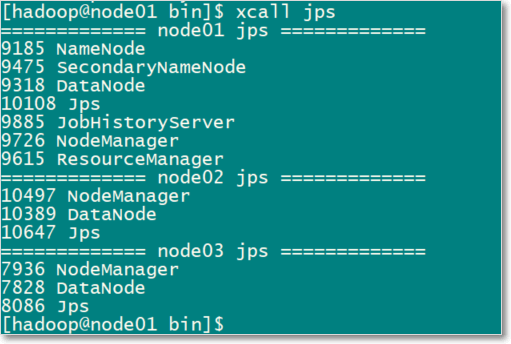
3. 运行一个mr例子
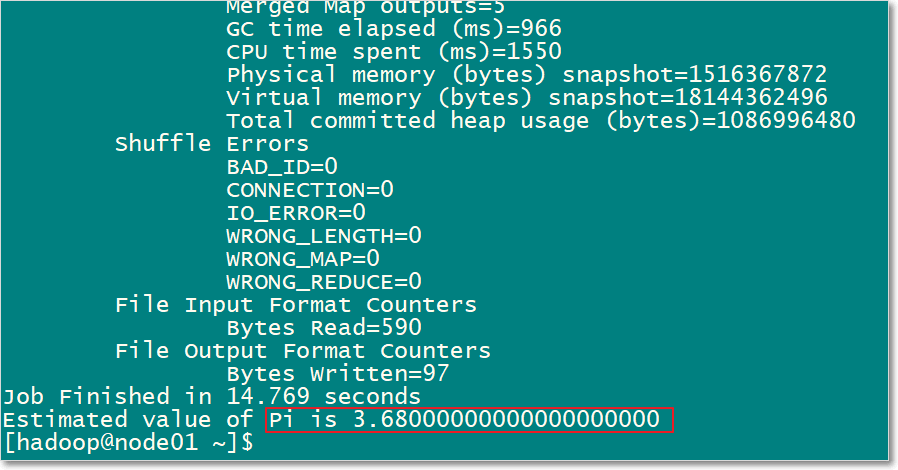
- 任一节点运行pi例子
[hadoop@node01 ~]$ hadoop jar /kkb/install/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar pi 5 5- 最后计算出pi的近似值
提醒:如果要关闭电脑时,清一定要按照以下顺序操作,否则集群可能会出问题
-
关闭hadoop集群
-
关闭虚拟机
-
关闭电脑
Views: 124