
Sqoop导出Hive表到MySQL中
前提
- DFS和Yarn需保持运行状态
- MySQL服务处于运行状态
创建对应的MySQL表
根据Hive中用于存放分析结果的四个表,也同样在MySQL中创建具有相同表结构的四个表
使用Sqoop命令导出
语法
sqoop export \
--connect "jdbc:mysql://hadoop100:3306/job?useSSL=false&characterEncoding=utf-8" \
--username root --password niit1234 \
--table <mysql_table_name> \
--export-dir /user/hive/warehouse/job.db/<hive_table_name>/data_date=<partition_value> \
--input-fields-terminated-by "\001";第一个表
建表
mysql> create table job_count(process_date date,total_job_count int);导出
sqoop export \
--connect "jdbc:mysql://hadoop100:3306/job?useSSL=false&characterEncoding=utf-8" \
--username root \
--password niit1234 \
--table job_count \
--export-dir /user/hive/warehouse/job.db/job_count/data_date=2021-02-28 \
--input-fields-terminated-by "\001"第二个表
建表
mysql> create table job_city_count(process_date date,city varchar(20), total_job_count int);导出
sqoop export \
--connect "jdbc:mysql://hadoop100:3306/job?useSSL=false&characterEncoding=utf-8" \
--username root \
--password niit1234 \
--table job_city_count \
--export-dir /user/hive/warehouse/job.db/job_city_count/data_date=2021-02-28 \
--input-fields-terminated-by "\001"第三个表
建表
create table job_city_salary(process_date date,city varchar(20), job_name varchar(50), salary_per_month int);导出
sqoop export \
--connect "jdbc:mysql://hadoop100:3306/job?useSSL=false&characterEncoding=utf-8" \
--username root \
--password niit1234 \
--table job_city_salary \
--export-dir "/user/hive/warehouse/job.db/job_city_salary/data_date=2021-02-28" \
--input-fields-terminated-by "\001"第四个表
建表
create table job_tag(process_date date,job_tag varchar(50), tag_count int);导出
sqoop export \
--connect "jdbc:mysql://hadoop100:3306/job?useSSL=false&characterEncoding=utf-8" \
--username root \
--password niit1234 \
--table job_tag \
--export-dir "/user/hive/warehouse/job.db/job_tag/data_date=2021-02-28" \
--input-fields-terminated-by "\001"数据可视化展示
superset是由Airbnb(知名在线短租赁公司)开源的数据分析与可视化平台(曾用名Caravel、Panoramix),该工具主要特点是可自助分析、自定义仪表盘、分析结果可视化(导出)、用户/角色权限控制,还集成了一个SQL编辑器,可以进行SQL编辑查询对结果集进行保存可视化等。
启动superset后,打开浏览器访问http://hadoop100:8787
输入用户名(admin)和密码(admin)登陆即可使用superset进行数据可视化展示。
创建数据库连接
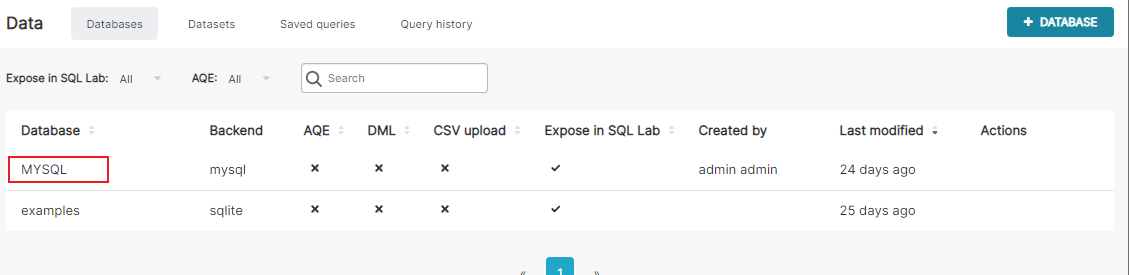
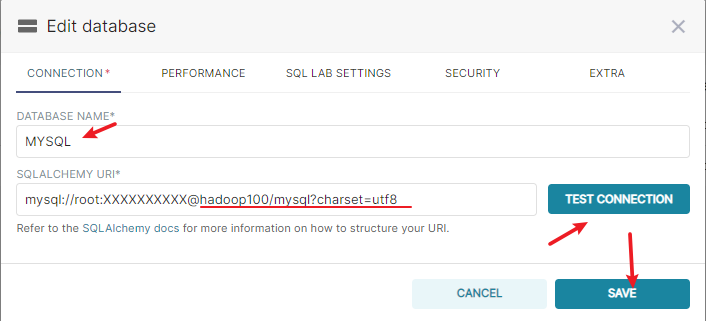
具体配置为
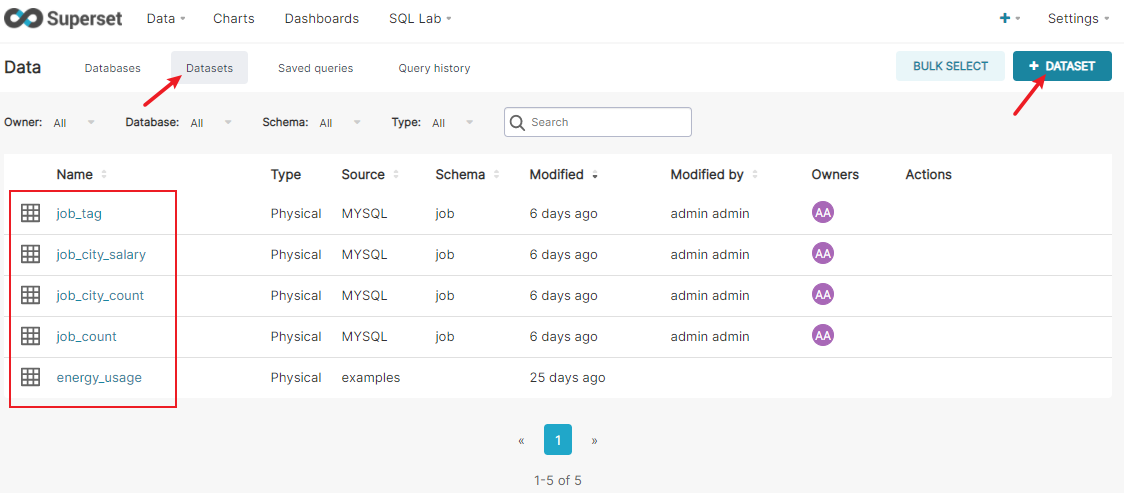
创建数据集
创建图表
根据数据集创建需要展示的图标(Chart)
表1
爬取的总岗位数
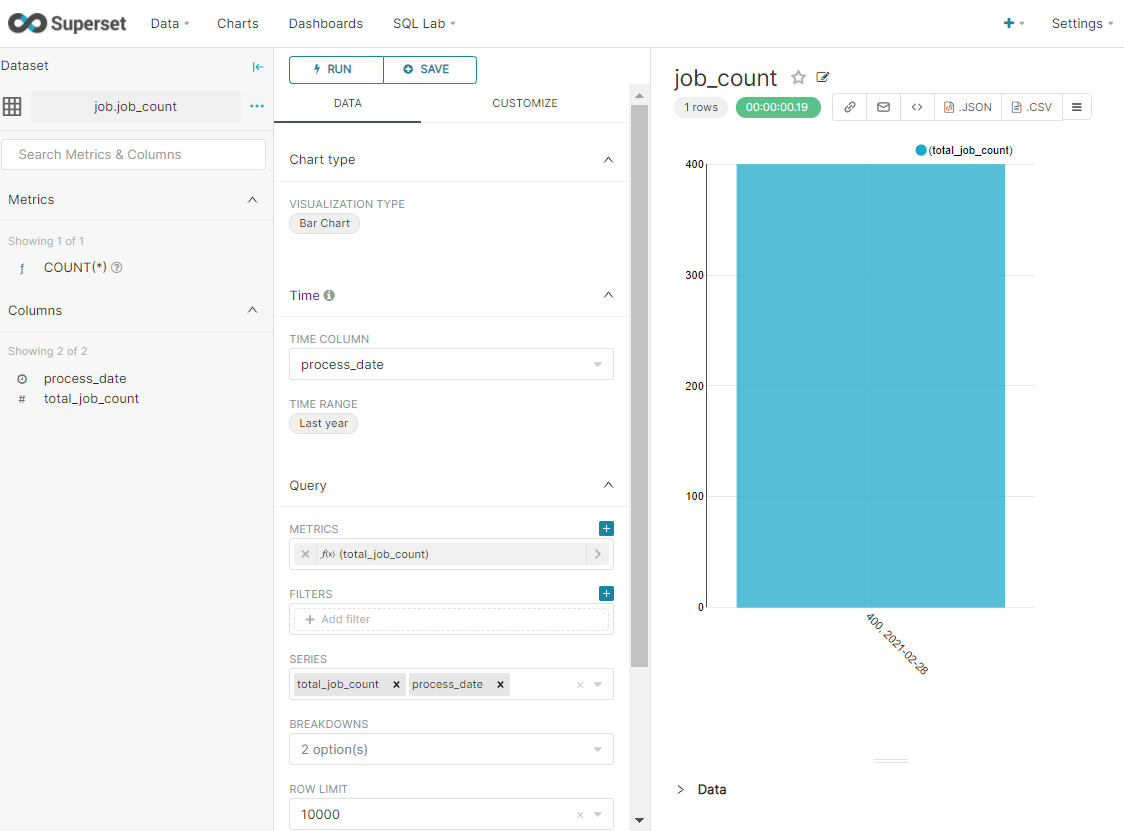
表2
不同城市提供的大数据相关岗位数量比较
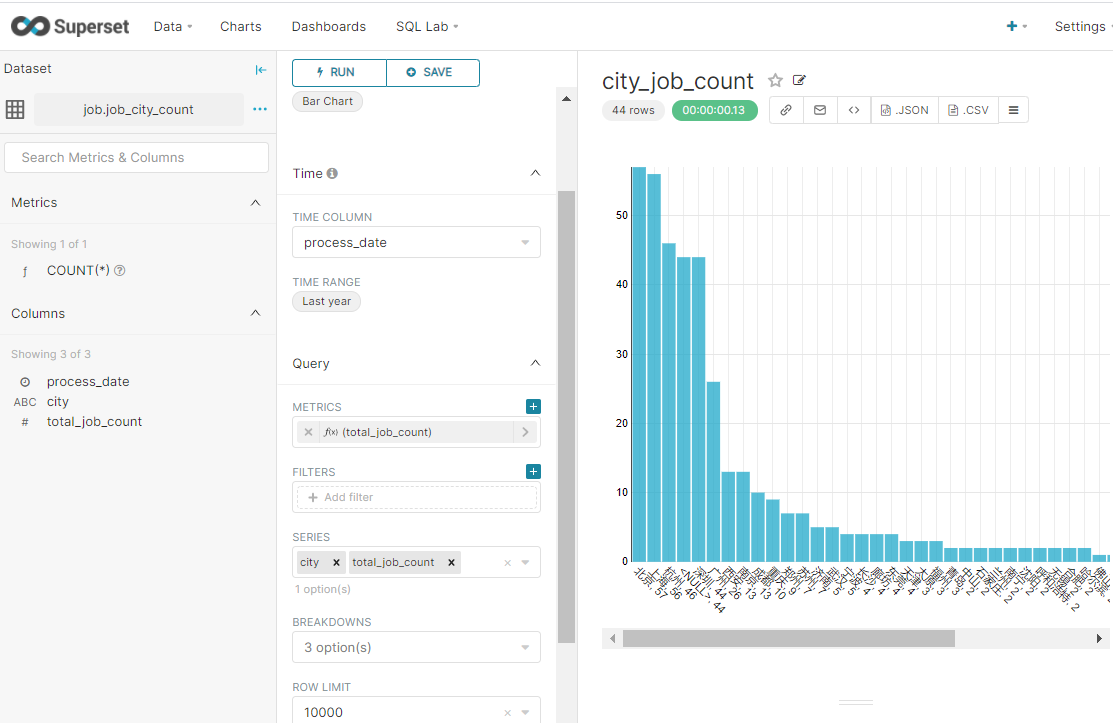
表3
不同城市提供的大数据相关岗位的薪资倒序排列 - 取TopN
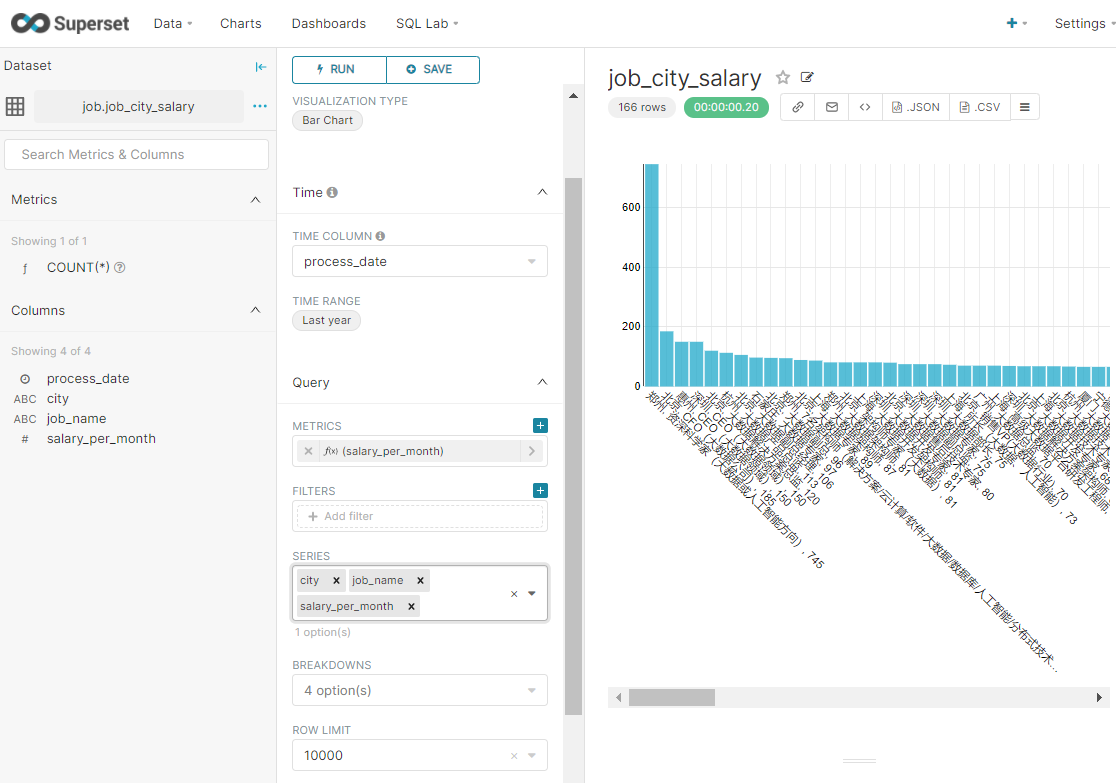
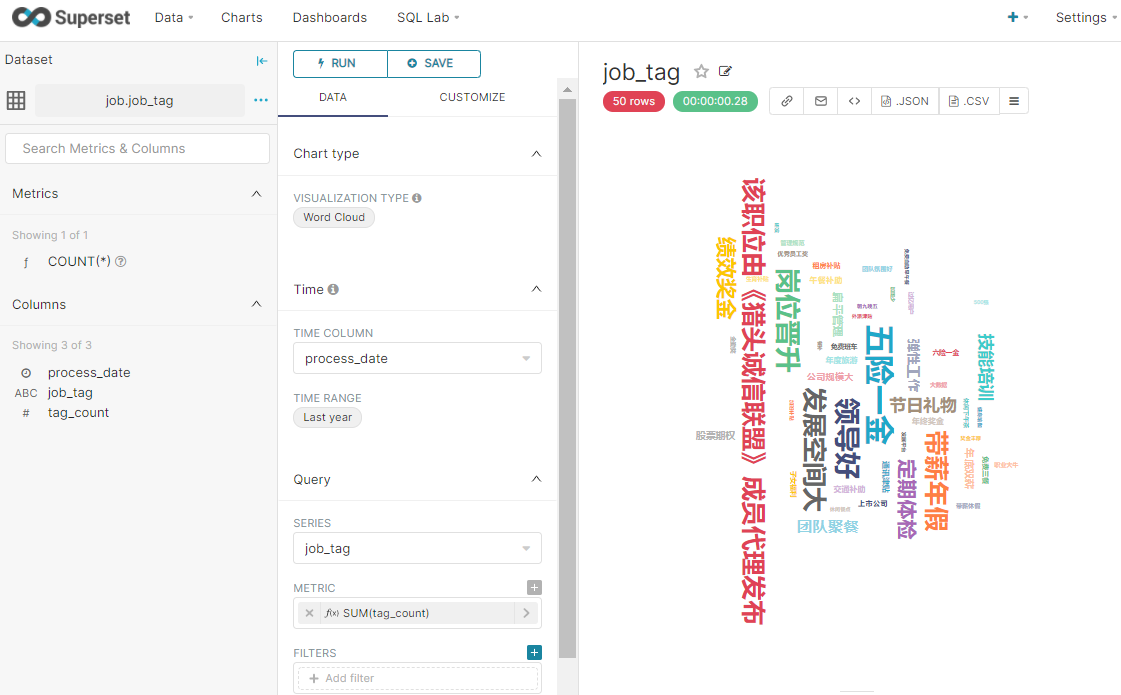
表4
岗位标签做成词云统计
创建仪表盘
仪表盘可以将需要展示的所有图标布局到一起。
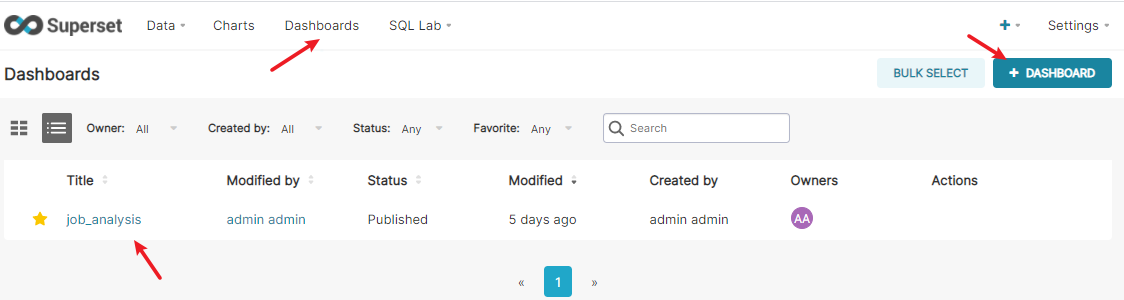
布局后
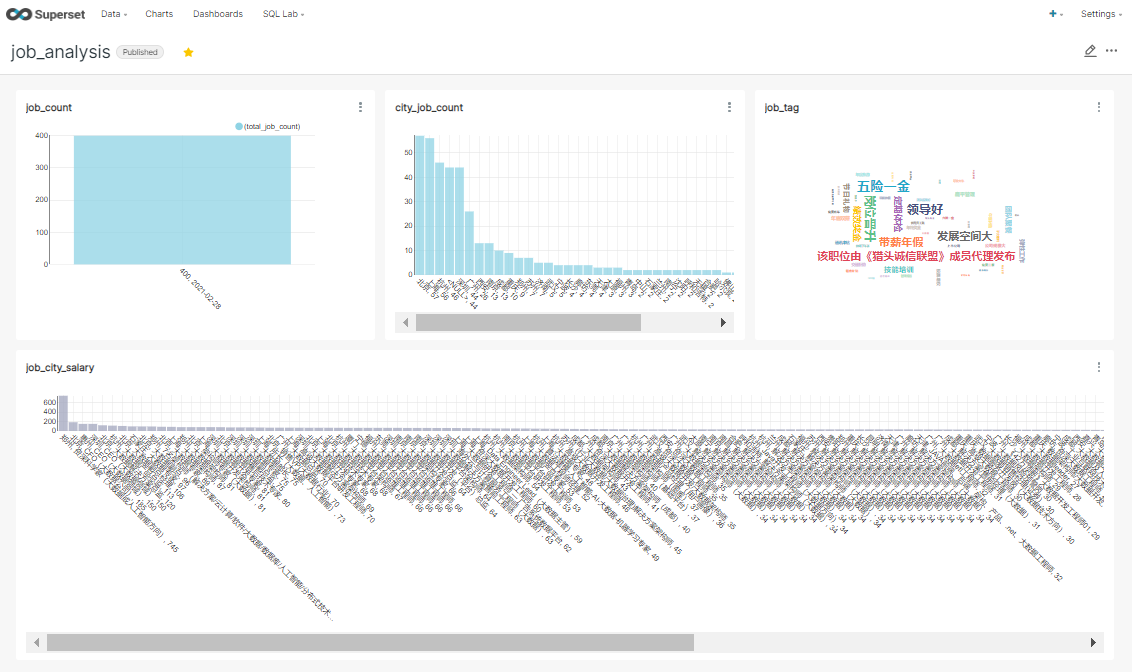
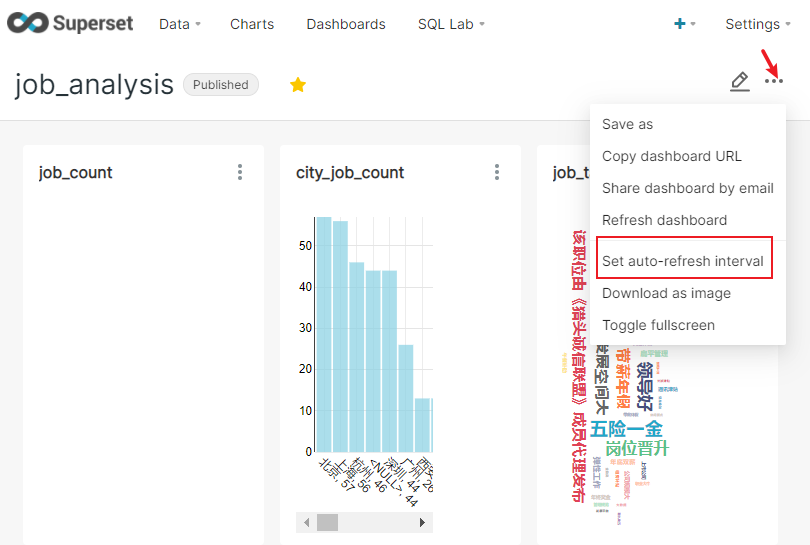
将仪表盘设置为实时更新
如果是需要实时更新数据的表,可以设置同步间隔时间
Views: 82