
程序设计基础总复习
时间地点:
以教务系统为准.
课程得分:
平时: 40%, 考试: 60%
考核方式:
闭卷.
不允许电子设备和纸质材料.
选择题 30个
填空题 10个
判断题 10个
分析题 1个
编程题 2个
使用语言:
标准C语言
编程基础
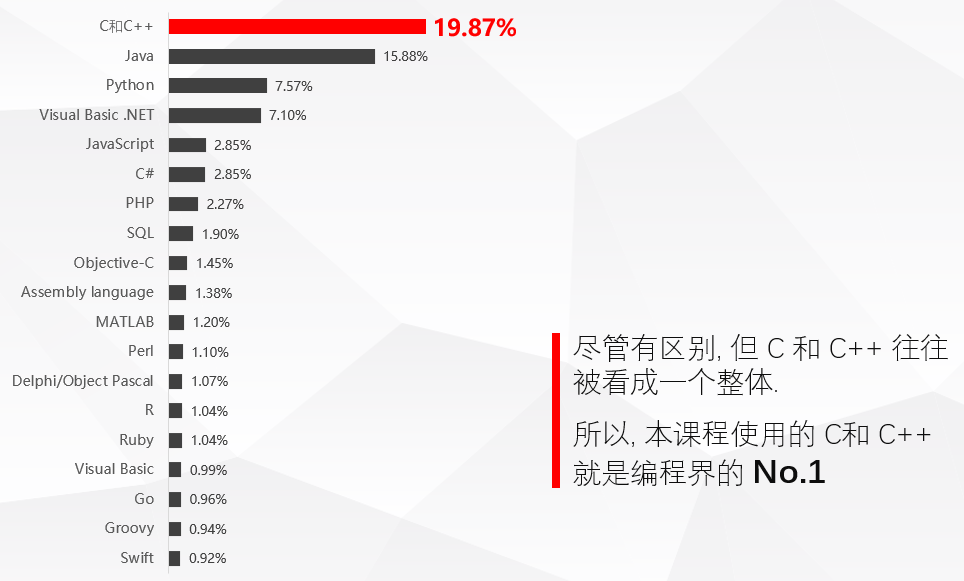
编程语言分类
- 机器语言
0101 - 汇编语言
指令: ADD MOV - 高级语言
C/C++, Python, Java
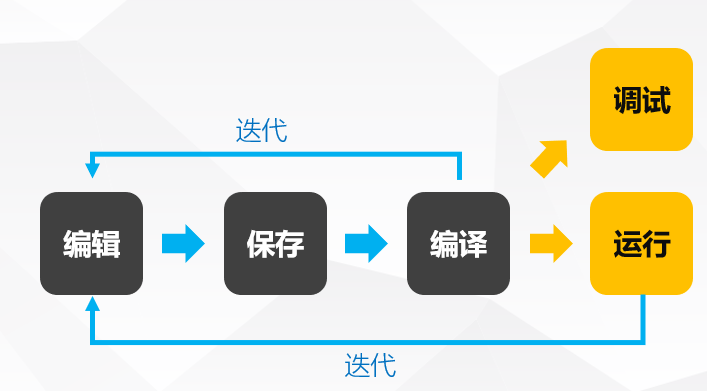
高级语言代码的旅程
常用关键字

sizeof关键字
sizeof是C语言中保留关键字,也是单目运算符。常见的使用方式:
int a=10;
int arr[] = {1, 2, 3};
char str[] = "hello";
int len_a = sizeof(a);
int len_arr = sizeof(arr);
int len_str = sizeof(str)二进制计算
二进制整数最终都是以补码形式出现的.
•正数的补码与原码、反码是一样的.
•负数的补码是反码加 1 的结果.
这种设计, 使得符号位也可以参与运算, 使加法器也能实现减法运算. 在计算机里的任何计算最终都可以变成加法运算, 加法运算是高频率运算, 使用同一个运算器(加法器), 可以减少中间变量存储的开销, 降低CPU内部的设计复杂度, 使计算机内部结构更精简, 计算更高效.
举例使用二进制计算 2 - 3
为了方便演示, 假设存储单元长度为8位
有符号的情况下, 第一位为符号位, 正数符号位为0, 负数符号位为1
计算 2 - 3, 其实就是计算 (+2) + (-3)
+2 原码 (0)000 0010,
+2 补码 (0)000 0010
-3 原码 (1)000 0011,
-3 补码 (1)111 1101
因此当计算机处理 2 - 3的时候, 其实是将 +2 和 -3 的二进制补码相加
0000 0010
+ 1111 1101
-----------
1111 1111
最终结果为 1111 1111(补码), 对应的数值是 -1
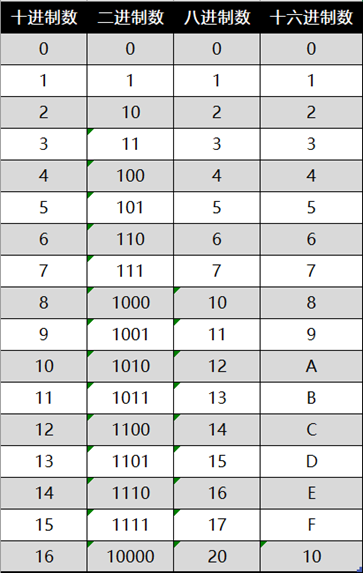
不同进制的比较
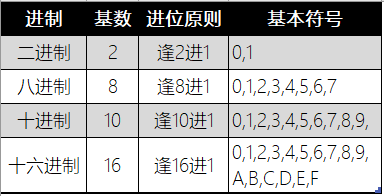
非负数在不同进制下的表示
变量定义
不被初始化的局部变量,其值为随机数
变量作用域
#include <stdio.h>
int a = 1;
int main (){
{
printf("%d", a); // ?
int a = 2;
printf("%d", a); // ?
}
printf("%d", a); // ?
}合法标识符
C语言标识符是指用来标识某个实体的一个符号,在不同的应用环境下有不同的含义,标识符由字母(A-Z,a-z)、数字(0-9)、下划线“_”组成,并且首字符不能是数字,但可以是字母或者下划线($符号也可以)。例如,正确的标识符:abc,a1,prog_to。
另外标识符不可以是关键字.
基本数据类型
-
int整数,在目前绝大多数机器上占
4个字节 -
float单精度浮点数,
4个字节 -
double双精度浮点数,
8个字节 -
char字符,
1个字节表示
256个ASCII字符,或0~255的整数
1 == sizeof(char) <= sizeof(short) <= sizeof(int) <= sizeof(long) <= sizeof(long long).
取值范围
| Data Type | Min Value | Max Value |
|---|---|---|
| short int | 2^15 | 2^1 |
| unsigned short int | 0 | 2^15-1 |
| unsigned char | 0 | 2^8-1 |
数据类型修饰符
-
shortshort int,简写为short短整数,2 个字节
-
longlong int,简写为long
长整数,至少4个字节
long double,长双精度(高精度)
浮点数,至少8字节
-
unsigned | signed用来修饰
char | int | short | longunsigned表示无符号整数(包括正整数和0)signed表示有符号, 因为是默认情况一般省略
字符类型
通过关键字 char 来定义, 如
char c;常用转义字符表
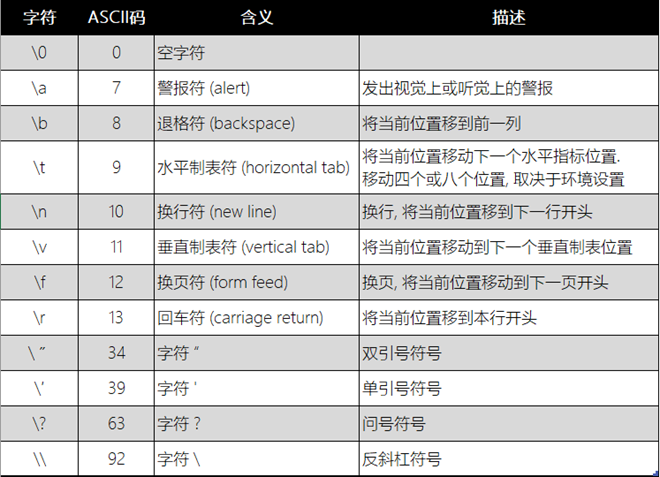
-
8进制转义字符- octal escape sequence8进制数字字符需在前面使用\进行转义 -
16进制转义字符- hexadecimal escape sequence16进制数字字符需在前面使用\x进行转义
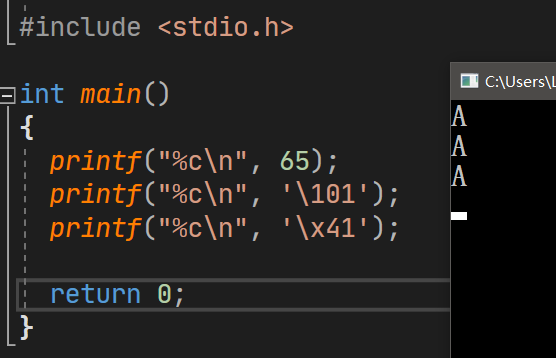
编程思维
- 变量的定义和初始化
- 变量及其作用域
- 基本数据类型
- 前缀
[unsigned/signed] char 固定1字节short [int] 一般2字节int 一般4字节long [int] 一般4字节long long [int] 一般8字节float 一般4字节double 一般8字节long double 一般16字节
- 前缀
- 各类运算符和表达式:
- 算术
+ - * / % - 显示类型转换
- 隐式类型转换
- 赋值
- 自增自减
- 位操作
- 关系运算
- 算术
- 结构化程序设计
- 逻辑运算符和表达式: && || !
- 运算符的优先级
- 分支结构
- if, switch的使用
- 循环结构 for, while, do while的使用
变量
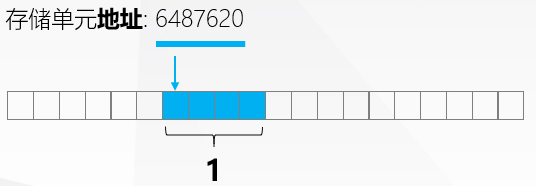
变量的四个属性
int a = 1;-
变量名字: a
-
变量类型: int (4字节)
-
变量值: 1
-
存储单元地址: 6487620
注: 每一个变量要有一个与其它变量不相同的合法名字.
该名字的第一个字符必须是字母或下划线, 其后的字符只能是字母、数字和下划线, 且不得与 C 语言系统所保留的关键字相同.
常量
常量(Constant) 在程序中不能改变其值的量
包括:
-
整型常量
如:
0,67,-2,123L,123u,022,0x12默认为
int85 /* 十进制 */ 0213 /* 八进制 */ 0x4b /* 十六进制 */ 30 /* 整数 */ 30u /* 无符号整数 */ 30l /* 长整数 */ 30ul /* 无符号长整数 */ 212 /* 合法的 */ 215u /* 合法的 */ 0xFeeL /* 合法的 */ 078 /* 非法的八进制没有8*/ -
实型常量
2.3,1.2e-5,2.73F,2.73L默认为
double3.14159 /* 合法的 */ 314159E-5L /* 合法的 */ 510E /* 非法:不完整指数 */ 210f /* 非法:没小数或指数 */ .e55 /* 非法:缺基数(整数或分数) */ -
字符型常量
'z', '3', '$', '\n', '\x41'
用'\'开头的字符为转义字符, 连同之后的字符一起代表1个字符
'\\' \ '\'' ' '\"' " '\?' ? '\a' 警报铃声 '\b' 退格键 '\f' 换页符 '\n' 换行符 '\r' 回车 '\t' 水平制表符 '\v' 垂直制表符 '\ooo' ooo 代表八进制数 '\xhh' hh 代表十六进制数 -
字符串常量
"123", "UKM", "1", "5a"
// 3种写法相同 char c1[] = "hello, dear"; char c2[] = "hello, \ dear"; char c3[] = "hello, " "d" "ear"; -
枚举型常量
enum枚举是 C 语言中的一种基本数据类型,它可以让数据更简洁,更易读。
如果不指定, 第一个枚举成员的默认值为整型的 0,后续枚举成员的值在前一个成员上加 1
enum DAY{ MON=1, TUE, WED, THU, FRI, SAT, SUN};
定义常量
在 C 中,有两种简单的定义常量的方式:
-
使用
#define预处理器#define LENGTH 10 #define WIDTH 5 #define NEWLINE -
使用
const关键字。const int LENGTH = 10; const int WIDTH = 5; const char NEWLINE = '\n';
运算符优先级
表达式有多个运算符时, 需保证计算过程无二义性.
- 通过规定运算符的 “优先级” 和 “结合性” 来保证运算结果的唯一性.
- 对表达式求值, 应先按运算符优先级的高低次序执行.
- 运算符优先级规律:
! > 算术运算符 > 关系运算符 > && > || > 赋值运算符 - 如果操作数两侧的运算符优先级相同, 则按运算符的结合性处理(运算次序由结合方向所决定).
- 对于复杂的运算, 建议使用括号明确表示优先级关系
#include <stdio.h>
int main()
{
int a = 1, b = 2, c = 3;
a + b * c; // 1
a + b - c; // 2
}| 优先级 | 运算符 | 名称或含义 | 使用形式 | 结合方向 | 说明 |
|---|---|---|---|---|---|
| 1 | [] | 数组下标 | 数组名[常量表达式] | 左到右 | -- |
| 1 | () | 圆括号 | (表达式)/函数名(形参表) | 左到右 | -- |
| 1 | . | 成员选择(对象) | 对象.成员名 | 左到右 | -- |
| 1 | -> |
成员选择(指针) | 对象指针->成员名 |
左到右 | -- |
| 2 | - | 负号运算符 | -表达式 | 右到左 | 单目运算符 |
| 2 | ~ | 按位取反运算符 | ~表达式 | 右到左 | 单目运算符 |
| 2 | ++ | 自增运算符 | ++变量名/变量名++ | 右到左 | 单目运算符 |
| 2 | -- | 自减运算符 | --变量名/变量名-- | 右到左 | 单目运算符 |
| 2 | ***** | 取值运算符 | *指针变量 | 右到左 | 单目运算符 |
| 2 | & | 取地址运算符 | &变量名 | 右到左 | 单目运算符 |
| 2 | ! | 逻辑非运算符 | !表达式 | 右到左 | 单目运算符 |
| 2 | (类型) | 强制类型转换 | (数据类型)表达式 | 右到左 | -- |
| 2 | sizeof | 长度运算符 | sizeof(表达式) | 右到左 | -- |
| 3 | / | 除 | 表达式/表达式 | 左到右 | 双目运算符 |
| 3 | ***** | 乘 | 表达式*表达式 | 左到右 | 双目运算符 |
| 3 | % | 余数(取模) | 整型表达式%整型表达式 | 左到右 | 双目运算符 |
| 4 | + | 加 | 表达式+表达式 | 左到右 | 双目运算符 |
| 4 | - | 减 | 表达式-表达式 | 左到右 | 双目运算符 |
| 5 | << | 左移 | 变量<<表达式 | 左到右 | 双目运算符 |
| 5 | >> | 右移 | 变量>>表达式 | 左到右 | 双目运算符 |
| 6 | > | 大于 | 表达式>表达式 | 左到右 | 双目运算符 |
| 6 | >= | 大于等于 | 表达式>=表达式 | 左到右 | 双目运算符 |
| 6 | < | 小于 | 表达式<表达式 | 左到右 | 双目运算符 |
| 6 | <= | 小于等于 | 表达式<=表达式 | 左到右 | 双目运算符 |
| 7 | == | 等于 | 表达式==表达式 | 左到右 | 双目运算符 |
| 7 | != | 不等于 | 表达式!= 表达式 | 左到右 | 双目运算符 |
| 8 | & | 按位与 | 表达式&表达式 | 左到右 | 双目运算符 |
| 9 | ^ | 按位异或 | 表达式^表达式 | 左到右 | 双目运算符 |
| 10 | | | 按位或 | 表达式|表达式 | 左到右 | 双目运算符 |
| 11 | && | 逻辑与 | 表达式&&表达式 | 左到右 | 双目运算符 |
| 12 | || | 逻辑或 | 表达式||表达式 | 左到右 | 双目运算符 |
| 13 | ? : | 条件运算符 | 表达式1?表达式2: 表达式3 | 右到左 | 三目运算符 |
| 14 | = | 赋值运算符 | 变量=表达式 | 右到左 | -- |
| 14 | /= |
除后赋值 | 变量/=表达式 | 右到左 | -- |
| 14 | *= | 乘后赋值 | 变量*=表达式 | 右到左 | -- |
| 14 | %= | 取模后赋值 | 变量%=表达式 | 右到左 | -- |
| 14 | += | 加后赋值 | 变量+=表达式 | 右到左 | -- |
| 14 | -= | 减后赋值 | 变量-=表达式 | 右到左 | -- |
| 14 | <<= |
左移后赋值 | 变量<<=表达式 | 右到左 | -- |
| 14 | >>= |
右移后赋值 | 变量>>=表达式 | 右到左 | -- |
| 14 | &= | 按位与后赋值 | 变量&=表达式 | 右到左 | -- |
| 14 | ^= | 按位异或后赋值 | 变量^=表达式 | 右到左 | -- |
| 14 | |= |
按位或后赋值 | 变量|=表达式 | 右到左 | -- |
| 15 | , | 逗号运算符 | 表达式,表达式,… | 左到右 | -- |
表达式
C语言的表达式由运算符、常量、变量所组成, 以分号结尾.
#include <stdio.h>
int main()
{
int a = 0;
1;
a;
-a + 1;
-a + 2.5 * 3;
return 0;
}
表达式的最基本形式就是一个数据, 也称为操作数, 可以是任意类型的常量或变量.
将操作数与运算符结合, 可以构建一个新的表达式, 继而使用多个运算符连接多个操作数可以形成更为复杂的表达式.
条件表达式
条件操作符(? :)中的第一个操作数,逻辑非(!)、逻辑与(&&)、逻辑或(||)的操作数都是条件表达式。if、while、do while、以及for的第2个表达式都是条件表达式。
在C语言里, 条件表达式返回0时表示为假(0), 返回非0时表示为真(1).
printf("%d\n", 2 == 1 + 1); // 1复合赋值
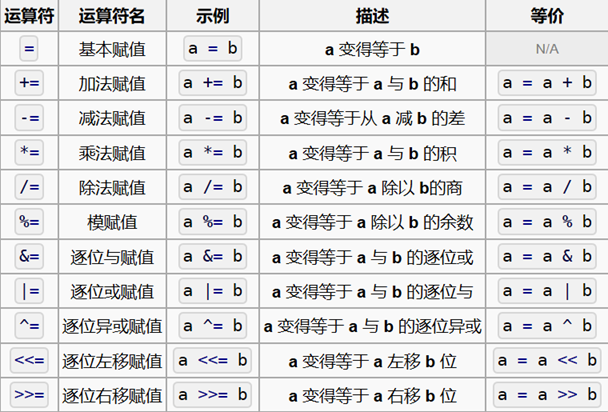
隐式类型转换
隐式类型转换可以发生在:运算、赋值、函数参数、函数返回值时, 具体是在
- 运算时操作数之间类型不同时
- 赋值时表达式返回类型和接受变量类型不同时
- 实参类型和形参类型不同时
- 函数实际返回类型和定义返回类型不同时
转换后的类型范围更大, 精度更高.
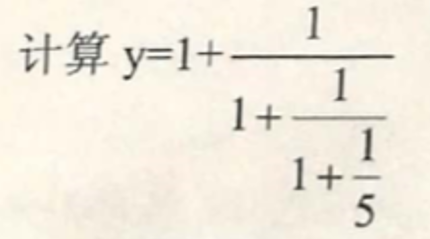
1 / 5; // int
1 / 5.0; // double 0.2举例
int ival; double dval;
ival >= dval; // int -> double整形提升
-
算术转换通常的是做整型提升
- integral promotion
int ival = 3.14; // 3.14 -> int
int *ip = 0; // 0 -> NULL ptr流程控制
C语言的流程控制结构主要分为:顺序结构,选择(分支)结构,循环结构.
其中选择结构和循环结构可以互相任意嵌套
分支
if语句
// 语句可以是单独的一条语句
// 也可以是{}包围的一条复合语句
if (条件表达式)
语句;
// else 总是向上匹配距离最近的 if
if (条件表达式)
语句1;
else
语句2;
// 三元运算符可以替换简单的 if else
int a = 3, b = 5, max;
if (a > b) max = a; else max = b;
// 等同于
max = a > b ? a : b;
// 多分支, else if 可以多个
if (条件表达式)
语句;
else if (条件表达式)
语句;
else if (条件表达式)
语句;
else
语句;注意条件判断是有顺序的, 如果命中了一个判断条件, 则会跳过其他的判断.
举例: foo bar baz 问题
这是一个国外非常常见的编程面试题: 遍历打印数字1至数字50, 遇到能被3整除的打印'foo'、遇到能被5整除的打印'bar'、遇到即能被3整除也能被5整除的打印'baz'。
#include <stdio.h>
int main()
{
int i;
for (i = 1; i <= 50; i++)
{
if (i % 3 == 0 && i % 5 == 0)
puts("baz");
else if (i % 3 == 0)
puts("foo");
else if (i % 5 == 0)
puts("bar");
else
printf("%d\n", i);
}
return 0;
}
输出
1
2
foo
4
bar
foo
7
8
foo
bar
11
foo
13
14
baz
16switch语句
switch语句 只能对 返回整形(枚举返回的也是整形)的条件表达式 进行 相等判断

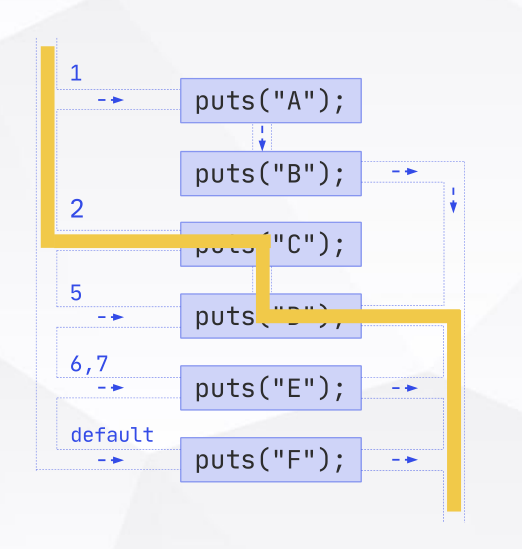
为了避免出错, 除了一些特殊情况外, 每一个case都应该用break结束
循环
for循环语句
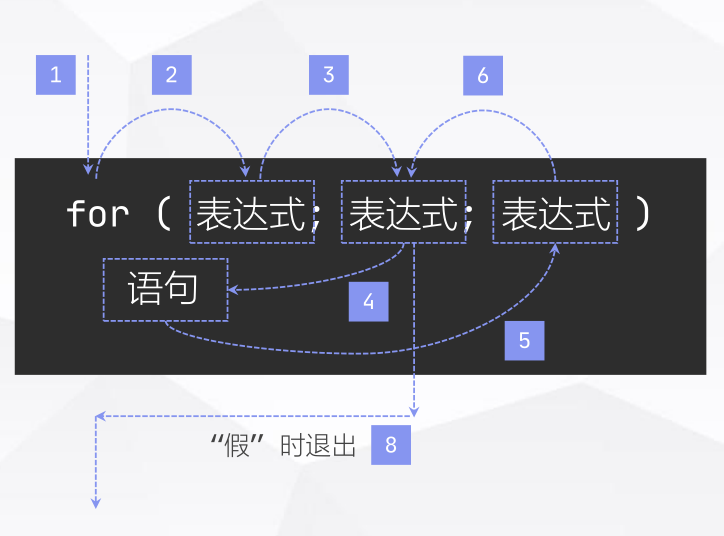
break VS continue
-
都在循环体内出现
-
break: 无条件退出该层循环,循环控制变量不再起作用 -
continue: 并不退出该层循环,只是不再执行循环体中位于其后的语句,循环控制变量仍然起作用。
while 当循环
先检测 表达式 的值, 如果为 非0 则执行循环体中的 语句,如果为 0 则跳出循环过程
语法:
while (表达式)
{
语句
};do while 直到循环
先执行do里面的语句, 然后检查条件表达式的结果, 如果为 非0 继续循环,如果为 0 则跳出循环过程, 直到型循环可以保证至少执行语句一次.
语法:
do
{
语句
} while (表达式);最后的分号别忘了添加.
枚举算法
有序地去尝试每一种可能
所有的可能都一一验证.
把重复的工作交给计算机去完成.
// 伪代码
for (ans in allCandidates)
{
if (ans is answer)
{
output ans;
}
}等式填数
在两个□内填入相同的数字, 使得以下等式成立:
_3 X 6528 = 3_ X 8256
如果有多个答案, 要求从小到大列出所有满足条件的等式. 例如:
43 X 6528 = 34 X 8256
过滤法(筛法)
在循环里面添加判断, 例如找出1-100之间的所有合数, 就可以通过筛去所有素数得到
#include <stdio.h>
#include <math.h>
int main()
{
int nums[101] = {0};
for (int i = 2; i < 101; i++)
{
int divisor = 2;
while (divisor <= sqrt(i))
{
if (i % divisor == 0)
{
nums[i] = 1;
break;
}
divisor++;
}
}
for (int i = 2; i < 101; i++)
printf("%d\t是%s\n", i, (nums[i] ? "合数" : "质数"));
return 0;
}
函数和递归
- 函数的定义: 名字, 形参列表, 返回值类型
- 形参与实参概念和使用
- 值传递和引用传递
- 递归函数的特点
- 熟记经典问题及其递归解法
- 斐波那契序列, 汉诺塔, 8皇后…
求和函数定义示例
int sum (int x, int y)
{
int z;
z = x + y;
return z;
}函数首部 即"{}"以上的一行说明, 包括: 返回值类型、函数名、形式参数列表;
函数体 则是从"{"开始, 到"}"结束的代码块, 函数体又分为声明部分和语句部分
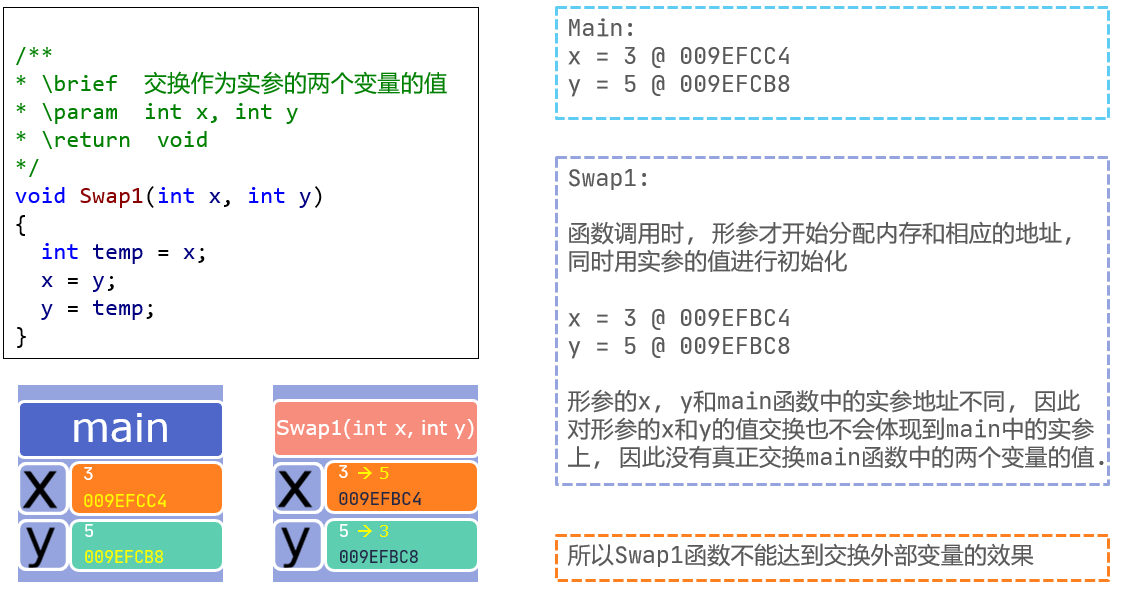
函数参数传递
- 声明和定义时: 形参
- 调用时: 实参
- 形参是在函数被调用时才分配形参的存储单元.
- 实参可以是常量、变量或表达式.
- 实参类型必须与形参相符.
#include <stdio.h>
void AddOne(int a) // a 形参
{
a++;
printf("a=%d", a);
}
int main()
{
int x = 1;
AddOne(x); // x 实参
printf("x=%d", x);
}
数组作为参数
数组作为函数参数时,在函数内对数组名进行sizeof运算的结果总为4(目标编译平台是32位时)
这是因为,函数中的指针传递本质上也是属于值传递(指针变量的地址), 编译器并不会检查数组的长度. – 导致在函数内部数组退化成指针.
对编译器来说下面的三个定义并没有什么区别:
void Test( char array[20]);
void Test( char array[]);
void Test( char* const array);这也是为什么C语言的很多函数在需要数组作为参数时需要同时传入数组名和数组大小作为形参.
void putValues(int arr[], int size);函数返回值
在绝大多数情况下,函数定义的返回值类型与 return 语句中返回值的数据类型必须是一致的.
函数定义的返回值类型, 与return语句中返回值的数据类型不一致时, 以函数定义的返回值类型为准.
编译器先尝试将return语句中的返回值隐式转换为函数定义的返回值类型, 然后再返回给主调对象, 如果不能完成转换, 编译器将会报错.
#include <stdio.h>
int AddTwo(short a, short b)
{
return a + b; // short -> int
}
int main()
{
short a = 2, b = 3;
printf("x=%d", AddTwo(a, b));
}void类型
void 被翻译为"无类型",相应的void * 为"无类型指针"。常用在程序编写中对定义函数的参数类型、返回值、函数中指针类型进行声明。
void的作用
-
当函数不需要返回值值时,必须使用
void限定,这就是我们所说的第一种情况。例如:void func(int a,char *b) -
当函数不允许接受参数时,必须使用
void限定,这就是我们所说的第二种情况。例如:int func(void) -
当没有定义函数返回值时,
C语言默认返回值类型是int, 而C++是void
递归调用
- 递归就是函数直接或者间接调用自身
- 递归利用了函数调用栈, 如果调用层级过深会导致堆栈溢出错误 -
Stack Overflow - 递归必须有出口, 如果没有出口就会出现无限循环调用, 同样会导致堆栈溢出.
- 递归函数必须带有形参, 递归过程中的每一次调用必须调整函数的参数使问题范围越缩越小, 小到可以直接解决为止(到达出口).
- 递归函数根据情况可以有返回值, 也可以没有返回值
// 返回n的阶乘 - 递归的方式
// n > 1
long double f(const int n)
{
if (n == 1)
return 1;
return f(n - 1) * n;
}递归过程

递归是自顶向下解决问题, 将大问题化解成小问题, 小问题解决了, 反过来大问题就解决了, 和迭代相比递归的代码量一般会更少, 逻辑更清晰, 符合人类思维方式, 可读性更好.
数组
- 数组的定义和初始化
- 数组下标的使用(从0开始)
- 一维数组、二维数组
- 数组作为函数形参
- 常用数组元素的排序方法及其代码
- 已排序数组元素的折半查找
- 指针, 地址
何为数组
数组 (array) 是一种数据格式, 能够存储多个同类型的值, 数组在定义时就要确定空间大小, 里面的元素在内存上是连续的.
- 可以将数组中的每个元素看做一个简单的变量.
- 数组是具有一定顺序关系的若干相同类型变量的集合体, 组成数组的变量称为该数组的元素.
- 数组还被称为复合类型, 时因为它是使用其他类型来创建的.
- 数组的元素在逻辑上是连续, 在物理上也是连续的, 通过下标即可快速计算出指定元素的位置.
一维数组的顺序存储
数组元素在内存中顺次存放, 它们的地址时连续的:
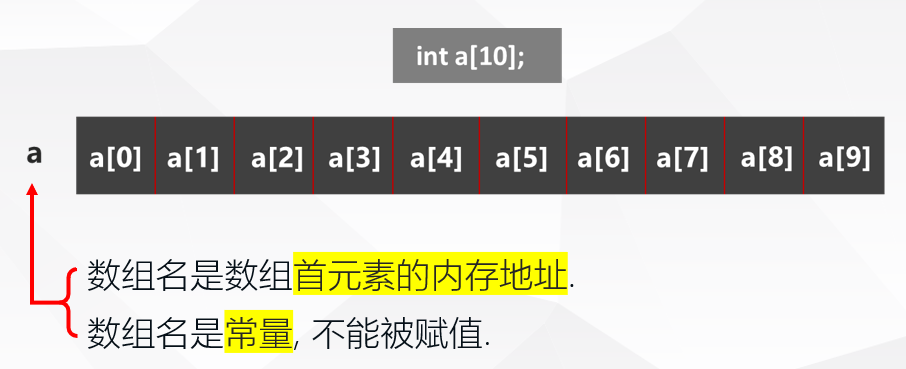
下标越界检查?
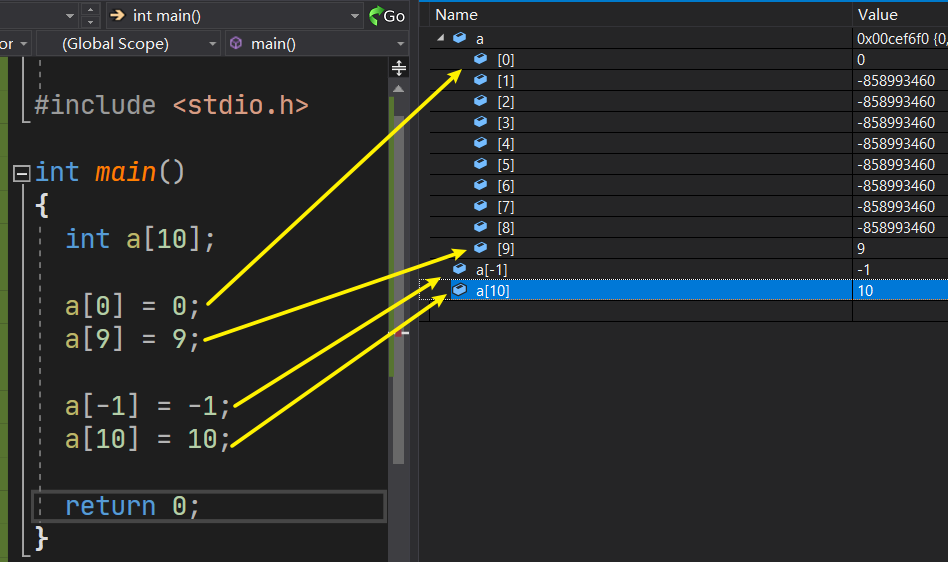
不存在的. C语言编译器不会帮你检查使用的下标是否有效.
例如, 如果将一个值赋给不存在的元素 a[10], 编译器并不会指出错误. 但是程序运行后, 这种赋值可能会引发问题, 它可能破坏数据或代码, 也可能导致程序异常终止.
所以必须确保程序只使用有效的下标.
数组初始化
-
在声明数组时对数组元素赋以初值. 例如:
int a[10]={1, 2, 3, 4, 5, 6, 7, 8, 9,10}; -
可以只给一部分元素赋初值.
int a[10]={1, 3, 5, 7}; int a[10]={0}; -
在对全部数组元素赋初值时, 可以不指定数组长度.
int a[]={1, 2, 3, 4, 5, 6, 7, 8, 9, 10}使用
memset函数对数组初始化
使用memset函数, 调用此库函数需要加入头文件<memory.h>
用法: memset(数组名,初始化值,sizeof(数组名))
int arr[];
// 初始化成 0
memset(arr, 0, sizeof( arr ));
// 初始化成 -1
memset(arr, -1, sizeof( arr ));
// 注意, 这样不能初始化成 1
// 实际初始化成了 16843009
memset(arr, 1, sizeof( arr ));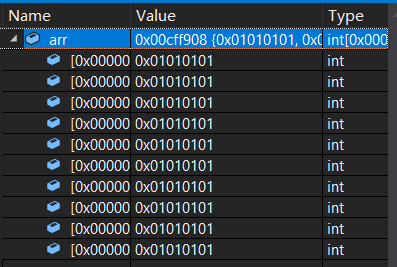
数组下标使用
&a[x] = a + x * sizeof(a[0]);二维数组
二维数组本质上也是一维数组, 数组元素在内存中顺次存放, 它们的地址是连续的. 例如:
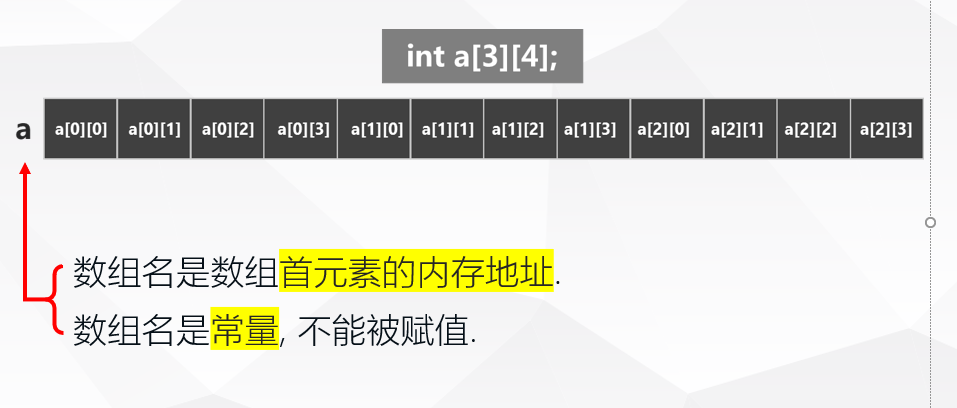
二维数组初始化
二维数组的初始化: 在定义数组的同时赋给初值.
// 将所有数据写在一个{}内, 按顺序赋值
int a[3][4]={1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
// 分行给二维数组赋初值, 例如:
int a[3][4] ={
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12}
};
// 可以对部分元素赋初值, 例如:
int a[3][4]={
{1},
{0, 6},
{0, 0, 11}
};
// 以上写法等同于
int a[3][4]={
{1, 0, 0, 0},
{0, 6, 0, 0},
{0, 0, 11, 0}
};
// 列出全部初始值时, 第1维下标个数可以省略, 例如:
int a[][4]={1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
// 再如:
int a[][4] ={
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12}
};
// 但是这样是错误的
int a[3][] ={
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12}
};
- 数组定义的时候必须指定数据类型, 好确定每个元素需要开辟多少空间.
- 数组空间大小定义时就已经确定, 不能更改.
- 多维数组可以视为特殊的一维数组, 只不过其元素也是数组.
- 因为多维数组的其余维是用来确定每次开辟多少空间, 而第一维是用来确定开辟空间的倍数.
- 如果定义时不指定其余维的长度将导致二义性, 即编译器无法确定给每次开辟多少空间, 造成编译错误.
- 所以多维数组定义时, 除了第一维长度可以省略, 其余维度必须给出具体长度.
二维数组下标
// 二维数组下标与元素寻址
&a[x][y] == a + x*sizeof(a[0]) + y*sizeof(a[0][0])冒泡排序
for (int i = 0;i < SIZE-1;i++)
{
for (int j = 0;j < SIZE-i-1;j++)
{
if (arr[j] > arr[j + 1])
{
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}基于数组的排序方法非常多, 例如:
- 冒泡排序
- 快速排序
- 堆排序
- 桶排序
字符数组
数组元素在内存中顺次存放, 它们的地址是连续的.字符数组中的每个元素在内存中占用一个字节的存储单元, 用于存取一个字符.
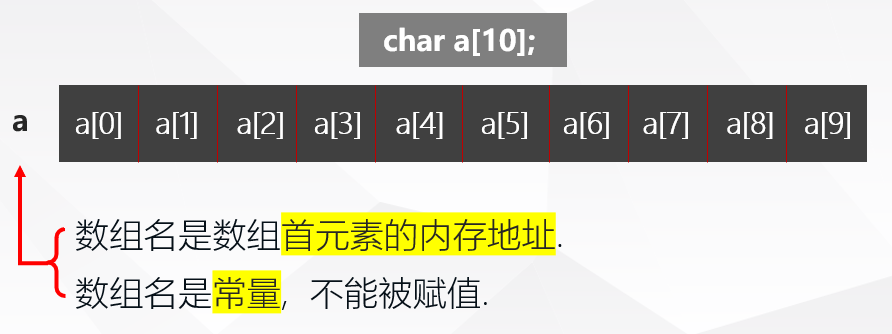
空终止字符串
也叫 NTBS - NULL Terminated Byte String- C语言中没有字符串数据类型, 于是将字符串中的字符逐个存放到数组元素中.
- 字符串是一个独立的概念, 其以
'\0'字符结尾, 字符串的本质还是字符数组. - 字符串常量用
"xxx"表示
比如字符数组 {'\x63', '\x61', '\x74', '\0'} 是 ASCII 编码的字符串 "cat" 的 NTBS 。
用字符串来初始化字符数组
// 数组大小要考虑字符串末尾的空字符'\0'
char c[12] = {"hello world"};
// 花括号可以省略
char c[12] = "hello world";
// 数组大小可以省略
char c[] = "hello world";
// 虽然可以通过编译, 但避免这样使用
char *c = "hello world";
字符表示ASCII
*注意, ASCII是American Standard Code for Information Interchange缩写, 而不是ASCⅡ(罗马数字2), 有很多人在这个地方产生误解.
ASCII (美国信息交换标准代码) 是基于拉丁字母的一套电脑编码系统, 主要用于显示现代英语和其他西欧语言.
ASCII包含三个部分内容:

-
"控制码“
0~32: 规定了特殊的用途, 一旦终端、打印机遇上这些字符, 就要做一些约定的动作. -
"标准字符"
33~127: 空格、标点符号、数字、大小写字母. -
"扩展字符“
128~255: 表示新的字母、符号, 还有画表格用到的横线、竖线、交叉等形状.
但是ASCII的扩展十分有限, 然而想要表示譬如中文这样的文字显然是不太够用的。于是,计算机工程师们给自己国家的语言创建了对应的字符集(Charset)和字符编码(Character Encoding)。
如果要表示汉字, 可以使用 GB编码(GB2312,GBK等可以表示简体中文),BIG5编码(表示繁体中文), UNICODE编码(也叫万国码, 包含了 150 种语言的 14 万个不同的字符).
以GB2312为例, 即《信息交换用汉字编码字符集》
两个大于 127 的字符(unsigned char)连在一起, 表示一个汉字. 这样, 双字节可以组合出约 7000 多个简体汉字 (常用的汉字都在这里面了).
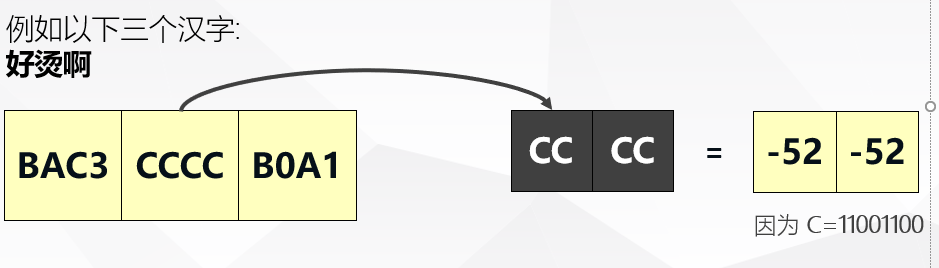
我们常常会看到乱码, 乱码是怎么产生的呢?
`手持两把锟斤拷,
口中疾呼烫烫烫。
脚踏千朵屯屯屯,
笑看万物锘锘锘`
锟斤拷:
UTF8编码的文本用<code>GBK格式解码时一些无法被字符集识别的字符会变成"\xef\xbf\xbd\xef\xbf\xbd", 由于GBK编码是2个字符表示一个汉字, 结果就成了"锟斤拷"
烫烫烫:
Visual Studio 的Debug模式用'0xCC'表示未初始化的内存, 其中'0xCC'在MBCS字符集中表示为"烫"
常用字符处理函数
Defined in header <string.h>
-
strlenreturns the length of a given stringstrlen("HELLO WORLD"); //11 -
strcpychar src[] = "cpycpy"; char des[strlen(src) + 1]; strcpy(des, src); -
strcmp// 使用字典序比较两个字符串 strcmp("abc", "def"); // -1 strcmp("aaa", "aaa"); // 0 strcmp("acb", "abc"); // 1 -
strstrstrstr("Hi, delucia, bye~", "delucia"); // delucia, bye~
结构体
结构体类型 struct
C语言允许使用结构体, 建立由不同数据类型组成的构造类型, 这种数据类型被称为结构体类型.
通过结构体类型, 我们可以将分散的信息集中起来表示一个实体类型.
如将学号、姓名、年龄、成绩等各项属性组织在一起, 用来表示某个学生.

struct类型和C++的class类型基本用法相同. 主要区别是struct类型的成员默认可见性是public, 而class类型是private.
初始化
结构体类型可使用{}括起来的初值列表进行初始化
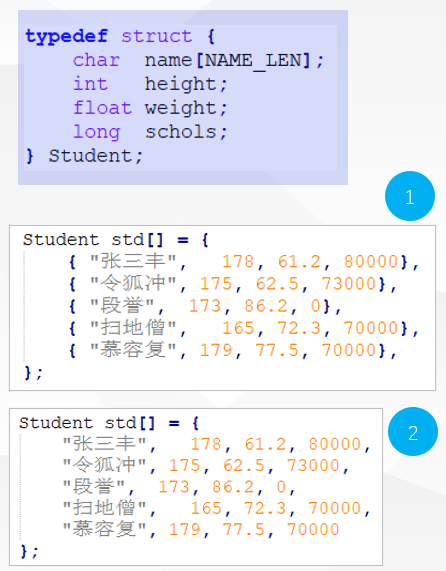
结构体类型变量可以作为函数参数以及返回值使用.
但是要注意, 结构体类型做参数时, 如果需要永久改变实参变量的成员的值, 则需要传递指针

typedef
typedef 声明, 可以给原有的数据类型定义 “别名”, 它的作用等同于数据类型名称, 通过合适的命名可以让数据类型表示的更直观.
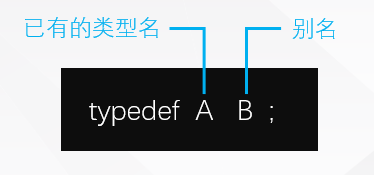
typedef unsigned long ULONG;
ULONG number = 1L;字节对齐
结构体在内存中是连续存储的 为了让操作系统可以快速读取到每个成员的 数据, 需要进行字节对齐 目的是将不同的成员分段存储, 保证任何成 员的地址偏移都是2或4或8的倍数.
- 在没指定对齐方式时, 按照最大成员类型的字节长度的倍数对齐
- 如果指定对齐方式, 则按照指定的对齐值和最大成员类型的字节长度之间取最小值对齐
下面我们分别使用不同的编排方式定义结构体类型.
编排方式 1
struct test
{
int a; // 4 pad 4
double b; // 8
char c; // 1 pad 7
}
// 内存分成连续三段, 每段8字节
// |XXXX____|XXXXXXXX|X______|
// 一共24字节, 浪费11字节编排方式 2
struct test
{
int a; // 4
char c; // 1 pad 3
double b; // 8
}
// 内存分成连续三段, 每段8字节
// |XXXXX___|XXXXXXXX|
// 一共16字节, 浪费3字节引用成员
struct NorthEastF4
{
char name[20];
char sex;
unsigned long birthday;
float height;
float weight;
};
struct NorthEastF4 boys[4] =
{
{"莱昂纳多·小沈阳", 'M', 19810507, 1.74, 60},
{"约翰尼·刘小宝", 'M', 19810105, 1.62, 50},
{"克里斯蒂安·刘能",'M', 19690226, 1.72, 75},
{"尼古拉斯·赵四",'M', 19740320, 1.71, 65}
};
NorthEastF4 bao = boys[1]; //拷贝
NorthEastF4 *p_bao = &boys[1];//指向
// 赋值时字符串长度不匹配报出异常
// boys[1].name = "约翰尼·宋小宝";
strcpy(bao.name, "约翰尼·宋小宝");
// 访问结构体成员
bao.name;
p_bao->height;
(*p_bao).weight;
指针
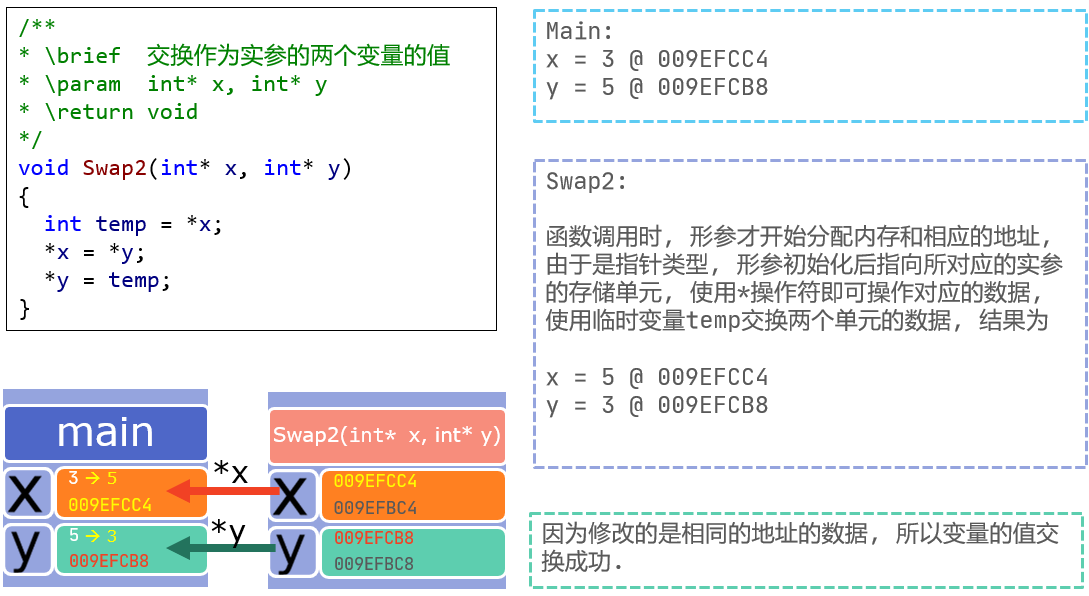

文件
了解文件的
- 打开
- 关闭
- 写入
- 读出
文件与流
程序的处理结果或计算结果会随着程序运行结束而消失.
因此要将程序运行结束后仍需保存的数值和字符等数据, 保存在文件 (file) 上.
针对文件、键盘、显示器、打印机等外部设备的数据读写操作都是通过流 (stream) 进行的, 我们可以想象成流淌着字符的水管.
C语言中的文件读写步骤
-
打开文件
无论对文件进行读还是写操作, 都需要先打开文件, 打开文件用
fopen函数. -
读写文件
写就是将内存中的数据存到文件中去. 主要是
fscanf和fprintf函数. -
关闭文件
当文件不再使用时, 需将其关闭. 关闭文件用
fclose函数.
举例, 向 D:\c\f1.txt 中写入内容
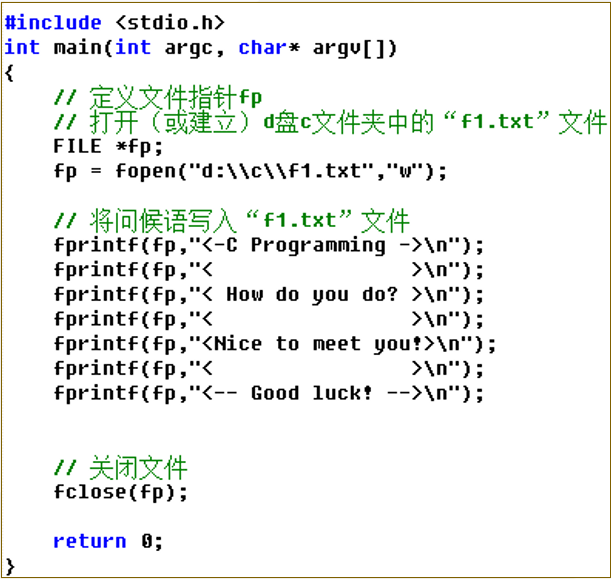
执行后, 打开f1.txt, 结果如下:
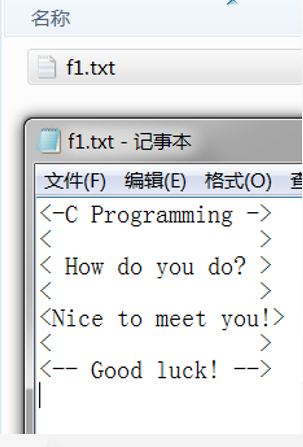
格式输入输出
考试内容不涉及C++的写法
printfscanfgetsputsgetchargetch
调试
给出一段代码, 可以很快指出代码存在的问题
常见编程问题
-
判断质数:
1 3 5 7 9 11 13 17 19 -
判断水仙花数:
153 370 371 401 -
判断回文数:
101 111 121 -
foo-bar-baz -
猜大小游戏
-
穷举法: 打印
99乘法表 -
穷举 + 过滤: 跳水成绩预测, 等式填数
-
冒泡排序
-
二分查找
-
阶乘, 累加, 斐波那契序列等
其他注意事项
- 考试都是
C语言题目, 答题也使用C语言 - 考试内容集中在
3 - 9章 - 这次不考或者很少涉及的内容有
- 链表的具体实现
- 使用指针动态分配和释放内存
- 函数指针
- 复杂递归算法实现
- IO流和文件处理
- 编程题需要手写编程
- 唯手熟尔
Views: 320