
01 什么是Spark Streaming
Spark Streaming是Spark Core API(Spark RDD)的扩展,支持对实时数据流进行可伸缩、高吞吐量、容错处理。数据可以从Kafka、Flume、Kinesis或TCP Socket等多种来源获取,并且可以使用复杂的算法处理数据,这些算法由map()、reduce()、join()和window()等高级函数表示。处理后的数据可以推送到文件系统、数据库等存储系统。事实上,可以将Spark的机器学习和图形处理算法应用于数据流。

Spark Streaming的主要优点如下:
易于使用。Spark Streaming提供了很多高级操作算子,允许以编写批处理作业的方式编写流式作业。它支持Java、Scala和Python语言。
易于与Spark体系整合。通过在Spark Core上运行Spark Streaming,可以在Spark Streaming中使用与Spark RDD相同的代码进行批处理,构建强大的交互应用程序,而不仅仅是数据分析。
02 Spark Streaming工作原理
Spark Streaming接收实时输入的数据流,并将数据流以时间片(秒级)为单位拆分成批次,然后将每个批次交给Spark引擎(Spark Core)进行处理,最终生成以批次组成的结果数据流。

Spark Streaming提供了一种高级抽象,称为DStream(Discretized Stream)。DStream表示一个连续不断的数据流,它可以从Kafka、Flume和Kinesis等数据源的输入数据流创建,也可以通过对其他DStream应用高级函数(例如map()、reduce()、join()和window())进行转换创建。在内部,对输入数据流拆分成的每个批次实际上是一个RDD,一个DStream则由多个RDD组成,相当于一个RDD序列

DStream中的每个RDD都包含来自特定时间间隔的数据。

应用于DStream上的任何操作实际上都是对底层RDD的操作。例如,对一个DStream应用flatMap()算子操作,实际上是对DStream中每个时间段的RDD都执行一次flatMap()算子,生成对应时间段的新RDD,所有的新RDD组成了一个新Dstream。

03 输入DStream和Receiver
输入DStream表示从数据源接收的输入数据流,每个输入DStream(除了文件数据流之外)都与一个Receiver对象相关联,该对象接收来自数据源的数据并将其存储在Spark的内存中进行处理。
如果希望在Spark Streaming应用程序中并行接收多个数据流,可以创建多个输入DStream,同时将创建多个Receiver,接收多个数据流。但需要注意的是,一个Spark Streaming应用程序的Executor是一个长时间运行的任务,它会占用分配给Spark Streaming应用程序的一个CPU内核(占用Spark Streaming应用程序所在节点的一个CPU内核),因此Spark Streaming应用程序需要分配足够的内核(如果在本地运行,则是线程)来处理接收到的数据,并运行Receiver。
在本地运行Spark Streaming应用程序时,不要使用“local”或“local[1]”作为主URL。这两种方式都意味着只有一个线程将用于本地运行任务。如果正在使用基于Receiver的输入DStream(例如Socket、Kafka、Flume等),那么将使用单线程运行Receiver,导致没有多余的线程来处理接收到的数据(Spark Streaming至少需要两个线程,一个线程用于运行Receiver接收数据,一个线程用于处理接收到的数据)。因此,在本地运行时,应该使用“local[n]”作为主URL,其中n>Receiver的数量(若Spark Streaming应用程序只创建了一个DStream,则只有一个Receiver,n的最小值为2)。
每个Spark应用程序都有各自独立的一个或多个Executor进程负责执行任务。将Spark Streaming应用程序发布到集群上运行时,每个Executor进程所分配的CPU内核数量必须大于Receiver的数量,因为1个Receiver独占1个CPU内核,还需要至少1个CPU内核进行数据的处理,这样才能保证至少两个线程同时进行(一个线程用于运行Receiver接收数据,一个线程用于处理接收到的数据)。否则系统将接收数据,但无法进行处理。若Spark Streaming应用程序只创建了一个DStream,则只有一个Receiver,Executor所分配的CPU内核数量的最小值为2。
04 第一个Spark Streaming程序
假设需要监听TCP Socket端口的数据,实时计算接收到的文本数据中的单词数,步骤如下:
- 导入相应类
导入Spark Streaming所需的类和StreamingContext中的隐式转换,代码如下:
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._- 创建StreamingContext
StreamingContext是所有数据流操作的上下文,在进行数据流操作之前需要先创建该对象。例如,创建一个本地StreamingContext对象,使用两个执行线程,批处理间隔为1秒(每隔1秒获取一次数据,生成一个RDD),代码如下:
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("NetworkWordCount")
//按照时间间隔为1秒钟切分数据流
val ssc = new StreamingContext(conf, Seconds(1))
- 创建DStream
使用StreamingContext可以创建一个输入DStream,它表示来自TCP源的流数据。例如,从主机名为localhost、端口为9999的TCP源获取数据,代码如下:
val lines = ssc.socketTextStream("localhost", 9999)上述代码中的lines是一个输入DStream,表示从服务器接收的数据流。lines中的每条记录都是一行文本。
- 操作DStream
DStream创建成功后,可以对DStream应用算子操作,生成新的DStream,类似对RDD的操作。例如,按空格字符将每一行文本分割为单词,代码如下:
val words = lines.flatMap(_.split(" "))在本例中,lines的每一行将被分成多个单词,单词组成的数据流则为一个新的DStream,使用words表示。接下来需要统计单词数量,代码如下:
import org.apache.spark.streaming.StreamingContext._ //计算每一批次中的每一个单词数量
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print() //默认打印前10个元素(DStream中的RDD)到控制台
- 启动Spark Streaming
在DStream的创建与转换代码编写完毕后,需要启动Spark Streaming才能真正的开始计算,因此需要在最后添加以下代码:
//开始计算
ssc.start()
//等待计算结束
ssc.awaitTermination()
到此,一个简单的单词计数例子就完成了。
05 Spark Streaming数据源
Spark Streaming提供了两种内置的数据源支持:基本数据源和高级数据源。基本数据源是指文件系统、Socket连接等;高级数据源是指Kafka、Flume、Kinesis等数据源。
- 文件流
对于从任何与HDFS API兼容的文件系统上的文件中读取数据,可以通过以下方式创建DStream:
streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass](dataDirectory)- Socket流
通过监听Socket端口接收数据,例如以下代码,从本地的9999端口接收数据:
//创建一个本地StreamingContext对象,使用两个执行线程,批处理间隔为1秒
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
//连接localhost:9999获取数据,转为DStream
val lines = ssc.socketTextStream("localhost", 9999)
- RDD队列流
使用streamingContext.queueStream(queueOfRDDs)可以基于RDD队列创建DStream。推入队列的每个RDD将被视为DStream中的一批数据,并像流一样进行处理。这种方式常用于测试Spark Streaming应用程序。
下面以Kafka数据源为例,介绍高级数据源的使用。
首先需要在Maven工程中引入Spark Streaming的API依赖库:
<!--Spark核心库-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<!--Spark Streaming依赖库-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.0</version>
</dependency>
然后引入Spark Streaming针对Kafka的第三方依赖库(针对Kafka 0.10版本):
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId> spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.0</version>
</dependency>引入所需库后,可以在Spark Streaming应用程序中使用以下格式代码创建输入DStream:
import org.apache.spark.streaming.kafka._
val kafkaStream = KafkaUtils.createStream(streamingContext,
[ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
06 DStream操作
与RDD类似,许多普通RDD上可用的操作算子DStream也支持。使用这些算子可以修改输入DStream中的数据,进而创建一个新的DStream。对DStream的操作主要有三种:无状态操作、状态操作、窗口操作。
1、无状态操作
无状态操作指的是,每次都只计算当前时间批次的内容,处理结果不依赖于之前批次的数据,例如每次只计算最近1秒钟时间批次产生的数据。常用的DStream无状态操作算子如表所示。

2、状态操作
状态操作是指,需要把当前时间批次和历史时间批次的数据进行累加计算,即当前时间批次的处理需要使用之前批次的数据或中间结果。使用updateStateByKey()算子可以保留key的状态,并持续不断地用新状态更新之前的状态。使用该算子可以返回一个新的“有状态的”DStream,其中通过对每个key的前一个状态和新状态应用给定的函数来更新每个key的当前状态。
例如,对数据流中的实时单词进行计数,每当接收到新的单词,需要将当前单词数量累加到之前批次的结果中。这里单词的数量就是状态,对单词数量的更新就是状态的更新。定义状态更新函数,实现按批次累加单词数量的代码如下:
/**
* 定义状态更新函数,按批次累加单词数量
* @param values 当前批次某个单词的出现次数,相当于Seq(1,1,1)
* @param state 某个单词上一批次累加的结果,因为可能没有值,所以用Option类型
*/
val updateFunc=(values:Seq[Int],state:Option[Int])=>{
//累加当前批次某个单词的数量
val currentCount=values.foldLeft(0)(+)
//获取上一批次某个单词的数量,默认值0
val previousCount= state.getOrElse(0)
//求和。使用Some表示一定有值,不为None
Some(currentCount+previousCount)
}
将updateFunc函数作为参数传入updateStateByKey()算子即可对DStream中的单词按批次累加,代码如下:
//更新状态,按批次累加
val result:DStream[(String,Int)]= wordCounts.updateStateByKey(updateFunc)
//默认打印DStream中每个RDD中的前10个元素到控制台
result.print()
3、窗口操作
Spark Streaming提供了窗口计算,允许在滑动窗口(某个时间段内的数据)上进行操作。当窗口在DStream上滑动时,位于窗口内的RDD就会被组合起来,并对其进行操作。
假设批处理时间间隔为1秒,现需要每隔2秒对过去3秒的数据进行计算,此时就需要使用滑动窗口计算,计算过程如图所示(相当于一个窗口在DStream上滑动)。
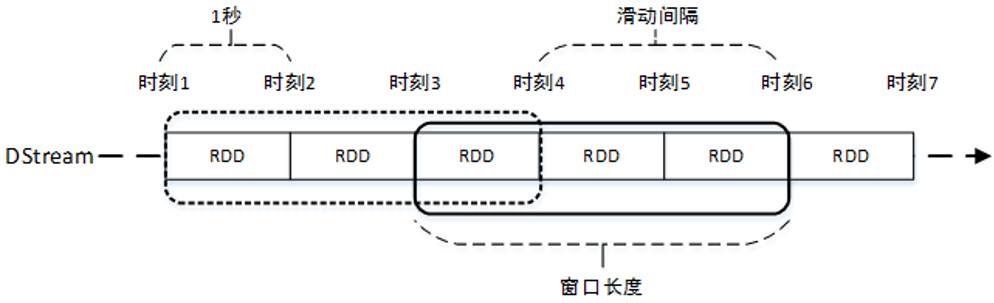
任何窗口计算都需要指定以下两个参数:
窗口长度:窗口覆盖的流数据的时间长度。必须是批处理时间间隔的倍数。
滑动时间间隔:前一个窗口滑动到后一个窗口所经过的时间长度。必须是批处理时间间隔的倍数。
Spark针对窗口计算提供了相应的算子。例如,每隔10秒计算最后30秒的单词数量,代码如下:
val windowedWordCounts = pairsDStream.reduceByKeyAndWindow(
(a: Int, b: Int) => (a + b),
Seconds(30),
Seconds(10)
)
一些常用的窗口操作算子如表。

4、输出操作
输出操作允许将DStream的数据输出到外部系统,如数据库或文件系统。输出操作触发所有DStream转换操作的实际执行,类似于RDD的行动算子。Spark Streaming定义的输出操作如表。

foreachRDD(func)是一个功能强大的算子,它允许将数据发送到外部系统。理解如何正确有效地使用这个算子非常重要。
5、缓存及持久化
与RDD类似,DStream也允许将流数据持久化到内存中。也就是说,在DStream上使用persist()方法可以将该DStream的每个RDD持久化到内存中。这在DStream中的数据需要被计算多次(例如,对同一数据进行多次操作)时非常有用。对于基于窗口的操作,如reduceByWindow()、reduceByKeyAndWindow(),以及基于状态的操作,如updateStateByKey(),这些都默认开启了persist()。因此,基于窗口操作生成的DStream将自动持久化到内存中,而不需要手动调用persist()。
对于通过网络接收的输入流(如Kafka、Flume、Socket等),默认的持久化存储级别被设置为将数据复制到两个节点,以便容错。
6、检查点
Spark Streaming应用程序必须全天候运行,因此与应用程序逻辑无关的故障(例如,系统故障、JVM崩溃等)不应该对其产生影响。为此,Spark Streaming需要对足够的数据设置检查点,存储到容错系统中,使其能够从故障中恢复。Spark Streaming有两种类型的检查点:元数据检查点、数据检查点。
元数据检查点:元数据主要指配置信息、DStream操作、未完成的批次。
数据检查点:将生成的RDD保存到可靠的存储系统(例如HDFS)中。为了避免系统恢复时间的无限增长,将有状态转换的中间RDD定期存储到可靠系统中,以切断依赖链。
Views: 174