
一、课前准备
- Hadoop-3.1.2集群
- MySQL-5.7
- zookeeper-3.6.2集群
- Hive-3.1.2
- spark-2.3.3
二、课堂目标
- 熟练使用DolphinScheduler调度系统
三、知识要点
1、DolphinScheduler简介
-
Apache DolphinScheduler](https://dolphinscheduler.apache.org/)(目前处在孵化阶段)是一个分布式、去中心化、易扩展的可视化DAG工作流任务调度系统,其致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
-
DolphinScheduler是2019年中国易观公司开源的一个调度系统,在美国时间2019年8月29号,易观开源的分布式任务调度引擎DolphinScheduler(原EasyScheduler)正式通过顶级开源组织Apache基金会的投票决议,根据Apache基金会邮件列表显示,在包含11个约束性投票(binding votes)和2个无约束性投票(non-binding votes)的投票全部持赞同意见,无弃权票和反对票,投票顺利通过,这样便以全票通过的优秀表现正式成为了Apache孵化器项目!
2、DolphinScheduler的特性
2.1 高可靠性
- 去中心化多Master和Worker,自身支持HA功能,采用任务队列来避免过载,不会造成机器卡死
2.2.简单易用
- DAG监控界面,所有流程定义都是可视化,通过拖拽任务制定DAG
- 通过API方式与第三方系统对接,一键部署。
2.3.丰富的使用场景
- 支持暂停、恢复操作,支持多租户,更好的应对大数据的使用场景,支持更多的任务类型,如hive,mr,spark,python
2.4.高扩展性
- 支持自定义任务类型,调度器使用分布式调度,调度能力随集群线性增长,Master和Worker支持动态上下线
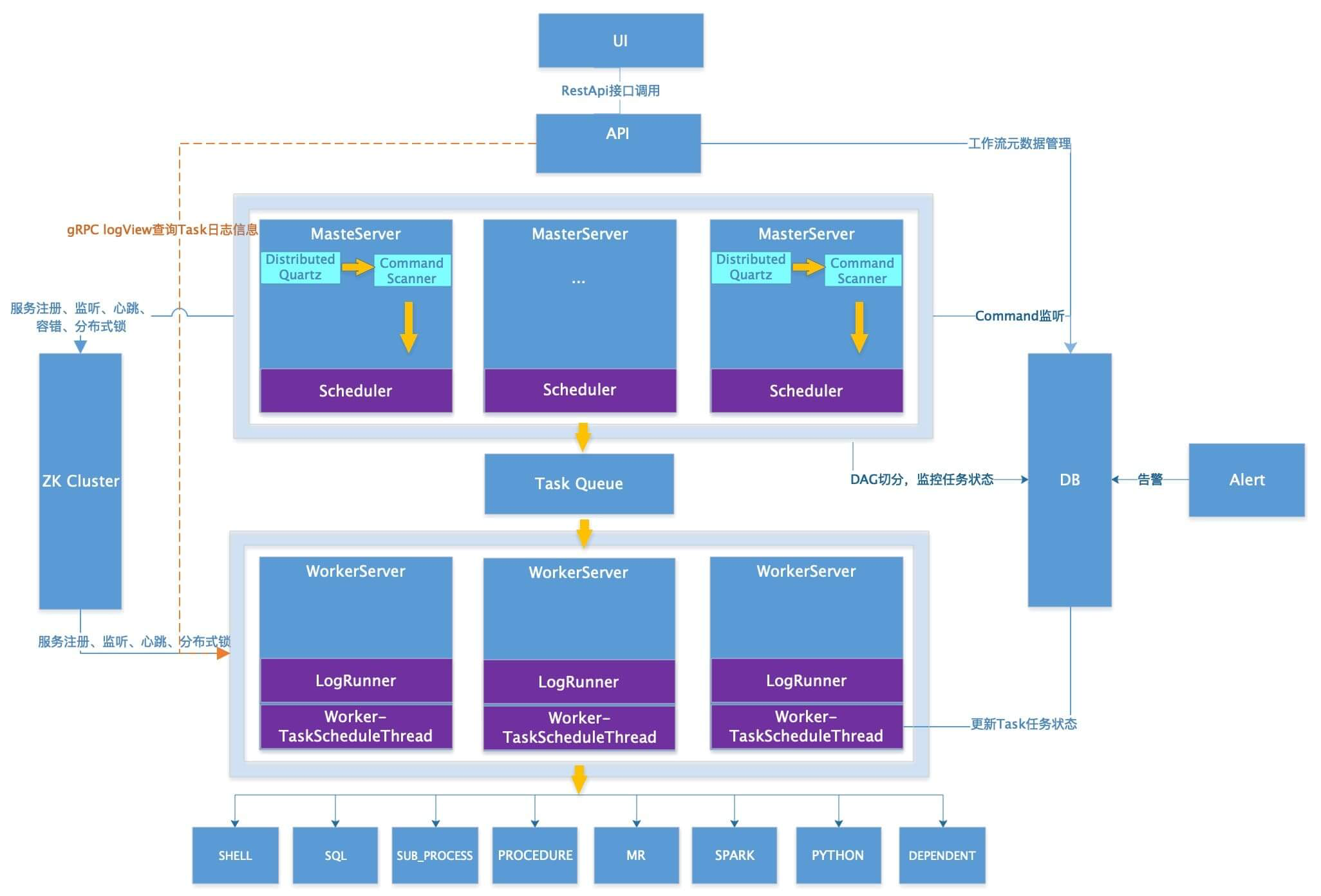
3、DolphinScheduler的架构介绍
3.1 系统架构设计
https://dolphinscheduler.apache.org/zh-cn/blog/architecture-design.html
3.2 DS-1.3改进及新特性
-
数据库减压,减少极端情况下的可能造成的调度延时
-
Worker去DB、职责更单一
-
Master和Worker直接通信,降低 延时
-
Master多种策略分发任务(有三种方式选择Worker节点:随机、循环、CPU和 内存的线性加权负载平衡 )
-
资源中心支持多目录
-
任务类型新增Datax、 Sqoop、条件分支
-
DAG一键格式化
-
批量导出和导入工作流
-
工作流复制
3.3 DS-1.3系统架构图
4、前置环境准备
说明:
安装DolphinScheduler(以下简称ds)前,建议跟文档下边说明的环境保持统一
否则安装及使用ds的过程中,可能会出现位置错误需要自己解决
4.1 安装JDK-1.8
- 此文档以3节点在
/kkb/install都安装了jdk1.8.0_141为例进行演示 - 安装包
jdk-8u141-linux-x64.tar.gz
4.2 安装Hadoop-3.1.4集群
- 此文档以3节点在
/kkb/install都安装了hadoop-3.1.4为例进行演示 - 若没有如此安装,参考资料《HADOOP集群搭建(3.X版本,3节点)》进行安装
4.3 安装Zookeeper-3.6.2集群
- 此文档以3节点在
/kkb/install都安装了zookeeper-3.6.2为例进行演示 - 若没有如此安装,参考资料《zookeeper集群安装部署》进行安装
4.4 安装Mysql-5.7
- 安装node03节点安装了mysql-5.7
- 若没有如此安装,参考资料《CENTOS 7安装MYSQL5.7 – 大数据环境》进行安装
4.5 安装hive-3.1.2
- node02、node03节点安装了hive-3.1.2
- 若没有如此安装,参考资料《Hive安装部署》进行安装
4.6 安装Spark-2.3.3
-
dolphinscheduler中会演示调度spark程序,先演示基本的用法
-
此文档以3节点在
/kkb/install都安装了spark-2.3.3为例进行演示 -
若没有如此安装,参考资料《spark安装部署.md》进行安装
5、安装部署
官方安装指导:https://dolphinscheduler.apache.org/zh-cn/docs/1.3.4/user_doc/quick-start.html
5.1节点规划
| 机器 | 服务 | 端口 | group |
|---|---|---|---|
| node01 | master、api、logger | 8787(master)、8888(api) | |
| node02 | master、alert、worker、logger | 8787(master)、7878(worker) | hadoop |
| node03 | worker、logger | 7878(worker) | hadoop |
hadoop 组配置后master分发任务才能根据cpu和内存的负载选择具体哪个worker执行任务
5.2 准备工作
1、创建目录
- 确保三个节点都有目录
/kkb/soft、/kkb/install,且所属用户及用户组如下
[hadoop@node01 ~]$ ll /kkb/
总用量 0
drwxr-xr-x. 2 hadoop hadoop 6 4月 13 14:21 install
drwxr-xr-x. 2 hadoop hadoop 6 4月 13 14:22 soft
- 若没有这些目录,那么如下创建;==3个节点==都运行如下命令
sudo mkdir -p /kkb/install
sudo mkdir -p /kkb/soft
sudo chown -R hadoop:hadoop /kkb/
ll /kkb/- 确保目录所属变成如下样子
2、确保已安装zookeeper集群
- 启动zookeeper集群
- 确保三节点上已经安装了zk;
- zk版本要求:ZooKeeper (3.4.6+)
- 若没有安装,请先安装再往下继续
3、启动HDFS
-
因为ds的资源存储在HDFS上
-
所以,node01上运行
start-dfs.sh启动hdfs
5.3 开始安装
第一步:安装包下载,在node01上执行
[hadoop@node01 ~]$ cd /kkb/soft/
[hadoop@node01 soft]$ wget https://mirrors.tuna.tsinghua.edu.cn/apache/dolphinscheduler/1.3.5/apache-dolphinscheduler-incubating-1.3.5-dolphinscheduler-bin.tar.gz第二步:解压压缩包
[hadoop@node01 soft]$ tar -xzvf apache-dolphinscheduler-incubating-1.3.5-dolphinscheduler-bin.tar.gz -C /kkb/install/第三步:重命名
[hadoop@node01 soft]$ cd /kkb/install/
[hadoop@node01 install]$ mv apache-dolphinscheduler-incubating-1.3.5-dolphinscheduler-bin/ dolphinscheduler-1.3.5
[hadoop@node01 install]$ ll
总用量 0
drwxrwxr-x. 9 hadoop hadoop 156 4月 13 14:35 dolphinscheduler-1.3.5第四步:建库建表
此处以node03安装了mysql为例
node01上
[hadoop@node01 install]$ scp /kkb/install/dolphinscheduler-1.3.5/sql/dolphinscheduler_mysql.sql node03:/kkb/soft/node03上,进入MySQL命令行执行
mysql -uroot -p
set global validate_password_policy=LOW;
set global validate_password_length=6;
CREATE DATABASE IF NOT EXISTS dolphinscheduler DEFAULT CHARSET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'root'@'%' IDENTIFIED BY '123456';
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'root'@'localhost' IDENTIFIED BY '123456';
flush privileges;
use dolphinscheduler;
source /kkb/soft/dolphinscheduler_mysql.sql;
mysql> show tables;
+--------------------------------+
| Tables_in_dolphinscheduler |
+--------------------------------+
| QRTZ_BLOB_TRIGGERS |
| QRTZ_CALENDARS |
| QRTZ_CRON_TRIGGERS |
| QRTZ_FIRED_TRIGGERS |
| QRTZ_JOB_DETAILS |
| QRTZ_LOCKS |
| QRTZ_PAUSED_TRIGGER_GRPS |
| QRTZ_SCHEDULER_STATE |
| QRTZ_SIMPLE_TRIGGERS |
| QRTZ_SIMPROP_TRIGGERS |
| QRTZ_TRIGGERS |
| t_ds_access_token |
| t_ds_alert |
| t_ds_alertgroup |
| t_ds_command |
| t_ds_datasource |
| t_ds_error_command |
| t_ds_process_definition |
| t_ds_process_instance |
| t_ds_project |
| t_ds_queue |
| t_ds_relation_datasource_user |
| t_ds_relation_process_instance |
| t_ds_relation_project_user |
| t_ds_relation_resources_user |
| t_ds_relation_udfs_user |
| t_ds_relation_user_alertgroup |
| t_ds_resources |
| t_ds_schedules |
| t_ds_session |
| t_ds_task_instance |
| t_ds_tenant |
| t_ds_udfs |
| t_ds_user |
| t_ds_version |
+--------------------------------+
35 rows in set (0.00 sec)第五步:修改配置文件
[hadoop@node01 ~]$ cd /kkb/install/dolphinscheduler-1.3.5/conf/1、alert.properties #配置告警邮箱相关信息
- 此处已126邮箱为例
- 登录自己的126邮箱
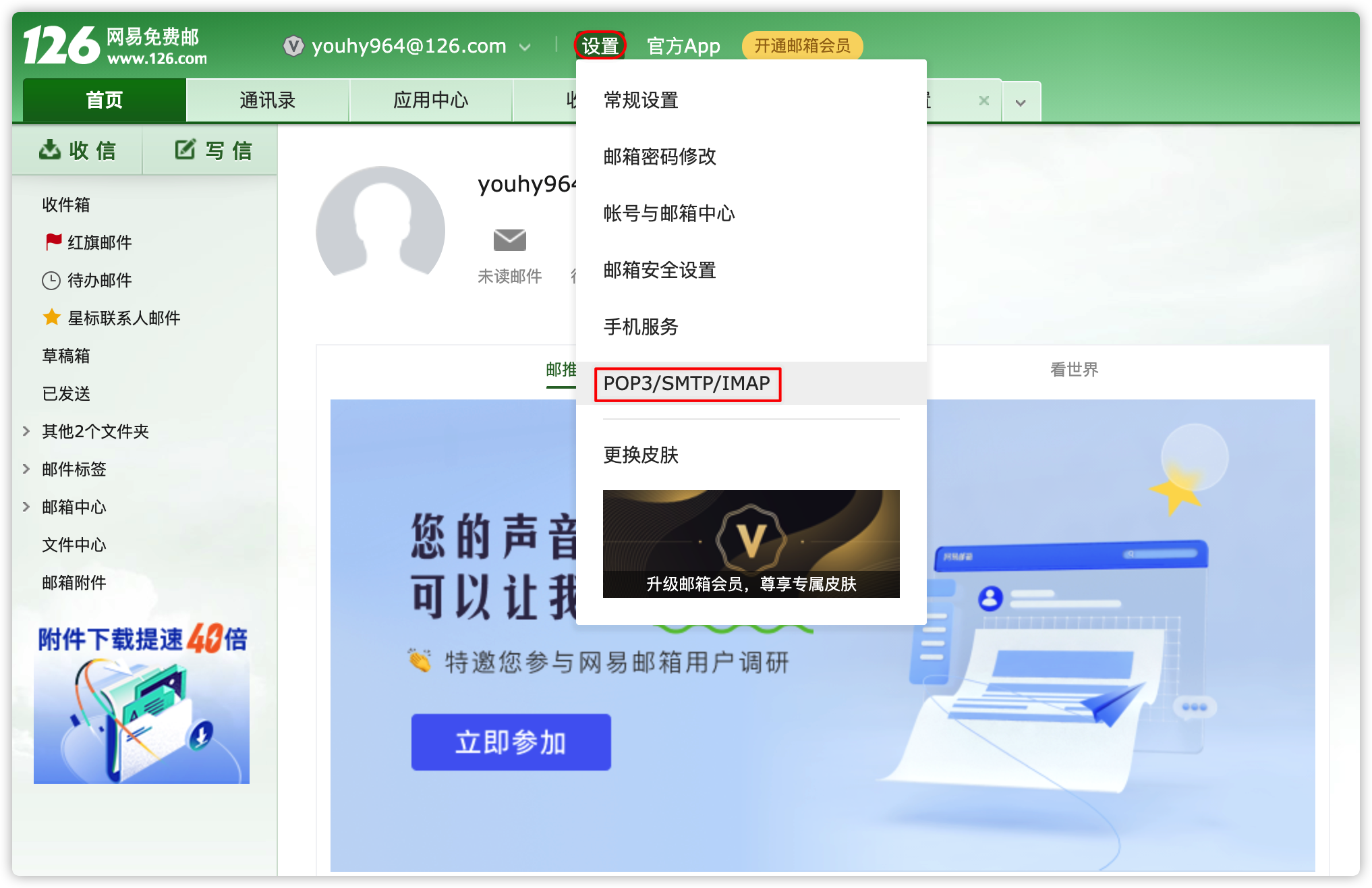
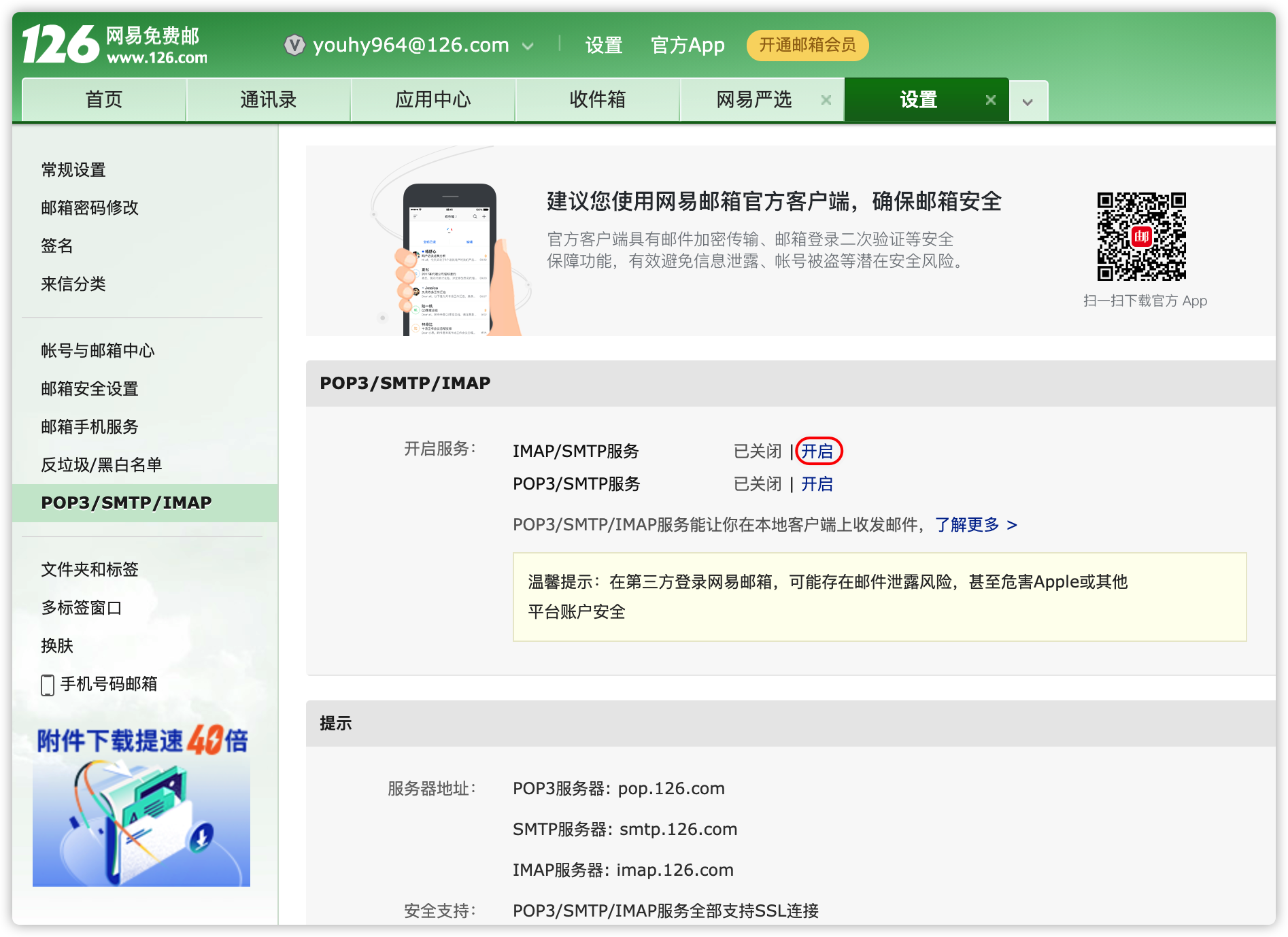
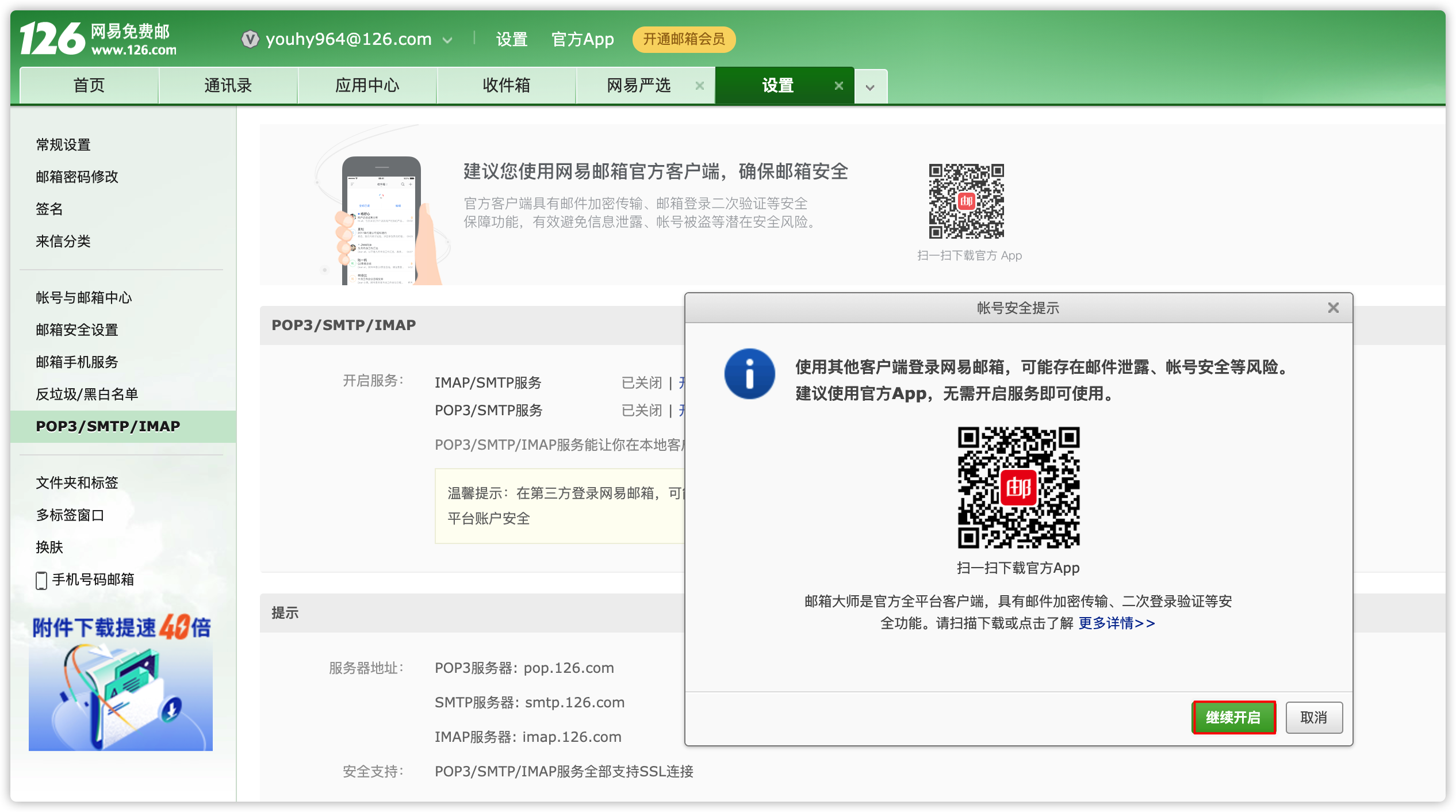
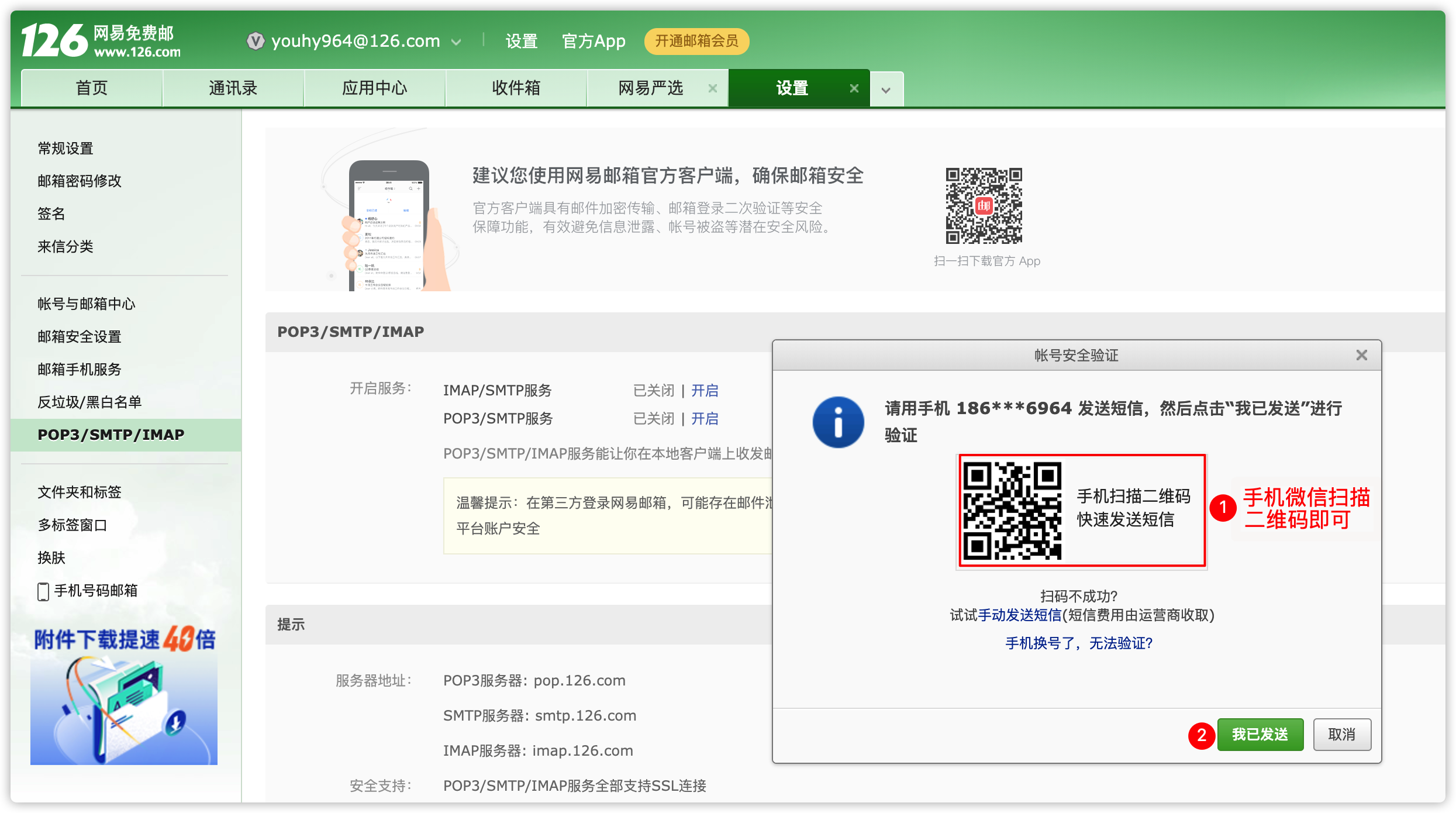
- 开始配置文件
[hadoop@node01 conf]$ vim alert.properties
#alert type is EMAIL/SMS
alert.type=EMAIL
# mail server configuration
mail.protocol=SMTP
mail.server.host=smtp.126.com
mail.server.port=25
mail.sender=youhy964@126.com
mail.user=youhy964@126.com
mail.passwd=WBNPUGCNZMQQYBUT
# TLS
mail.smtp.starttls.enable=true
# SSL
mail.smtp.ssl.enable=false
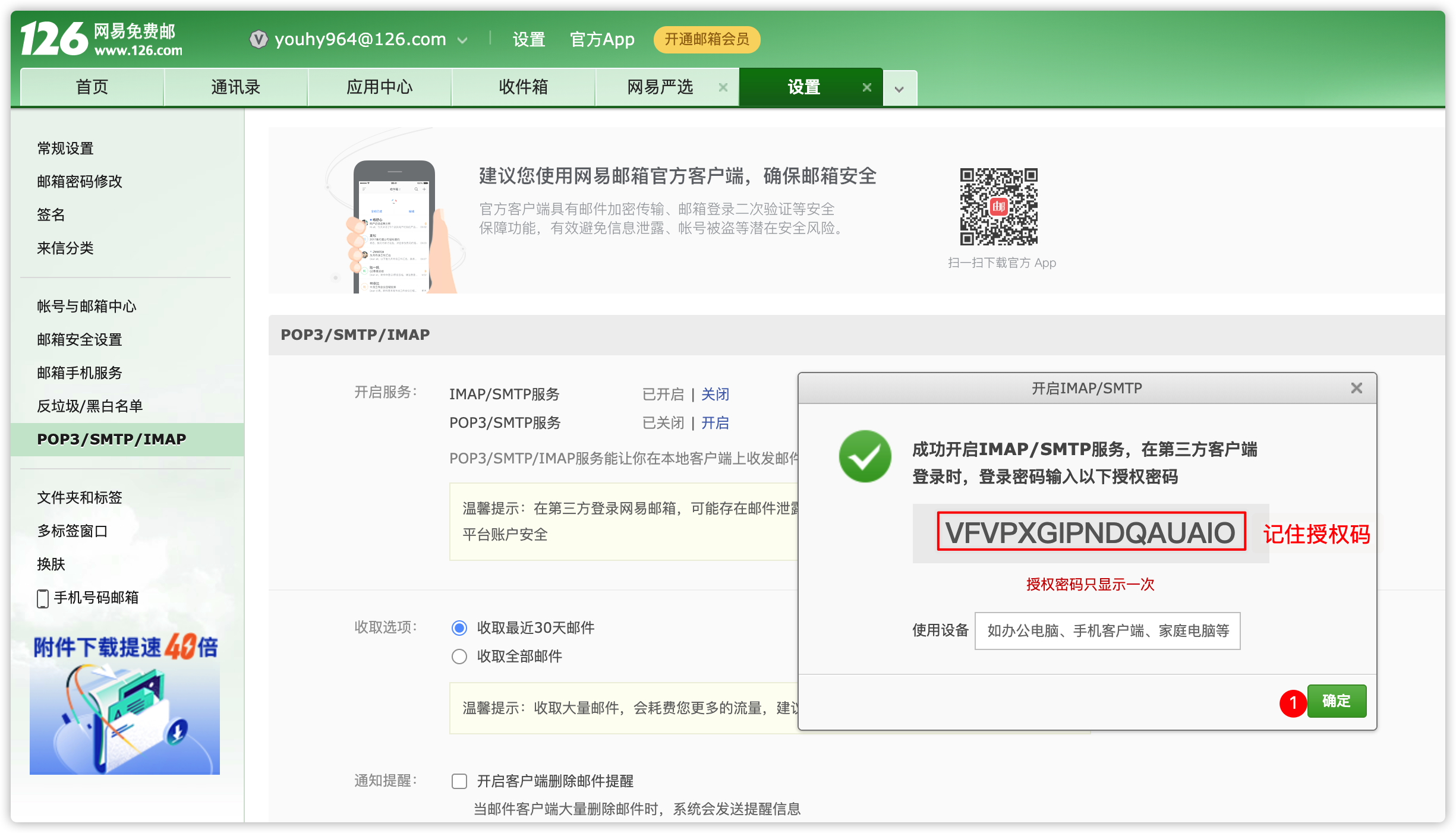
mail.smtp.ssl.trust=smtp.126.com2、application-api.properties
- 修改web ui端口号
[hadoop@node01 conf]$ vim application-api.properties
# server port
server.port=8888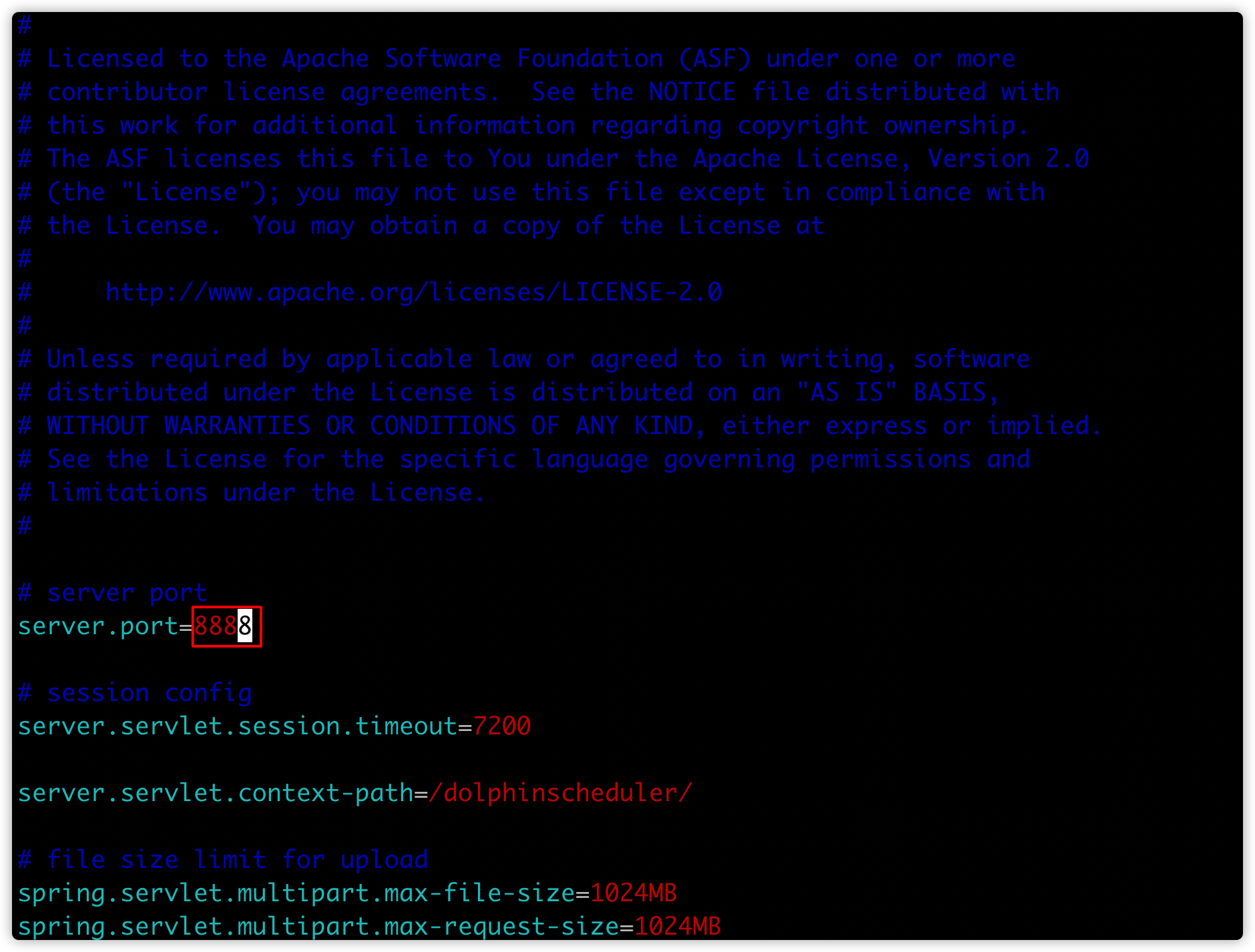
3、common.properties
# 修改如下3个属性的值
[hadoop@node01 conf]$ vim common.properties
resource.storage.type=HDFS
fs.defaultFS=hdfs://node01:8020
yarn.application.status.address=http://node01:8088/ws/v1/cluster/apps/%s4、datasource.properties
假设mysql安装在node03节点
# 修改如下几个属性的值
[hadoop@node01 conf]$ vim datasource.properties
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://node03:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true
spring.datasource.username=root
spring.datasource.password=1234565、master.properties
[hadoop@node01 conf]$ vim master.properties
master.listen.port=8787 6、worker.properties
[hadoop@node01 conf]$ vim worker.properties
worker.listen.port=7878
worker.groups=hadoop
7、zookeeper.properties
[hadoop@node01 conf]$ vim zookeeper.properties
zookeeper.quorum=node01:2181,node02:2181,node03:21818、env/dolphinscheduler_env.sh
# 修改如下属性,根据自己的实际情况,配置属性值
[hadoop@node01 conf]$ vim env/dolphinscheduler_env.sh
export HADOOP_HOME=/kkb/install/hadoop-3.1.4
export HADOOP_CONF_DIR=/kkb/install/hadoop-3.1.4/etc/hadoop
export SPARK_HOME1=/kkb/install/spark-2.3.3-bin-hadoop2.7
export JAVA_HOME=/kkb/install/jdk1.8.0_141
export HIVE_HOME=/kkb/install/apache-hive-3.1.2
第六步:将hdfs-site.xml、core-site.xml 拷贝至ds的 conf 目录下,同时 把mysql-connector-java-5.1.48-bin.jar驱动包上传到ds的lib目录下
[hadoop@node01 conf]$ cp /kkb/install/hadoop-3.1.4/etc/hadoop/hdfs-site.xml /kkb/install/dolphinscheduler-1.3.5/conf
[hadoop@node01 conf]$ cp /kkb/install/hadoop-3.1.4/etc/hadoop/core-site.xml /kkb/install/dolphinscheduler-1.3.5/conf# 将mysql-connector-java-5.1.38.jar上传到node01的/kkb/soft目录
[hadoop@node01 soft]$ cd /kkb/soft/
[hadoop@node01 soft]$ cp mysql-connector-java-5.1.38.jar /kkb/install/dolphinscheduler-1.3.5/lib/第七步:到ds的bin目录下(1.3.5版本,可以跳过此步)
dos2unix dolphinscheduler-daemon.sh #dos2unix:将DOS格式的文本文件转换成UNIX格式的(DOS/MAC to UNIX text file format converter)
chmod +x dolphinscheduler-daemon.sh第八步:scp到node02、node03
[hadoop@node01 bin]$ cd /kkb/install/
[hadoop@node01 install]$ scp -r dolphinscheduler-1.3.5/ node02:$PWD
[hadoop@node01 install]$ scp -r dolphinscheduler-1.3.5/ node03:$PWD部署过程中的问题
建表时出现 Index column size too large. The maximum column size is 767 bytes.(此问题在MySQL-5.6及以前版本会出现)
将建表文件中 CHARSET=utf8mb4 改为 CHARSET=utf85.4 调优配置
生产环境上建议,worker.properties里设置的cpu和内存调一下就可以保护worker不至于挂掉,一般别超过cpu核数的2倍,内存留上1~2G(当然如果比较豪,可以预留更多资源),线程数别超过cpu核数的2.5倍。
例如:8c16G机器
worker.exec.threads=20
worker.max.cpuload.avg=16
worker.reserved.memory=1同理对于master调优配置 8c16G机器
master.properties文件
master.max.cpuload.avg=16
master.reserved.memory=15.5 启动
在node01 启动 master、api、logger
[hadoop@node01 ~]$ cd /kkb/install/dolphinscheduler-1.3.5/bin/
[hadoop@node01 bin]$ ./dolphinscheduler-daemon.sh start master-server
[hadoop@node01 bin]$ ./dolphinscheduler-daemon.sh start api-server
[hadoop@node01 bin]$ ./dolphinscheduler-daemon.sh start logger-server
在node02 启动 master、alert、worker、logger
[hadoop@node02 ~]$ cd /kkb/install/dolphinscheduler-1.3.5/bin/
[hadoop@node02 bin]$ ./dolphinscheduler-daemon.sh start master-server
[hadoop@node02 bin]$ ./dolphinscheduler-daemon.sh start alert-server
[hadoop@node02 bin]$ ./dolphinscheduler-daemon.sh start worker-server
[hadoop@node02 bin]$ ./dolphinscheduler-daemon.sh start logger-server
在node03 启动 worker、logger
[hadoop@node03 ~]$ cd /kkb/install/dolphinscheduler-1.3.5/bin/
[hadoop@node03 bin]$ ./dolphinscheduler-daemon.sh start worker-server
[hadoop@node03 bin]$ ./dolphinscheduler-daemon.sh start logger-server
目前3节点已经启动了hadoop集群、zookeeper集群、及ds相关进程;
启动成功之后,会出现如下进程
[hadoop@node01 bin]$ xcall jps
============= node01 jps =============
3680 ApiApplicationServer
2465 DataNode
3761 LoggerServer
3410 JobHistoryServer
2036 QuorumPeerMain
2294 NameNode
3607 MasterServer
2666 SecondaryNameNode
2892 ResourceManager
3037 NodeManager
4351 Jps
============= node02 jps =============
2320 NodeManager
2880 LoggerServer
2179 DataNode
3446 Jps
3287 AlertServer
2616 MasterServer
2798 WorkerServer
2031 QuorumPeerMain
============= node03 jps =============
2160 DataNode
2289 NodeManager
3009 LoggerServer
1996 QuorumPeerMain
2927 WorkerServer
3103 Jps- 如何关闭ds集群?
- 关闭个节点的各角色,就是将上边启动命令中的start换成stop即可
[hadoop@node01 ~]$ cd /kkb/install/dolphinscheduler-1.3.5/bin/
[hadoop@node01 bin]$ ./dolphinscheduler-daemon.sh stop master-server
[hadoop@node01 bin]$ ./dolphinscheduler-daemon.sh stop api-server
[hadoop@node01 bin]$ ./dolphinscheduler-daemon.sh stop logger-server
[hadoop@node02 ~]$ cd /kkb/install/dolphinscheduler-1.3.5/bin/
[hadoop@node02 bin]$ ./dolphinscheduler-daemon.sh stop master-server
[hadoop@node02 bin]$ ./dolphinscheduler-daemon.sh stop alert-server
[hadoop@node02 bin]$ ./dolphinscheduler-daemon.sh stop worker-server
[hadoop@node02 bin]$ ./dolphinscheduler-daemon.sh stop logger-server
[hadoop@node03 ~]$ cd /kkb/install/dolphinscheduler-1.3.5/bin/
[hadoop@node03 bin]$ ./dolphinscheduler-daemon.sh stop worker-server
[hadoop@node03 bin]$ ./dolphinscheduler-daemon.sh stop logger-server6、快速上手
6.1 web页面
-
访问地址:http://node01:8888/dolphinscheduler/ui/view/login/index.html
-
默认用户:admin
-
默认密码:dolphinscheduler123
- 登录后,进入如下界面
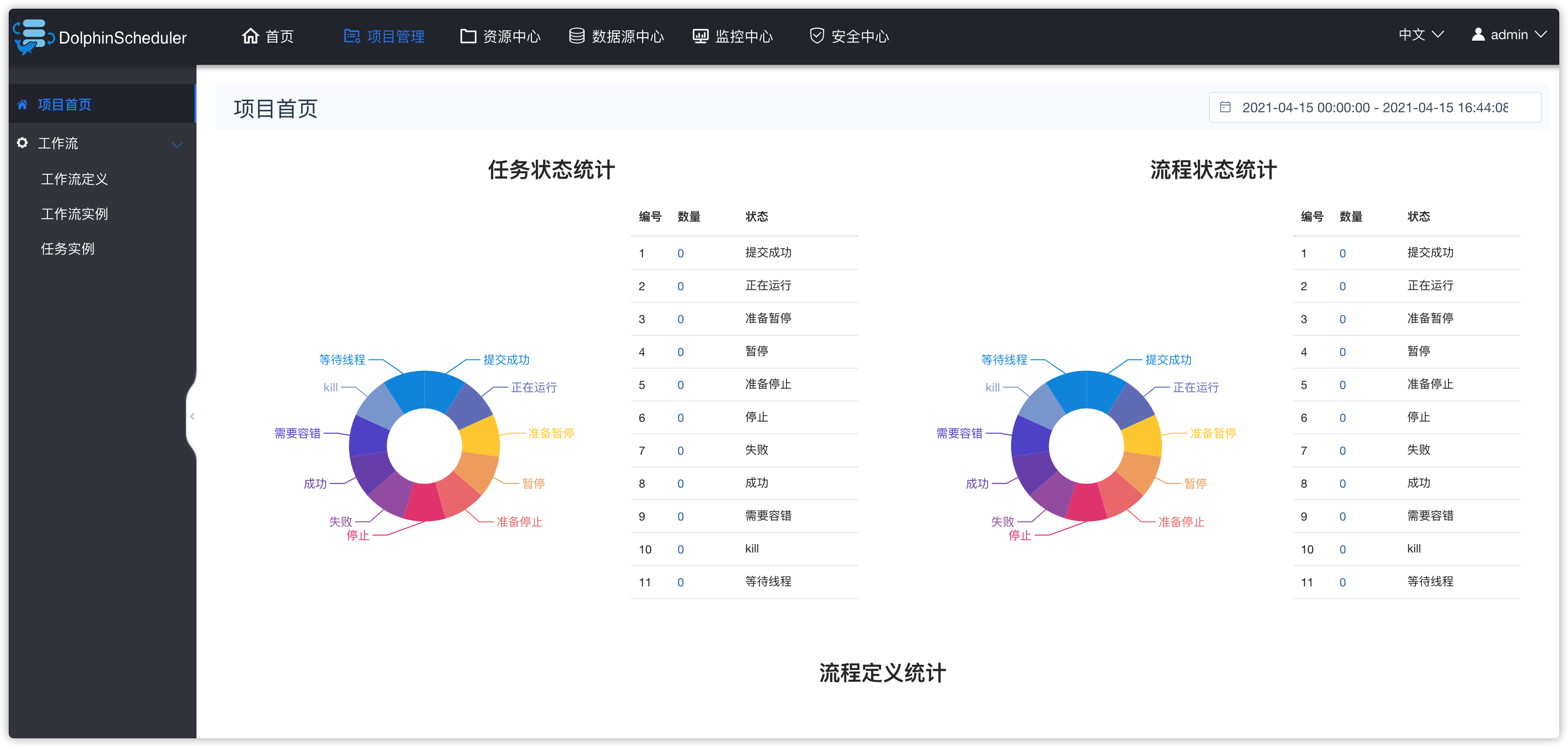
6.2 首页
- 点击上图①,进入“首页”,能够看到任务状态、流程状态
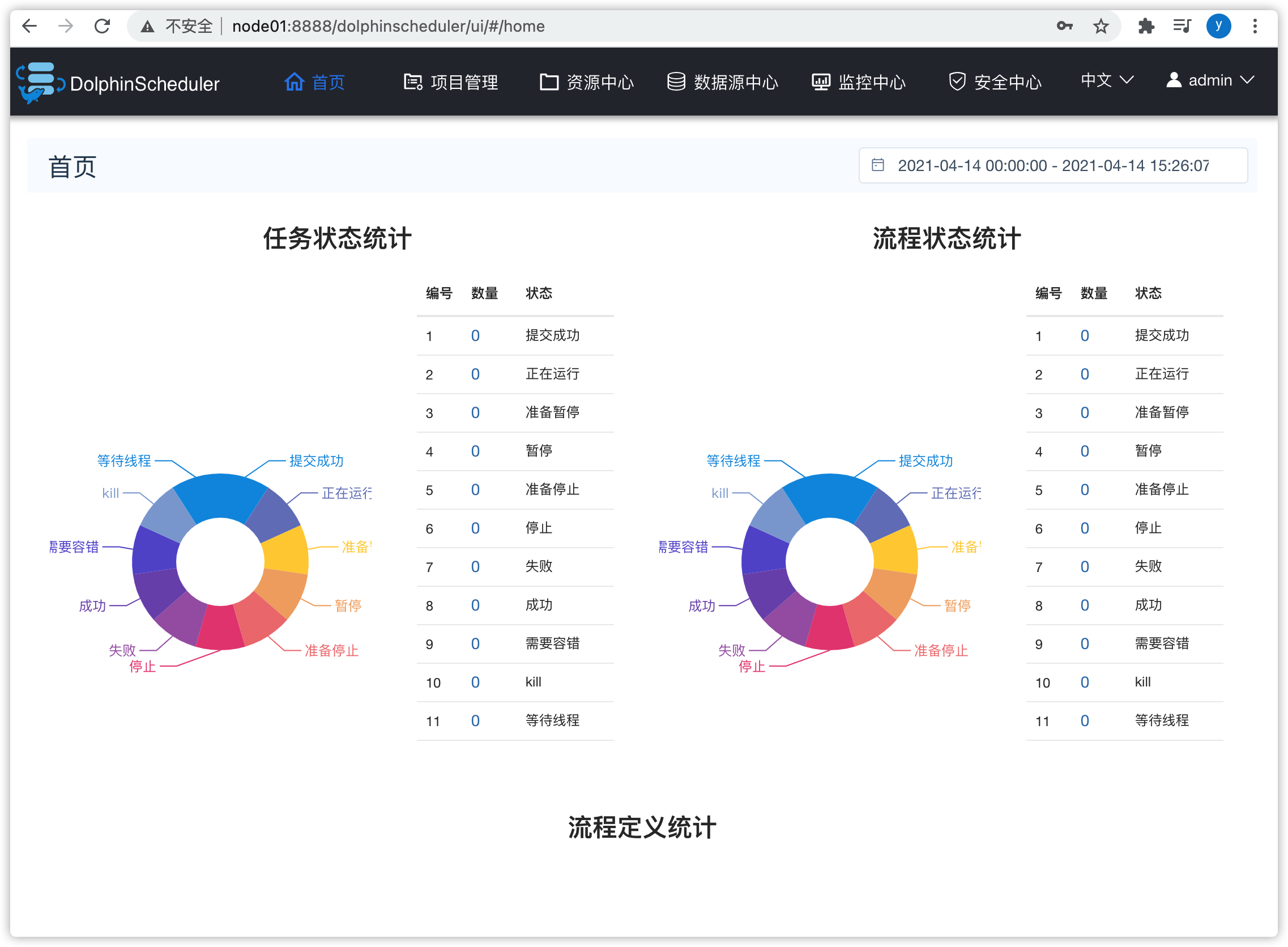
- 任务状态:
- 某个任务的各种状态;
- 如上图:提交成功、正在运行、准备暂停、暂停......
- 通过各种状态,可以看到集群的繁忙程度,尤其是“等待线程”的数量
- 流程状态:
- 流程由一个或多个任务组成
6.3 项目管理
- 点击导航栏“项目管理”
- 用来创建项目及列出已有项目
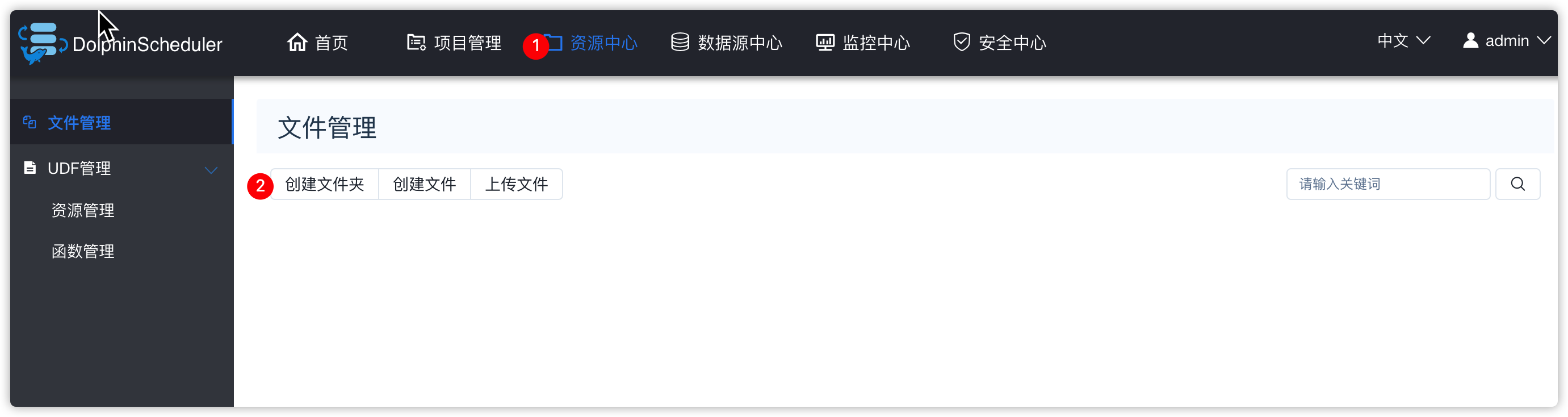
6.4 资源管理
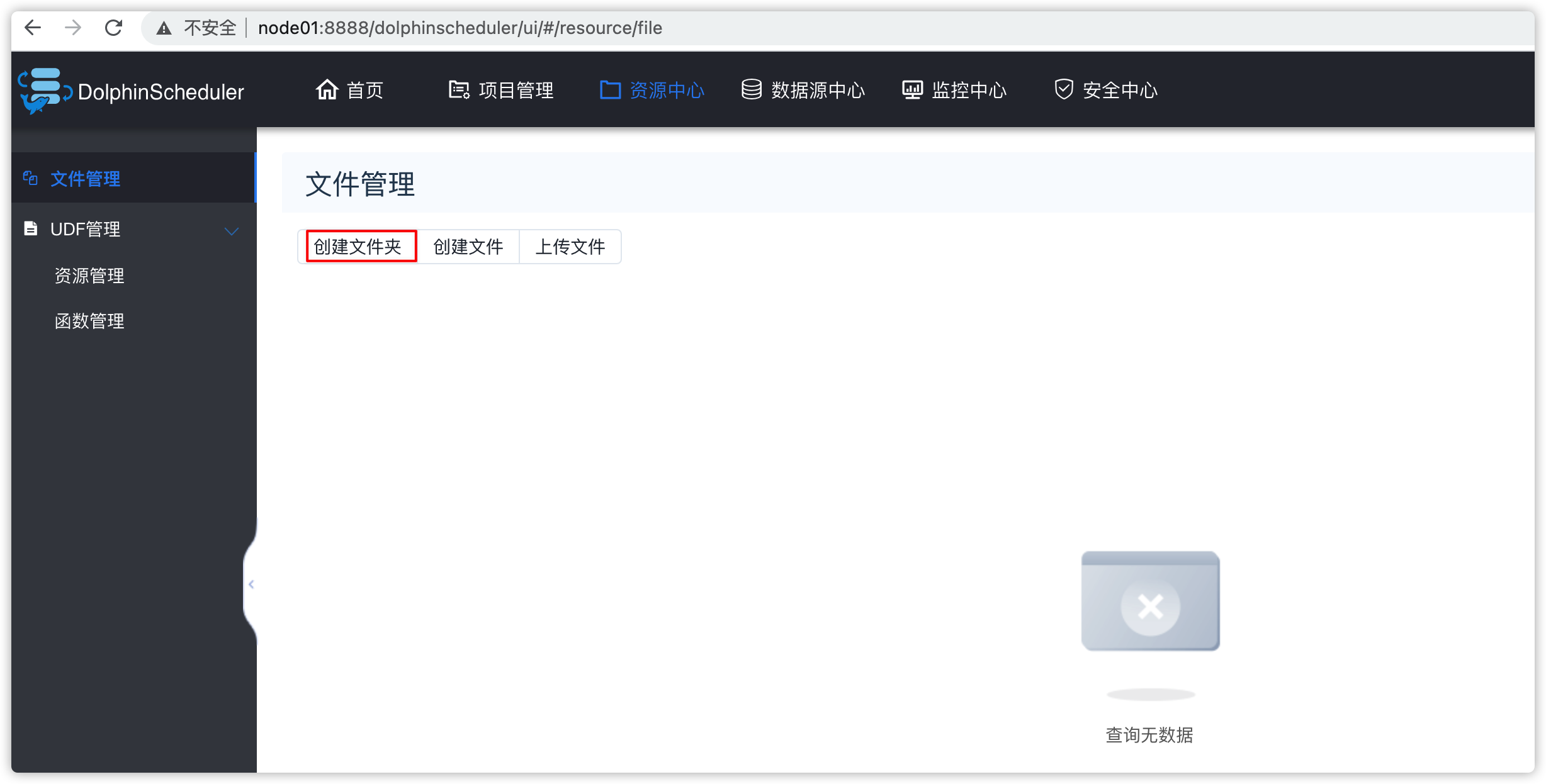
- 可以创建文件夹
- 然后在文件夹中创建脚本
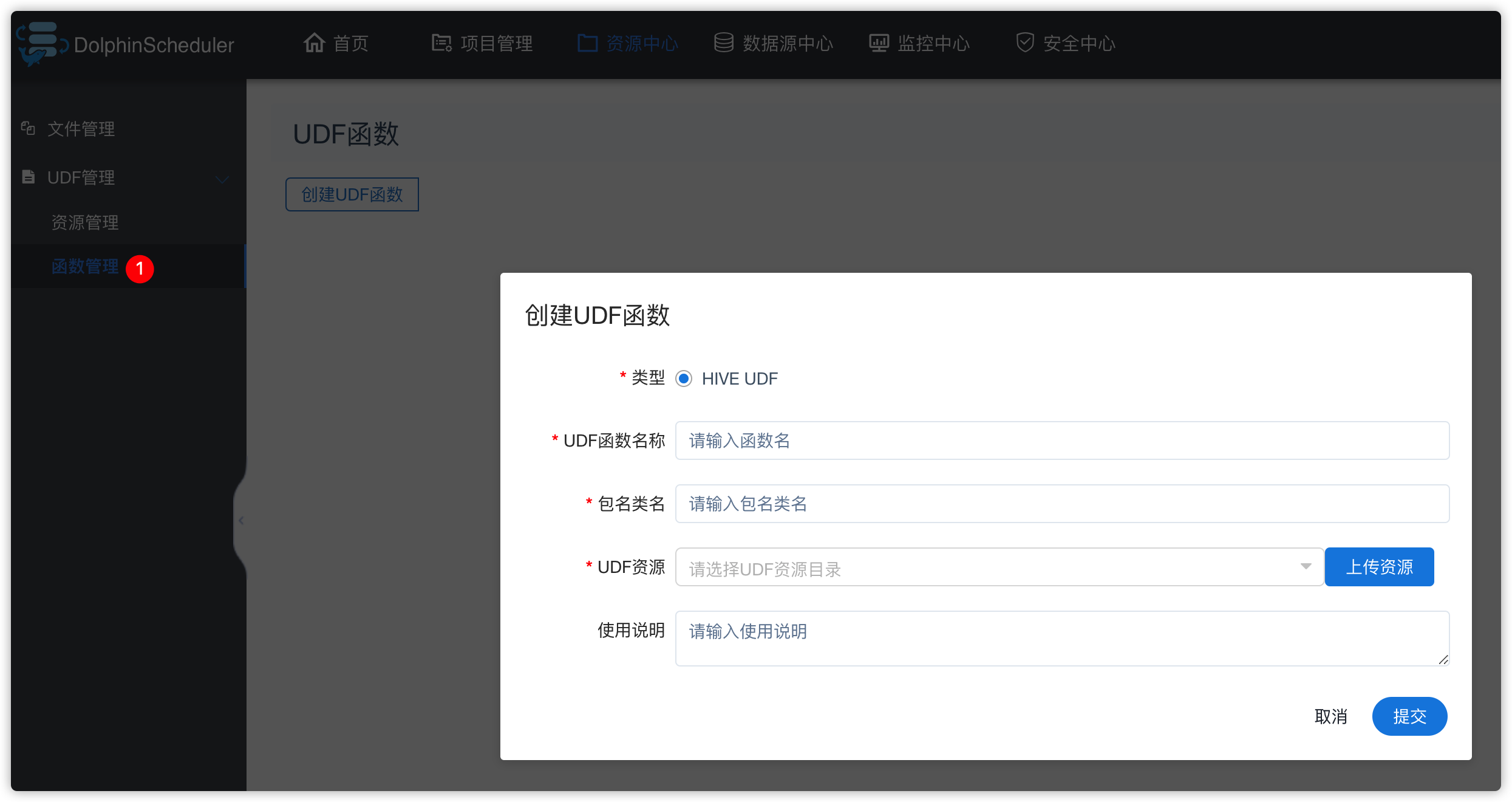
- 以后的项目里的流程中的任务可以用到这些脚本
- 函数管理:主要是创建hive的UDF函数
6.5 数据源中心
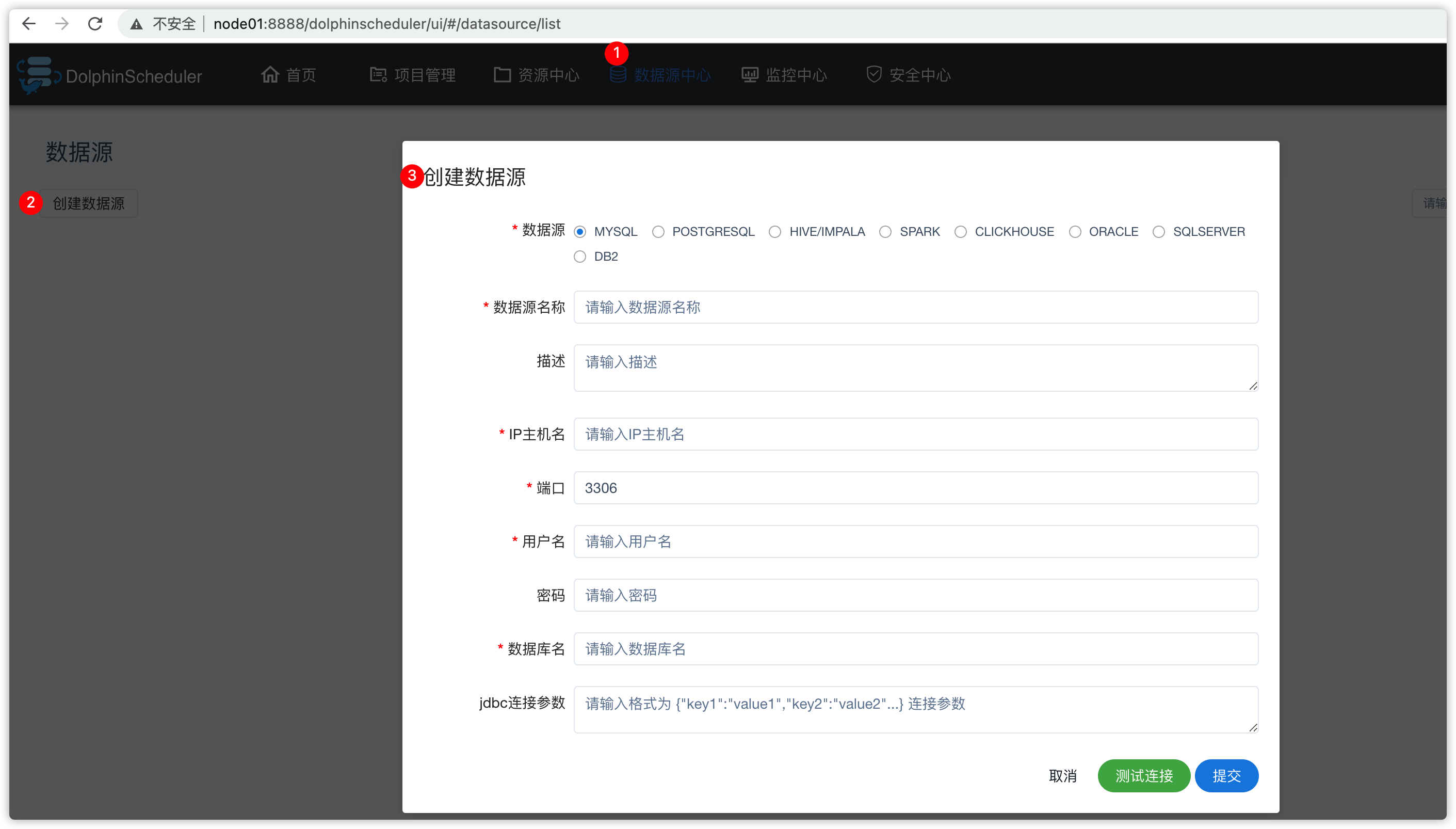
- 可以贴sql操作
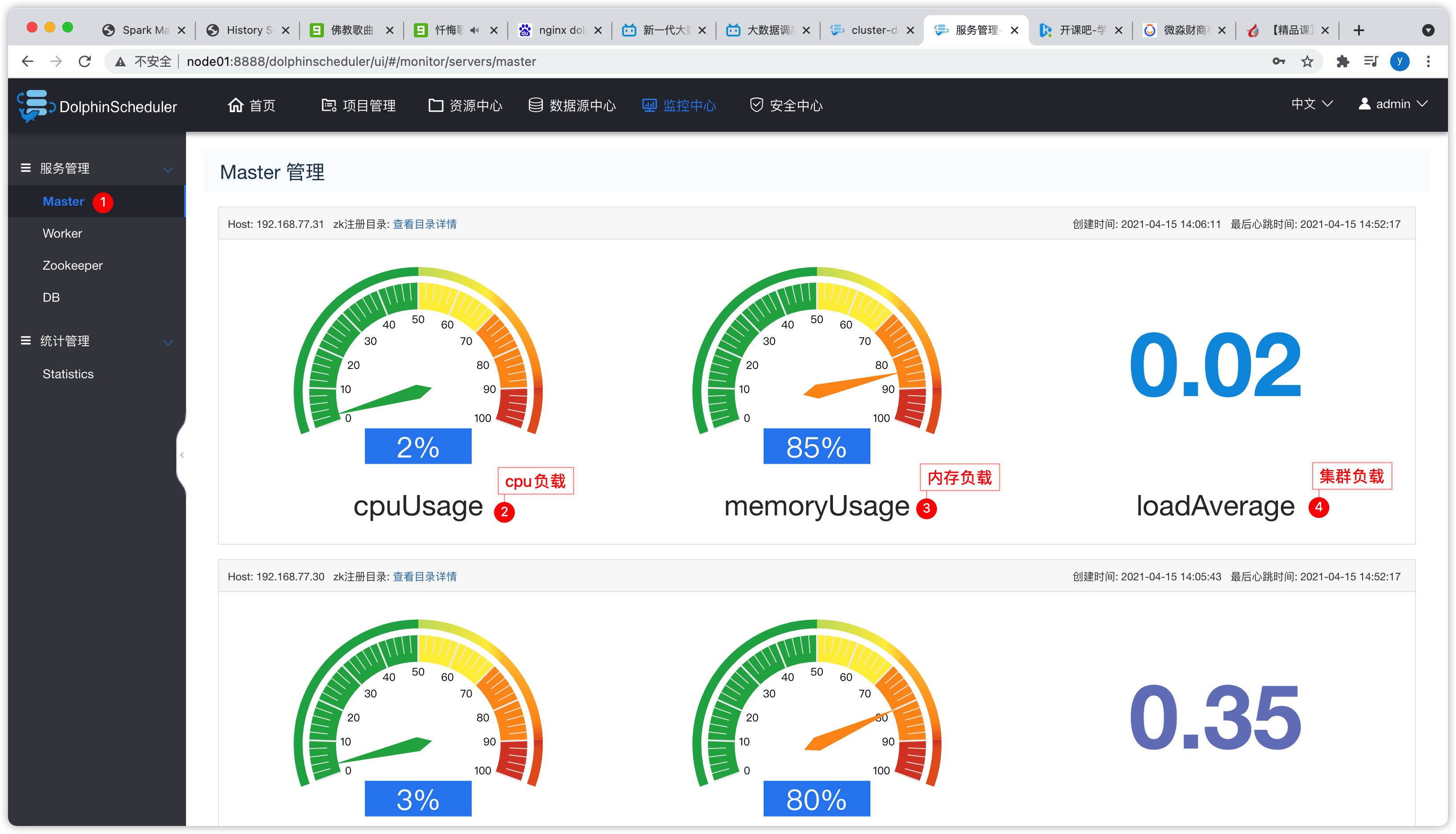
6.6 监控中心
- 可以查看master、worker、zookeeper、db等统计信息
- master
- 集群负载小于10比较正常,如果大于10,就比较繁忙了,意味着机器的性能比较弱了
- worker
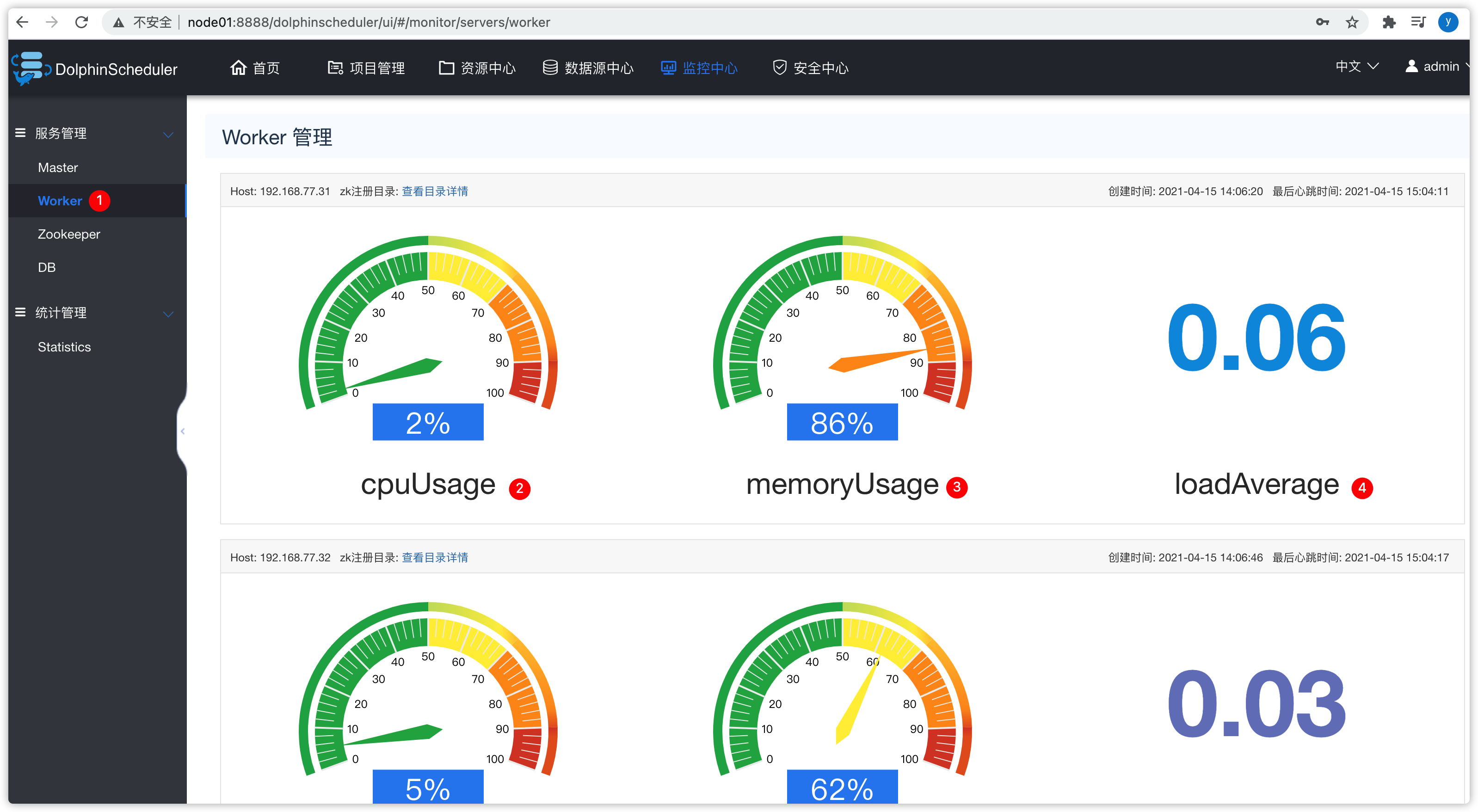
- zookeeper
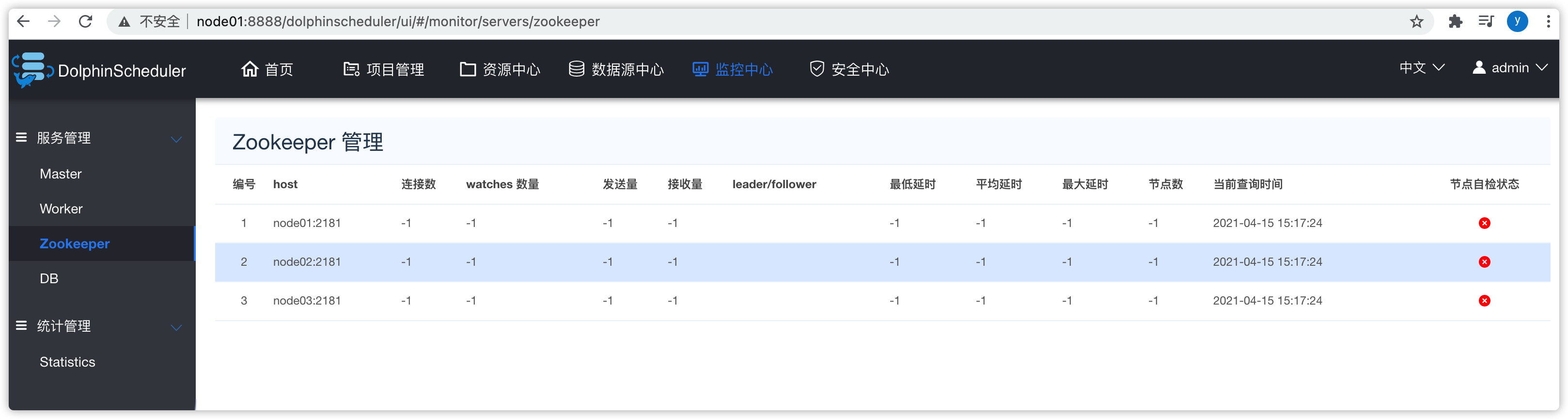
- DB
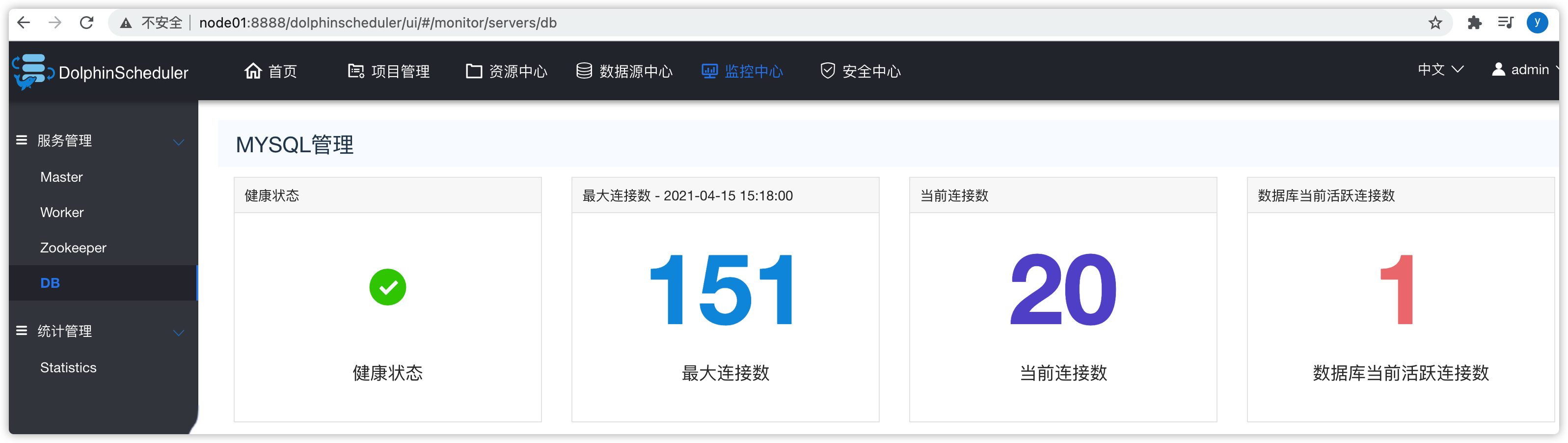
6.7 安全中心
- 管理员常用的配置页面
7、演示
7.1 安全中心
####### 1、令牌管理
- 安全中心 - 令牌管理
- 令牌管理:
- 在工作中一般用不到
- java程序跟ds调度器进行集成,用rest api进行交互的时候,会用到令牌
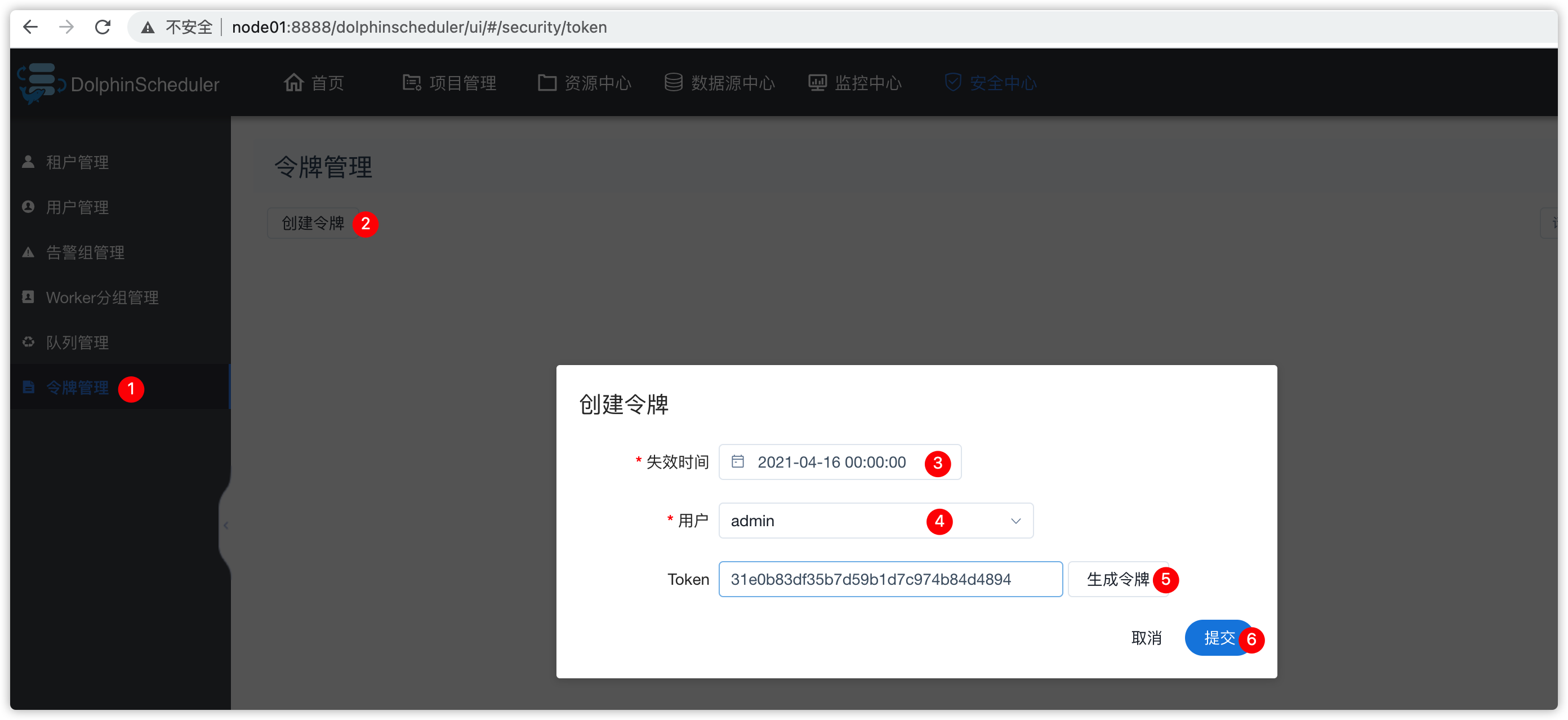
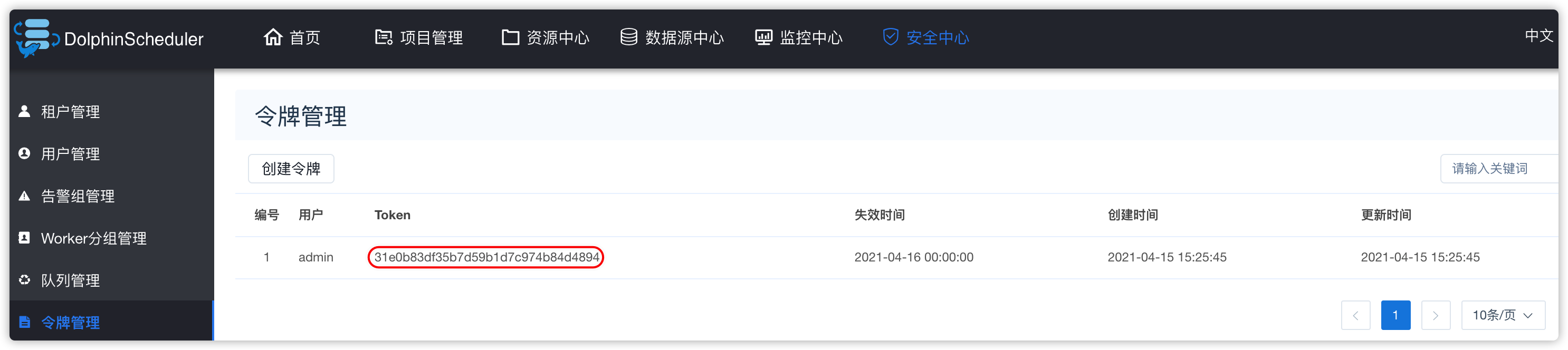
- 把token给其他项目组,其他项目组进行源代码的二次开发的时候,进行插件集成的时候,会用到token值
- 工作中正常使用ds调度时,一般用不到
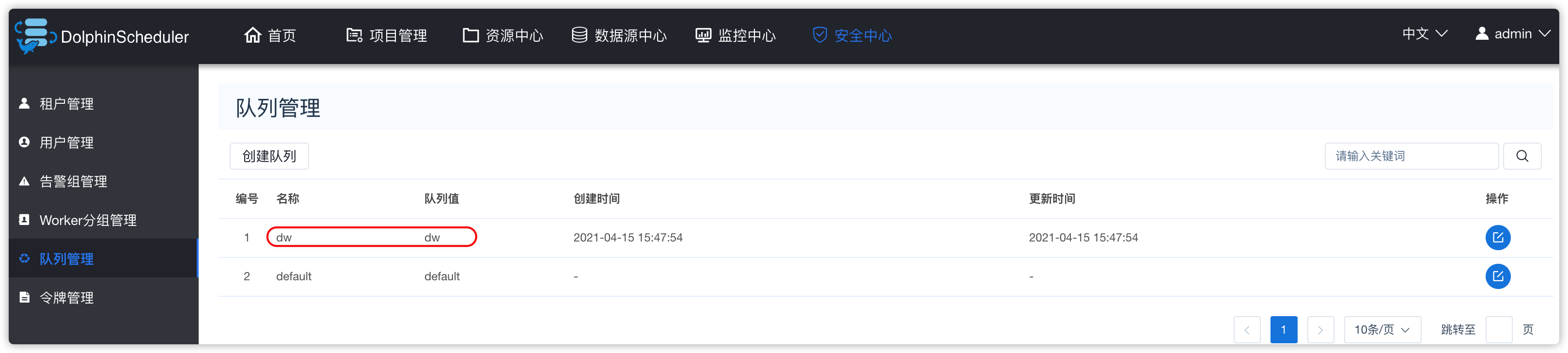
2、队列管理
- 指的是yarn调度器中的队列或cdh的动态资源池
- 提交应用到yarn集群时,可以指定将应用提交到指定的队列中,此队列占据集群的一定量的内存、cpu资源,共此应用使用;具体的可以回顾yarn中的调度器相关的知识
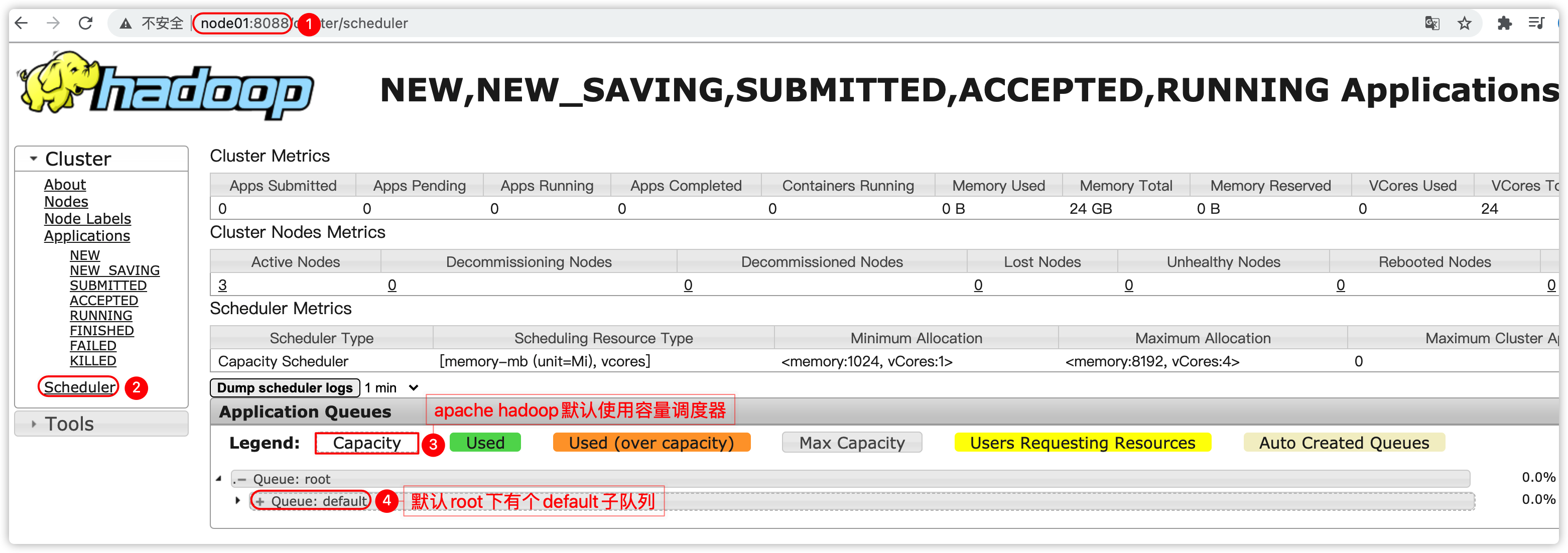
- 假设yarn的root队列下还有个队列叫
dw - 那么在ds的ui界面创建队列
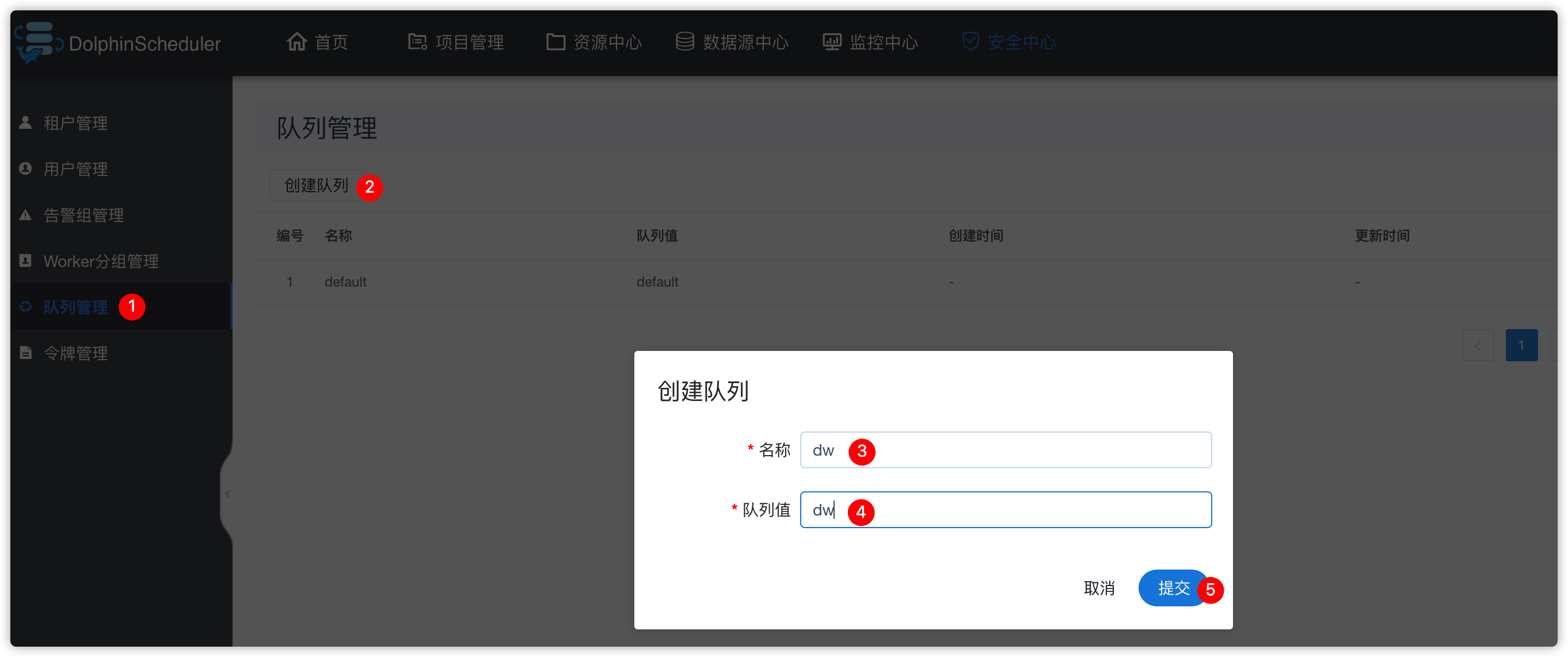
- 效果如下
3、Worker分组管理
- 默认只有default一个分组
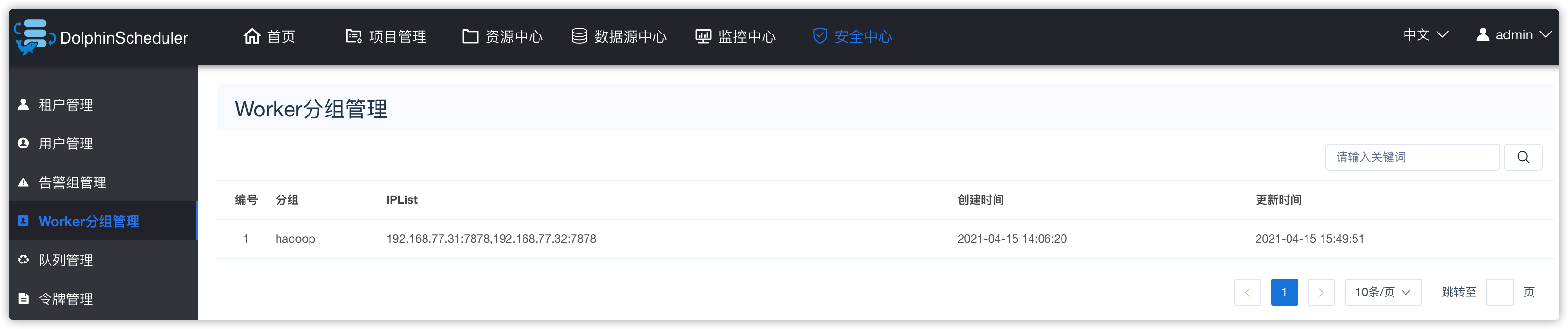
- 如果将来ds集群有一些机器是高配,一些是低配的,那么可以进行分组,比如提交时,指定提交到高配的机器上执行
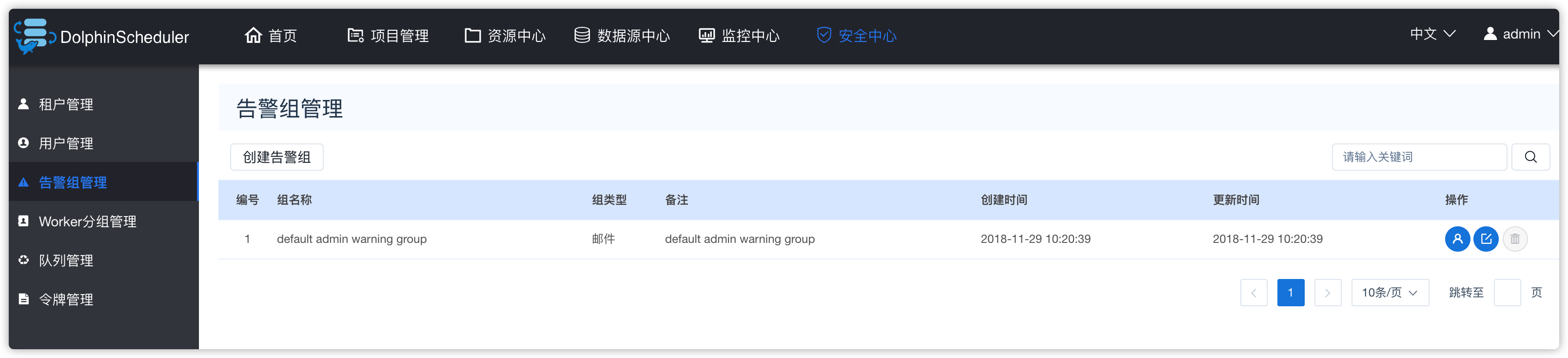
4、告警组管理
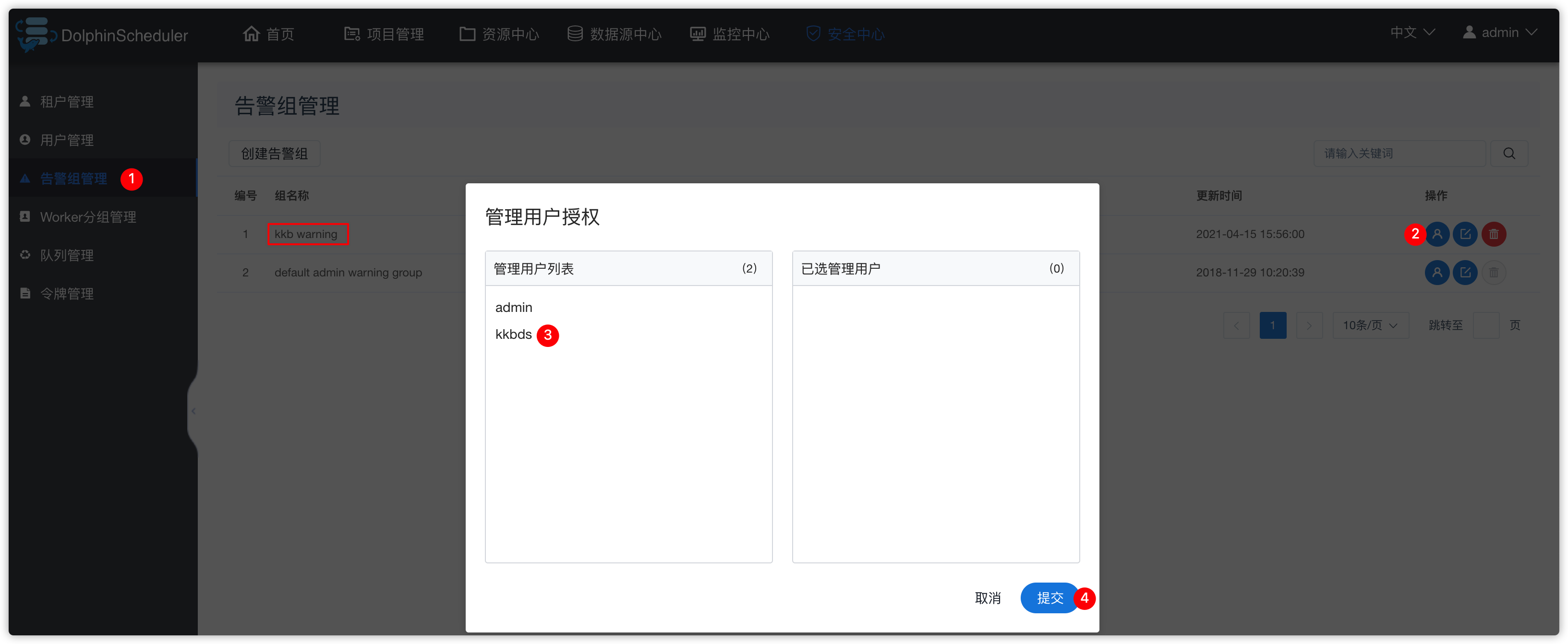
- 默认如下
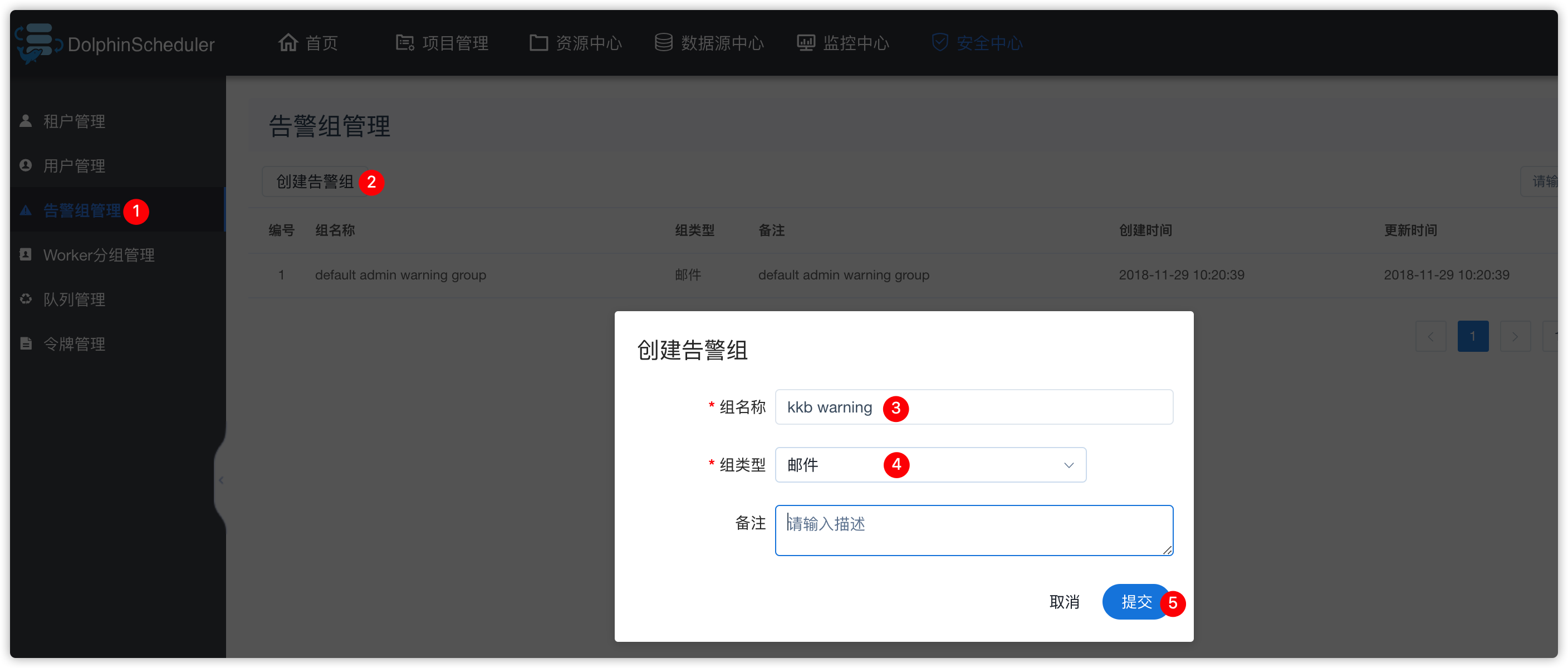
- 创建告警组
- 管理告警组关联的管理用户
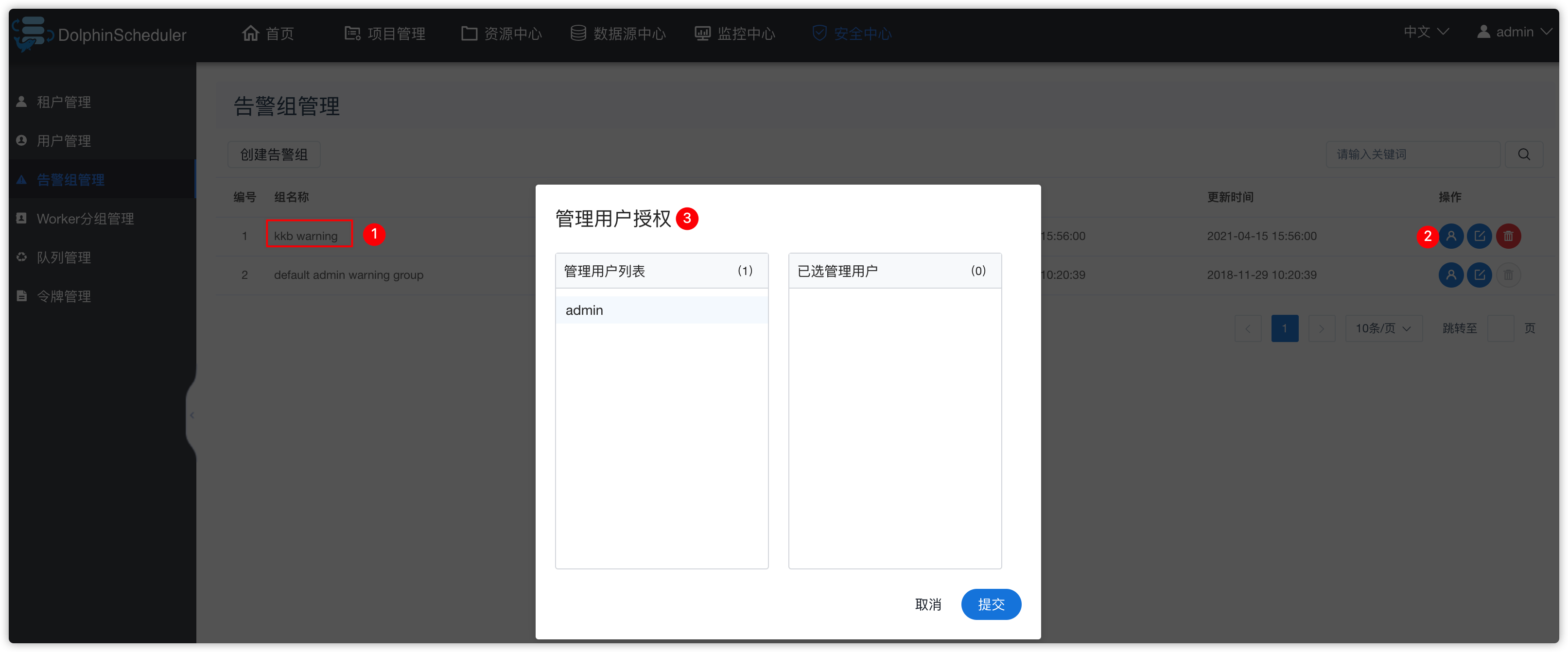
- 随后创建好一个ds用户后,再在上图中关联“管理用户” todo
5、租户管理
- 如果要创建ds的用户,会用到租户
- 所以,此处,我们先创建租户
- 租户:
- ds调度执行时,会通过
su - hadoop类似的用法,切换到linux的某用户,进行执行任务
- ds调度执行时,会通过
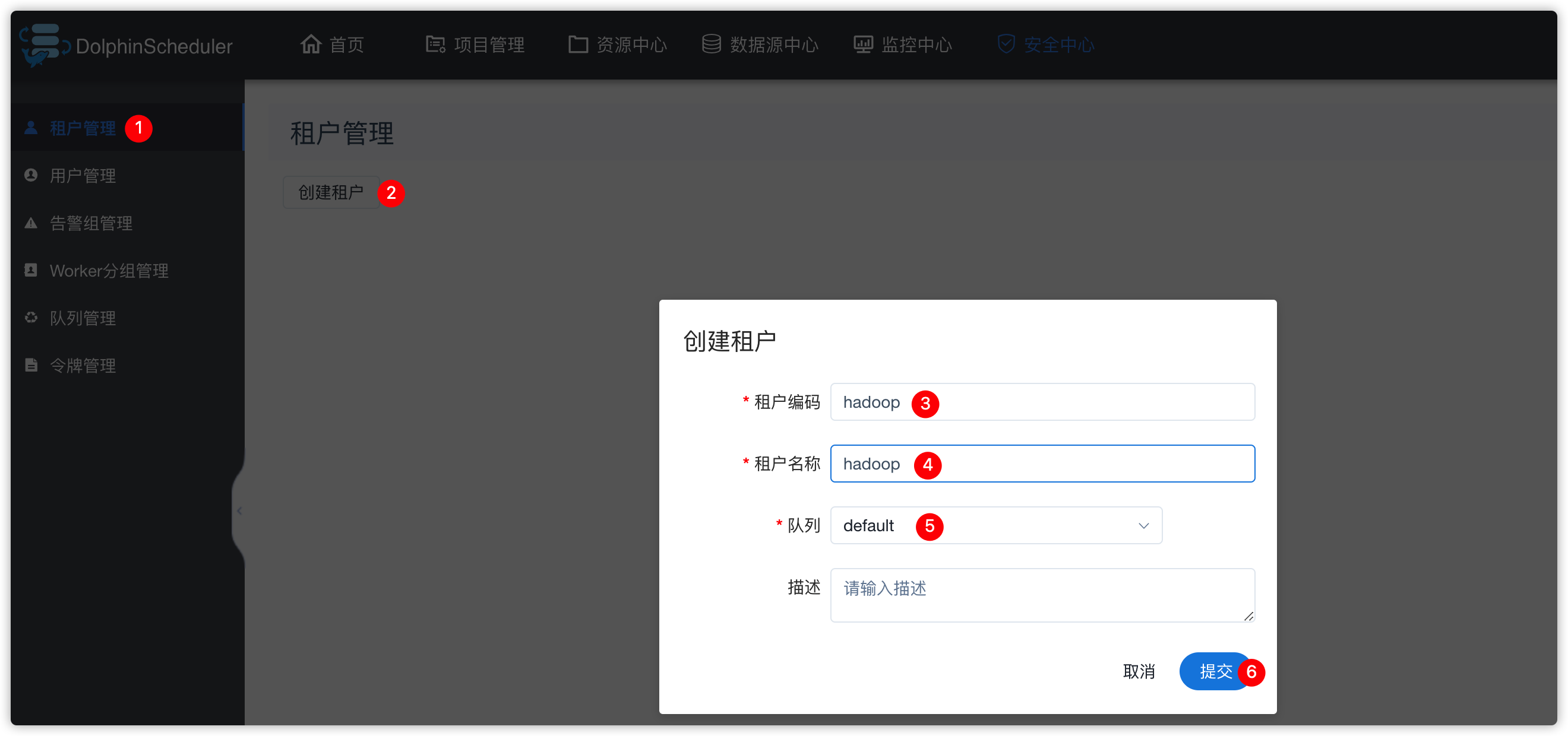
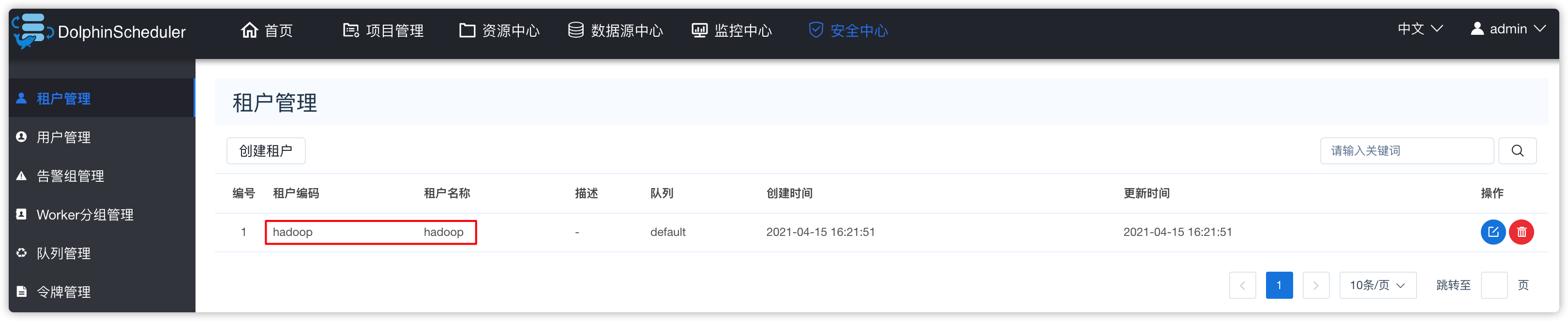
- 效果如下
6、用户管理
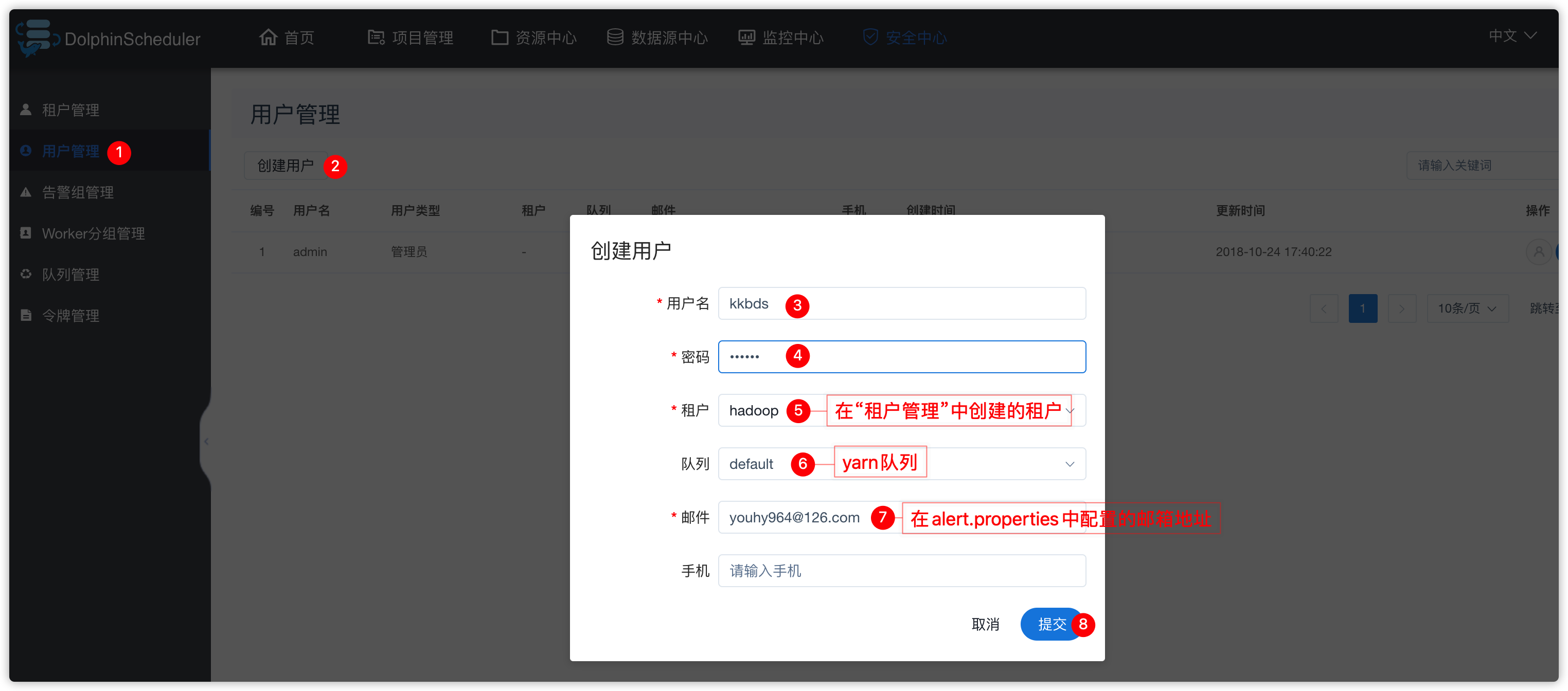
- 效果如下
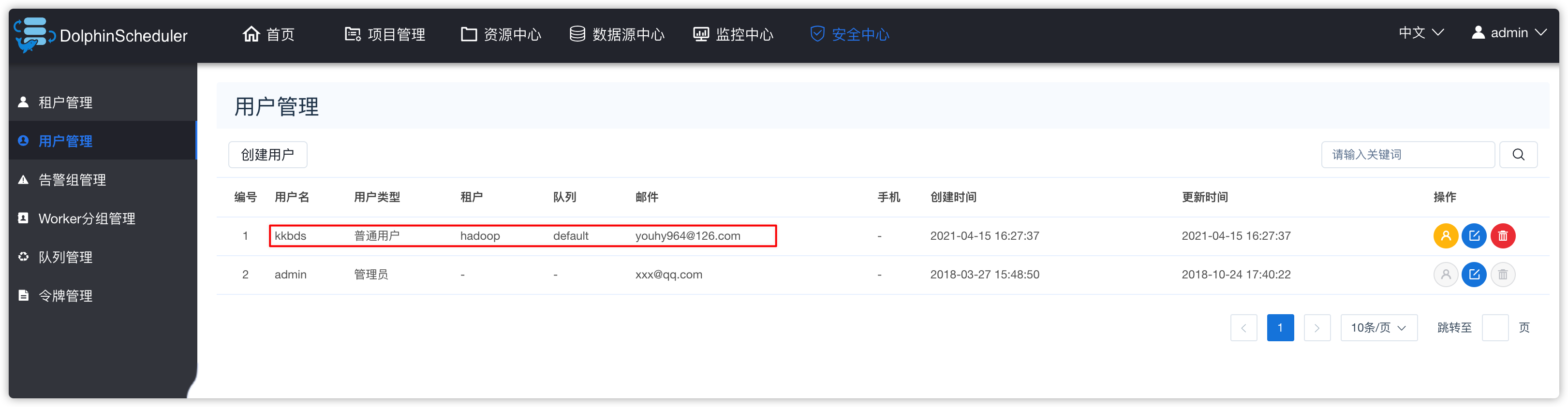
- 接下来去“告警组管理”中,给刚创建的告警组“kkb warning”进行管理用户授权,如下操作
- 告警发生后,发送给谁?此处我们发送给
kkbds用户的邮箱
7.2 项目管理
1、创建项目
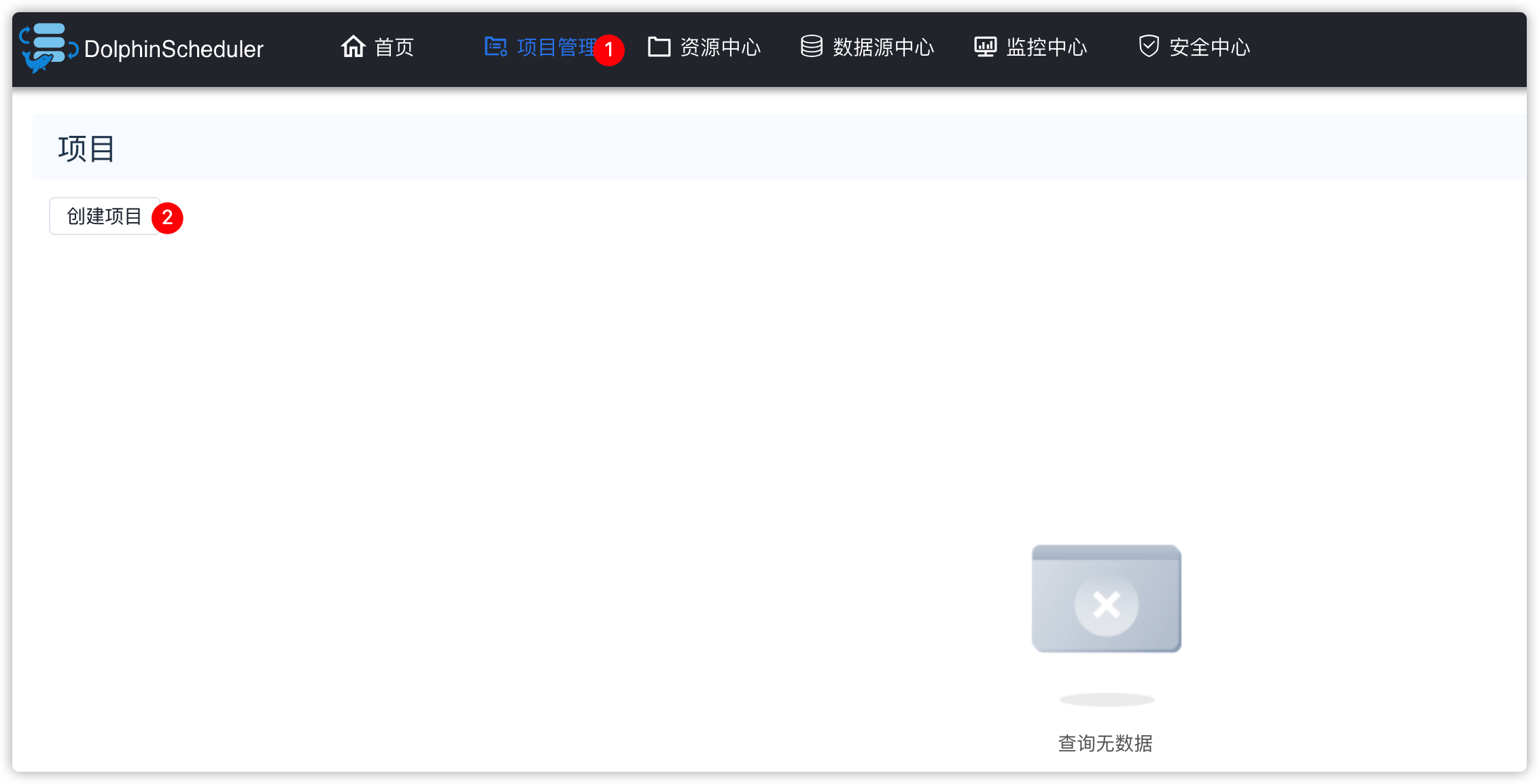
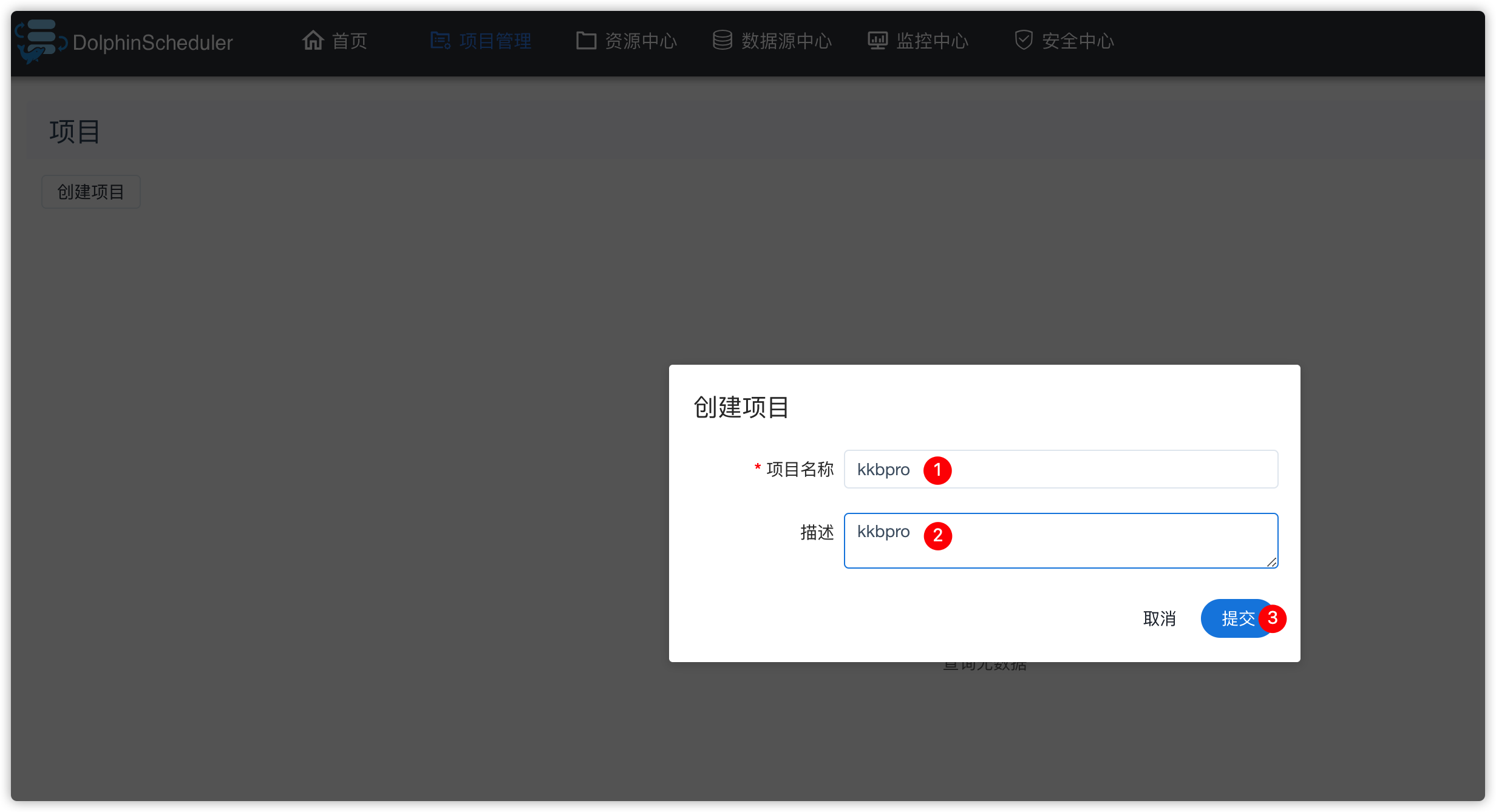
2、创建工作流
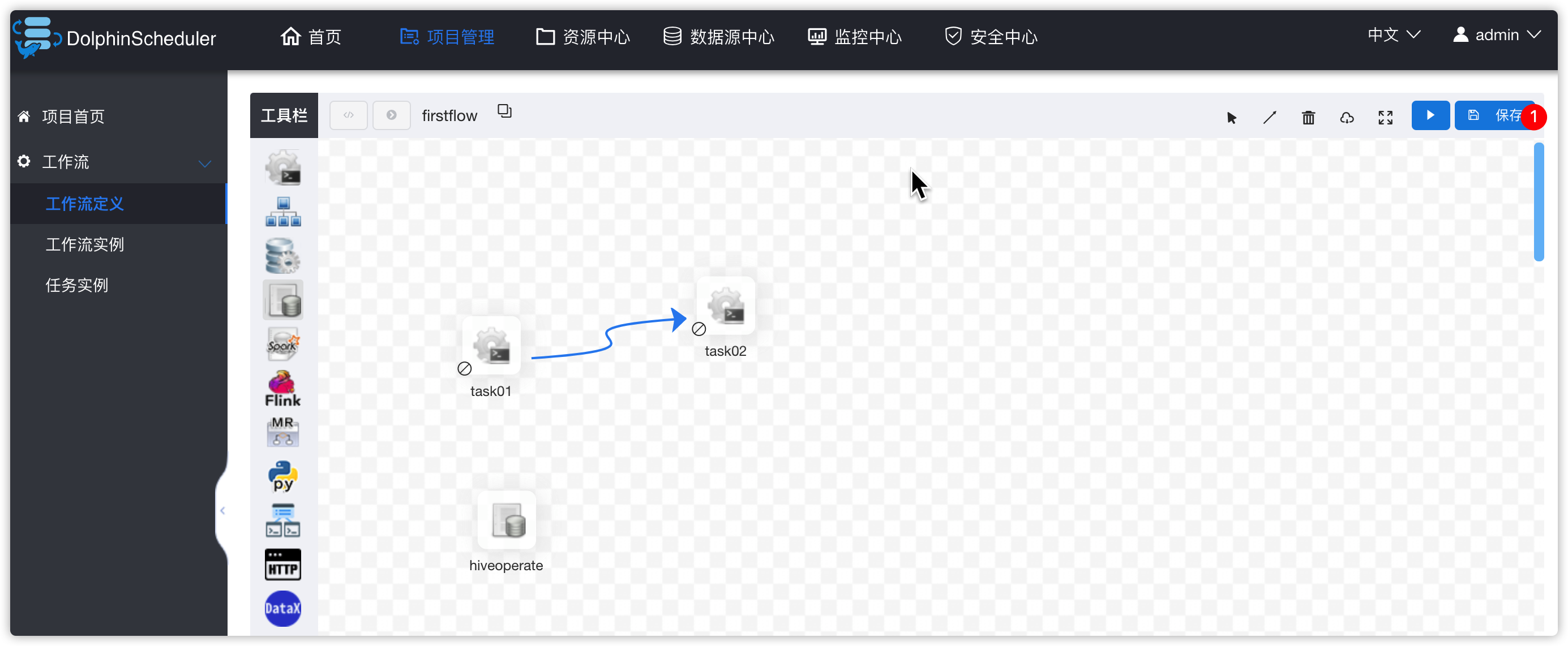
- 进入项目页面
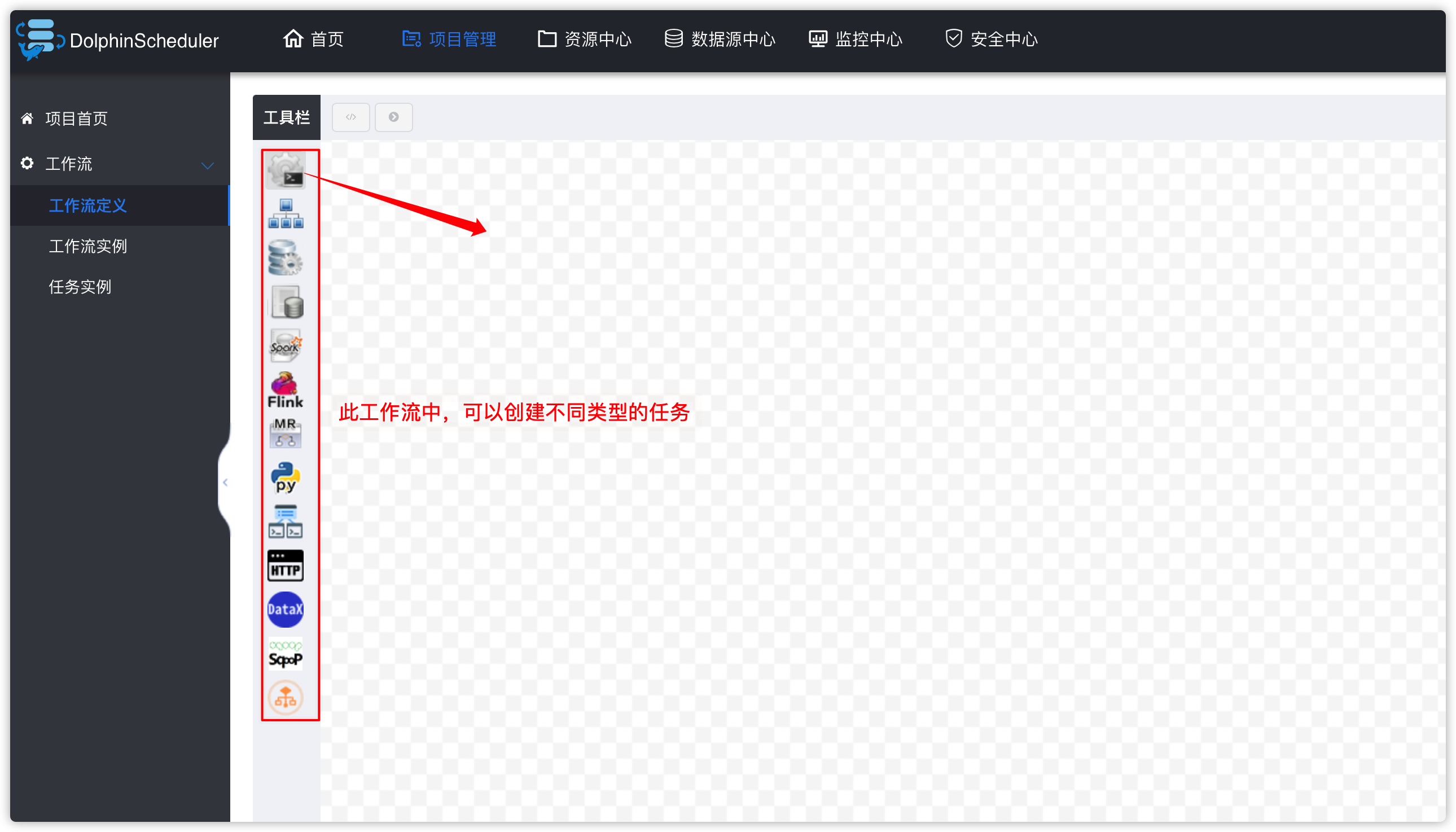
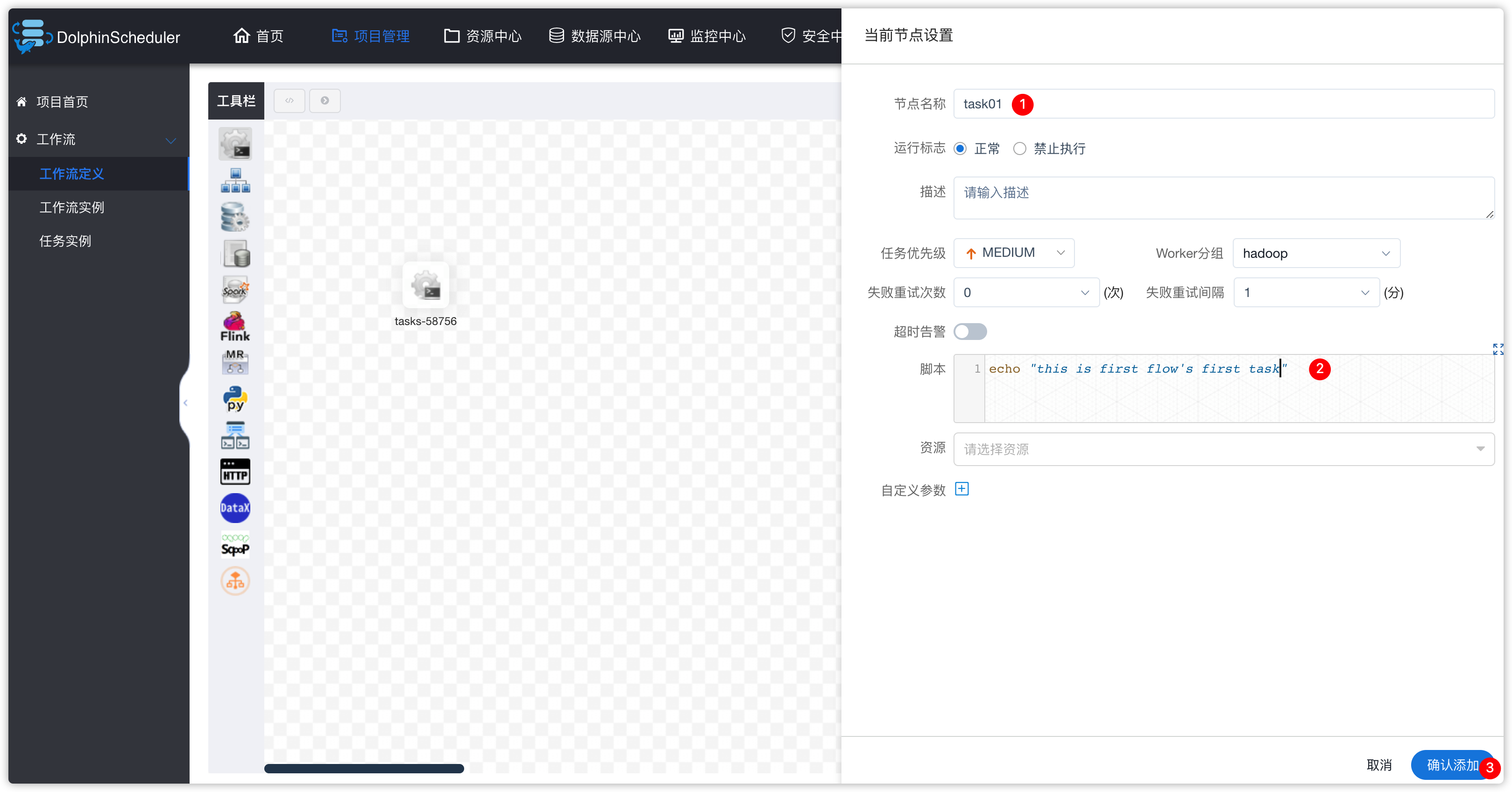
- 拖动shell图标到右侧区域,添加一个shell类型的task,并在下图中设置相关的参数
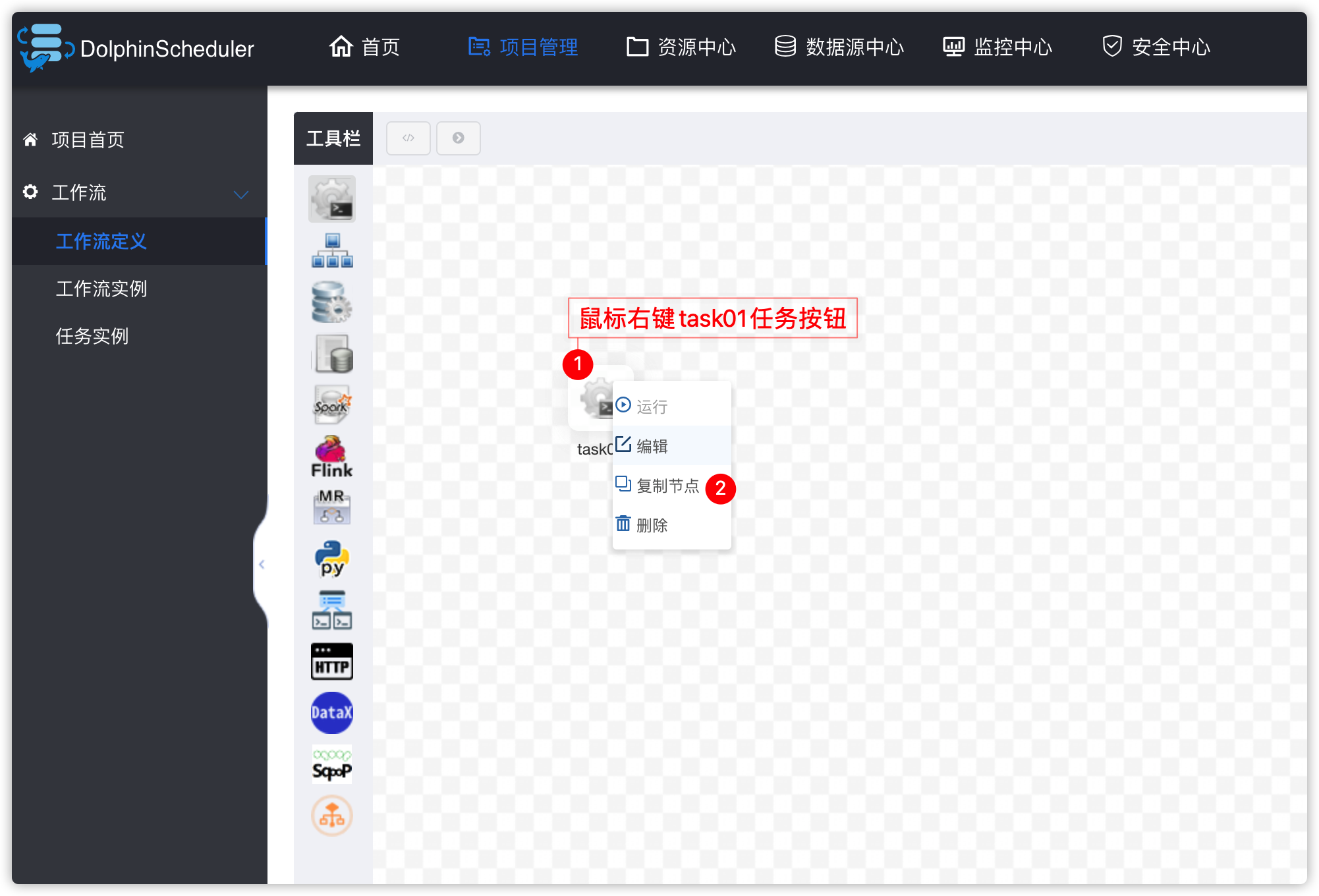
- 复制一个task
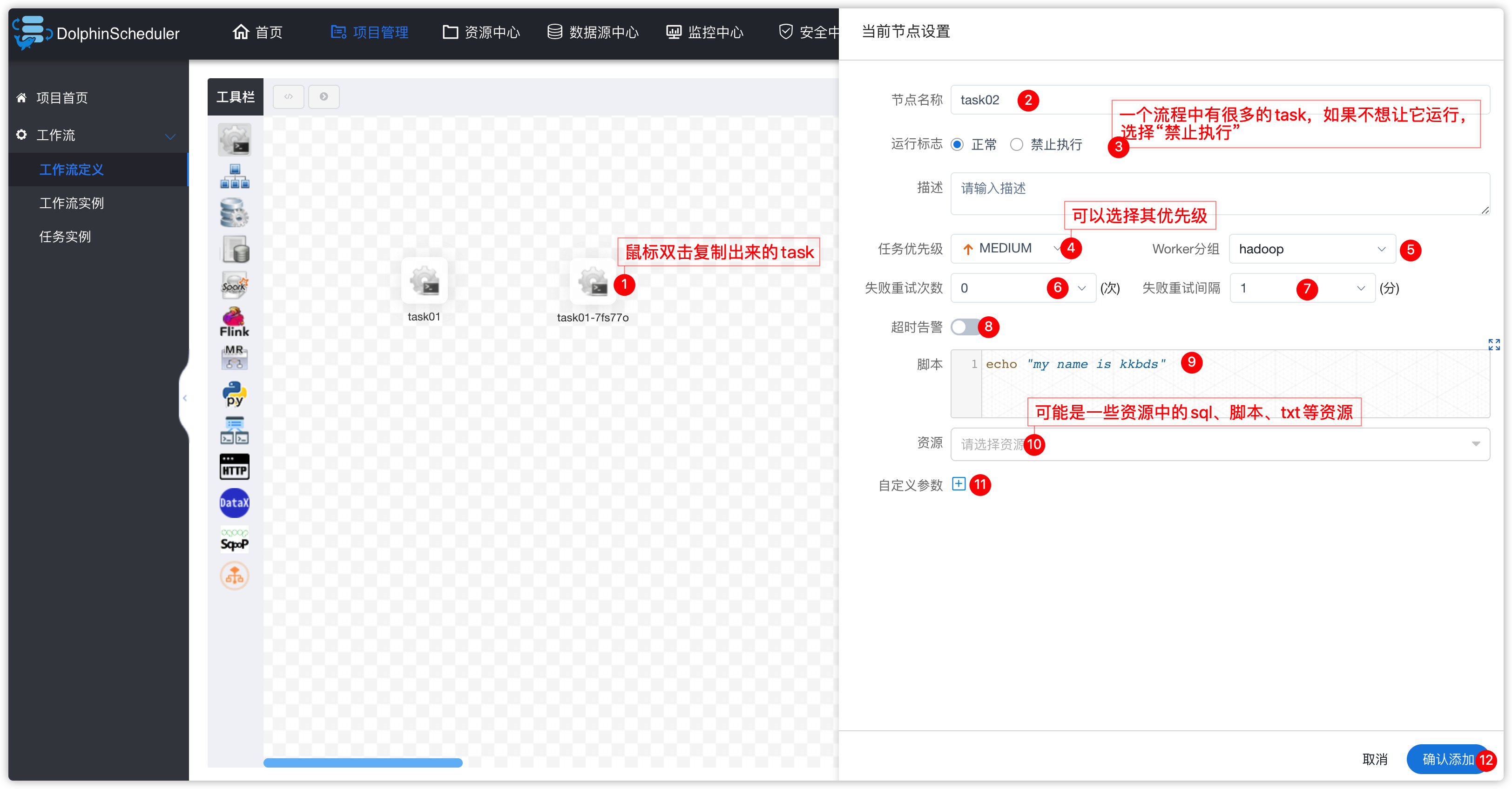
- 给新task做参数设置
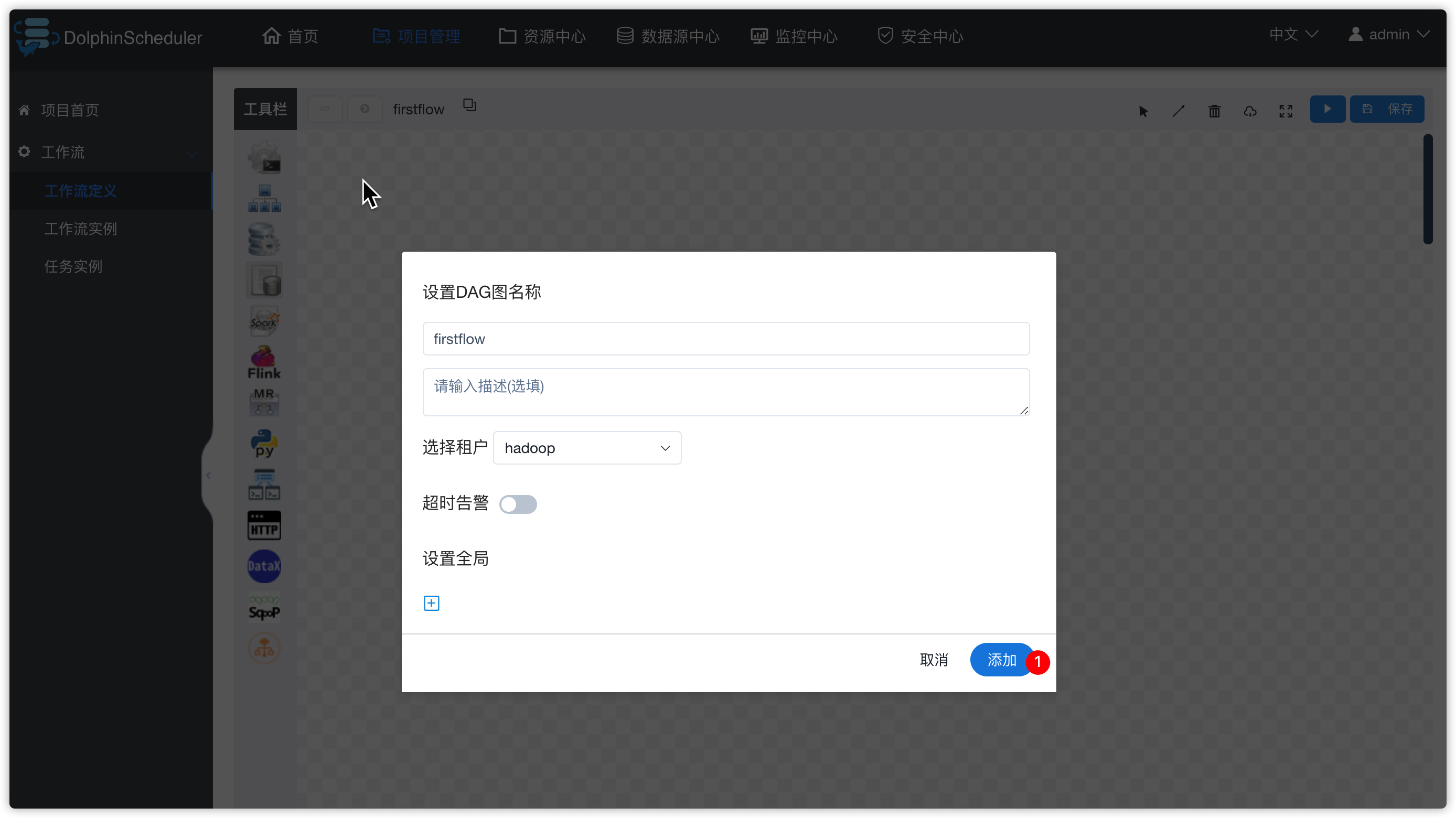
- 串联两个task,并保存
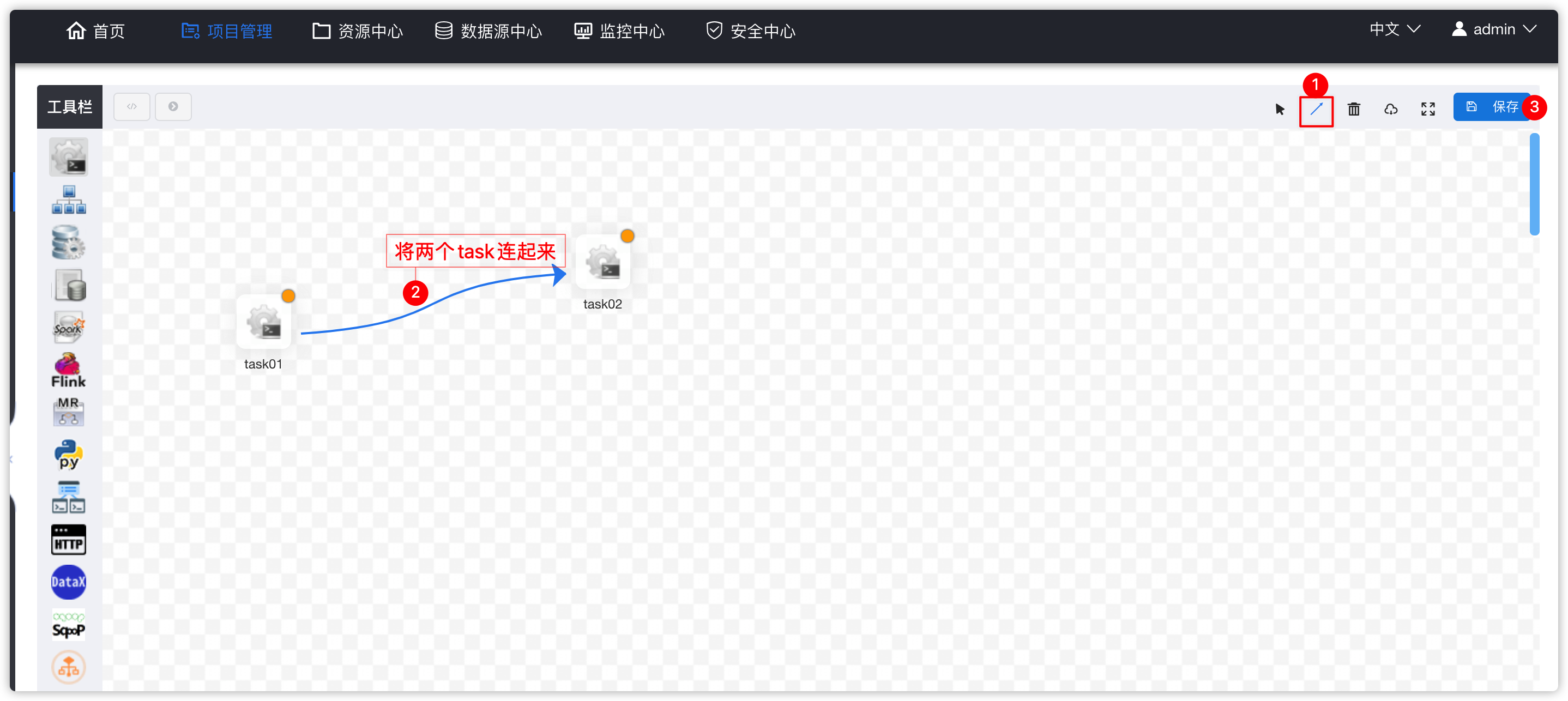
- 弹出下图
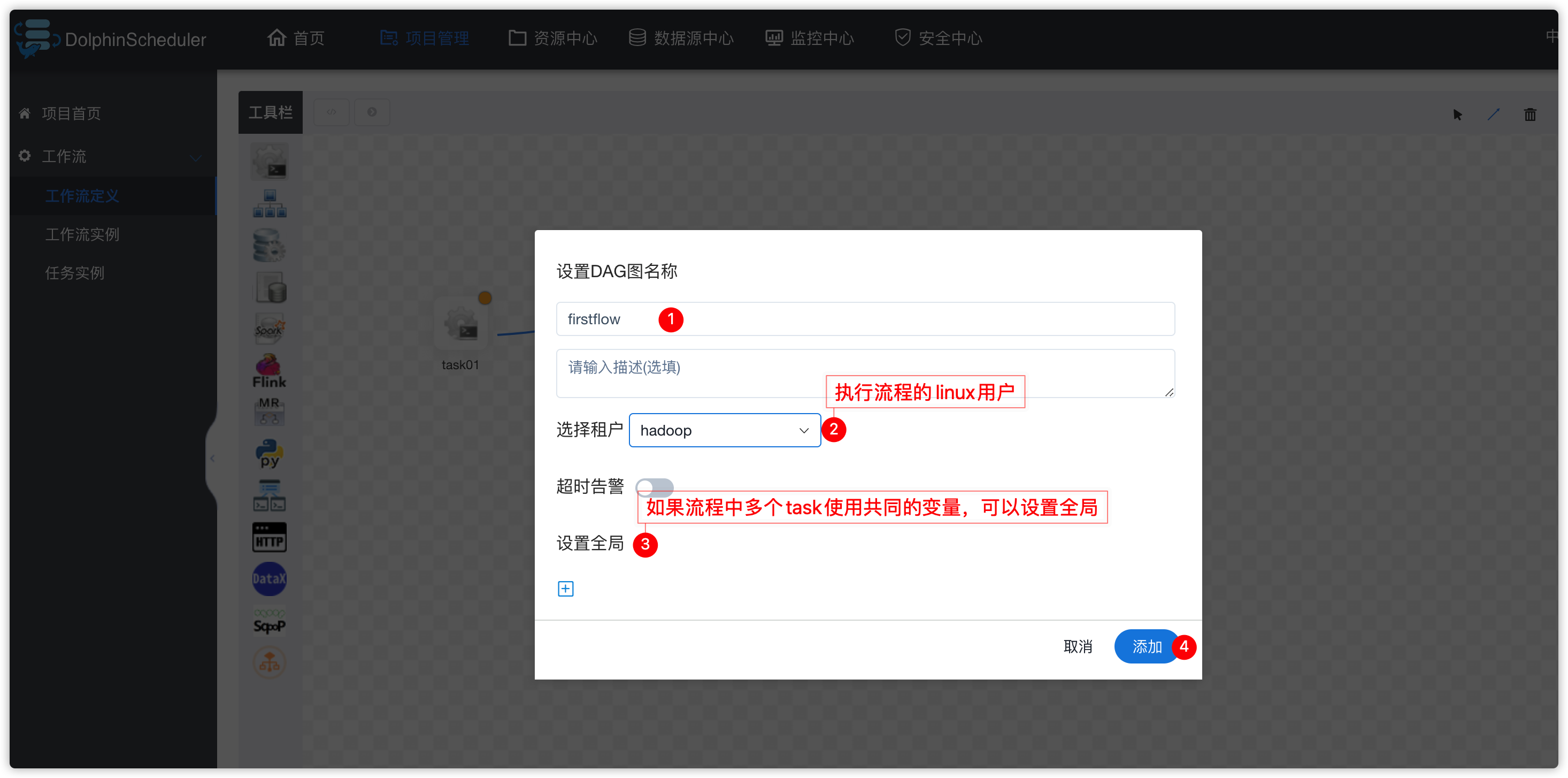
- 出现下图效果
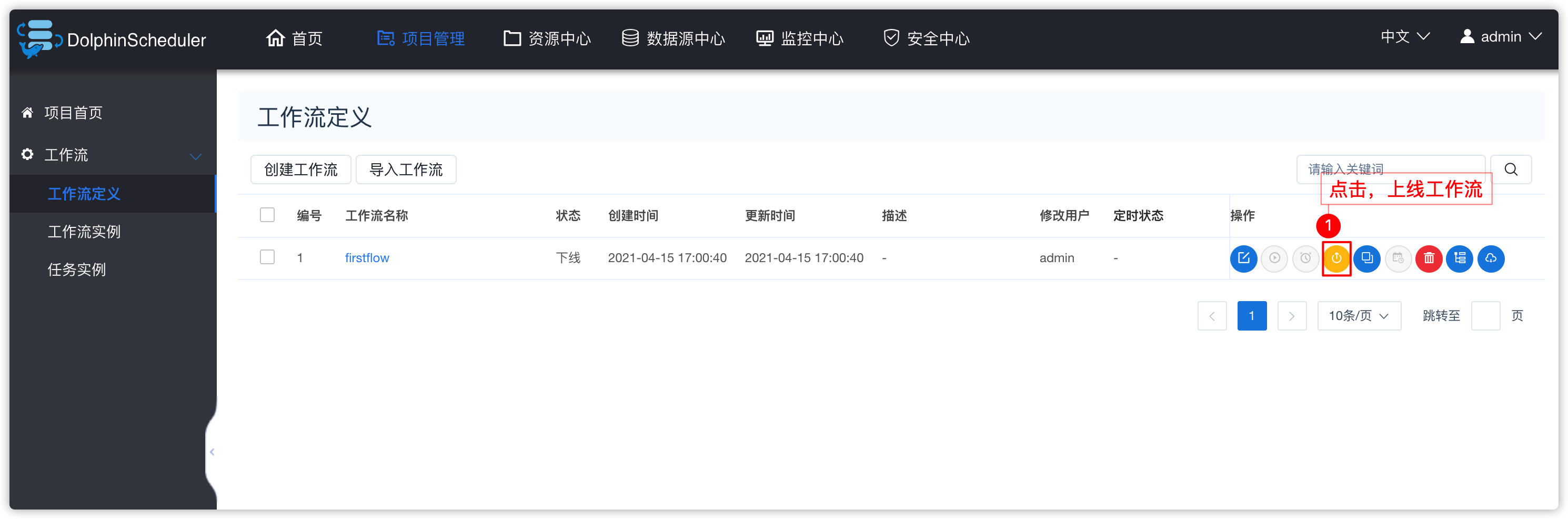
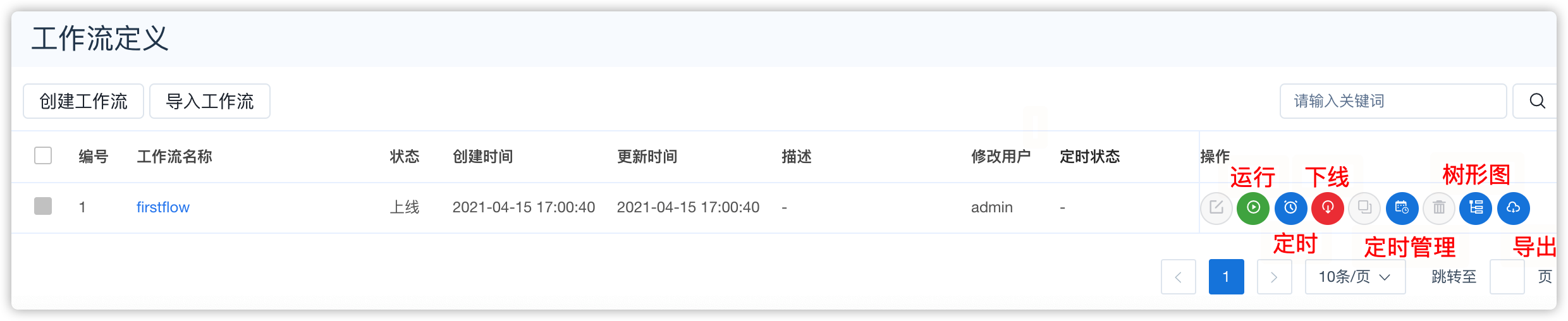
- 流程按钮说明
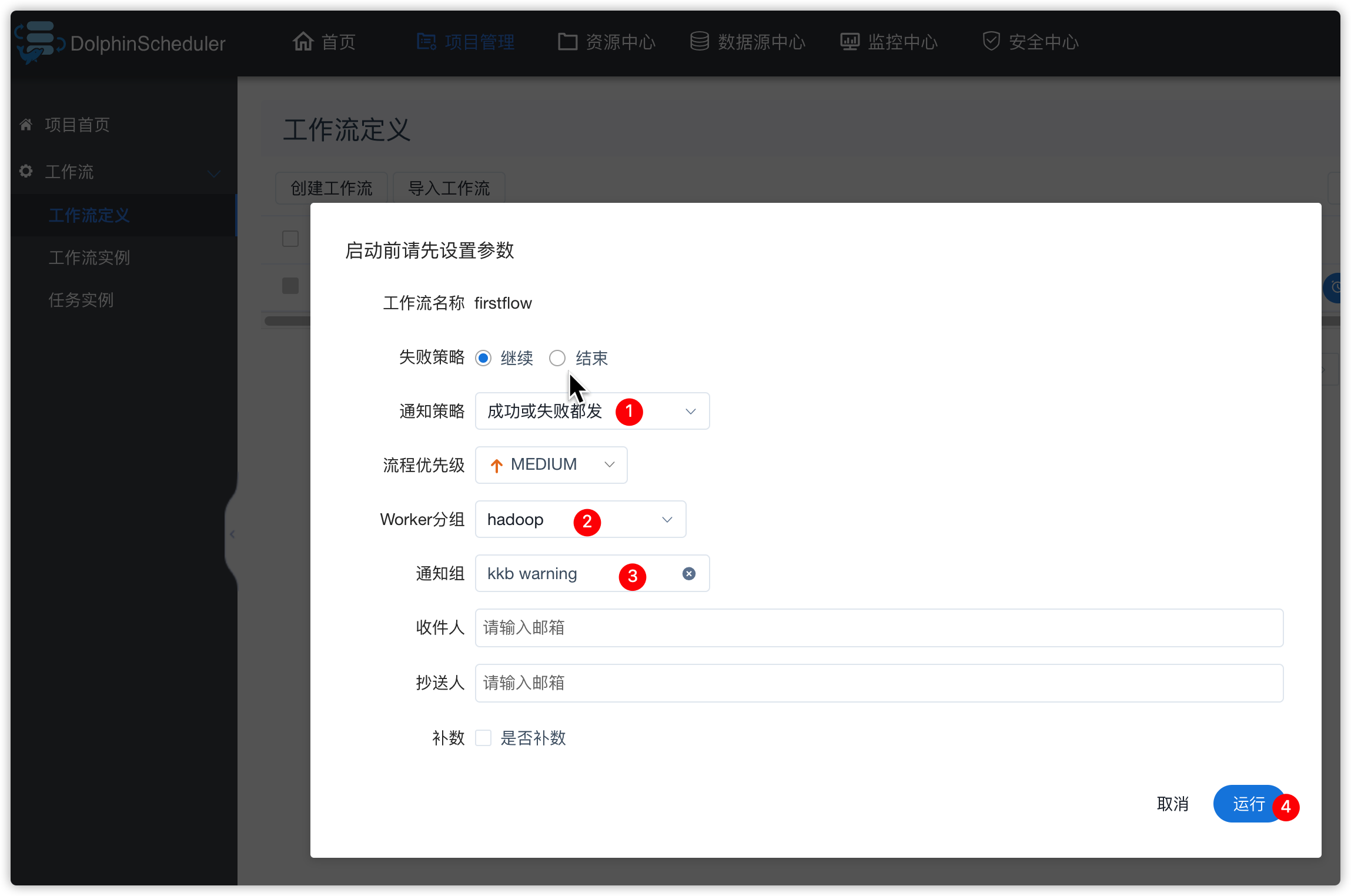
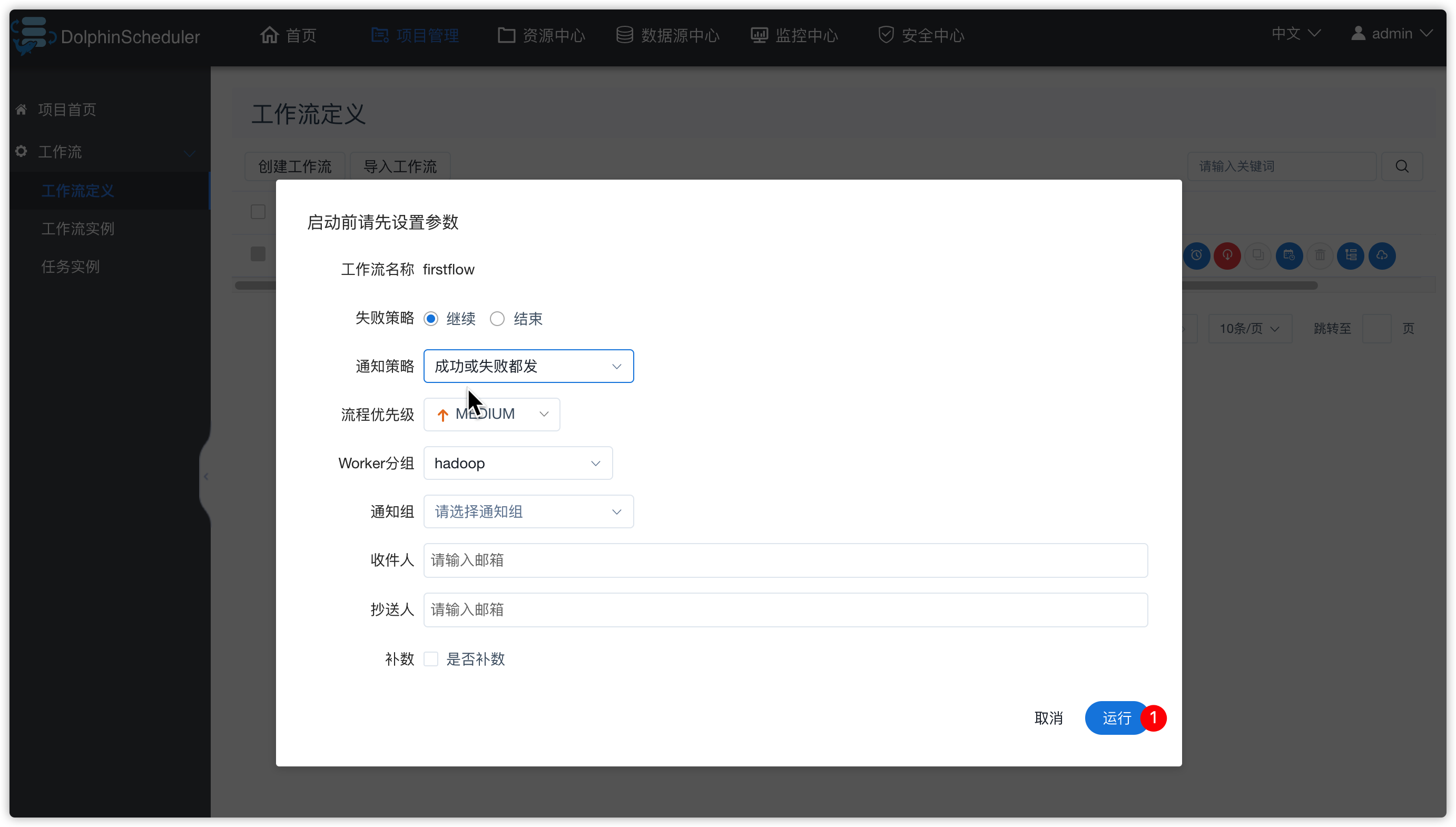
- 点击“运行”按钮
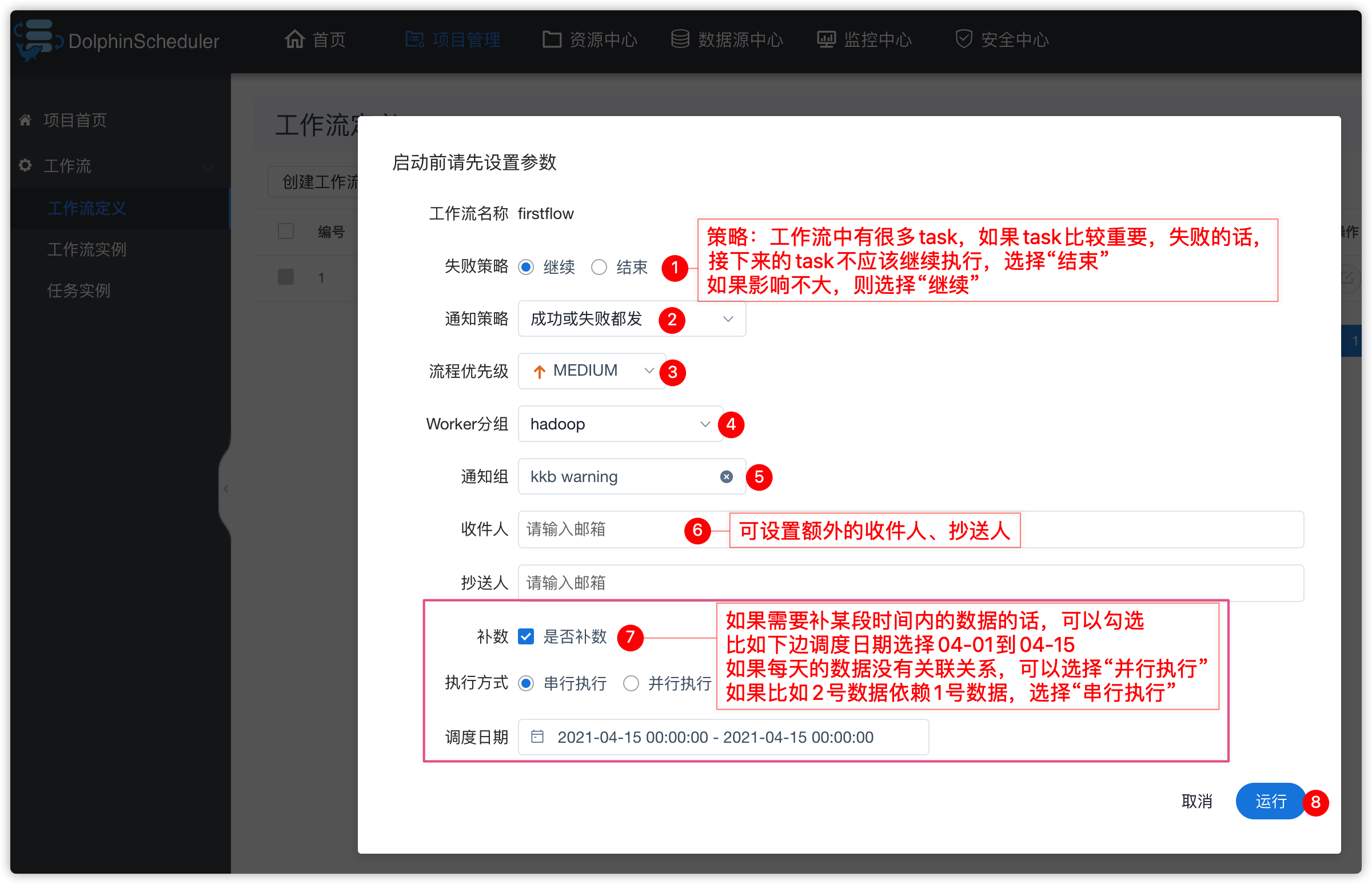
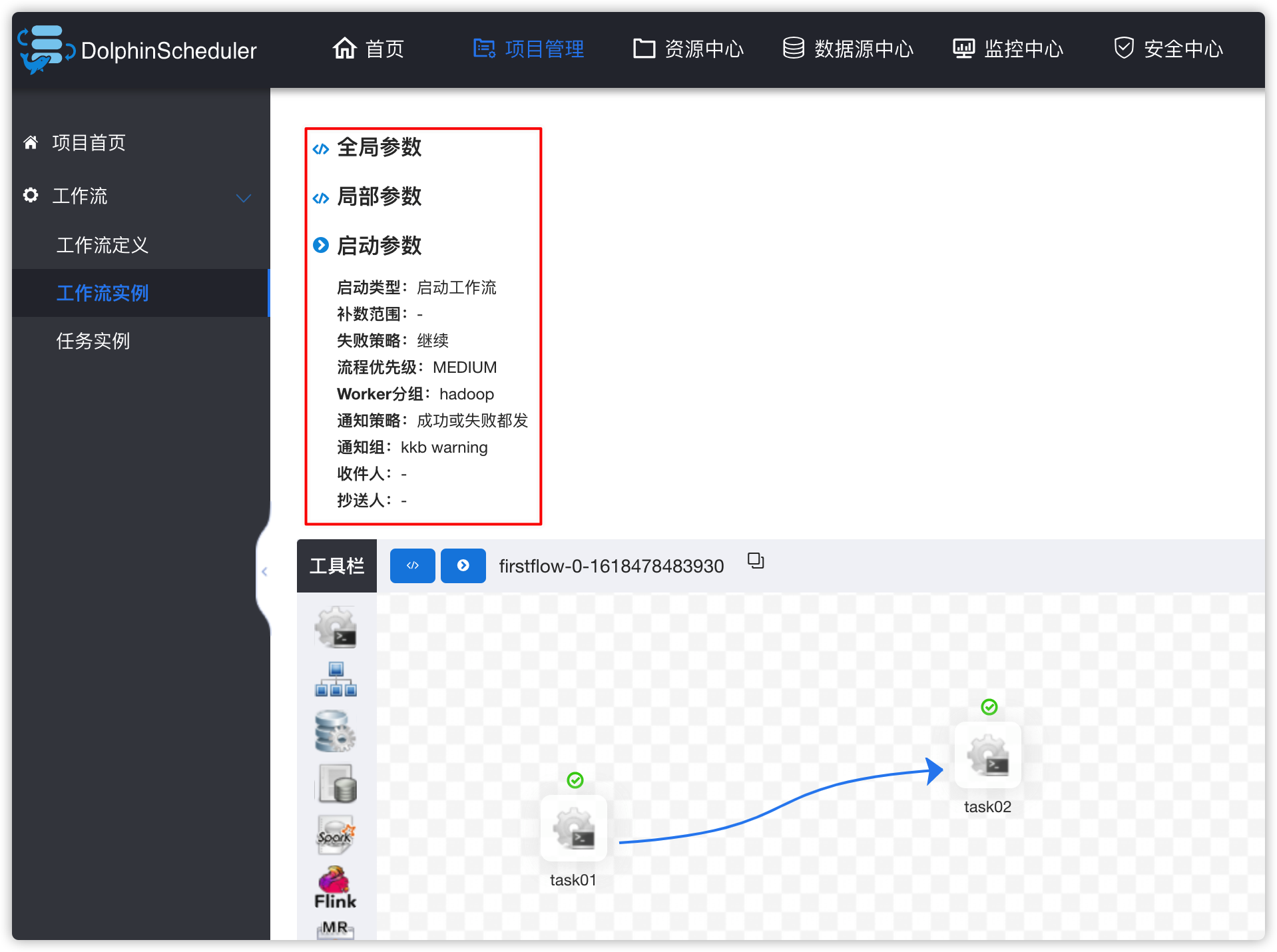
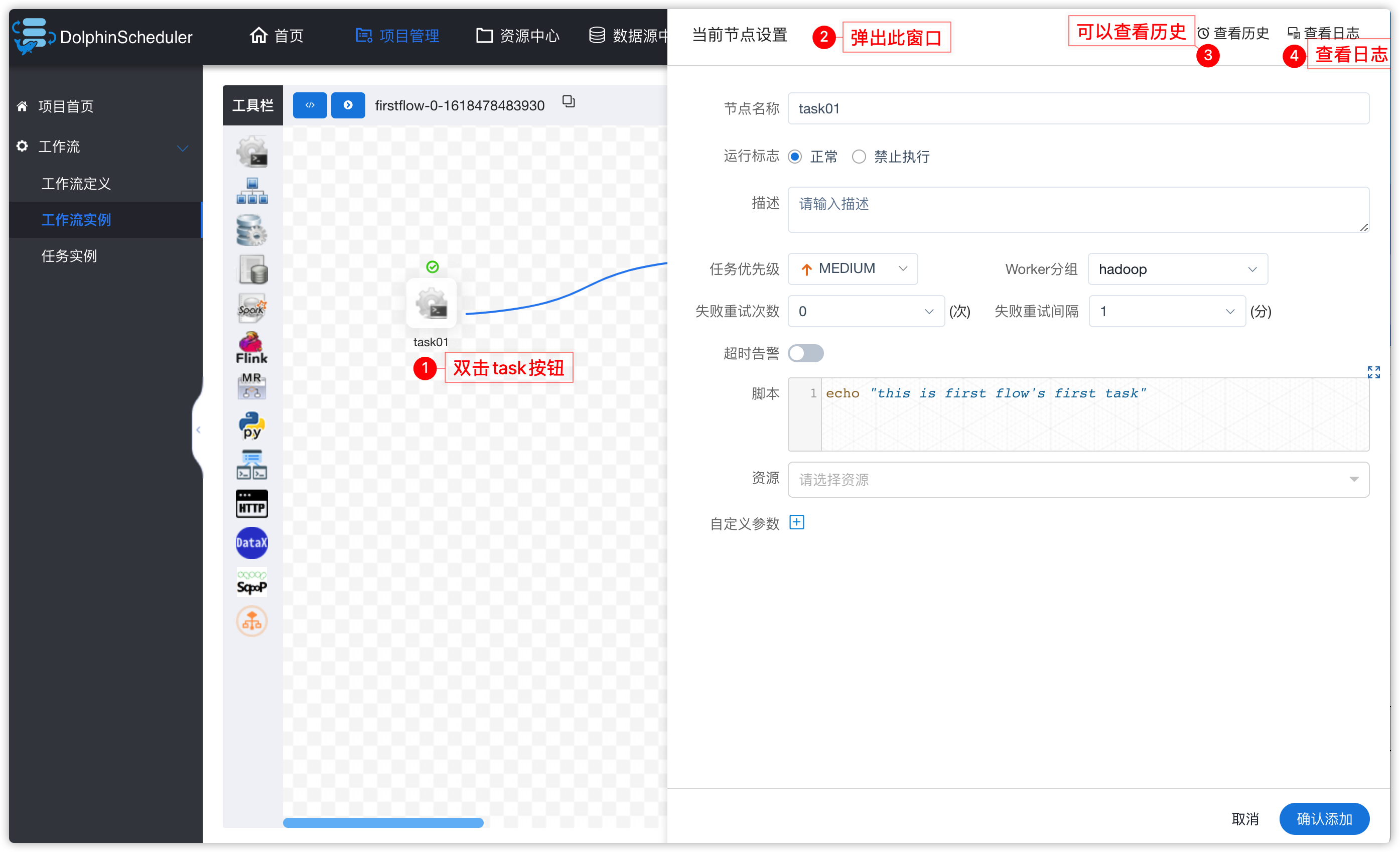
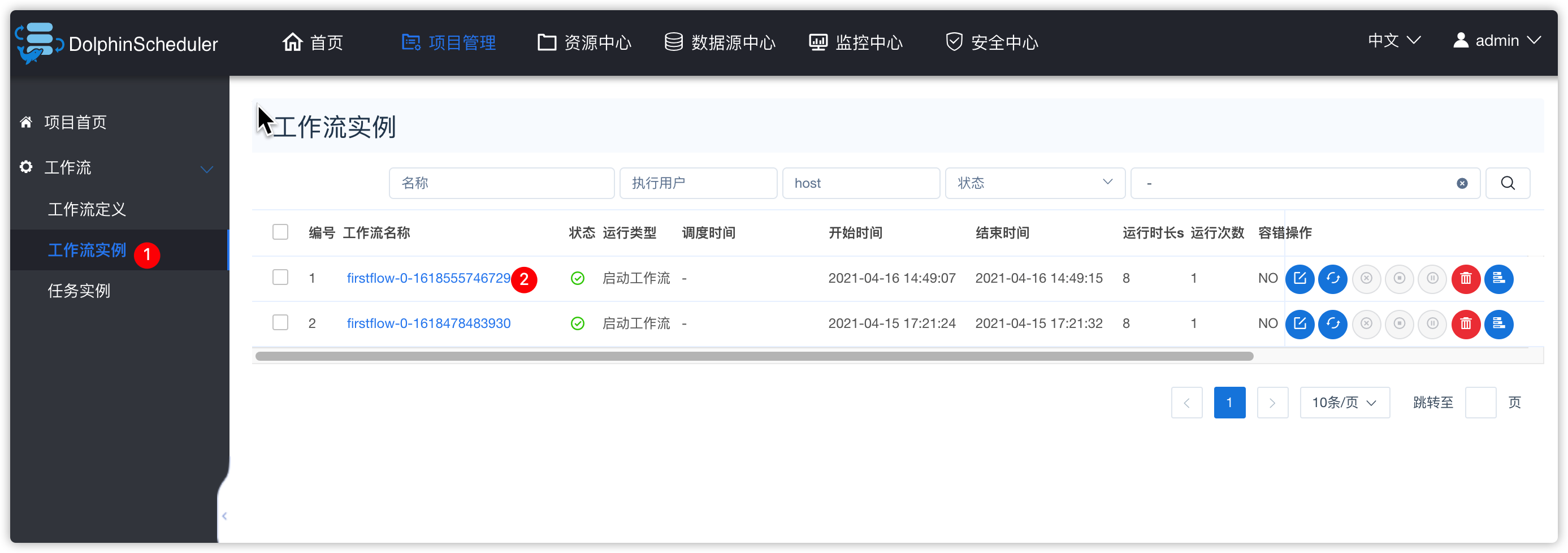
3、工作流实例
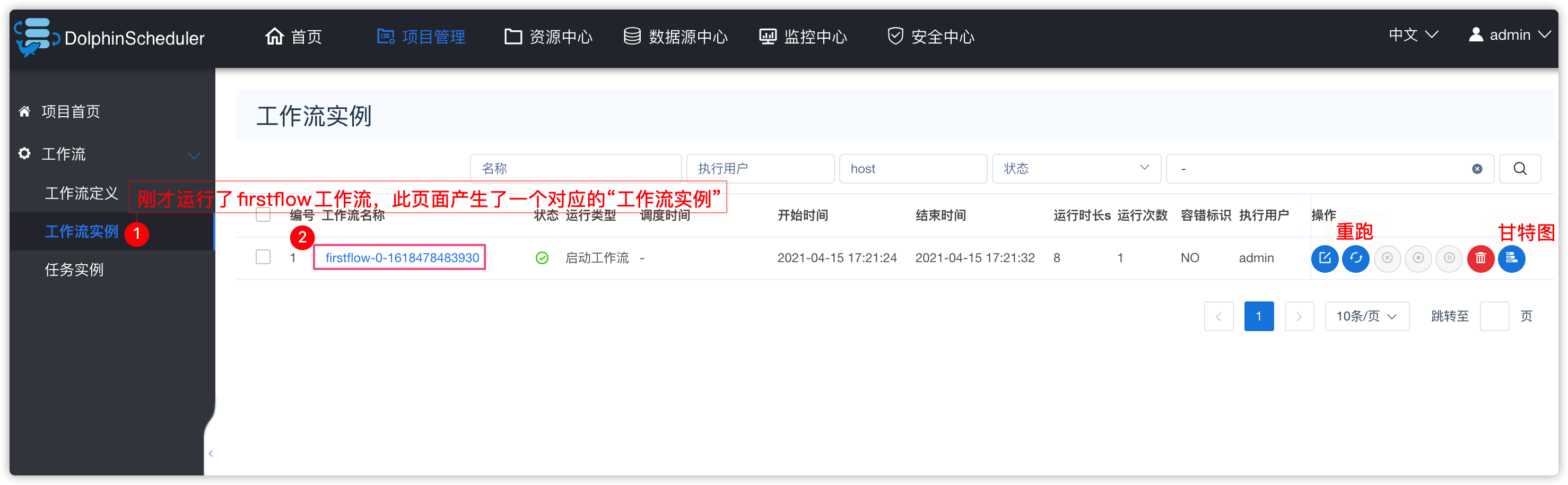
- 下图中有两个task,如果task还正在运行,可以点击右上角“刷新”按钮,刷新其状态
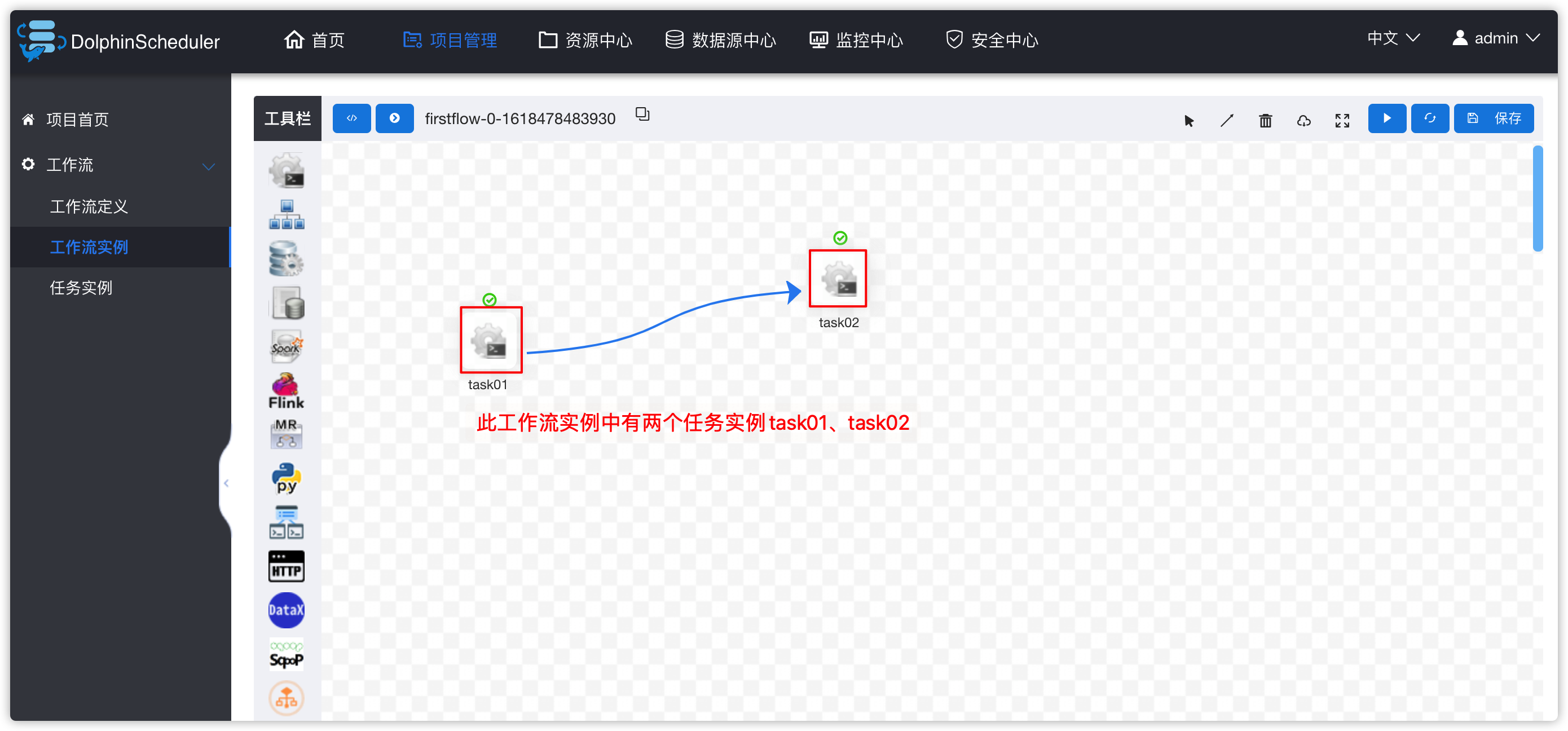
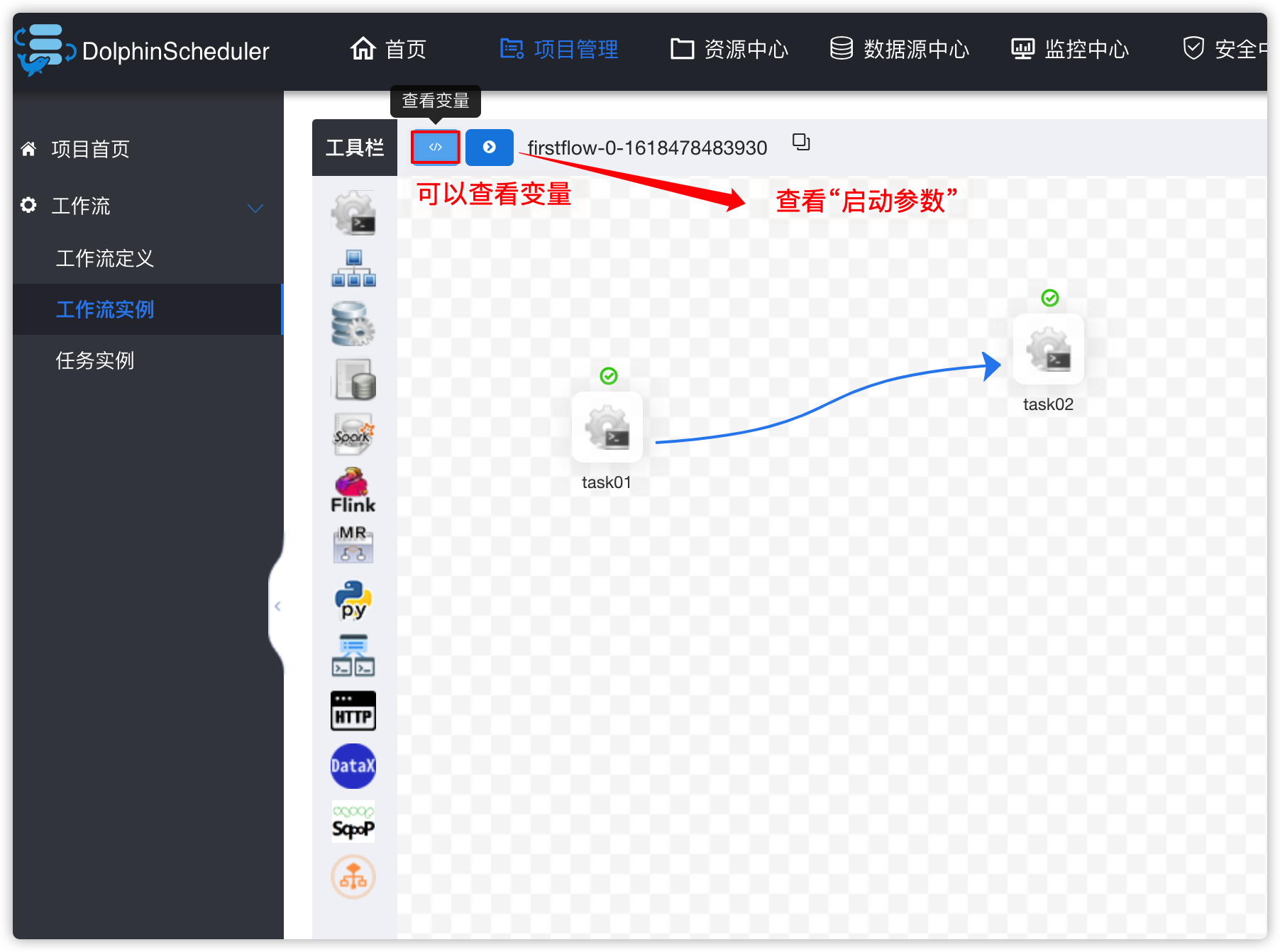
- 效果如下
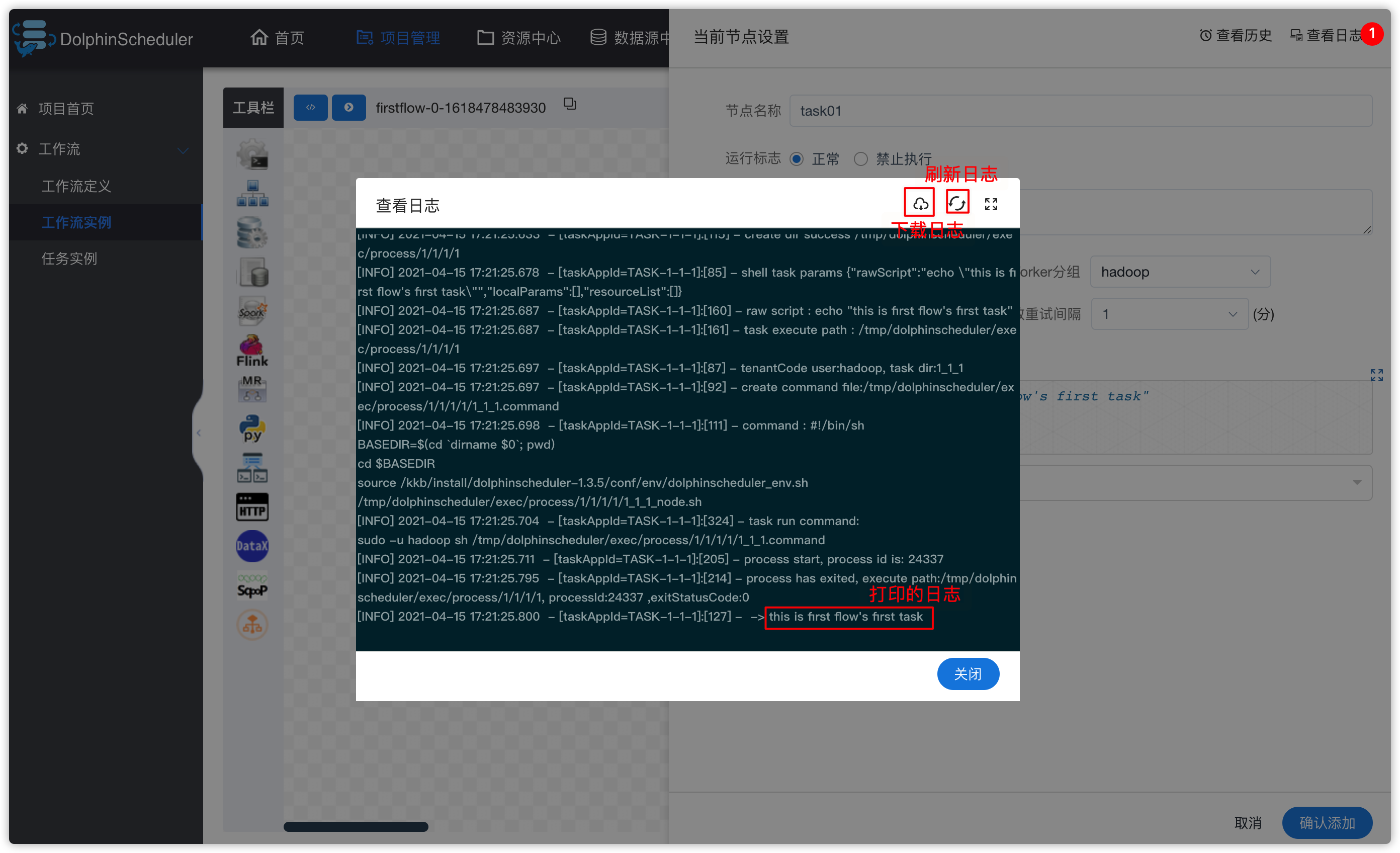
- 查看日志
- 查看历史
4、任务实例
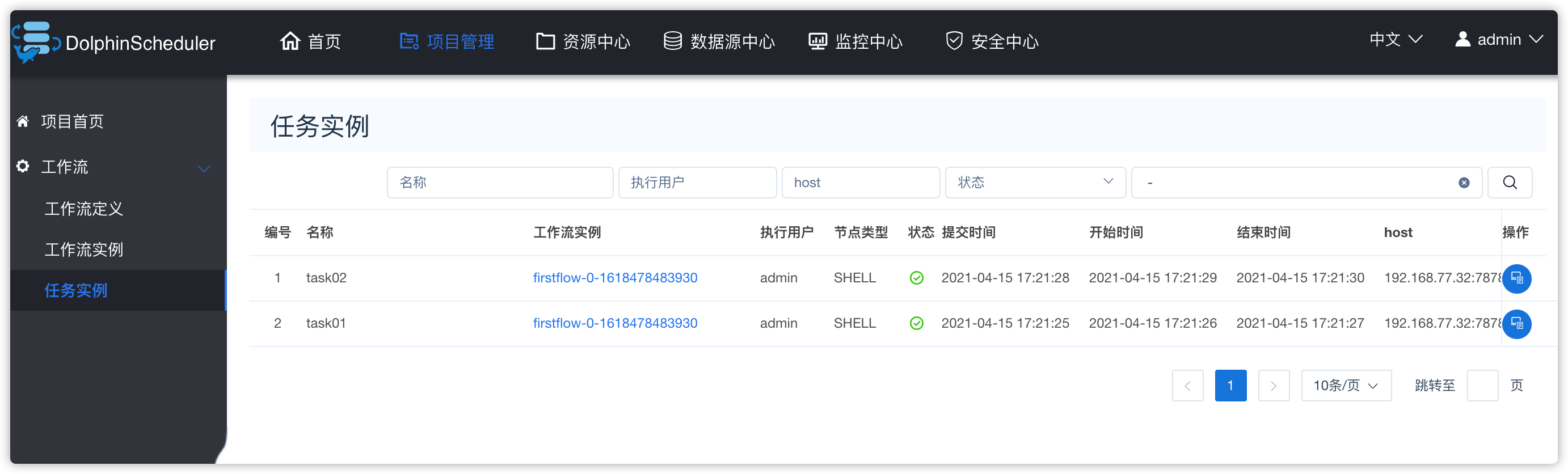
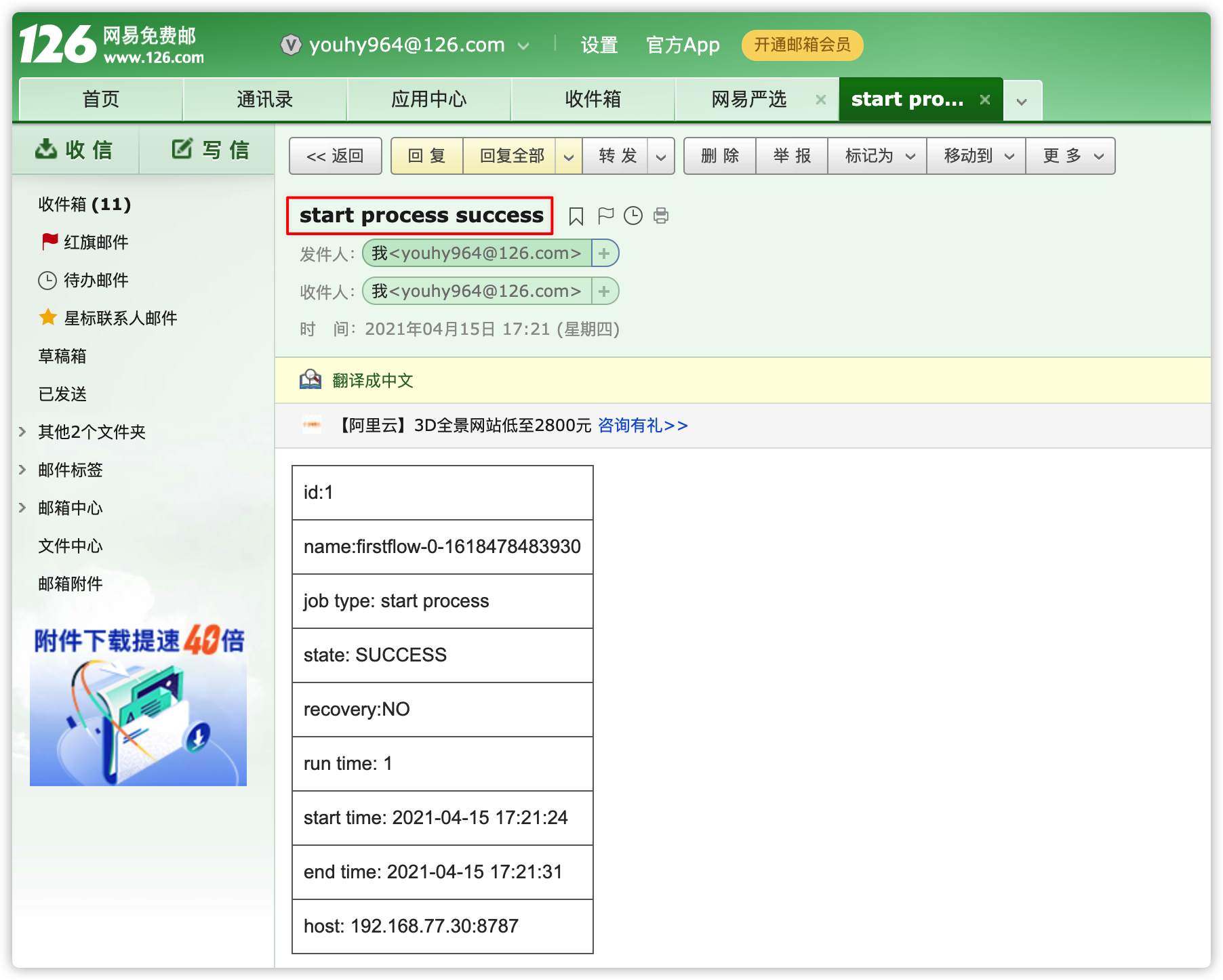
- 看到firstflow中的两个任务实例都执行成功
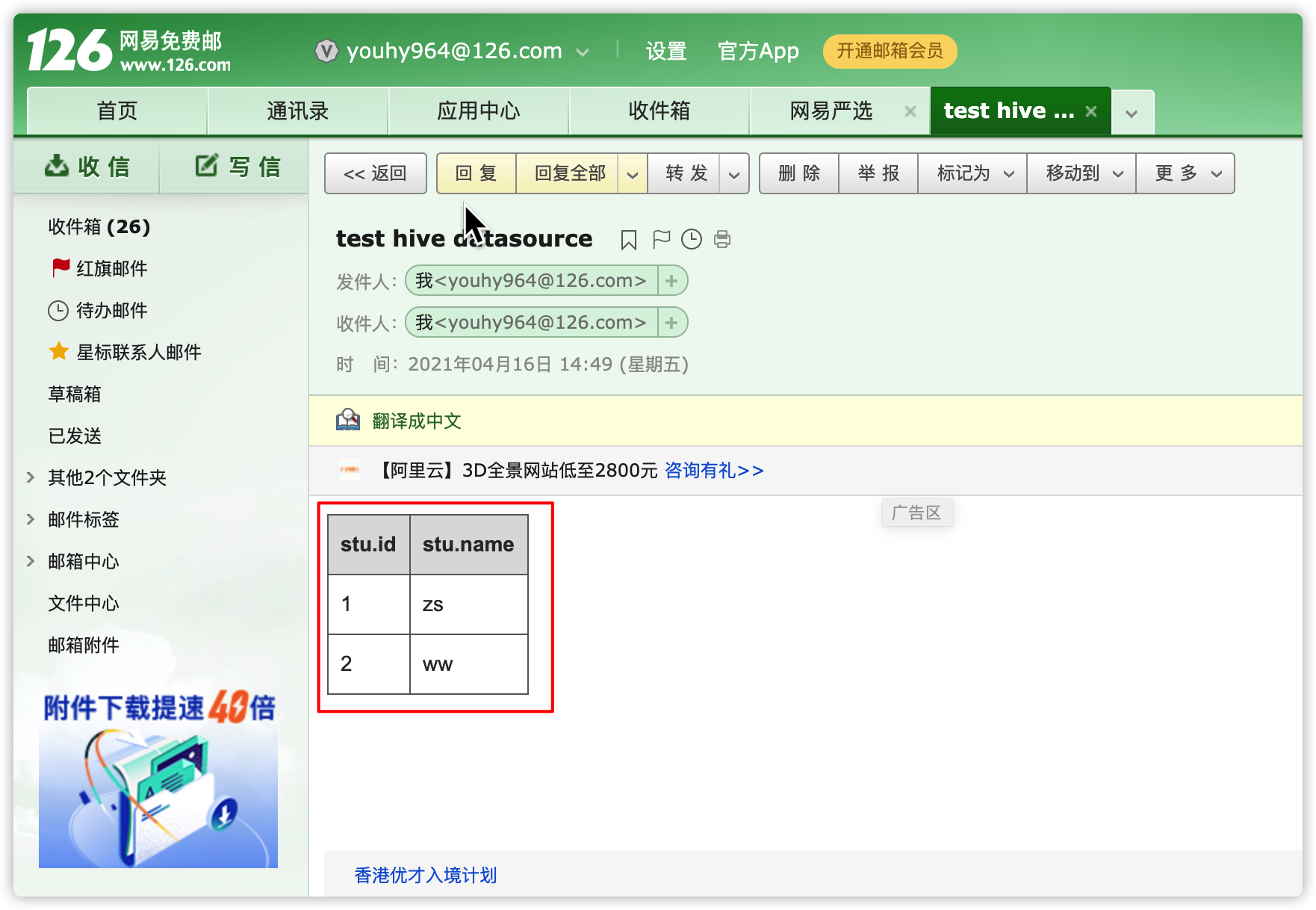
- 去邮箱确认是否收到邮件
7.3 调度hive
1、hive环境准备
环境说明:
- 此处以==node03安装mysql-5.7、hive-3.1.2为例==
- ==node02安装了hive-3.12.为例==
- 若没有安装,请参考资料《Hive安装部署.md》
- ==启动Hiveserver2==
[hadoop@node03 ~]$ cd /kkb/install/apache-hive-3.1.2/bin
[hadoop@node03 bin]$ ./hiveserver2- 若启动hiveserver2时,报错如下
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V- 原因是hadoop、hive中的guava包冲突
- 解决方案:将hive的此包删除,hadoop的guava包复制一个到hive的lib目录
[hadoop@node03 ~]$ cd /kkb/install/apache-hive-3.1.2/lib/
[hadoop@node03 lib]$ rm -rf guava-19.0.jar
[hadoop@node03 lib]$ cp /kkb/install/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar ./
[hadoop@node03 lib]$2、方式一:贴hive sql
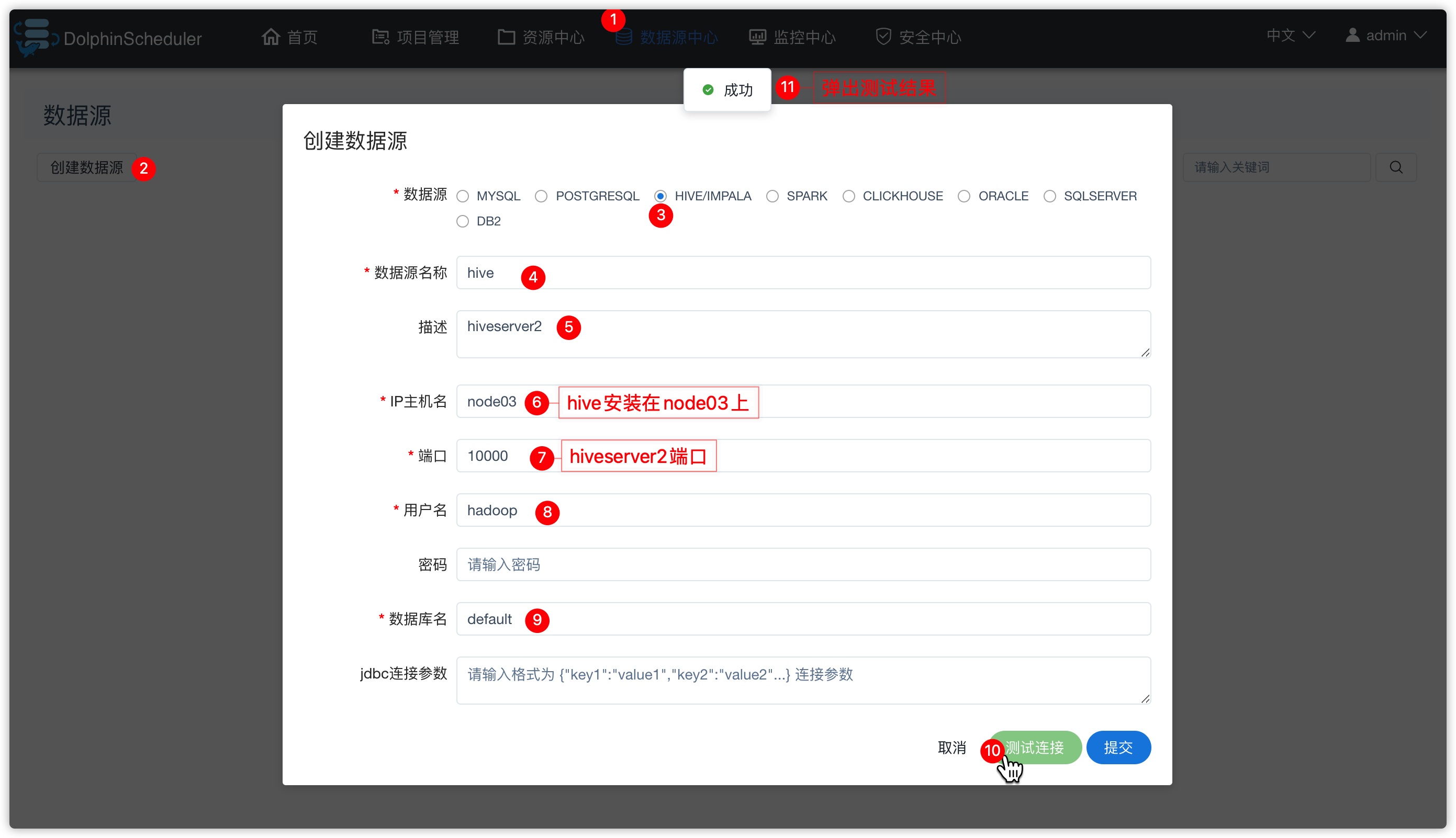
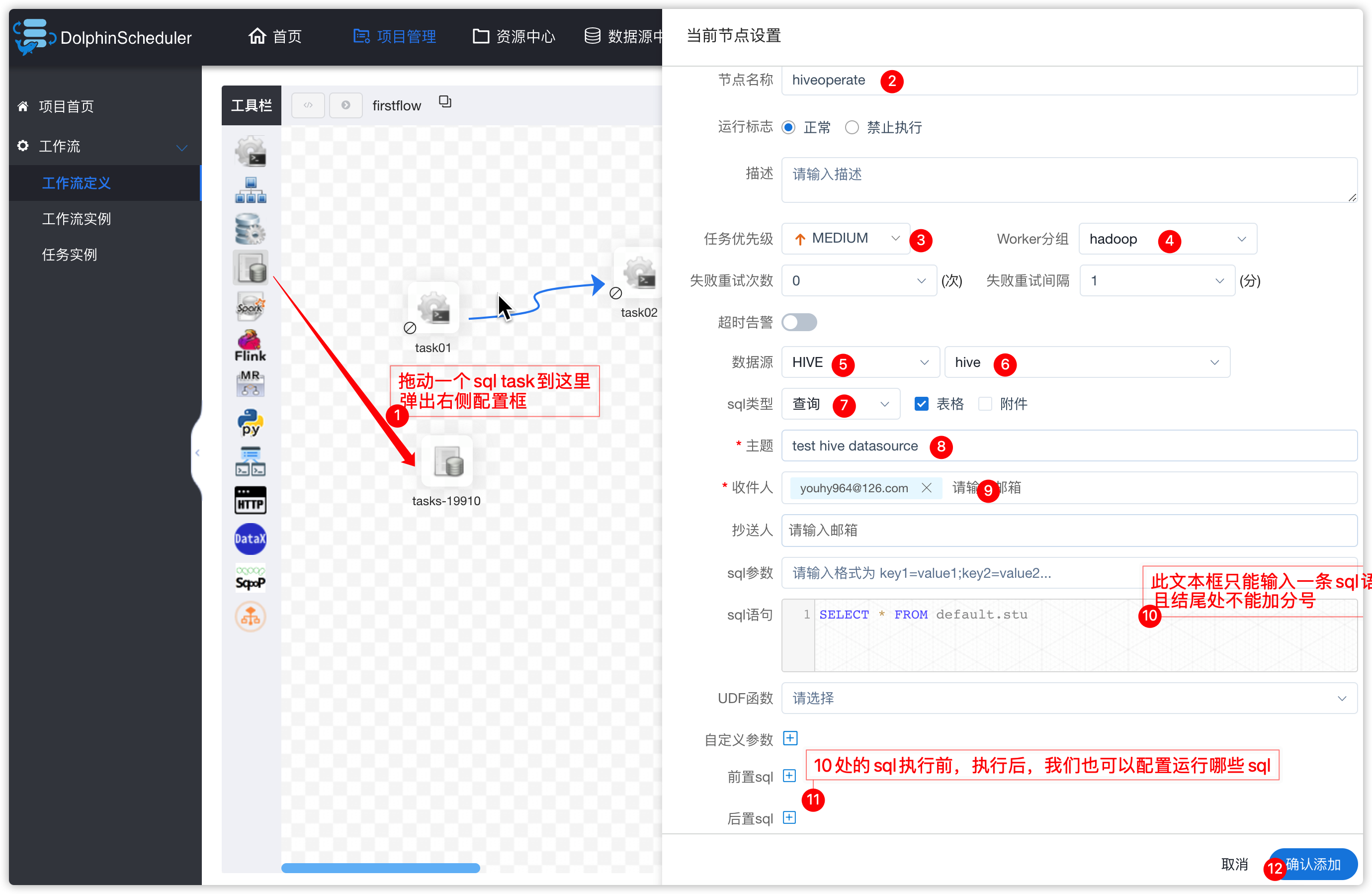
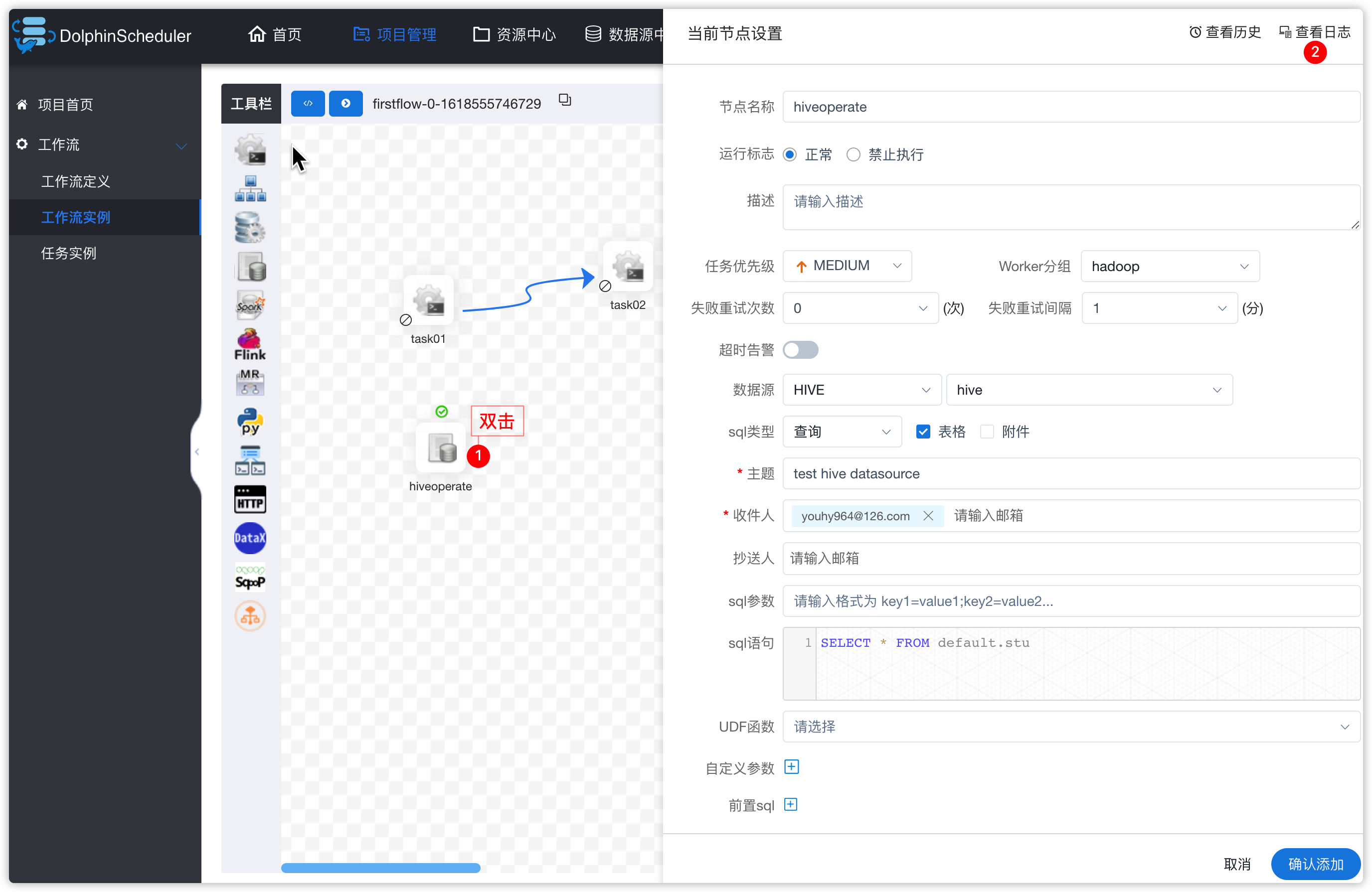
1、创建hive数据源
- 如下图操作
-
点击上图右下角“提交”按钮
-
效果如下
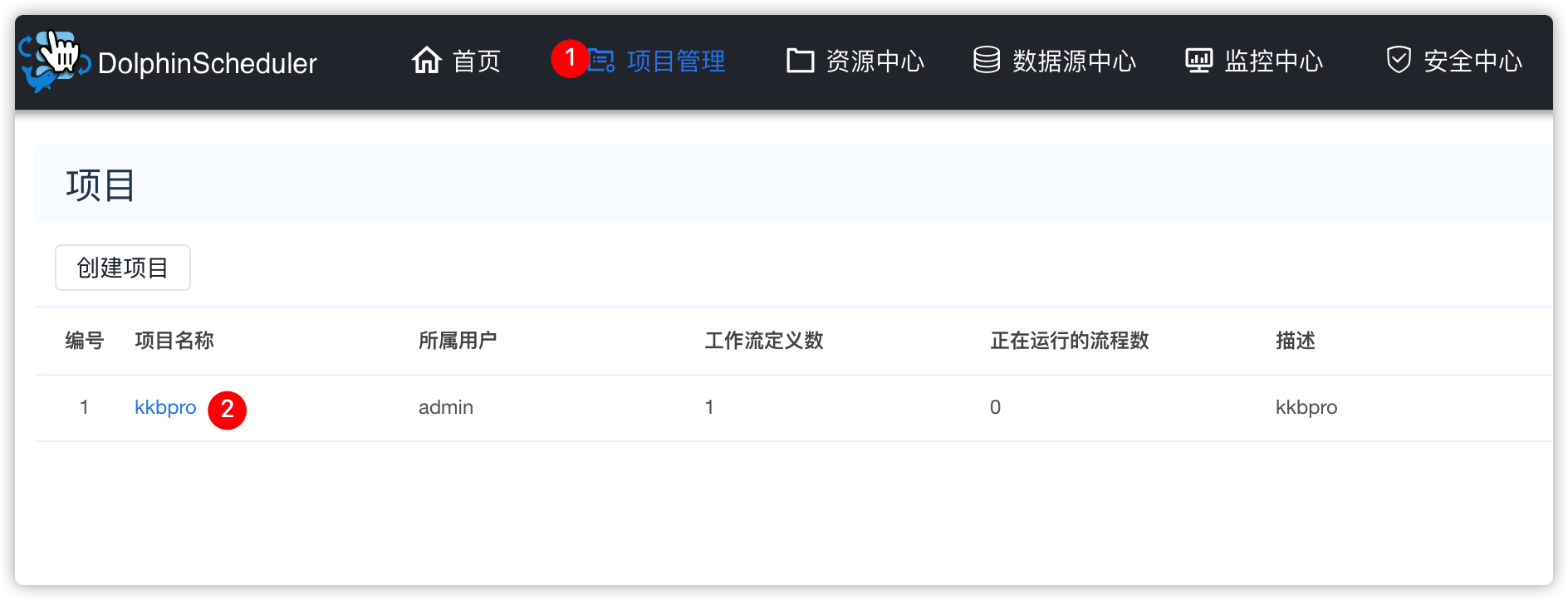
- 去“项目管理”,打开前边创建的项目"kkbpro"
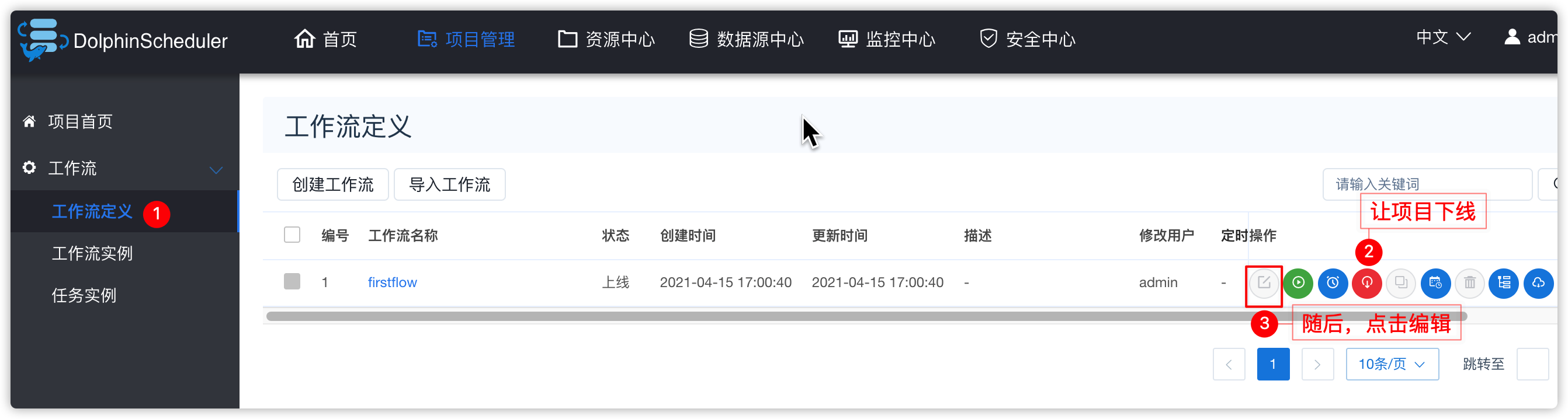
- 进入下图,将task01、task02禁用掉
- 以task01操作为例:
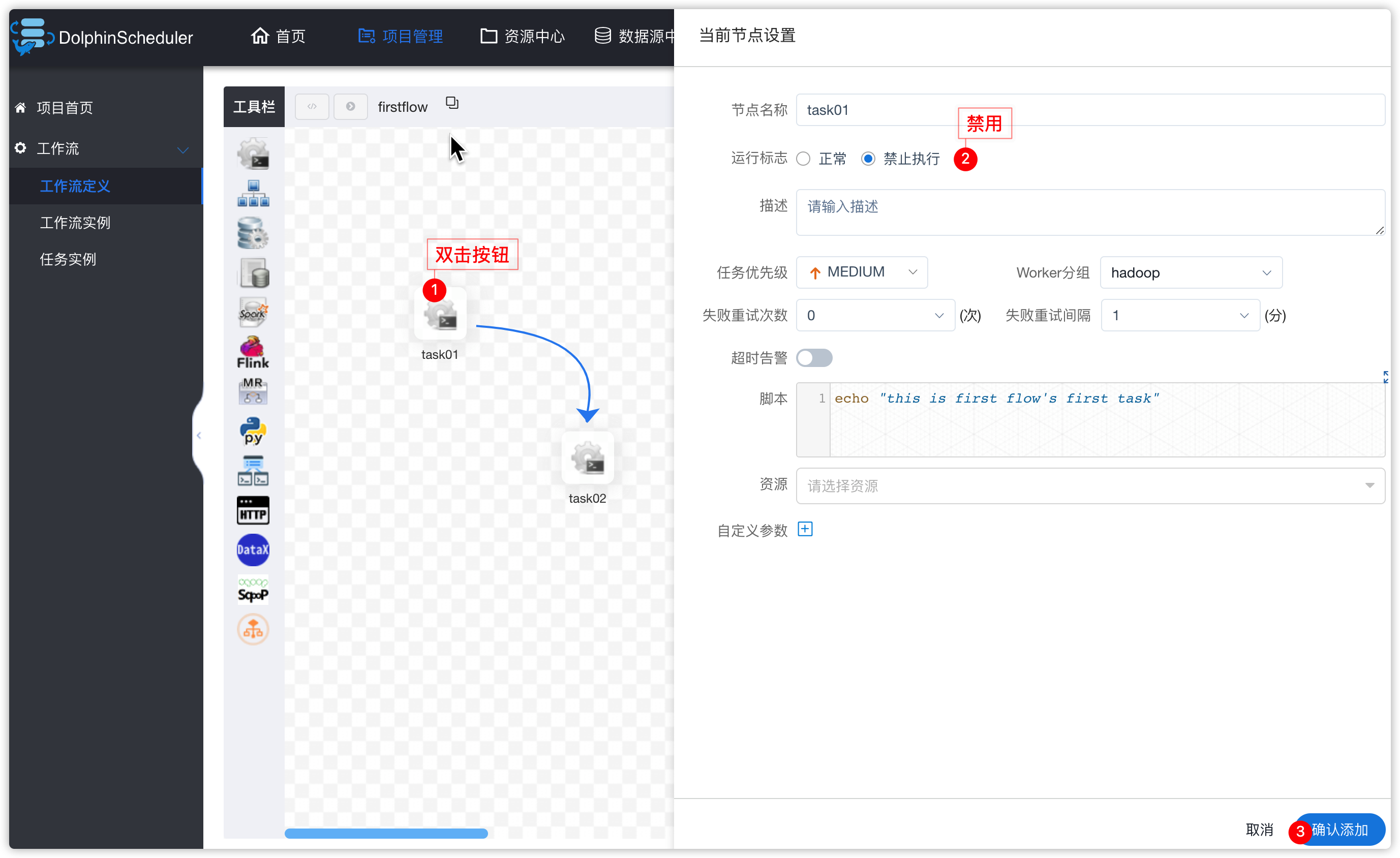
先在hive的default中创建表,并插入数据,用于一会ds中测试hive数据源操作
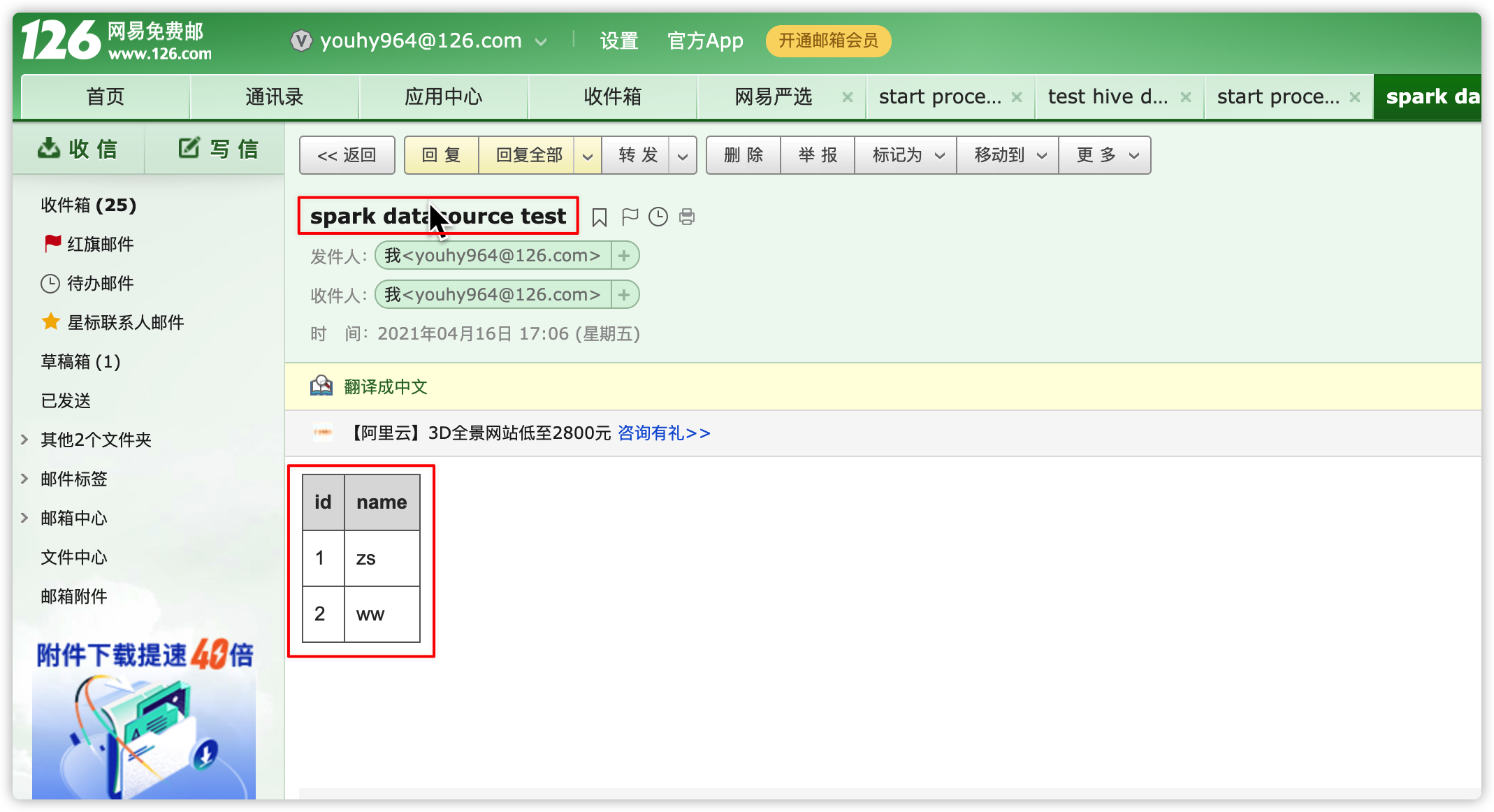
create table stu(id int, name string); insert into stu values(1, "zs"); insert into stu values(2, "ww"); 查询结果 hive (default)> select * from stu; OK stu.id stu.name 1 zs 2 ww
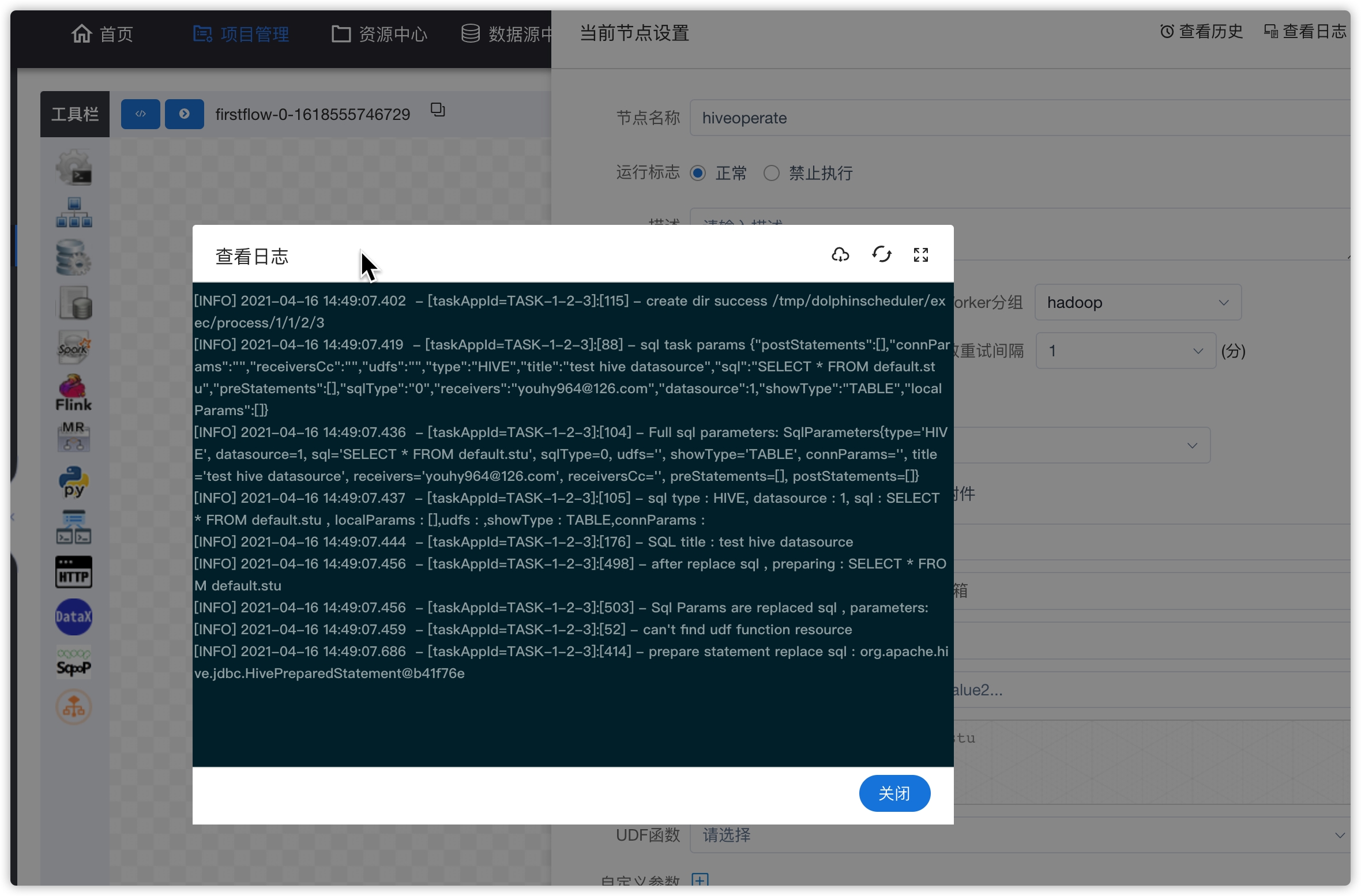
- 查看工作流实例
- 查看邮件
3、方式二:调度hive脚本
1、hive脚本操作
- 上边讲了hive数据源中,贴sql的操作
- 接下来看看如果调用hive脚本
- 先给ds的admin用户添加租户
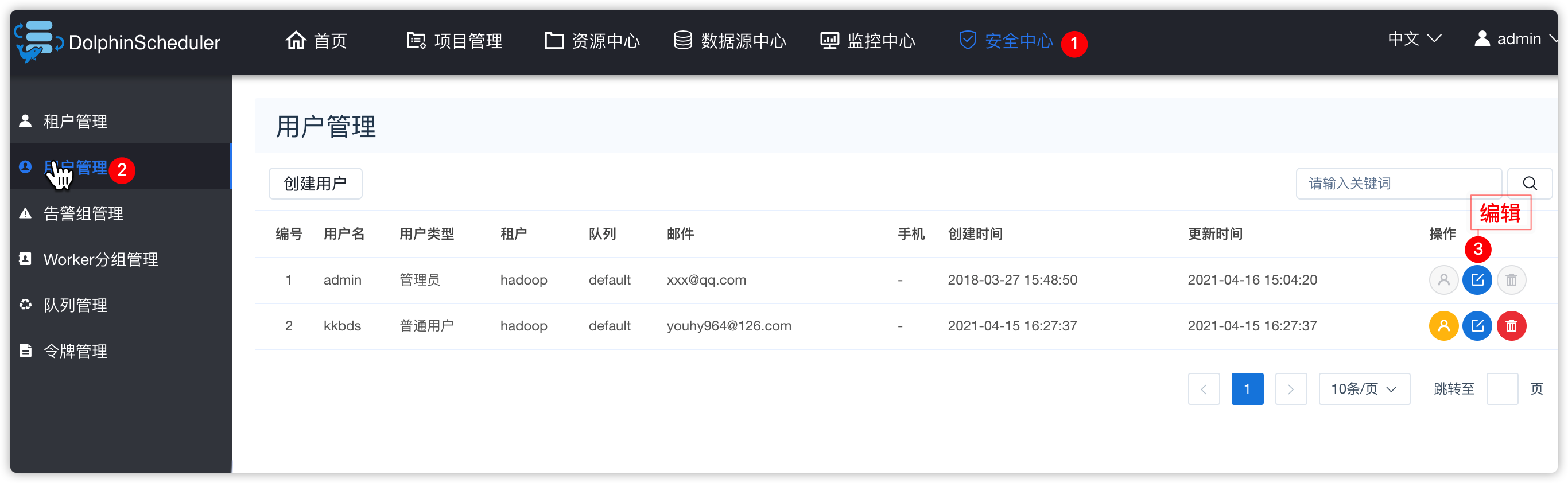
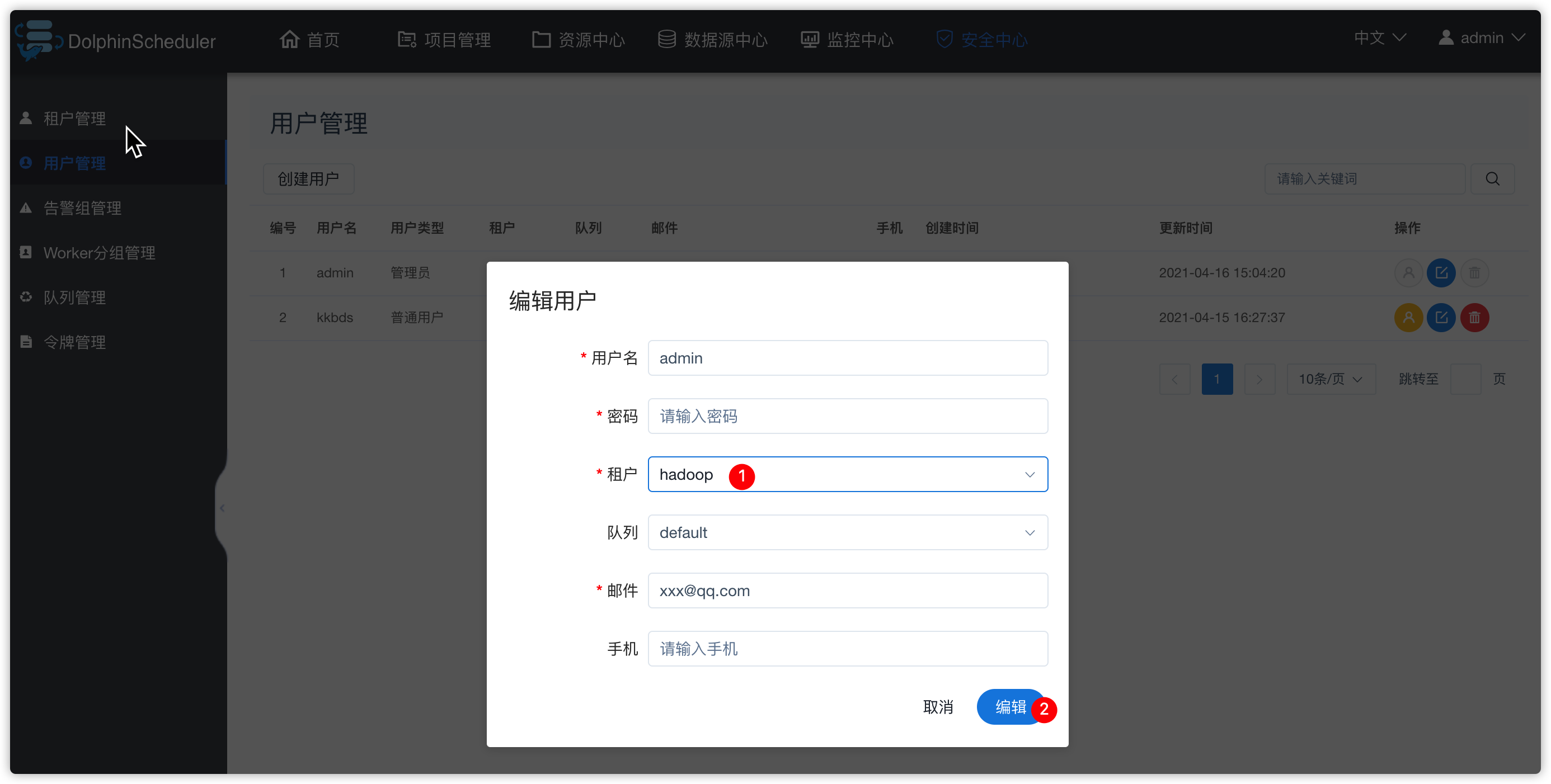
- 资源中心相关操作
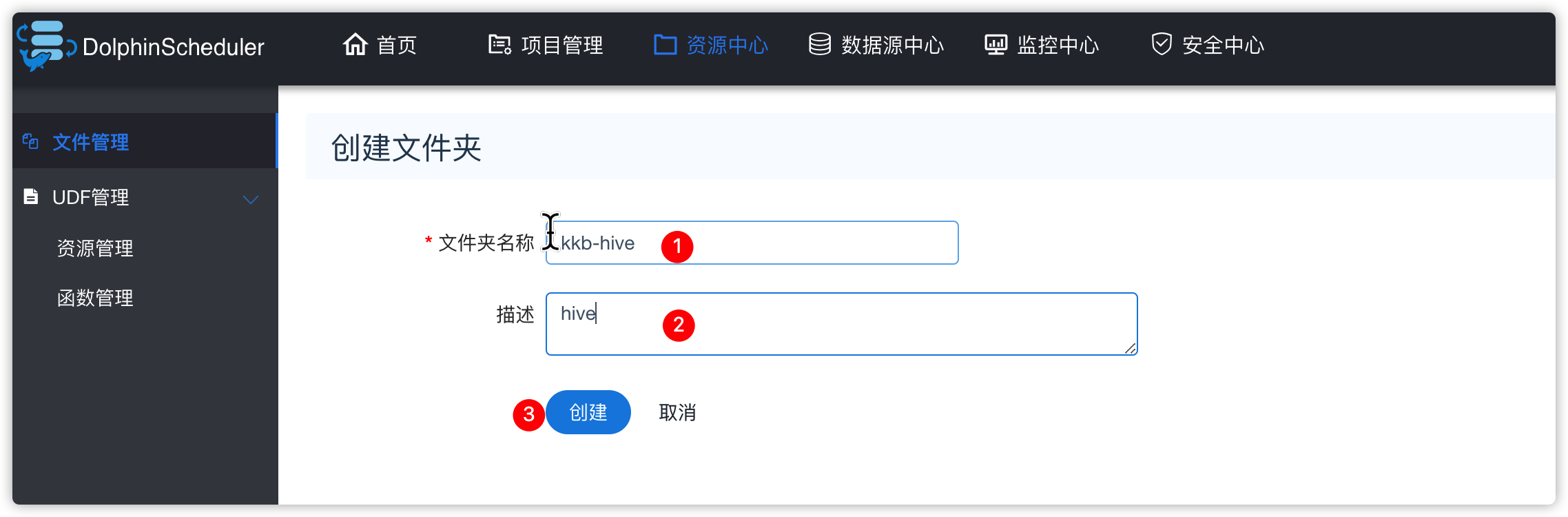
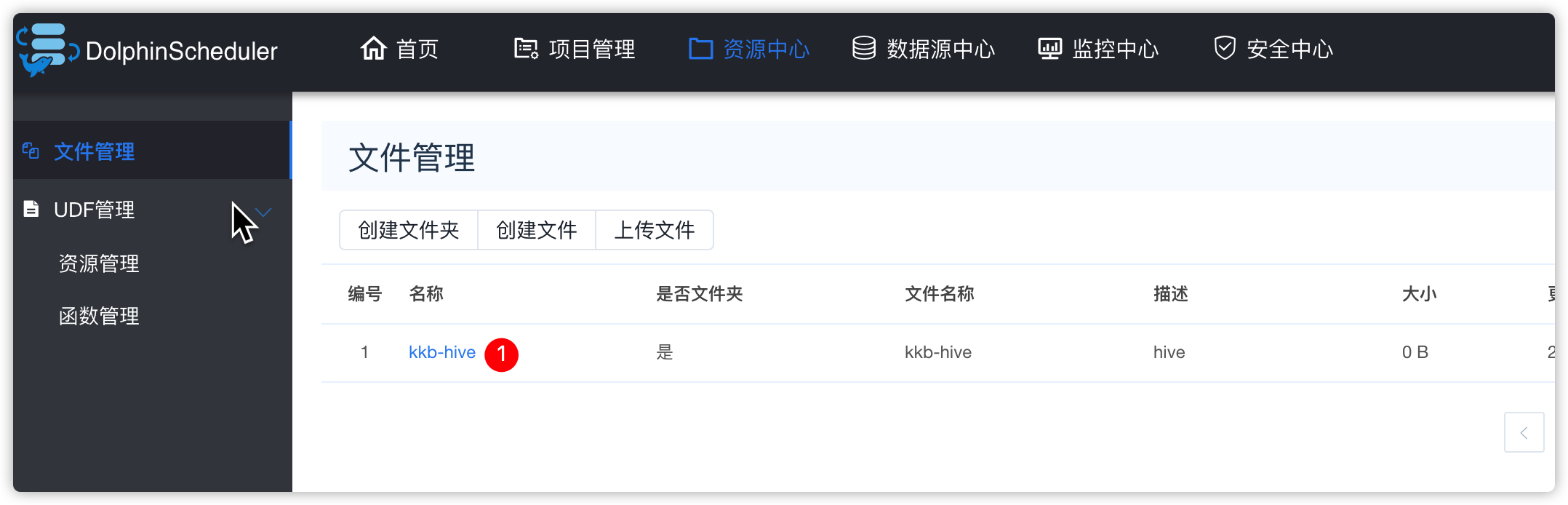
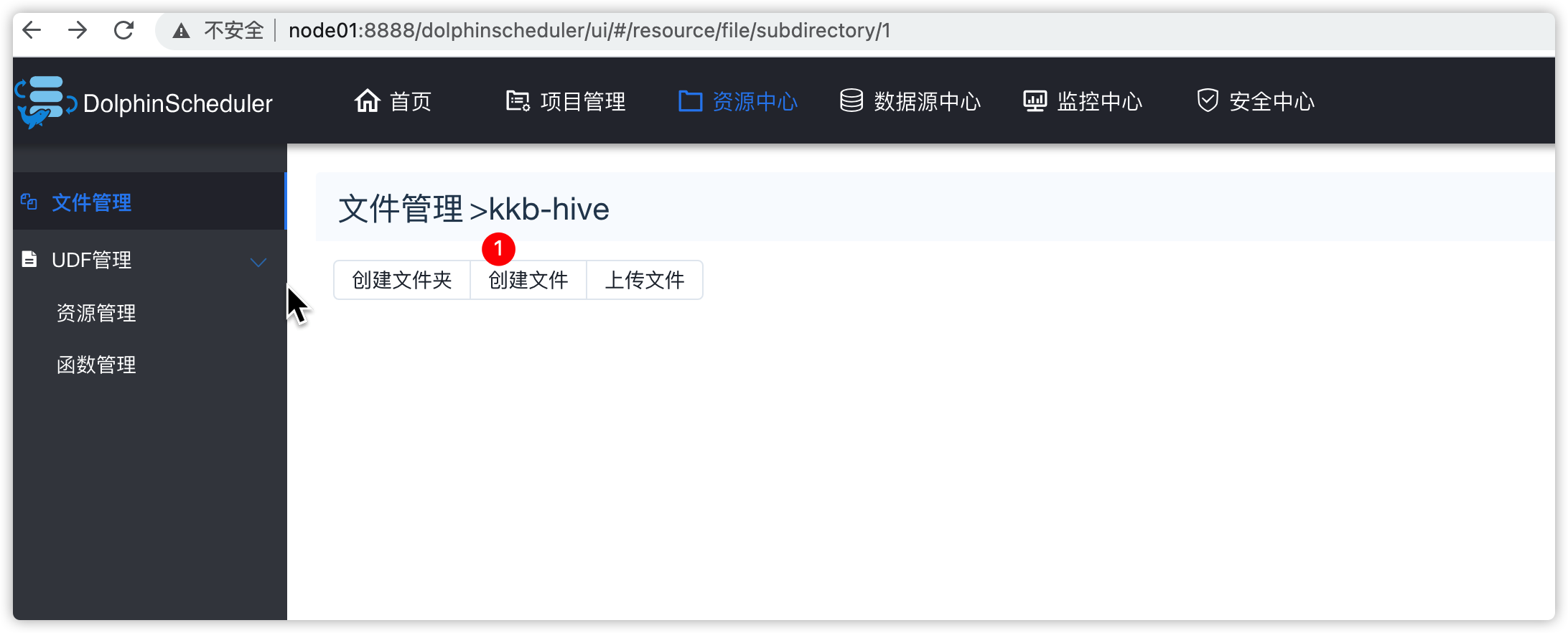
创建脚本
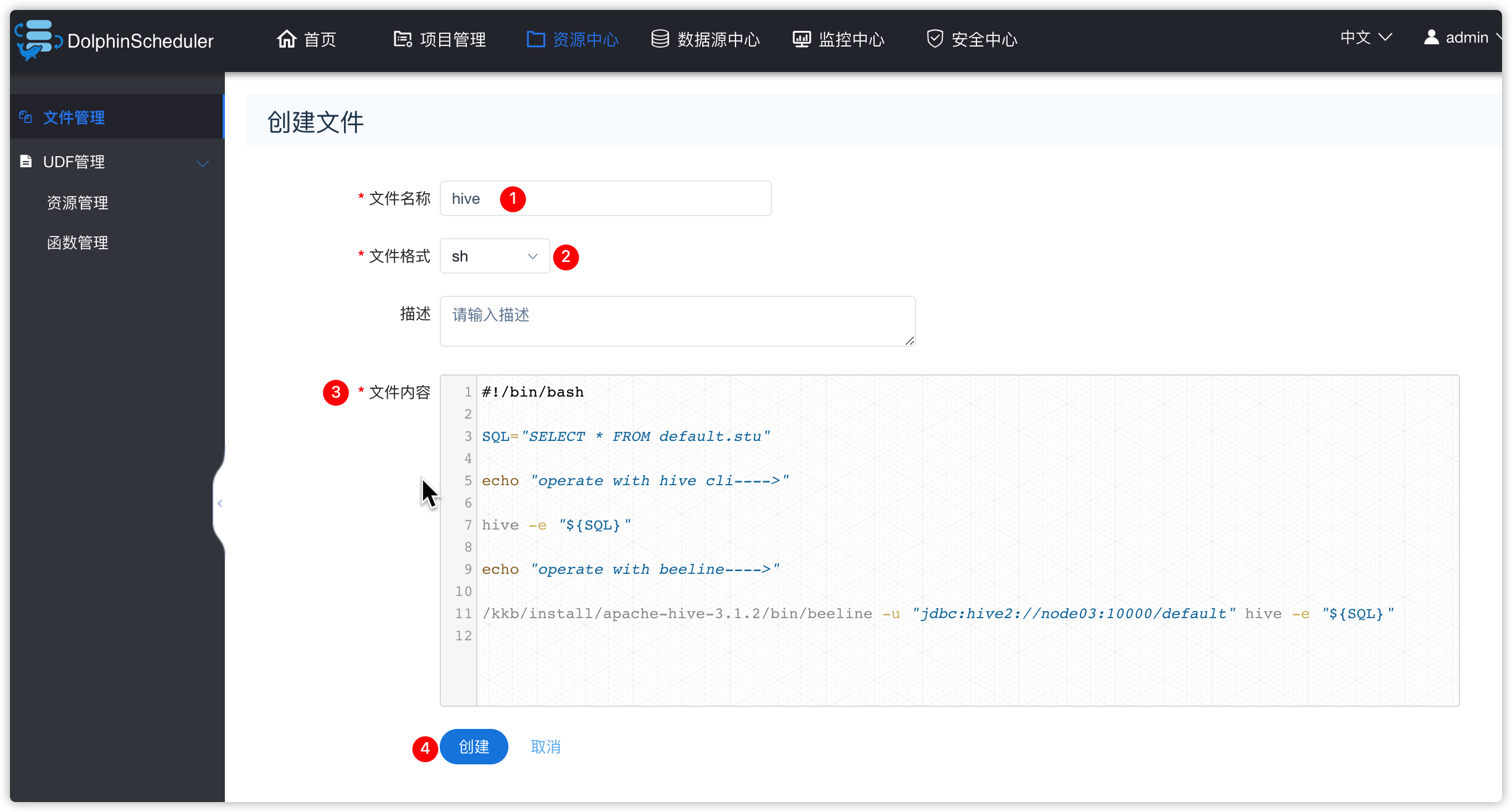
文件内容如下
#!/bin/bash
SQL="SELECT * FROM default.stu"
echo "operate with hive cli---->"
hive -e "${SQL}"
echo "operate with beeline---->"
/kkb/install/apache-hive-3.1.2/bin/beeline -u "jdbc:hive2://node03:10000/default" hive -e "${SQL}"2、调用脚本
- 项目管理 -》kkbpro项目
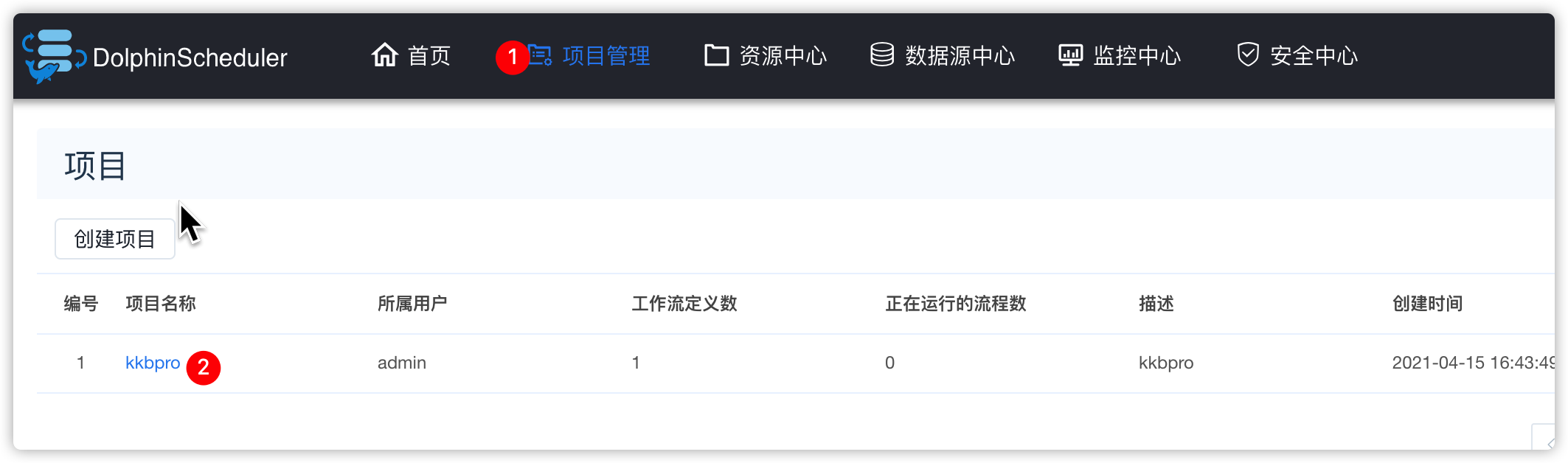
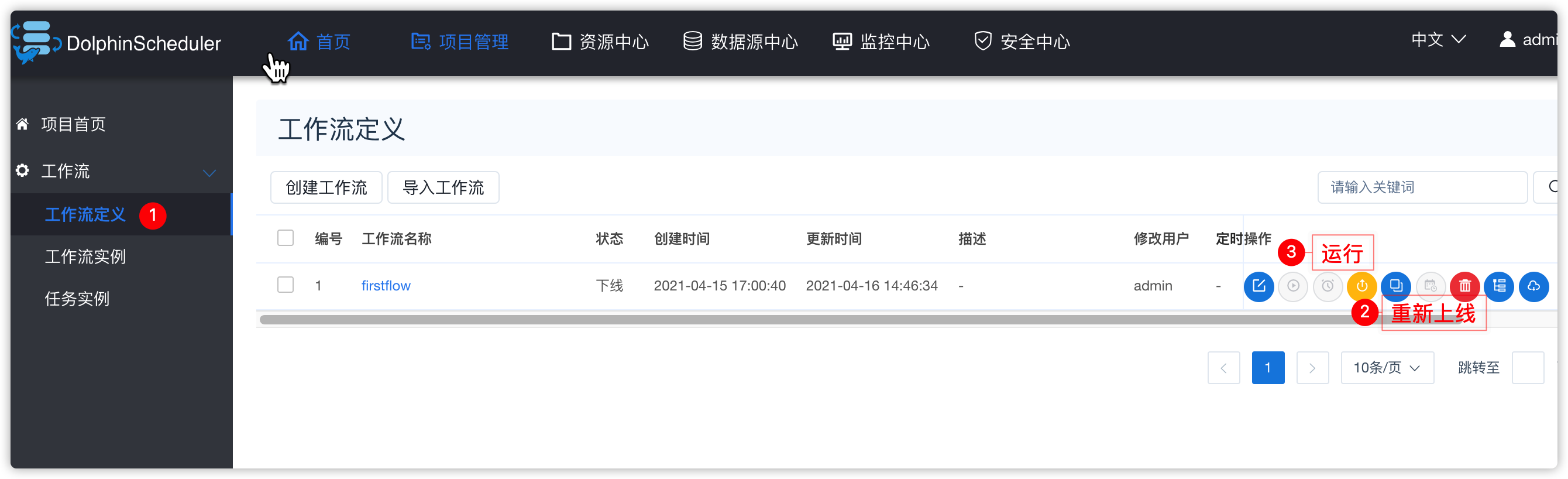
- 将firstflow工作流下线,并重新编辑
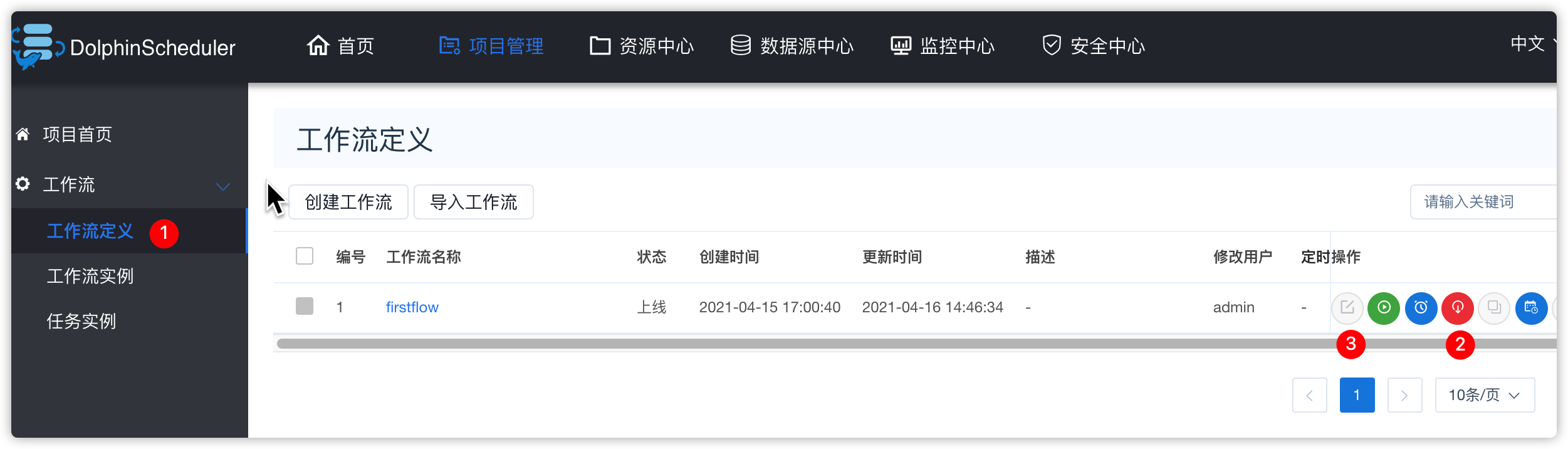
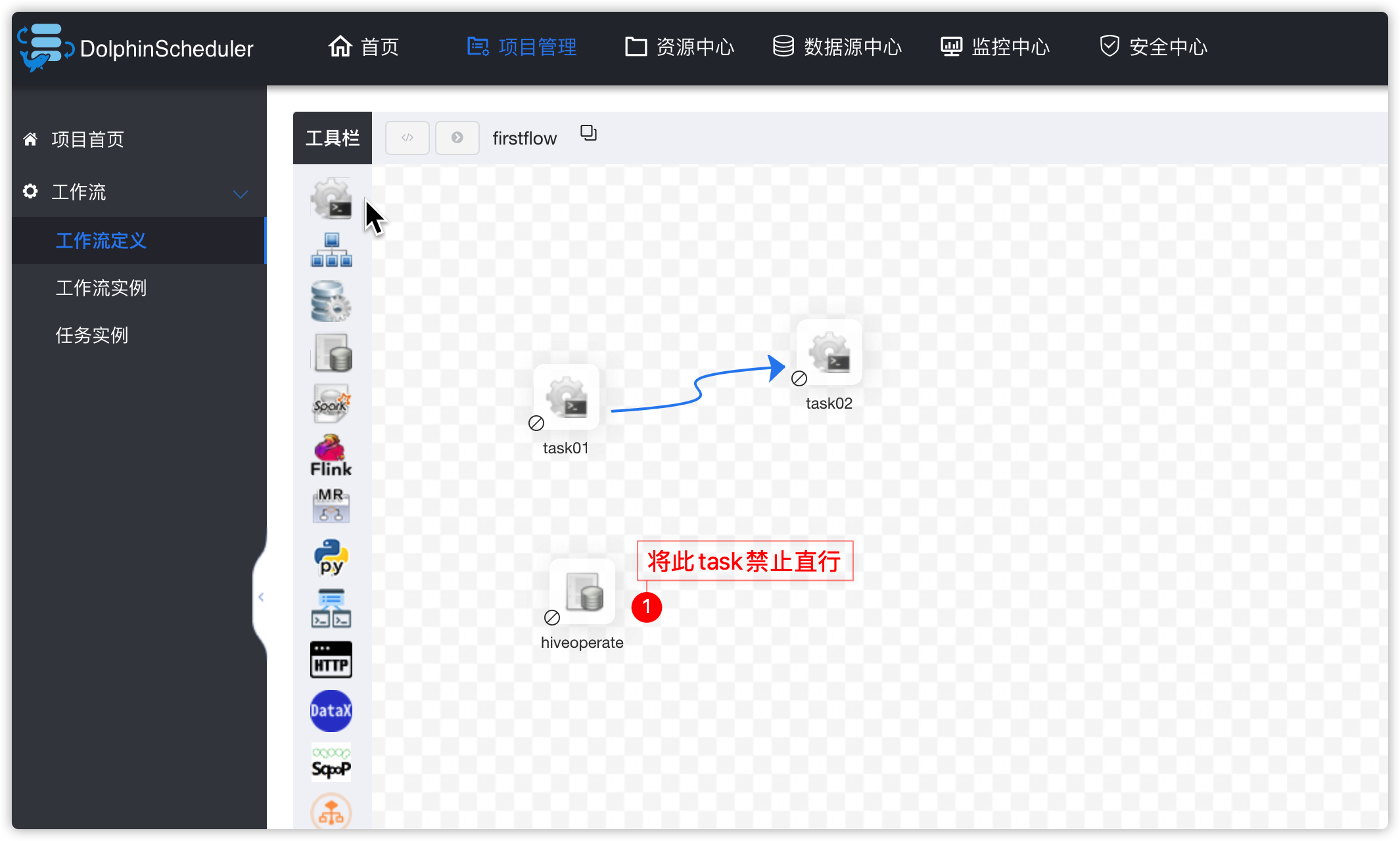
- 让后工作流中添加shell脚本类型的task,task直行上边创建的hive脚本文件
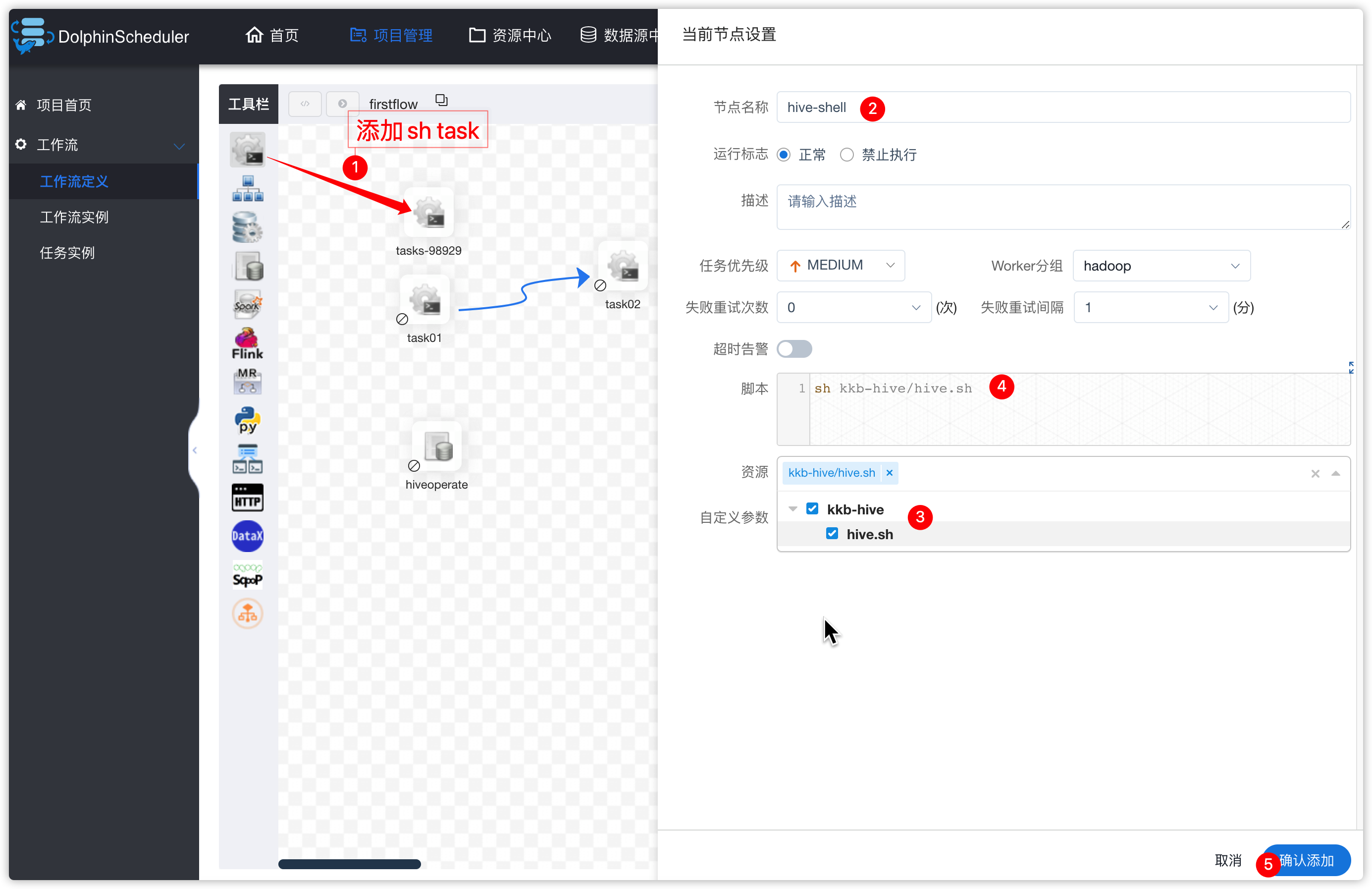
- 保存工作流
- 重新上线工作流,然后运行(这些操作之前都已经演示过,不再重复给出截图)
- 查看工作流实例
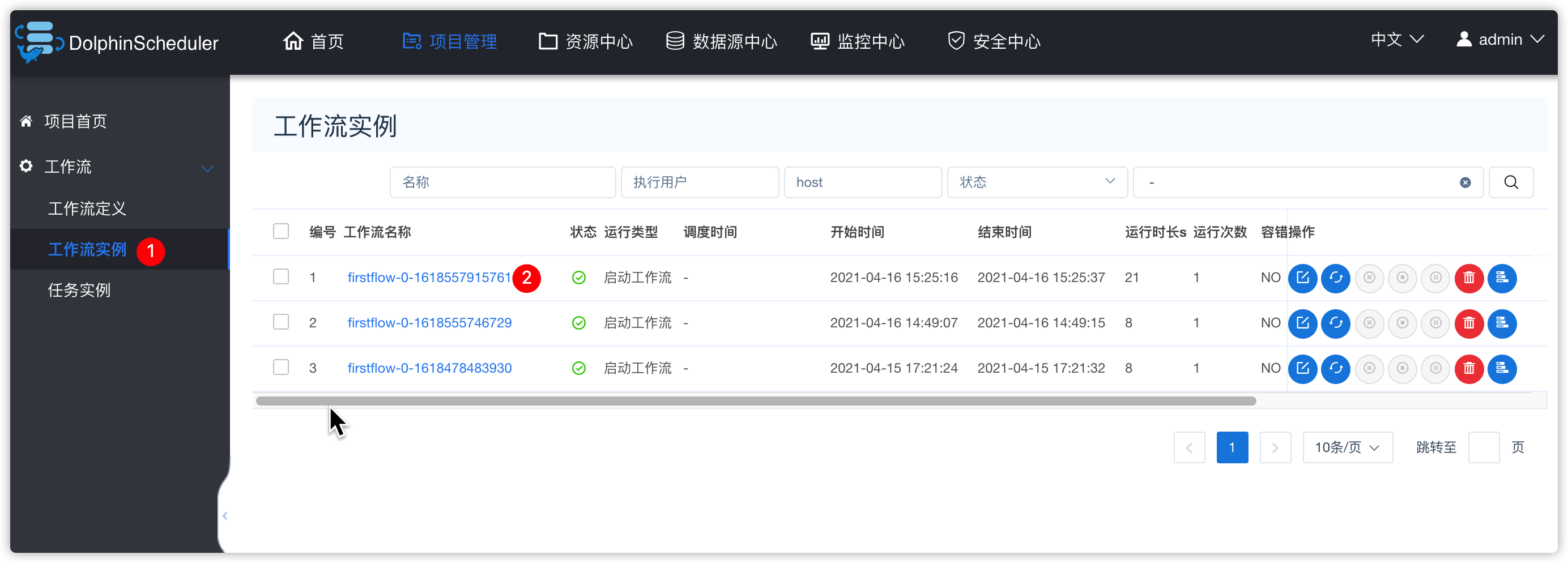
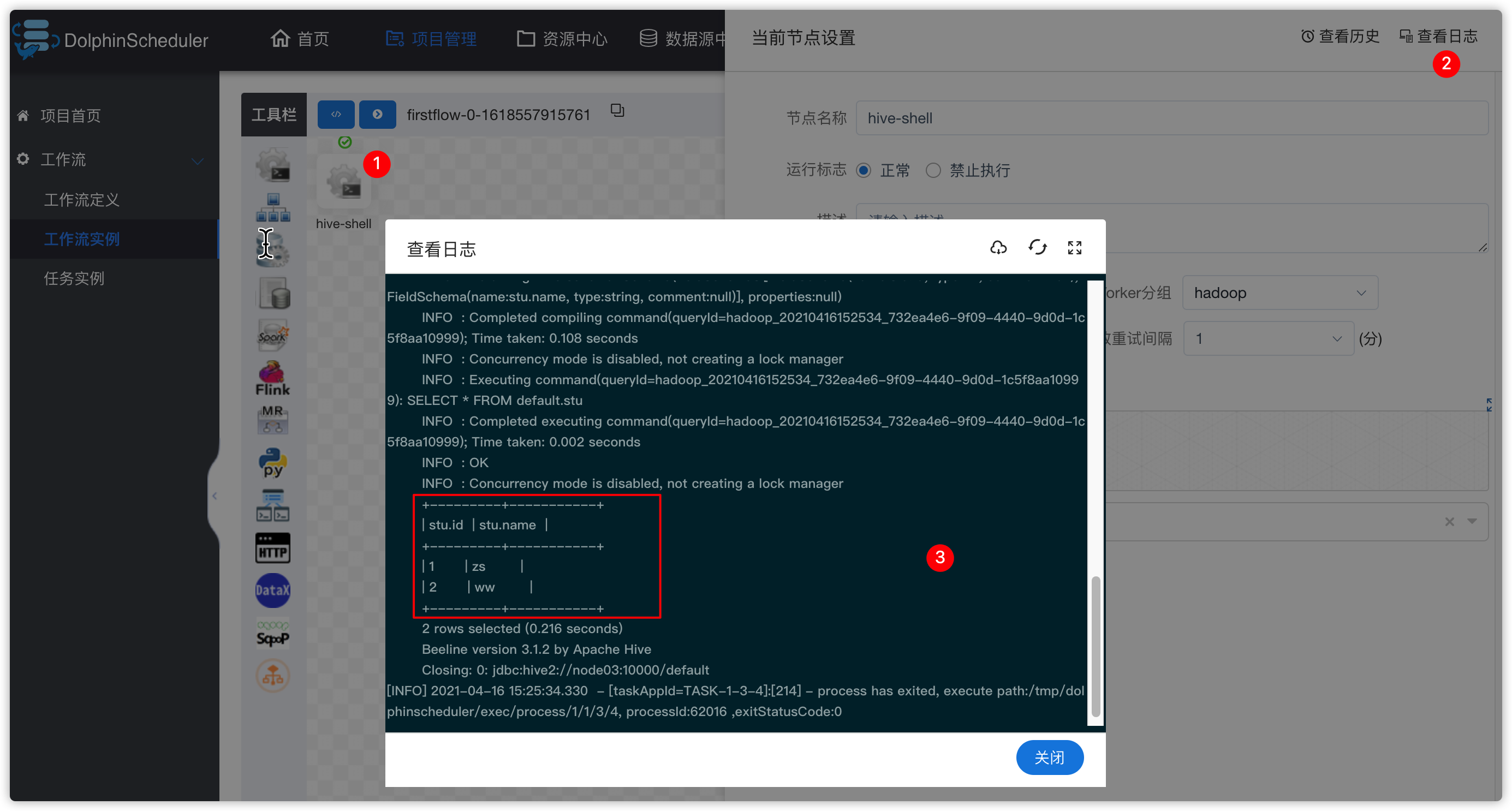
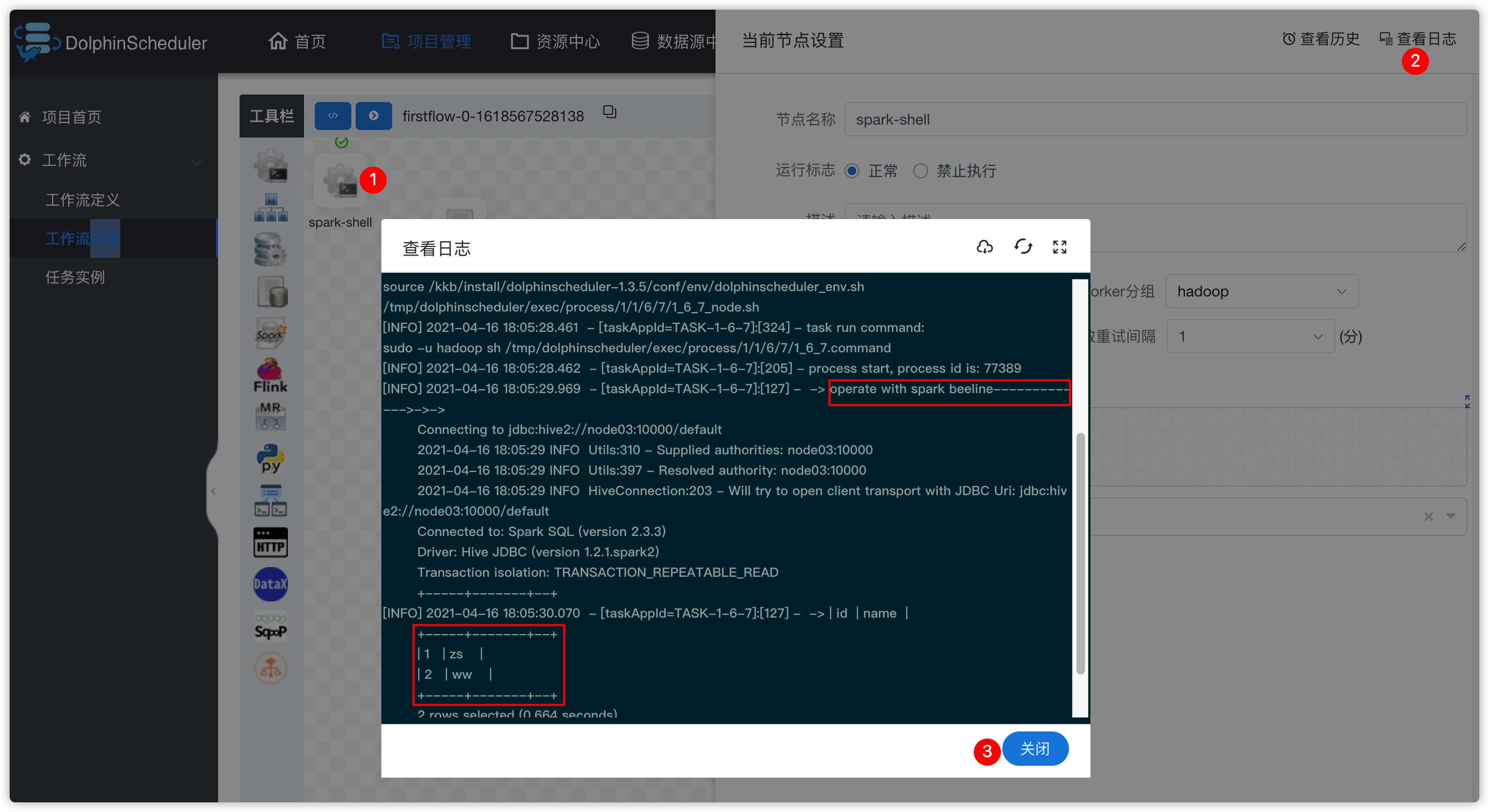
- 查看hive-shell任务的日志
7.4 调度spark
1、spark环境准备
- 若spark还未学习,可以先看此部分的讲解视频,不进行实操
- 因为ds可以调度spark,所以此文档先将内容给出
环境说明:
所有的ds worker节点都安装了spark
- 先启动spark集群
- node03节点,启动hive的metastore服务
hive --service metastore- 启动spark thriftserver服务
[hadoop@node03 sbin]$ cd /kkb/install/spark-2.3.3-bin-hadoop2.7/sbin
[hadoop@node03 sbin]$ ./start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10000 \
--master yarn-client \
--driver-cores 1 \
--driver-memory 1G \
--executor-cores 1 \
--executor-memory 1G \
--num-executors 2 以yarn-client的方式运行spark thriftserver
yarn界面
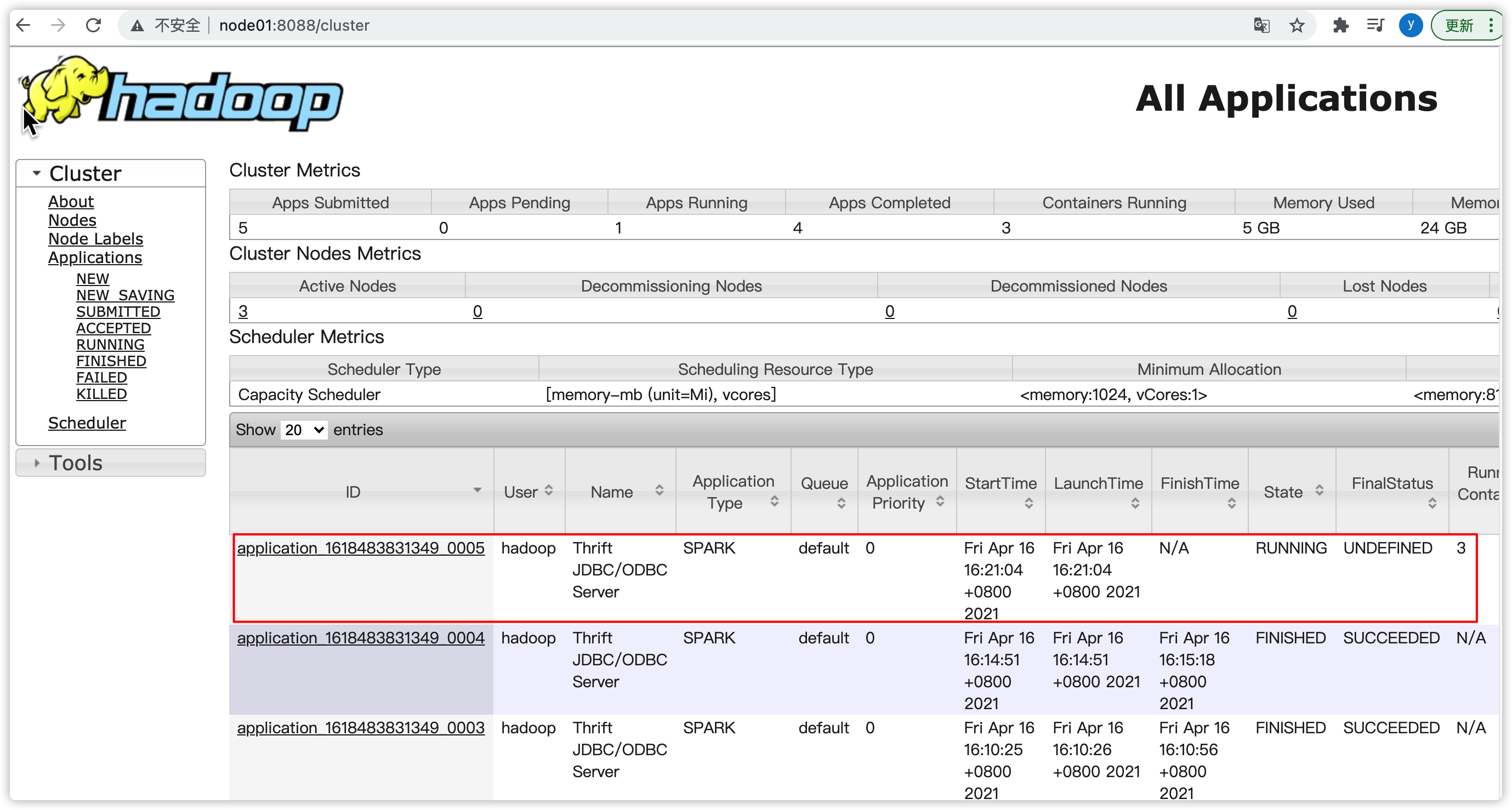
2、方式一:直接贴sql
- 数据源中心-创建数据源
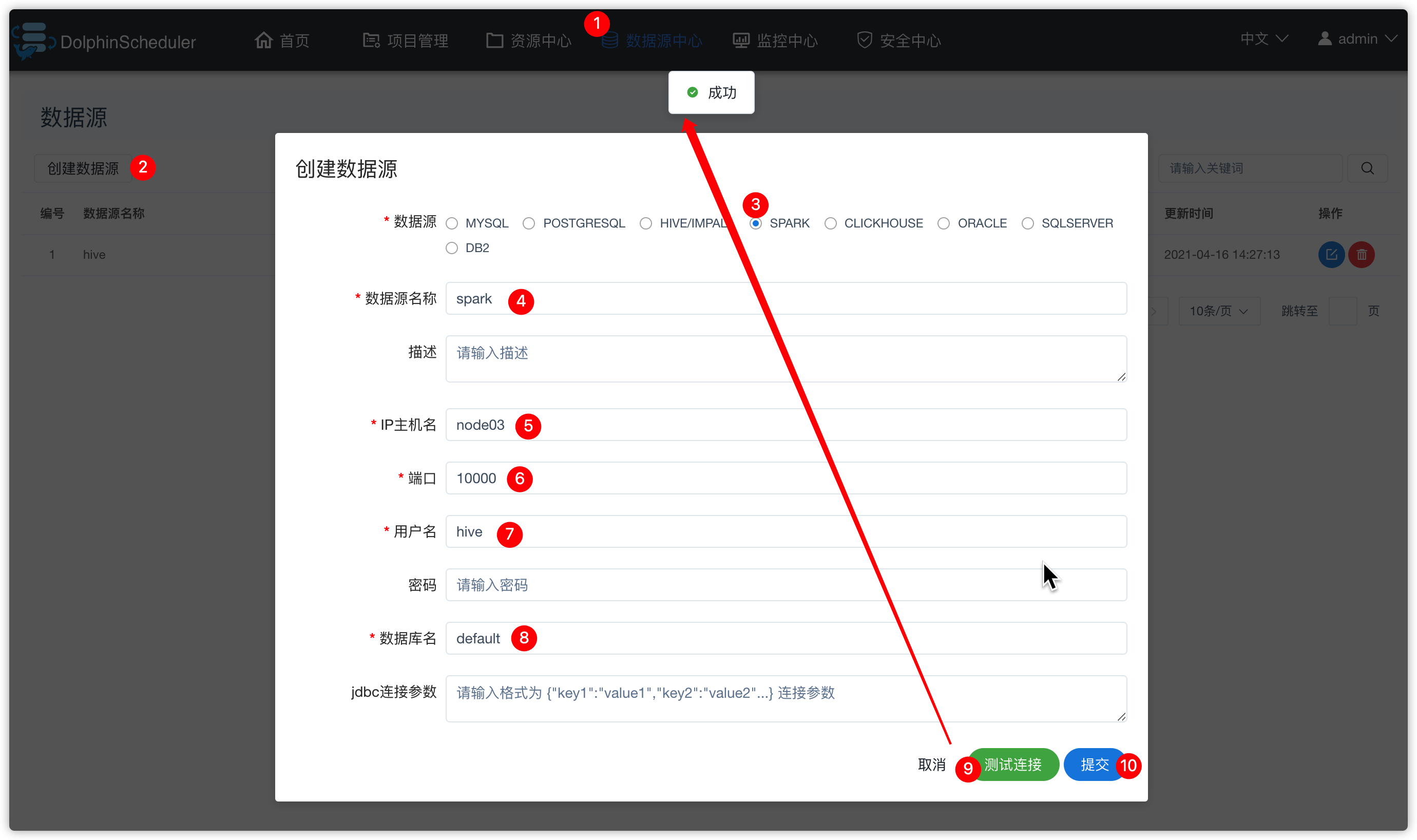
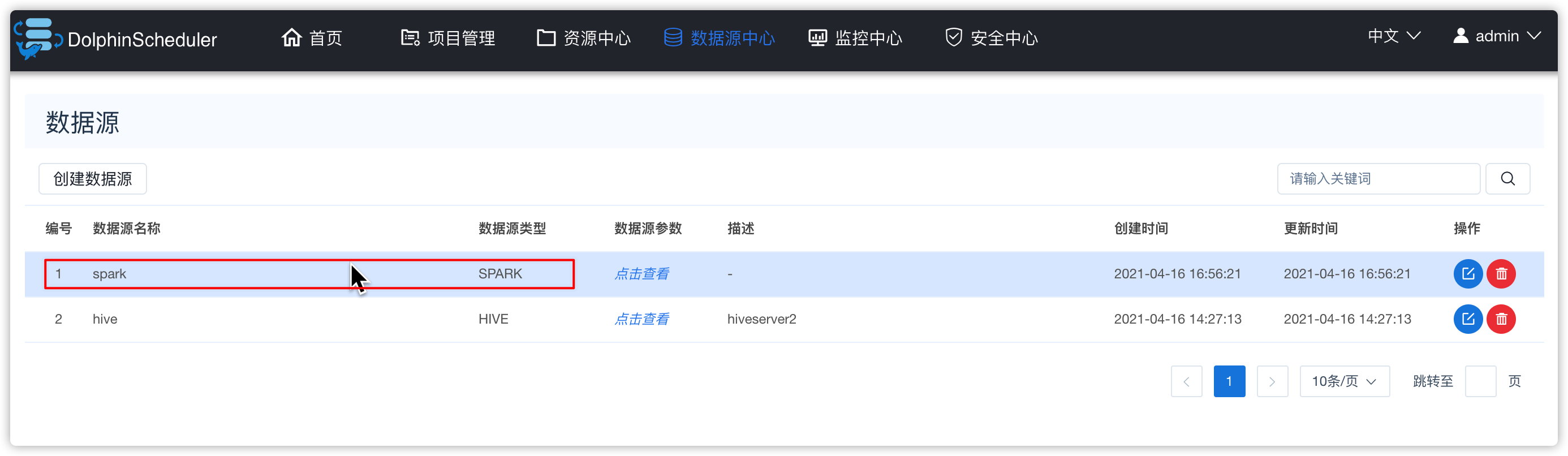
- 进入项目管理 -》 项目kkbpro -》工作流定义 -》下线firstflow工作流 -》编辑firstflow工作流 -》hive-shell 任务停用
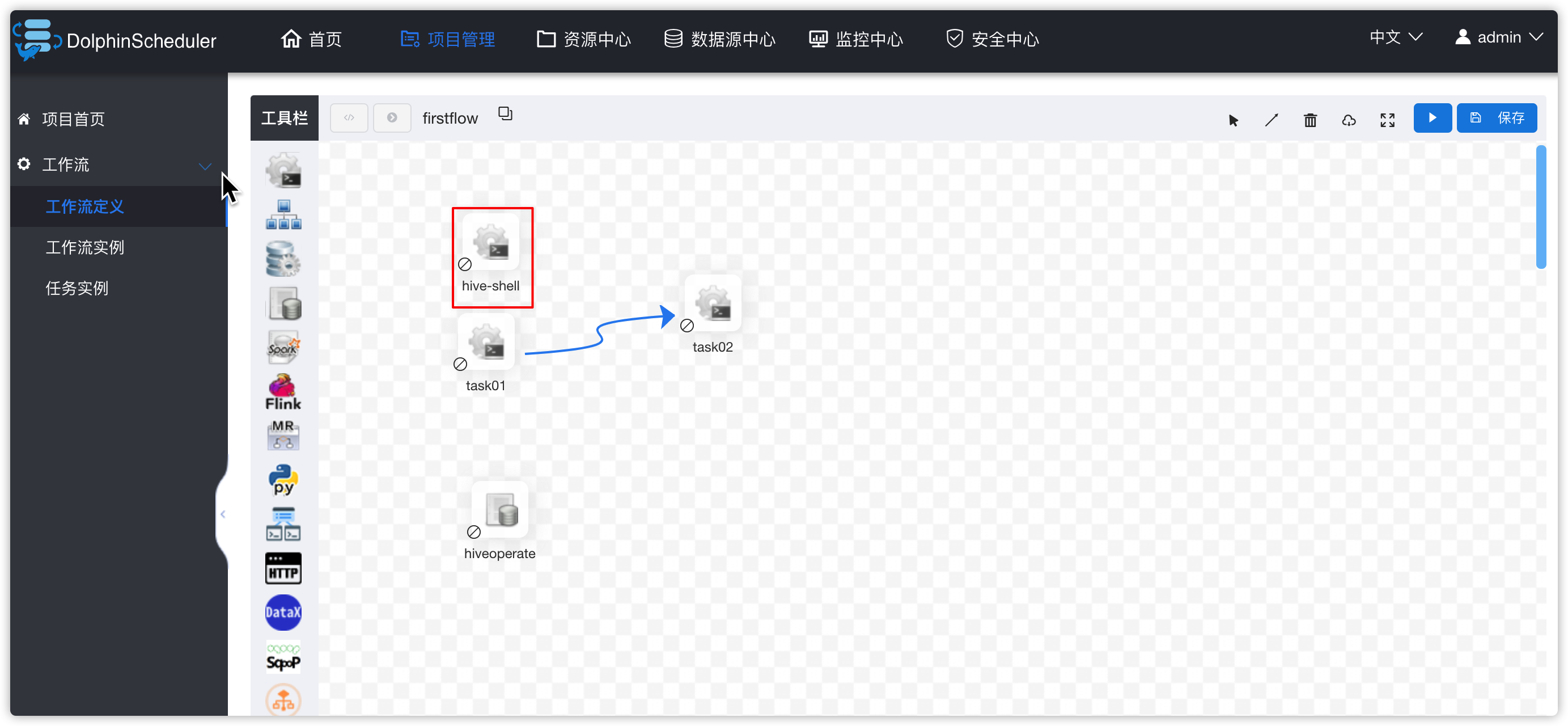
- 然后创建一个新的sql任务,并配置
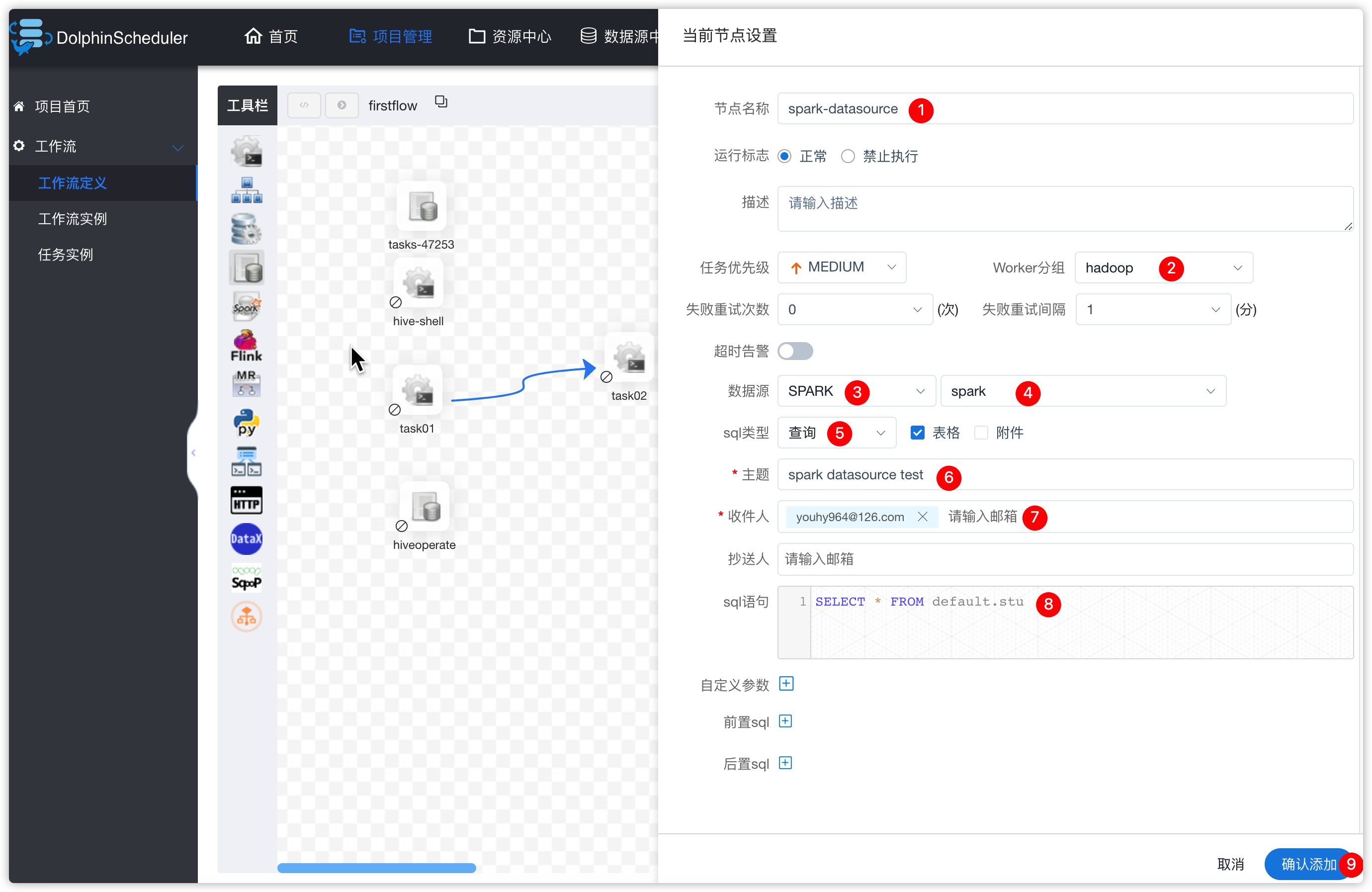
- 保存工作流
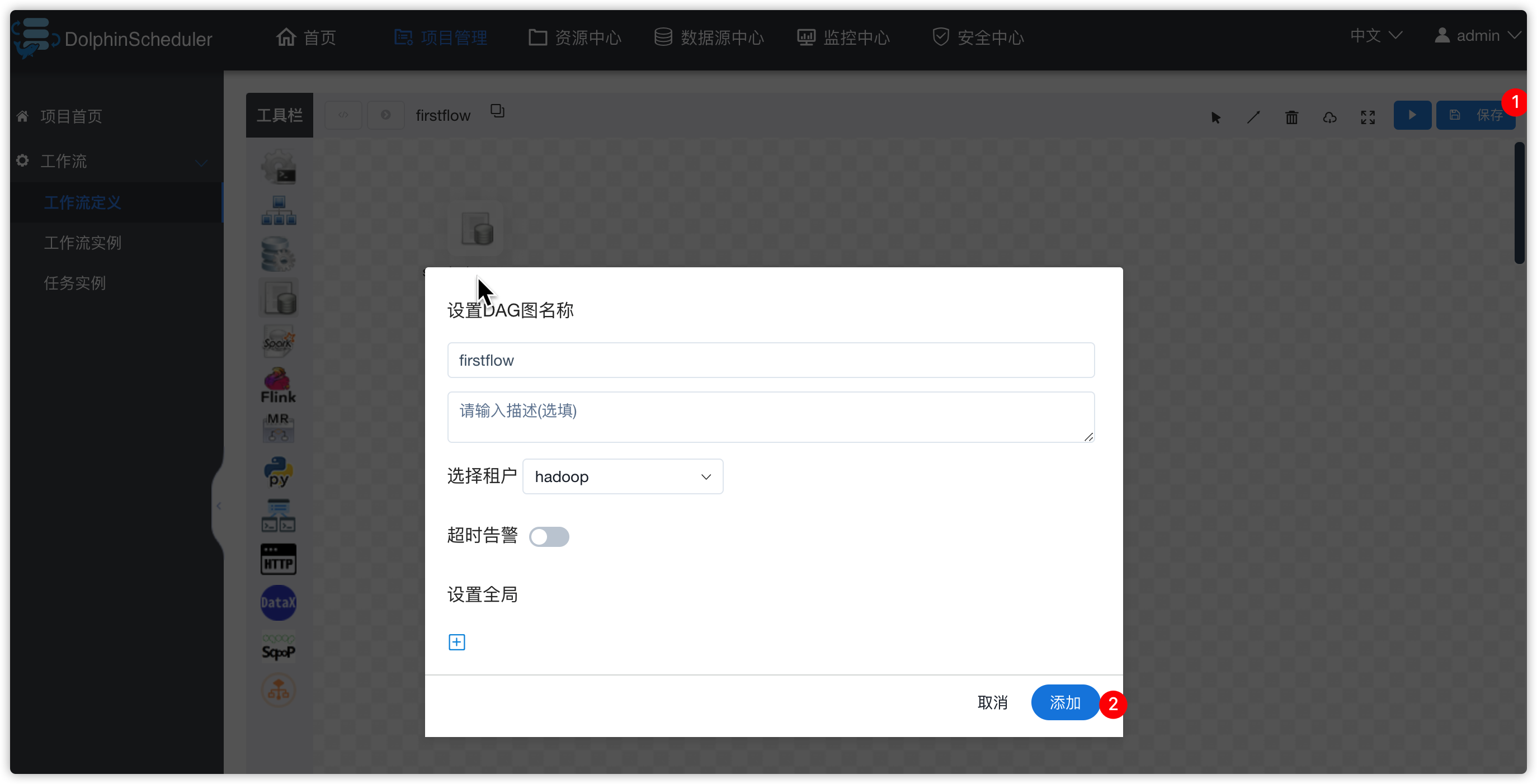
- 工作流重新上线,并运行
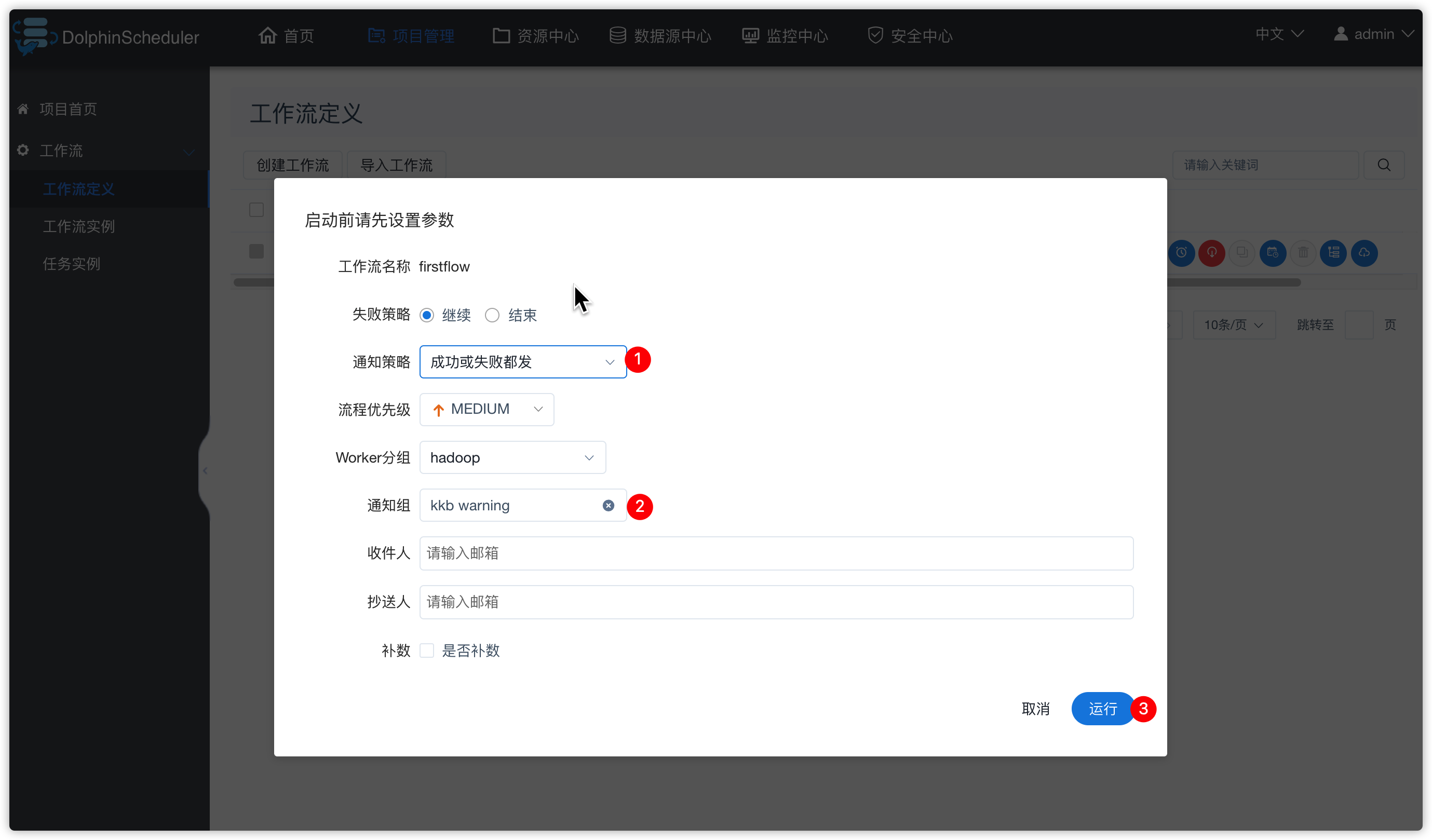
- 查看此工作流的工作流实例中spark-datasource任务的日志
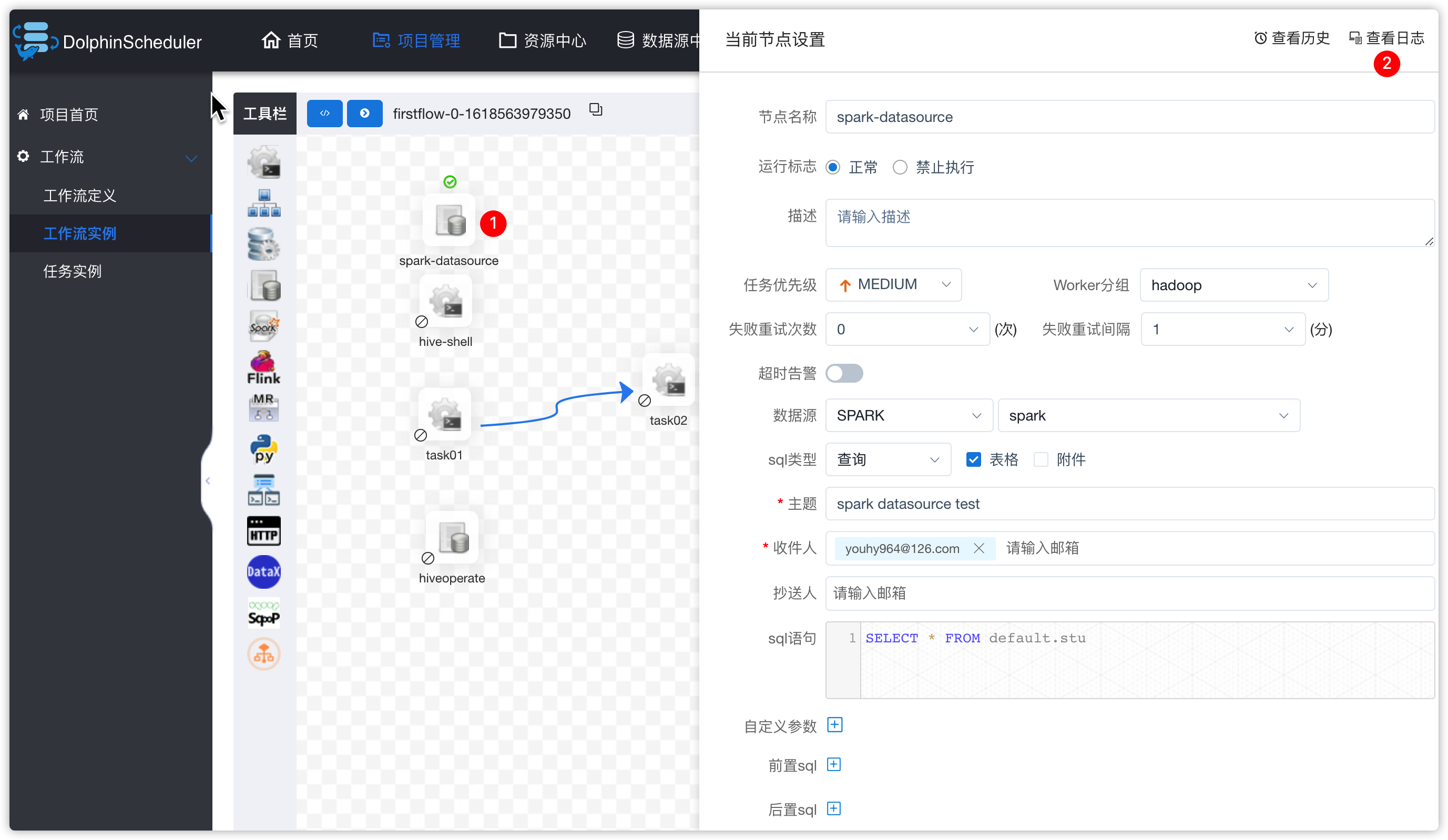
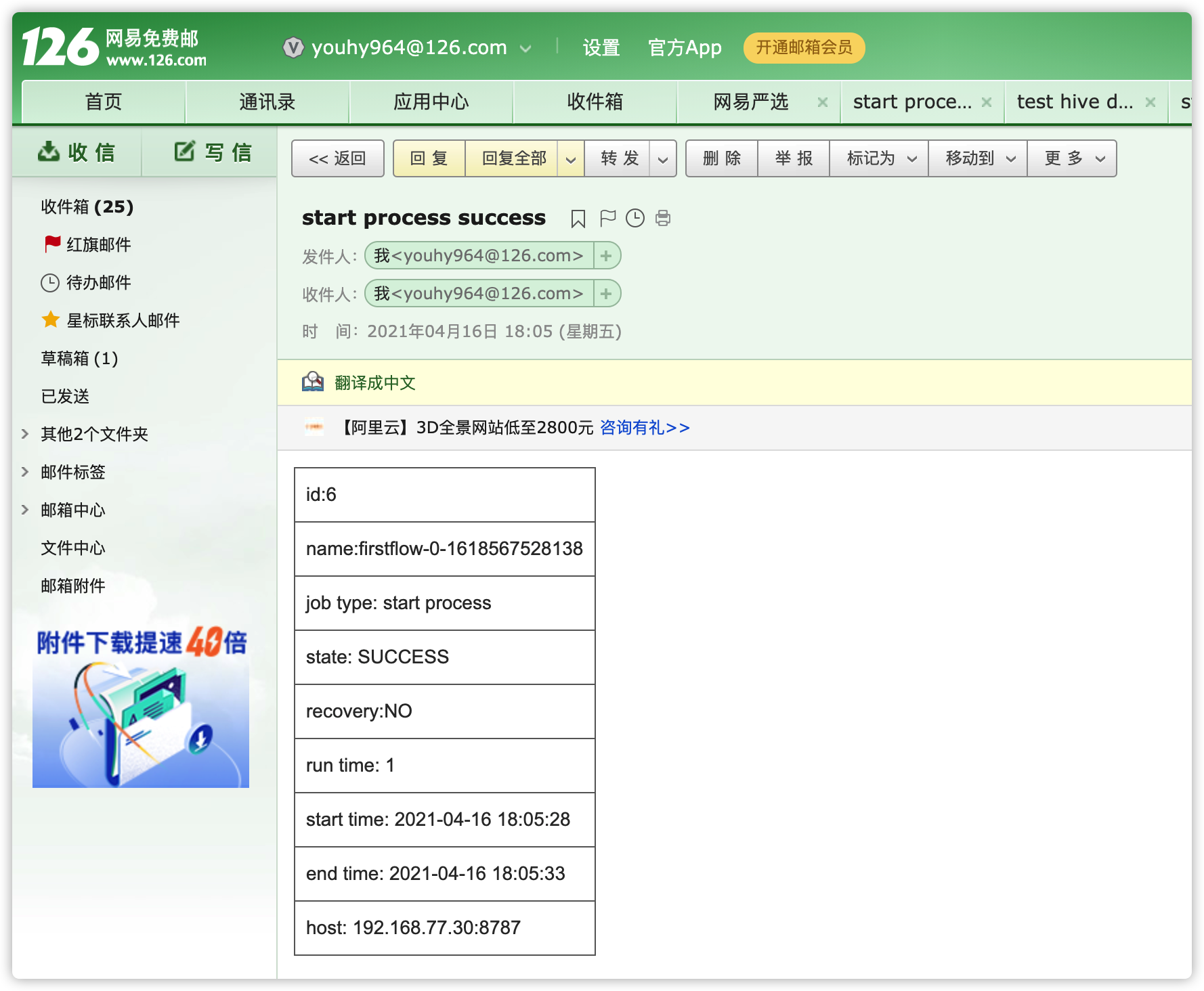
- 查看通知邮件
3、方式二:执行spark脚本
- 类似于hive脚本操作
- 通过spark beeline操作脚本
- 资源中心-创建文件夹
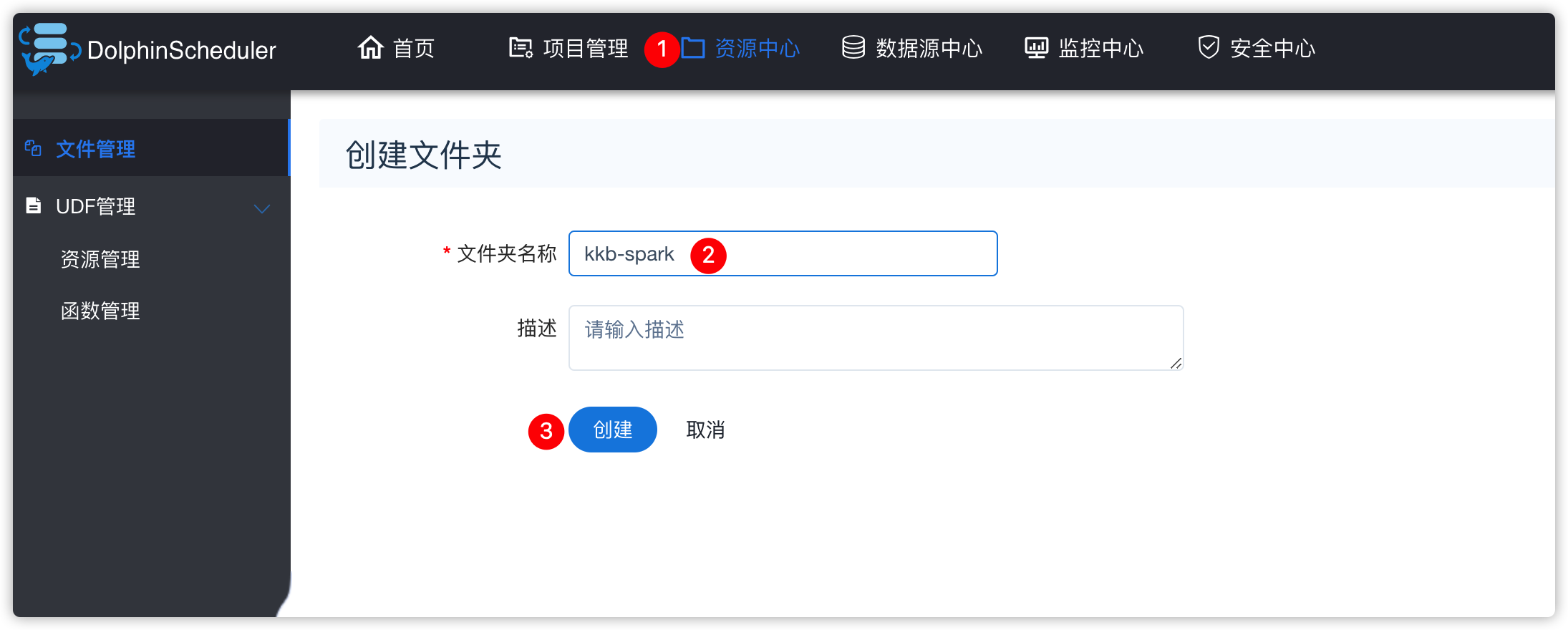
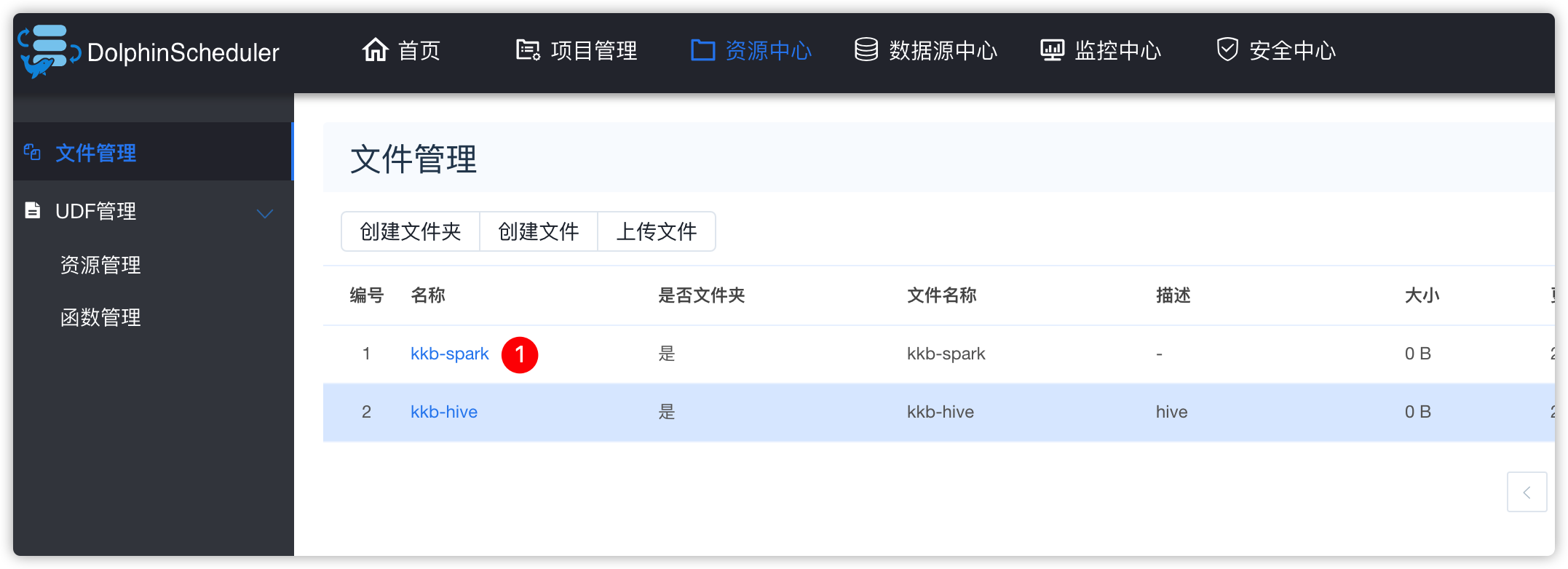
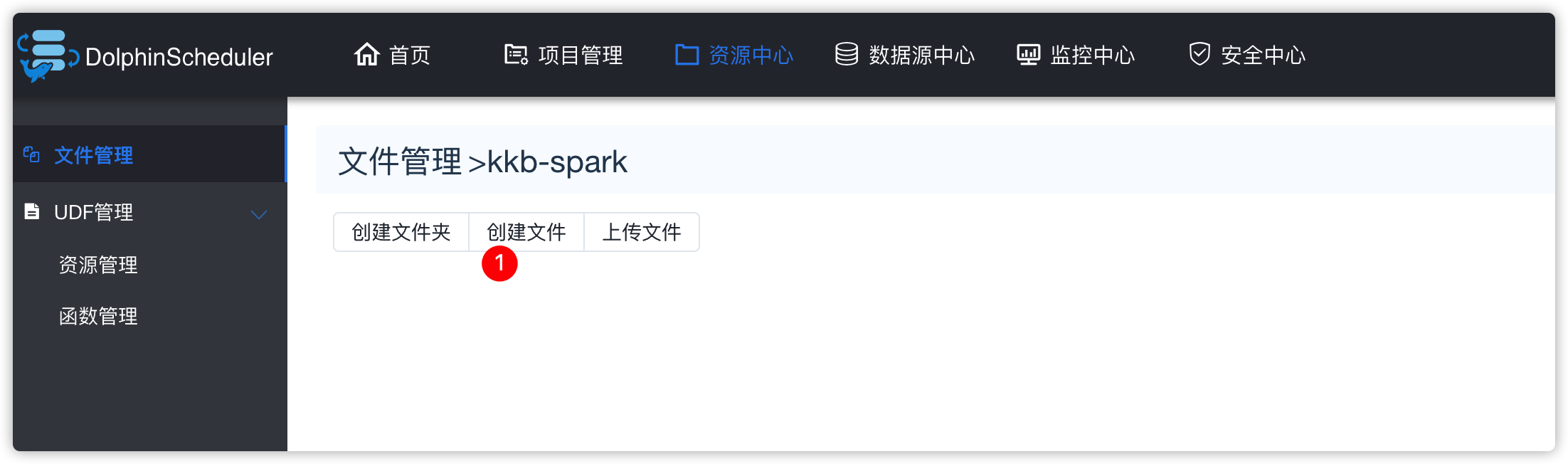

- 脚本内容如下
#!/bin/bash
SQL="SELECT * FROM default.stu"
echo "operate with spark beeline------------->->->"
/kkb/install/spark-2.3.3-bin-hadoop2.7/bin/beeline \
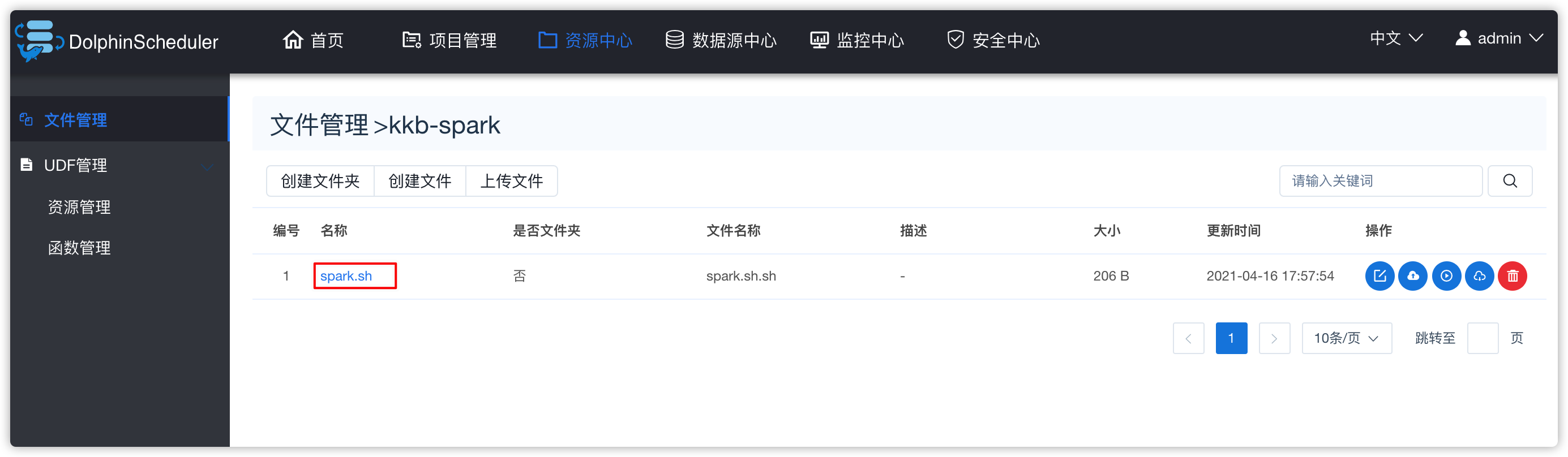
-u "jdbc:hive2://node03:10000/default" hive -e "${SQL}"- 效果如下
-
如下类似的操作,之前已经做过截图,所以部分操作截图省略
-
进入项目管理 -》 项目kkbpro -》工作流定义 -》下线firstflow工作流 -》编辑firstflow工作流 -》spark-datasource任务停用
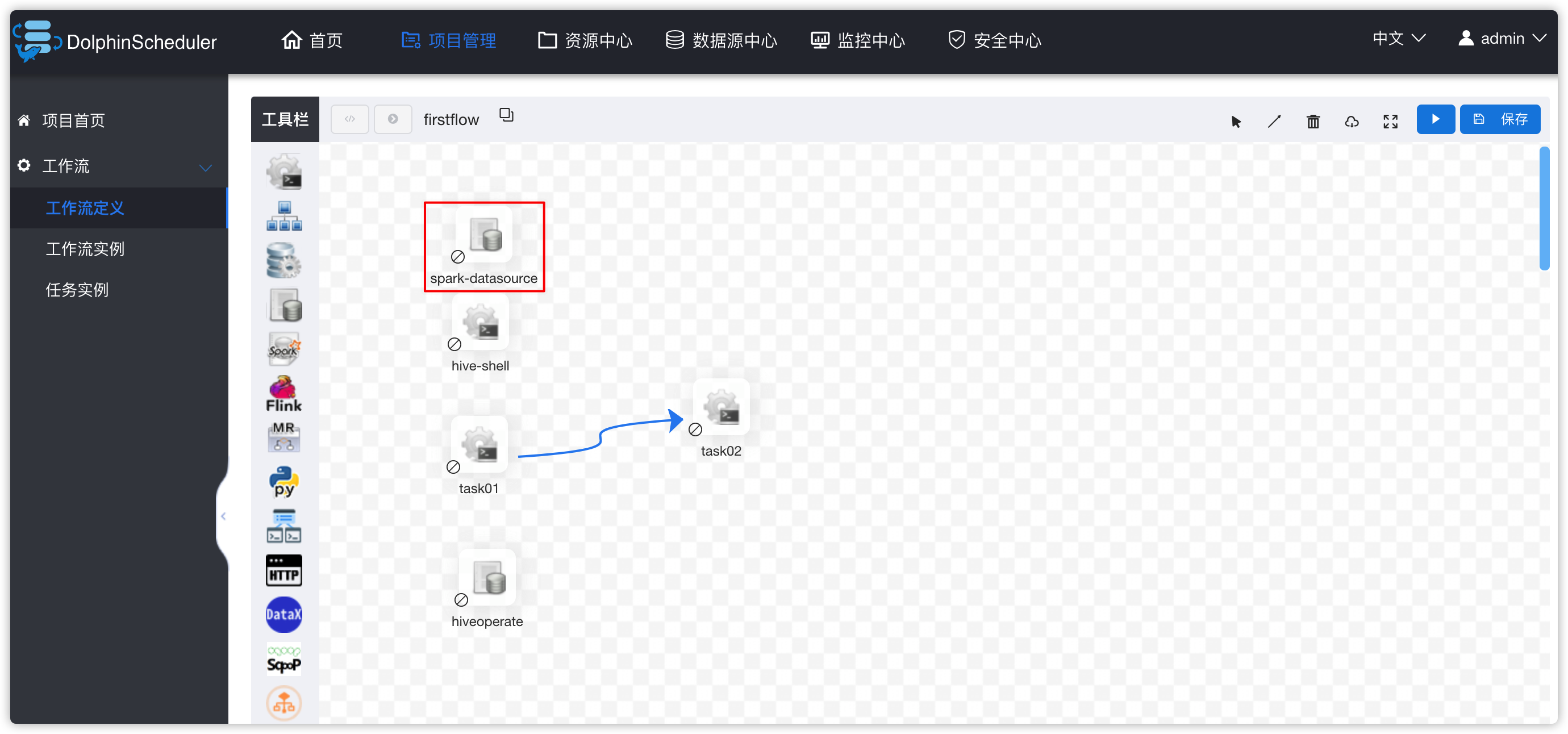
- 工作流中添加SHELL类型的任务
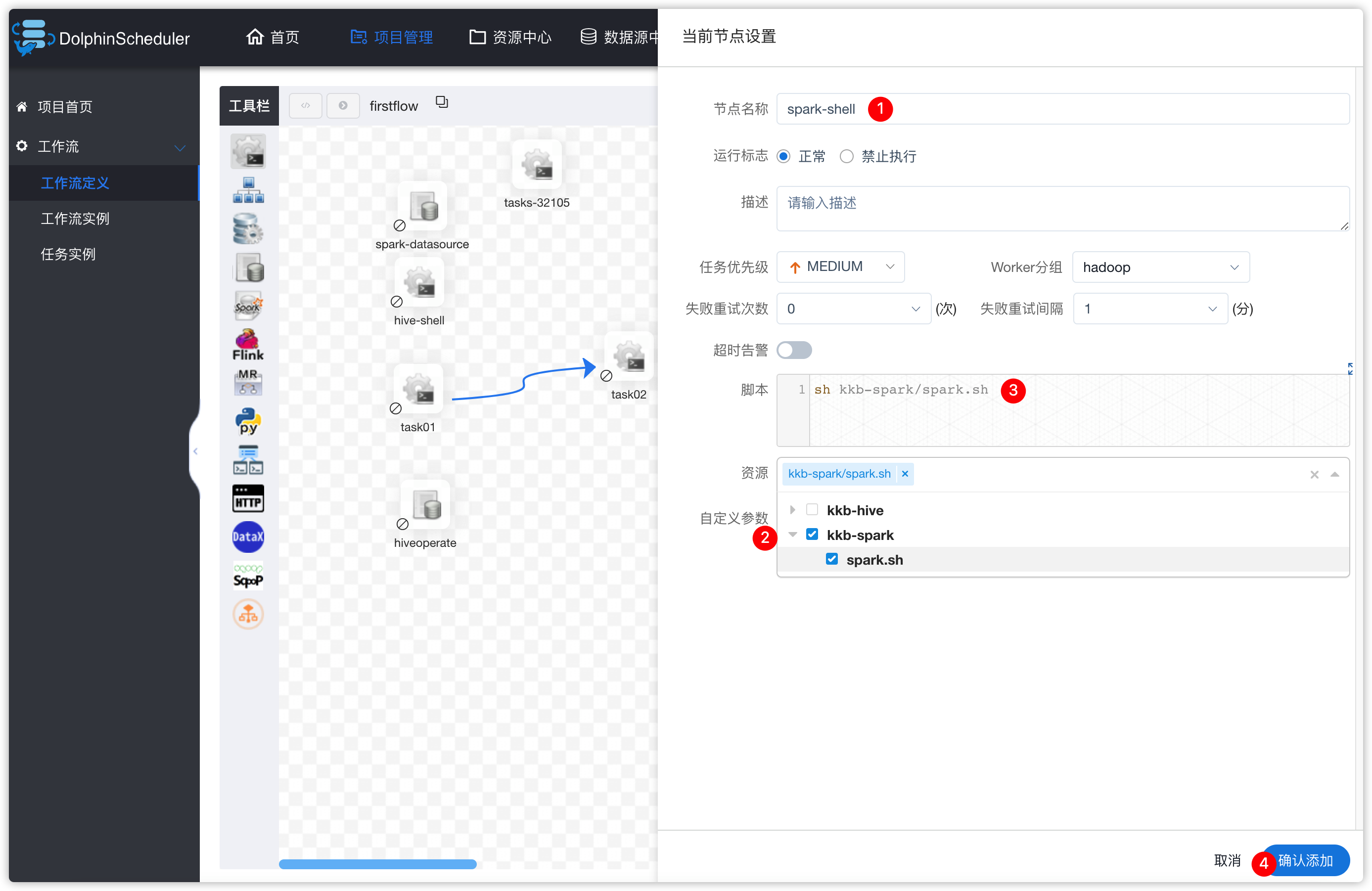
- 保存工作流
- 重新上线firstflow工作流,并运行
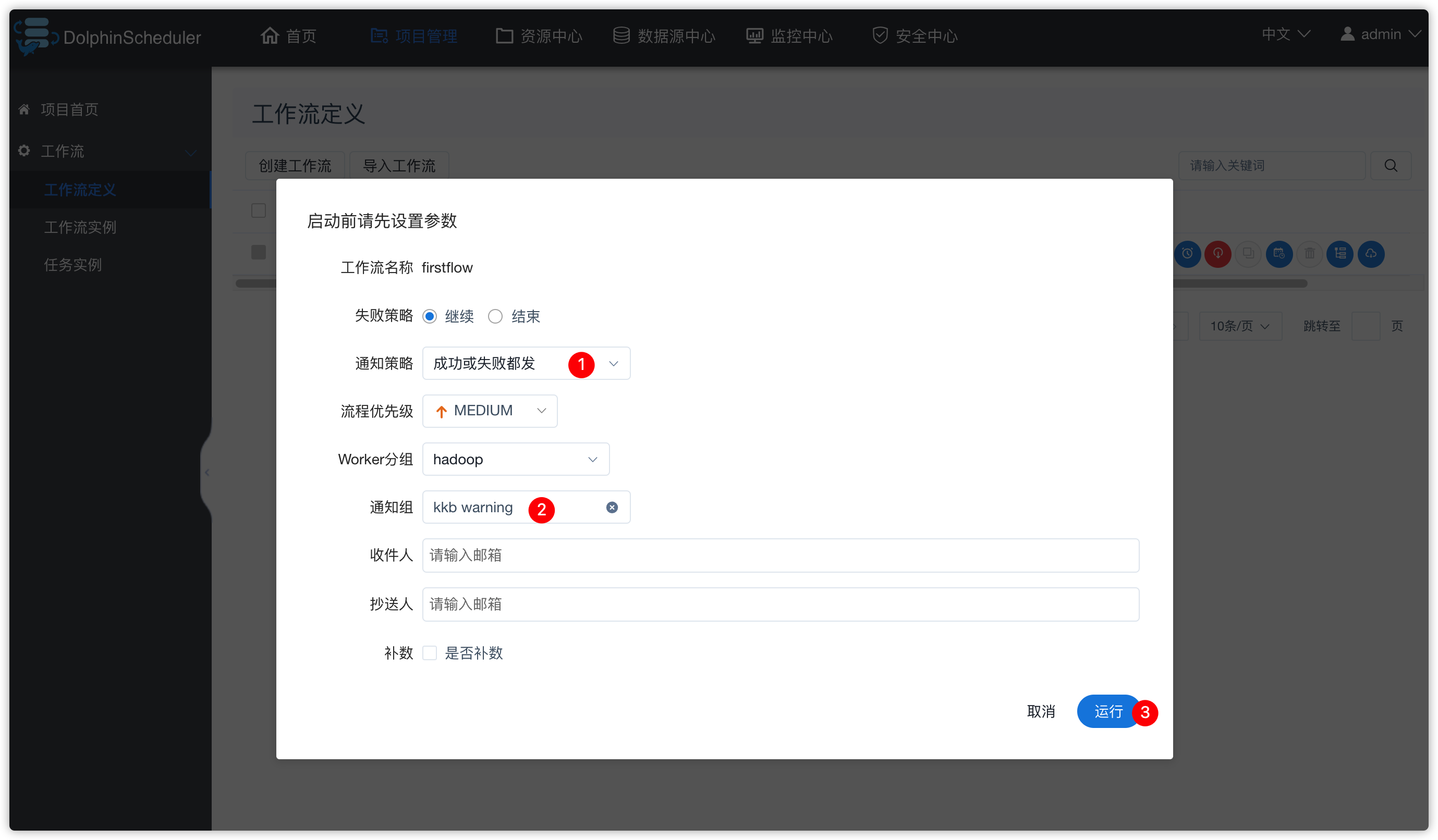
- 查看日志及邮件
Views: 36