
Azkaban使用
-
azkaban 4.x目前同时支持flow1.0与flow 2.0;
-
官网说flow 1.0将来会被淘汰,所以本文档使用flow 2.0
-
如果对flow 1.0感兴趣的同学,可以参考文章自行学习体验
-
Azkaba内置的任务类型支持command、java
1. Flow 2.0
1. 入门例子Hello World
- 在
windows或mac中,创建文件flow20.project,内容如下
azkaban-flow-version: 2.0- 创建
basic.flow文件,内容如下
nodes:
- name: jobA
type: command
config:
command: echo "Hello World! This is an flow 2.0 example."文件中要有
nodes的部分,包含所有你想要运行的job需要为每个job指定
name、type大多的job需要
config
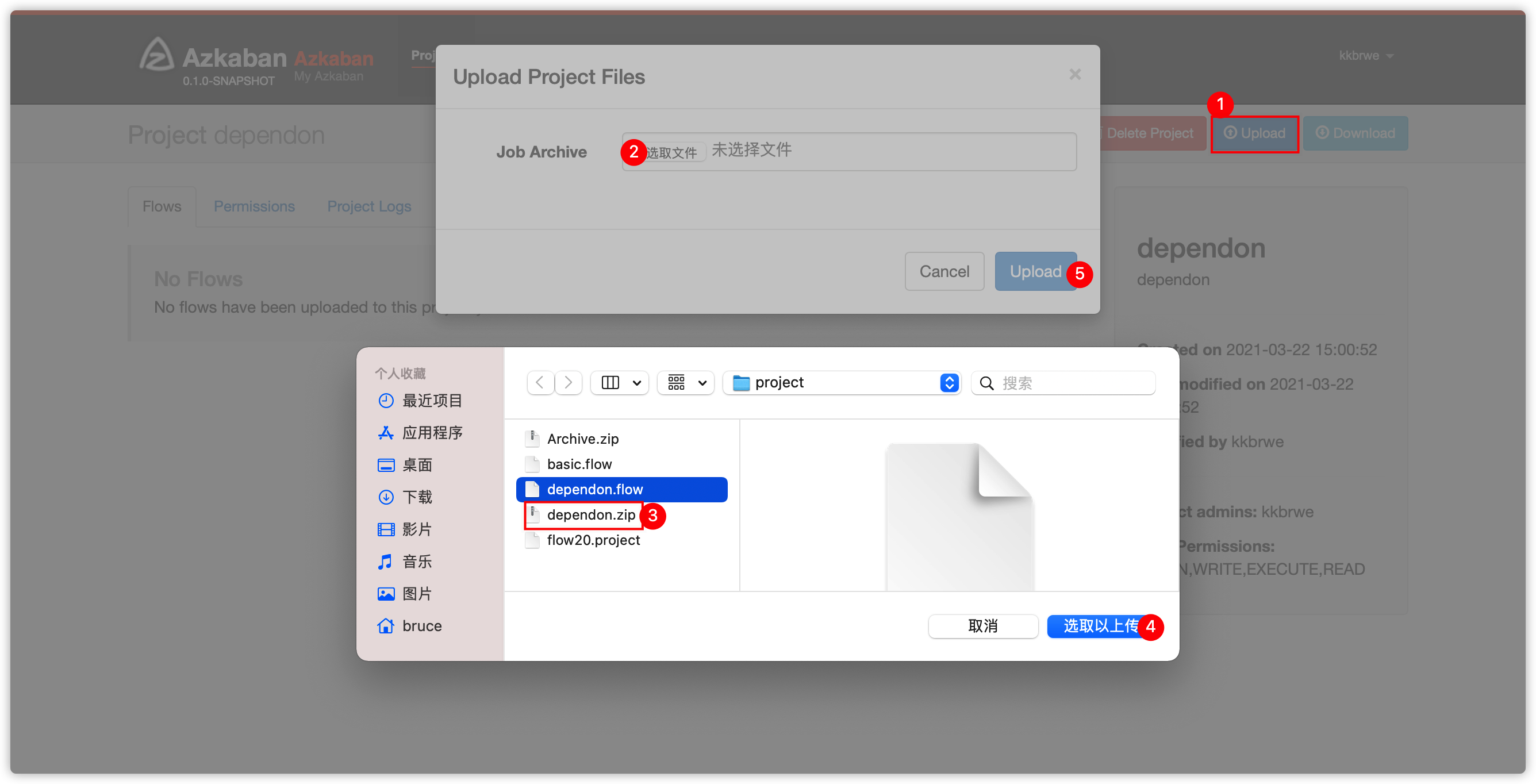
- 将两个文件压缩成一个zip包,比如起名叫
Archive.zip - 使用如下账号信息登录azkaban
用户名:kkbrwe
密码:kkb123- 创建工程
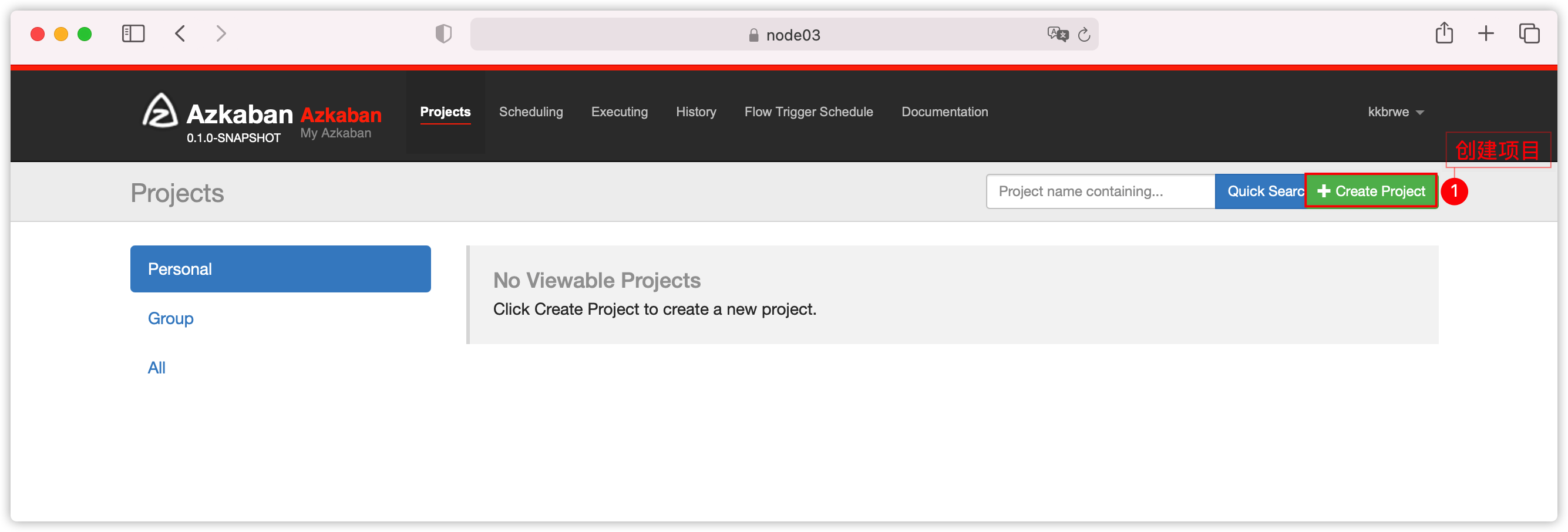
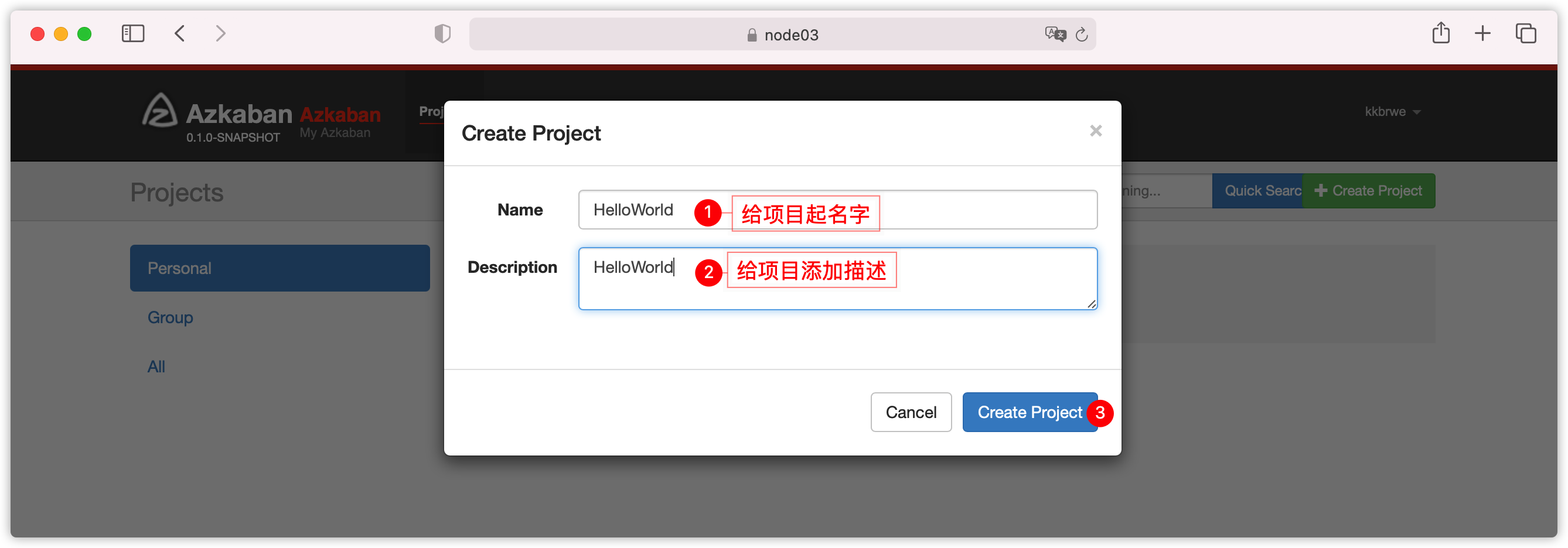
- 上传项目zip文件
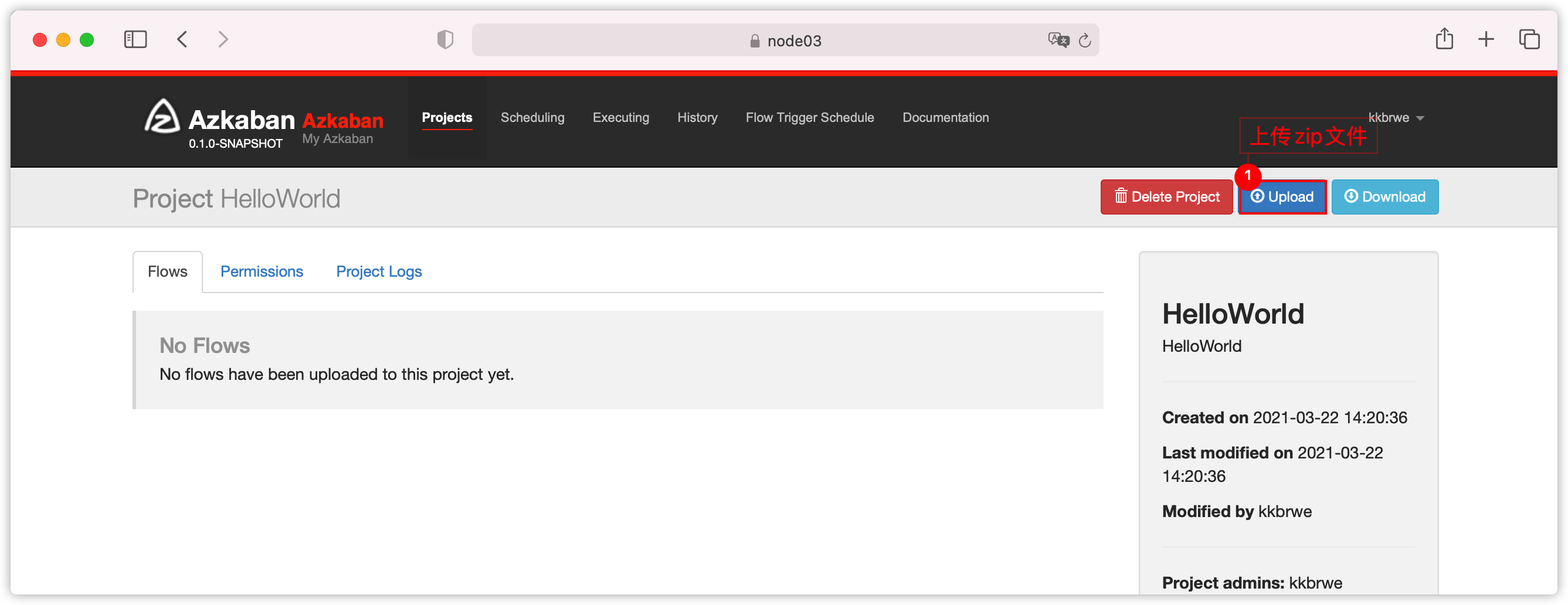
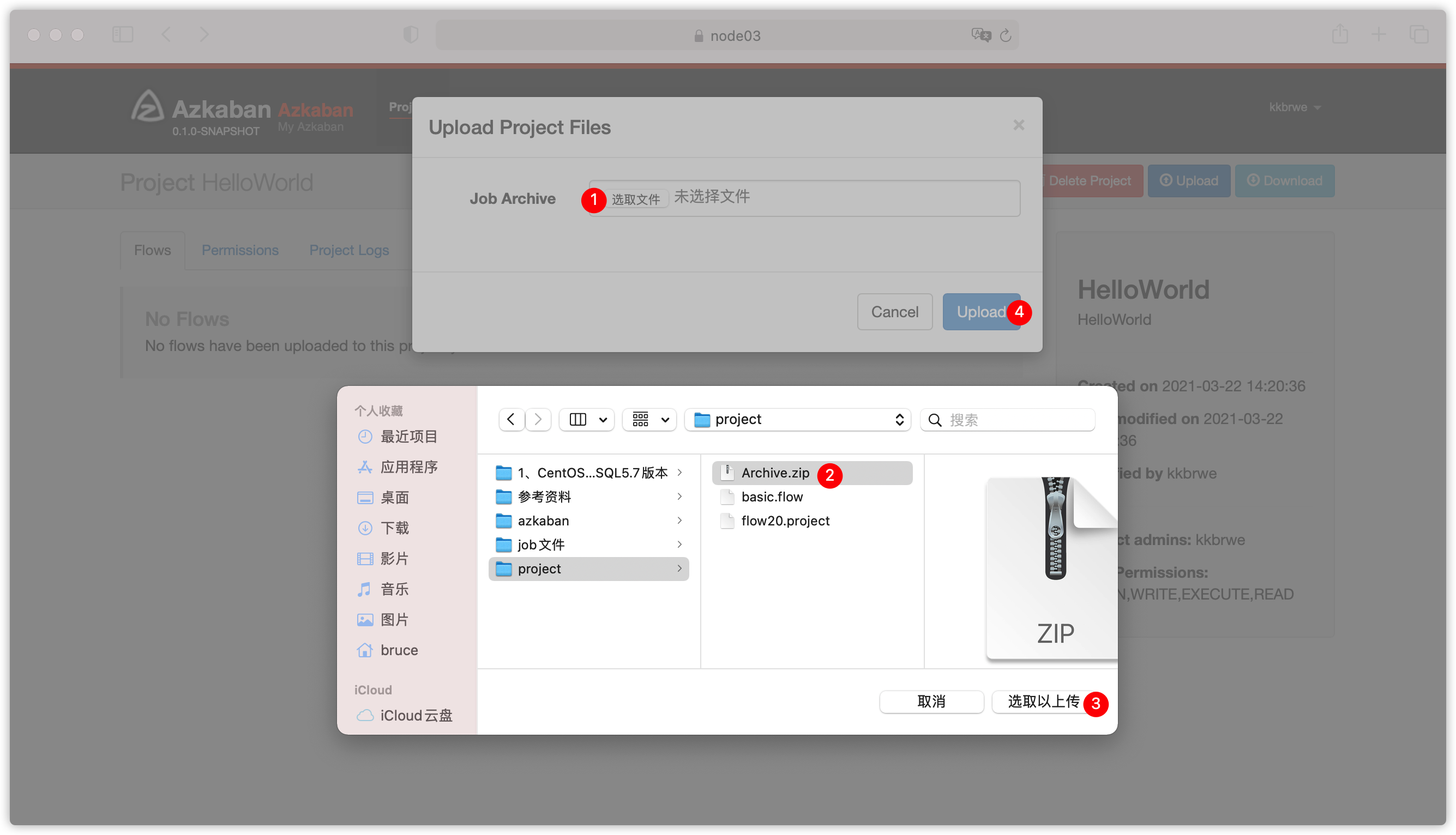
- 执行flow
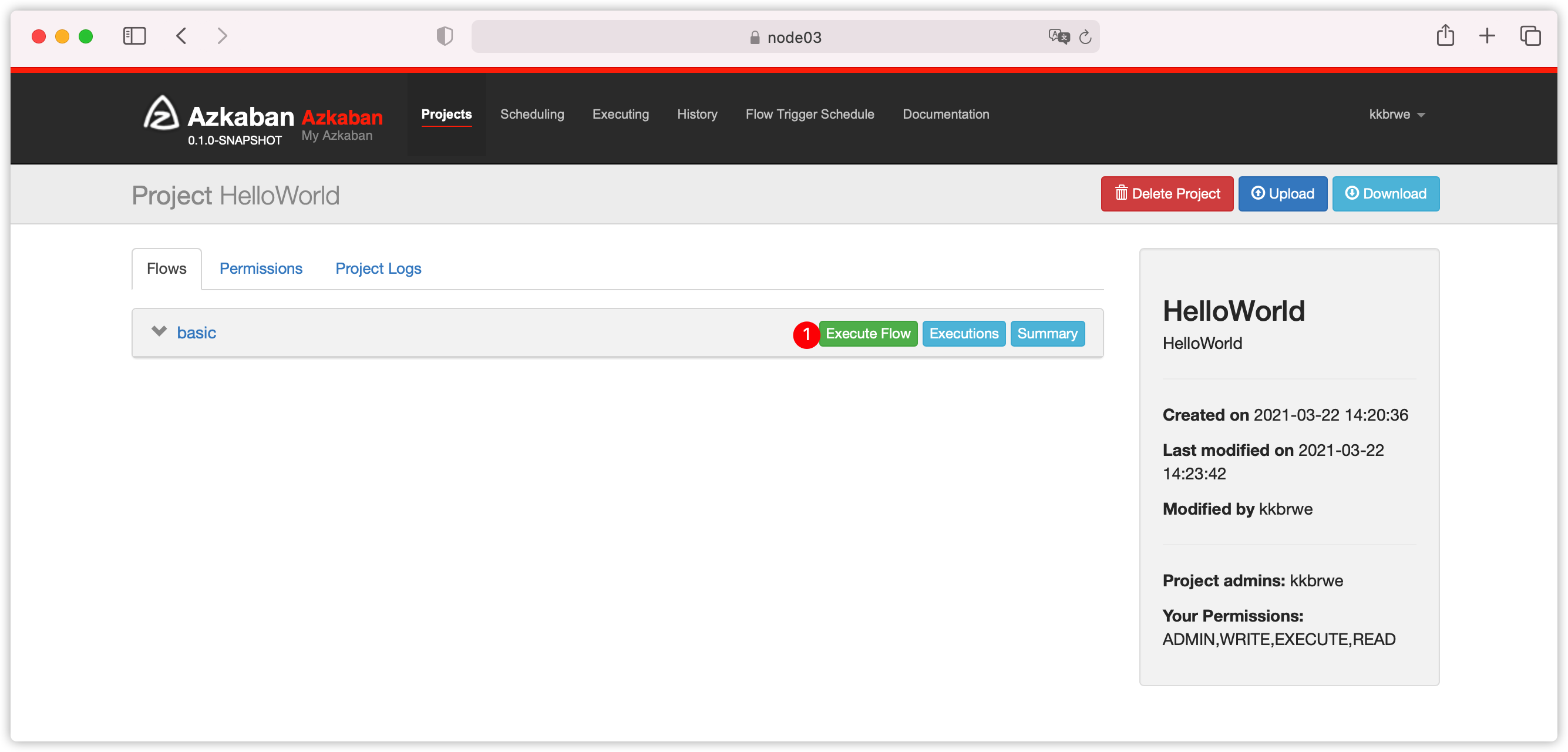
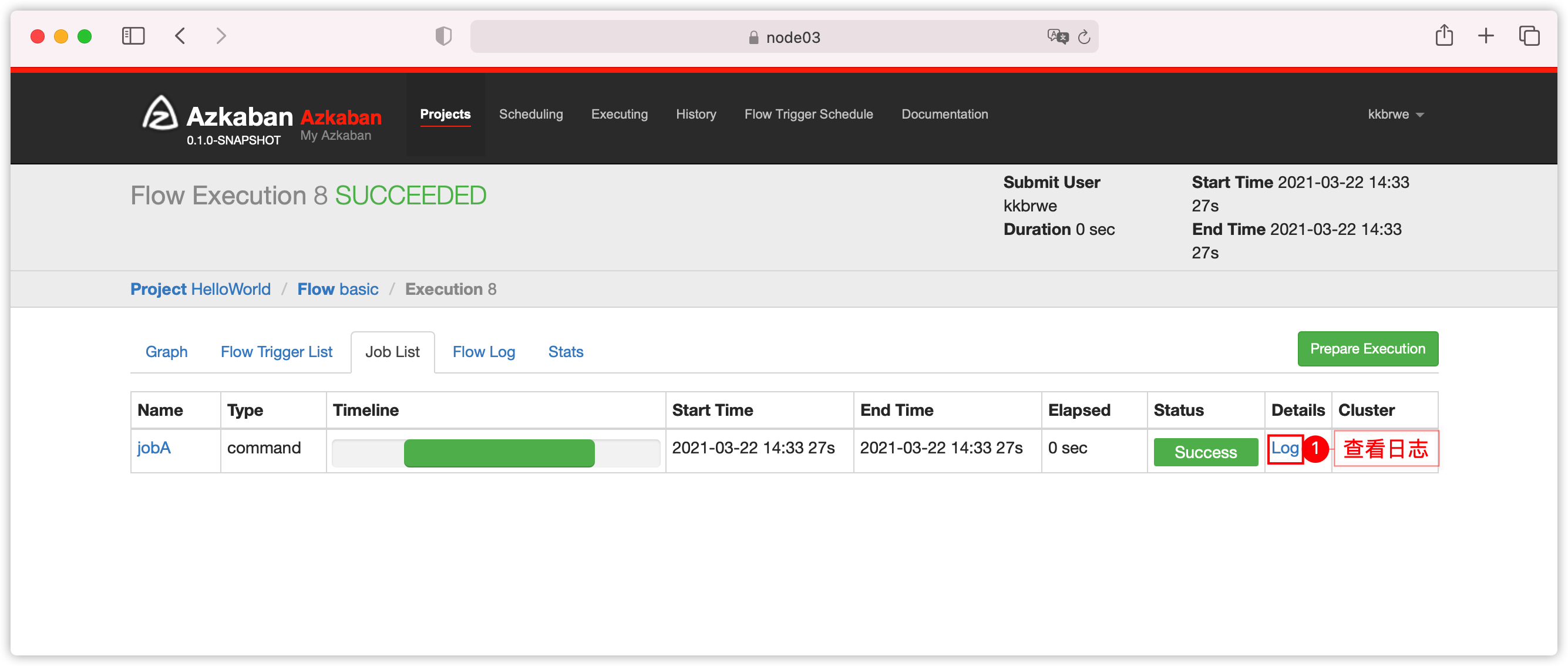
- 弹出如下界面
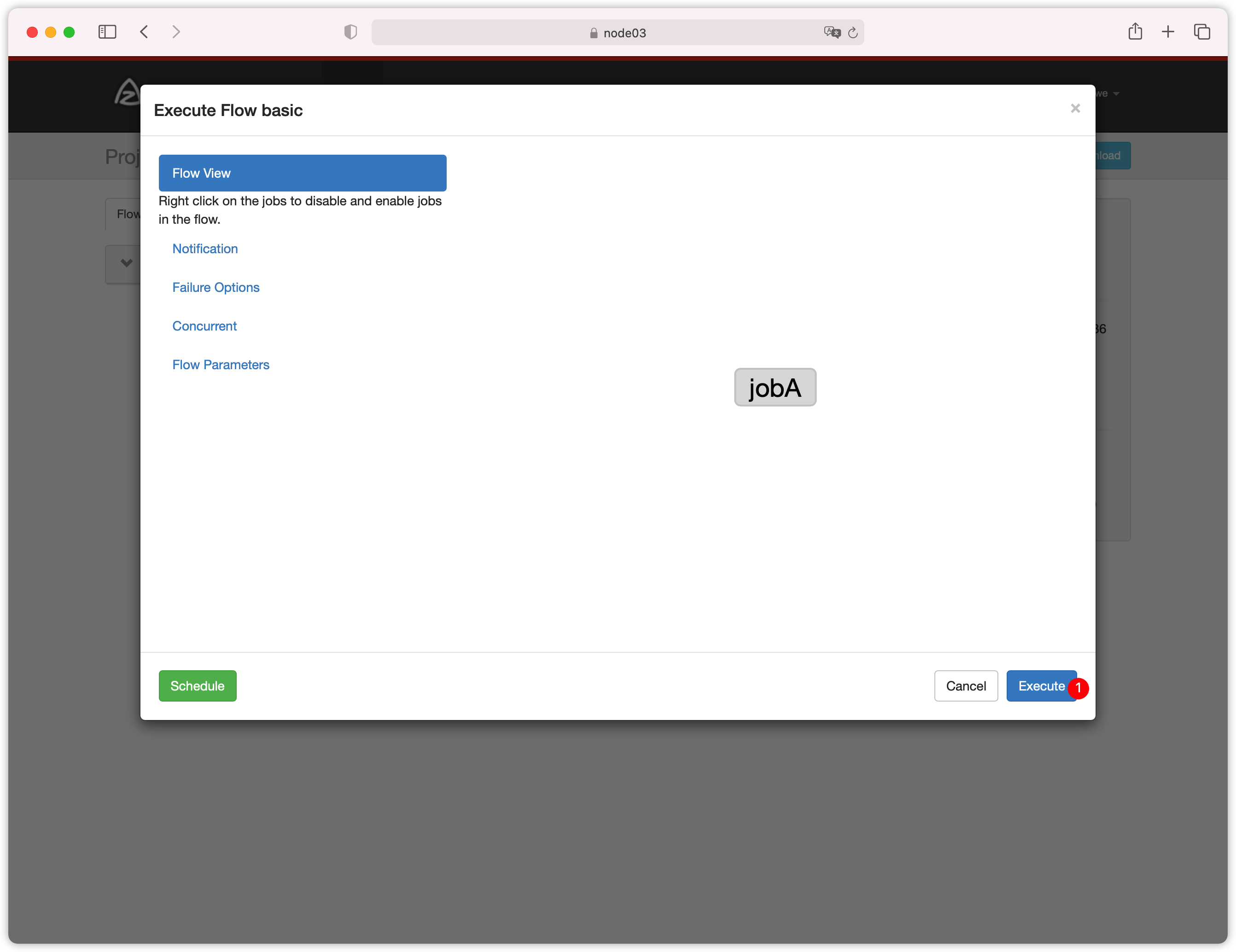
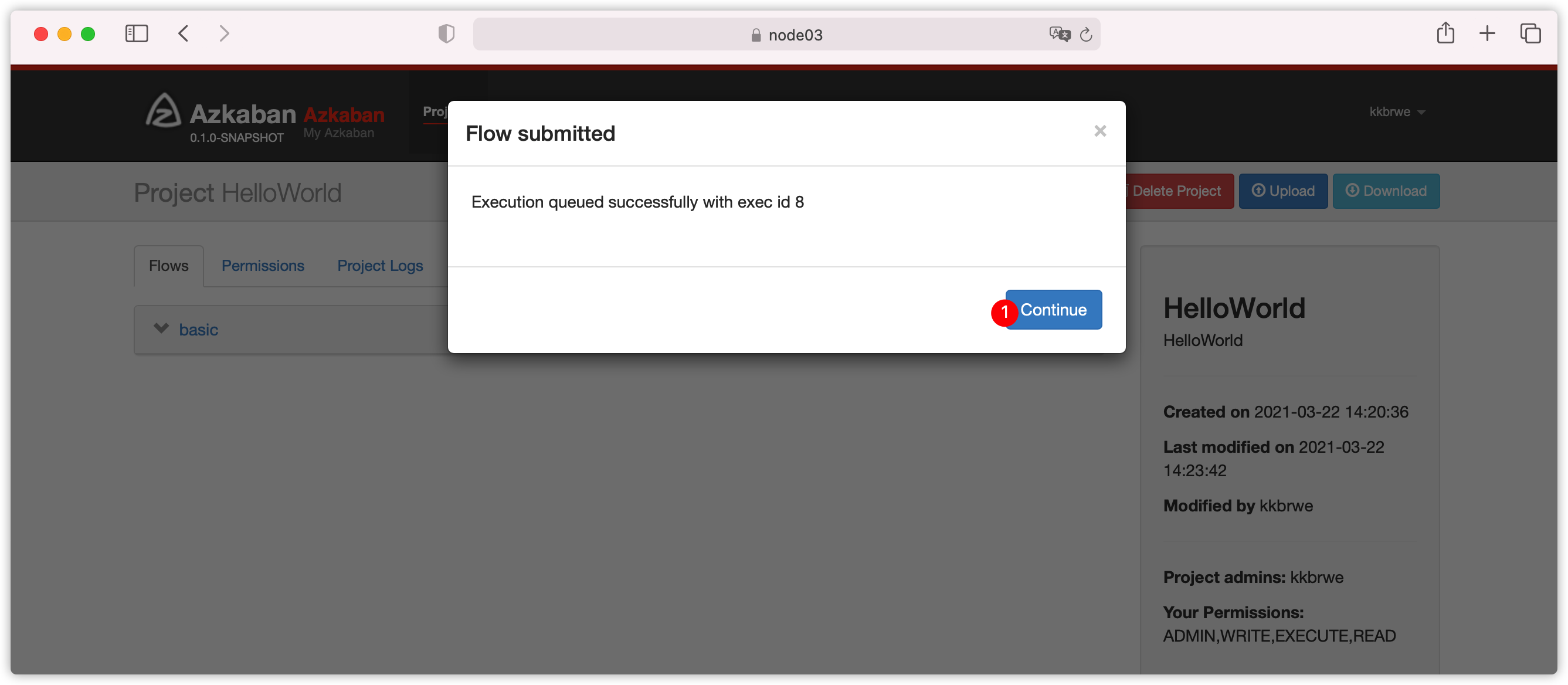
- 下图
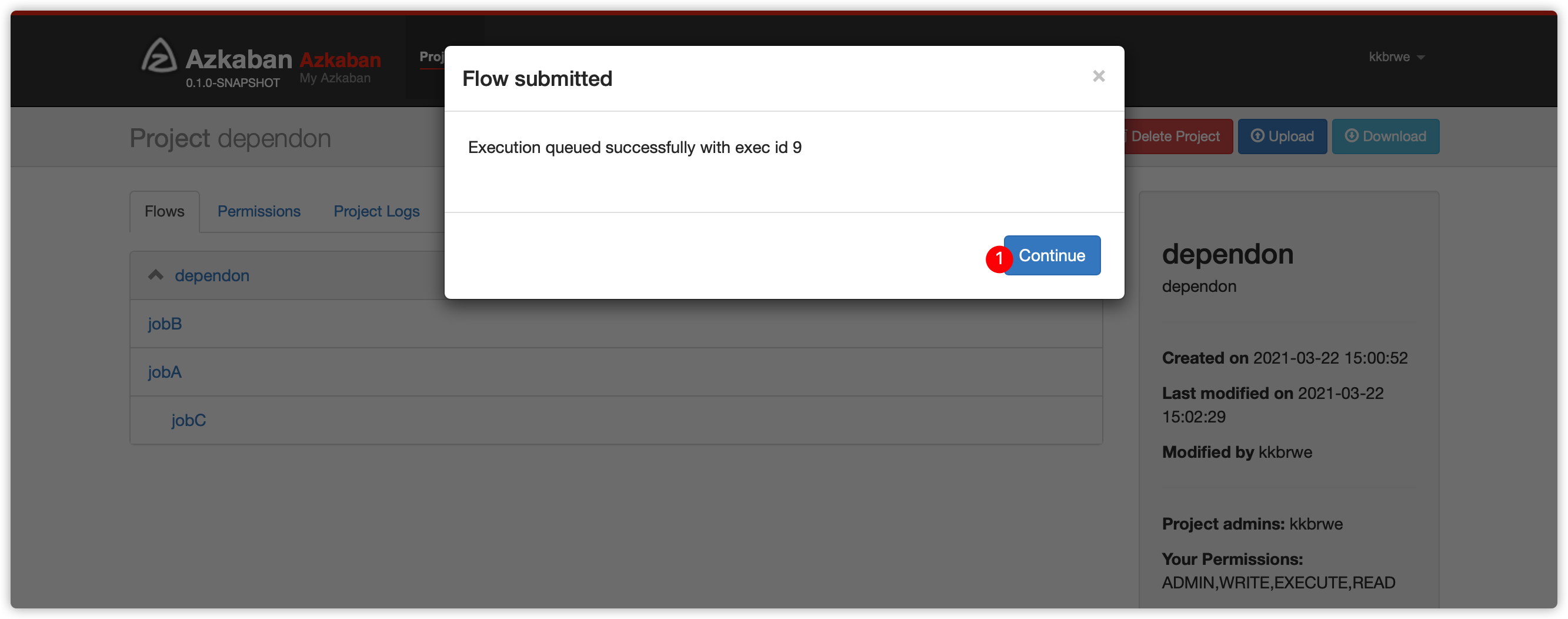
Execution queued successfully with exec id 8表示,web server选择id是8的exec server执行此流
- 绿色表示执行成功;查看
Job List
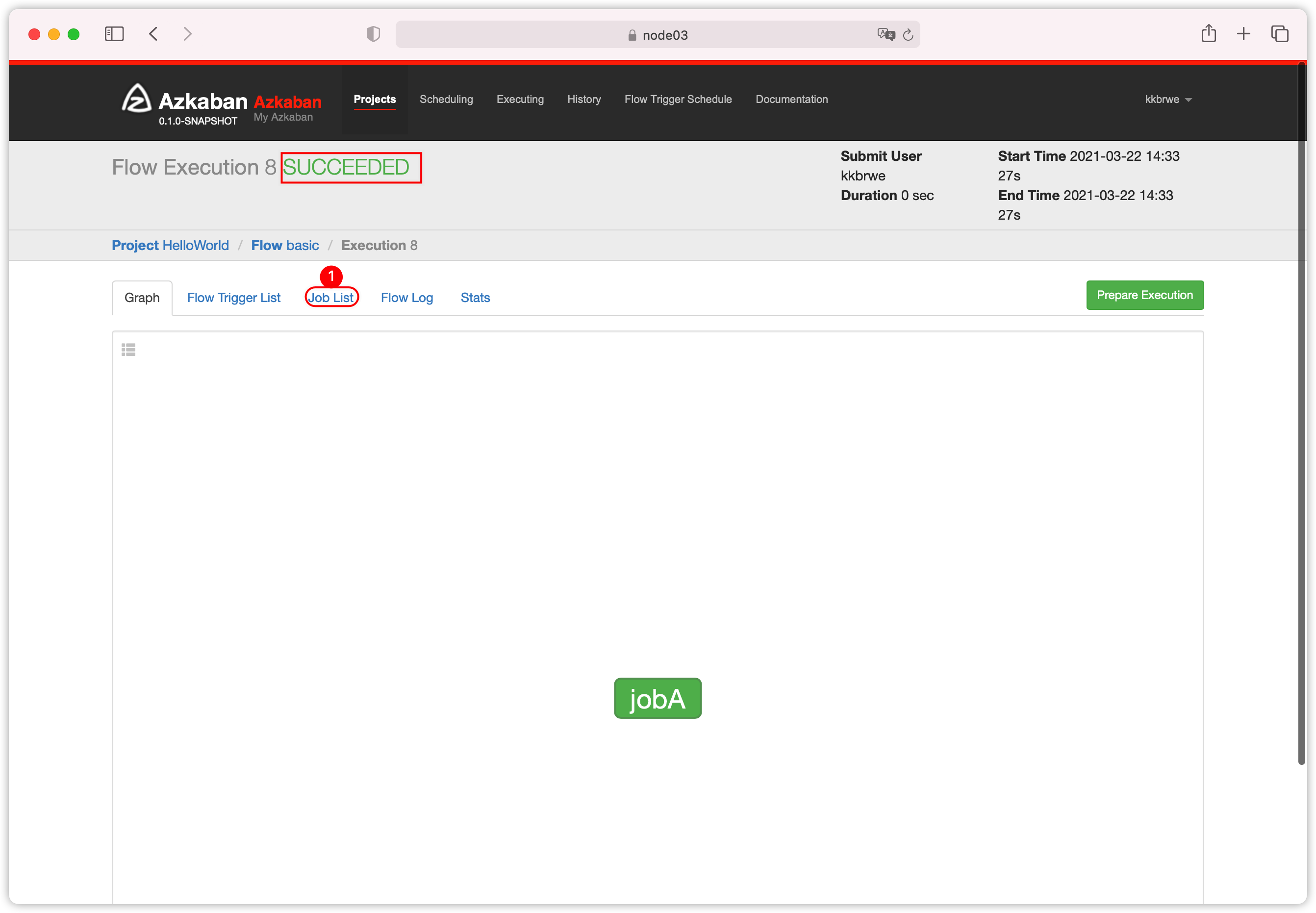
- 查看日志
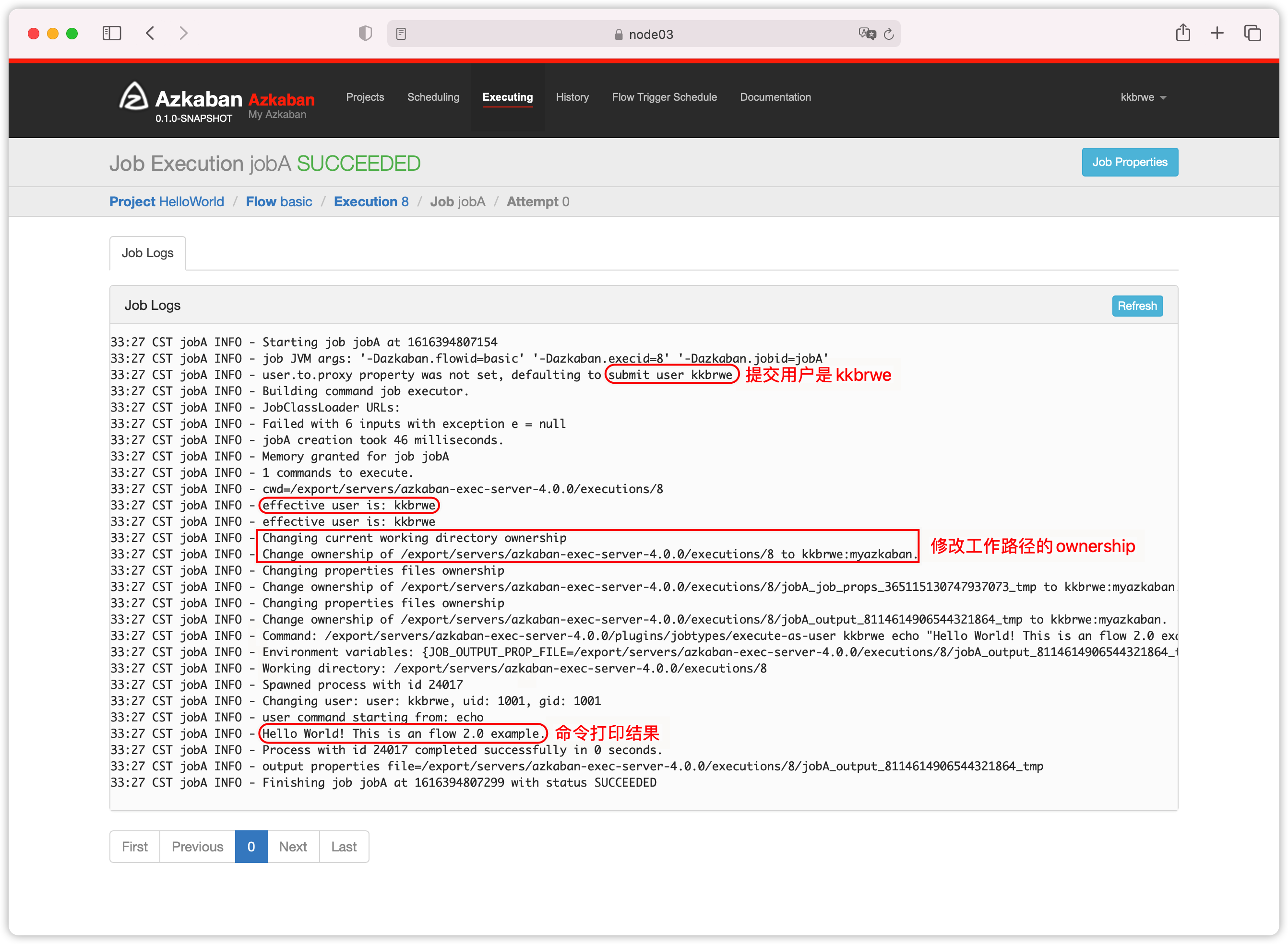
2. 单job有多个command
- flow中的一个job有多个command
nodes:
- name: jobA
type: command
config:
command: mkdir /export/servers/azkaban-exec-server-4.0.0/executions/test1
command.1: mkdir /export/servers/azkaban-exec-server-4.0.0/executions/test2第一个command用command表示
第二个用command.1表示
第三个用command.2表示,以此类推
- 剩余步骤(图略)
- 生成项目zip文件
- web ui创建项目
- 上传zip文件
- 执行flow
- 查看日志
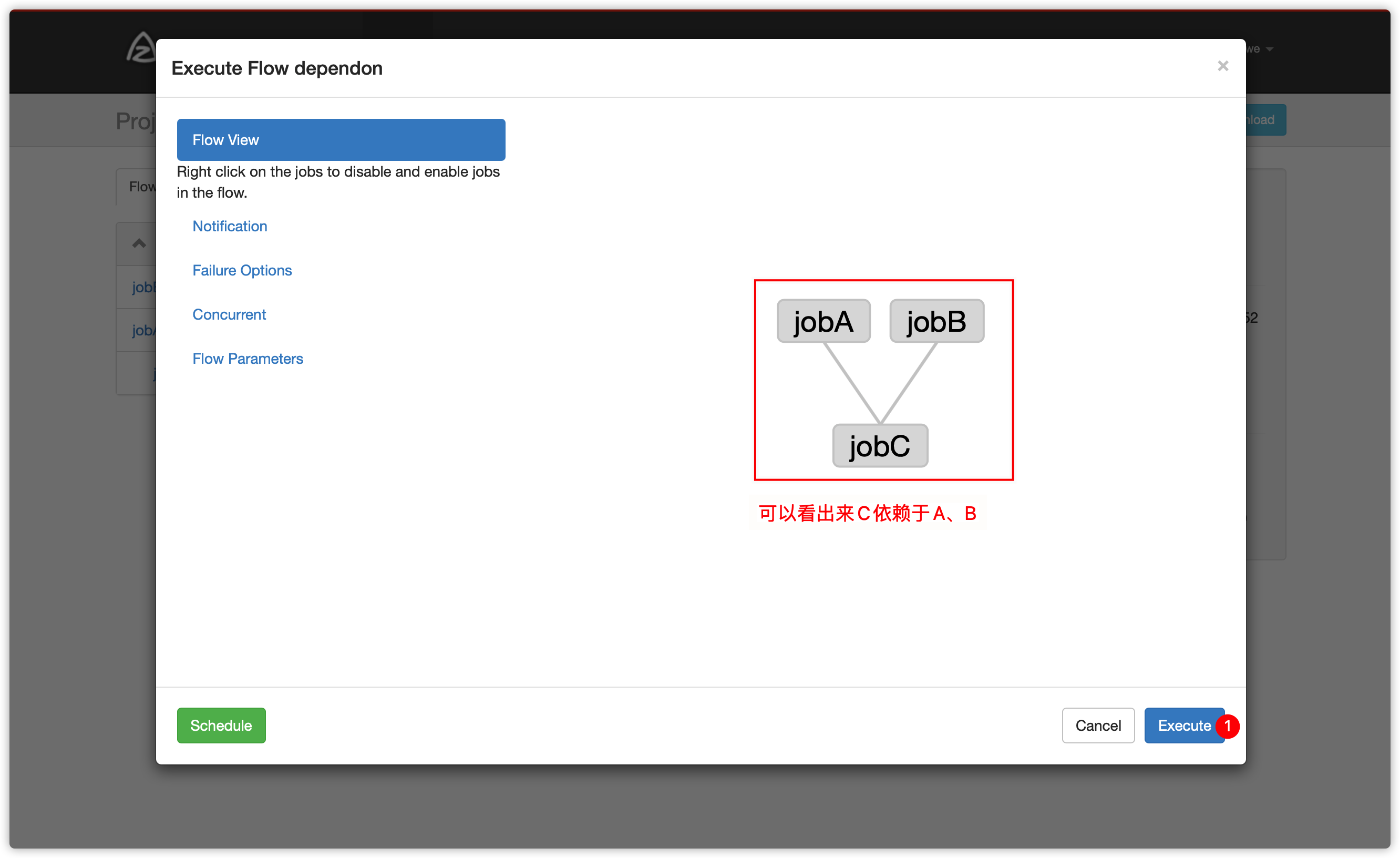
3. 包含多个有依赖关系job的flow
- job间可以相互依赖,创建flow文件
dependon.flow,内容如下
nodes:
- name: jobC
type: noop
# jobC depends on jobA and jobB
dependsOn:
- jobA
- jobB
- name: jobA
type: command
config:
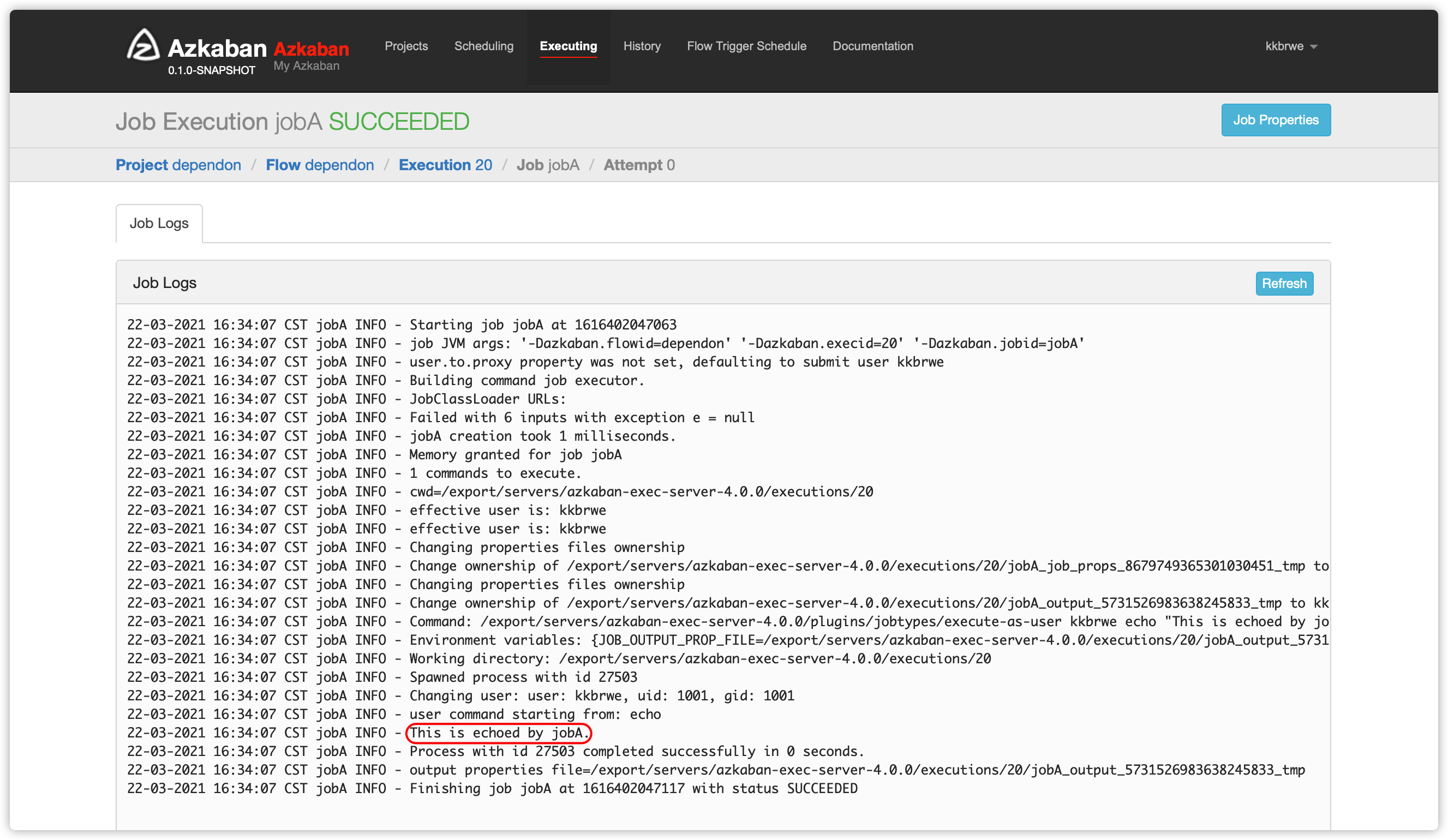
command: echo "This is echoed by jobA."
- name: jobB
type: command
config:
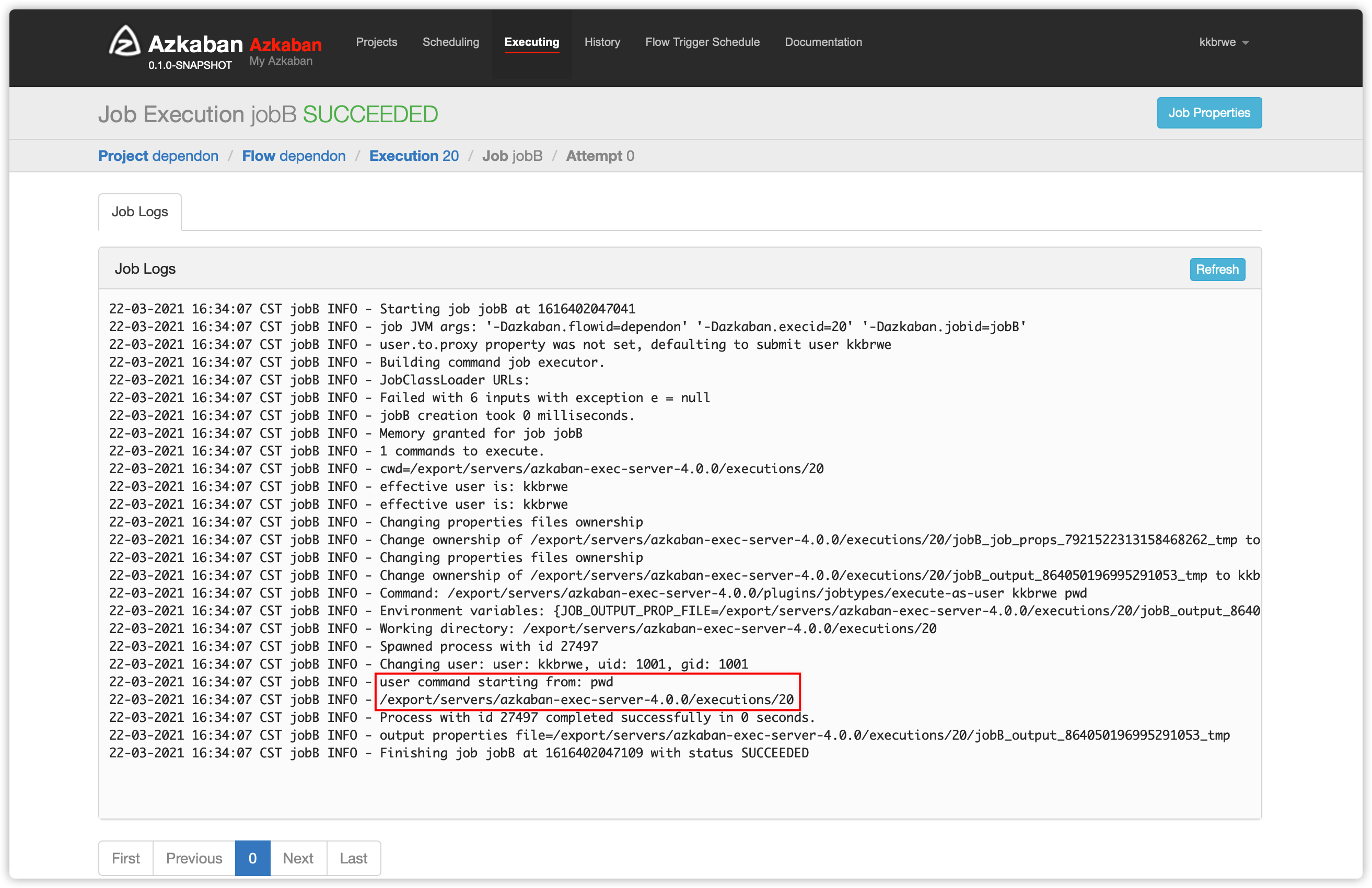
command: pwdjobC依赖jobA、jobB
Noop: A job that takes no parameters and is essentially a null operation. Used for organizing your graph
- 以下操作跟上边的例子
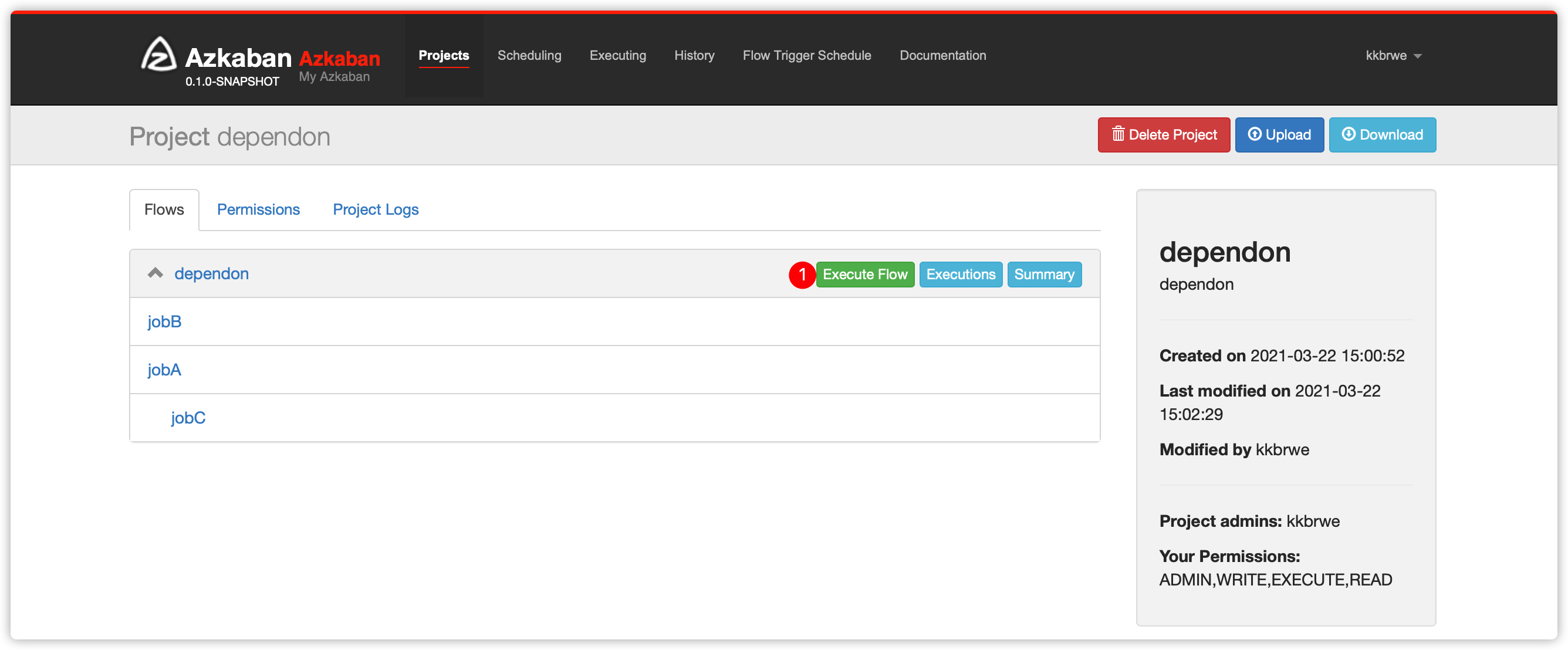
入门例子Hello World相似 dependon.flow与flow20.project压缩生成zip文件dependon.zip- web server ui界面创建项目,然后上传项目zip文件,然后执行,并查看
Job List及job日志
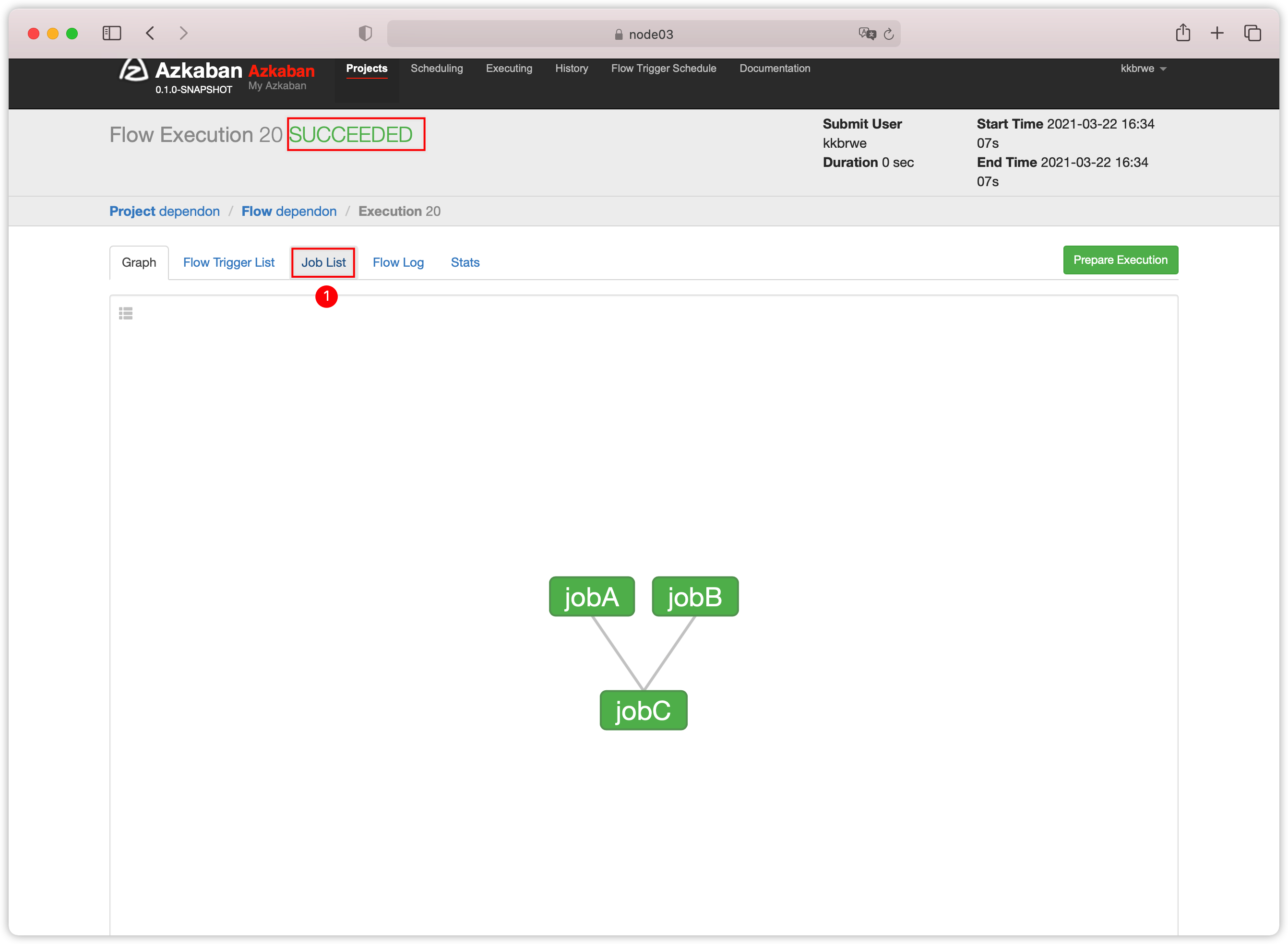
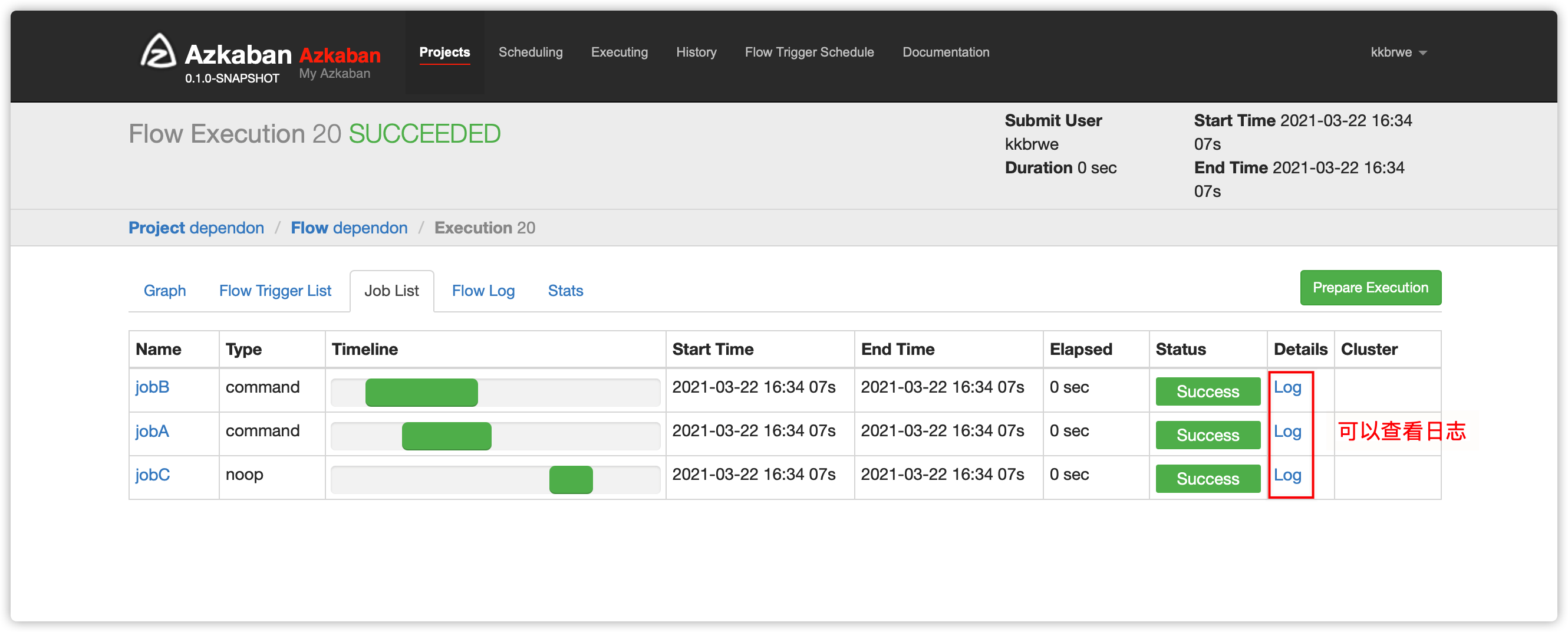
- 以下是
jobA日志
- 以下是
jobB日志
4. 自动失败重试案例
- 如果job执行失败,可以配置成自动重试若干次,每次重试时间间隔一定时长
nodes:
- name: JobA
type: command
config:
command: sh /a_non_exists.sh
retries: 3
retry.backoff: 3000说明:
/a_non_exists.sh是一个不存在的sh脚本
retries重试次数
retry.backoff每次重试的时间间隔,单位毫秒
-
以下操作跟上边的例子
入门例子Hello World相似 -
retry.flow与flow20.project压缩生成zip文件retry.zip -
web server ui界面创建项目,然后上传项目zip文件,然后执行,并查看
Job List及job日志 -
部分截图略
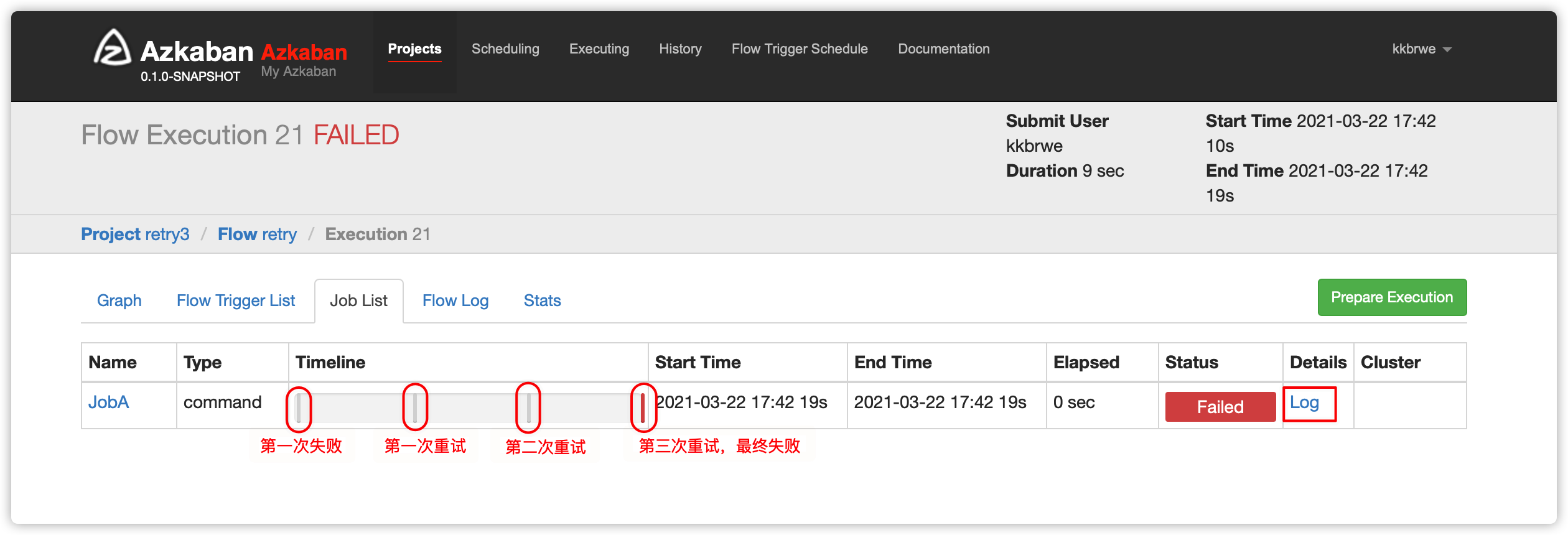
- 日志
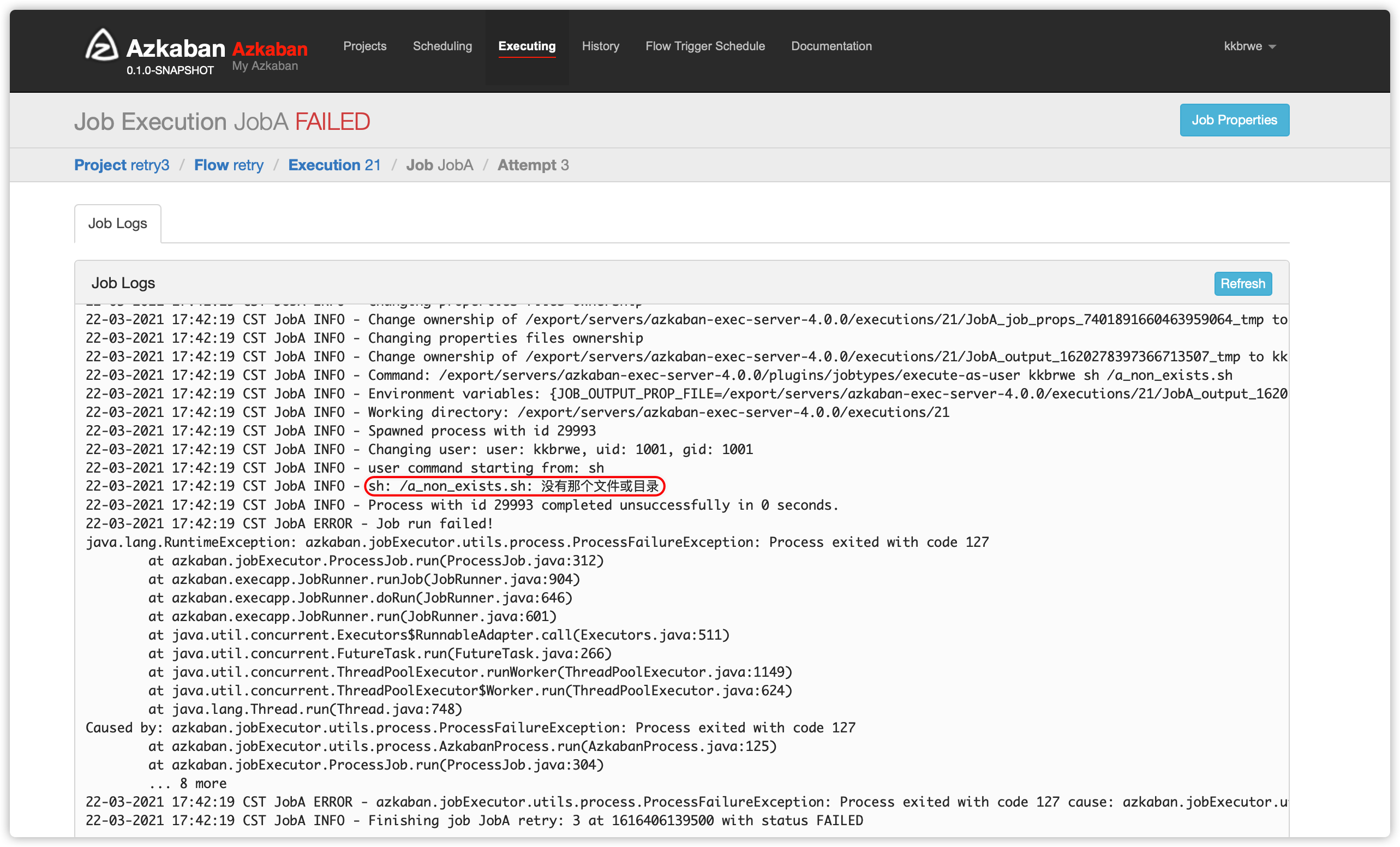
- 也可以在flow文件中,加入全局重试次数,此重试配置对flow文件中的所有job都生效;内容如下
config:
retries: 3
retry.backoff: 3000
nodes:
- name: JobA
type: command
config:
command: sh /a_non_exists.sh5. 手动失败重试案例
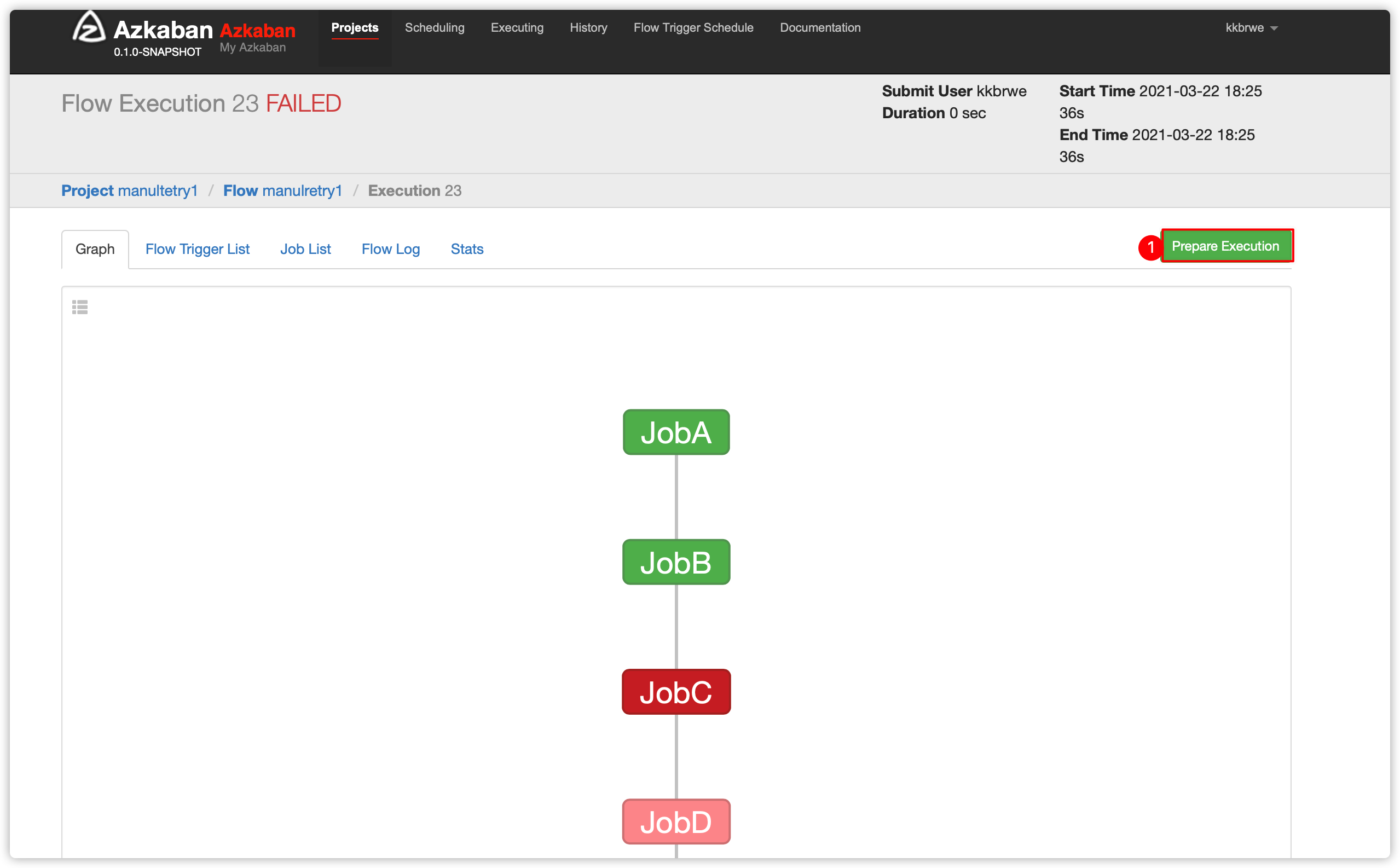
-
手动失败重试场景:
- 对于某些flow中的失败job,不能通过自动重试解决的,比如并非一些系统短时的问题,比如暂时的网络故障导致的超时、暂时的资源不足导致的执行失败
- 此时需要手动的做些处理后,然后再进行重新执行flow中job
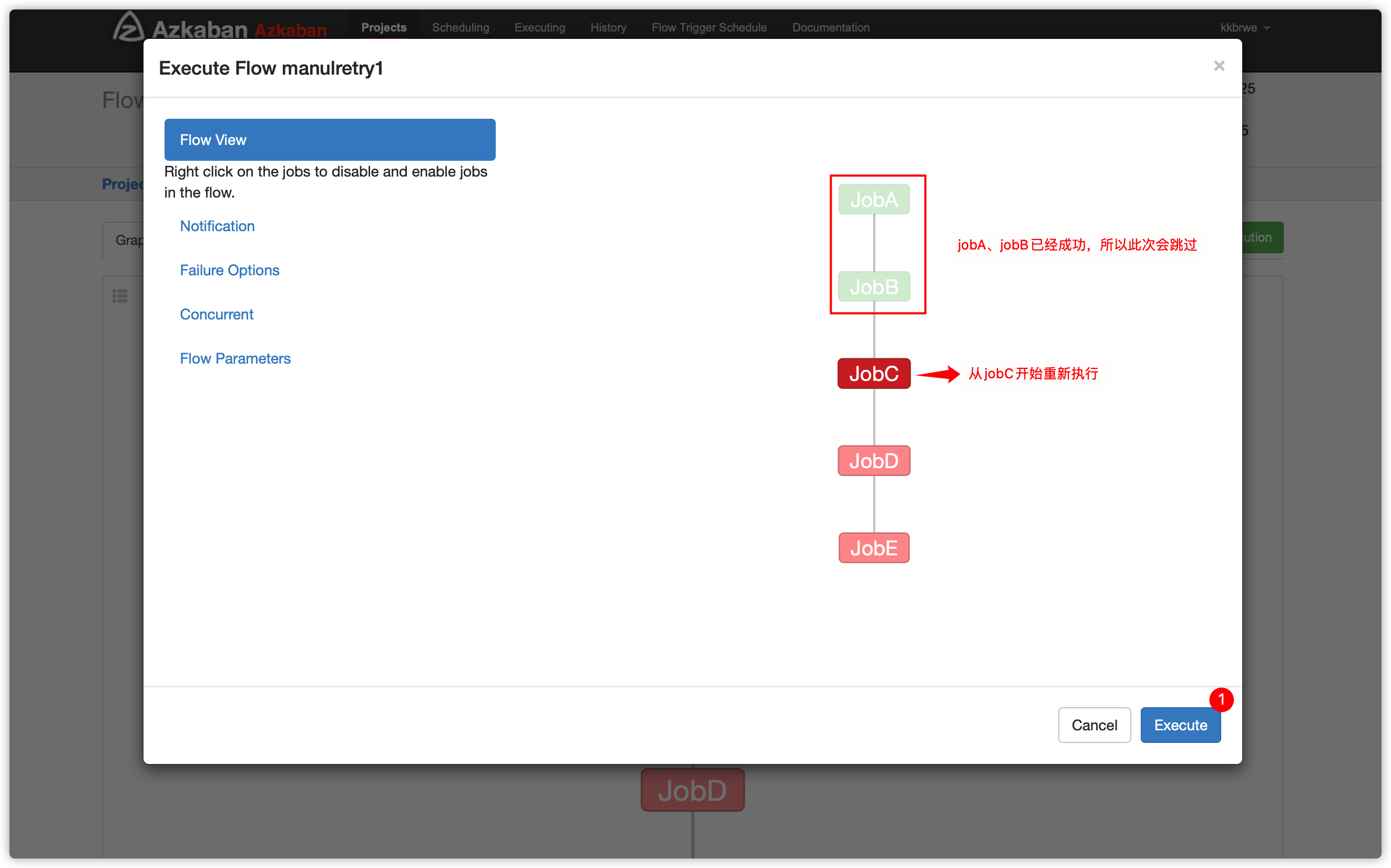
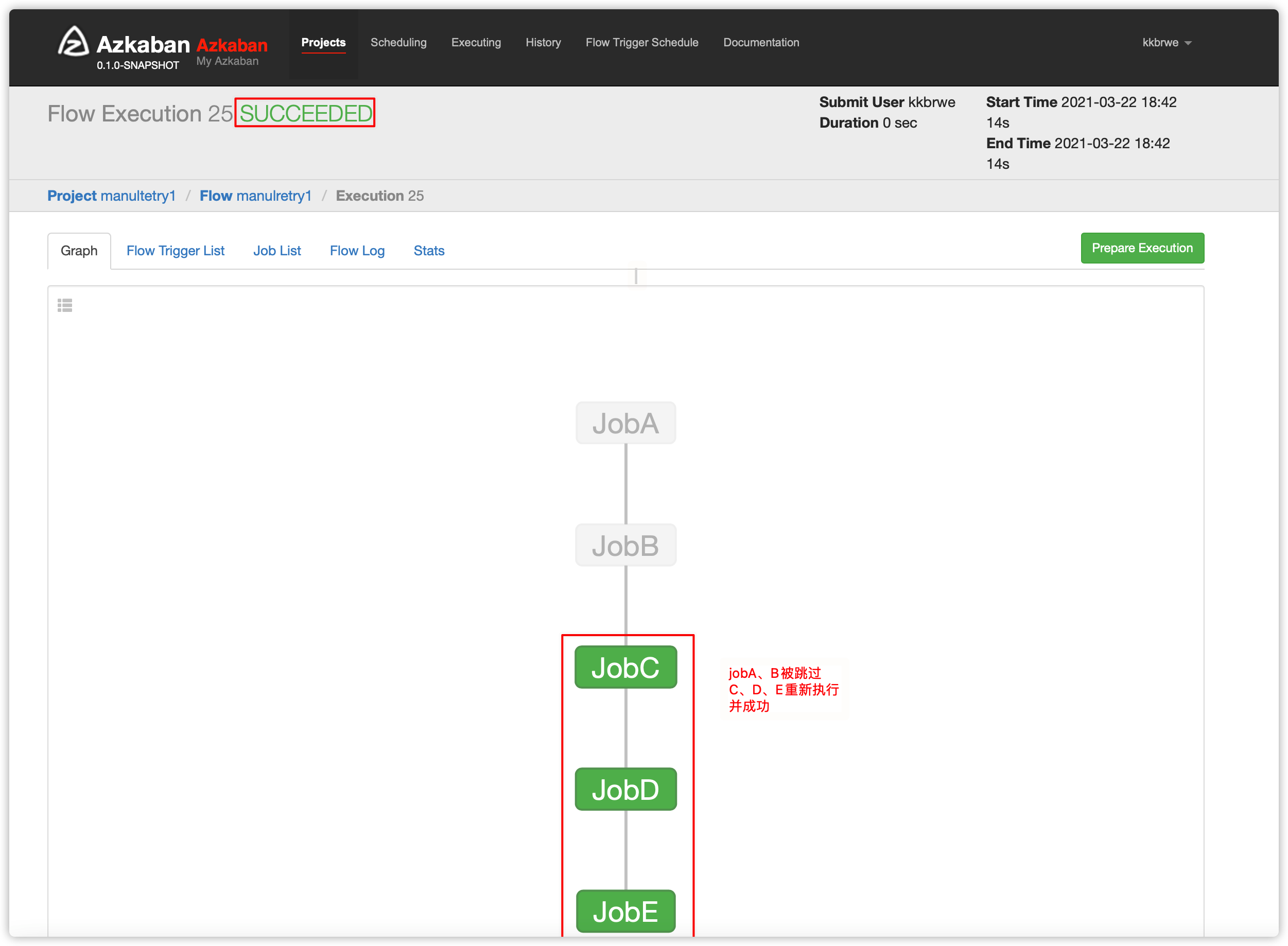
- 跳过成功的job
- 从失败的job开始执行
-
一个flow中,有5个job,有依赖关系如下
- jobE依赖jobD;
- jobD依赖jobC;
- jobC依赖jobB
- jobB依赖jobA
-
创建flow文件
manulretry.flow内容如下
nodes:
- name: JobA
type: command
config:
command: echo "This is JobA."
- name: JobB
type: command
dependsOn:
- JobA
config:
command: echo "This is JobB."
- name: JobC
type: command
dependsOn:
- JobB
config:
command: sh /export/servers/azkaban-exec-server-4.0.0/tmp.sh
- name: JobD
type: command
dependsOn:
- JobC
config:
command: echo "This is JobD."
- name: JobE
type: command
dependsOn:
- JobD
config:
command: echo "This is JobE."- 压缩生成zip包、web ui创建项目、上传zip、执行flow
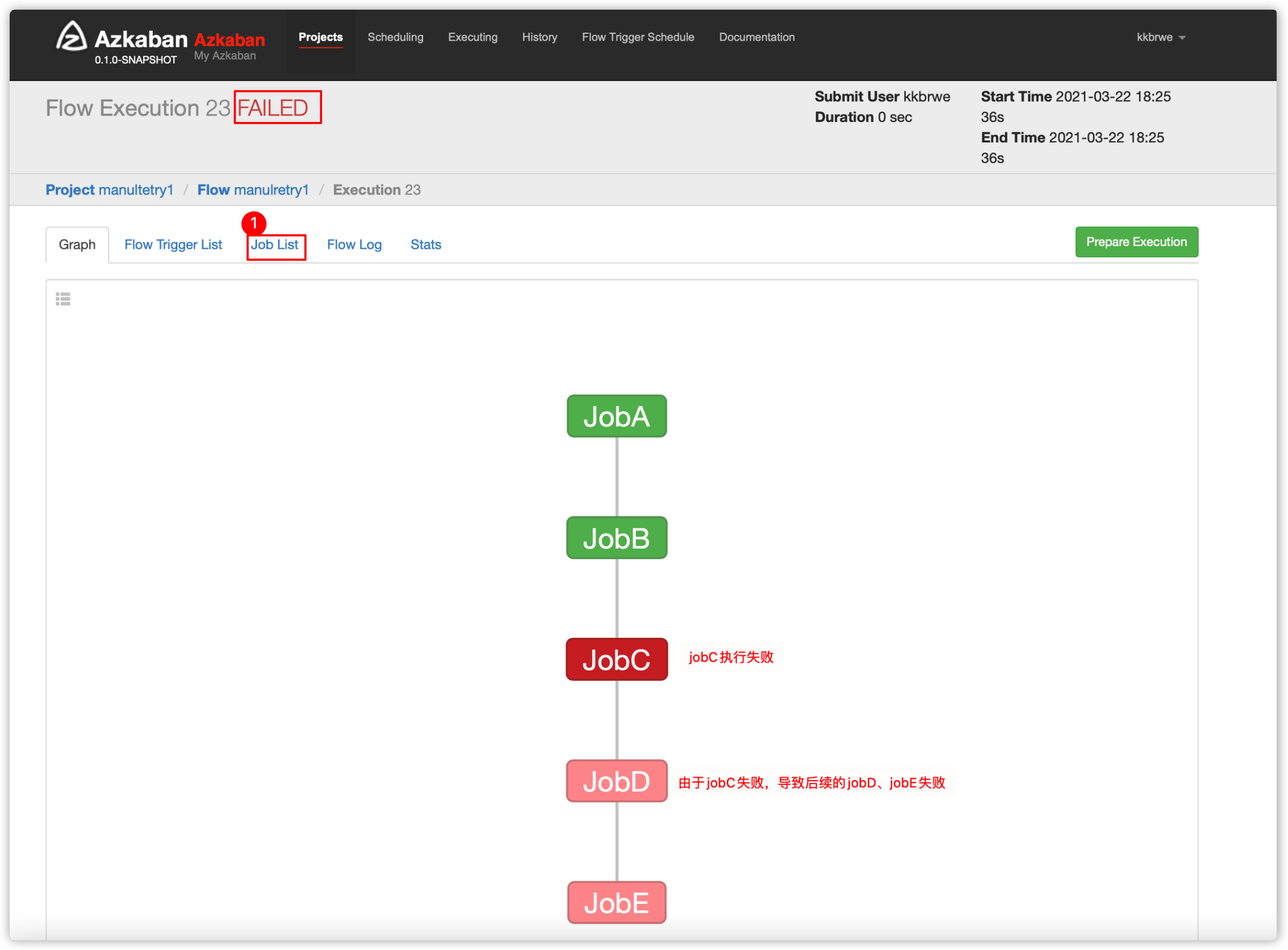
- 查看jobC的日志
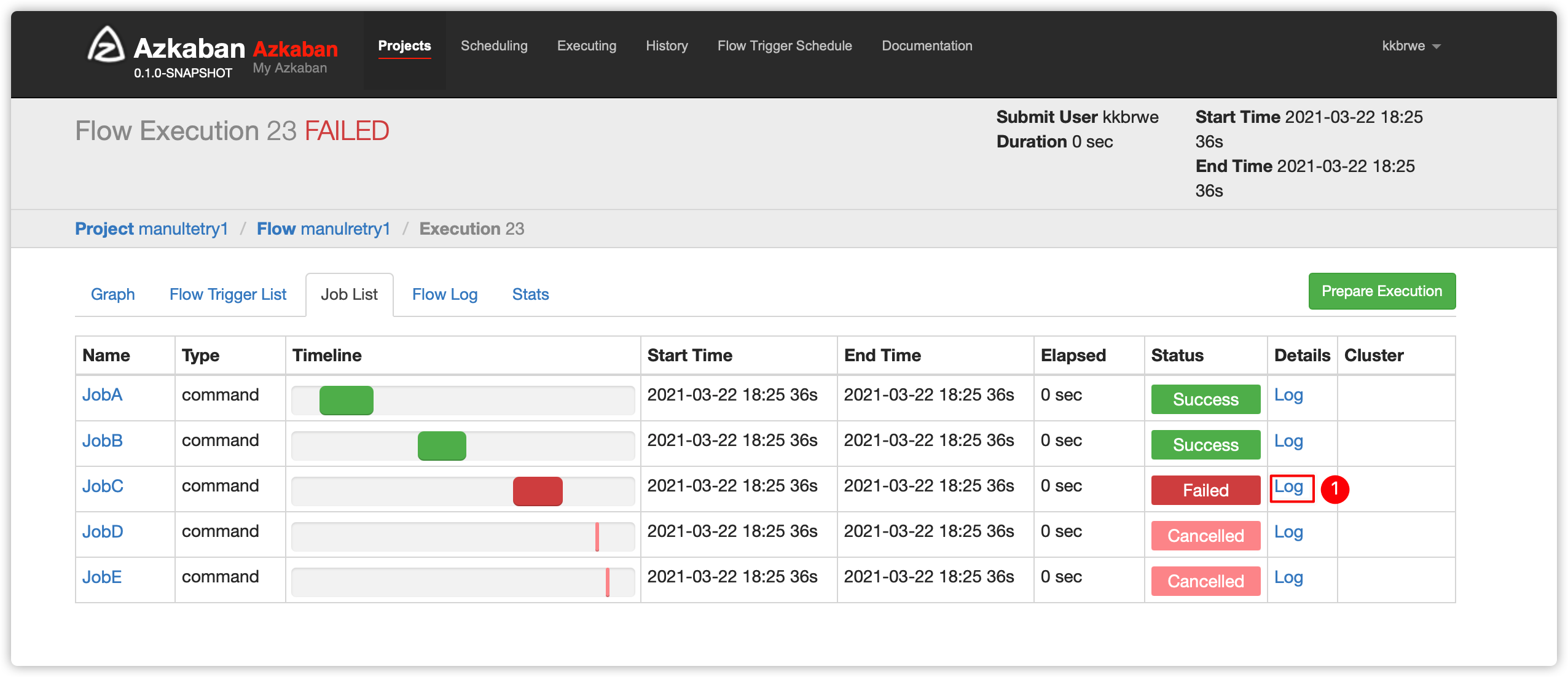
- 原因是没有找到下图的sh脚本文件
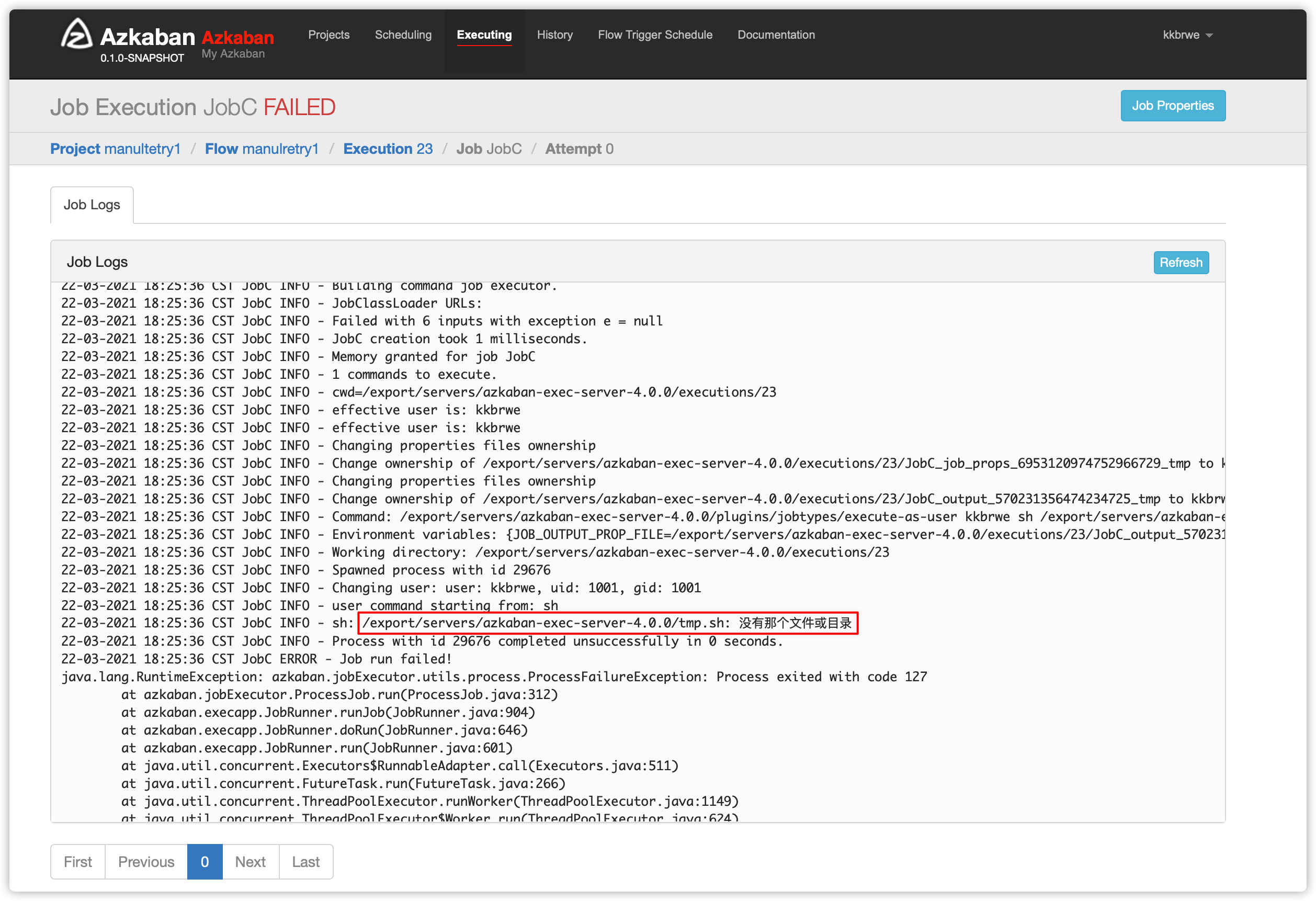
-
那么在对应的exec server的对应目录下创建此sh脚本文件
- 由于不确定,flow重试时,web选择哪个exec执行flow,所以保险起见,有两个方法
- 方法一:在3个exec节点中都创建tmp.sh脚本
[hadoop@node01 azkaban-exec-server-4.0.0]$ cd [hadoop@node01 ~]$ cd /export/servers/azkaban-exec-server-4.0.0 [hadoop@node01 azkaban-exec-server-4.0.0]$ vim tmp.sh [hadoop@node02 azkaban-exec-server-4.0.0]$ cd [hadoop@node02 ~]$ cd /export/servers/azkaban-exec-server-4.0.0 [hadoop@node02 azkaban-exec-server-4.0.0]$ vim tmp.sh [hadoop@node03 azkaban-exec-server-4.0.0]$ cd [hadoop@node03 ~]$ cd /export/servers/azkaban-exec-server-4.0.0 [hadoop@node03 azkaban-exec-server-4.0.0]$ vim tmp.sh- 脚本内容如下
#!/bin/bash echo 'this is echoed by tmp sh script'- 方法二:重试flow时,指定执行的executor(此处暂略,下文会提到用法)
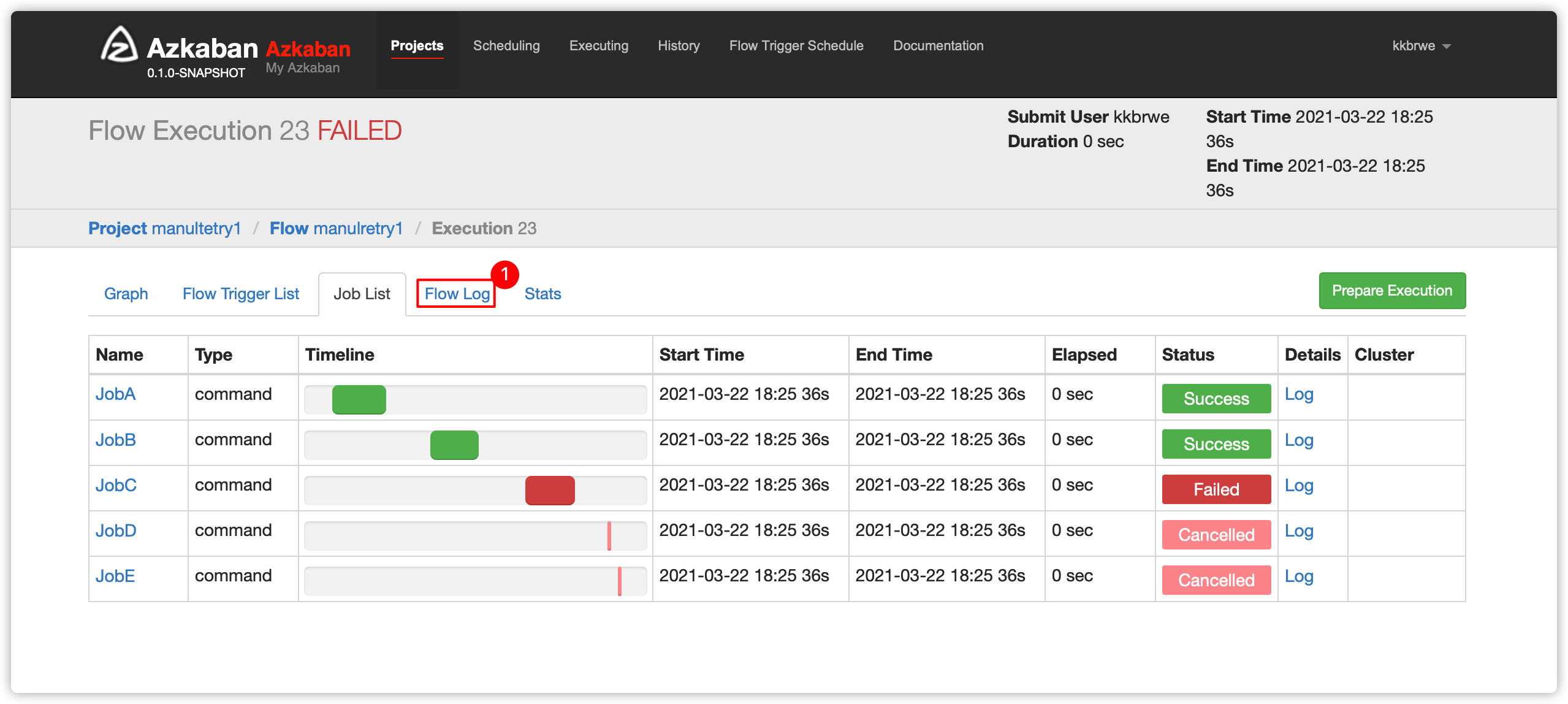
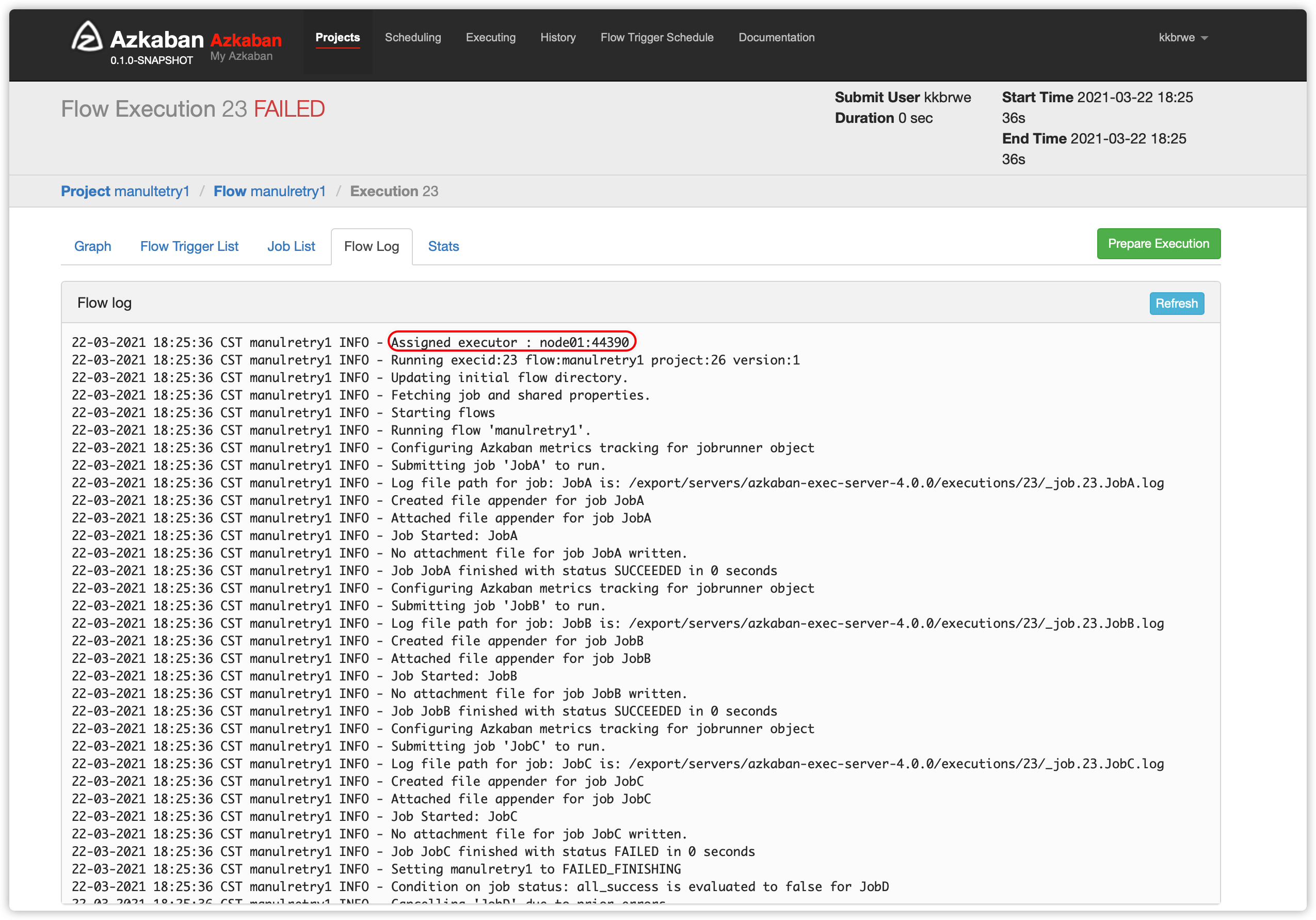
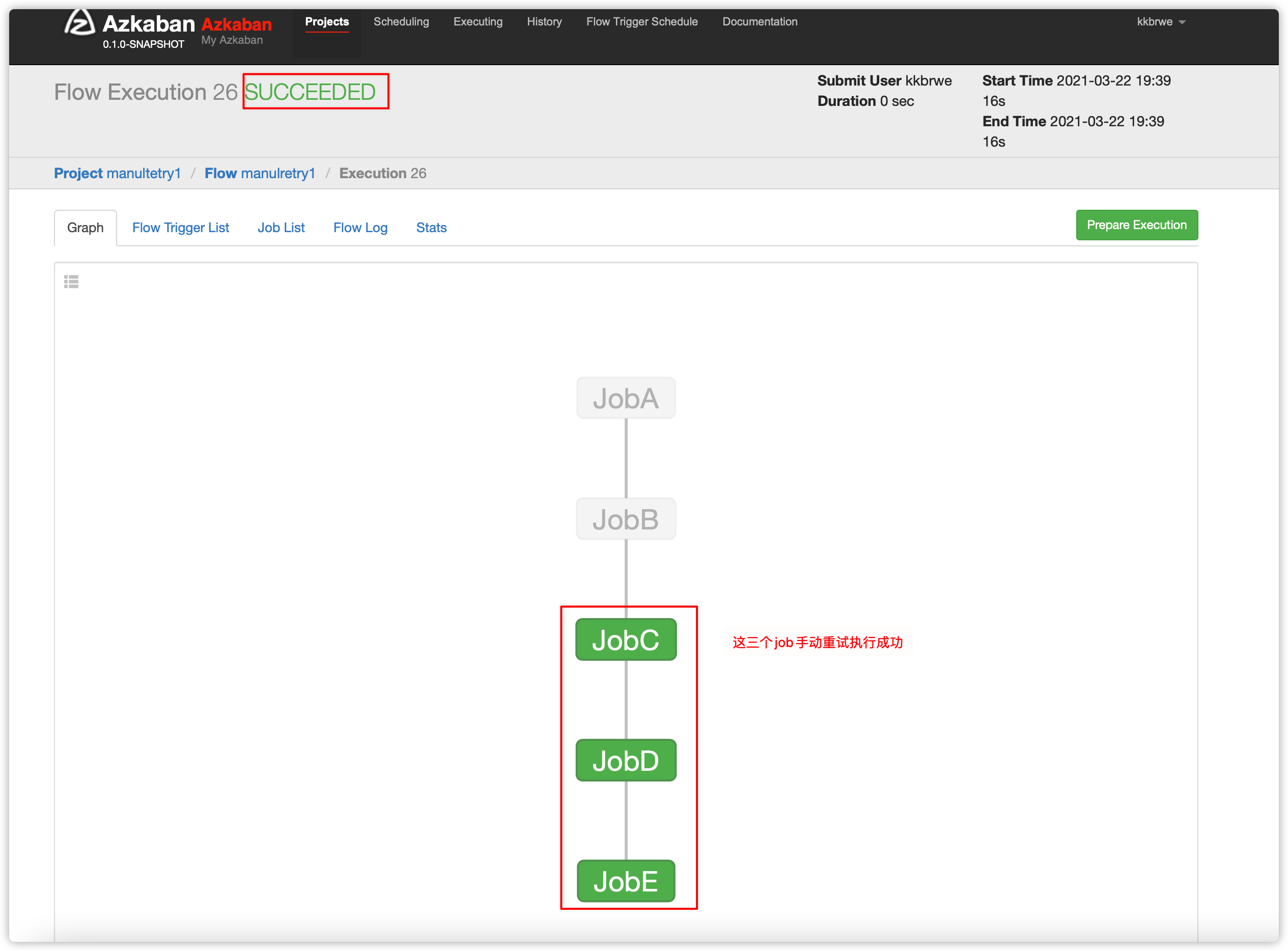
- 手动重试有两个方案
1、方案一
2、方案二
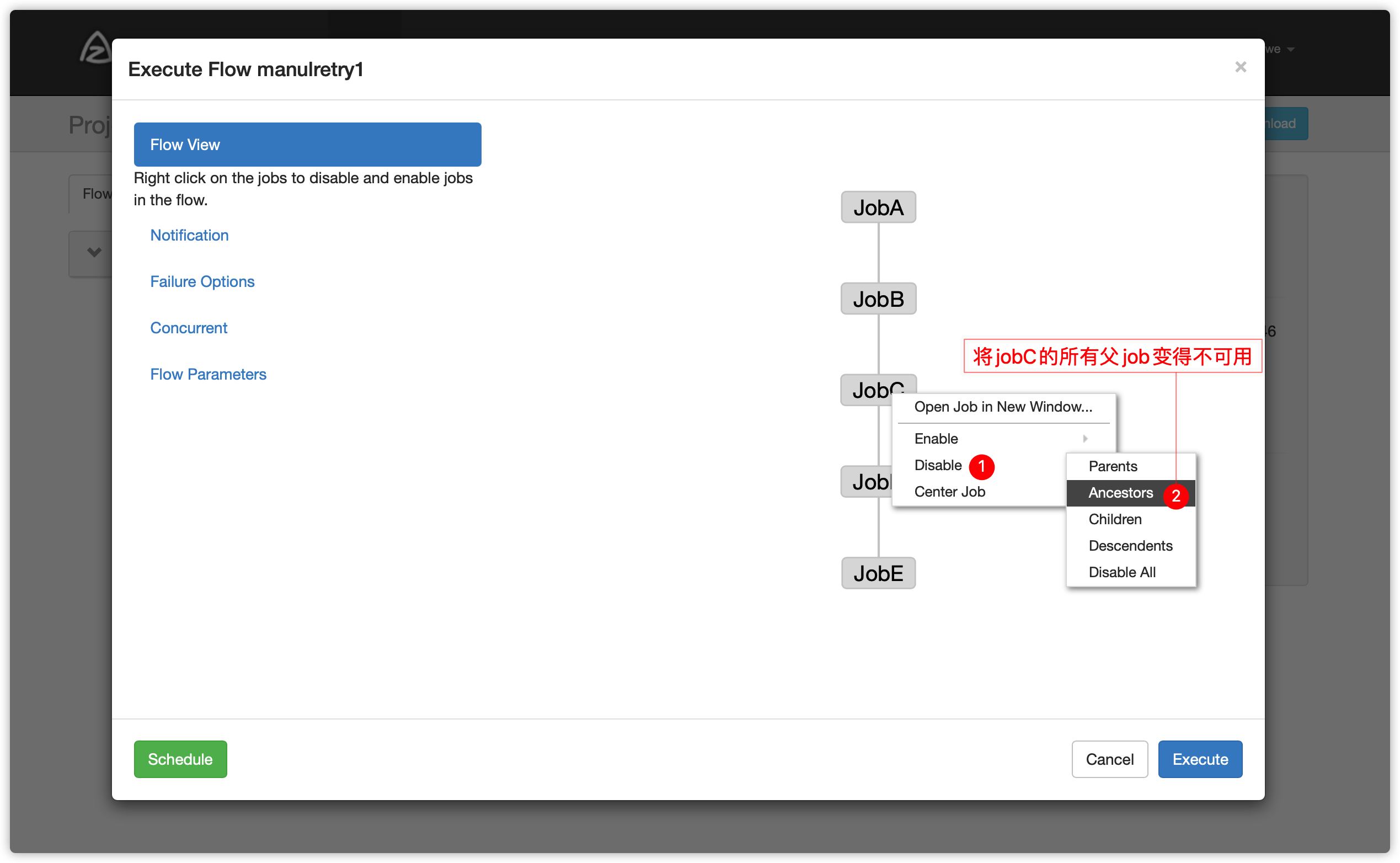
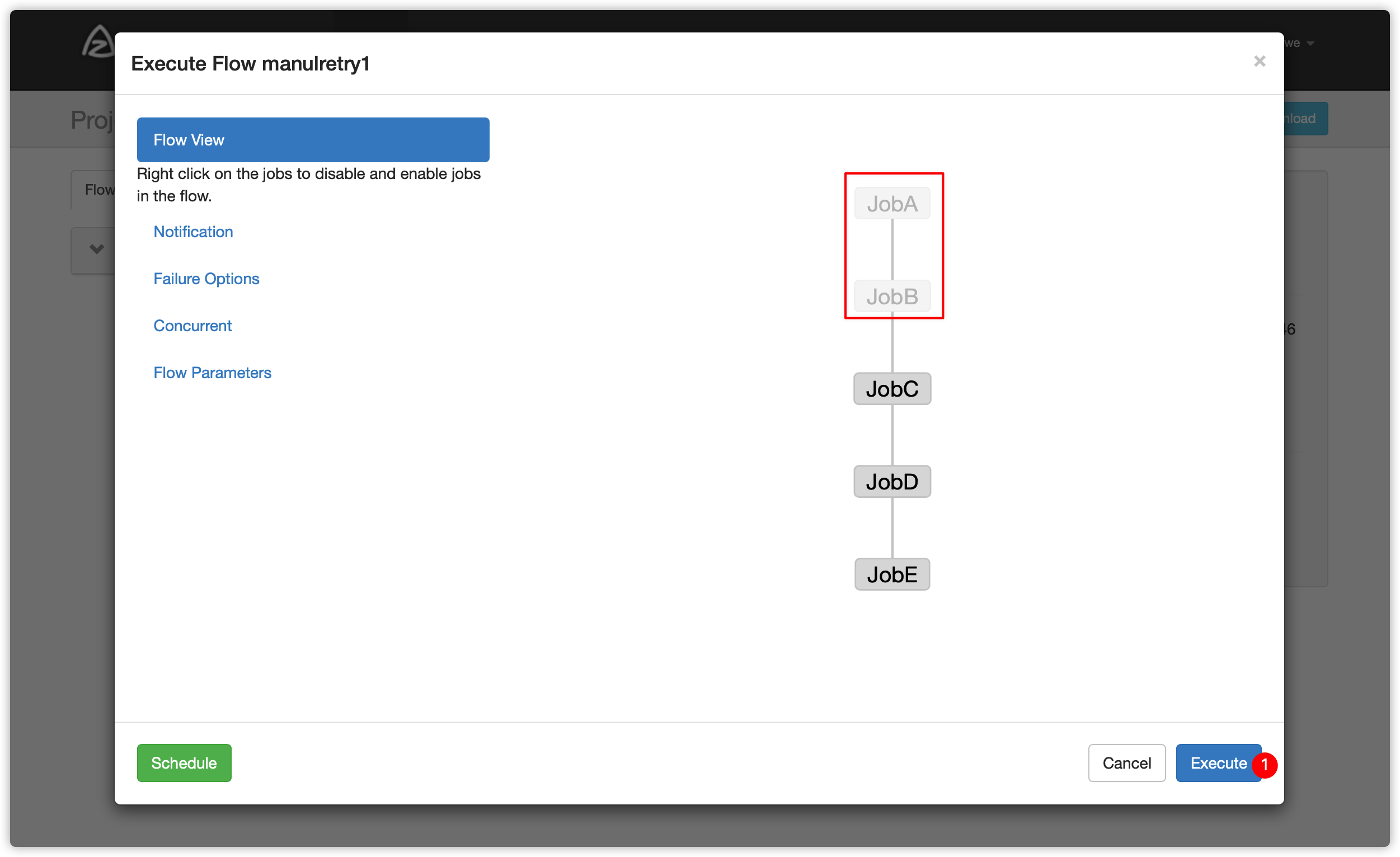
Enable 和 Disable 下面都分别有如下参数:
Parents:该作业的上一个job
Ancestors:该作业前的所有job
Children:该作业后的一个job
Descendents:该作业后的所有job
Enable All: 所有的job
- 可以根据实际情况选择enable方案
6. 操作HDFS
- node01节点用root用户启动hadoop集群
[hadoop@node01 bin]$ su root
密码:
[root@node01 bin]#
[root@node01 bin]# cd
[root@node01 ~]# start-all.sh- 编写flow文件
operateHdfs.flow,内容如下
nodes:
- name: jobA
type: command
config:
command: echo "start execute"
command.1: /export/servers/hadoop-2.7.5/bin/hdfs dfs -mkdir /azkaban
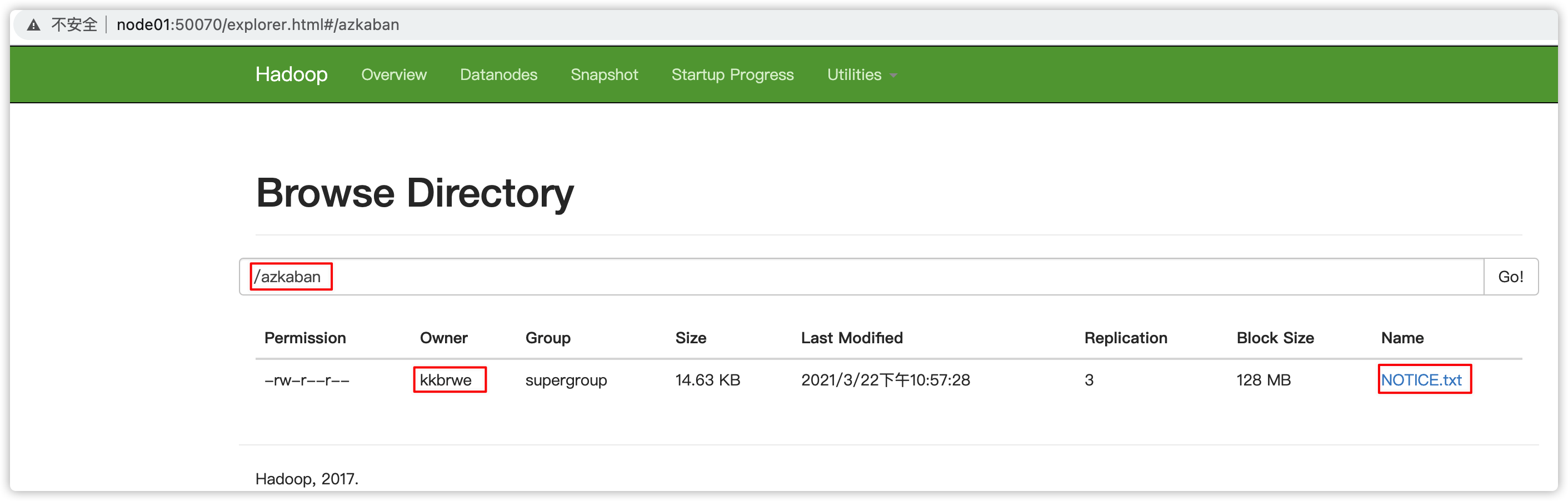
command.2: /export/servers/hadoop-2.7.5/bin/hdfs dfs -put /export/servers/hadoop-2.7.5/NOTICE.txt /azkaban- 生成zip项目文件、web ui上传zip、执行flow
- 查看HDFS结果
7. MR任务
- 记得启动hadoop的
historyserver,否则执行mr项目时,job的日志会报如下类似错误日志
22-03-2021 23:17:23 CST jobMR INFO - 21/03/22 23:17:23 INFO impl.YarnClientImpl: Submitted application application_1616423563192_0001
22-03-2021 23:17:39 CST jobMR INFO - 21/03/22 23:17:39 INFO mapred.ClientServiceDelegate: Application state is completed. FinalApplicationStatus=SUCCEEDED. Redirecting to job history server
22-03-2021 23:17:41 CST jobMR INFO - 21/03/22 23:17:41 INFO ipc.Client: Retrying connect to server: node01/192.168.77.30:10020. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
22-03-2021 23:17:42 CST jobMR INFO - 21/03/22 23:17:42 INFO ipc.Client: Retrying connect to server: node01/192.168.77.30:10020. Already tried 1 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
22-03-2021 23:17:44 CST jobMR INFO - 21/03/22 23:17:44 INFO ipc.Client: Retrying connect to server: node01/192.168.77.30:10020. Already tried 2 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
192.168.77.30:10020 应该是hadoop集群的historyserver服务
- 编写flow文件
mr.flow,内容如下
nodes:
- name: jobMR
type: command
config:
command: /export/servers/hadoop-2.7.5/bin/hadoop jar /export/servers/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar pi 3 3- 为了避免执行mr过程中,对hdfs操作的一些权限问题
[hadoop@node01 azkaban-exec-server-4.0.0]$ su root
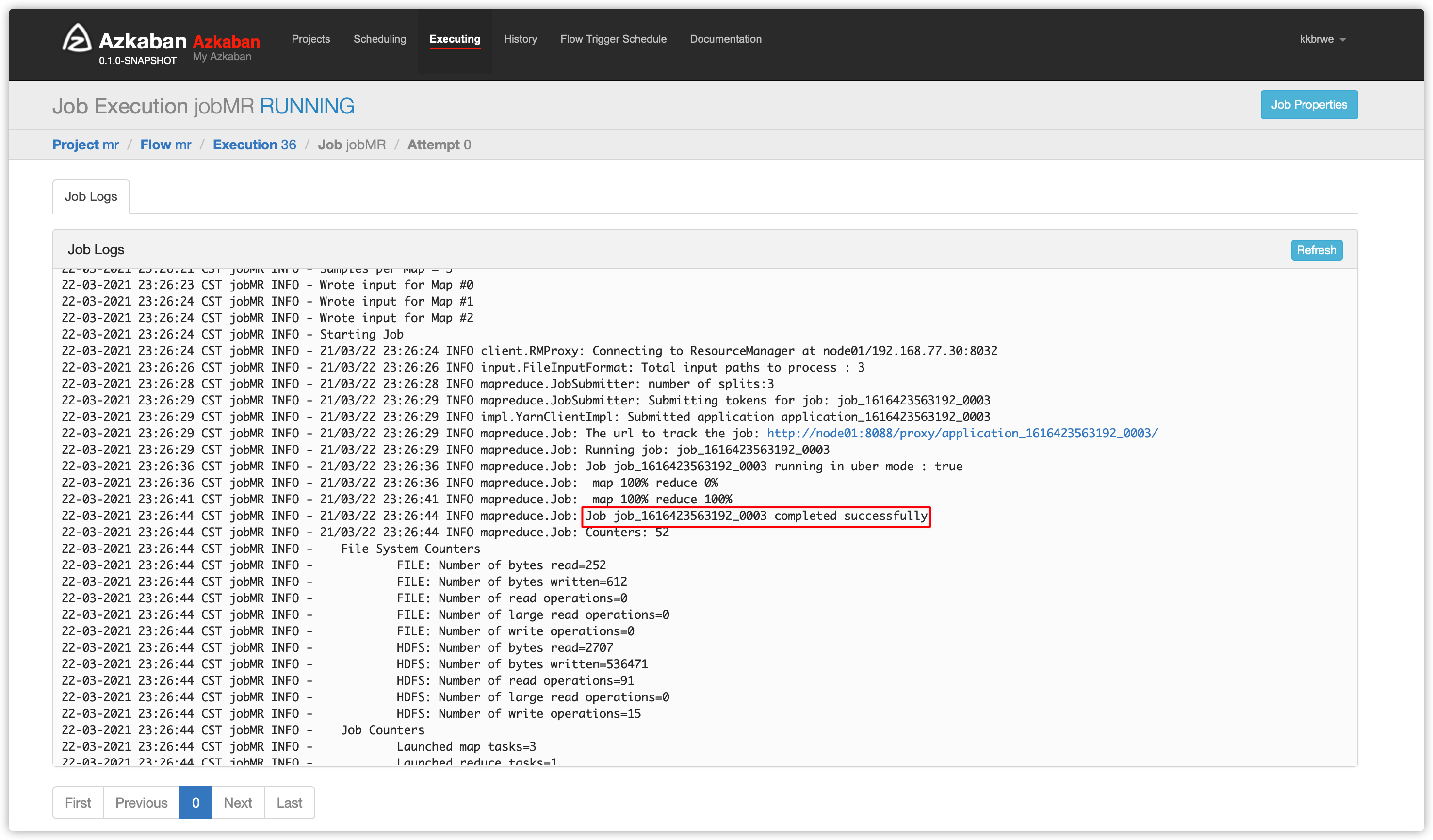
[root@node01 azkaban-exec-server-4.0.0]# hdfs dfs -chmod -R 777 /tmp/- 生成zip项目文件、web ui上传zip、执行flow
- 查看结果
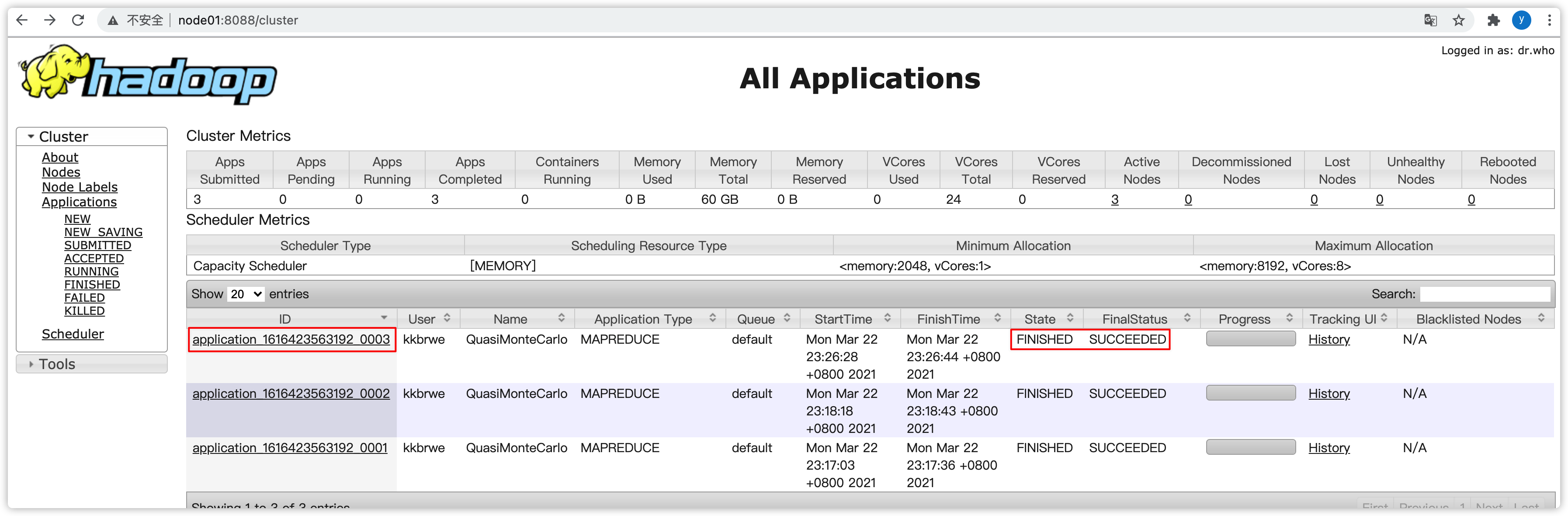
- 可以去yarn界面看看此job的执行情况
8. Hive任务
- 编写hive脚本文件
hive.sql,内容如下
create database if not exists azhive;
use azhive;
create table if not exists aztest(id string,name string) row format delimited fields terminated by '\t';- flow文件
hive.flow内容如下
nodes:
- name: jobHive
type: command
config:
command: /export/servers/apache-hive-3.1.2/bin/hive -f 'hive.sql'- 利用
hive.sql、hive.flow、flow20.project生成zip项目文件、web ui上传zip、执行flow
1、自动选择exec执行失败
- 部分截图如下
- 执行失败
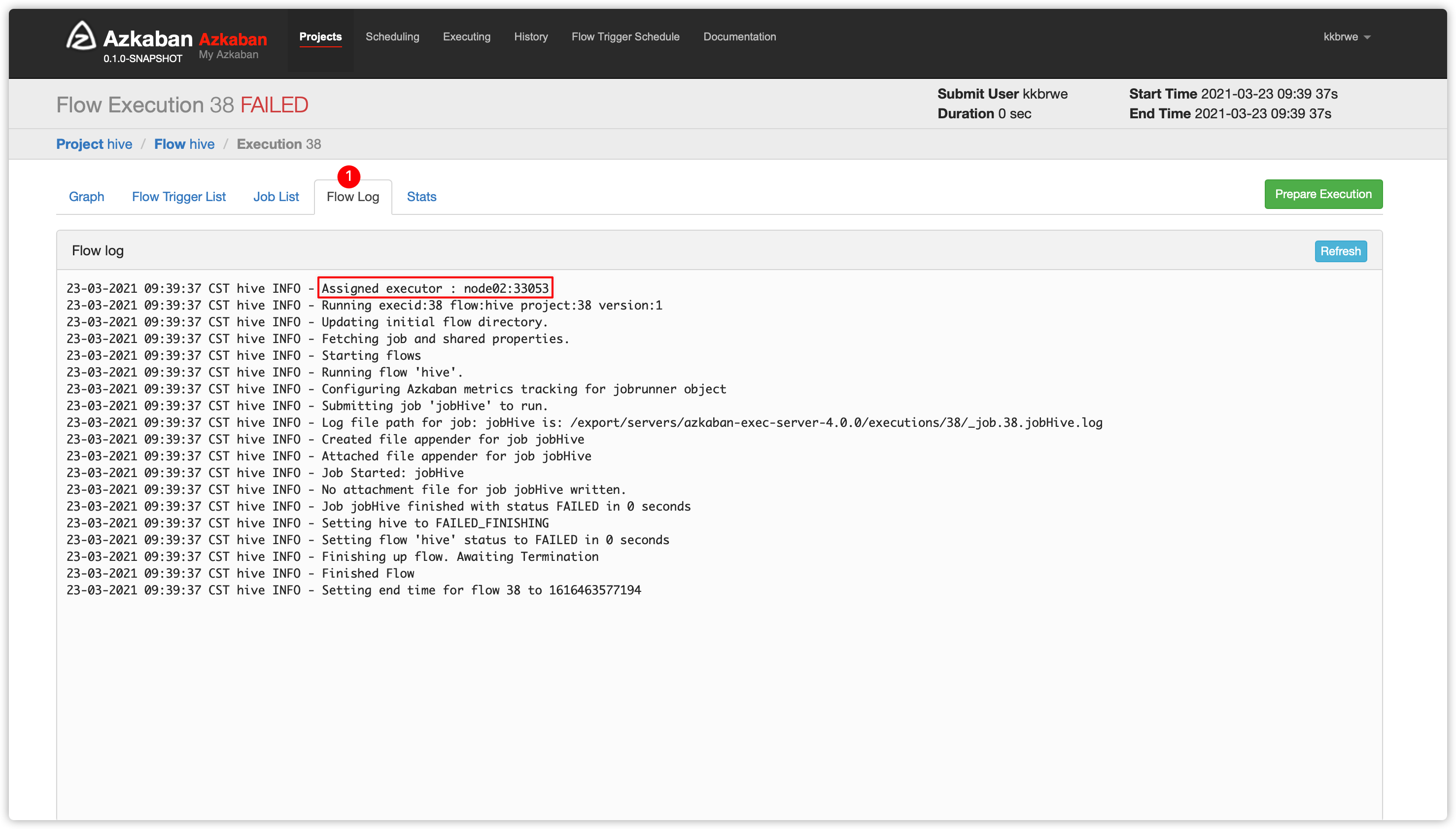
- 查看
Flow Log,发现选择的executor是node02;而node02上没有安装hive
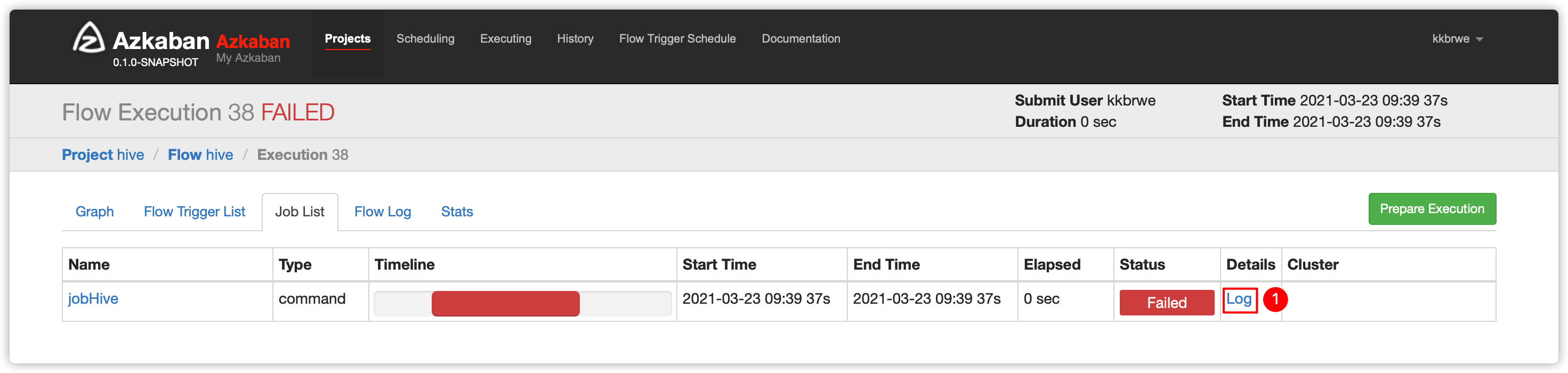
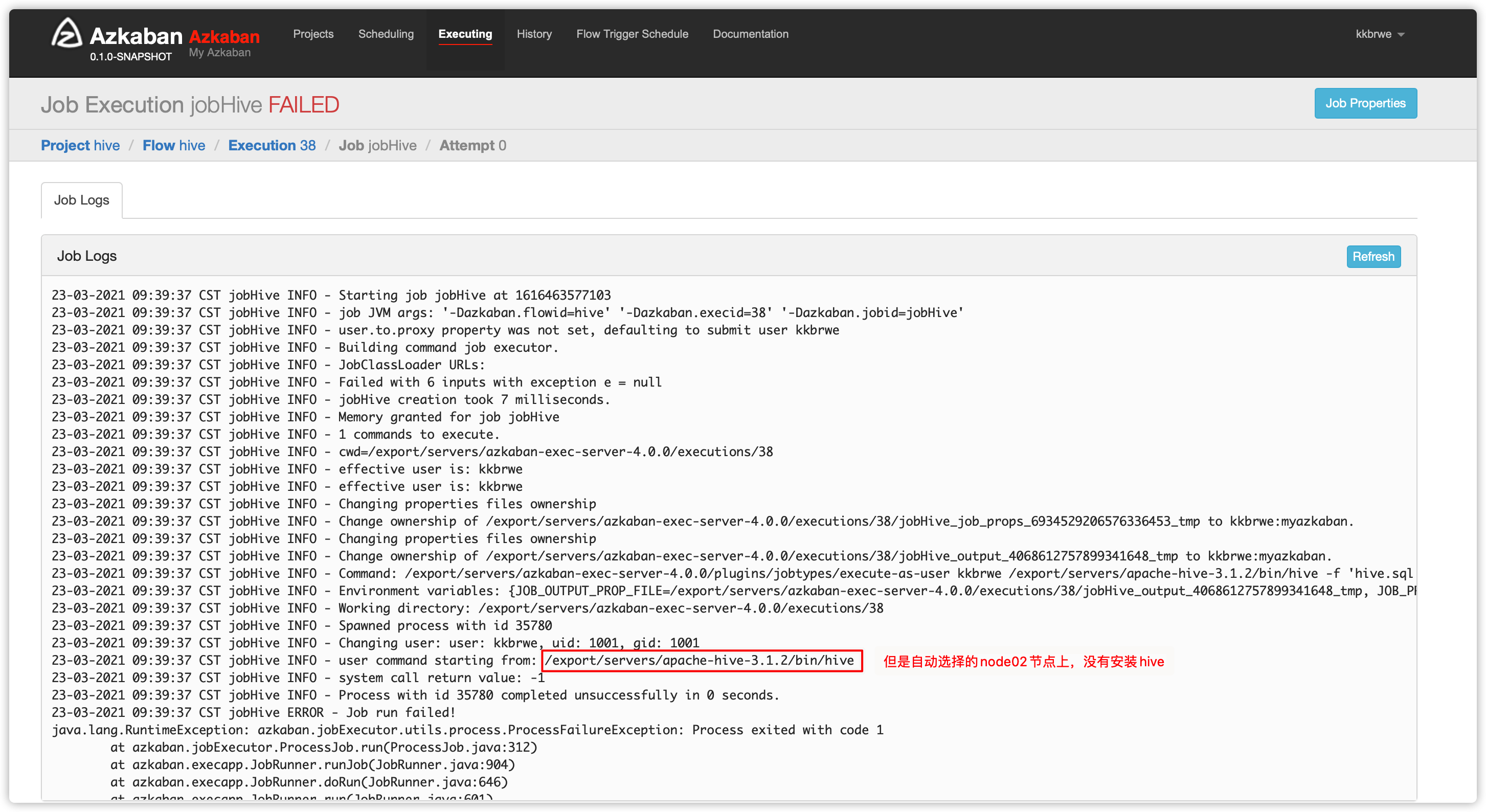
- 所以最终执行失败
2、解决方案:指定executor
- 官网提供说明:要指定执行flow的executor的话,azkaban用户必须拥有admin权限
- 我们在安装azkaban web服务时,在文件中指定创建了拥有ADMIN权限的用户
kkbadmin
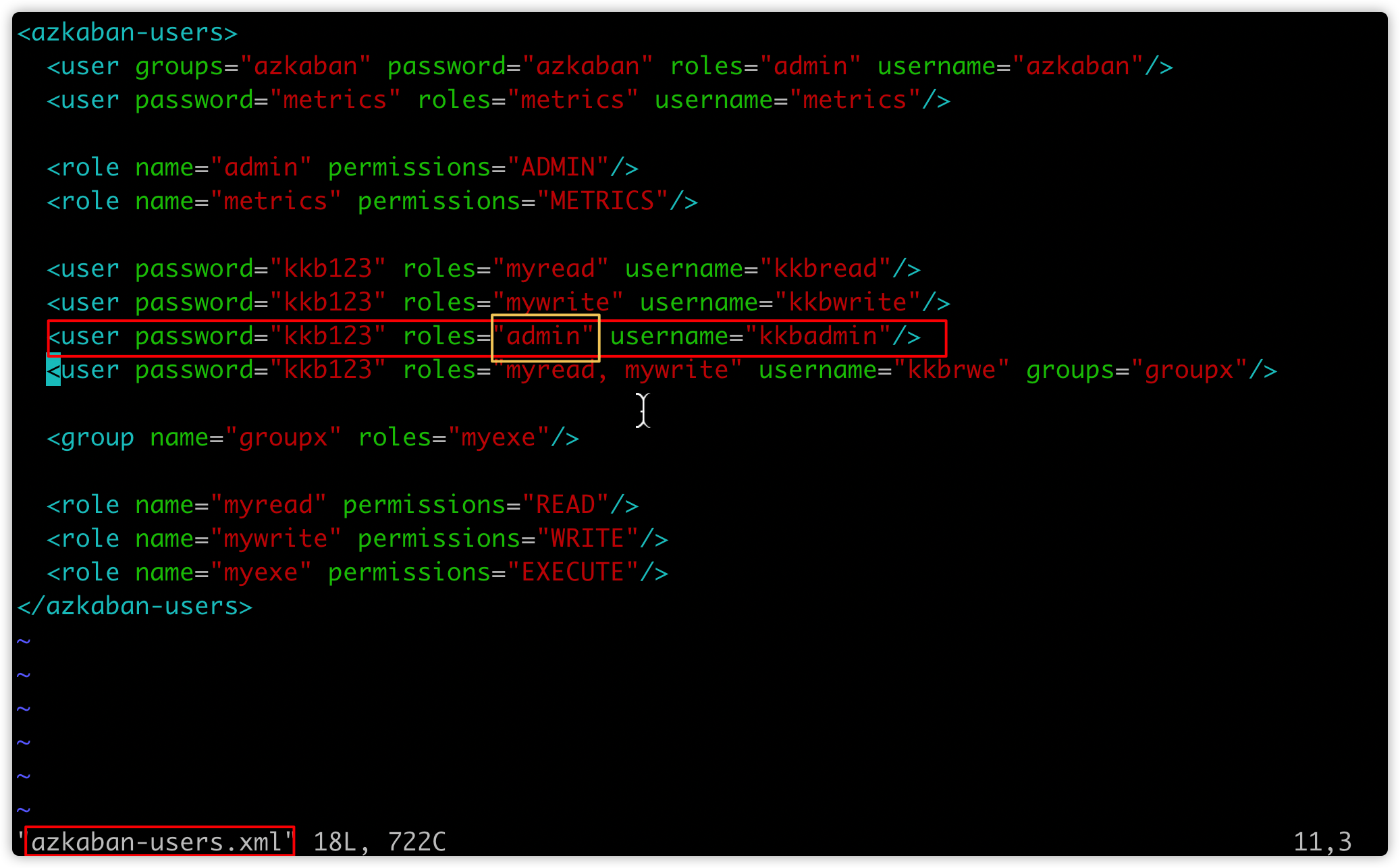
- 接下来我们想用
kkbadmin登录azkaban,并指定执行executor是node03(安装了hive的机器) - 那么,在此之前,得在node03创建用户
kkbadmin,并且此用户属于node03的linux用户组myazkaban(参考创建kkbrwe的做法即可)
[hadoop@node03 ~]$ sudo groupadd kkbadmin
[sudo] hadoop 的密码:
[hadoop@node03 ~]$ sudo useradd -g myazkaban kkbadmin
[hadoop@node03 ~]$ sudo passwd kkbadmin
更改用户 kkbadmin 的密码 。
新的 密码:123456
无效的密码: 密码少于 8 个字符
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
# 将kkbadmin添加附加用户组
[hadoop@node03 ~]$ sudo usermod -a -G hadoop kkbadmin
# 查看用户kkbadmin
[hadoop@node03 ~]$ sudo id kkbadmin
uid=1002(kkbadmin) gid=1001(myazkaban) 组=1001(myazkaban),1000(hadoop)- 如何解决?
- 运行前,因为
kkbrwe没有ADMIN权限,所以先退出登录web ui界面 - 使用
kkbadmin登录web ui界面 - 创建项目、上传zip、执行flow并指定executor服务器是node03节点(安装了hive的节点)
- 运行前,因为
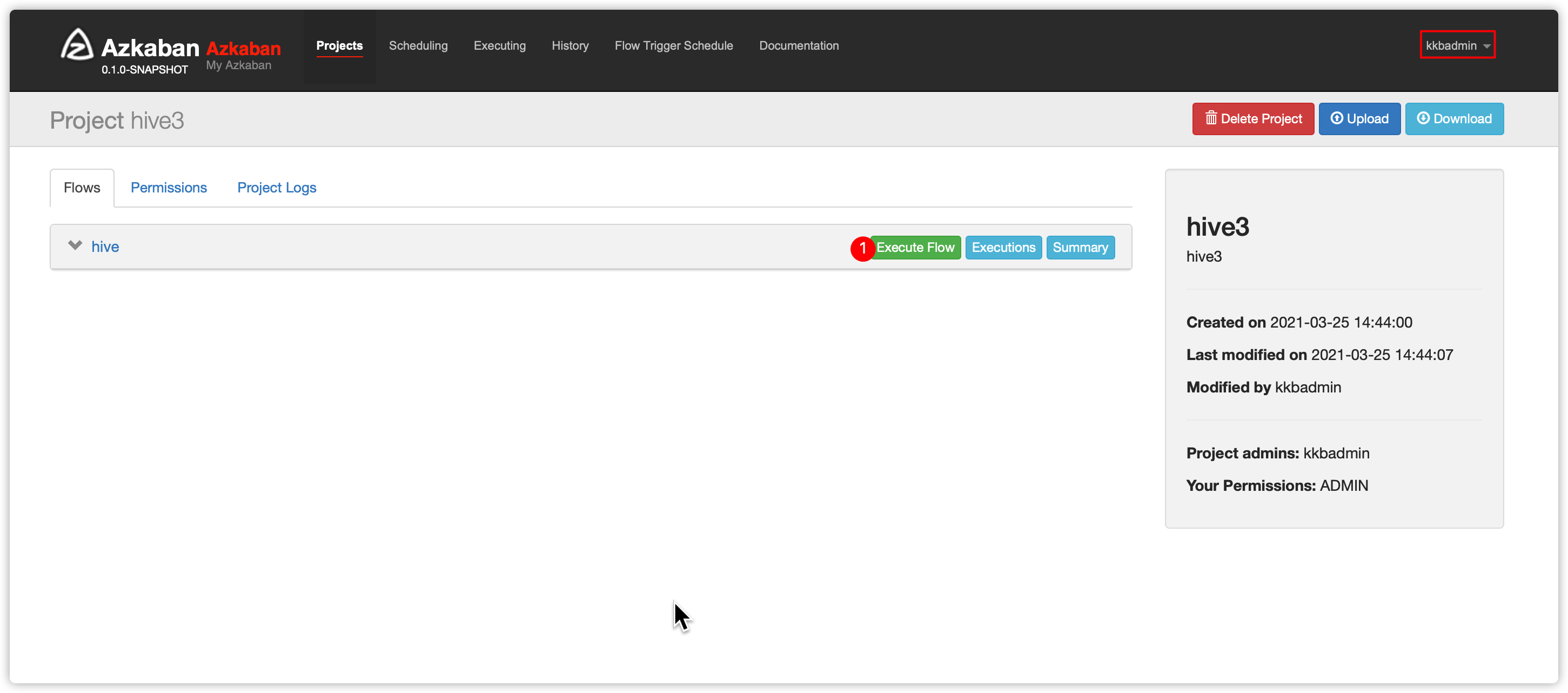
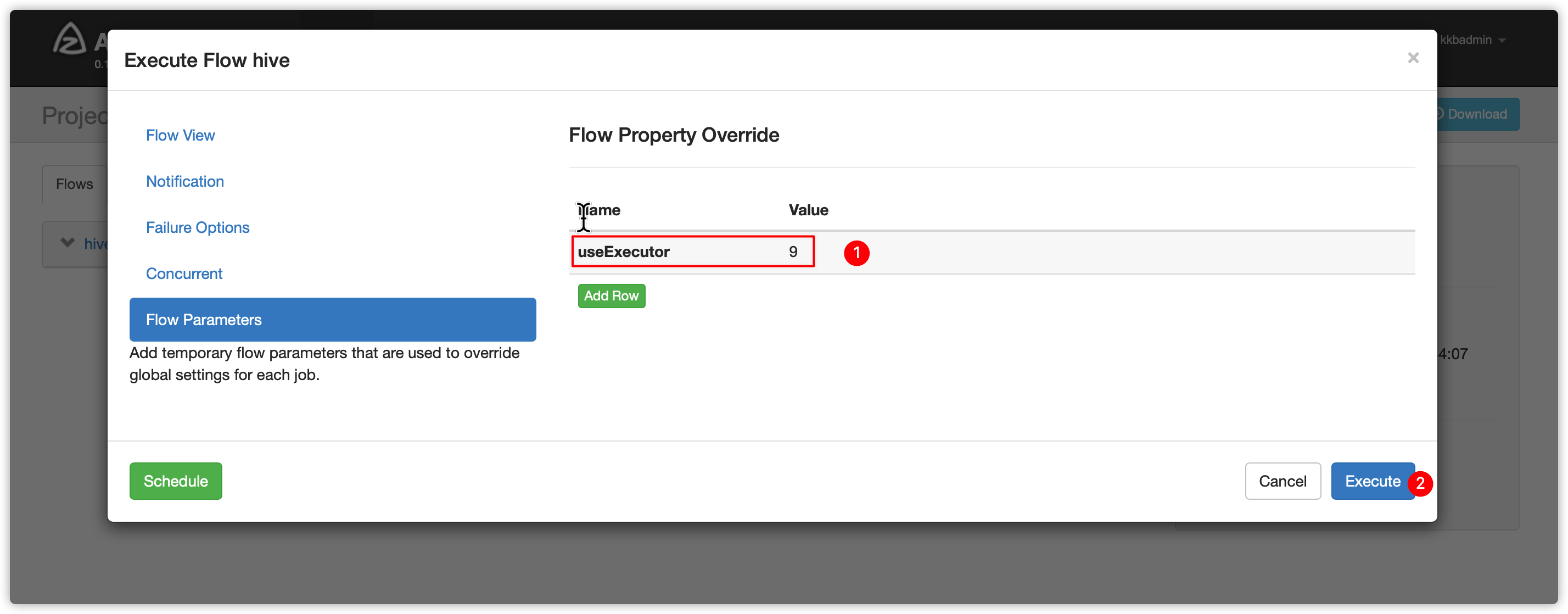
- 指定flow参数
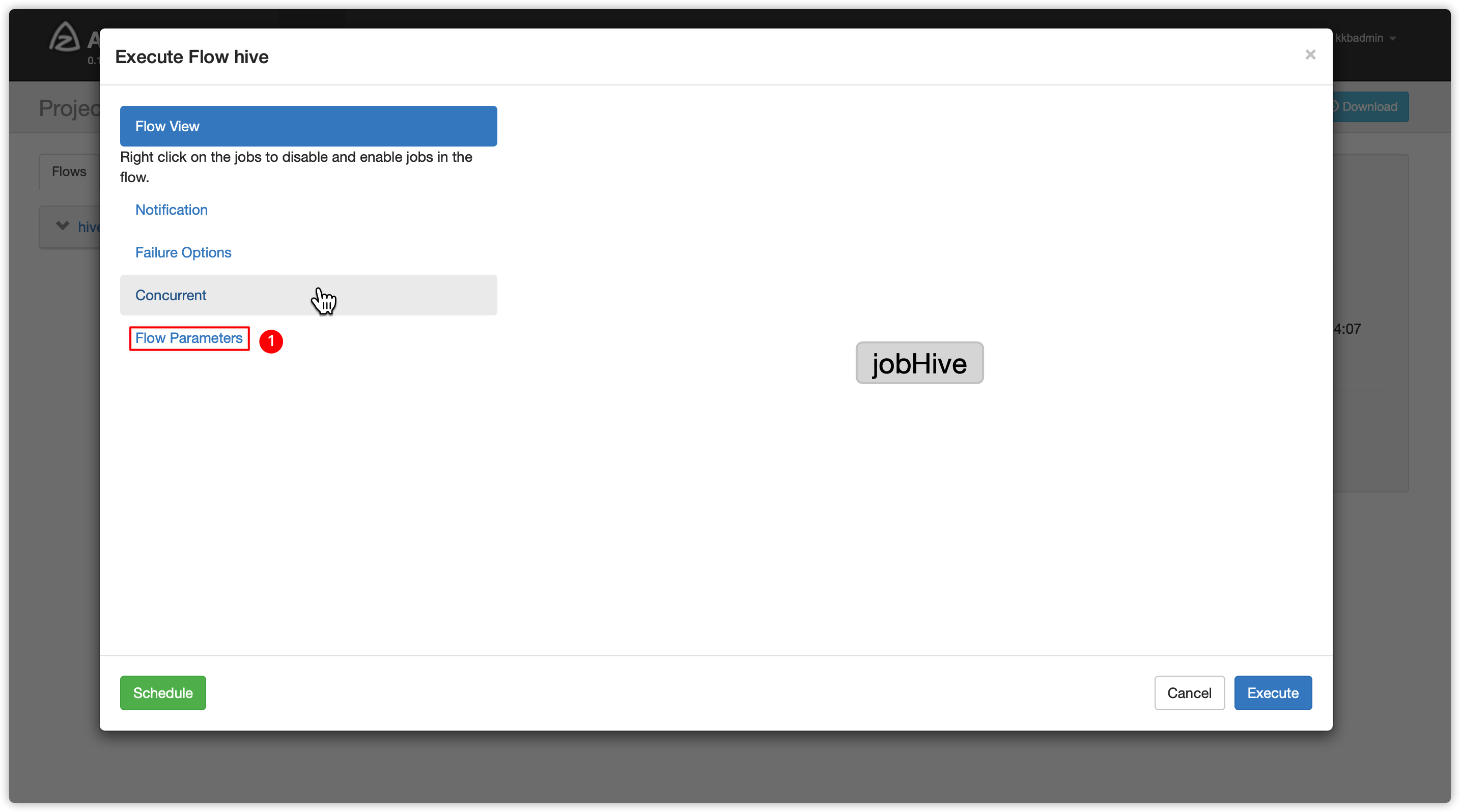
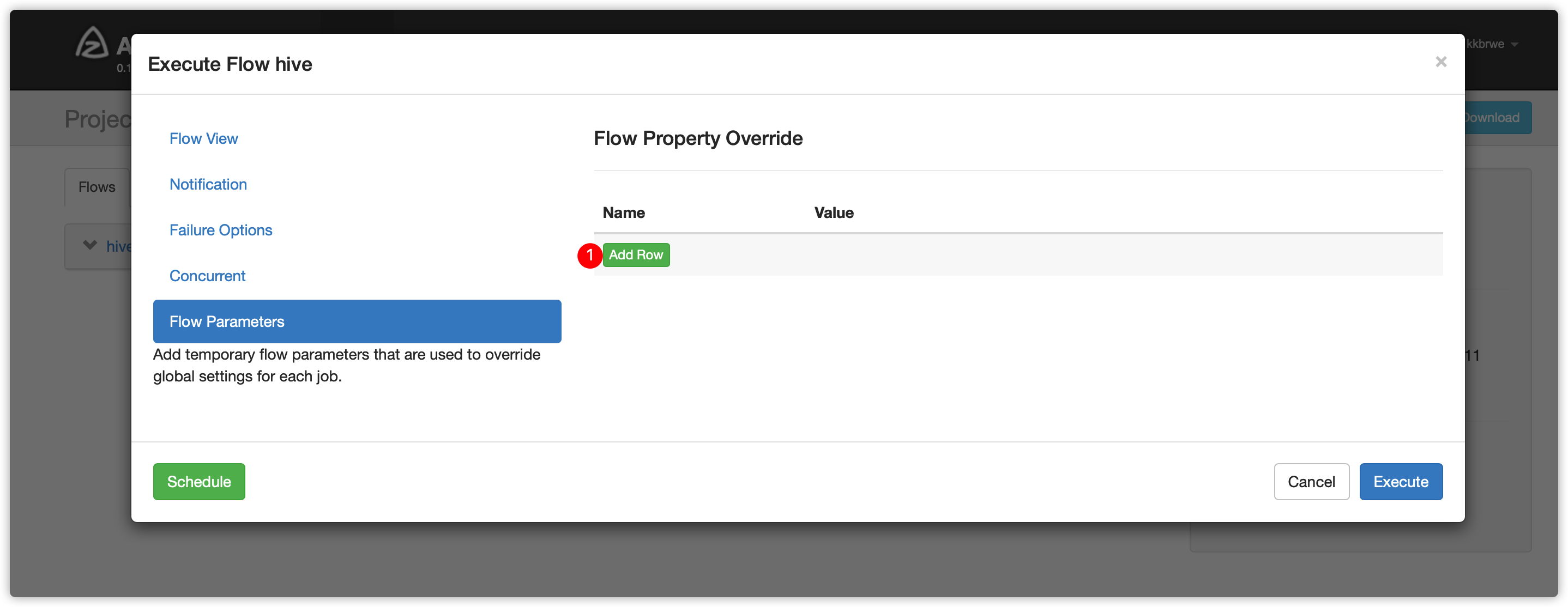
- node03节点登录mysql查看executor都有哪些?
[hadoop@node03 bin]$ mysql -uroot -p
mysql> use azkaban;
mysql> select * from executors;
+----+--------+-------+--------+
| id | host | port | active |
+----+--------+-------+--------+
| 7 | node01 | 39689 | 1 |
| 8 | node02 | 42295 | 1 |
| 9 | node03 | 35891 | 1 |
+----+--------+-------+--------+
3 rows in set (0.00 sec)-
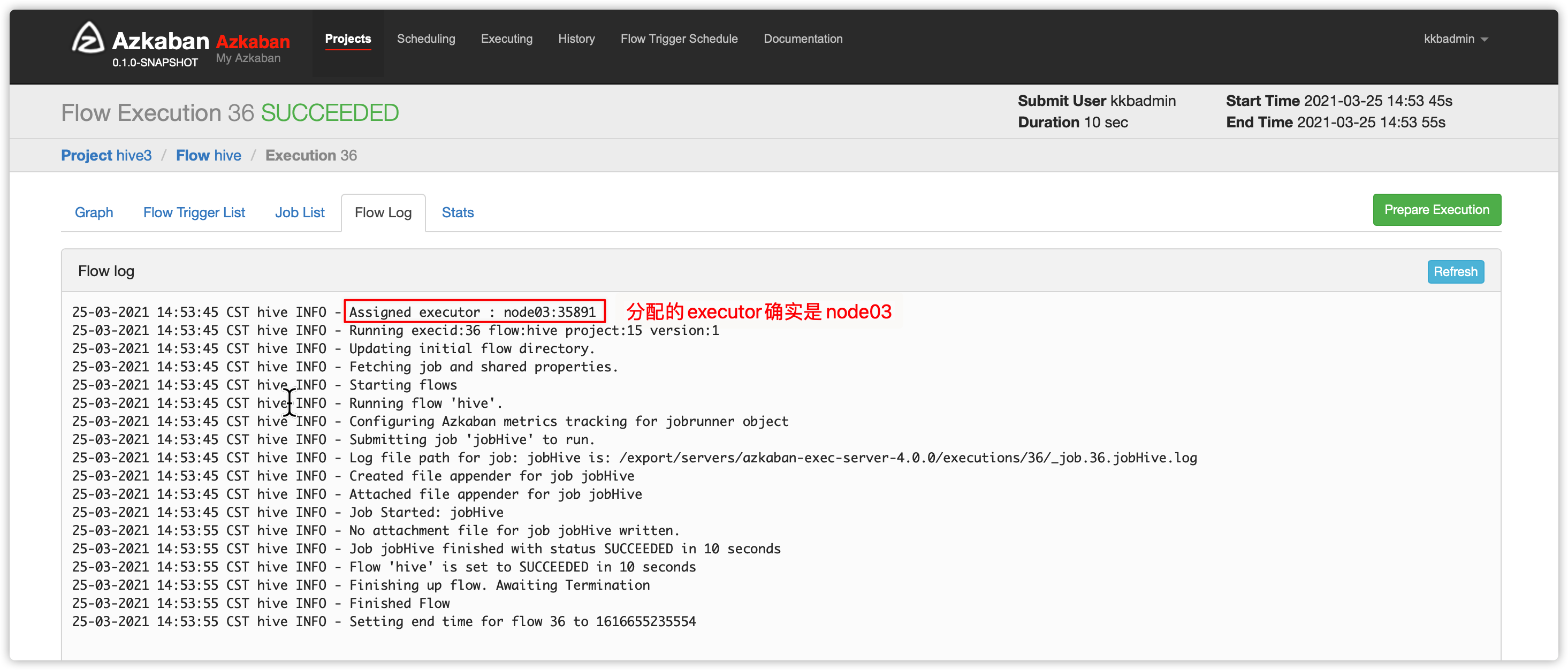
比如此时发现noded 03的id是9(根据自己的实际情况填写executor id)
-
上边azkaban界面输入参数如下,然后执行
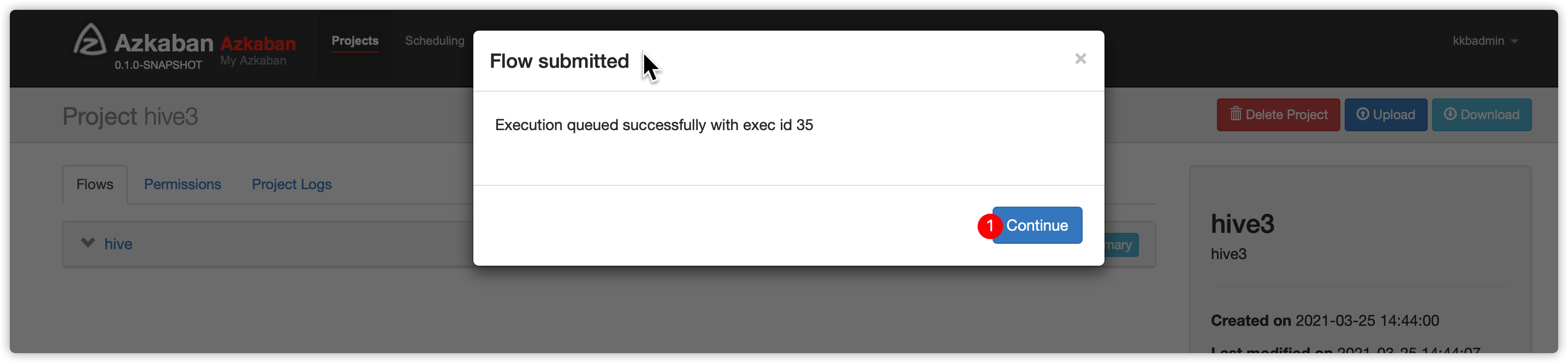
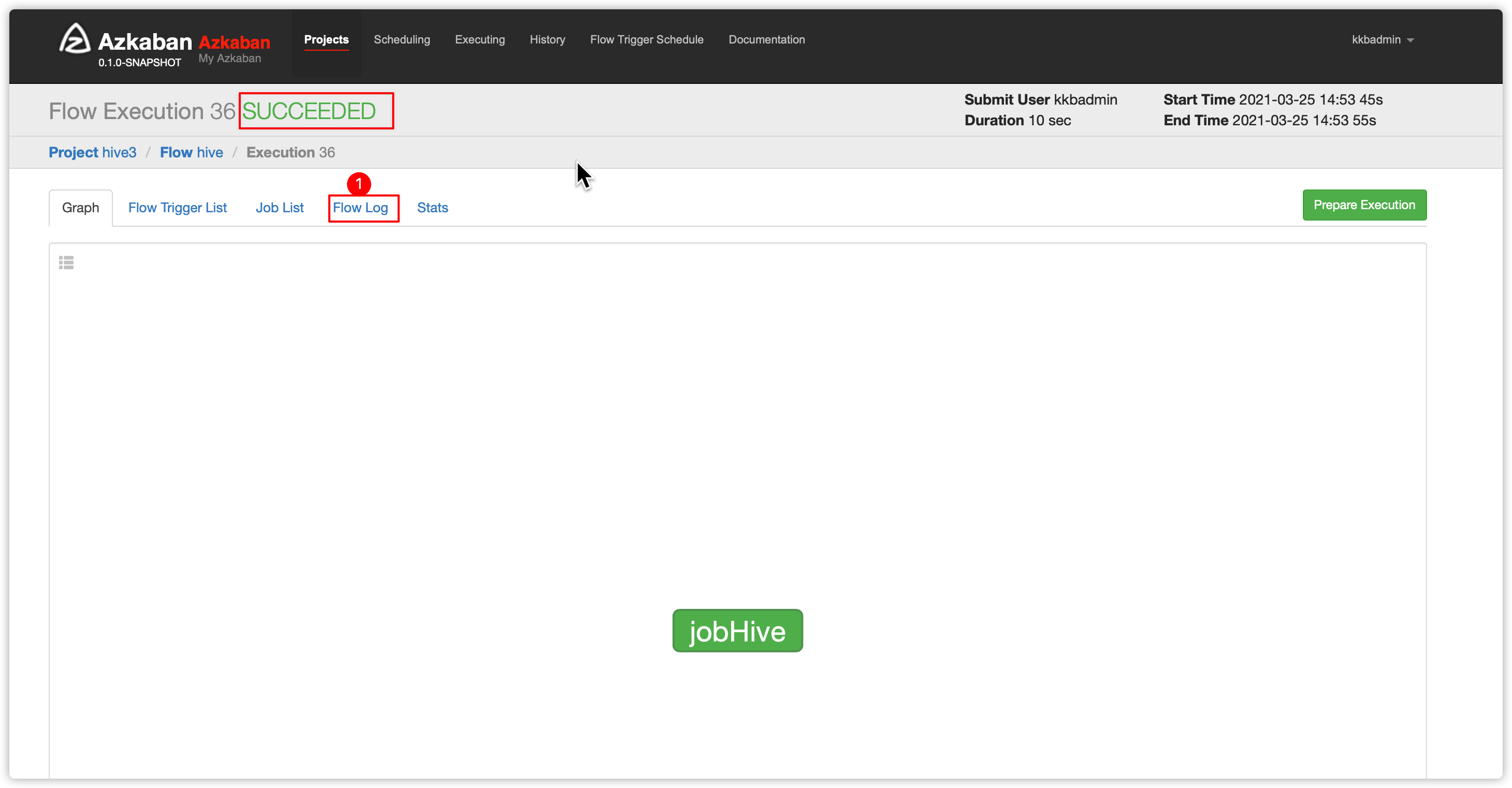
- 刷新页面,发现执行成功
Views: 24