
HBase表的预分区
- 当一个table刚被创建的时候,Hbase默认的分配一个region给table。也就是说这个时候,所有的读写请求都会访问到同一个regionServer的同一个region中,这个时候就达不到负载均衡的效果了,集群中的其他regionServer就可能会处于比较空闲的状态。
- 解决这个问题可以用pre-splitting,在创建table的时候就配置好,生成多个region。
1 为何要预分区?
- 增加数据读写效率
- 负载均衡,防止数据倾斜
- 方便集群容灾调度region
- 优化Map数量
2 预分区原理
- 每一个region维护着startRowKey与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。
手动指定预分区
-
三种方式
-
方式一
create 'person','info1','info2',SPLITS => ['1000','2000','3000','4000']可以在UI界面查看这个表的每个分区的起始和结束rowKey。
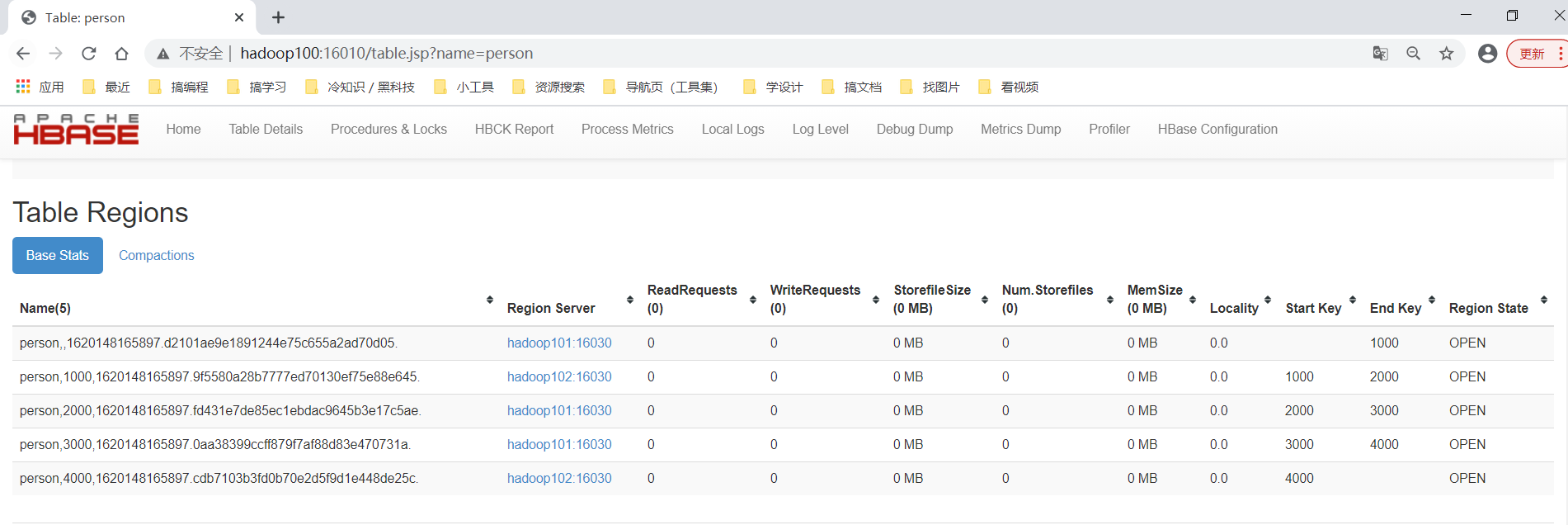
-
方式二:也可以把分区规则创建于文件中
cd /opt/data vim split.txt- 文件内容
aaa bbb ccc ddd- hbase shell中,执行命令
create 'student','info',SPLITS_FILE => '/opt/data/split.txt'- 成功后查看web界面

-
方式三: HexStringSplit 算法
-
HexStringSplit会将数据从“00000000”到“FFFFFFFF”之间的数据长度按照n等分之后算出每一段的起始rowkey和结束rowkey,以此作为拆分点。
-
例如:
create 'mytable', 'base_info',' extra_info', {NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'} -

Views: 10