
HBase介绍
HBase基于Google的BigTable论文,是建立的HDFS之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的分布式数据库系统。
在需要实时读、写随机访问、超大规模数据集时,可以使用HBase。
HBase的特点
- 极易扩展,海量存储
底层依赖HDFS,当磁盘空间不足的时候,只需要动态增加datanode节点就可以了
可以通过增加服务器来对集群的存储进行扩容 - 列式存储
HBase表的数据是基于列族进行存储的,列族是在列的方向上的划分。 - 高并发
支持高并发的读写请求 - 稀疏
稀疏主要是针对HBase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。 - 数据的多版本
HBase表中的数据可以有多个版本值,默认情况下是根据版本号去区分,版本号就是插入数据的时间戳 - 数据类型单一
所有的数据在HBase中是以字节数组进行存储
Hbase在实际场景中的应用
-
交通方面
船舶GPS信息,全长江的船舶GPS信息,每天有1千万左右的数据存储。
-
金融方面
消费信息、贷款信息、信用卡还款信息等
-
电商方面
电商网站的交易信息、物流信息、游览信息等
-
电信方面
通话信息、语音详单等
总结:海量明细数据的存储,并且后期需要有很好的查询性能
HBase集群安装部署
准备安装包
-
下载安装包并上传到hadoop100服务器
-
安装包下载地址:
https://www.apache.org/dyn/closer.lua/hbase/2.2.6/hbase-2.2.6-bin.tar.gz
-
将安装包上传到hadoop100服务器/kkb/softwares路径下,并进行解压
[hadoop@hadoop100 ~]$ cd /opt/download
[hadoop@hadoop100 soft]$ tar -zxvf hbase-2.2.6-bin.tar.gz -C /opt/pkg/修改HBase配置文件
-
hbase-env.sh
修改文件
[hadoop@hadoop100 softwares]$ cd /opt/pkg/hbase-2.2.6/conf [hadoop@hadoop100 conf]$ vim hbase-env.sh修改如下两项内容,值如下
export JAVA_HOME=/opt/pkg/java export HBASE_MANAGES_ZK=false -
hbase-site.xml
修改文件
[hadoop@hadoop100 conf]$ vim hbase-site.xml内容如下
<configuration> <!-- 指定hbase在HDFS上存储的路径 --> <property> <name>hbase.rootdir</name> <value>hdfs://hadoop100:8020/hbase</value> </property> <!-- 指定hbase是否分布式运行 --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- 指定zookeeper的地址,多个用“,”分割 --> <property> <name>hbase.zookeeper.quorum</name> <value>hadoop100,hadoop101,hadoop102:2181</value> </property> <!--指定hbase管理页面--> <property> <name>hbase.master.info.port</name> <value>16010</value> </property> <!-- 在分布式的情况下一定要设置,不然容易出现Hmaster起不来的情况 --> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> </configuration> -
regionservers
修改文件
[hadoop@hadoop100 conf]$ vim regionservers指定HBase集群的从节点;原内容清空,添加如下两行
hadoop101 hadoop102 -
back-masters
创建back-masters配置文件,里边包含备份HMaster节点的主机名,每个机器独占一行,实现HMaster的高可用
[hadoop@hadoop100 conf]$ vim backup-masters将hadoop101作为备份的HMaster节点,问价内容如下
hadoop101
分发安装包
- 将 hadoop100上的HBase安装包,拷贝到其他机器上
[hadoop@hadoop100 conf]$ cd /opt/pkg
[hadoop@hadoop100 install]$ scp -r hbase-2.2.6/ hadoop101:$PWD
[hadoop@hadoop100 install]$ scp -r hbase-2.2.6/ hadoop102:$PWD创建软连接
- 注意:三台机器均做如下操作
因为HBase集群需要读取hadoop的core-site.xml、hdfs-site.xml的配置文件信息,所以我们==三台机器==都要执行以下命令,在相应的目录创建这两个配置文件的软连接
ln -s /opt/pkg/hadoop-3.1.4/etc/hadoop/core-site.xml /opt/pkg/hbase-2.2.6/conf/core-site.xml
ln -s /opt/pkg/hadoop-3.1.4/etc/hadoop/hdfs-site.xml /opt/pkg/hbase-2.2.6/conf/hdfs-site.xml执行完后,出现如下效果,以hadoop100为例

添加HBase环境变量
注意:三台机器均执行以下命令,添加环境变量
sudo vim /etc/profile文件末尾添加如下内容
export HBASE_HOME=/opt/pkg/hbase-2.2.6
export PATH=$PATH:$HBASE_HOME/bin重新编译/etc/profile,让环境变量生效
source /etc/profileHBase的启动与停止
需要提前启动HDFS及ZooKeeper集群
- 如果没开启hdfs,请在hadoop100运行
start-dfs.sh命令 - 如果没开启zookeeper,请在3个节点分别运行
zkServer.sh start命令- 第一台机器
hadoop100(HBase主节点)执行以下命令,启动HBase集群[hadoop@hadoop100 ~]$ start-hbase.sh
- 第一台机器
- 启动完后,jps查看HBase相关进程
hadoop100、hadoop101上有进程HMaster、HRegionServer
hadoop102上有进程HRegionServer
警告提示:HBase启动的时候会产生一个警告,这是因为jdk7与jdk8的问题导致的,如果linux服务器安装jdk8就会产生这样的一个警告
可以注释掉所有机器的hbase-env.sh当中的 “HBASE_MASTER_OPTS”和“HBASE_REGIONSERVER_OPTS”配置 来解决这个问题。不过警告不影响我们正常运行,可以忽略。

我们也可以执行以下命令,单节点启动相关进程
#HMaster节点上启动HMaster命令
hbase-daemon.sh start master
#启动HRegionServer命令
hbase-daemon.sh start regionserver访问WEB页面
浏览器页面访问 http://hadoop100:16010
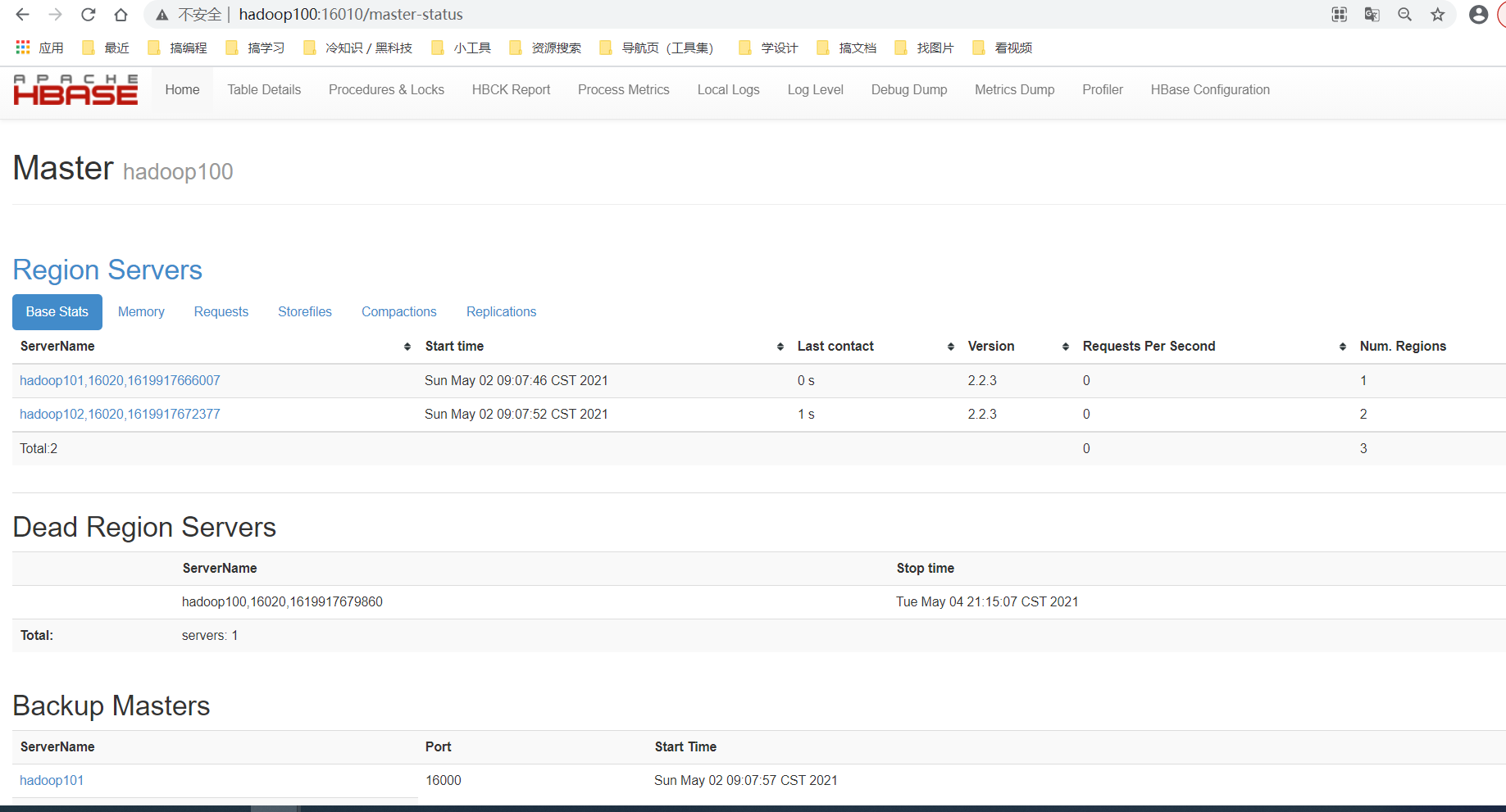
停止HBase集群
停止HBase集群的正确顺序
hadoop100上运行,关闭hbase集群
[hadoop@hadoop100 ~]$ stop-hbase.sh- 关闭ZooKeeper集群
- 关闭Hadoop集群
- 关闭虚拟机
- 关闭笔记本
Views: 28