
Hadoop安装与配置
Flume的安装与配置
Apache httpd 安装
安装httpd的原因主要是使用它提供的ab压测工具.
- 安装httpd
yum install -y httpd- 配置httpd,为了避免和ngixn端口冲突修改端口号为81,配置如下:
vi /etc/httpd/conf/httpd.conf修改内容如下:
#Listen 80
Listen 81- 启动服务
systemctl enable httpd # 开机自启动
systemctl start httpd # 启动httpd- 查看启动状态
systemctl status httpd注意:
- 其实使用
httpd只是为了使用ab工具,无需启动httpd服务
AB压测生成日志
访问http://hadoop100/university/ 登陆进入后台界面
后台UI界面生成商品链接
点击获取商品链接,页面打印生成的JSON格式数据
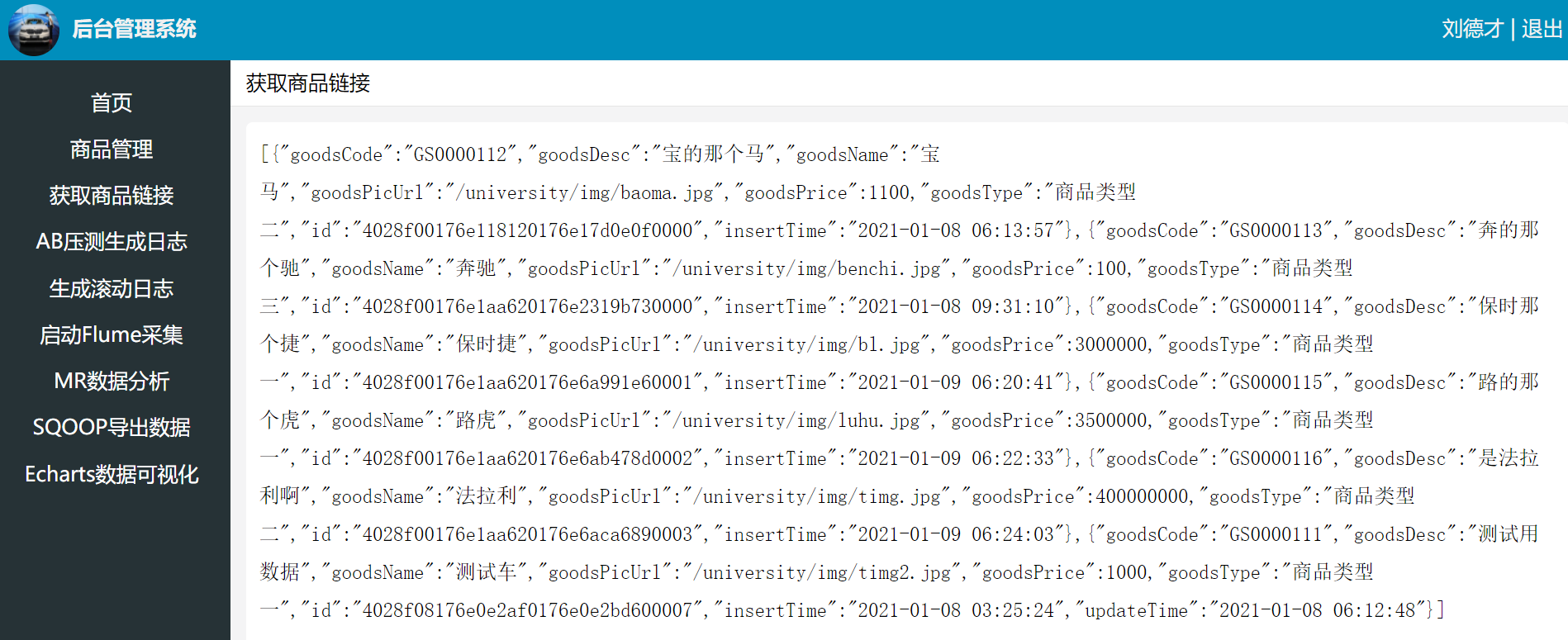
同时在服务器生成文件/tmp/project-urls.txt,里面保存着所有商品链接:
http://hadoop100/shop/detail.html?id=4028f00176e118120176e17d0e0f0000
http://hadoop100/shop/detail.html?id=4028f00176e1aa620176e2319b730000
http://hadoop100/shop/detail.html?id=4028f00176e1aa620176e6a991e60001
http://hadoop100/shop/detail.html?id=4028f00176e1aa620176e6ab478d0002
http://hadoop100/shop/detail.html?id=4028f00176e1aa620176e6aca6890003
http://hadoop100/shop/detail.html?id=4028f08176e0e2af0176e0e2bd600007后台UI界面AB压测生成日志
编写压测脚本ab_test.sh,内容可自行修改,如下:
$ vi /opt/bin/project/ab-test.sh
#!/bin/bash
n=$(cat /tmp/project-urls.txt | wc -l)
for ((i=1;i<=$n;i++))
do
echo "No.$i"
url=$(shuf -n1 /tmp/project-urls.txt)
r=$(shuf -i 6-100 -n 1)
c=$(shuf -i 1-5 -n 1)
echo "access url -> $url"
echo "requests -> $r"
echo "concurrency -> $c"
ab -n $r -c $c $url >> /tmp/project-abtest-results.log &
done
说明:
- 给与执行权限方便执行
shuf在指定范围生成随机数abapache benchmark工具,常用于压力测试-n请求数-c并发数
- 压测结果可在
/tmp/project-abtest-resuilts.log中找到
压测结果说明
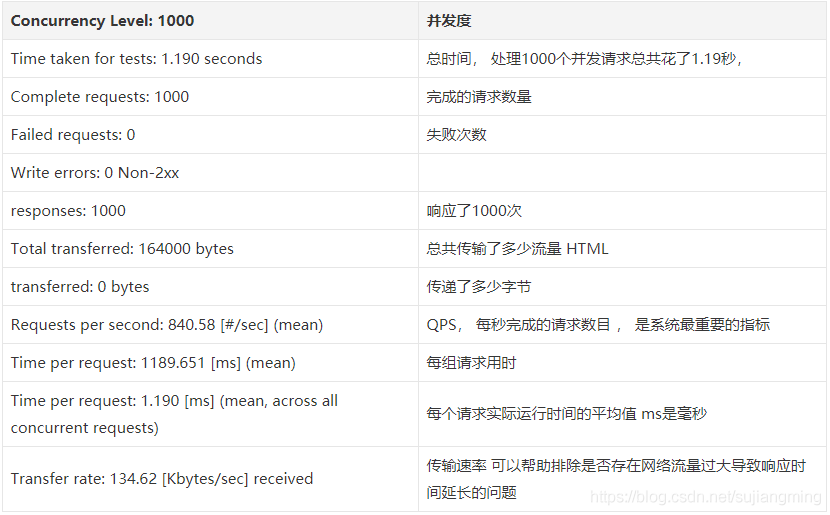
点击AB压测生成日志
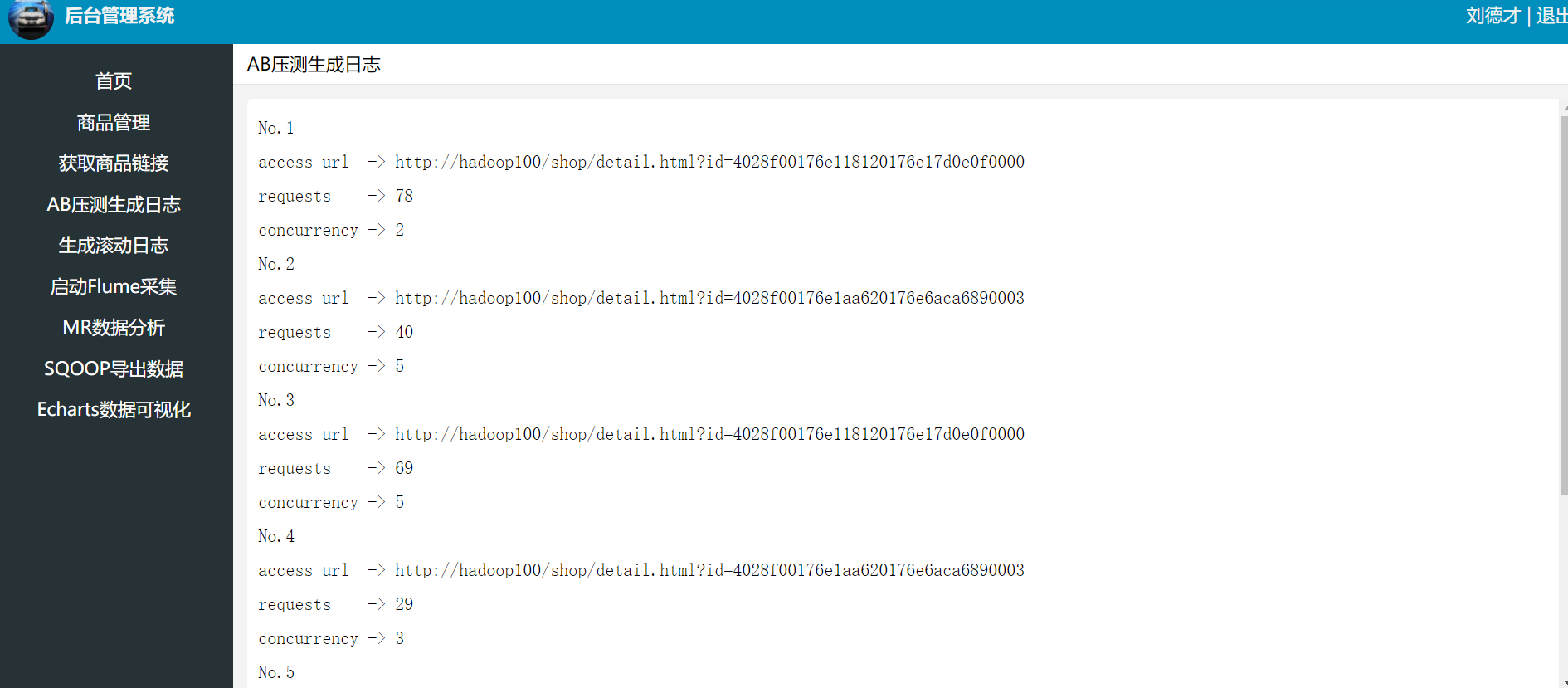
产生的日志在/var/log/nginx/access.log中。
使用FLume收集滚动日志上传到HDFS上
修改nginx生成的日志文件所有者
nginx默认生成的日志文件access.log的用户组和用户分别是adm和nginx,如下所示:
[hadoop@hadoop100 nginx]$ ll
-rw-r----- 1 nginx adm 135470 Apr 21 01:22 access.log而现在需要让另一用户读取该文件,做日志的分析监控. 应该修改日志文件的所属用户组和用户,避免出现权限问题。
修改Nginx运行时进程的用户与组
Nginx运行时进程需要有用户与组的支持,用以实现对网站文件读取时进行访问控制。主进程由 root创建,子进程由指定的用户与组创建, 一般默认为 nginx adm 或 nobody nobody。
由于我们项目中使用的操作账户为hadoop,而这个用户对nginx用户生成的日志没有操作权限,因此使用Flume收集时会出现权限问题导致收集失败。
当然也可以简单粗暴的临时使用下面的命令解决问题
$ sudo chown hadoop:hadoop -R /var/log/nginx/但是这样并不能从根本解决问题,因为下次滚动生成的日志所有者还会变成原来配置的。
修改 nginx 用户与组有两种办法。如果是编译安装,可以在编译前指定用户和组;也可以修改配置文件指定用户与组,然后重启服务器即可。
编译 nginx 时指定用户与组
即修改 ./configure 后面指定用户与组的参数
./configure \
--prefix=/usr/local/nginx \
--user=nginx \ //指定用户名是 nginx
--group=nginx \ //指定组名是 nginx
--with-http_stub_status_module修改 nginx 配置文件指定用户与组
打开文件/etc/nginx/nginx.conf,我这里默认是
user nginx; //修改用户为nginx,组为nginx现在我们改成
user hadoop hadoop; // //修改用户为 hadoop,组为 hadoopsudo service nginx restart重启服务后,查看进程情况,主进程由root创建,子进程则由nginx创建。

修改 Nginx 日志滚动策略
可以通过修改这个文件修改 Nginx 的日志滚动策略(如有需要)
$ sudo vi /etc/logrotate.d/nginx
/var/log/nginx/*.log {
daily
missingok
rotate 52
compress
delaycompress
notifempty
create 640 nginx adm
sharedscripts
postrotate
if [ -f /var/run/nginx.pid ]; then
kill -USR1 $(cat /var/run/nginx.pid)
fi
endscript
}
其中nginx adm就是滚动日志的权限拥有者及所在群组, 640表示滚动日志的权限。下面比如我们需要将滚动日志的用户组和用户改为hadoop:hadoop, 只需要修改此处:
#create 640 nginx adm
create 640 hadoop hadoop滚动access.log日志文件
接着编写Linux Shell脚本实现/var/log/nginx/access.log日志滚动到flume-logs目录下。
在/opt/bin/project目录下新建rolling-log.sh,并添加执行权限,内容如下:
#!/bin/bash
#定义日期格式
dataformat=$(date +%Y-%m-%d-%H-%M-%S)
#复制access.log并重命名,添加时间信息
cp /var/log/nginx/access.log /var/log/nginx/access_$dataformat.log
host=$(hostname)
sed -i 's/^/'${host}',&/g' /var/log/nginx/access_$dataformat.log
#统计日志文件行数
lines=$(wc -l < /var/log/nginx/access_$dataformat.log)
#将格式化的日志移动到flumeLogs目录下
mv /var/log/nginx/access_$dataformat.log /var/log/nginx/flume-logs
#清空access.log的内容
sed -i '1,'${lines}'d' /var/log/nginx/access.log
#重启nginx , 使access.log可以继续滚动
kill -USR1 $(cat /var/run/nginx.pid)
##返回给服务器信息
ls -al /var/log/nginx/flume-logs/后台管理界面点击生成滚动日志
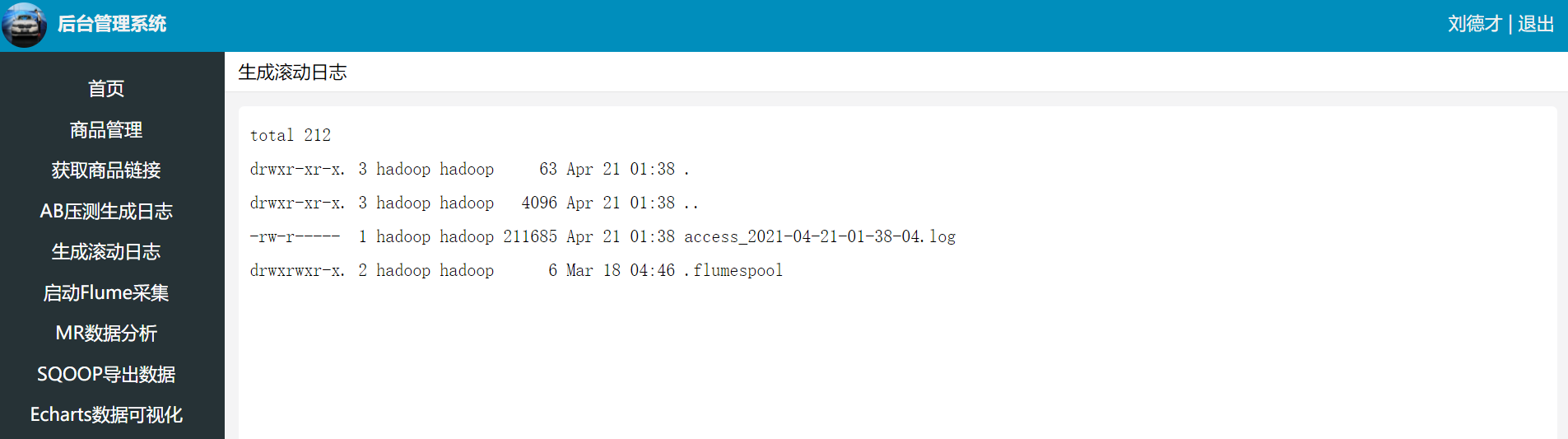
编写Flume Agent配置文件:
vi /opt/pkg/flume/conf/log2hdfs.conf`
# define the agent a1
a1.sources=r1
a1.channels=c1
a1.sinks=k1
# define the source
#上传目录类型
a1.sources.r1.type=spooldir
a1.sources.r1.spoolDir=/var/log/nginx/flume-logs
#定义自滚动日志完成后的后缀名
a1.sources.r1.fileSuffix=.FINISHED
#根据每行文本内容的大小自定义最大长度4096=4k
a1.sources.r1.deserializer.maxLineLength=4096
# define the sink
a1.sinks.k1.type = hdfs
#上传的文件保存在hdfs的/flume/logs目录下
a1.sinks.k1.hdfs.path = hdfs://hadoop100:8020/flume/logs/%y-%m-%d/
a1.sinks.k1.hdfs.filePrefix=access_log
a1.sinks.k1.hdfs.fileSufix=.log
a1.sinks.k1.hdfs.batchSize=1000
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat= Text
# roll 滚动规则:按照数据块128M大小来控制文件的写入,与滚动相关其他的都设置成0
#为了演示,这里设置成500k写入一次
a1.sinks.k1.hdfs.rollSize= 512000
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.rollInteval=0
#控制生成目录的规则:一般是一天或者一周或者一个月一次,这里为了演示设置10秒
a1.sinks.k1.hdfs.round=true
a1.sinks.k1.hdfs.roundValue=10
a1.sinks.k1.hdfs.roundUnit= second
#是否使用本地时间
a1.sinks.k1.hdfs.useLocalTimeStamp=true
#define the channel
a1.channels.c1.type = memory
#自定义event的条数
a1.channels.c1.capacity = 500000
#flume事务控制所需要的缓存容量1000条event
a1.channels.c1.transactionCapacity = 1000
#source channel sink cooperation
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1创建脚本flume_start.sh,用于启动Flume Agent
#!/bin/bash
/opt/pkg/flume-1.9.0/bin/flume-ng agent --conf ./conf/ -f ./conf/log2hdfs.conf --name a1 -Dflume.root.logger=INFO,console编写停止Flume脚本 flume_stop.sh,停止Flume
#!/bin/bash
JAR="flume"
#停止flume函数
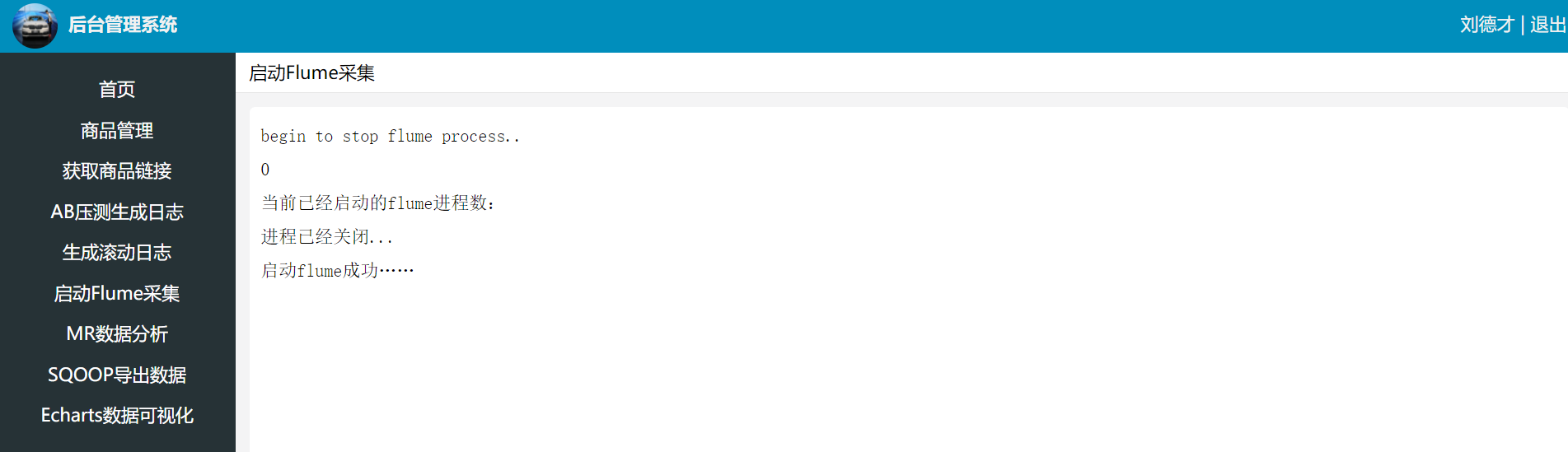
echo "begin to stop flume process.."
num=$(ps -ef|grep java|grep $JAR|wc -l)
echo "当前已经启动的flume进程数:$num"
if [ "$num" != "0" ];then
#正常停止flume
ps -ef|grep java|grep $JAR|awk '{print $2;}'|xargs kill -9
echo "进程已经关闭..."
else
echo "服务未启动,无须停止..."
fi编写重启Flume脚本 flume-log2hdfs.sh,综合了前两个脚本
#!/bin/bash
#先停止正在启动的flume
./flume_stop.sh
nohup ./flume_start.sh > nohup_output.log 2>&1 &
echo "启动flume成功……"
后台管理界面点击启动FLume采集
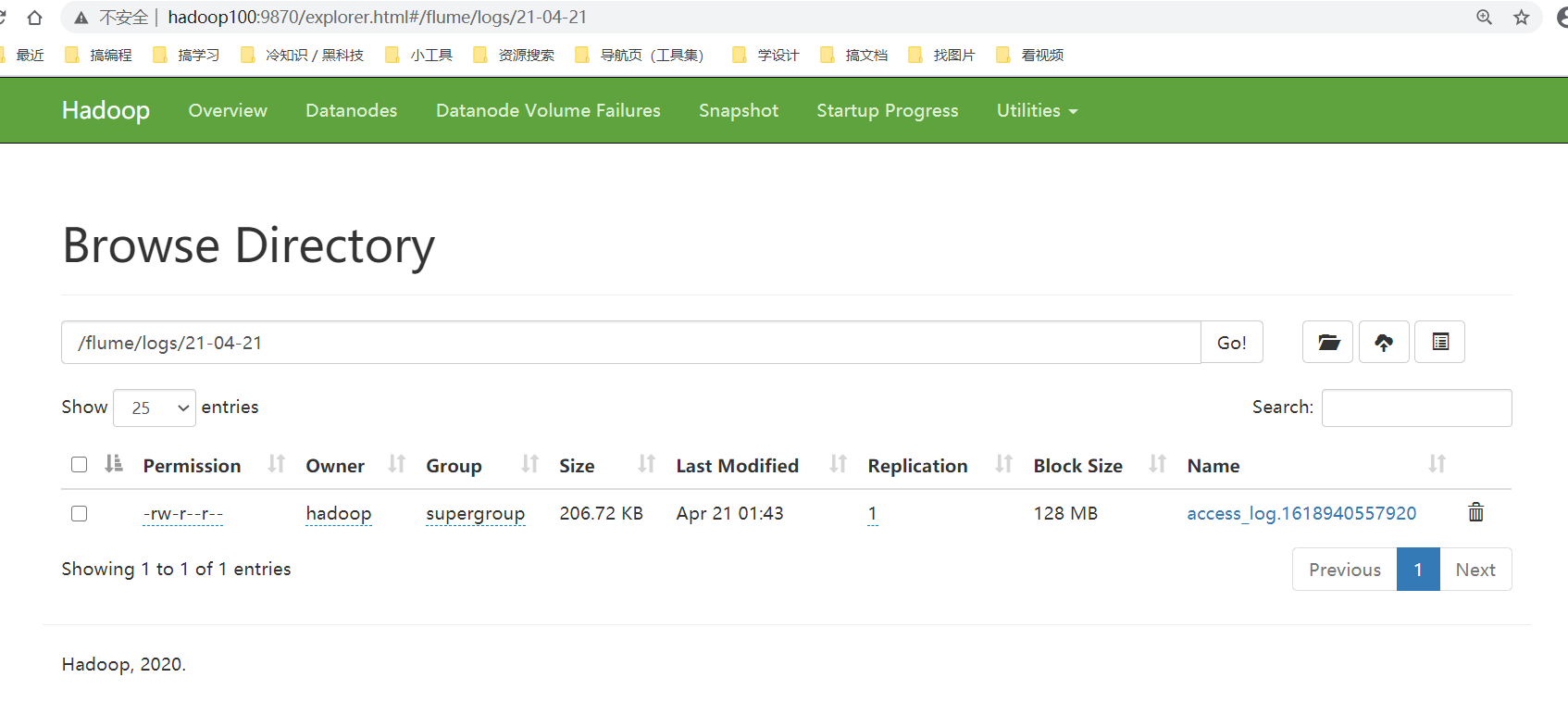
查看滚动日志是否成功上传到HDFS系统
异常: 日志收集失败,报错:
2021-03-09 22:38:50,834 (SinkRunner-PollingRunner-DefaultSinkProcessor) [ERROR - org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:459)] process failed
java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V原因: flume/lib/guava-xxx.jar 和 hadoop自带的jar包发生冲突
解决: 将flume/lib下的guava包删除或者改名, 只保留hadoop的版本即可
Views: 136