
伪分布式集群搭建
- Q: 为什么要搭建伪分布式集群?
- A: 为了更好的理解 ZooKeeper 的工作原理, 以及更好的理解 ZooKeeper 的应用场景.
ZooKeeper 伪分布式集群(单机多进程)搭建步骤
- 下载和安装
下载,解压,配置环境变量就不多说了,和其他框架都大致一样
版本选择 3.4.14
- 单机多服务配置
在 conf 目录下创建三个配置文件
zoo-1.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/tmp/zk-1
dataLogDir=/opt/tmp/zk-log-1
clientPort=2181
4lw.commands.whitelist=*
server.1=localhost:2891:3891
server.2=localhost:2892:3892
server.3=localhost:2893:3893zoo-2.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/tmp/zk-2
dataLogDir=/opt/tmp/zk-log-2
clientPort=2182
4lw.commands.whitelist=*
server.1=localhost:2891:3891
server.2=localhost:2892:3892
server.3=localhost:2893:3893zoo-3.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/tmp/zk-3
dataLogDir=/opt/tmp/zk-log-3
clientPort=2183
4lw.commands.whitelist=*
server.1=localhost:2891:3891
server.2=localhost:2892:3892
server.3=localhost:2893:3893-
4lw:4 letter word的缩写,代表着 ZooKeeper 服务器的内部命令,这里是为了方便我们查看 ZooKeeper 服务器的运行状态,所以将这个命令列入白名单,允许我们通过客户端来执行这个命令(关于 4lw 的使用后续的章节再进行讲解)。 -
server.x=ip:port:port: 这个配置项是用来配置集群中的每个服务器的,x 代表服务器的编号,ip代表服务器的 IP 地址,port代表服务器的端口号,这里的端口号是用来和集群中的其他服务器进行通信的端口号,也就是说,这个端口号是用来和集群中的其他服务器进行通信的 (而不是用来和客户端进行通信的,客户端和服务器通信的端口号是由clientPort配置项来指定的)28xx是 Leader 暴露的端口, 用于处理写请求和数据同步38xx端口是用于 Leader 选举时使用的端口,
接下来在三个配置文件中dataDir所指向的目录里面分别建立一个 myid 文件, 里面分别保存数字 1, 2, 3,假设数字为 x 对应配置文件中的 server.x=...,这个 x 代表 ZooKeeper 的服务器 ID 编号, 集群中的每个服务器的 ID 编号都应该是唯一的正整数。
mkdir -p /opt/tmp/zk-1
mkdir -p /opt/tmp/zk-2
mkdir -p /opt/tmp/zk-3
echo 1 > /opt/tmp/zk-1/myid
echo 2 > /opt/tmp/zk-2/myid
echo 3 > /opt/tmp/zk-3/myid4、zk 服务相关命令
# 启动 zoo-1.cfg 所配置的 ZooKeeper 服务器
zkServer.sh start conf/zoo-1.cfg
# 检查 zoo-1.cfg 所配置的 ZooKeeper 服务器运行状态
zkServer.sh status conf/zoo-1.cfg
# 停止 zoo-1.cfg 所配置的 ZooKeeper 服务器
zkServer.sh stop conf/zoo-1.cfg观察 Leader 选举过程
-
启动三个 ZooKeeper 服务器
zkServer.sh start conf/zoo-1.cfg zkServer.sh start conf/zoo-2.cfg zkServer.sh start conf/zoo-3.cfg -
查看三个 ZooKeeper 服务器的运行状态
zkServer.sh status conf/zoo-1.cfg zkServer.sh status conf/zoo-2.cfg zkServer.sh status conf/zoo-3.cfg可以看到服务器 2 为 Leader.
观察崩溃恢复过程
-
停止 id 为 2 的 ZooKeeper 服务器
zkServer.sh stop conf/zoo-2.cfg -
查看三个 ZooKeeper 服务器的运行状态
zkServer.sh status zoo-1.cfg zkServer.sh status zoo-2.cfg zkServer.sh status zoo-3.cfg可以看到服务器 3 为 Leader.
-
如果此时停止 id 为 3 的服务器会怎样?
前面已经停止了服务器 2, 如果再停止服务器 3, 则只有一台服务器 1 在运行, 少于等于集群中总服务器数量的一半, 此时集群将无法正常工作, 服务器 1 将自杀, 无法提供服务.
- 查看服务器日志文件
tail -F zookeeper.out默认日志文件会在执行启动服务命令时的当前目录下生成, 默认日志文件名为
zookeeper.out
如果想要指定日志文件生成的位置:
- 可以在启动服务时, 指定日志文件生成的位置:添加一个系统属性:
-Dzookeeper.log.dir=${ZOOKEEPER_HOME}/logs}- 或者导出环境变量:
export ZOO_LOG_DIR=${ZOOKEEPER_HOME}/logs
ZooKeeper 的事务和选举功能
在 ZooKeeper 服务器集群中,一个服务器被选为领导者,其余所有服务器被选为追随者。leader 负责处理所有向 ZooKeeper 服务的写请求(事务性请求)。追随者接收领导者提出的写操作,并通过多数共识机制(majority consensus mechanism)实现数据的一致性。
Zookeeper 服务器角色
Zookeeper 集群中,有 Leader、Follower 和 Observer 三种角色
-
Leader: Leader 服务器是整个 ZooKeeper 集群工作机制中的核心,其主要工作:
- 事务请求的唯一调度和处理者,保证集群事务处理的顺序性
- 集群内部各服务的调度者
-
Follower: Follower 服务器是 ZooKeeper 集群状态的跟随者,其主要工作:
- 处理客户端非事务请求,转发事务请求给 Leader 服务器
- 参与事务请求 Proposal(提案)的投票
- 参与 Leader 选举投票
-
Observer: Observer 是 3.3.0 版本开始引入的一个服务器角色,它充当一个观察者角色——观察 ZooKeeper 集群的最新状态变化并将这些状态变更同步过来。其工作:
- 处理客户端的非事务请求,转发事务请求给 Leader 服务器
- 不参与任何形式的投票
ZooKeeper 启动过程的 Leader 选举机制
在 ZooKeeper 集群启动时,需要在集群中的服务器之间确定一台 Leader 服务器。当 ZooKeeper 集群中的三台服务器启动之后,首先会进行通信检查,如果集群中的服务器之间能够进行通信。集群中的三台机器开始尝试寻找集群中的 Leader 服务器并进行数据同步等操作。
如何这时没有搜索到 Leader 服务器,说明集群中不存在 Leader 服务器。这时 ZooKeeper 集群开始发起 Leader 服务器选举。
在整个 ZooKeeper 集群中 Leader 选举主要可以分为三大步骤分别是:
发起投票、接收投票、统计投票。

- 发起投票
我们先来看一下发起投票的流程,在 ZooKeeper 服务器集群初始化启动的时候,集群中的每一台服务器都会将自己作为 Leader 服务器进行投票。也就是每次投票时,发送的服务器的 myid(服务器标识符)和 ZXID (集群投票信息标识符)等选票信息字段都指向本机服务器。 而一个投票信息就是通过这两个字段组成的。以集群中三个服务器 Serverhost1、Serverhost2、Serverhost3 为例,三个服务器的投票内容分别是:Severhost1 的投票是(1,0)、Serverhost2 服务器的投票是(2,0)、Serverhost3 服务器的投票是(3,0)。
-
接收投票
集群中各个服务器在发起投票的同时,也通过网络接收来自集群中其他服务器的投票信息。在接收到网络中的投票信息后,服务器内部首先会判断该条投票信息的有效性。检查该条投票信息的时效性,是否是本轮最新的投票,并检查该条投票信息是否是处于 LOOKING 状态的服务器发出的。
服务器有四种状态:
- LOOKING:寻找 Leader 状态。当服务器处于该状态时,它会认为当前集群中没有 Leader,因此需要进入 Leader 选举状态。
- FOLLOWING:跟随者状态。表明当前服务器角色是 Follower。
- LEADING:领导者状态。表明当前服务器角色是 Leader。
- OBSERVING:观察者状态。表明当前服务器角色是 Observer。
-
统计投票
在接收到投票后,ZooKeeper 集群就该处理和统计投票结果了。对于每条接收到的投票信息,集群中的每一台服务器都会将自己的投票信息与其接收到的 ZooKeeper 集群中的其他投票信息进行对比。主要进行对比的内容是(myid, ZXID),ZXID 数值比较大的投票信息优先作为 Leader 服务器。如果每个投票信息中的 ZXID 相同,就会接着比对投票信息中的 myid 信息字段,选举出 myid 较大的服务器作为 Leader 服务器。注释:
事务 ID,即 zxid。ZooKeeper 的在选举时通过比较各结点的 zxid 和机器 ID 选出新的主结点的。zxid 由 Leader 节点生成,有新写入事件时,Leader 生成新 zxid 并随提案一起广播,每个结点本地都保存了当前最近一次事务的 zxid,zxid 是递增的,所以谁的 zxid 越大,就表示谁的数据是最新的。
集群初始化时的选举过程
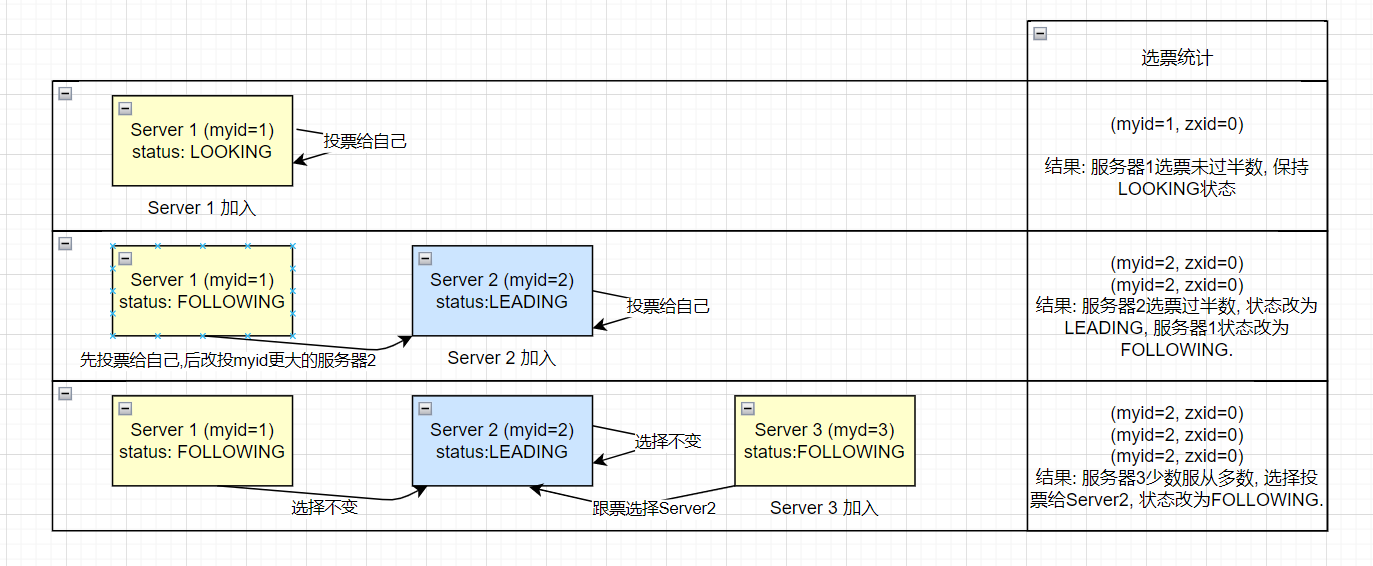
zookeeper 集群初始化阶段,服务器(myid=1-3)依次启动,开始选举 Leader:
- 服务器 1(myid=1)启动,当前只有一台服务器,无法完成 Leader 选举, 服务器状态为 LOOKING.
- 服务器 2(myid=2)启动,此时两台服务器能够相互通讯,开始进入 Leader 选举阶段
Leader 选举阶段
-
每个服务器发出一个投票: 服务器 1 和 服务器 2 都将自己作为 Leader 服务器进行投票,然后各自将这个投票发给集群中的其他所有机器。
投票的基本元素包括:服务器的 myid 和 ZXID,我们以(myid,ZXID)形式表示。初始阶段,服务器 1 和服务器 2 都会投给自己,即服务器 1 的投票为(1,0),服务器 2 的投票为(2,0).
- 接受来自各个服务器的投票: 每个服务器都会接受来自其他服务器的投票。同时,服务器会校验投票的有效性,是否本轮投票、是否来自 LOOKING 状态的服务器。
-
处理投票: 收到其他服务器的投票,会将别人的投票跟自己的投票 PK,PK 规则如下优先检查 ZXID。ZXID 比较大的服务器优先作为 leader。如果 ZXID 相同的话,就比较 myid,由 myid 比较大的服务器作为 leader。
服务器 1 的投票是(1,0),它收到投票是(2,0),两者 zxid 都是 0,因为收到的 myid=2,大于自己的 myid=1,所以它更新自己的投票为(2,0),然后重新将投票发出去。
对于服务器 2 呢,即不再需要更新自己的投票,把上一次的投票信息发出即可。
- 统计投票: 每次投票后,服务器会统计所有投票,判断是否有过半的机器接受到相同的投票信息。服务器 2 收到两票,因为已经过半,所以它进入 LEADING 状态,成为 Leader 服务器, 服务器 1 则成为 Follower 服务器。
如果选票统计时发现某一服务器获得的选票数大于等于(n/2+1,n 为总服务器)则进入 LEADING 状态,成为 Leader 服务器。
反之如果少于(n/2+1,n 为总服务器)则继续保持 LOOKING 状态, 进行下一轮投票, 直到选出 Leader。
Q: 当服务器 1 和服务器 2 进行选票统计时, 如何得知半数选票是多少?
A:
通过服务器配置文件可知。
- 由于此时 Leader 服务器已经确定是服务器 2, 启动服务器 3 加入了集群, 此时服务器 1 和 2 的角色已经不是 LOOKING, 不会更改选票信息和交换投票信息, 服务器 3 服从多数, 更改选票信息为服务器 2, 更改状态为 FOLOWER, 成为服务器 2 的 FOLLOWER.
思考: 推演拥有 5 个节点的 ZooKeeper 集群的 Leader 选举过程
Leader 崩溃后的选举过程
假设 Leader 服务器 2(myid=2)宕机,由于集群中没有了 Leader 节点, 此时会触发以下选举流程。

-
变更状态: Leader 服务器挂了之后,余下的非 Observer 服务器都会把自己的服务器状态更改为 LOOKING,然后开始进入 Leader 选举流程。
-
每个服务器发起投票,每个服务器都把票投给自己
因为是运行期间,所以每台服务器的 ZXID 可能不相同。假设服务 1,3 的 zxid 分别为 333,666,则分别产生投票(1,333),(3,666),然后各自将这个投票发给集群中的其他所有机器。
-
接受来自各个服务器的投票
-
处理投票
投票规则是优先检查 ZXID,大的优先作为 Leader,所以显然服务器 zxid=666 具有优先权。
-
统计投票
-
改变服务器状态
需要注意的是, 在 Leader 选举过程中, ZooKeeper 不能对外提供服务。
源码学习: org.apache.zookeeper.server.quorum.FastLeaderElection
为什么需要 Leader 服务器
Zookeeper 中主要依赖 Zab 协议来实现数据一致性,基于该协议,zk 实现了一种主备模型(即 Leader 和 Follower 模型)的系统架构来保证集群中各个副本之间数据的一致性。
这里的主备系统架构模型,就是指只有一台客户端(Leader)负责处理外部的写事务请求,然后 Leader 客户端将数据同步到其他 Follower 节点。
什么是 ZAB 协议?
Zab 协议 的全称是 Zookeeper Atomic Broadcast (Zookeeper 原子广播)。Zab 协议是为分布式协调服务 Zookeeper 专门设计的一种 支持崩溃恢复 的 原子广播协议 ,是 Zookeeper 保证分布式事务的最终一致性的核心算法。
- ZAB 协议是一个基于消息广播的一致性协议,它可以保证在任何情况下,ZooKeeper 集群中的每个服务器上的数据最终都是一致的。
- ZAB 协议是一个两阶段提交协议,它包括两个阶段: 崩溃恢复(新 leader 选举)和原子广播。
协议过程
当整个集群启动过程中,或者当 Leader 服务器出现网络中断、崩溃退出或重启等异常时,Zab 协议就会 进入崩溃恢复模式,选举产生新的 Leader。
当选举产生了新的 Leader,同时集群中有过半的机器与该 Leader 服务器完成了状态同步(即数据同步)之后,Zab 协议就会退出崩溃恢复模式,进入消息广播模式。
这时,如果有一台遵守 Zab 协议的服务器加入集群,因为此时集群中已经存在一个 Leader 服务器在广播消息,那么该新加入的服务器自动进入恢复模式:找到 Leader 服务器,并且完成数据同步。同步完成后,作为新的 Follower 一起参与到消息广播流程中。
协议状态切换
当 Leader 出现崩溃退出或者机器重启,亦或是集群中不存在超过半数的服务器与 Leader 保存正常通信,Zab 就会再一次进入崩溃恢复,发起新一轮 Leader 选举并实现数据同步。同步完成后又会进入消息广播模式,接收事务请求。
保证消息有序
在整个消息广播中,Leader 会将每一个事务请求转换成对应的 proposal 来进行广播,并且在广播 事务 Proposal 之前,Leader 服务器会首先为这个事务 Proposal 分配一个全局单递增的唯一 ID,称之为事务 ID(即 zxid),由于 Zab 协议需要保证每一个消息的严格的顺序关系,因此必须将每一个 proposal 按照其 zxid 的先后顺序进行排序和处理。
Zab 协议实现的作用
-
使用一个单一的主进程(Leader)来接收并处理客户端的事务请求(也就是写请求),并采用了 Zab 的原子广播协议,将服务器数据的状态变更以 事务 proposal (事务提议)的形式广播到所有的副本(Follower)进程上去。
-
保证一个全局的变更序列被顺序引用。
Zookeeper 是一个树形结构,很多操作都要先检查才能确定是否可以执行,比如 P1 的事务 t1 可能是创建节点"/a",t2 可能是创建节点"/a/bb",只有先创建了父节点"/a",才能创建子节点"/a/b"。为了保证这一点,Zab 要保证同一个 Leader 发起的事务要按顺序被 apply,同时还要保证只有先前 Leader 的事务被 apply 之后,新选举出来的 Leader 才能再次发起事务。
-
当主进程出现异常的时候,整个 zk 集群依旧能正常工作。
使用 ZooKeeper 实现 Leader 选举
假设一个集群中有 N 个节点。下面是一个通过 ZooKeeper 来实现 Leader 选举的简单流程:
- 所有节点都创建了一个有序临时 znode,它们路径相同,
/app/leader_election/guid_。 - ZooKeeper 集成会将 10 位序列号附加到路径上,创建的 znode 将是
/app/leader_election/guid_0000000001,
/app/leader_election/guid_0000000002...。
- 让 znode 最小的节点成为 leader,其他节点都是 follower。
- 每个 follower 节点都监视序号小于它的前一个 znode。例如:
创建 znode/app/leader_election/guid_0000000008的节点将监视 znode/app/leader_election/guid_0000000007;
创建 znode/app/leader_election/guid_0000000007的节点将监视 znode/app/leader_election/guid_0000000006。
- 如果 leader 下线,那么它对应的 znode
/app/leader_election/guid_000000000N被删除。 - 下一个 follower 节点将通过 watcher 获得关于 leader 移除的通知。
- 下一个 follower 节点将检查是否有其他最小的 znode。如果没有,那么它将承担领导者的角色。否则,它将查找创建 znode 中序列数字最小的节点作为 leader。
- 类似地,所有其他跟随节点选择创建 znode 中序列数字最小的节点作为 leader。
领导选举的最后一步是领导激活。新当选的领导者提出一个 NEW_LEADER 提议,只有在 NEW_LEADER 提议被集合中的大多数服务器(法定人数)认可之后,领导者才会被激活。在提交 NEW_LEADER 提案之前,新的领导者不会接受新的提案。因此, 集群中存活的服务器数必须过半数,否则领导者将永远不会被激活。
原子广播(Atomic Broadcast)
ZooKeeper 中所有写请求都会被转发给 leader。领导者向集合中的追随者广播更新。只有在大多数追随者承认他们坚持了更改之后,领导者才会提交更新。ZooKeeper 使用 ZAB 协议来达成共识,它被设计成原子的。因此,更新要么成功,要么失败。在 leader 故障时,集合中的其他服务器输入 leader 选举算法,在它们之间选举一个新的 leader。
ZooKeeper 中的事务实现
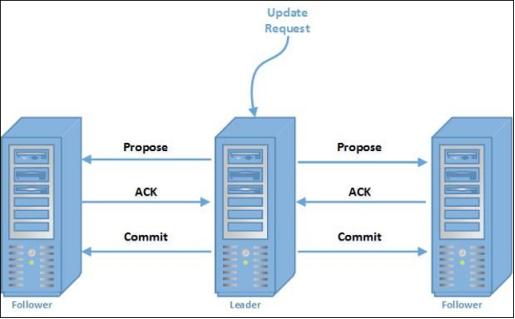
ZAB 保证了事务交付和事务提交中的严格顺序。
练习问题
-
ZooKeeper 中的数据寄存器称为___。
a.ZooKeeper Ensemble
b.ZNODES
c.Watcher
d.Leader答案
b
-
在显式删除之前,哪种类型的 znode 在 ZooKeeper 的命名空间中具有生命周期?
a.Ephemeral Sequential
b.Persistent
c.Persistent Sequential答案
b & c
-
下面哪个选项对于触发 ZooKeeper Watch 是正确的?
a.对 znode 数据的任何更改,例如使用 setData 操作将新数据写入 znode 的数据字段。
b.对 znode 子节点的任何更改。例如,使用 delete 操作删除 znode 的子节点。
c.创建或删除 znode,这可能发生在将新的 znode 添加到路径或删除现有 znode 的情况下。
d.以上所有答案
d
-
考虑下面的语句,找到正确的选项:
A:ZAB 协议确保集群中的本地副本永远不会偏离。
B: ZAB 协议是原子性的,因此该协议保证更新成功或失败。
A. 只有 A 是正确的
B. 只有 B 是正确的
c. A 和 B 都是真的
d. A 和 B 都是假的答案
c
小结
在本章中,你学习了:
- 客户端可以通过连接到集成的任何成员来连接到 ZooKeeper 服务。
- ZooKeeper 允许分布式进程通过数据寄存器的共享分层命名空间相互协调。
- ZooKeeper 数据模型中的每个 znode 都维护一个 stat 结构,该结构简单地提供 znode 的元数据。
- Stat 结构有 4 个不同的信息:
- 版本号
- 动作控制列表
- 时间戳
- 数据长度
- ZooKeeper 主要有两种类型的 znode: persistent 和 ephemeral。还有第三种类型称为 sequential znode,它是另外两种类型的一种限定符。
- watch 是一种简单的机制,让客户端获得关于 ZooKeeper 集合变化的通知。
- watch 只触发一次。如果客户端希望再次收到通知,则必须仓鞥捏 in 设置监听(比如通过 Get 操作)。
- ZooKeeper 确保 watch 始终按照先进先出(FIFO)的方式进行排序,通知始终按照顺序发送。
- ZooKeeper 中的所有读操作——getData()、getChildren()和 exists() - 都可以设置一个通知客户端的监视(对应四个 ZkCli 命令: get、ls、ls2 和 stat)。
- 在服务器集合中,一个服务器被选为 leader,其余的服务器被选为 follower。leader 负责处理所有更改 ZooKeeper 服务的事务请求。追随者收到领导者的广播后更新数据。
- ZAB (ZooKeeper Atomic Broadcast)是一种原子消息传递协议,它确保集成中的本地副本的数据一致性。
Views: 504