
基础环境:百度网盘,提取码:NIIT
--来自百度网盘超级会员V4的分享)
- Linux: CentOS 7
- JDK: 1.8
- Hadoop: 2.7.3
- HBase: 1.2.4
- Hive: 1.2.2
Storm版本选择: 2.1.0
参考文档:http://storm.apachecn.org/#/docs/25?id=%e8%ae%be%e7%bd%aestorm%e9%9b%86%e7%be%a4
安装ZooKeeper集群
Storm 使用 Zookeeper 协调管理集群. Zookeeper 并不是 用于消息传递, 所以 Storm 对Zookeeper造成的负载压力非常低. 单节点Zookeeper集群在大多数情况下应该是足够的,但是如果您想要故障转移或部署大型Storm集群,则可能需要较大的Zookeeper集群. 部署Zookeeper的说明是这里.
这里我们安装一个单机伪分布式的Zookeeper集群:
conf/zoo_1.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/hadoop/tmp/zk1/data
dataLogDir=/home/hadoop/tmp/zk1/dataLog
clientPort=2181
4lw.commands.whitelist=*
server.1=localhost:2891:3891
server.2=localhost:2892:3892
server.3=localhost:2893:3893conf/zoo_2.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/hadoop/tmp/zk2/data
dataLogDir=/home/hadoop/tmp/zk2/dataLog
clientPort=2182
4lw.commands.whitelist=*
server.1=localhost:2891:3891
server.2=localhost:2892:3892
server.3=localhost:2893:3893conf/zoo_3.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/hadoop/tmp/zk3/data
dataLogDir=/home/hadoop/tmp/zk3/dataLog
clientPort=2183
4lw.commands.whitelist=*
server.1=localhost:2891:3891
server.2=localhost:2892:3892
server.3=localhost:2893:3893在dataDir中创建文件myid内容是1或2或3
echo 1 > /home/hadoop/tmp/zk1/data/myid
echo 2 > /home/hadoop/tmp/zk2/data/myid
echo 3 > /home/hadoop/tmp/zk3/data/myid启动服务
bin/zkServer.sh start conf/zoo_1.cfg
bin/zkServer.sh start conf/zoo_2.cfg
bin/zkServer.sh start conf/zoo_3.cfg关于Zookeeper部署的几点注意事项:
1.在监督(supervision)下运行Zookeeper至关重要,因为Zookeeper是快速失败的,如果遇到任何错误的情况都将退出进程. 有关详细信息,请参阅这里 .
2.建立一个cron定时任务来压缩Zookeeper的数据和事务日志至关重要. Zookeeper守护进程本身不会这样做,如果没有设置cron,Zookeeper将很快耗尽磁盘空间. 有关详细信息,请参阅这里.
Nimbus和worker节点的安装环境
接下来你需要准备Nimbus 和 worker 节点的安装环境:
- Java 8+ (Apache Storm 2.x is tested through travisci against a java 8 JDK)
- Python 2.6.6 (Python 3.x should work too,but is not tested as part of our CI enviornment)
这些依赖版本是Storm已经测试过的. Storm 在不同的Java 或Python版本上也许会存在问题.
下载解压 Storm
接下来,下载一个Storm版本,并解压zip文件到Nimbus和每个worker机器上的某个目录下. Storm版本可以从这里下载.
当前最新的版本是2.2.0,这里使用2.1.0的版本。
我们需要下载:
- apache-storm-2.1.0.tar.gz 二进制包(安装)
- apache-storm-2.1.0-src.tar.gz 源码包(学习用)
也可以使用wget下载,如
wget https://dlcdn.apache.org/storm/apache-storm-2.1.0/apache-storm-2.1.0.tar.gz在storm.yaml中设置必要的配置
Storm 发布包中在目录conf/storm.yaml 下包含一个默认的配置文件. 你可以在[这里](http://github.com/apache/storm/blob/master /conf/defaults.yaml)查看默认值. storm.yaml 中的存在的配置项会覆盖掉 defaults.yaml中相应的配置项. 下面一些配置是集群运行时所必要的:
- storm.zookeeper.servers: 这是一个Storm集群所依赖 Zookeeper 集群的hosts列表. 类似于:
storm.zookeeper.servers:
- "111.222.333.444"
- "555.666.777.888"如果配置的Zookeeper集群不是默认的端口, 你应该设置 storm.zookeeper.port 选项.
- storm.local.dir: Nimbus 和 Supervisor 守护进程需要配置一个本地目录来存储少量状态信息(例如jars包,配置文件等等). 您应该在每个机器上创建该目录,给予适当的权限,然后使用此配置填写目录位置. 例如:
storm.local.dir: "/mnt/storm"如果您在windows下运行Strom,应该如下: yaml storm.local.dir: "C:\\storm-local" 如果您使用相对路径,那么路径是相对于(STORM_HOME). 您也可以使用默认值 $STORM_HOME/storm-local
- nimbus.seeds: worker节点需要知道哪些机器是主机的候选者,以便下载 topology jar和confs(nimbus.host 在1.0之后已经废弃,这里实现了HA). 例如:
nimbus.seeds: ["111.222.333.44"]鼓励您填写机器的FQDN (Fully Qualified Domain Name,全域名)列表. 如果要设置Nimbus HA,则必须解决运行nimbus的所有机器的FQDN.当您只想设置“伪分布式”集群时您可能希望将其保留为默认值,仍然鼓励您填写FQDN.
- supervisor.slots.ports: 对于每个worker节点,您可以使用此配置设置在该计算机上运行的worker数量. 每个worker使用单个端口接收消息,并且此设置定义哪些端口打开以供使用. 如果您在此定义五个端口,那么Storm将分配最多五个worker在本机上运行. 如果您定义了三个端口,Storm将只能运行三个worker. 默认情况下,此设置被配置为在端口6700,6701,6702和6703上运行4个worker:
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703 以上是一些配置的介绍,下面我们的具体配置如下:
storm.zookeeper.servers:
- "hadoop000"
storm.local.dir: "/home/hadoop/app/storm-2.1.0/data"
nimbus.seeds: ["hadoop000"]
storm.zookeeper.port: 2181
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
ui.port: 8082注意:配置storm.zookeeper.servers前面有空格,等等细节很严格。另外ui服务进程的端口8080由于很容易和其他服务冲突,这里改成了8082。
启动Storm进程
-
主节点启动nimbus服务
启动Nimbus。Run the command bin/storm nimbus under supervision on the master machine.
storm nimbus & -
主节点启动UI服务:
Run the Storm UI (a site you can access from the browser that gives diagnostics on the cluster and topologies) by running the command “bin/storm ui” under supervision. The UI can be accessed by navigating your web browser to http://{ui host}:8080. by default
但是由于之前在配置文件中已经将UI端口修改成8082(避免和tomcat的8080冲突), 因此现在的访问方式是http://{ui host}:8082
bin/storm ui & -
在从节点(工作节点)上启动supervisor服务(只不过目前是配置的伪分布式,所有服务都是在一个节点上,没有备用节点):
storm supervisor & -
用jps判断是否启动成功(如果失败,则检查日志)
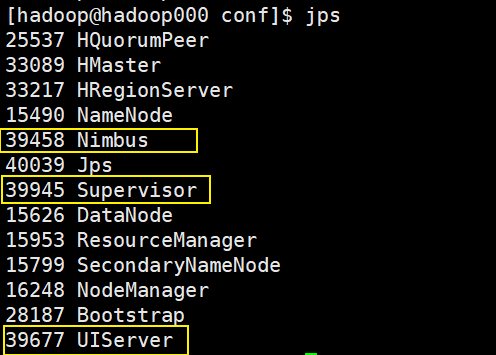
-
避免打印信息或者报错信息出现在屏幕上
为了避免打印信息或者报错信息出现的屏幕上,也可以这样
bin/storm ui >/dev/null 2>&1 &其中,2>&1 是将标准出错重定向到标准输出,但是最好的方式是采用
nohup方式运行。nohup命令:如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束,那么可以使用nohup命令。该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。nohup就是不挂起的意思( no hang up), 像这样:nohup ./bin/storm nimbus > /dev/null 2>&1 & nohup ./bin/storm supervisor > /dev/null 2>&1 & nohup ./bin/storm ui > /dev/null 2>&1 &
查看UI界面
访问http://hadoop000:8082/ (端口是在配置文件中配置过的)
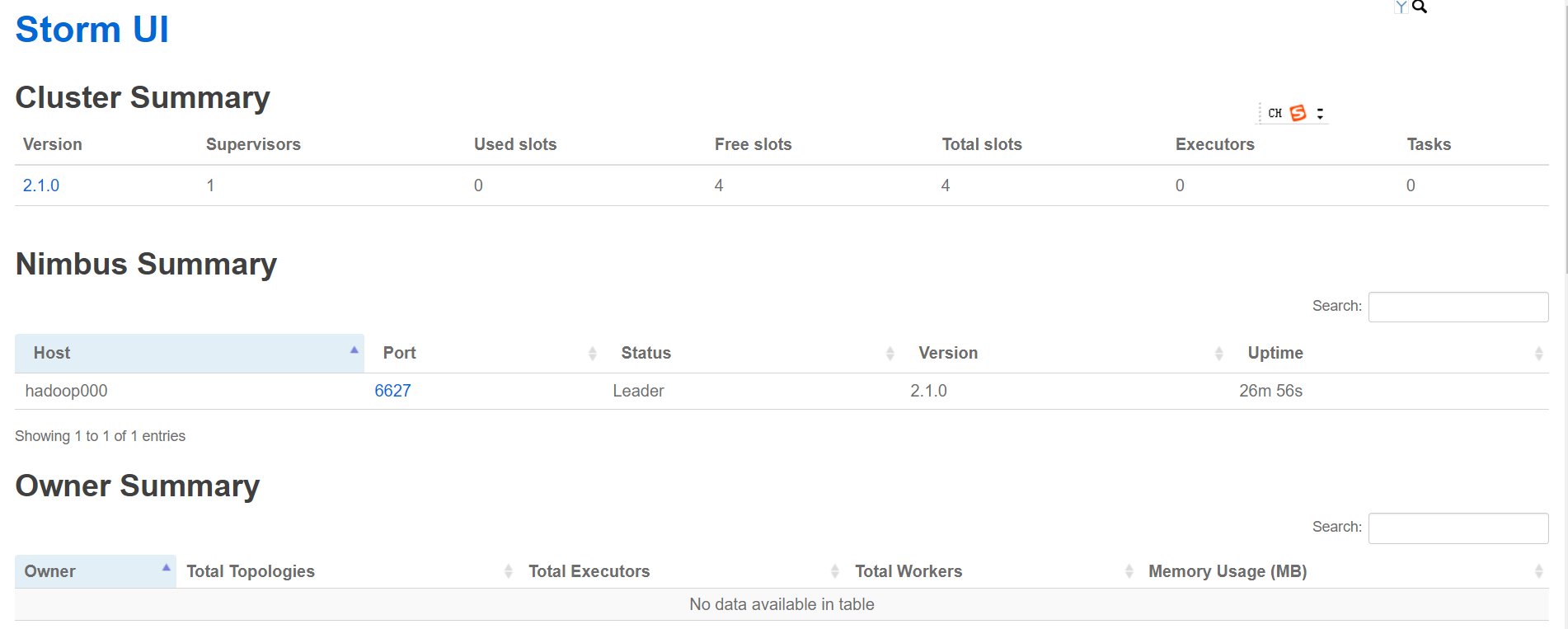
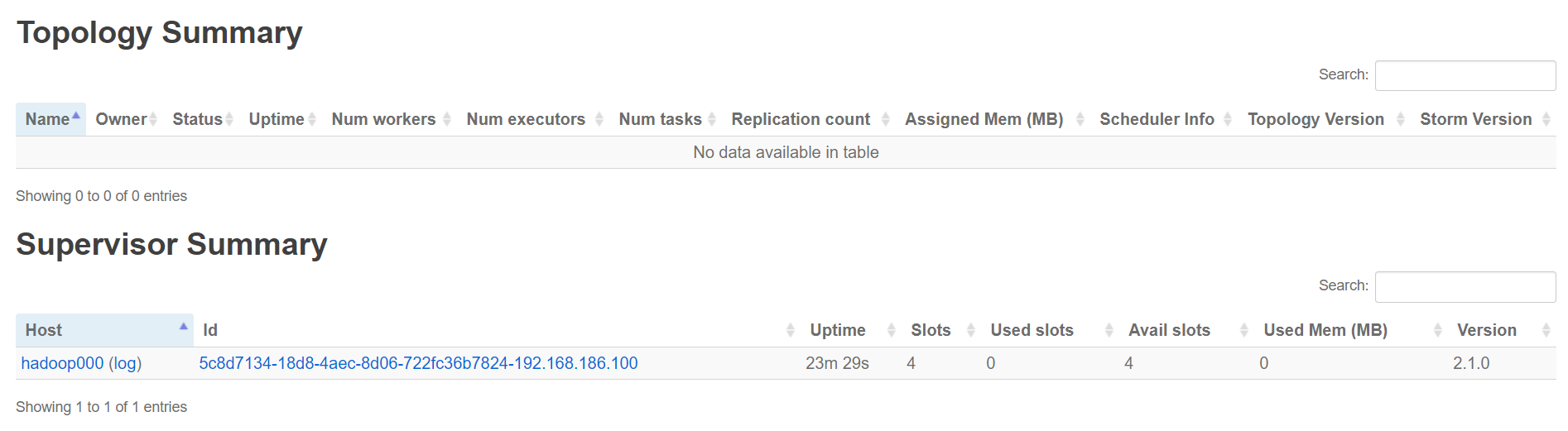
Numbus的配置超级繁杂, 有14页之多
查看log
log日志在storm包的logs文件夹中
如果想要在UI界面点击主机名或者端口号查看日志,则对应的机器需要开启logviewer服务
storm logviewer &配置集群
假设当前机器hadoop001作为主节点, 如果要增加从节点机器hadoop002和hadoop003`,只需要修改如下:
storm.zookeeper.servers:
- "hadoop001"
- "hadoop002"
- "hadoop003"
storm.local.dir: "/home/hadoop/app/storm-2.1.0/data"
nimbus.seeds: ["hadoop001"]
storm.zookeeper.port: 2181
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
ui.port: 8082 给bin目录的文件添加可执行权限:
bin> chmod u+x *开启nimbus和ui后台进程,把整个安装文件夹使用scp命令复制到其他两台机器(需要提前配置好通信机器之间的ssh免密访问),清空logs和data文件夹里面的内容,给bin目录的文件添加可执行权限,开启supervisor进程,这样就准备好集群环境了。
打开UI界面查看 可以看到Nimbus是hadoop001, 而supervisor是hadoop002和hadoop003
Cluster Summary
| Version | Supervisors | Used slots | Free slots | Total slots | Executors | Tasks |
|---|---|---|---|---|---|---|
| 2.1.0 | 2 | 0 | 8 | 8 | 0 | 0 |
Nimbus Summary
Search:
| Host | Port | Status | Version | Uptime |
|---|---|---|---|---|
| hadoop001 | 6627 | Leader | 2.1.0 | 9m 16s |
Showing 1 to 1 of 1 entries
Owner Summary
Search:
| Owner | Total Topologies | Total Executors | Total Workers | Memory Usage (MB) |
|---|---|---|---|---|
| No data available in table |
Showing 0 to 0 of 0 entries
Topology Summary
Search:
| Name | Owner | Status | Uptime | Num workers | Num executors | Num tasks | Replication count | Assigned Mem (MB) | Scheduler Info | Topology Version | Storm Version |
|---|---|---|---|---|---|---|---|---|---|---|---|
| No data available in table |
Showing 0 to 0 of 0 entries
Supervisor Summary
Search:
| Host | Id | Uptime | Slots | Used slots | Avail slots | Used Mem (MB) | Version |
|---|---|---|---|---|---|---|---|
| hadoop002 (log) | d8412147-0dbb-4933-a2d3-1bb28c806dc2-192.168.186.102 | 10m 33s | 4 | 0 | 4 | 0 | 2.1.0 |
| hadoop003 (log) | 57798559-c338-4844-9e29-eb9aa99fa2fe-192.168.186.103 | 1m 7s | 4 | 0 | 4 | 0 | 2.1.0 |
Showing 1 to 2 of 2 entries
Nimbus Configuration
Show entries
Search:
| Key | Value |
|---|---|
| blacklist.scheduler.reporter | "org.apache.storm.scheduler.blacklist.reporters.LogReporter" |
| blacklist.scheduler.resume.time.secs | 1800 |
| blacklist.scheduler.strategy | "org.apache.storm.scheduler.blacklist.strategies.DefaultBlacklistStrategy" |
| blacklist.scheduler.tolerance.count | 3 |
| blacklist.scheduler.tolerance.time.secs | 300 |
| client.blobstore.class | "org.apache.storm.blobstore.NimbusBlobStore" |
| dev.zookeeper.path | "/tmp/dev-storm-zookeeper" |
| drpc.authorizer.acl.filename | "drpc-auth-acl.yaml" |
| drpc.authorizer.acl.strict | false |
| drpc.childopts | "-Xmx768m" |
| drpc.disable.http.binding | true |
| drpc.http.creds.plugin | "org.apache.storm.security.auth.DefaultHttpCredentialsPlugin" |
| drpc.http.port | 3774 |
| drpc.https.keystore.password | "" |
| drpc.https.keystore.type | "JKS" |
| drpc.https.port | -1 |
| drpc.invocations.port | 3773 |
| drpc.invocations.threads | 64 |
| drpc.max_buffer_size | 1048576 |
| drpc.port | 3772 |
Showing 1 to 20 of 266 entries
为nimbus配置高可用
最后, 尽管前面我们使用了三台机器搭建了集群,由于nimbus服务没有配置高可用, 实际上还是算伪分布式。为nimbus配置高可用也非常简单, 比如说让hadoop001和hadoop002其中一个作为主节点,另一个作为备用主节点,则配置如下:
nimbus.seeds: ["hadoop001", "hadoop002"]Nimbus Summary
Search:
| Host | Port | Status | Version | Uptime |
|---|---|---|---|---|
| hadoop001 | 6627 | Leader | 2.1.0 | 9m 16s |
| hadoop002 | 6627 | Follower | 2.1.0 | ... |
作业
使用Centos7系统搭建Storm集群, 将搭建过程形成笔记,并附上截图。
练习
在互联网上查询Twitter是如何使用storm进行情感分析的,了解storm的重要性以及用途。
Views: 889