
01 Spark集群启动原理
Spark集群启动时,会在当前节点(脚本执行节点)上启动Master,在配置文件conf/slave中指定的每个节点上启动一个Worker。而Spark集群是通过脚本启动的。
查看启动脚本的内容:
$ cat sbin/start-all.sh内容:
#!/usr/bin/env bash
#启动所有spark守护进程
#在此节点上启动Master
#在conf/slave中指定的每个节点上启动一个Worker
#如果SPARK_HOME环境变量为空,则使用export设置
if [ -z "${SPARK_HOME}" ]; then
export SPARK_HOME="$(cd "<code>dirname "$0""/..; pwd)"
fi
#加载Spark配置
. "${SPARK_HOME}/sbin/spark-config.sh"
#启动Master
"${SPARK_HOME}/sbin"/start-master.sh
#启动Workers
"${SPARK_HOME}/sbin"/start-slaves.sh从启动脚本的内容和注释可以看出,start-all.sh脚本主要做了四件事:
(1)检查并设置环境变量
(2)加载Spark配置
Spark配置的加载,使用了脚本文件sbin/spark-config.sh。
(3)启动Master进程
Master进程的启动,使用了脚本文件sbin/start-master.sh。
(4)启动Worker进程
Worker进程的启动,使用了脚本文件sbin/start-slaves.sh,该文件负责批量启动集群中各个节点上的Worker进程。
02 Spark应用程序提交原理
Spark应用程序的提交入口是spark-submit脚本。除此之外,也可以使用spark-shell脚本和spark-sql脚本进入交互式命令行执行Spark程序。
查看spark-shell脚本的内容:
$ cat bin/spark-shell内容关键代码:
#!/usr/bin/env bash
......
function main() {
if $cygwin; then
stty -icanon min 1 -echo > /dev/null 2>&1
export SPARK_SUBMIT_OPTS="$SPARK_SUBMIT_OPTS -Djline.terminal=unix"
"${SPARK_HOME}"/bin/spark-submit --class org.apache.spark.repl.Main --name
"Spark shell" "$@"
stty icanon echo > /dev/null 2>&1
else
export SPARK_SUBMIT_OPTS
"${SPARK_HOME}"/bin/spark-submit --class org.apache.spark.repl.Main --name
"Spark shell" "$@"
fi
}
......从关键代码可以看出,spark-shell脚本调用了应用程序提交脚本spark-submit,并传入了org.apache.spark.repl.Main类和使用spark-shell命令时的所有参数(例如--master)。通过org.apache.spark.repl.Main类启动的spark-shell将进入REPL模式(交互式编程环境),一直等待用户的输入,除非手动退出。
查看spark-sql脚本的内容:
$ cat bin/spark-sql代码如下:
#!/usr/bin/env bash
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
export _SPARK_CMD_USAGE="Usage: ./bin/spark-sql [options] [cli option]"
exec "${SPARK_HOME}"/bin/spark-submit --class
org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver "$@"从上述代码可以看出,spark-sql脚本同样调用了应用程序提交脚本spark-submit。这说明,无论采用哪种方式提交应用程序,都间接的调用了spark-submit脚本。查看spark-submit脚本的内容,发现最后一行有如下代码:
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@“可以看出,最后使用exec命令执行了脚本bin/spark-class,并传入了org.apache.spark.deploy.SparkSubmit类和使用spark-submit命令时的所有参数。脚本bin/spark-class用于执行Spark应用程序并启动JVM进程,而这里执行的正是SparkSubmit类。
从上面的分析可以总结出,若通过spark-shell进行启动,将默认传入以下参数:
org.apache.spark.deploy.SparkSubmit
--class org.apache.spark.repl.Main
--name "Spark shell"若通过spark-submit提交应用程序,将默认传入以下参数:
org.apache.spark.deploy.SparkSubmit03 Spark作业工作原理
在学习Spark作业的工作原理时,通常会引入Hadoop MapReduce的工作原理作为入门比较,因为MapReduce与Spark的工作原理有很多相似之处。
1、MapReduce工作原理
MapReduce计算模型主要由三个阶段组成:Map阶段、Shuffle阶段、Reduce阶段。
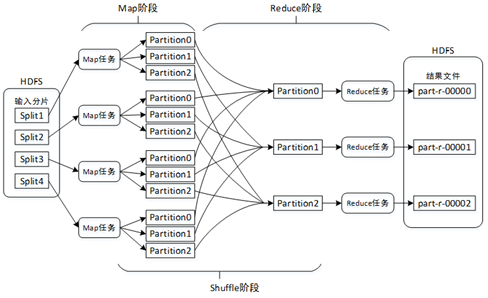
(1)Map阶段
将输入的多个分片(Split)由Map任务以完全并行的方式处理。每个分片由一个Map任务来处理。默认情况下,输入分片的大小与HDFS中数据块(Block)的大小是相同的,即文件有多少个数据块就有多少个输入分片,也就会有多少个Map任务。从而可以调整HDFS数据块的大小来间接改变Map任务的数量。
每个Map任务对输入分片中的记录按照一定的规则解析成多个<key,value>对。默认将文件中的每一行文本内容解析成一个<key,value>对,key为每一行的起始位置,value为本行的文本内容。然后将解析出的所有<key,value>对分别输入到map()方法中进行处理(map()方法一次只处理一个<key,value>对)。map()方法将处理结果仍然是以<key,value>对的形式进行输出。
在数据溢写到磁盘之前,会对数据进行分区(Partition)。分区的数量与设置的Reduce任务的数量相同(默认Reduce任务的数量为1,可以在编写MapReduce程序时对其修改)。这样每个Reduce任务会处理一个分区的数据,可以防止有的Reduce任务分配的数据量太大,而有的Reduce任务分配的数据量太小,从而可以负载均衡,避免数据倾斜。数据分区的划分规则为:取<key,value>对中key的hashCode值,然后除以Reduce任务数量后取余数,余数则是分区编号,分区编号一致的<key,value>对则属于同一个分区。因此,key值相同的<key,value>对一定属于同一个分区,但是同一个分区中可能有多个key值不同的<key,value>对。由于默认Reduce任务的数量为1,而任何数字除以1的余数总是0,因此分区编号从0开始。
(2)Reduce阶段
Reduce阶段首先会对Map阶段的输出结果按照分区进行再一次合并,将同一分区的<key,value>对合并到一起,然后按照key对分区中的<key,value>对进行排序。
每个分区会将排序后的<key,value>对按照key进行分组,key相同的<key,value>对将合并为<key,value-list>对,最终每个分区形成多个<key,value-list>对。例如,key中存储的是用户ID,则同一个用户的<key,value>对会合并到一起。
排序并分组后的分区数据会输入到reduce()方法中进行处理,reduce()方法一次只能处理一个<key,value-list>对。
最后,reduce()方法将处理结果仍然以<key,value>对的形式通过context.write(key,value)进行输出。
(3)Shuffle阶段
Shuffle阶段所处的位置是Map任务输出后,Reduce任务接收前。主要是将Map任务的无规则输出形成一定的有规则数据,以便Reduce任务进行处理。
总结来说,MapReduce的工作原理主要是:通过Map任务读取HDFS中的数据块,这些数据块由Map任务以完全并行的方式处理;然后将Map任务的输出进行排序后输入到Reduce任务中;最后Reduce任务将计算的结果输出到HDFS文件系统中。
2、Spark工作原理
典型的Spark作业(Job)的工作流程如图:
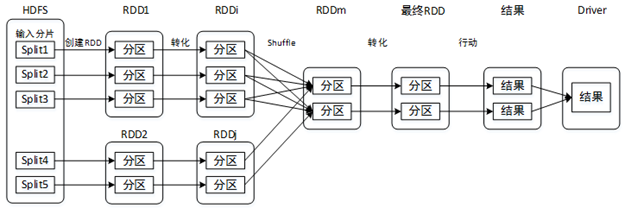
(1)从数据源(本地文件、HDFS、HBase等)读取数据并创建RDD。
(2)对RDD进行一系列的转化操作。
(3)对最终RDD执行行动操作,开始一系列的计算,产生计算结果。
(4)将计算结果发送到Driver端,进行查看和输出。
04 Spark检查点原理
通过调用SparkContext的setCheckpointDir()方法指定检查点数据的存储路径,即把RDD数据放到什么位置,通常是放到HDFS中(如果在集群中运行,则必须是HDFS目录)。
总结来说,RDD检查点的运行流程如下:
(1)通过SparkContext的setCheckpointDir()方法设置RDD检查点数据的存储路径。
(2)调用RDD的checkpoint()方法将RDD标记为检查点。
(3)当在RDD上运行一个作业后,会立即触发RDDCheckpointData中的checkpoint()方法。
(4)在checkpoint()方法中又执行了doCheckpoint()方法。
(5)doCheckpoint()方法中执行了writeRDDToCheckpointDirectory()方法。
(6)writeRDDToCheckpointDirectory()方法内部通过调用runJob()方法运行一个作业,真正将RDD数据写入到检查点目录中,写入完成后返回一个ReliableCheckpointRDD实例。
Views: 90