
项目架构
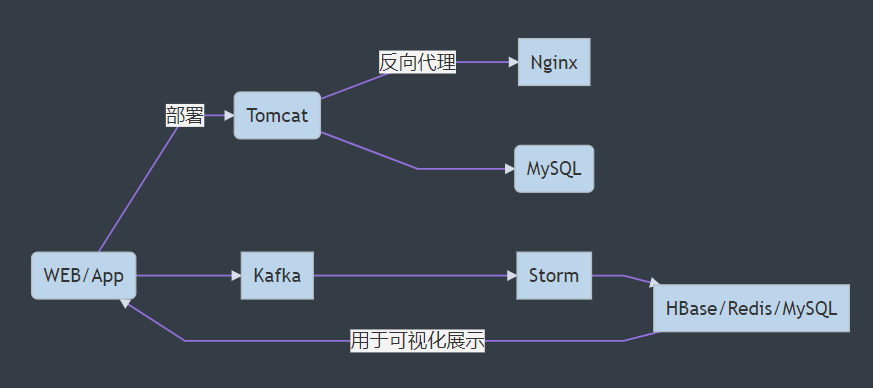
基本要求
- 主题相关的WebAPP
- 1个首页和若干功能页面
- 有生成数据的能力(实际展示的时候,为了有更多丰富的数据, 允许使用脚本生成假数据)
- KafkaProducer 直接将需要采集的信息发送到Storm
- 分析结果的图表展示
- echarts, 或者其他图表库
- Jquery的ajax库
- json
- echarts, 或者其他图表库
- 其他要求:
- 参照Alibaba的Java开发手册的规约
- 代码中适当添加注释
- 部署到服务器(虚拟机或者购买的服务器)
- JavaWeb程序需要部署到 Tomcat
- Nginx 实现反向代理
- 实时数据分析
- kafka -> storm
- 持久化到数据库(HBase,MySQL,Redis)
- 最好每个团队成员都有一个完整的实时分析流程
- 每个团队最少有两种实时分析, 不同类型(不要过于简单,分析的内容要能体现实时性)
开发流程建议
-
确定需求和分工
-
学习使用版本控制工具(Gitee 码云 / Github)
-
统一消息格式,建议使用JSON
-
开发时先采用本地的Tomcat和Storm环境测试
-
本地环境测试时可以远程连接服务器上的的Kafka和Hbase
没问题再使用Tomcat和Nginx部署到服务器
-
将拓扑上传到Storm集群中运行
-
联调所有模块
-
完善SRS报告
记录整个项目的需求, 架构, 开发、部署、测试的详细过程
-
每个人准备PPT, 视频等交付资料
-
每周使用在线表格记录项目进度情况
WebApp开发
采用前后端分离的模式开发和部署
后端可以采用基于tomcat的普通JavaWeb应用或者SpringBoot项目
消息传递
一般项目可以使用kafka-clients依赖里的KafkaProducer API来发送消息到Kafka, 这样便于快速调试.
对于SpringBoot项目,可以使用spring-kafka依赖.
kafka相关配置
spring:
kafka:
bootstrap-servers: hadoop000:9092,hadoop000:9093,hadoop000:9094
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
client-id: app-pro-cli
acks: 1
retries: 3
consumer:
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
client-id: app-pro-cli
group-id: g1Kafka的初始化配置
package cn.delucia.project.conf;
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class KafkaInitConf {
@Value("${app.kafka-topic}")
private String kafkaTopic;
@Value("${app.topic-partitions}")
private Integer topicPartitions;
// 创建一个Topic并设置分区数和副本数
@Bean
public NewTopic initialTopic() {
return new NewTopic(kafkaTopic, 1, (short) 1);
}
// 如果要修改分区数,只需修改配置值重启项目即可
// 修改分区数并不会导致数据的丢失,但是分区数只能增大不能减小
@Bean
public NewTopic updateTopic() {
return new NewTopic(kafkaTopic, topicPartitions, (short) 1);
}
}在控制器类中注入kafkaTemplate并调用send方法发送消息, 例如:
@Slf4j
@RestController
public class GreetingController {
@Autowired
private KafkaTemplate<Object, String> kafkaTemplate;
public Greeting greeting(@RequestParam(value = "name", defaultValue = "农场主") String name) {
Greeting greeting = new Greeting(counter.incrementAndGet(), name);
try {
String s = new ObjectMapper().writeValueAsString(greeting);
// 带回调的生产者
kafkaTemplate.send(kafkaTopic, "Greeting:" + s).addCallback(success -> {
// 消息发送到的topic
String topic = Objects.requireNonNull(success).getRecordMetadata().topic();
// 消息发送到的分区
int partition = success.getRecordMetadata().partition();
// 消息在分区内的offset
long offset = success.getRecordMetadata().offset();
log.info("发送消息成功: {}-{}-{}, Greeting:{}", topic, partition, offset, s);
}, failure -> {
log.info("发送消息失败: {}", failure.getMessage());
});
} catch (JsonProcessingException e) {
log.info("解析Json格式失败: {}", e.getMessage());
}
...
}
}安装Tomcat
准备:安装Java JDK1.8
这里安装openjdk是因为比较简单, 工作场合一定要使用oracle提供的jdk1.8
sudo yum -y install java-1.8.0-openjdk*这样安装的好处就是环境变量都配好了
可以直接查看版本 java -version
Tomcat安装
下载页面: https://tomcat.apache.org/download-90.cgi
文档:https://tomcat.apache.org/tomcat-9.0-doc/index.html
wget https://mirrors.tuna.tsinghua.edu.cn/apache/tomcat/tomcat-9/v9.0.41/bin/apache-tomcat-9.0.41.tar.gz解压到后改名tomcat9
tar -zxvf apache-tomcat-9.0.41.tar.gz -C ~/app
cd ~/app
mv apache-tomcat-9.0.41/ tomcat9默认tomcat端口是8080, 为了避免冲突, 这里修改为18080
$ vi ~/app/tomcat9/conf/server.xml
69 <Connector port="18080" protocol="HTTP/1.1"
70 connectionTimeout="20000"
71 redirectPort="8443" />
启动: 进入 /bin目录下 运行startup.sh脚本文件
$ ./startup.sh
Using CATALINA_BASE: /home/hadoop/app/tomcat9
Using CATALINA_HOME: /home/hadoop/app/tomcat9
Using CATALINA_TMPDIR: /home/hadoop/app/tomcat9/temp
Using JRE_HOME: /home/hadoop/app/jdk1.8.0_211
Using CLASSPATH: /home/hadoop/app/tomcat9/bin/bootstrap.jar:/home/hadoop/app/tomcat9/bin/tomcat-juli.jar
Tomcat started.检查tomcat进程信息
$ bin]$ ps -ef | grep tomcat
hadoop 15142 1 1 14:41 pts/0 00:00:05 /home/hadoop/app/jdk1.8.0_211/bin/java -Djava.util.logging.config.file=/home/hadoop/app/tomcat9/conf/logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djdk.tls.ephemeralDHKeySize=2048 -Djava.protocol.handler.pkgs=org.apache.catalina.webresources -Dorg.apache.catalina.security.SecurityListener.UMASK=0027 -Dignore.endorsed.dirs= -classpath /home/hadoop/app/tomcat9/bin/bootstrap.jar:/home/hadoop/app/tomcat9/bin/tomcat-juli.jar -Dcatalina.base=/home/hadoop/app/tomcat9 -Dcatalina.home=/home/hadoop/app/tomcat9 -Djava.io.tmpdir=/home/hadoop/app/tomcat9/temp org.apache.catalina.startup.Bootstrap start
hadoop 15296 15064 0 14:47 pts/0 00:00:00 grep --color=auto tomcat检查对应的监听端口信息
netstat -anpt | grep 15142网页访问虚拟机主机名或IP地址:18080
为了方便可以为tomcat的安装目录配置环境变量CATALINA_HOME,添加到PATH中
为tomcat添加用户和角色
修改conf/tomcat-users.xml, 添加如下内容
<!--
<role rolename="tomcat"/>
<role rolename="role1"/>
<user username="tomcat" password="tomcat" roles="tomcat"/>
<user username="both" password="tomcat" roles="tomcat,role1"/>
<user username="role1" password="tomcat" roles="role1"/>
-->
<role rolename="manager-gui"/>
<role rolename="manager-script" />
<user username="admin" password="123123" roles="manager-gui,manager-script" />
</tomcat-users>修改webapps/manager/META-INF目录下的context.xml,在allow行的末尾加上|\d+.\d+.\d+.\d+表示允许所有主机访问。
<Context antiResourceLocking="false" privileged="true" >
<Valve className="org.apache.catalina.valves.RemoteAddrValve"
allow="127\.\d+\.\d+\.\d+|::1|0:0:0:0:0:0:0:1|\d+\.\d+\.\d+\.\d+" />
<Manager sessionAttributeValueClassNameFilter="java\.lang\.(?:Boolean|Integer|Long|Number|String)|org\.apache\.catalina\.filters\.CsrfPreventionFilter\$LruCache(?:\$1)?|java\.util\.(?:Linked)?HashMap"/>
</Context>重启tomcat生效
部署项目
一般的javaee项目可以直接build出一个war包进行上传服务器。
SpringBoot默认是打成jar包,如果需要打成war包, 需要修改pom.xml文件:
<groupId>com.niit</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<!-- 这里打成war包 若打jar,需将war改为jar -->
<packaging>war</packaging>
<name>demo</name>
<description>Demo project for Spring Boot</description>然后使用mvn:package构建war包即可,然后上传到服务器的tomcat目录下的webapp文件夹之内。
tomcat 容器的运行机制👇
tomcat默认会加载tomcat目录下的webapp文件夹之内的文件,如
其中ROOT目录下为Tomcat的欢迎页
{kind=link}
examples目录是一些官方示例
tomcat也会默认会加载tomcat目录下的webapp文件夹中下面的war包,并自动解压在webapp下面。
默认的访问方式就是 http://域名:端口号/war包名, 端口号默认是8080
启动tomcat, 浏览器访问 http://hadoop000:18080/demo/
部署SpringBoot项目
项目的服务器设置:
server:
port: 18080
servlet:
context-path: "/project"
#debug: on使用maven的springboot打包插件按照jar包的方式打包
<groupId>com.niit</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<!-- 这里打成war包 若打jar,需将war改为jar -->
<packaging>jar</packaging>
<name>demo</name>
<description>Demo project for Spring Boot</description>然后使用mvn:package打包即可,将打包出来的jar文件重命名然后上传到服务器
在服务器启动项目(需要Java8以上环境)
[hadoop@hadoop000 webapps]$ java -jar demo-jar.jar
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v2.3.0.RELEASE)
如果后台运行可以(推荐)
$ nohup java -jar demo-jar.jar 1> demo.log 2>&1 &浏览器访问 http://hadoop000:18080/project/greeting
配置Nginx反向代理
但是这样带8080端口的访问并不是很好,因此一般都使用nginx反向代理.
通过反向代理将对nginx的80端口的访问请求转发到tomcat的8080端口
首先在物理机hosts文件创建虚拟机主机名和ip的映射
192.168.186.100 hadoop000Nginx安装
安装前确认是否已经安装过
sudo yum search nginxNginx文档: http://nginx.org/en/docs/
Installation on Linux, nginx packages from nginx.org can be used.
Installation instructions
RHEL/CentOS
Debian
Ubuntu
SLES
Alpine
以 CentOS为例进行安装
Install the prerequisites:
sudo yum install yum-utils
To set up the yum repository, create the file named /etc/yum.repos.d/nginx.repo with the following contents:
sudo vi /etc/yum.repos.d/nginx.repo内容如下:
[nginx-stable] name=nginx stable repo baseurl=http://nginx.org/packages/centos/$releasever/$basearch/ gpgcheck=1 enabled=1 gpgkey=https://nginx.org/keys/nginx_signing.key module_hotfixes=true [nginx-mainline] name=nginx mainline repo baseurl=http://nginx.org/packages/mainline/centos/$releasever/$basearch/ gpgcheck=1 enabled=0 gpgkey=https://nginx.org/keys/nginx_signing.key module_hotfixes=true
By default, the repository for stable nginx packages is used. If you would like to use mainline nginx packages, run the following command:
sudo yum-config-manager --enable nginx-mainline
To install nginx, run the following command:
sudo yum install -y nginx
When prompted to accept the GPG key, verify that the fingerprint matches 573B FD6B 3D8F BC64 1079 A6AB ABF5 BD82 7BD9 BF62, and if so, accept it.
Nginx配置
创建java.conf ,进行最简配置
$ cd /etc/nginx/conf.d/
$ sudo cp default.conf java.conf
$ vi java.confURL记住不要忘了加http://前缀
server {
listen 80;
server_name hadoop000;
location / {
proxy_pass http://127.0.0.1:18080;
}
}常用命令
| 解释 | 命令 |
|---|---|
| 安装服务 | yum install nginx |
| 启动服务 | service nginx start |
| 停止服务 | service nginx stop |
| 重载服务 | service nginx reload |
配置完成后启动服务
sudo service nginx start如果服务器已经启动,当配置发生变化可以直接使用重载服务来更新配置,运维常用,因为不需要停止服务就可以重载新的配置。
如果启动失败可以查看错误日志
sudo vi /var/log/nginx/error.log 经过反向代理配置之后,使用浏览器访问 http://hadoop000就相当于访问虚拟机hadoop000的本地服务http://127.0.0.1:18080的效果
如果发现502错误:
2020/11/18 16:12:39 [crit] 16376#16376: *1 connect() to 127.0.0.1:8080 failed (13: Permission denied) while connecting to upstream, client: 192.168.186.1, server: hadoop000, request: "GET /favicon.ico HTTP/1.1", upstream: "http://127.0.0.1:8080/favicon.ico", host: "hadoop000", referrer: "http://hadoop000/"此时需要考虑把linux操作系统默认的强制访问安全限制设置为禁用。
关闭SElinux即可
-
临时关闭 SElinux
sudo setenforce 0 -
永久关闭 SElinux
sudo vim /etc/selinux/config SELINUX=disabled
修改之后就可以正常访问了
配置开机启动
[hadoop@hadoop000 download]$ chkconfig nginx
注意:正在将请求转发到“systemctl is-enabled nginx.service”。
disabled
[hadoop@hadoop000 download]$ chkconfig nginx on
注意:正在将请求转发到“systemctl enable nginx.service”。
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-unit-files ===
Authentication is required to manage system service or unit files.
Authenticating as: root
Password:
==== AUTHENTICATION COMPLETE ===
Created symlink from /etc/systemd/system/multi-user.target.wants/nginx.service to /usr/lib/systemd/system/nginx.service.
==== AUTHENTICATING FOR org.freedesktop.systemd1.reload-daemon ===
Authentication is required to reload the systemd state.
Authenticating as: root
Password:
==== AUTHENTICATION COMPLETE ===
[hadoop@hadoop000 download]$ chkconfig nginx
注意:正在将请求转发到“systemctl is-enabled nginx.service”。
enabled
前后端分离
nginx是一个高性能服务器,除了配置反向代理之外,也非常适合部署静态资源并支持高并发请求, 并且也提供负载均衡的功能。
首先删除默认的配置
# sudo vim /etc/nginx/conf.d/default.conf为了将反向代理请求和静态资源的请求分开,修改我们之前的配置如下:
upstream webapp.server {
server hadoop000:18080;
}
server {
listen 80;
server_name localhost hadoop000;
root /data/www/;
# 静态资源
location / {
index index.html;
access_log /var/log/nginx/java-hadoop.log main;
}
# 反向代理到本地JavaWeb的后台服务
location ^~ /project/ {
proxy_pass http://webapp.server/project/;
}
}
一些说明如下:
- listen 80 是http协议的默认端口,:80 可以省略
- server_name 表示请求路径中的服务器主机名,可配置多个
- /data/www 为站点根目录,需手动创建,权限一般为755
- access_log 对应的路径是应用的服务器日志,文件夹不存在则需手动创建
- location 的匹配规则,优先匹配 /demo/,其次 /
一般来说前后端分离部署应该是部署在不同的服务器上的,这里放在一台服务器上只是为了演示方便。
前端部署
然后将项目的静态页面放到/data/www下即可
后端部署
SpringBoot项目移除静态资源,单独部署在tomcat上,并使用ngixn实现反向代理
实时数据采集
主要技术:Kafka

实时数据流计算
主要技术:Kafka-clients,storm-hbase|storm-redis|storm-mysql
以热力图项目为例, 拓扑代码如下
package com.niit.project;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.hbase.bolt.HBaseBolt;
import org.apache.storm.hbase.bolt.mapper.SimpleHBaseMapper;
import org.apache.storm.kafka.spout.ByTopicRecordTranslator;
import org.apache.storm.kafka.spout.KafkaSpout;
import org.apache.storm.kafka.spout.KafkaSpoutConfig;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.HashMap;
import java.util.Map;
public class KafkaStormProjectApp {
public static String topologyName = "project-topo";
public static final String KAFKA_BROKER = "hadoop000:9092";
public static final String INPUT_TOPIC = "storm-project";
private static class SplitBolt extends BaseRichBolt {
private OutputCollector outputCollector;
@Override
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.outputCollector = collector;
}
@Override
public void execute(Tuple input) {
String id = input.getStringByField("line");
String[] split = id.split(",");
try {
double lng = Double.parseDouble(split[0]);
double lat = Double.parseDouble(split[1]);
this.outputCollector.emit(new Values(id, lng, lat));
} catch (NumberFormatException e) {
System.err.println(e.getMessage());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "lng", "lat"));
}
}
/**
* 计数利用HBase的CountColumn特性
*/
private static class CountBolt extends BaseRichBolt {
private OutputCollector collector;
private final HashMap<String, Long> counts = null;
@Override
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String id = input.getString(0);
double lng = input.getDouble(1);
double lat = input.getDouble(2);
this.collector.emit(new Values(id, lng, lat, 1L));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "lng", "lat", "count"));
}
}
public static void main(String[] args) throws Exception {
final TopologyBuilder builder = new TopologyBuilder();
// storm conf
Config conf = new Config();
conf.setNumAckers(0);
conf.setDebug(true);
// kafka bolt
ByTopicRecordTranslator<String, String> translator =
new ByTopicRecordTranslator<>((r) -> new Values(r.value()), new Fields("line"));
translator.forTopic(INPUT_TOPIC, (r) -> new Values(r.value()), new Fields("line"));
KafkaSpoutConfig<String, String> kafkaSpoutConfig = KafkaSpoutConfig
// bootstrapServers 以及topic
.builder(KAFKA_BROKER, INPUT_TOPIC)
// 设置group.id
.setProp(ConsumerConfig.GROUP_ID_CONFIG, "location")
// ensure at-least-once processing
.setProp(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest")
// 设置开始消费的起始位置
// 设置提交消费边界的时长间隔
.setOffsetCommitPeriodMs(10_000)
//Translator
.setRecordTranslator(translator)
.build();
KafkaSpout<String, String> kafkaSpout = new KafkaSpout<>(kafkaSpoutConfig);
// hbase bolt
Map<String, Object> hbConf = new HashMap<>();
hbConf.put("hbase.rootdir", "hdfs://hadoop000:9000/hbase");
hbConf.put("hbase.zookeeper.quorum", "hadoop000:2181");
conf.put("hbase.conf", hbConf);
conf.setNumWorkers(2); // 设置为1个topology创建2个worker进程
SimpleHBaseMapper mapper = new SimpleHBaseMapper()
.withRowKeyField("id")
.withColumnFields(new Fields("lng","lat"))
.withCounterFields(new Fields("count"))
.withColumnFamily("cf");
HBaseBolt hbaseBolt = new HBaseBolt("project", mapper).withConfigKey("hbase.conf");
// build topology
builder.setSpout("kafka_spout", kafkaSpout);
builder.setBolt("split-bolt", new SplitBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("kafka_spout");
builder.setBolt("count-bolt", new CountBolt())
.fieldsGrouping("split-bolt", new Fields("id"));
builder.setBolt("hbase-bolt", hbaseBolt).globalGrouping("count-bolt");
if (args != null && args.length > 0) {
topologyName = args[0];
StormSubmitter.submitTopology(topologyName, conf, builder.createTopology());
} else {
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology(topologyName, conf, builder.createTopology());
}
}
}
其中聚合操作是利用了HBase的CounterColumn特性
这里没有使用时间窗口Bolt来体现实时,而是利用了HBase表的TTL属性,TTL可以在创建表的时候指定,TTL设置为60即表示表中记录的存活时间为1分钟:
create "project",{NAME => 'cf', MIN_VERSIONS => '0',TTL => '60'}也可以disable表之后使用alter语句对已有表进行修改。
由于插入数据的时候经纬度是采用了Double类型,而计数列采用了Long类型,但是HBase只有使用字节数组这样一种方式进行存储,所以需要程序员自己控制数据类型的转换。在查看表中记录的使用需要这样进行数据类型的转换:
scan 'project', {COLUMNS => ['cf:lng:toDouble','cf:lat:toDouble','cf:count:toLong']}将上传到Storm集群
[kafka-storm-project]$ storm jar project-topology.jar com.niit.demo.KafkaStormProjectTopology project-topo数据可视化
主要技术:百度echarts图表,异步请求图表渲染(Ajax & JSON)
这个热力图项目的前端比较简单,只有一个index.html文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>百度地图</title>
<style>
#main {
position: absolute;
top: 0;
left: 0;
right: 0;
bottom: 0;
width: 100%;
height: 100%;
}
</style>
</head>
<body>
<!-- 为ECharts准备一个具备大小(宽高)的Dom -->
<div id="main"></div>
<!-- jquery 1.11.3 -->
<script type="text/javascript" src="https://cdn.jsdelivr.net/npm/jquery@1.11.3/dist/jquery.min.js"></script>
<!-- bootstrap 3.3.7-->
<script type="text/javascript" src="https://cdn.jsdelivr.net/npm/bootstrap@3.3.7/dist/js/bootstrap.min.js"></script>
<!-- echarts 插件 -->
<script type="text/javascript" src="https://cdn.jsdelivr.net/npm/echarts/dist/echarts.min.js"></script>
<!-- echarts 百度地图插件 -->
<script type="text/javascript" src="https://cdn.jsdelivr.net/npm/echarts/dist/extension/bmap.js"></script>
<script type="text/javascript"
src="https://api.map.baidu.com/api?v=2.0&ak=KOmVjPVUAey1G2E8zNhPiuQ6QiEmAwZu&__ec_v__=20190126"></script>
<script>
var points = [];
var myChart = echarts.init(document.getElementById('main'));
myChart.setOption(option = {
animation: false,
bmap: {
center: [110.337731, 20.064295], // 海南大学
zoom: 18, // 地图缩放等级
roam: true
},
visualMap: {
show: false,
top: 'top',
min: 0,
max: 5,
seriesIndex: 0,
calculable: true,
inRange: {
color: ['blue', 'blue', 'green', 'yellow', 'red']
}
},
series: [{
type: 'heatmap',
coordinateSystem: 'bmap',
data: points,
pointSize: 5,
blurSize: 6
}]
});
// 添加百度地图插件
var bmap = myChart.getModel().getComponent('bmap').getBMap();
bmap.addControl(new BMap.MapTypeControl());
// 禁止拖拽和缩放
bmap.disableDragging();
bmap.disableScrollWheelZoom();
bmap.addEventListener("click", function (e) {
$.post('log', {
lng: e.point.lng,
lat: e.point.lat
});
});
// 10秒更新一次地图
window.setInterval(function () {
$.get(
"points",
function (data) {
for (var i = 0; i < data.length; i++) {
point = [];
for (var j = 0; j < data[i].count; j++) {
points.push([data[i].lng, data[i].lat, 1]);
}
}
option.series.data = points;
myChart.setOption(option);
}
)
}, 10000);
</script>
</body>
</html>其中请求demo/points可以到达后端的SpringBoot项目,并且返回HBase的最新数据,对应的接口如下:
src\main\java\com\niit\demo\service\LocationService.java
package com.niit.demo.service;
import com.niit.demo.entity.Point;
import com.niit.demo.utils.HBaseHelper;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.util.Bytes;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.List;
@Component
public class LocationService {
public List<Point> getLocationList() {
List<Point> list = new ArrayList<>();
ResultScanner scanner = HBaseHelper.getScanner("project");
if (scanner != null) {
scanner.forEach(rowResult -> {
Point point = new Point();
for (Cell cell : rowResult.listCells()) {
String qualifier = Bytes.toString(CellUtil.cloneQualifier(cell));
switch (qualifier) {
case "lng":
point.setLongitude(Bytes.toDouble(CellUtil.cloneValue(cell)));
break;
case "lat":
point.setLatitude(Bytes.toDouble(CellUtil.cloneValue(cell)));
break;
case "count":
point.setCount(Bytes.toLong(CellUtil.cloneValue(cell)));
break;
default:
break;
}
}
list.add(point);
});
}
return list;
}
}
src\main\java\com\niit\demo\IndexController.java
package com.niit.demo;
import com.niit.demo.entity.Point;
import com.niit.demo.service.LocationService;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
@RequestMapping("/")
public class IndexController {
@Autowired
public LocationService service;
Logger logger = LoggerFactory.getLogger(IndexController.class);
@GetMapping("/points")
public List<Point> getPoints() {
return service.getLocationList();
}
@PostMapping("/log")
public void log(double lng, double lat) {
logger.info("{},{}", lng, lat);
}
}
常见问题:
Tomcat项目乱码
Tomcat中部署的JSP页面出现中文乱码问题:
-
修改tomcat/conf目录下的主配置文件server.xml,添加URIEncoding=“UTF-8”配置项,配置位置如下:
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" URIEncoding="UTF-8" /> <Connector protocol="AJP/1.3" address="::1" port="8009" redirectPort="8443" URIEncoding="UTF-8" /> -
修改tomcat/conf/web.xml,在
<servlet>节点中添加如下内容:<init-param> <param-name>fileEncoding</param-name> <param-value>UTF-8</param-value> </init-param>
3.重启服务
Tomcat设为开机自启
- 进入init.d目录
进入到/etc/init.d目录下,命令是:
cd /etc/init.d- 新建一个名为tomcat的文件
vim tomcat- 为/etc/init.d/tomcat文件添加可执行权限
chmod 755 tomcat- 编辑tomcat文件,添加以下内容
vi tomcat添加内容为: 注意CATALINA_HOME需要修改正确
#!/bin/bash
# processname: tomcat9
# chkconfig: 2345 86 16
# description: Tomcat9 start|restart|stop.
if [ -f /etc/init.d/functions ]; then
. /etc/init.d/functions
elif [ -f /etc/rc.d/init.d/functions ]; then
. /etc/rc.d/init.d/functions
else
echo -e "/atomcat: unable to locate functions lib. Cannot continue."
exit -1
fi
RETVAL=$?
CATALINA_HOME=/opt/pkg/tomcat9
case "$1" in
start)
if [ -f $CATALINA_HOME/bin/startup.sh ];
then
echo $"Starting Tomcat"
$CATALINA_HOME/bin/startup.sh
fi
;;
stop)
if [ -f $CATALINA_HOME/bin/shutdown.sh ];
then
echo $"Stopping Tomcat"
$CATALINA_HOME/bin/shutdown.sh
fi
;;
*)
echo $"Usage: $0 {start|stop}"
exit 1
;;
esac
exit $RETVAL
- 把tomcat这个脚本添加到开机启动项里面
chkconfig --add tomcat
chkconfig tomcat on- 如果想看看是否添加成功
chkconfig --list
netconsole 0:关 1:关 2:关 3:关 4:关 5:关 6:关
network 0:关 1:关 2:开 3:开 4:开 5:开 6:关
tomcat 0:关 1:关 2:开 3:开 4:开 5:开 6:关- 在tomcat/bin下创建一个setenv.sh文件,加入以下环境变量, 并赋予执行权限
[root@hadoop000 tomcat9]# vi bin/setenv.sh
export JAVA_HOME=/opt/pkg/jdk1.8.0_261
export JRE_HOME=/opt/pkg/jdk1.8.0_261/jre
export CATALINA_HOME=/opt/pkg/tomcat9
export CATALINA_BASE=/opt/pkg/tomcat9
[root@hadoop000 tomcat9]# chmod a+x bin/setenv.sh- 查看看是否开机启动
使用命令重启机器,命令是:
reboot- 查看网络状态,执行命令,查看8080端口是否启动
netstat -lntup- 查看tomcat进程
ps -ef |grep tomcat- 如果不需要开机启动,从启动脚本删除即可
chkconfig --del tomcatViews: 397