
Kafka分布式消息系统被认为是一种消息引擎系统,或者消息队列中间件。
队列(Queque)是一种先入先出(Fist In First Out - FIFO)的线性表数据结构, 可以使用数组或者链表实现队列, 一个队列需要维护两个指针, head指向队首, tail指向队尾, 移动队尾添加元素(入队), 移动队首指针删除元素(出队).
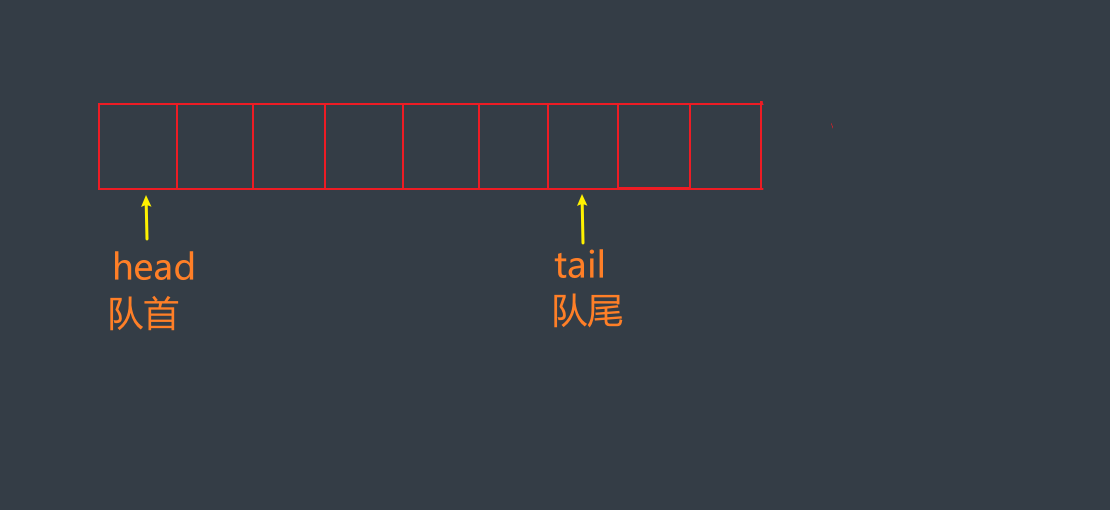
实际生活中,队列的应用随处可见,比如排队、挂号、传递过程都可以用队列来描述或者实现。
什么是消息队列
生产出美味的巧克力需要三道工序:首先将可可豆磨成可可粉,然后将可可粉加热并加入糖变成巧克力浆,最后将巧克力浆灌入模具,撒上坚果碎,冷却后就是成品巧克力了。
最开始的时候,每次研磨出一桶可可粉后,工人就会把这桶可可粉送到加工巧克力浆的工人手上,然后再回来加工下一桶可可粉。这样一来我们很快就发现,其实工人可以不用自己运送半成品,于是在每道工序之间都增加了一组传送带,研磨工人只要把研磨好的可可粉放到传送带上,就可以去加工下一桶可可粉了。 传送带解决了上下游工序之间的“通信”问题。
传送带上线后确实提高了生产效率,但也带来了新的问题:每道工序的生产速度并不相同。在巧克力浆车间,一桶可可粉传送过来时,工人可能正在加工上一批可可粉,没有时间接收。不同工序的工人们必须协调好什么时间往传送带上放置半成品,如果出现上下游工序加工速度不一致的情况,上下游工人之间必须互相等待,确保不会出现传送带上的半成品无人接收的情况。
为了解决这个问题,我们在每组传送的下游带配备了一个暂存半成品的仓库,这样上游工人就不用等待下游工人有空,任何时间都可以把加工完成的半成品丢到传送带上,无法接收的货物被暂存在仓库中,下游工人可以随时来取。传送带配备的仓库实际上起到了“通信”过程中“缓存”的作用。
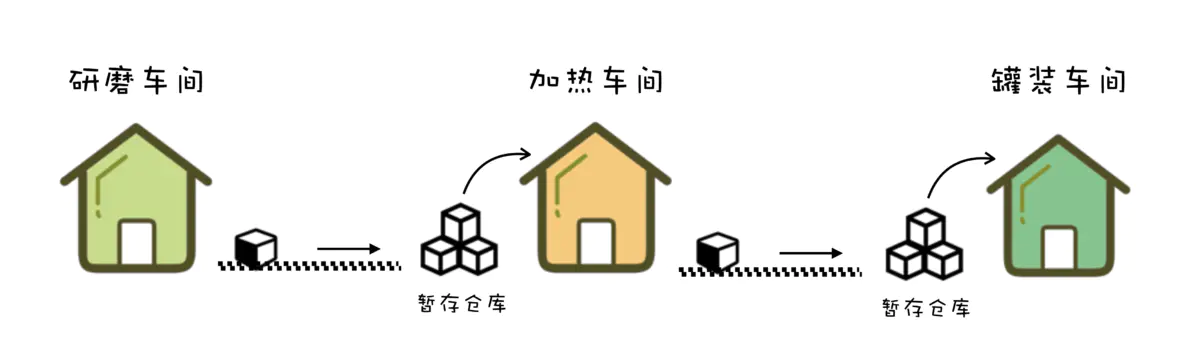
在解决上述问题的过程中, 不知不觉我们就实现了一个消息队列.
队列能解决什么问题?
缓存数据,且保持数据存取顺序一致
为什么使用消息队列
消息异步处理
如需要快速响应的事情集中资源处理,其余的放入消息队列异步完成
很多时候,你不想也不需要立即处理消息。消息队列提供了异步处理机制,允许你把一个消息放入队列,但并不立即处理它。你想向队列中放入多少消息就放多少,然后在你想要处理的时候再去处理它们。
想一想如何设计一个秒杀系统可以达到更高的成交量。
秒杀系统需要解决的核心问题是,如何利用有限的服务器资源,尽可能多地处理短时间内的海量请求。我们知道,处理一个秒杀请求包含了很多步骤,例如:
- 风险控制;
- 库存锁定;
- 生成订单;
- 短信通知;
- 更新统计数据。
能否决定秒杀成功,实际上只有风险控制和库存锁定这 2 个步骤。只要用户的秒杀请求通过风险控制,并在服务端完成库存锁定,就可以给用户返回秒杀结果了,对于后续的生成订单、短信通知和更新统计数据等步骤,并不一定要在秒杀请求中处理完成。
所以当服务端完成前面 2 个步骤,确定本次请求的秒杀结果后,就可以马上给用户返回响应,然后把请求的数据放入消息队列中,由消息队列异步地进行后续的操作。
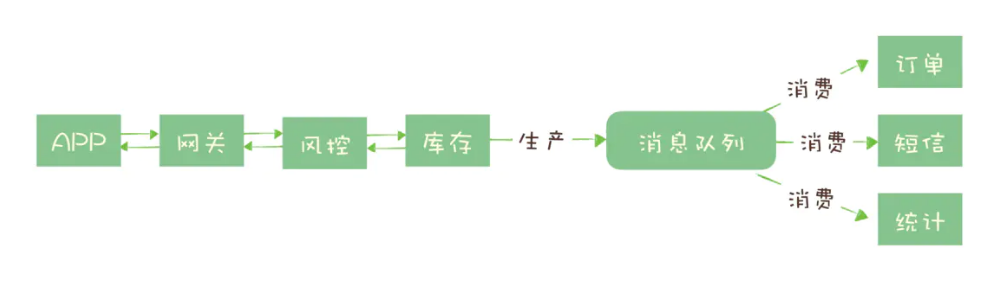
处理一个秒杀请求,从 5 个步骤减少为 2 个步骤,这样不仅响应速度更快,并且在秒杀期间,我们可以把大量的服务器资源用来处理秒杀请求。秒杀结束后再把资源用于处理后面的步骤,充分利用有限的服务器资源处理更多的秒杀请求。
可以看到,在这个场景中,消息队列被用于实现服务的异步处理。这样做的好处是:
- 可以更快地返回结果
- 减少等待,自然实现了步骤之间的并发,提升系统总体的性能。
流量控制
继续说我们的秒杀系统,我们已经使用消息队列实现了部分工作的异步处理,但我们还面临一个问题:如何避免过多的请求压垮我们的秒杀系统?
加入消息队列后,整个秒杀流程变为:
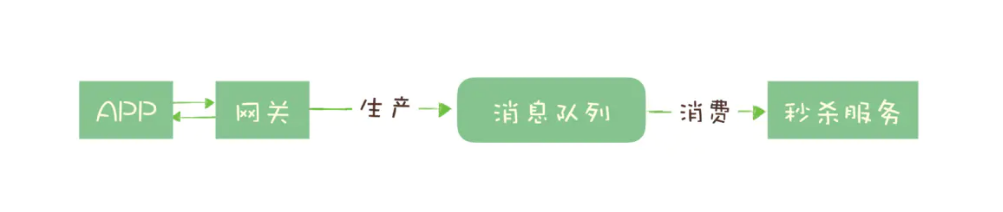
网关在收到请求后,将请求放入请求消息队列;
后端服务从请求消息队列中获取 APP 请求,完成后续秒杀处理过程,然后返回结果。
秒杀开始后,当短时间内大量的秒杀请求到达网关时,不会直接冲击到后端的秒杀服务,而是先堆积在消息队列中,后端服务按照自己的最大处理能力,从消息队列中消费请求进行处理。
这种设计的优点是:能根据下游的处理能力自动调节流量,达到“削峰填谷”的作用。
但这样做同样是有代价的:
增加了系统调用链环节,导致总体的响应时延变长。
上下游系统都要将同步调用改为异步消息,增加了系统的复杂度。
服务解耦
消息队列的另外一个作用,就是实现系统应用之间的解耦。
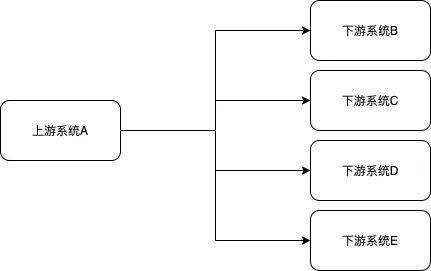
订单是电商系统中比较核心的数据,当一个新订单创建时:
支付系统需要发起支付流程;
风控系统需要审核订单的合法性;
客服系统需要给用户发短信告知用户;
经营分析系统需要更新统计数据;
……
这些订单下游的系统都需要实时获得订单数据。随着业务不断发展,这些订单下游系统不断的增加,不断变化
引入消息队列后,订单服务在订单变化时发送一条消息到消息队列的一个主题 Order 中,所有下游系统都订阅主题 Order,这样每个下游系统都可以获得一份实时完整的订单数据。
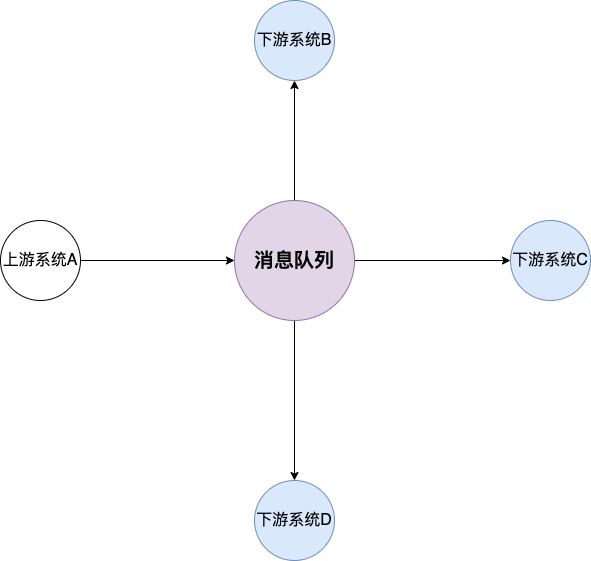
无论增加、减少下游系统或是下游系统需求如何变化,订单服务都无需做任何更改,实现了订单服务与下游服务的解耦。
总结
以上就是消息队列最常被使用的三种场景:异步处理、流量控制和服务解耦。当然,消息队列的适用范围不仅仅局限于这些场景.简单的说,我们在单体应用里面需要用队列解决的问题,在分布式系统中大多都可以用消息队列来解决。
消息队列的选型
- 开源
- 流行, 活跃
- 兼容
- 确保消息的可靠传递
- 支持集群, 高可用
- 性能要求
可供选择的消息队列
1. Rabbit MQ (AMQP协议)
- "messaging that just works"
- 老牌产品
2. Rocket MQ
- Alibaba 2012年开源
- 2017年成为Apache顶级项目
- 经过多次双十一考验, 稳定可靠
3. Kafka
- 也是Apache顶级项目
- 最初设计目的是处理海量日志
- 不保证消息可靠性(可能丢消息)
- 不支持集群
- 当下的Kafka
- 非常成熟的消息队列产品
- 稳定可靠, 功能特性可以满足绝大多数场景要求
- 兼容性好,尤其是大数据和流计算领域优先支持Kafka!!!
- 异步性能最好(同步性能反而较差).
4. 第二梯队
- Active MQ(JMS)
- Zero MQ
- 雅虎Pulsar
Views: 240