
旧文档(3.0.12.RELEASE):
https://docs.spring.io/spring-cloud-stream/docs/3.0.12.RELEASE/reference/html/
Spring Cloud Stream 是一个用来为微服务应用构建消息驱动能力的框架。它可以基于 Spring Boot 来创建独立的,可用于生产的 Spring 应用程序。
它通过使用 Spring Integration 来连接消息代理中间件以实现消息事件驱动。Spring Cloud Stream 为一些供应商的消息中间件产品提供了个性化的自动化配置实现。
常见的消息中间件有:
- RabbitMQ
一个开源的 AMQP 实现, 服务器端用 Erlang 语言编写,支持多种客户端,如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP 等,支持 AJAX、REST、SOAP 等多种通信协议。 - Kafka
一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域。 - ActiveMQ
一个完全支持 JMS1.1 和 J2EE 1.4 规范的 JMS Provider 实现,尽管 JMS 规范出台已经是很久的事情了,但是 JMS 在当今的 J2EE 应用中间仍然扮演着特殊的地位。 - RocketMQ
一个分布式的消息中间件,具有低延迟、高性能、高可靠、亿级并发的特点,适用于大规模分布式系统的高性能场景。经受了阿里双十一的考验,具有丰富的实战经验。
简单地说,Spring Cloud Stream 本质上就是整合了 SpringBoot 和 Spring Integration, 实现了一套轻量级的消息驱动的微服务框架。
Spring Integration 是一个轻量级的消息代理框架,它的主要目的是为了在应用程序之间提供消息发送和接收的功能。
通过使用 Spring Cloud Stream ,可以有效简化开发人员对消息中间件的使用复杂度,让系统开发人员可以有更多的精力关注于核心业务逻辑的处理。
由于 Spring Cloud Stream 基于 Spring Boot 实现,所以它秉承了 Spring Boot 的优点,自动化配置的功能可帮助我们快速上手使用.
早期的版本比如 Spring Cloud Stream 3.0.12.RELEASE, 只支持 RabbitMQ 和 Kafka 两个著名的消息中间件的自动化配置。
最新版本的 Spring Cloud Stream 已经可以支持几乎所有的主流消息中间件,包括:RabbitMQ、Kafka、ActiveMQ、RocketMQ、Redis、Amazon Kinesis 等。
本章节将主要以 RabbitMQ 为例进行 Spring Cloud Stream 的内容讲解。
目标
在本章中,您将学习:
- Spring Cloud Stream 快速入门
- 核心概念
- 绑定器 Binder
- 发布-订阅模式 Publis-Subscribe Pattern
- 消费组 Consumer Group
- 分区 Partitioning
- 使用详解
- 绑定器详解
- 配置详解
Spring Cloud Stream 快速入门
需求:
- 本地安装 RabbitMQ。
- 构建一个基于 Spring Boot 的微服务应用,
- 这个微服务应用将通过使用消息中间件 RabbitMQ 来接收消息并将消息打印到日志中。
RabbitMQ
消息队列 - MQ(message queue)从字面意思上看,本质是个队列,FIFO 先入先出,只不过队列中存放的是 message 而已,还是一种跨进程的通信机制,用于上下游传递消息。在互联网架构中,MQ 是一种非常常见的上下游"逻辑解耦+物理解耦"的消息通信服务。
通过消息队列可以实现应用程序之间的解耦,提高系统的可扩展性和可维护性。消息队列的应用场景非常多,比如异步处理、应用解耦、流量削锋、日志处理、消息通讯、消息广播等。
RabbitMQ 是 MQ 的实现之一, 具体来说它是一个开源的 AMQP 0-9-1(Advanced Message Queuing Protocol) 的实现。
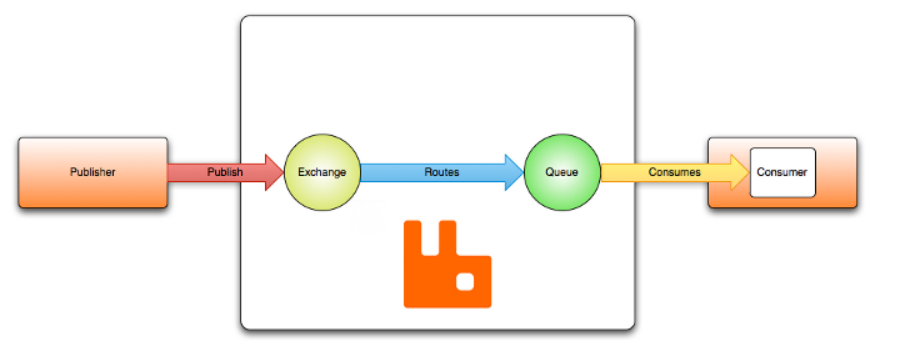
消息代理(Broker)从发布者(publishers)(发布消息的应用程序,也称为生产者)接收消息,并将其路由到消费者(处理这些消息的应用程序)。由于 AMQP 是一个网路协议, 所以发布者、代理和消费者可以在不同的进程中运行, 甚至在不同的主机上运行。
消息被发布到交换机(exchange),交换机可比作邮局或邮箱。然后,交换使用称为绑定(binding)的规则将消息副本分发到队列。然后,代理将消息传递给订阅队列的消费者,或者消费者根据需要从队列中获取/拉取消息。
RabbitMQ 有着运行在所有 Erlang 语言所支持的平台之上的潜力,从嵌入式系统到多核心集群还有基于云端的服务器。为了方便学习和演示,我们将在本地的 windows 系统上配置 RabbitMQ。
RabbitMQ 的安装方式,在其官方网站上有详细的介绍,包括如何下载资源,如何配置,如何启动等。为演示方便我们在 windows 系统上进行 RabbitMQ 安装。
官方文档地址: https://www.rabbitmq.com/install-windows.html 。这里我们下载rabbitmq-server-3.11.15.exe, 安装前请确保已经安装了 erlang。
可以从这里了解到你使用的 rabbitmq 需要安装什么 Erlang 版本.
https://www.rabbitmq.com/which-erlang.html
Erlang 安装: https://erlang.org/download/otp_versions_tree.html
在 Windows 安装 RabbitMQ 具体安装步骤如下:
-
下载 otp_win64_25.3.2.exe 并双击安装。
-
下载 rabbitmq-server-3.11.15.exe 并双击安装。
-
启动 RabbitMQ 服务
rabbitmq_server-3.11.15\sbin>rabbitmq-server.bat start -
激活监控插件
rabbitmq_server-3.11.15\sbin>rabbitmq-plugins enable rabbitmq_management
安装成功之后,在浏览器中访问:http://127.0.0.1:15672 (RabbitMQ 的默认 UI 端口号是 15672, 默认本地登录账户 guest, 密码也是 guest):

之后点击 login 按钮,进入主界面:
稍后,我们就可以在 RabbitMQ 主界面进行一些操作,现在让我们准备开始修改我们之前的两个微服务 orderservice 和 userservice,使用 Spring Cloud Stream 模拟一次简单的异步通讯吧。
异步: 一方发送消息,另一方接收消息,发送方不需要等待接收方的响应,而是继续执行后续的操作。
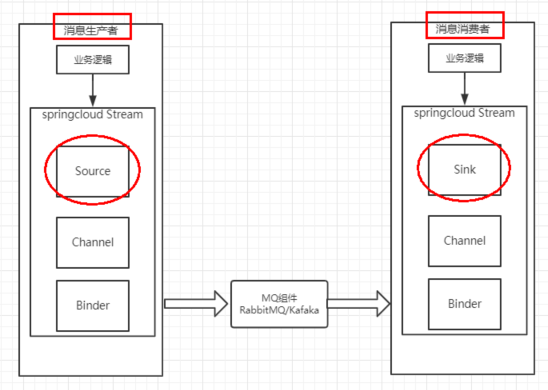
消息生产者
我们使用 userservice 服务作为消息的生产者,模拟一次消息的生产和发送。
1.引入依赖
引入 Spring Cloud Stream 整合 RabbitMQ 的依赖:
<!--Spring Cloud Stream 的rabbitmq整合依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>注意: 由于 Spring Cloud Stream 依赖于 Spring Boot,所以我们不需要再引入 Spring Boot 的依赖。但是如果需要创建控制器,则需要引入 Spring Boot 的 web 依赖。
2.修改配置文件
对配置文件进行修改,添加 Spring Cloud Stream 与 RabbitMQ 的相关属性,稍后我们会对这些属性进行解读:
spring:
cloud:
stream:
binders: #在此处配置要绑定的rabbitmq的服务信息
defaultRabbit: #表示定义绑定名称
type: rabbit #消息组件类型是RabbitMQ
environment: #rabbitmq的相关的环境配置
spring:
rabbitmq:
host: localhost
port: 5672 ## rabbitmq的服务器端口
username: guest
password: guest
bindings: #exchange将路由到队列的规则
output: #这个名字是一个通道的名称
destination: niitExchage #表示要使用的交换机的名称定义
content-type: application/json #设置消息类型
binder: defaultRabbit #设置要绑定的消息服务的具体设置
group: niit #消息分组binding 是一个接口,用于声明输入和输出通道 12。每个通道可以绑定到一个外部的消息代理(如 RabbitMQ 或 Kafka)上,通过 Binder 实现来连接。
binders 是一个抽象,用于实现不同类型的消息代理的连接逻辑。Spring Cloud Stream 提供了一些默认的 Binder 实现,如 RabbitMQ 和 Kafka,也可以自定义 Binder 实现。
一个应用可以使用多个 Binder 实现来连接不同类型的消息代理,但是需要在配置文件中指定每个通道使用哪个 Binder 实现。
3.启动类添加@EnableBinding 注解
创建一个消息生产的接口,定义发送消息的方法签名:
@EnableBinding({Source.class})
@MapperScan("com.niit.user.mapper")
@SpringBootApplication
public class UserApplication {
public static void main(String[] args) {
SpringApplication.run(UserApplication.class, args);
}
}
不是必须
4.实现消息生产服务业务逻辑
创建一个实现类,用来具体实现接口业务逻辑方法:
@EnableBinding(Source.class)
public class UserMessageService {
@Resource
private MessageChannel output;
@Override
public String send(String msg) {
Message<String> build = MessageBuilder.withPayload(msg).build();
boolean sendFlag = output.send(build);
if (sendFlag) {
return "消息发送成功: "+msg;
}
return "消息发送失败: " + msg;
}
}5.创建控制器,对外暴露接口
创建一个 Controller,可以让外部 HTTP 请求访问内部业务,从而向通道中发送消息:
@RestController
@RequestMapping("/message")
public class UserMessageController {
@Autowired
private UserMessageService messageService;
@GetMapping("/rabbitmq/{msg}")
public String sendMessage(@PathVariable("msg") String msg){
return messageService.send(msg);
}
}
消息消费者
我们使用 orderservice 服务作为消息的消费者,模拟一次消息的接收和消费。
1.引入依赖
引入 Spring Cloud Stream 整合 RabbitMQ 的依赖:
<!--Spring Cloud Stream 的rabbitmq整合依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>2.修改配置文件
对配置文件进行修改,添加 Spring Cloud Stream 与 RabbitMQ 的相关属性,稍后我们会对这些属性进行解读:
spring:
cloud:
stream:
binders: #在此处配置要绑定的rabbitmq的服务信息
defaultRabbit: #表示定义的名称,用于与binding整合
type: rabbit #消息组件类型是RabbitMQ
environment: #rabbitmq的相关的环境配置
spring:
rabbitmq:
host: localhost
port: 5672 ## rabbitmq的服务器默认端口
username: guest
password: guest
bindings: #服务的整合处理
input: #这个名字是一个通道的名称
destination: niitExchage #表示要使用的交换机的名称定义
content-type: application/json #设置消息类型
binder: defaultRabbit #设置要绑定的消息服务的具体设置
group: niit #消息分组3.启动类添加@EnableBinding 注解
@EnableBinding({Sink.class})
...
public class OrderApplication {...}不是必须
4.创建 Java 类,接收并消费消息
@EnableBinding({Sink.class})
public class MessageReceiver {
@StreamListener(Sink.INPUT) // 注解监听队列, 用于消费者的队列的消息接收
public void receiveMessage(Message<String> msg){
System.out.println("order-service接收到的消息是: " + msg.getPayload());
}
}核心注解
现在介绍刚才出现的两个 Spring Cloud Stream 核心注解:
-
@EnableBinding: 通过@EnableBinding (Sink.class)绑定了Sink接口,该接口是 Spring Cloud Stream 中默认实现的对输入消息通道绑定的定义,它的源码如下:public interface Sink { String INPUT = "input"; @Input("input") SubscribableChannel input(); }
-
@EnableBinding: 通过@EnableBinding (Source.class)绑定了Source接口,该接口是 Spring Cloud Stream 中默认实现的对输出消息通道绑定的定义,它的源码如下:public interface Source { String OUTPUT = "output"; @Output("output") MessageChannel output(); }
-
@EnableBinding: 通过@EnableBinding (Processor.class)绑定了Processor接口, 它是一个消息通道的定义,它继承了 Sink 接口,同时还继承了 Source 接口, 作用是既可以作为消息的生产者,也可以作为消息的消费者,它的源码如下:public interface Processor extends Source, Sink {}
通过 @Input 注解绑定了一个名为 input 的通道。除了 Sink 之外, Spring Cloud Stream 还默认实现了绑定 output 通道的 Source 接口,还有结合了 Sink 和 Source 的 Processor 接口,实际使用时也可以自己通过 @Input 和 @Output 注解来定义绑定消息通道的接口。
在 Spring Cloud Stream 3.1 版本中,@EnableBinding 注解已被弃用,取而代之的是功能编程模型。
@StreamListener:主要定义在方法上,作用是将被修饰的方法注册为消息中间件上数据流的事件监听器,注解中的属性值对应了监听的消息通道名。在上面的例子中,通过@StreamListener (Sink.INPUT)注解将 receiveMessage 方法注册为input消息通道的监听处理器,所以在 RabbitMQ 的控制页面中发布消息的时候, receiveMessage 方法会做出对应的响应动作。
测试
同时启动生产者和消费者
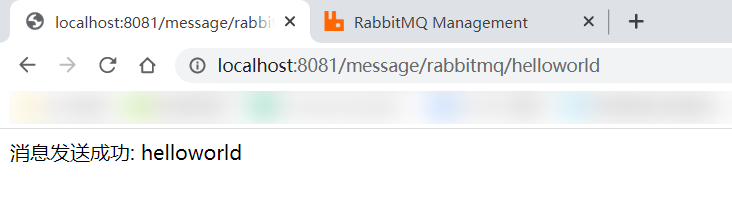
启动 Nacos 服务,然后分别启动 userservice 服务和 orderservice 服务。现在,我们访问: http://localhost:8081/message/rabbitmq/helloworld ,可以在 web 浏览器页面看到消息是否发送成功:
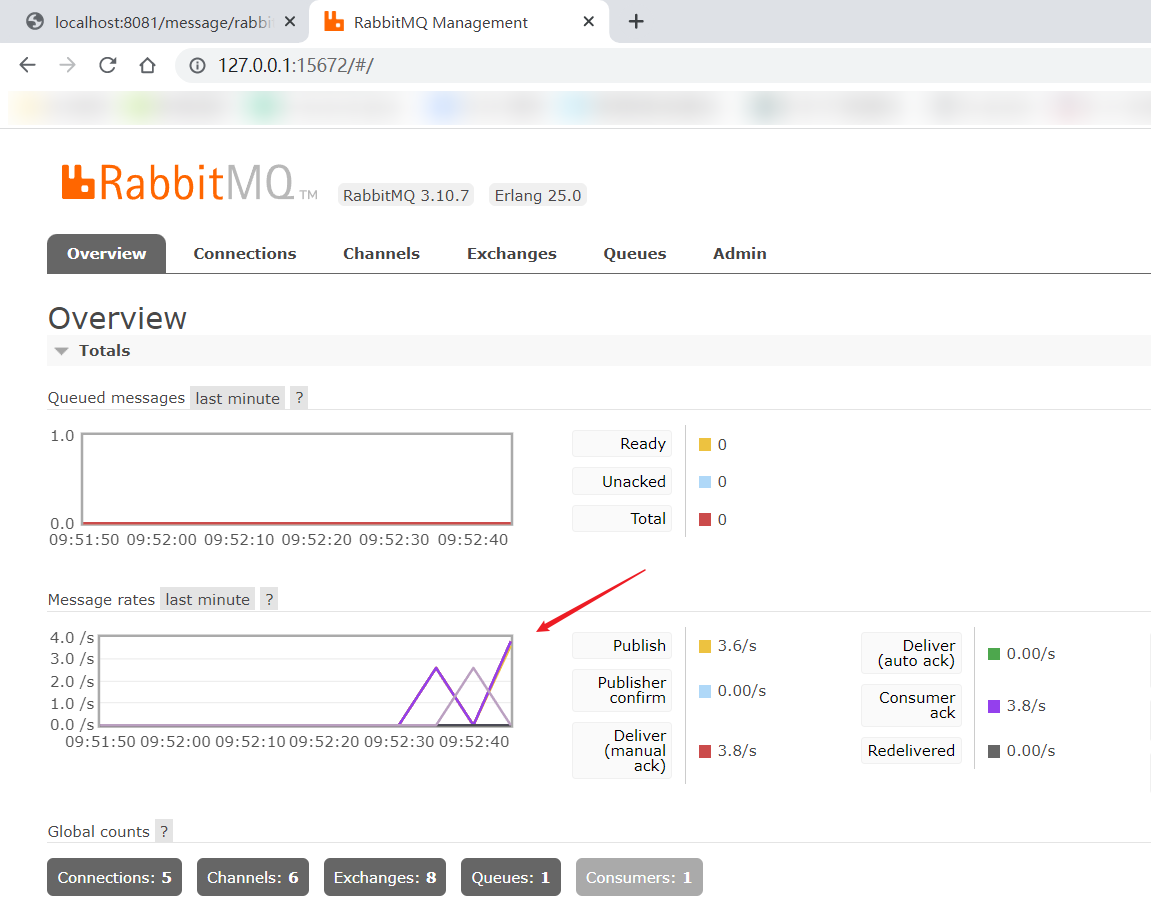
多发送几次请求之后,我们可以在 RabbitMQ 的控制台页面看到消息流量的波动图:
此时,我们在 orderservice 服务的控制台上,也可以观察到我们接收的消息:
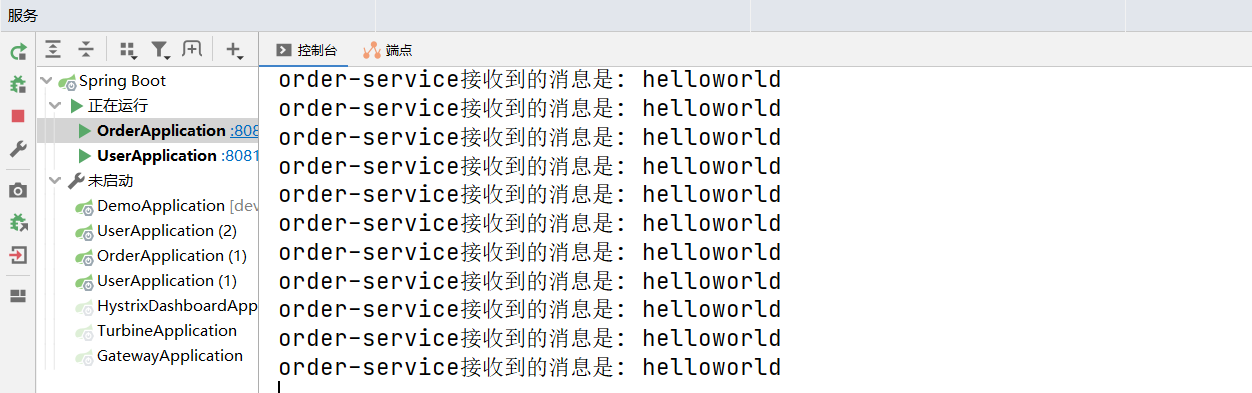
先启动生产者后启动消费者
上面的测试步骤,还不能直观的体现出异步消息的特性,我们现在模拟现实中的异步情境。我们可以先把消息消费者 orderservice 服务停掉,然后让消息生产者 userservice 服务多生产一些消息,发送到消息队列中,随后再启动消息消费者 orderservice 服务,查看 orderservice 服务的控制台输出日志:

由此我们可以发现,当消费者服务重启之后,可以重新消费之前没有消费的消息。
需要指定消息分组(group)才有消息持久化的效果
通过 Spring Cloud Stream 框架驱动 RabbitMQ 消息中间件,解除了 userservice 和 orderservice 之间的耦合性,并且屏蔽了 RabbitMQ 底层复杂 API 的使用。
通过上一节介绍的快速入门示例,相信同学们对 Spring Cloud Stream 的工作模式己经有了一些基础概念,比如输入、输出通道的绑定,通道消息事件的监听等。在本节中,将详细介绍在 Spring Cloud Stream 中是如何通过定义一些基础概念来对各种不同的消息中间件做抽象的。
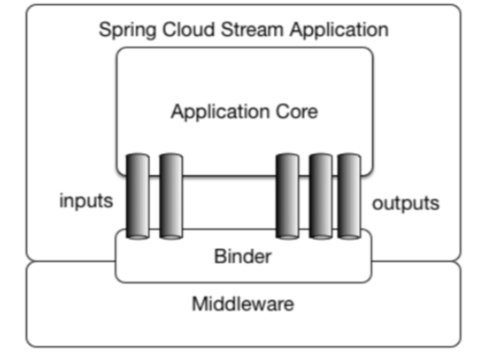
官网提供的 Spring Cloud Stream 的模型结构图。从中可以看到, Spring Cloud Stream 构建的应用程序与消息中间件之间是通过绑定器 Binder 相关联的,绑定器对于应用程序而言起到了隔离作用,它使得不同消息中间件的实现细节对应用程序来说是透明的。
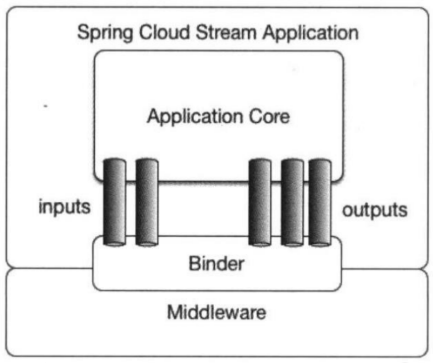
所以对于每一个 Spring Cloud Stream 的应用程序来说,它不需要知晓消息中间件的通信细节,它只需知道 Binder 对应程序提供的抽象概念来使用消息中间件来实现业务逻辑即可,而这个抽象概念就是在快速入门中提到的消息通道: Channel 。如图所示,在应用程序和 Binder 之间定义了两条输入通道和三条输出通道来传递消息,而绑定器则是作为这些通道和消息中间件之间的桥梁进行通信。
绑定器
Binder 绑定器是 Spring Cloud Stream 中一个非常重要的概念。
绑定器的作用: 屏蔽底层消息中间件的差异, 降低消息中间件切换成本,统一消息的编程模型。
在没有绑定器这个概念的情况下,Spring Boot 应用要直接在业务代码中与消息中间件进行信息交互的时候,由于各消息中间件构建的初衷不同,所以它们在实现细节上会有较大的差异,这使得实现的消息交互逻辑就会非常笨重。
因为对具体的中间件实现细节有太重的依赖,当中间件有较大的变动升级或是更换中间件的时候,就需要付出非常大的代价来实施, 比如修改业务中的相关代码。
通过定义绑定器作为中间层,完美地实现了应用程序与消息中间件细节之间的隔离。通过向应用程序暴露统一的 Channel 通道,使得应用程序不需要再考虑各种不同的消息中间件的实现。当需要升级消息中间件,或是更换其他消息中间件产品时,要做的就是更换它们对应的 Binder 绑定器而不需要修改任何 Spring Boot 的应用逻辑。
早期 3.x 版本的 Spring Cloud Stream 只为 RabbitMQ 和 Kafka 提供了默认的 Binder 实现,在快速入门的例子中,就使用了 RabbitMQ 的 Binder。
另外, Spring Cloud Stream 还实现了一个专门用于单元测试的 TestSupportBinder, 开发者可以直接使用它来对通道的接收内容进行可靠的测试断言。
如果要使用除了 RabbitMQ 和 Kafka 以外的消息中间件的话,也可以过使用它所提供的扩展 API 来自行实现其他中间件的 Binder.
或者也可以使用较新版本的 Spring Cloud Stream 从而自动实现对其他消息中间件的支持。
相信大家己经发现,在快速入门示例中,使用 application.yml 做了一些属性设置。
当然,我们还可以通过 Spring Boot 应用支持的任何方式来修改这些配置,比如,通过应用程序参数、环境变量、
application.properties或是application.yaml配置文件等。
发布-订阅模式
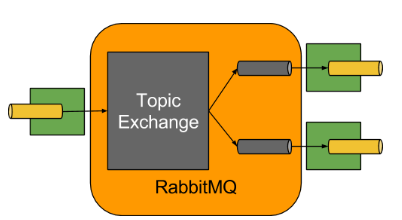
Spring Cloud Stream 中的消息通信方式遵循了发布 - 订阅模式,当一条消息被投递到消息中间件之后,它会通过共享的 Topic 主题进行广播,消息消费者在订阅的主题中收到它并触发自身的业务逻辑处理。这里所提到的 Topic 主题是 Spring Cloud Stream 中的一个抽象概念,用来代表发布共享消息给消费者的地方。
在不同的消息中间件中, Topic 可能对应不同的概念,比如,在 RabbitMQ 中,它对应 Exchange ,而在 Kakfa 中则对应 Kafka 中 的 Topic 。
在快速入门的示例中,通过 RabbitMQ 的 Channel 发布消息给我们编写的应用程序消费,而实际上 Spring Cloud Stream 应用启动的时候,在 RabbitMQ 的 Exchange 中也创建了一个名为 niitExchange 的交换器,
由于 Binder 的隔离作用,应用程序并无法感知它的存在,应用程序只知道自己指向 Binder 的输入或是输出通道。
在 Exchanges 选项卡中,还能找到名为 niitExchange 的交换器,单击进入可以看到如下图所示的详情页面。
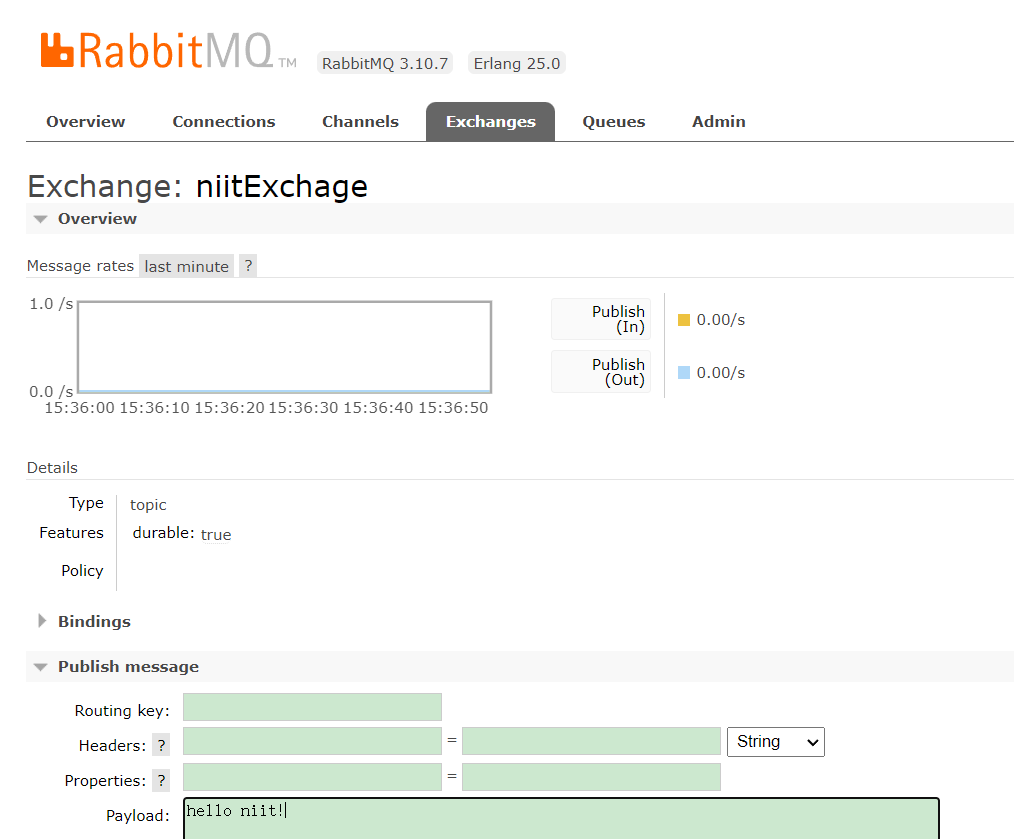
可以通过 Exchange 页面的 Publish Message 来发布消息:
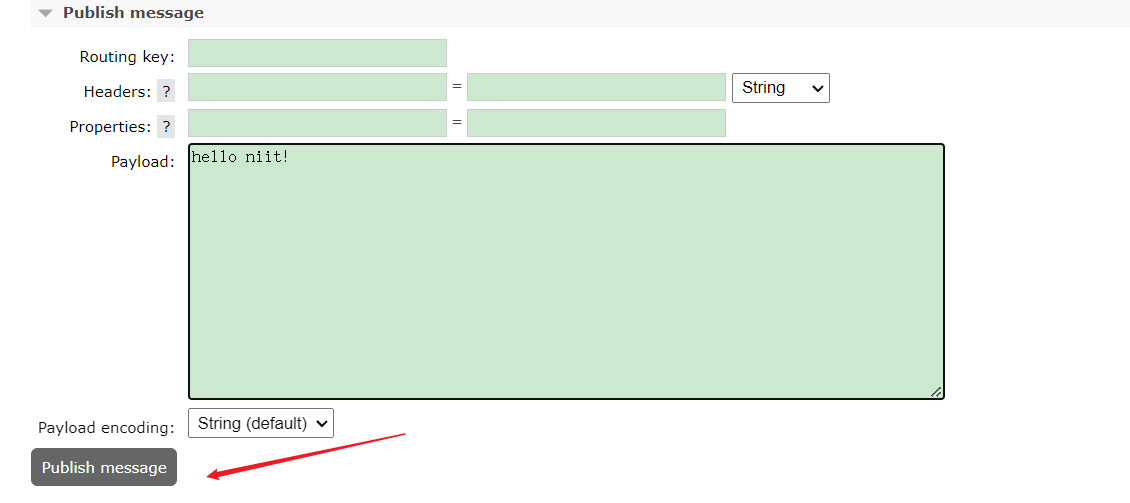
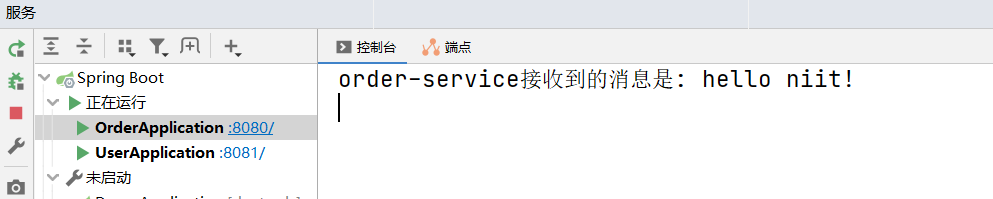
此时可以发现消费者服务接收到了消息:
发布 - 订阅模式
- 相对于点对点队列实现的消息通信来说, Spring Cloud Stream 采用的发布 - 订阅模式可以有效降低消息生产者与消费者之间的耦合。当需要对同一类消息增加一种处理方式时,只需要增加一个应用程序并将输入通道绑定到既有的 Topic 中就可以实现功能的扩展,而不需要改变原来己经实现的任何内容。
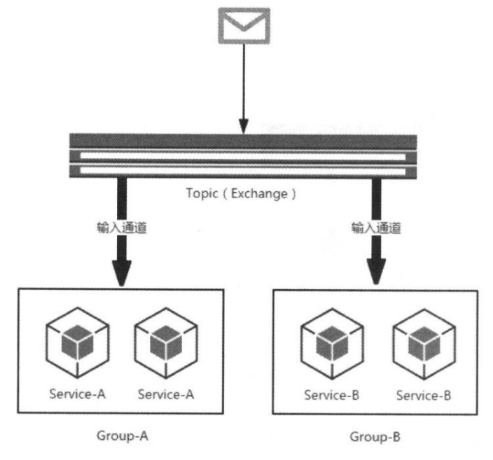
消费组
虽然 Spring Cloud Stream 通过发布 - 订阅模式将消息生产者与消费者做了很好的解耦,基于相同主题的消费者可以轻松地进行扩展,但是这些扩展都是针对不同的应用实例而言的。在现实的微服务架构中,每一个微服务应用为了实现高可用和负载均衡,实际上都会部署多个实例。在很多情况下,消息生产者发送消息给某个具体微服务时,只希望被消费一次。但是同一个应用的多个实例都会接收到消息,这个消息将会被重复消费。
为了解决这个问题,在 Spring Cloud Stream 中提供了消费组的概念。如果在同一个主题上的应用需要启动多个消费者实例的时候,可以通过 spring.cloud.stream.bindings.input.group 属性为应用指定一个组名,这样这个应用的多个实例在接收到消息的时候,只会有一个成员真正收到消息并进行处理。
如下图所示,为 Service-A 和 Service-B 分别启动了两个实例,并且根据服务名进行了分组,这样当消息进入主题之后, Group-A 和 Group-B 都会收到消息的副本,但是在两个组中都只会有一个实例对其进行消费。
默认情况下,当没有为应用指定消费组的时候, Spring Cloud Stream 会为其分配一个独立的匿名消费组。所以,如果同一主题下的所有应用都没有被指定消费组的时候,当有消息发布之后,所有的应用都会对其进行消费,因为它们各自都属于一个独立的组。如果这个消息根据业务要求只需要被消费一次,那么就会出现重复消费的问题。
匿名消费者组订阅的消息是不会持久化的, 因此是不可靠的.
也可以为多个消费者指定相同的组, 可以逻辑上看做是一个消费者. 这样可以实现负载均衡和故障转移的效果, 因为每个消息只会被消费者组中的成员消费一次. 具体由哪个消费者消费, 由消息中间件决定.
指定的消费者组订阅的消息会持久化, 因此更加可靠.
消息分区
通过引入消费组的概念,己经能够在多实例的情况下,保障每个消息只被组内的一个实例消费。但是消费组无法控制消息具体被哪个实例消费。也就是说,对于同一条消息,它多次到达之后可能是由不同的实例进行消费的。
但是对于一些业务场景,需要对一些具有相同特征的消息设置每次都被同一个消费实例处理,比如,一些用于监控服务,为了统计某段时间内消息生产者发送的报告内容,监控服务需要在自身聚合这些数据,
那么消息生产者可以为消息在消息的 header 中增加一个固有的特征 ID 来进行分区,使得拥有这些 ID 的消息每次都能被发送到一个特定的实例上实现累计统计的效果,否则这些数据就会分散到各个不同的节点导致监控结果不一致的情况。
而分区概念的引入就是为了解决这样的问题:当生产者将消息数据发送给多个消费者实例时,保证拥有共同特征的消息数据始终是由同一个消费者实例接收和处理。
Spring Cloud Stream 为分区提供了通用的抽象实现,用来在消息中间件的上层实现分区处理,所以它对于消息中间件自身是否实现了消息分区并不关心,这使得 Spring Cloud Stream 为不具备分区功能的消息中间件也增加了分区功能扩展。
小问题 :
什么是 Spring Cloud Stream 中一个非常重要的概念?
- Spring 绑定器
- Prop 绑定器
- Binder 绑定器
查看答案
正确答案:3
使用详解
在介绍了 Spring Cloud Steam 的基础结构和核心概念之后,我们来详细地学习一下它所提供的一些核心注解的具体使用方法。
开启绑定功能
在 Spring Cloud Stream 中,需要通过 @EnableBinding 注解来为应用启动消息驱动的功能,该注解在快速入门中己经有了基本的介绍,下面来详细看看它的定义:
@Target({ElementType.TYPE, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Configuration
@Import({BindingBeansRegistrar.class, BinderFactoryAutoConfiguration.class})
@EnableIntegration
public @interface EnableBinding {
Class<?>[] value() default {};
}从该注解的定义中可以看到,它自身包含了 @Configuration 注解,所以用它注解的类也会成为 Spring 的基本配置类。另外该注解还通过 @Import 加载了 Spring Cloud Stream 运行需要的几个基础配置类。
-
BindingBeansRegistrar:该类是ImportBeanDefinitionRegistrar接口的实现,主要是在 Spring 加载 Bean 的时候被调用,用来实现加载更多的 Bean 。由于BindingBeansRegistrar被@EnableBinding注解的@Import所引用,所以在其他配置加载完后,它的实现会被回调来创建其他的 Bean, 而这些 Bean 则从@EnableBinding注解的 value 属性定义的类中获取。就如入门实例中定义的@EnableBinding (Sink.class),它在加载用于消息驱动的基础 Bean 之后, 会继续加载 Sink 中定义的具体消息通道绑定。 -
BinderFactoryConfiguration: Binder 工厂的配置,主要用来加载与消息中间件相关的配置信息,比如,它会从应用工程的 META-INF/spring.binders 中 加载针对具体消息中间件相关的配置文件等。
@EnableBinding 注解只有一个唯一的属性: value 。上面己经介绍过,由于该注解 @Import 了 BindingBeansRegistrar 实现,所以在加载了基础配置内容之后,它会回调来读取 value 中的类,以创建消息通道的绑定。另外,由于 value 是一个 Class 类型的数组,所以可以通过 value 属性一次性指定多个关于消息通道的配置。
绑定消息通道
在 Spring Cloud Steam 中,可以在接口中通过 @Input 和 @Output 注解来定义消息通道,而用于定义绑定消息通道的接口则可以被 @EnableBinding 注解的 value 参数来指定,从而在应用启动的时候实现对定义消息通道的绑定。
在快速入门的示例中,演示了使用 Sink 接口绑定的消息通道。 Sink 接口是 Spring Cloud Steam 提供的一个默认实现,除此之外还有 Source 和 Processor ,可从它们的源码中学习它们的定义方式:
//Sink
public interface Sink {
String INPUT = "input";
@Input("input")
SubscribableChannel input();
}
//Source
public interface Source {
String OUTPUT = "output";
@Output("output")
MessageChannel output();
}
//Processor
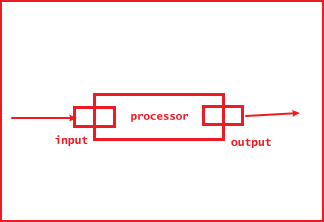
public interface Processor extends Source, Sink {
}从上面的源码中,可以看到, Sink 和 Source 中分别通过 @Input 和 @Output 注解定义了输入通道和输出通道,而 Processor 通过继承 Source 和 Sink 的方式同时定义了一个输入通道和一个输出通道。
另外, @Input 和 @Output 注解都还有一个 value 属性,该属性可以用来设置消息通道的名称,这里 Sink 和 Source 中指定的消息通道名称分别为 input 和 output。如果直接使用这两个注解而没有指定具体的 value 值,将默认使用方法名作为消息通道的名称。
最后,需要注意一点,
-
当定义输出通道的时候,需要返回
MessageChannel接口对象,该接口定义了向消息通道发送消息的方法; -
而定义输入通道时,需要返回
SubscribableChannel接口对象,- 该接口继承自
MessageChannel接口,它定义了维护消息通道订阅者的方法。
- 该接口继承自
注入绑定接口
在完成了消息通道绑定的定义之后, Spring Cloud Stream 会为其创建具体的实例,而开发者只需要通过注入的方式来获取这些实例并直接使用即可。举个简单的例子,在快速入门示例中 orderservice 服务己经为 Sink 接口绑定的 input 消息通道实现了具体的消息消费者,下面可以通过注入的方式实现一个消息生成者,向 input 消息通道发送数据。
-
创建一个将消息通道
"input"作为输出通道的发送消息的接口,具体如下:public interface SinkSender { @Output(Sink.INPUT) MessageChannel output(); }
-
对
orderservice中 定义的ReceiveMessage做一些修改:在@Enablebinding注解中增加对SinkSender接口的指定,使 Spring Cloud Stream 能创建出对应的 Java Bean 的实例。@EnableBinding({Sink.class,SinkSender.class}) public class MessageReceiver { @StreamListener(Sink.INPUT) public void receiveMessage(Message<String> msg){ System.out.println("order-service接收到的消息是: "+ msg.getPayload()); } }
-
创建
OrderMessageController控制器类, 通过@Autowired注解注入SinkSender的实例,并在控制器方法中调用它的发送消息方法。@RestController @RequestMapping("/message") public class OrderMessageController { @Autowired private SinkSender sinkSender; @RequestMapping("/sinkSender/{msg}") public String contextLoads(@PathVariable("msg")String msg){ boolean send = sinkSender.output().send(MessageBuilder.withPayload(msg).build()); if (send) { return "成功发送消息: " + msg; } return "消息发送失败: " + msg; } }
- 重启 orderservice 服务,在浏览器中访问:http://localhost:8080/message/sinkSender/hello 。如果可以在控制台中找到如下输出内容,表明试验己经成功了,消息被正确地发送回 orderservice 服务的 input 通道中,并被消息消费者输出(等于是自己把消息发送给了自己)。

注入消息通道进行消息发送
由于 Spring Cloud Stream 会根据绑定接口中的 @Input 和 @Output 注解来创建消息通道实例,所以也可以通过直接注入的方式来使用消息通道对象。比如,可以通过下面的示例,注入上面例子中 SinkSender 接口中定义的名为 input 的消息输入通道。
@RestController
@RequestMapping("/message")
@EnableBinding({Sink.class, SinkSender.class})
public class OrderMessageController {
@Autowired
private MessageChannel input;
@RequestMapping("/inputChannel/{msg}")
public String channelMessage(@PathVariable("msg")String msg){
boolean send = input.send(MessageBuilder.withPayload(msg).build());
if (send) {
return "成功发送消息: " + msg;
}
return "消息发送失败: " + msg;
}
}上面定义的内容,完成了与之前通过注入绑定接口 SinkSender 方式实现的测试用例相同的操作。因为在通过注入绑定接口实现时, sinkSender.output() 方法实际获得的就是 SinkSender 接口中定义的 MessageChannel 实例,只是在这里直接通过注入的方式来实现了而己。
注入绑定接口 SinkSender这种用法虽然很直接,但是也容易犯错,很多时候在一个微服务应用中可能会创建多个不同名的 MessageChannel 实例,这样通过 @Autowired 注入时,要注意参数命名需要与通道同名才能被正确注入,或者也可以使@Qualifier 注解来特别指定具体实例的名称,该名称需要与定义 MessageChannel 的 @Output 中的 value 参数一致,这样才能被正确注入。
比如下面的例子,在一个接口中定义了两个输出通道,分别命名为 output1 和 output2, 当要使用 通道output1 的时候,可以通过
@Qualifier( "Output1") 来指定这个具体的实例来注入使用。
-
MySource 接口
//定义通道 public interface MySource { @Output("output1") MessageChannel output1(); @Output("output2") MessageChannel output2(); } -
OutputSender 类
//注入 @Component public class OutputSender { @Autowired @Qualifier("output1") MessageChannel output; ... }
提示:
@EnableBinding 注解也可以只写在启动类上,Binding 组件及其通道只需要注册一次
注解 @StreamListener 详解
通过入门示例,对于 @StreamListener 注解,应该都己经有了一些基本的认识,通过该注解修饰的方法, Spring Cloud Steam 会将其注册为输入消息通道的监听器。当输入 消息通道中有消息到达的时候,会立即触发该注解修饰方法的处理逻辑对消息进行消费。
@SteamListener 注解都实现了对输入消息通道的监听,并且内置了一系列的消息转换功能,这使得基于 @SteamListener 注解实现的消息处理模型更为简单。
消息转换
大部分情况下,通过消息来对接服务或系统时,消息生产者都会以结构化的字符串形式来发送,比如 JSON 或 XML 。当消息到达的时候,输入通道的监听器需要对该字符串做一定的转化,将 JSON 或 XML 转换成具体的对象,然后再做后续的处理。
可以这样为通道设置绑定消息的类型, 这样传输消息时会对格式进行校验如:
cloud.stream.bindings.input.content-type=application/jsoncloud.stream.bindings.output.content-type=application/json
假设,需要传输一个 User 对象,该对象有 username 和 address 两个字段,这时,如果使用 @SteamListener 注解的话,代码实现将变得非常简单优雅:
@EnableBinding(MySource.class)
public class MessageReceiver {
/**
* 监听output2通道,完成自动类型转换
* @param user
*/
@StreamListener("output2")
public void receive(User user) {
System.out.println("Received: " + user);
}
}我们可以在控制器中增加一个方法,使用我们刚刚定义的 output2 通道进行信息发送:
@RestController
@RequestMapping("/message")
public class OrderMessageController {
@Autowired
private MySource mySource;
@RequestMapping("/userInfo/")
public String output2ChannelMessage(User user){
boolean send = mySource.output2().send(MessageBuilder.withPayload(JSONUtil.toJsonStr(user)).build());
if (send) {
return "成功发送消息: " + JSONUtil.toJsonStr(user);
}
return "消息发送失败: " + JSONUtil.toJsonStr(user);
}
}我们可以通过之前介绍的小插件: FastRequest,模拟一个 User 信息,然后发送:
控制台上将会显示:

消息反馈
很多时候在处理完输入消息之后,需要反馈一个消息给对方,这时候可以通过 @SendTo 注解来指定返回内容的输出通道。我们对 orderservice 中消息接收类 MessageReceiver 进行修改,在其中一个类上添加@SendTo 注解:
@EnableBinding({Processor.class, SinkSender.class,MySource.class})
public class MessageReceiver {
@StreamListener(Sink.INPUT)
@SendTo(Processor.OUTPUT)
public String receiveMessage(Message<String> msg){
System.out.println("order-service接收到的消息是: "+msg.getPayload());
return msg.getPayload();
}
}在 userservice 中同样创建一个消息接收类,用来监听来自 orderservice 的消息回执:
@Component
public class UserMessageReceiver {
@StreamListener(Processor.INPUT)
public void receiveReturnMessage(Message<String> msg) {
System.out.println("receiveReturnMessage 接收到的消息回执是: " + msg.getPayload());
}
}userservice 是 orderservice 应用中 input 通道的生产者以及 output 通道的消费者。可以在配置文件中将两个应用的通道绑定反向地做一些配置。因为对于 userservice 来说,它的 input 绑定通道实际上是对 output 主题的消费者,而 output 绑定通道实际上是对 input 主题的生产者,
做如下具体配置。指定通道的 destination 来实现两个应用的消息交互:
orderservice 的配置
spring:
cloud:
stream:
binders: #在此处配置要绑定的rabbitmq的服务信息
defaultRabbit: #表示定义的名称,用于与binding整合
type: rabbit #消息组件类型是RabbitMQ
environment: #rabbitmq的相关的环境配置
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
bindings: #服务的整合处理
input: #这个名字是一个通道的名称
destination: niitExchange #表示要使用的交换机的名称定义
content-type: application/json #设置消息类型
binder: defaultRabbit #设置要绑定的消息服务的具体设置
group: niit
output:
destination: commonExchange
content-type: application/json
binder: defaultRabbit
group: niituserservice 的配置
spring:
cloud:
stream:
binders: #在此处配置要绑定的rabbitmq的服务信息
defaultRabbit: #表示定义的名称,用于与binding整合
type: rabbit #消息组件类型是RabbitMQ
environment: #rabbitmq的相关的环境配置
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
bindings: #服务的整合处理
output:
destination: niitExchange
content-type: application/json
binder: defaultRabbit
group: niit
input:
destination: commonExchange
content-type: application/json
binder: defaultRabbit
group: niit当 receiveMessage 方法处理消息之后, return 的值将会最终被 UserMessageReceiver 类的 receiveReturnMessage 方法消费。
消费组与消息分区
在“核心概念” 一节中,对消费组和消息分区己经进行了基本的介绍,在这里来详细介绍一下这两个概念的使用方法。
消费组
通常每个服务都不会以单节点的方式运行在生产环境中,当同一个服务启动多个实例的时候,这些实例会绑定到同一个消息通道的目标主题上。默认情况下,当生产者发出一 条消息到绑定通道上,这条消息会产生多个副本被每个消费者实例接收和处理。但是在有些业务场景之下,希望生产者产生的消息只被其中一个实例消费,这个时候就需要为这些消费者设置消费组来实现这样的功能。实现的方式非常简单,只需在服务消费者端设置 spring.cloud.stream.bindings.input.group 属性即可。在上面的消息回执例子中,我们正是基于此种原因,所以设置了 group 的属性。
分别运行 orderservice 和 userservice,其中 userservice 启动多个实例。以消息回执案例进行测试,可以发现,消息的回执会被启动的多个 userservice 实例以轮询的方式进行接收和输出。

消息分区
通过消费组的设置,虽然己经能够在多实例环境下,保证同一消息只被一个消费者实例进行接收和处理,但是,对于一些特殊场景,除了要保证单一实例消费之外,还希望那些具备相同特征的消息都能够被同一个实例进行消费。这时候我们就需要对消息进行分区处理。
在 Spring Cloud Stream 中实现消息分区非常简单,对消费组示例做一些配置修改就能实现,具体如下所示。
-
以 orderservice 作为消息生产者,修改其配置文件:
spring: cloud: stream: binders: #在此处配置要绑定的rabbitmq的服务信息 defaultRabbit: #表示定义的名称,用于与binding整合 type: rabbit #消息组件类型是RabbitMQ environment: #rabbitmq的相关的环境配置 spring: rabbitmq: host: localhost port: 5672 username: guest password: guest bindings: #服务的整合处理 input: #这个名字是一个通道的名称 destination: niitExchange #表示要使用的交换机的名称定义 content-type: application/json #设置消息类型 binder: defaultRabbit #设置要绑定的消息服务的具体设置 group: niit output: destination: commonExchange content-type: application/json binder: defaultRabbit group: niit producer: partitionKeyExpression: payload partitionCount: 3
从上面的配置中,我们可以看到增加了下面这两个参数。
spring.cloud.stream.bindings.output.producer.partitionKeyExpression:通过该参数指定了分区键的表达式规则,可以根据实际的输出消息规则配置SpEL来生成合适的分区键。payload: 根据类型自动分区header: 设定消息头 ,根据消息头手动设置分区, 如partitionKeyExpression: headers['partitionKey']表示根据消息头中的partitionKey的值来分区
spring.cloud.stream.bindings.output.producer.partitionCount:该参数指定了消息分区的数量。我们准备启动三个消费者实例,所以设置为3个分区。
-
以 userservice 作为消息消费者,修改其配置文件:
spring: cloud: stream: binders: #在此处配置要绑定的rabbitmq的服务信息 defaultRabbit: #表示定义的名称,用于与binding整合 type: rabbit #消息组件类型是RabbitMQ environment: #rabbitmq的相关的环境配置 spring: rabbitmq: host: localhost port: 5672 username: guest password: guest bindings: #服务的整合处理 output: destination: niitExchange content-type: application/json binder: defaultRabbit group: niit input: destination: commonExchange content-type: application/json binder: defaultRabbit group: niit partitioned: true instance-count: 3 instance-index: 0
从上面的配置中,可以看到增加了下面这三个参数。
spring.cloud.stream.bindings.input.consumer.partitioned:通过该参数开启消费者分区功能。spring.cloud.stream.instanceCount:该参数指定了当前消费者的总实例数量。spring.cloud.stream.instanceIndex:该参数设置当前实例的索引号,从 0 开始 。试验的时候需要启动多个实例,可以通过运行参数来为不同实例设置不同的索引值。
到这里消息分区配置就完成了,可以再次启动这两个应用,同时启动多个消费者。但需要注意的是,要为消费者指定不同的实例索引号,这样当同一个消息被发送给消费组时,可以发现只有一个消费实例在接收和处理这些相同的消息。
消息类型
Spring Cloud Stream 为了让开发者能够在消息中声明它的内容类型,在输出消息中定义了一个默认的头信息:contentType 。对于那些不直接支持头信息的消息中间件, Spring Cloud Stream 提供了自己的实现机制,它会在消息发出前自动将消息包装进它自定义的消息封装格式中,并加入头信息。而对于那些自身就支持头信息的消息中间件, Spring Cloud Stream 构建的服务可以接收并处理来自非 Spring Cloud Stream 构建但包含符合规范头信息的应用程序发出的消息。
Spring Cloud Stream 允许使用 spring.cloud.stream.bindngs.<channelName>.content-type 属性以声明式的配置方式为绑定的输入和输出通道设置消息内容的类型。 此外,原生的消息类型转换器依然可以轻松地用于我们的应用程序。
目前, Spring Cloud Stream 中自带支持了以下几种常用的消息类型转换。
-
JSON 与 POJO 的互相转换。
-
JSON 与
org.springframework.tuple.Tuple的互相转换。 -
Object 与
byte[]的互相转换。为了实现远程传输序列化的原始字节,应用程序需要发送 byte 类型的数据,或是通过实现 Java 的序列化接口来转换为字节( Object 对象必须可序列化)。 -
String 与
byte[]的互相转换。 -
Object 向纯文本的转换: Object 需要实现
toString()方法。
上面所指的 JSON 类型可以表现为一个 byte 类型的数组,也可以是一个包含有效 JSON 内容的字符串。另外, Object 对象可以由 JSON 、 byte 数组或者字符串转换而来,但是在转换为 JSON 的时候总是以字符串的形式返回。
MIME 类型
在 Spring Cloud Stream 中定义的 content-type 属性采用了 Media Type ,即 Internet Media Type (互联网媒体类型),也被称为 MIME 类型,常见的有 application/json 、text/plain;charset=UTF-8, 相信接触过 HTTP 的工程师们对这些类型都不会感到陌生。
MIME 类型对于标示如何转换为 String 或 byte [] 非常有用。并且,还可以使用 MIME 类型格式来表示 Java 类型,只需要使用带有类型参数的一般类型: application/x-java-object 。
比如,我们可以使用 application/x-java-object;type=java.util.Map 来表示传输的是一个 java.util.Map 对象,或是使用 application/x-java-object;type=com.niit.pojo.User 来表示传输的是一个 com.niit.pojo.User 对象;除此之外,更重要的是,它还提供了自定义的 MIME 类型, 比如通过 application/x-spring-tuple 来指定 Spring 的 Tuple 类型。
在 Spring Cloud Stream 中默认提供了一些可以开箱即用的类型转换器,具体如下表所示。
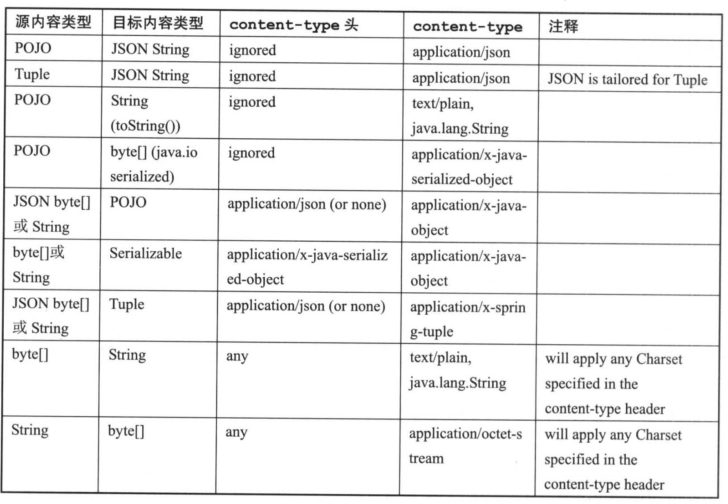
消息类型的转换行为只会在需要进行转换时才被执行,比如,当服务模块产生了一个头信息为 application/json 的 XML 字符串消息, Spring Cloud Stream 是不会将该 XML 字符串转换为 JSON 的,这是因为该模块的输出内容己经是一个字符串类型了,所以它并不会将其做进一步的转换。
另外需要注意的是, Spring Cloud Stream 虽然同时支持输入通道和输出通道的消息类 型转换,但还是推荐开发者尽量在输出通道中做消息转换。因为对于输入通道的消费者来说,当目标是一个 POJO 的时候,使用 @StreamListener 注解是能够支持自动对其进行转换的。
Spring Cloud Stream 除了提供上面这些开箱即用的转换器之外,还支持开发者自定义的消息转换器。这使得用户可以使用任意格式(包括二进制)的数据进行发送和接收,并且将这些数据与特定的 contentType 相关联。在应用启用的时候,Spring Cloud Stream 会将所有 org.springframework.messaging.converter.MessageConverter 接口实现的自定义转换器以及默认实现的那些转换器都加载到消息转换工厂中,以提供给消息处理时使用。
绑定器详解
在“核心概念”一节中,己经简单介绍过 Binder 绑定器的基本概念和作用:它是定义在应用程序与消息中间件之间的抽象层,用来屏蔽消息中间件对应用的复杂性,并提供简单而统一的操作接口给应用程序使用。在本节中,将详细介绍绑定器背后的细节和行为。
绑定器 SPI (了解)
绑定器 SPI 涵盖了一套可插拔的用于连接外部中间件的实现机制,其中包含了许多接口、开箱即用的实现类以及发现策略等内容。其中,最为关键的就是 Binder 接口,它是用来将输入和输出连接到外部中间件的抽象:
package org.springframework.cloud.stream.binder;
public interface Binder<T, C extends ConsumerProperties, P extends ProducerProperties> {
Binding<T> bindConsumer(String name, String group, T inboundBindTarget, C consumerProperties);
Binding<T> bindProducer(String name, T outboundBindTarget, P producerProperties);
}当应用程序对输入和输出通道进行绑定的时候,实际上就是通过该接口的实现来完成的。
-
向消息通道发送数据的生产者调用
bindProducer方法来绑定输出通道时,第一个参数代表了发往消息中间件的目标名称,第二个参数代表了发送消息的本地通道实例,第三个参数是用来创建通道时使用的属性配置 ( 比如分区键的表达式等 ) 。 -
从消息通道接收数据的消费者调用
bindConsumer方法来绑定输入通道时,第一个参数代表了接收消息中间件的目标名称,第二个参数代表了消费组的名称 ( 如果多个消费者实例使用相同的组名,则消息将对这些消费者实例实现负载均衡,每个生产者发出的消息只会被组内一个消费者实例接收和处理 ) ,第三个参数代表了接收消息的本地通道实例,第四个参数是用来创建通道时使用的属性配置。
另外,从 Binder 的定义中,还可以知道 Binder 是一个参数化并且可扩展的接口。
- 对于输入与输出的绑定类型,在 1.0 版本中仅支持
MessageChannel,但是在接口中通过泛型定义,所以在未来可以对其进行扩展。 - 对于属性配置也提供了可扩展的定义,可以为特定的 Binder 以类型安全的方式来补充一些特有的属性。
一个典型的 Binder 绑定器实现一般包含以下内容。
- 一个实现 Binder 接口的类。
- 一个 Spring 配置加载类,用来创建连接消息中间件的基础结构使用的实例。
- 一个或多个能够在 classpath 下的 META-INF/spring.binders 路径找到的绑定器定义文件。比如用户可以在
spring-cloud-starter-stream-rabbit中找到该文件,该文件中存储了当前绑定器要使用的自动化配置类的路径:

绑定器的自动化配置
Spring Cloud Stream 通过绑定器 SPI 的实现将应用程序逻辑上的输入输出通道连接到物理上的消息中间件。消息中间件之间通常都会有或多或少的差异性,所以为了适配不同的消息中间件,需要为它们实现各自独有的绑定器。目前, Spring Cloud Stream 中默认实现了对 RabbitMQ 、 Kafka 的绑定器,在上面的示例中引入的 spring-cloud- starter- stream-rabbit 依赖中就包含了 RabbitMQ 的绑定器 spring-cloud-stream-binder- rabbit 。
默认情况下, Spring Cloud Stream 也遵循 Spring Boot 自动化配置的特性。如果在 classpath 中能够找到单个绑定器的实现,那么 Spring Cloud Stream 会自动加载它。而在 classpath 中引入绑定器的方法也非常简单,只需要在 pom.xml 中增加对应消息中间件的绑定器依赖即可,比如增加 RabbitMQ 的绑定器依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>如果使用 Kafka, 则引入:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
</dependency>多绑定器配置
当应用程序的 classpath 下存在多个绑定器时, Spring Cloud Stream 在为消息通道做绑定操作时,无法判断应该使用哪个具体的绑定器,所以需要为每个输入或输出通道指定具体的绑定器。在一个应用程序中使用多个绑定器时,往往其中一个绑定器会是主要使用的,而第二个可能是为了适应一些特殊要求(比如性能等原因)。可以先通过设置默认绑定器 来为大部分的通道设置绑定器。比如,使用 RabbitMQ 设置默认绑定器:
spring:
cloud:
stream:
defaultBinder: rabbit在设置了默认绑定器之后,再为其他一些少数的消息通道单独设置绑定器,比如:
spring:
cloud:
stream:
bindings:
input:
binder: kafka需要注意的是,上面设置参数时用来指定具体绑定器的值并不是消息中间件的名称,而是在每个绑定器实现的
META-INF/spring.binders 文件中定义的标识(一个绑定器实现的标识可以定义多个,以逗号分隔),所以上面配置的 rabbit 和 kafka 分别来自于各自的配置定义,它们的具体内容如下所示:
rabbit:\
org.springframework.cloud.stream.binder.rabbit.config.RabbitServiceAutoConfiguration;
kafka:\
org.springframework.cloud.stream.binder.kafka.config.KafkaBinderConfiguration另外,当需要在一个应用程序中使用同一类型不同环境的绑定器时,也可以通过配置轻松实现通道绑定。比如,当需要连接两个不同的 RabbitMQ 实例的时候,可以参照如下配置(application.properties 格式):
spring.cloud.stream.bindings.input.binder=rabbit1
spring.cloud.stream.bindings.output.binder=rabbit2
spring.cloud.stream.binders.rabbitl.type=rabbit
spring.cloud.stream.binders.rabbitl.environment.spring.rabbitmq. hos t=l92.168.0.101
spring.cloud.stream.binders.rabbitl.environment.spring.rabbitmq.port=5672
spring.cloud.stream.binders.rabbitl.environment.spring.rabbitmq.username=springcloud
spring.cloud.stream.binders.rabbitl.environment.spring.rabbitmq.password=123456
spring.cloud.stream.binders.rabbit2.type=rabbit
spring.cloud.stream.binders.rabbit2.environment.spring.rabbitmq-host=l92.168.0,102
spring.cloud.stream.binders.rabbit2.environment.spring.rabbitmq.port=5672
spring.cloud.stream.binders.rabbit2.environment.spring.rabbitmq.username=springcloud
spring.cloud.stream.binders.rabbit2.environment.spring.rabbitmq.password=123456从上面的配置中,可以看到对于输入输出通道指定的绑定器采用了显式别名的配置方式,其中 input 通道的绑定指定了名为 rabbit1 的配置,而 output 通道的绑定指定了名为 rabbit2 的配置。当采用显式配置方式时会自动禁用默认的绑定器配置,所以当定义了显式配置别名后,对于这些绑定器的配置需要通过 spring.cloud.stream.binders.< configurationName> 属性来进行设置。
对于绑定器的配置主要有下面 4 个参数。
Spring.cloud.stream.binders.<configurationName>.type指定了绑定器的类型,可以是 rabbit 、 kafak 或者其他自定义绑定器的标识名,绑定器标识名的定义位于绑定器的 META-INF/spring.binders 文件中。Spring.cloud.stream.binders.<configurationName>.environment参数可以直接用来设置各绑定器的属性,默认为空。spring.cloud.stream.binders.<configurationName>.inheritEnvironment参数用来配置当前绑定器是否继承应用程序自身的环境配置,默认为 true 。spring.cloud.stream.binders.<configurationName>.defaultCandidate参数用来设置当前绑定器配置是否被视为默认绑定器的候选项,默认为true。 当需要让当前配置不影响默认配置时,可以将该属性设置为false。
RabbitMQ 与 Kafka 绑定器
在之前的章节中多次提到, Spring Cloud Stream 自身就提供了对 RabbitMQ 和 Kafka 的绑定器实现。由于 RabbitMQ 和 Kafka 自身的实现结构有所不同,理解绑定器实现与消息中间件自有概念之间的对应关系,对于正确使用绑定器和消息中间件会有非常大的帮助。下面就来分别说说 RabbitMQ 与 Kafka 的绑定器是如何使用消息中间件中不同概念来实现消息的生产与消费的。
- RabbitMQ 绑定器 : 在 RabbitMQ 中,通过 Exchange 交换器来实现 Spring Cloud Stream 的主题概念,所以消息通道的输入输出目标映射了一个具体的 Exchange 交换器。而对于每个消费组,则会为对应的 Exchange 交换器绑定一个 Queue 队列进行消息收发。
- Kafka 绑定器:由于 Kafka 自身就有 Topic 概念,所以 Spring Cloud Stream 的主题直接釆用了 Kafka 的 Topic 主题概念,每个消费组的通道目标都会直接连接 Kaflca 的主题进行消息收发。
配置详解
在 Spring Cloud Stream 中对绑定通道和绑定器提供了通用的属性配置项,一些绑定器还允许使用附加属性来对消息中间件的一些独有特性进行配置。这些属性的配置可以通过 Spring Boot 支持的任何配置方式来进行,包括使用环境变量、 YAML 或者 properties 配置文件等。
基础配置
下表是 Spring Cloud Stream 应用级别的通用基础属性,这些属性都以 <code>spring.cloud.stream.为前缀。| 参数名 | 说明 | 默认值 |
|---|---|---|
| instanceCount | 应用程序部署的实例数量,当使用 Kafka 的时候需要设置分区 | 1 |
| instanceIndex | 应用程序实例的索引,该值从 0 开始,最大值设置为-1。当使用分区和 Kafka 的时候使用 | |
| dynamicDestinations | 动态绑定的目标列表,该列表默认为空,当设置了具体列表之后,只有列表中的目标才能被发现 | 空 |
| defaultBinder | 默认绑定器配置,在应用程序中有多个绑定器时使用 | 空 |
| overrideCloudConnectors | 该属性只适用于激活 cloud 配置并且提供了 Spring Cloud Connectors 的应用。当使用默认属性 false 时,绑定器会自动检测合适的服务来绑定(比如,在 Cloud Foundry 中绑定的 RabbitMQ 服务)。当设置为 true 时,绑定器将忽略绑定的服务,而是依赖应用程序中的设置属性来进行绑定和连接 |
绑定通道配置
对于绑定通道的属性配置,在之前的示例中已经有过一些介绍,这些配置可以在属性文件中通过 spring.cloud.stream.bindings.<channelName>.<property>=<value> 格式的参数来进行设置。其中 <channelName> 代表在绑定接口中定义的通道名称,比如, Sink 中的 input 、Source 中的 output。
由于绑定通道分为输入通道和输出通道,所以在绑定通道的配置中包含了三类面向不同通道类型的配置:通用配置、消费者配置、生产者配置。在下面介绍各具体配置属性时将省略 spring.cloud.stream.bindings.<channelName>. 前缀,但在实际使用的时候记得使用完整的参数名称进行配置。
通用配置
对于绑定通道的通用配置,它们既适用于输入通道,也适用于输出通道,它们通过 spring.cloud.stream.bindings.<channelName>. 前缀来进行设置,具体可配置的属性如下表所示。| 参数名 | 说明 | 默认值 |
|---|---|---|
| destination | 该参数用来配置消息通道绑定在消息中间件中的目标名称,比如 RabbitMQ 的 Exchange 或 Kafka 的 Topic。如果配置的绑定通道是一个消费者(输入通道),那么它可以绑定多个目标,这些目标名称通过逗号分隔。如果没有设置该属性,将使用通道名 | |
| group | 该参数用来设置绑定通道的消费组,该参数主要作用于输入通道,以保证同一消息组中的消息只会有一个消费实例接收和处理 | null |
| contentType | 该参数用来设置绑定通道的消息类型 | null |
| binder | 当存在多个绑定器时使用该参数来指定当前通道使用哪个具体的绑定器 | null |
消费者配置
下面这些配置仅对输入通道的绑定有效,它们以 spring.cloud.stream.bindings.<channelName>.consumer. 格式作为前缀。| 参数名 | 说明 | 默认值 |
|---|---|---|
| concurrency | 输入通道消费者的并发数 | 1 |
| partitioned | 来自消息生产者的数据是否采用了分区 | false |
| headerMode | 当设置为 raw 的时候将禁用对消息头的解析,该属性只有在使用不支持消息头功能的中间件时有效,因为 Spring Cloud Stream 默认会解析嵌入的头部信息 | embeddedheaders |
| maxAttempts | 对输入通道消息处理的最大重试次数 | 3 |
| backOffInitialInterval | 重试消息处理的初始间隔时间 | 1000 |
| backOffMaxInterval | 重试消息处理的最大间隔时间 | 10000 |
| backOffMultiplier | 重试消息处理时间间隔的递增乘数 | 2.0 |
生产者配置
| 参数名 | 说明 | 默认值 |
|---|---|---|
| partitionKeyExpression | 该参数用来配置输出通道数据分区键的 SpEl 表达式,当设置该属性之后,将对当前绑定通道的输出数据进行分区处理。同时,partitionCount 的参数必须大于 1 才能生效。该参数与 partitionKeyExtractorClass 参数互斥,不能同时设置 | null |
| partitionKeyExtractorClass | 该参数用来配置分区键提取策略接口 PartitionKeyExtractorStrategy 的实现。当设置该属性之后,将对当前绑定通道的输出数据进行分区处理,同时,partitionCount 的参数必须大于 1 才能生效。该参数与 partitionKeyExpression 参数互斥,不能同时设置 | null |
| 参数名 | 说明 | 默认值 |
|---|---|---|
| partitionSelectorClass | 该参数用来指定分区选择器接口 PartitionSelectorStrategy 的实现。它与 partitionSelectorExpression 参数互斥,不能同时设置。如果两者都不设置,那么分区选择计算规则为 hashCode(key)%partitionCount,这里的 key 根据 partitionKeyExpression 或 partitionKeyExtractorClass 的配置计算得到 | null |
| partitionSelectorExpression | 该参数用来配置自定义分区选择器的 SpEL 表达式。它与 partitionSelectorClass 参数互斥,不能同时设置。如果两者都不设置,那么分区选择计算规则为 hashCode(key)%partitionCount,这里的 key 根据 partitionKeyExpression 或 partitionKeyExtractorClass 的配置计算得到 | null |
| partitionCount | 当分区功能开启时,使用该参数来配置消息数据的分区数。如果消息生产者已经配置了分区键的生成策略,那么它的值必须大于 1 | 1 |
| headerMode | 当设置为 raw 的时候将禁用对消息头的解析,该属性只有在使用不支持消息头功能的中间件时有效,因为 Spring Cloud Stream 默认会解析嵌入的头部信息 | embeddedheaders |
绑定器的配置属性
由于 Spring Cloud Stream 目前只实现了对 RabbitMQ 和 Kafka 的绑定器,所以对于绑定器的属性配置主要是针对这两个中间件。同时因为这两个中间件自身结构的不同,所以会有不同的附加属性来配置各自的一些特殊功能和基础设施。
RabbitMQ 配置
RabbitMQ 绑定器的配置同绑定通道的配置一样,分为三种不同类型:通用配置、消费者配置以及生产者配置。
通用配置
由于 RabbitMQ 绑定器默认使用了 Spring Boot 的 ConnectionFactory, 所以 RabbitMQ 绑定器支持在 Spring Boot 中的配置选项,它们以 spring.rabbitmq. 为前缀。 在之前的示例中,使用了这些配置来指定具体的 RabbitMQ 地址、端口、用户信息等,更多配置可见 Spring Boot 文档中对 RabbitMQ 支持的章节内容,或是通过 spring-boot-starter-amqp 模块中 RabbitProperties 类的源码来查看。
在 Spring Cloud Stream 对 RabbitMQ 实现的绑定器中主要有下面几个属性,它们都以 spring.cloud.stream.rabbit.binder. 为前缀。这些属性可以在 org.springframework.cloud.stream.binder.rabbit.config.RabbitBinderConfigurationProperties 中找到它们。
| 参数名 | 说明 | 默认值 |
|---|---|---|
| adminAddresses | 该参数用来配置 RabbitMQ 管理插件的 URL,当需要配置多个时用逗号分隔。该参数只有在 nodes 参数包含多个时使用,并且这里配置的内容必须在 spring.rabbitmq.addresses 中存在 | |
| nodes | 该参数用来配置 RabbitMQ 的节点名称,当需要配置多个时用逗号分隔。在配置多个的情况下,可以用来定位队列所在的服务器的地址。这里配置的内容必须在 spring.rabbitmq.addresses 中存在 | |
| compressionLevel | 绑定通道的压缩级别,它的具体可选值及含义可见 java.util.zip.Deflater 中的定义 | 1 |
消费者配置
下面这些配置仅对 RabbitMQ 输入通道的绑定有效,它们以 spring.cloud.stream.rabbit.bindings.<channelName>.consumer. 格式作为前缀。
| 参数名 | 说明 | 默认值 |
|---|---|---|
| acknowledgeMode | 用来设置消息的确认模式,可选配置包含:NONE,MANUAL,AUTO | AUTO |
| autoBindDlq | 用来设置是否自动声明 DLQ(Dead-Letter-Queue),并绑定到 DLX(Dead-Letter-Exchange)上 | false |
| durableSubscription | 用来设置订阅是否被持久化,该参数仅在 group 被设置的时候有效 | true |
| maxConcurrency | 用来设置消费者的最大并发数 | 1 |
| prefetch | 用来设置预取数量,它表示在一次会话中从消息中间件获取的消息数量,该值越大消息处理越快,但是会导致非顺序处理的风险 | 1 |
| prefix | 用来设置统一的目标和队列名称前缀 | |
| recoveryInterval | 用来设置恢复连接的尝试时间间隔,以毫秒为单位 | 5000 |
| 参数名 | 说明 | 默认值 |
|---|---|---|
| requestRejected | 用来设置消息传递失败时候重传 | true |
| requestHeaderPatterns | 用来设置需要被传递的请求头信息 | [STANDARD_REQUEST_HEADERS,'*'] |
| replyHeaderPatterns | 用来设置需要被传递的响应头信息 | [STANDARD_REPLY_HEADERS,'*'] |
| republishToDlq | 默认情况下,消息在重试也失败之后会被拒绝。如果 DLQ 被配置的时候,RabbitMQ 会将失败的消息路由到 DLQ 中。如果该参数设置为 true,总线会将失败的消息附加一些头信息(包括异常消息,引起失败的跟踪堆栈)之后重新发布到 DLQ 中 | |
| transacted | 用来设置是否启用 channel-transacted,即是否在消息中使用事务 | false |
| txSize | 用来设置 transaction-size 的数量,当 acknowledgeMode 被设置为 AUTO 时,容器会在处理 txSize 个消息之后才开始英达 | 1 |
生产者配置
下面这些配置仅对 RabbitMQ 输出通道的绑定有效,它们以 spring.cloud.stream.rabbit.bindings.<channelName>.producer. 格式作为前缀。| 参数名 | 说明 | 默认值 |
|---|---|---|
| autoBindQlp | 用来设置是否自动声明 DLQ(Dead-Letter-Queue),并绑定到 DLX(Dead-Letter-Exchange)上 | false |
| batchingEnable | 是否启用消息批处理 | false |
| batchSize | 当批处理开启时,用来设置缓存的批处理消息数量 | 100 |
| batchBufferLimit | 批处理缓存限制 | 10000 |
| batchTimeout | 批处理超时时间 | 5000 |
| compress | 消息发送时是否启用压缩 | false |
| deliveryMode | 消息发送模式 | PERSISTENT |
| prefix | 用来设置统一的目标前缀 | |
| requestHeaderPatterns | 用来设置需要被传递的请求头信息 | [STANDARD_REQUEST_HEADERS,'*'] |
| replyHeaderPatterns | 用来设置需要被传递的响应头信息 | [STANDARD_REPLY_HEADERS,'*'] |
Kafka 配置
Kafka 绑定器的配置在类别上与 RabbitMQ —样,分为三种不同类型:通用配置、消费者配置以及生产者配置。但是由于 RabbitMQ 与 Kafka 自身有一些差异,所以它们的配置也不一样。
通用配置
Spring Cloud Stream 实现的 Kafka 绑定器包含下面这些通用配置,它们都以 spring.cloud.stream.kafka.binder. 为前缀。| 参数名 | 说明 | 默认值 |
|---|---|---|
| brokers | Kafka 绑定器链接的消息中间件列表。需要配置多个时用逗号分隔,每个地址可以是单独的 host,也可以是 host:port 的形式 | localhost |
| defaultBrokerPort | 用来设置默认的消息中间件端口号。当 brokers 中的配置地址没有包含端口信息时,将使用该参数配置的默认端口进行连接 | 9092 |
| zkNodes | kafka 绑定器使用的 Zookeeper 节点列表。需要配置多个时用逗号分隔,每个地址可以是单独的 host,也可以是 host:port 的形式 | localhost |
| defaultZkPort | 用来设置默认的 Zookeeper 端口号。当 zkNodes 中的配置地址没有包含端口信息时,将使用该参数配置的默认端口进行连接 | 2181 |
| headers | 用来设置会被传输的自定义头信息 | |
| offsetUpdateTimeWindow | 用来设置 offset 的更新频率,以毫秒为单位,如果设置为 0 则忽略 | 10000 |
| offsetUpdateCount | 用来设置 offset 以次数表示的更新频率,如果为 0 则忽略,该参数与 offsetUpdateTimeWindow 互斥 | 0 |
| 参数名 | 说明 | 默认值 |
|---|---|---|
| minPartitionCount | 该参数仅在设置了 autoCreateTopics 和 autoAdd-Partitions 时生效,用来设置该绑定器所使用主题的全局分区最小数量。如果当生产者的 partitionCount 参数或 instanceCount*concurrency 的值大于该参数配置时,该参数值将被覆盖 | 1 |
| requiredAcks | 用来设置确认消息的数量 | 1 |
| replicationFactor | 当 autoCreateTopics 参数为 true 时候,用来配置自动创建主题的副本数量 | 1 |
| autoCreateTopics | 该参数默认为 true,绑定器会自动地创建新主题。如果设置为 false,那么绑定器使用已经配置的主题,但是在这种情况下,如果需要使用的主题不存在,绑定器会启动失败 | true |
| autoAddPartitions | 该参数默认为 false,绑定器会根据已经配置的主题分区来实现,如果目标主题的分区数小于预期值,那么绑定器会启动失败。如果该参数设置为 true,绑定器将在需要的时候自动创建新的分区 | false |
| socketBufferSize | 该参数用来设置 Kafka 的 Socket 缓存大小 | 2097152 |
消费者配置
下面这些配置仅对 Kafka 输入通道的绑定有效,它们以 spring.Cloud.Stream.kafka.bindings.<channelName>.consumer. 格式作为前缀。| 参数名 | 说明 | 默认值 |
|---|---|---|
| bufferSize | kafka 批量发送前的缓存数据上限,以字节为单位 | 16384 |
| sync | 该参数用来设置 Kafka 消息生产者的发送模式,默认为 false,即采用 async 配置,允许批量发送数据。当设置为 true 时,将采用 sync 配置,消息将不会被批量发送,而是一条一条地发送 | false |
| batchTimeout | 消息生产者批量发送时,为了积累更多发送数据而设置的等待时间。通常情况下,生产者基本不会等待,而是直接发送所有在前一批次发送时积累的消息数据。当我们设置一个非 0 值时,可以以延迟为代价来增加系统的吞吐量 | 0 |
活动 9.1
Spring Cloud Stream 的使用
练习问题
- 说明以下语句是正确还是错误。
通过定义绑定器作为中间层,完美地实现了应用程序与消息中间件细节之间的隔离 。
a. 正确
b. 错误答案
a 正确
- Spring Cloud Stream 中的消息通信方式遵循了什么模式?
a. 发布-订阅
b. 发布
c. 订阅
d. 订阅-发布答案
a 正确
- 在 Spring Cloud Stream 中,需要通什么注解来为应用启动消息驱动的功能?
a. @EnaBinding
b. @EnableBinding
c. @Enableding
d. @EnableBind答案
b 正确
- 应用 Spring Cloud Stream 是基于什么构建起的
a. Spring Integration
b. Integration
c. Spring
d. Spring Integrat答案
a 正确
小结
在本章中,您学习了:
- 本地配置安装 RabbitMQ
- Spring Cloud Stream 的核心概论
- 绑定器
- 发布-订阅模式
- 消费组
-
对于一些核心注解的使用
-
开启绑定功能
-
绑定消息通道
-
消息生产与消费
-
消费组与消息分区
-
消息类型
-
-
绑定器背后的细节和行为
- 绑定器 SPI
- 自动化配置
- RabbitMQ 与 Kafka 绑定器
-
了解 Spring Cloud Stream 中相应的配置
- 基础配置
- 绑定通道配置
- 绑定器配置
谢谢
Views: 26