
为什么使用Trident
逐个处理单个tuple会增加很多开销,因此storm中引入Trident实现batch处理.
Trident优点是:
- 批次处理消息
- 减少持久化的开销
- 结合
Trident State能可靠保证每个消息只被处理一次
Trident的 State
Trident 在进行聚合操作时需要缓存中间结果, 可以看做Trident的状态(State).
Trident状态既可以保留在topology的内部,比如说内存中,也可以放到外部存储当中,比如说Memcached或者Cassandra数据库中.
Trident 允许以一种容错的方式来管理状态, 可以保证当遇到重试或错误时状态的更新是幂等的, 以此来实现EOS(Exactly only semantics)。
注:在数据统计分析中,幂等性是一个很重要的指标,因为它可以保证即使数据被处理了多次,但是站在结果的角度看和处理一次完全一样。
使用Trident实现词频统计
这里我们词频统计使用Trident拓扑实现.
这里使用Storm提供的MemoryMapState管理状态(每个单词的实时统计个数), 顾名思义MemoryMapState管理的状态是保存在内存中的. 状态可以通过方法stateQuery进行实时查询.
然后提供一个DRPC服务, 客户端可以指定需要查询词频的单词有哪些.
本地提交模式
数据源
在这个例子中,我们使用FixedBatchSpout 对象模拟数据源来发送一句一句的文本内容。输入数据源也可以和Kestrel或者Kafka这样的消息队列对接, Trident在处理输入流的时候会转换成若干个tuple组成的batch来处理。这个 FixedBatchSpout 的maxBatchSize为5.
FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"), 5,
new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some candy"),
new Values("four score and seven years ago"),
new Values("how many apples can you eat"),
new Values("to be or not to be the person"));
spout.setCycle(false);Trident实现词频统计
接下来我们创建TridentTopology计算词频, 并将实时统计的结果保存在TridentState中:
TridentTopology topology = new TridentTopology();
Config conf = new Config();
conf.setMaxSpoutPending(20);
conf.setNumWorkers(3);
LocalDRPC drpc = new LocalDRPC();
LocalCluster localCluster = new LocalCluster();
TridentState wordCounts =
topology.newStream("spout1", spout).parallelismHint(16)
.each(new Fields("sentence"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"))
.parallelismHint(3);解析:
TridentTopology的newStream方法传入了一个spout对象,spout对象会从外部读取数据并输出到当前topology当中,从而在topology中创建了一个新的数据流.- Trident会在Zookeeper中保存一小部分状态信息来追踪数据的处理情况,而在代码中我们指定的字符串“spout1”就是Zookeeper中用来存储metadata信息的Znode节点.
persistentAggregate方法会把数据流转换成一个TridentState对象, TridentState记录了单词的实时词频。
处理过程:
- 根据空格拆分sentence,并将拆分出的每个单词作为一个tuple输出
- 根据“word”字段进行groupBy操作
persistentAggregate会帮助你把计数的结果进行存储
提供DRPC服务实现实时词频查询
通过newDRPCStream可以接受DRPC客户端请求的参数:
topology.newDRPCStream("words", drpc)
.each(new Fields("args"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.stateQuery(wordCounts, new Fields("word"), new MapGet(), new Fields("count"))
.each(new Fields("count"), new FilterNull())
.project(new Fields("word", "count"))
.aggregate(new Fields("count"), new Sum(), new Fields("sum"));解析:
- 对参数按照空格切分后作为
word字段发射出去, 再对word进行groupBy操作. - 使用
stateQuery来在上面代码中创建的TridentState对象上进行查询。 stateQuery利用MapGet来获取每个单词的出现个数。- 由于DRPC stream是使用跟TridentState完全同样的group方式(按照“word”字段进行group),每个单词的查询会被路由到
TridentState的相应分区去执行。 - 用
FilterNull这个过滤器把从未出现过的单词给去掉, - 并使用
Sum这个聚合器将这些词频统计结果累加起来。最终,Trident会自动把这个结果发送回等待的客户端。
提交到集群
为了更快看到结果, 这里使用本地提交方式:
localCluster.submitTopology(topoName, conf, topology.build());DRPC本地客户端发起实时查询
下面这部分实现了一个低延时的单词数量的分布式实时DRPC查询。这个查询以一个用空格分割的单词列表为输入,并返回这些单词事实出现次数。
这些查询是像普通的RPC调用那样被执行的,要说不同的话,那就是他们在后台是并行执行的。下面是执行DRPC实时查询的一个例子:
for (int i = 0; i < 10; i++) {
System.out.println("DRPC RESULT: " + drpc.execute("words", "cat the dog jumped"));
Thread.sleep(1000);
}
localCluster.shutdown();
drpc.shutdown();解析:
- 发起DRPC请求, 请求的参数是"cat the dog jumped", 每隔1秒查询一次, 共10次.
Trident在如何最大程度的保证执行topogloy性能方面是非常智能的。在topology中会自动的发生两件非常有意思的事情:
- 更新状态和读取状态操作 (比如说 persistentAggregate 和 stateQuery) 会自动的是batch的形式操作状态。
- 如果有20次更新需要被同步到存储中,Trident会自动的把这些操作汇总到一起批处理,只做一次读写操作,而不是进行20次读写操作。
因此你可以在很方便的执行计算的同时,保证了非常好的性能。
Trident 的聚合器已经是被优化的非常好了的。Trident并不是简单的把一个group中所有的tuples都发送到同一个机器上面进行聚合,而是在发送之前已经进行过一次局部的聚合。打个比方,Count聚合器会先在每个partition上面进行count,然后把每个分片count汇总到一起就得到了最终 的count。这个技术其实就跟MapReduce里面的combiner是一个思想。
完整代码代码:
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.LocalDRPC;
import org.apache.storm.trident.TridentState;
import org.apache.storm.trident.TridentTopology;
import org.apache.storm.trident.operation.BaseFunction;
import org.apache.storm.trident.operation.TridentCollector;
import org.apache.storm.trident.operation.builtin.Count;
import org.apache.storm.trident.operation.builtin.FilterNull;
import org.apache.storm.trident.operation.builtin.MapGet;
import org.apache.storm.trident.testing.FixedBatchSpout;
import org.apache.storm.trident.testing.MemoryMapState;
import org.apache.storm.trident.tuple.TridentTuple;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
/**
* 将wordcount结果持久化到数据库
*/
public class AxTridentWordCountLocally {
public static void main(String[] args) throws Exception {
String topoName = "wordCounter";
FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"), 5,
new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some candy"),
new Values("four score and seven years ago"),
new Values("how many apples can you eat"),
new Values("to be or not to be the person"));
spout.setCycle(false);
TridentTopology topology = new TridentTopology();
Config conf = new Config();
conf.setMaxSpoutPending(20);
conf.setNumWorkers(3);
LocalDRPC localDRPC = new LocalDRPC();
LocalCluster localCluster = new LocalCluster();
/*
* 根据数据源拆分单词后,然后分区操作,在每个分区上又进行分组(hash算法),然后在每个分组上进行聚合
* 所以这里可能有多个分区,每个分区有多个分组,然后在多个分组上进行聚合
* 用来进行group的字段会以key的形式存在于State当中,聚合后的结果会以value的形式存储在State当中
*/
TridentState wordCounts = topology.newStream("spout1", spout).parallelismHint(16)
.each(new Fields("sentence"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"))
.parallelismHint(3);
topology.newDRPCStream("words", localDRPC).each(new Fields("args"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.stateQuery(wordCounts, new Fields("word"), new MapGet(), new Fields("count"))
.each(new Fields("count"), new FilterNull())
.project(new Fields("word", "count"));
localCluster.submitTopology(topoName, conf, topology.build()); //异步
for (int i = 0; i < 10; i++) {
System.out.println("DRPC RESULT: " + localDRPC.execute("words", "cat the dog jumped"));
Thread.sleep(1000);
}
localCluster.shutdown();
localDRPC.shutdown();
}
public static class Split extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
String sentence = tuple.getString(0);
for (String word : sentence.split(" ")) {
collector.emit(new Values(word));
}
}
}
}
执行结果
在执行上述代码之后,可能输出如下所示:
DRPC RESULT: []
DRPC RESULT: [["the",30],["jumped",6]]
DRPC RESULT: [["the",84],["jumped",16]]
DRPC RESULT: [["jumped",26],["the",130]]
DRPC RESULT: [["jumped",30],["the",149]]
DRPC RESULT: [["jumped",40],["the",199]]
DRPC RESULT: [["the",245],["jumped",49]]
DRPC RESULT: [["jumped",59],["the",295]]
DRPC RESULT: [["the",345],["jumped",69]]
DRPC RESULT: [["the",394],["jumped",79]]数据流向示意图
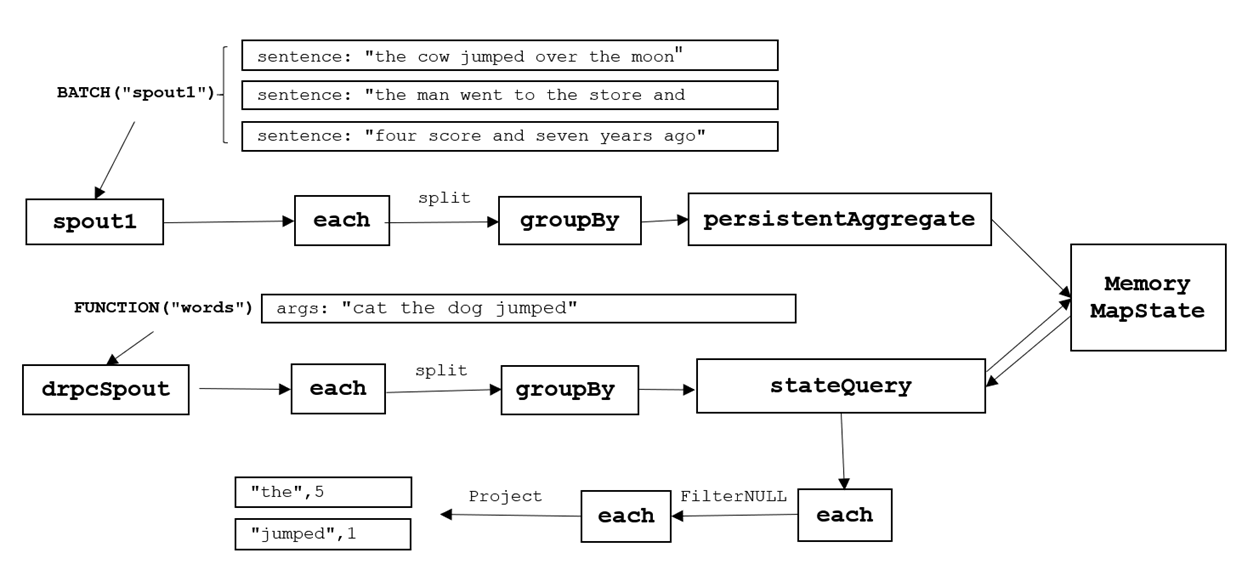
远程提交模式
import org.apache.storm.Config;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.trident.TridentState;
import org.apache.storm.trident.TridentTopology;
import org.apache.storm.trident.operation.BaseFunction;
import org.apache.storm.trident.operation.TridentCollector;
import org.apache.storm.trident.operation.builtin.Count;
import org.apache.storm.trident.operation.builtin.FilterNull;
import org.apache.storm.trident.operation.builtin.MapGet;
import org.apache.storm.trident.testing.FixedBatchSpout;
import org.apache.storm.trident.testing.MemoryMapState;
import org.apache.storm.trident.tuple.TridentTuple;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.DRPCClient;
public class CxTridentWordCountRemotely {
public static StormTopology buildTopology() {
FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"), 3, new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some candy"),
new Values("four score and seven years ago"),
new Values("how many apples can you eat"), new Values("to be or not to be the person"));
spout.setCycle(true);
TridentTopology topology = new TridentTopology();
TridentState wordCounts = topology.newStream("spout1", spout).parallelismHint(16).each(new Fields("sentence"),
new Split(), new Fields("word"))
.groupBy(new Fields("word")).persistentAggregate(new MemoryMapState.Factory(),
new Count(), new Fields("count"))
.parallelismHint(16);
topology.newDRPCStream("words").each(new Fields("args"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.stateQuery(wordCounts, new Fields("word"), new MapGet(), new Fields("count"))
.each(new Fields("count"), new FilterNull())
.project(new Fields("word", "count"));
return topology.build();
}
public static void main(String[] args) throws Exception {
Config conf = new Config();
conf.setMaxSpoutPending(20);
String topoName = "wordCounter";
if (args.length > 0) {
topoName = args[0];
}
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar(topoName, conf, buildTopology());
try (DRPCClient drpc = DRPCClient.getConfiguredClient(conf)) {
for (int i = 0; i < 10; i++) {
System.out.println("DRPC RESULT: " + drpc.execute("words", "cat the dog jumped"));
Thread.sleep(1000);
}
}
}
public static class Split extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
String sentence = tuple.getString(0);
for (String word : sentence.split(" ")) {
collector.emit(new Values(word));
}
}
}
}打成jar包上传到集群
Views: 626