
什么是Storm?
Storm为分布式实时计算提供了一组通用原语,可被用于“流处理”之中,实时处理消息并更新数据库。这是管理队列及工作者集群的另一种方式。 Storm也可被用于“连续计算”(continuous computation),对数据流做连续查询,在计算时就将结果以流的形式输出给用户。它还可被用于“分布式RPC”,以并行的方式计算。
Storm可以方便地在一个计算机集群中编写与扩展复杂的实时计算,Storm用于实时处理,就好比 Hadoop 用于批处理。Storm保证每个消息都会得到处理,而且它很快——在一个小集群中,每秒可以处理数以百万计的消息。更棒的是你可以使用任意编程语言来做开发。
离线计算和流式计算
离线计算
-
离线计算:批量获取数据、批量传输数据、周期性批量计算数据、数据展示
-
代表技术:Sqoop批量导入数据、HDFS批量存储数据、MapReduce批量计算、Hive
流式计算
(终极目的:留住用户,提升用户体验)
-
流式计算:数据实时产生、数据实时传输、数据实时计算、实时展示
-
代表技术:Flume实时获取数据、Kafka实时数据存储、Storm实时数据计算、Redis实时结果缓存。
-
一句话总结:将源源不断产生的数据实时收集并实时计算,尽可能快的得到计算结果
Storm与Hadoop的区别
| Storm | Hadoop |
|---|---|
| Storm用于实时计算 | Hadoop用于离线计算 |
| Storm的数据保存在内存,源源不断 | Hadoop的数据保存在文件系统中,一批一批 |
| Storm的数据通过网络传输进来 | Hadoop的数据保存在磁盘中 |
| Storm与Hadoop的编程模型相似 | Storm与Hadoop的编程模型相似 |
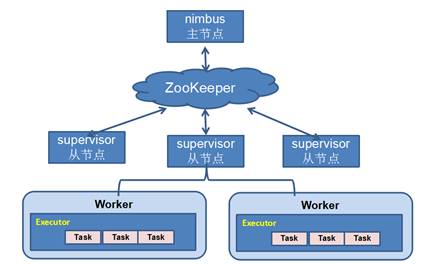
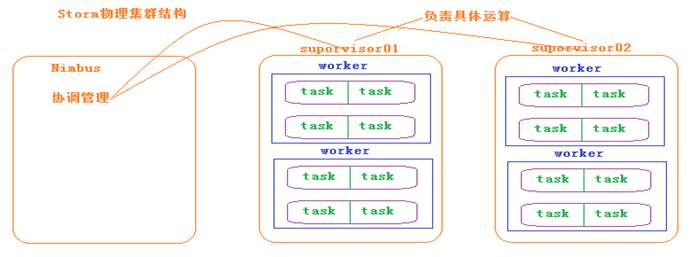
Storm的体系结构
-
Nimbus:负责资源分配和任务调度。
-
Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。通过配置文件设置当前supervisor上启动多少个worker。
-
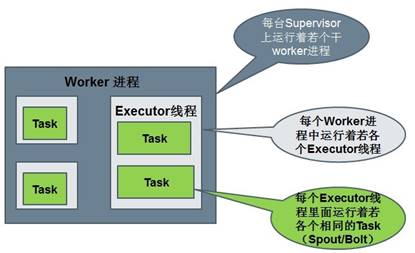
Worker:运行具体处理组件逻辑的进程。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。
-
Executor:Storm 0.8之后,Executor为Worker进程中的具体的物理线程,同一个Spout/Bolt的Task可能会共享一个物理线程,一个Executor中只能运行隶属于同一个Spout/Bolt的Task。
-
Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。
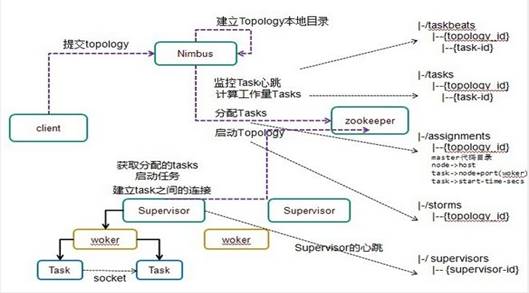
Storm的运行机制
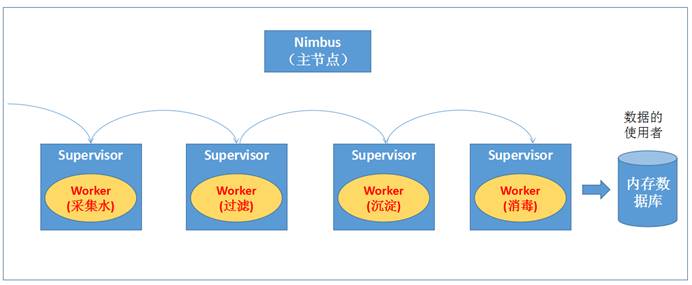
-
整个处理流程的组织协调不用用户去关心,用户只需要去定义每一个步骤中的具体业务处理逻辑
-
具体执行任务的角色是Worker,Worker执行任务时具体的行为则有我们定义的业务逻辑决定
参考
官方网站: http://storm.apache.org/
官方文档: http://storm.apache.org/releases/2.1.0/index.html
Views: 271