

一、课前准备
- 安装好Hadoop集群
- 安装好kafka集群
二、课堂主题
- 学习Druid的架构、安装、使用
三、课堂目标
- 了解druid
- 了解druid的应用场景
- 了解druid架构原理
- 了解druid数据结构
- 安装部署druid
- 使用druid
四、知识要点
1. druid是什么
Druid是一个专为大型数据集上的高性能切片和OLAP分析而设计的数据存储系统。
- 它使用了分布式的、列式存储,支持实时分析
- 相比传统的OLAP系统,在处理PB级别数据、毫秒级查询、实时处理方面,有很大的性能优势
- Druid最常用作为GUI分析应用程序提供的数据存储,或者用作需要快速聚合的高度并发API的后端。
- 官网地址:https://druid.apache.org/
注意:不要跟阿里巴巴的数据库连接池项目druid混淆;她们是完全不同的两个框架
2. druid的特点
1.列式存储格式
- Druid使用面向列的存储,这意味着它只需要加载特定查询所需的精确列。这为仅查看几列的查询提供了巨大的性能提升。
- 此外,每列都针对其特定数据类型进行了优化,支持快速扫描和聚合。
2.高可用性与高可拓展性
-
Druid采用分布式、SN(share-nothing)架构,管理类节点可配置HA,工作节点功能单一,不相互依赖,这些特性都使得Druid集群在管理、容错、灾备、扩容等方面变得十分简单。
-
Druid通常部署在数十到数百台服务器的集群中,并且可以提供数百万条记录/秒的摄取速度,保留数万亿条记录,以及亚秒级到几秒钟的查询延迟。
3.大规模并行处理
- Druid可以在整个集群中并行处理查询。
4.实时或批量摄取
-
实时流数据分析。区别于传统分析型数据库采用的批量导入数据进行分析的方式
-
Druid提供了实时流数据分析,采用LSM(Log structure-merge)-Tree结构使Druid拥有极高的实时写入性能;
-
同时实现了实时数据在亚秒级内的可视化。
5.自愈,自平衡,易于操作
- 作为运营商,要将集群扩展或缩小,只需添加或删除服务器,群集将在后台自动重新平衡,无需任何停机时间。
- 如果任何Druid服务器发生故障,系统将自动路由损坏,直到可以更换这些服务器。
- Druid旨在全天候运行,无需任何原因计划停机,包括配置更改和软件更新。
6.云原生,容错的架构,不会丢失数据
- 一旦Druid摄取了数据,副本就会安全地存储在深层存储(通常是云存储,HDFS或共享文件系统)中。
- 即使每个Druid服务器都出现故障,您的数据也可以从深层存储中恢复。
- 对于仅影响少数Druid服务器的更有限的故障,复制可确保在系统恢复时仍可进行查询。
7.亚秒级的OLAP查询分析
- Druid采用了列式存储、倒排索引、位图索引等关键技术,能够在亚秒级别内完成海量数据的过滤、聚合以及多维分析等操作。
8.近似算法
- Druid包括用于近似计数 – 不同,近似排序以及近似直方图和分位数的计算的算法。这些算法提供有限的内存使用,并且通常比精确计算快得多。
- 对于精确度比速度更重要的情况,Druid还提供精确计数 – 不同且精确的排名。
9.丰富的数据分析功能
- 针对不同用户群体,Druid提供了友好的可视化界面、类SQL查询语言以及REST 查询接口。
10.数据进行了预聚合或预计算,查询速度快
- 对数据采用了bitmap算法压缩
3. druid的应用场景
适合的场景:
- 插入新数据的量很大,但是并不经常对已插入的数据进行修改。
- 大部分查询请求是聚合和报表类查询(group by 类查询);也可以支持搜索和扫描类查询。
- 实时性要求高:期望的查询响应时间是100毫秒到几秒之间。
- 数据是基于时间组织的(Druid对时间处理做了专门的优化)。
- 可以有多个表,但是每次查询都只能对一个大表进行操作。但是需要的时候可以join一些小的信息表。
- 你的列具有很高的基数(比如url或者用户id),同时需要进行快速的计数以及根据计数进行排序。
- 你需要从kafka,HDFS,普通文件,或者类似于Amazon S3之类对象存储中加载数据。
- 适用于数据质量不高的场景
不适合的场景;
- 你需要通过一些主键对已有的数据进行低延迟的更新。Druid支持流式插入,但是不支持流式更新(更新需要通过后台批处理任务)。
- 你需要建立一个离线的报表系统,因此查询延迟并不是系统的关键因素。
- 你需要对多个大表进行join操作。
4. druid于其他分析框架对比
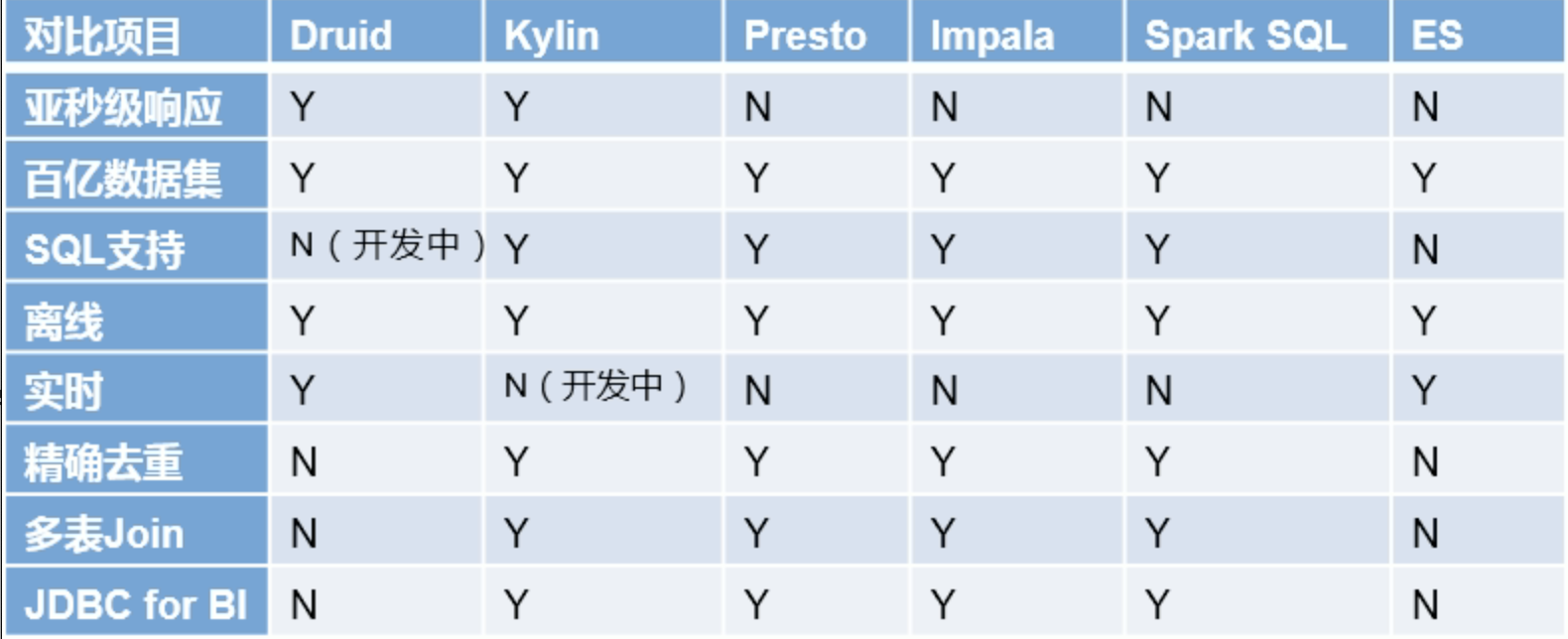
-
druid是一个基于时序数据的实时的OLAP工具;其索引首先按照时间分片,查询也是按时间去路由索引
-
kylin核心概念cube,本质上预计算;即预先对数据创建多维索引,查询时并非是全表扫描,只扫描索引,从而提升查询速度
-
presto计算在内存中完成,减少磁盘io;比hive快一个数量级
-
impala基于内存进行计算,速度快;但是presto支持的数据源比impala多
-
spark sql基于内存的OLAP框架
-
es使用倒排索引解决索引问题;es在获取数据及聚集时用的资源要比druid高
-
技术选型
- 针对超大数据的查询效率
druid(精确度不高、基于内存、预计算) > kylin(预计算) > presto(基于内存的) > spark sql
druid 实时分析、kylin预计算、presto临时的任务、spark sql定时任务
- 支持的数据源多少
presto > spark sql > kylin > druid
5. druid架构原理
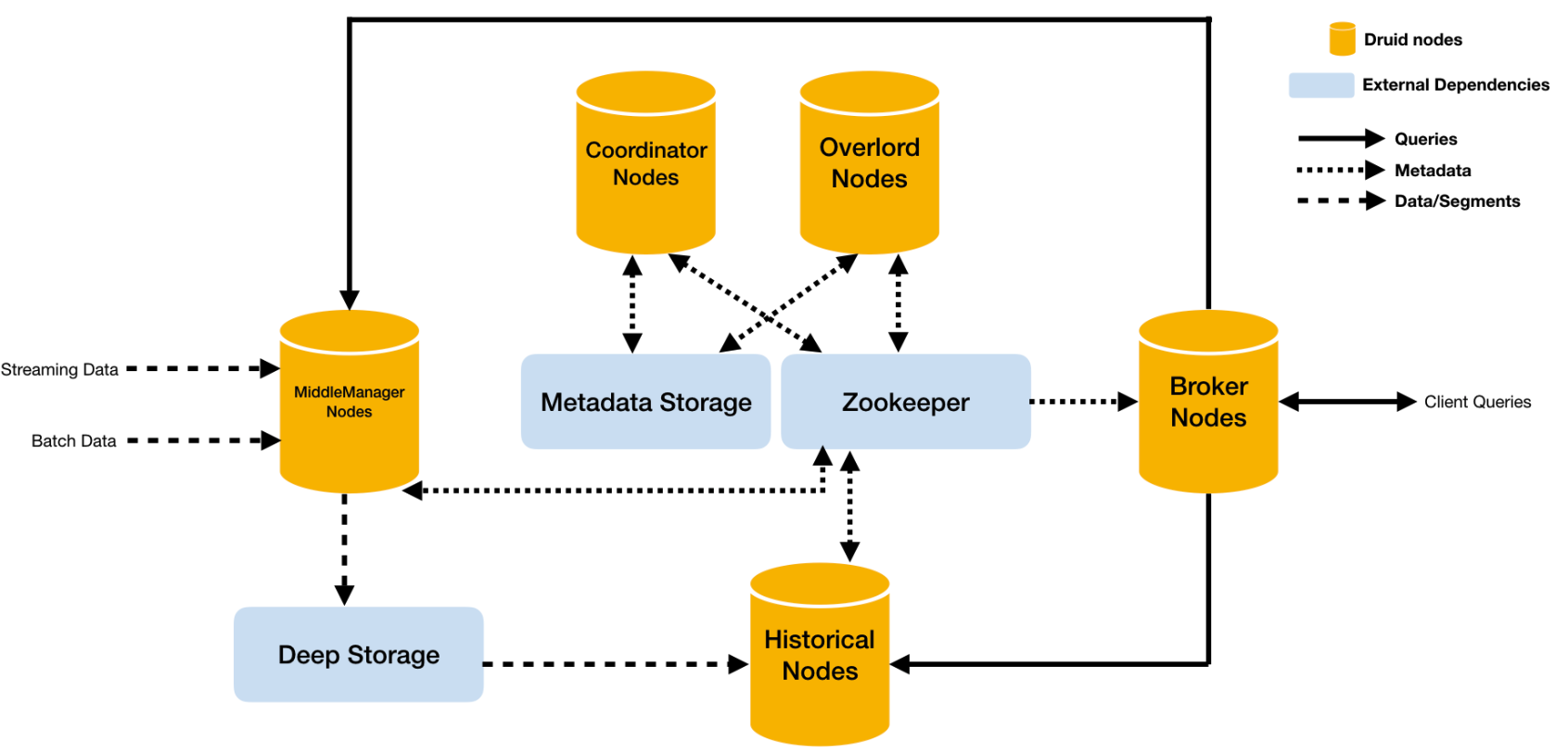
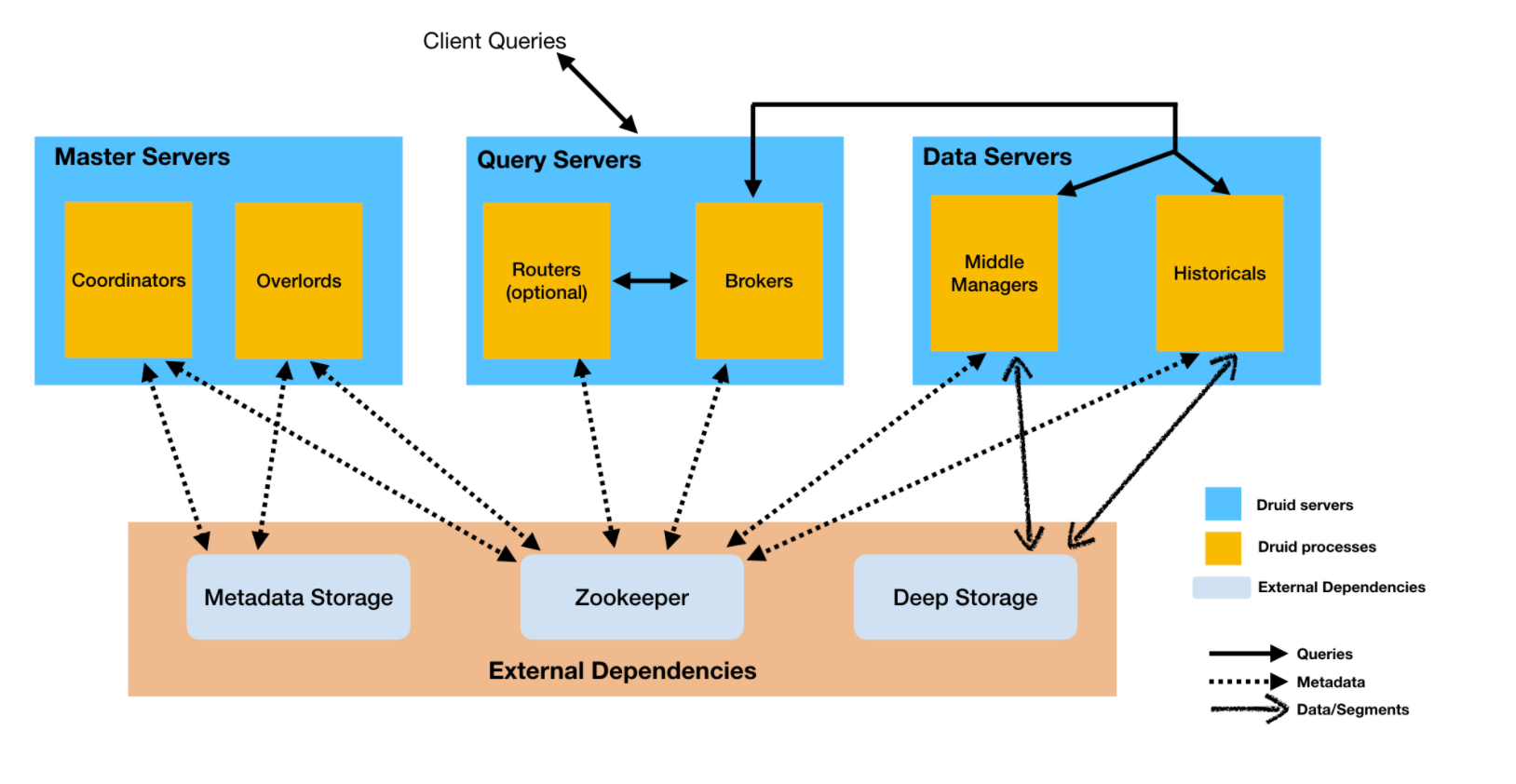
- middlemanager node中间管理节点,及时消费进来的数据,生成segment文件
- historical node加载已生成的数据文件,作为查询到数据源;historical会承担大部分的针对segment的查询
- broker node接受客户端的查询请求,然后将请求转发给historical node及middle manager node;当自查询返回结果时,broker会合并这些结果,并返回给调用者
- coordinator node通过规则管理数据的生命周期及负责historical node数据的负载均衡
- overlord node用于监控middle manager进程;控制druid数据的摄入;负责将提取的任务分配给middle manager并协调segment的发布
- deep storage存储segment文件,并供historical node下载;单节点集群一般时本地磁盘;分布式集群一般时HDFS
- metadata storage存储druid集群的元数据,比如segment有关信息,一般使用mysql存储元数据
- zookeeper为druid提供分布式协调服务;如领导者的选举、服务的监控、协调
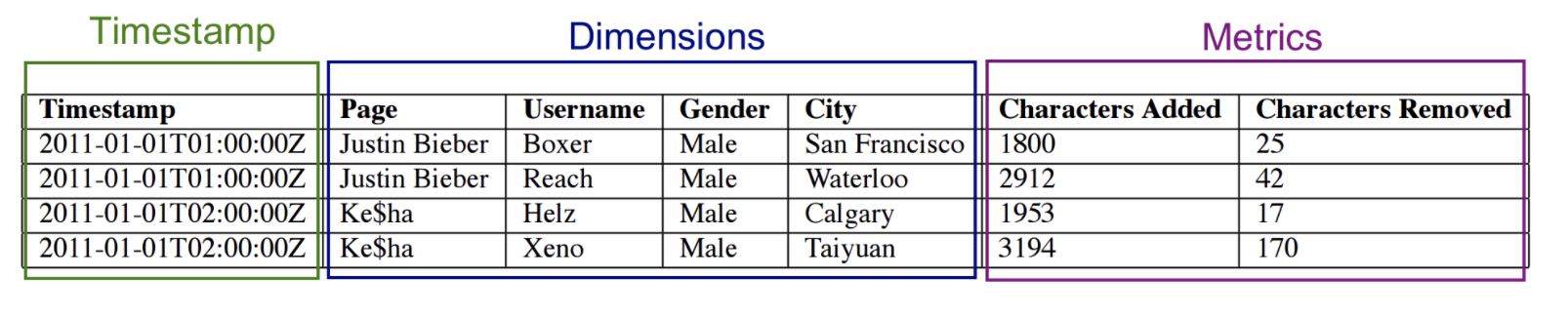
6. druid数据结构
Druid的高性能,除了来自LSM-Tree的贡献,其DataSource以及Segment的完美设计也功不可没
1. DataSource
- druid的数据存储在datasources中;DataSource类似于数据库中的表;每一个datasource的数据,基于“时间”进行了分区;
- 每个时间范围的数据,称为chunk(如果datasource被时间单位天分区,每天一个分区,那么每天的数据,组成一个chunk);
- 一个chunk的数据被分到一个或多个segment中;每个segment是一个单独的文件,一般包含几百万行数据
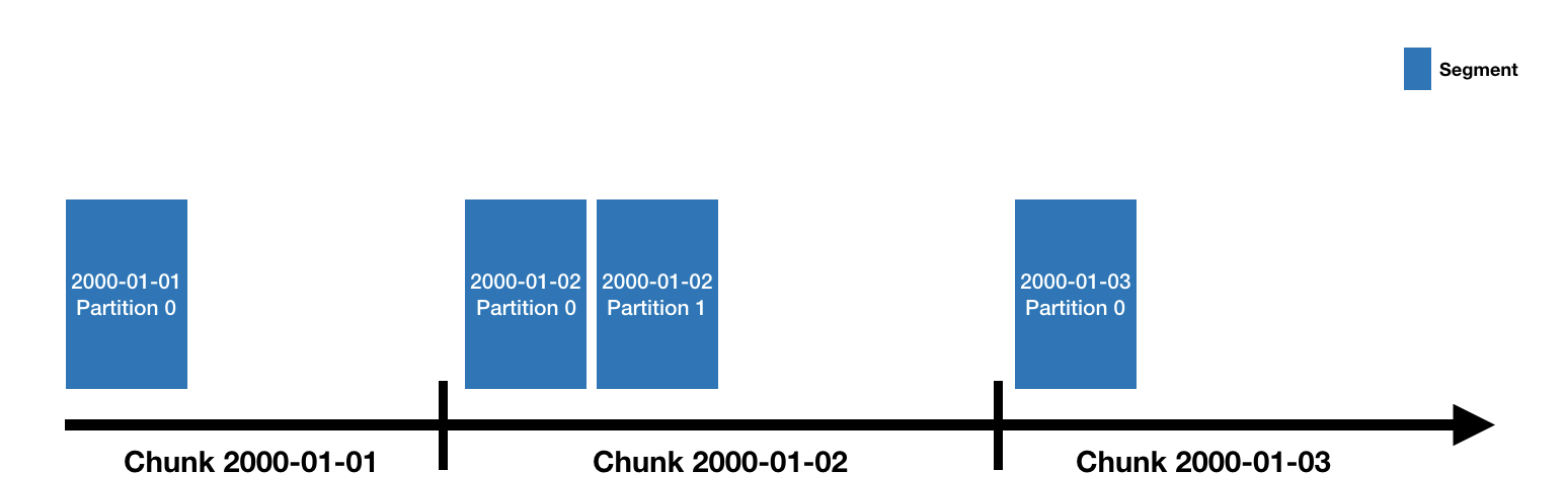
-
一个DataSource可以有少数几个segment构成,也可能包含多达数十万甚至上百万个segment。
-
datasource结构包括
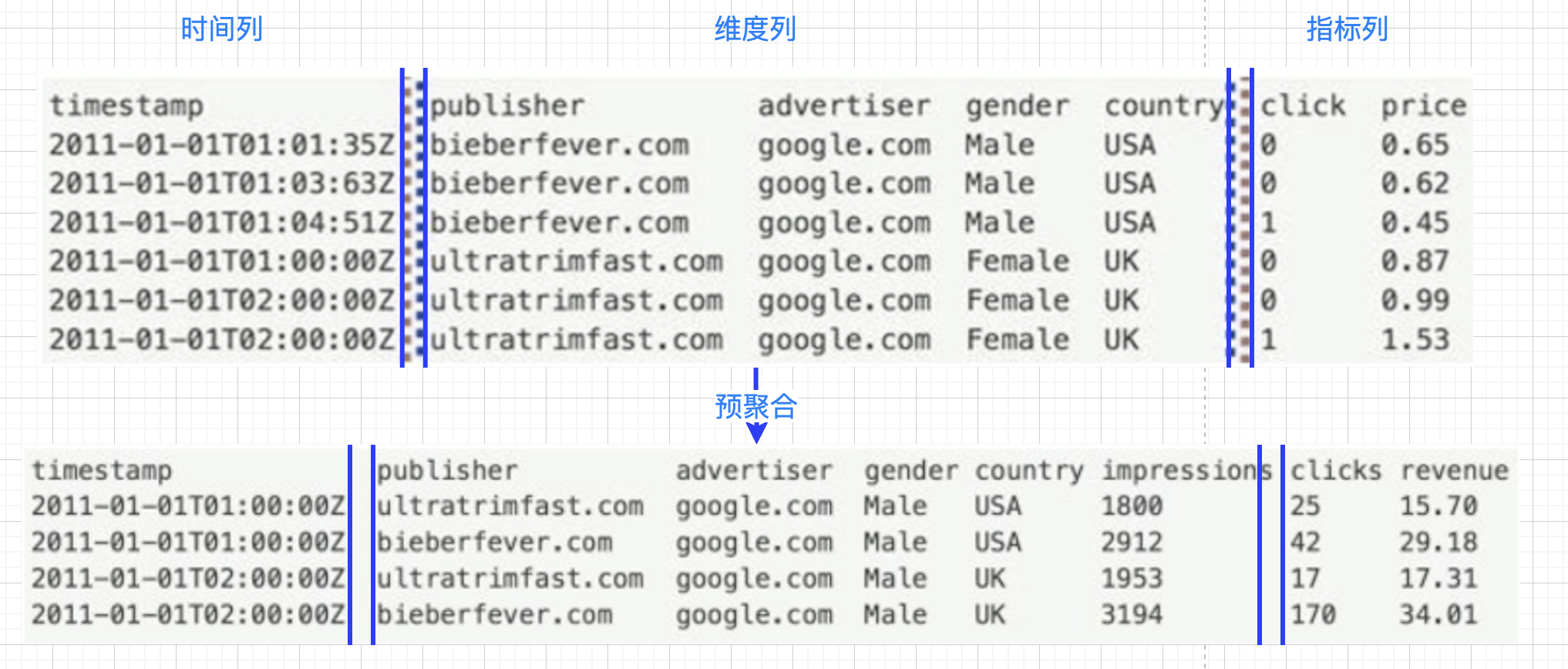
- 时间列:表示每条记录对应的时间,默认时UTC格式,精确到毫秒
- 维度列:OLAP中的概念,标识记录中的类别信息
- 指标列:用于计算和聚合的列;通常是数字,做些如count、sum、avg等的操作
-
无论数据来自实时数据还是批量数据,druid在基于DataSource结构存储数据时,就可以选择对任意的指标列进行聚合操作。该聚合操作主要基于维度列、时间范围两方面
-
在数据存储时,druid可对数据进行聚合操作;使得druid不仅减少了存储开销,而且提高了聚合查询的效率
2. segment
- 所有的segment的生命周期从在MiddleManager接收数据时被创建
- 最初的时候,segment是处于可修改和未提交的状态,segment的数据是紧凑的并且支持快速查询,它是通过如下步骤被创建:
- 数据的横向切割:横向切割主要只指站在时间范围的角度,将不同时间段的数据存储在不同的Segment文件中(时间范围可以通过segmentGranularity进行设置),查询时只需要根据时间条件遍历对应的Segment文件即可。
- 把数据转换成列式格式;面向列进行数据压缩
- 通过bitmap编码来建立倒排索引;
- 通过不同的算法进行压缩:
- 对于string类型的列,通过字典编码的方式将string转换为id以最小化存储空间;
- 对bitmap索引进行位图压缩;使用BitMap等技术对数据访问进行优化
- 所有的列都根据类型来选择合适的压缩算法;
- segment会被定期提交和发布。提交时他们会被写入deepstorage中,提交后会变成不可改变的状态,然后数据就被从MiddleManager移交给Historical进程。
7. 安装部署druid
-
说明
- 安装部署druid可以使用druid原始的安装方式,但是比较麻烦,需要针对druid集群中各种node节点,修改相应的配置文件
有兴趣,可以自己看下druid的集群安装方式:https://druid.apache.org/docs/latest/tutorials/cluster.html
-
此处,我们采用imply进行安装druid;imply集成了apache druid,可通过图形化界面操作Druid,让druid更加易用
-
另外,此处采用单节点安装,应为druid集群安装对各节点的资源要求比较高;
-
单节点安装前提:
jdk1.8
linux或Mac OS操作系统
最少4G内存,建议给的大些,如8G
- 若自己有足够的机器及资源,对集群模式安装感兴趣的话,可以参考官网文档:https://docs.imply.io/2.7/on-prem/deploy/cluster
druid官网:https://druid.apache.org/
imply官网:https://imply.io/
1. 下载安装包
安装包上传到node01的目录/kkb/soft
2. 解压
|
1 2 |
cd /kkb/soft tar -zxvf imply-2.7.10.tar.gz -C /kkb/install |
3. 修改配置文件
- 修改common.runtime.properties
|
1 2 |
cd /kkb/install/imply-2.7.10/conf/druid/_common/ vim common.runtime.properties |
- 修改如下zk属性
|
1 |
druid.zk.service.host=node01:2181,node02:2181,node03:2181 |
- 修改启动命令参数,使其不校验、不启动内置ZK
|
1 |
vim /kkb/install/imply-2.7.10/conf/supervise/quickstart.conf |
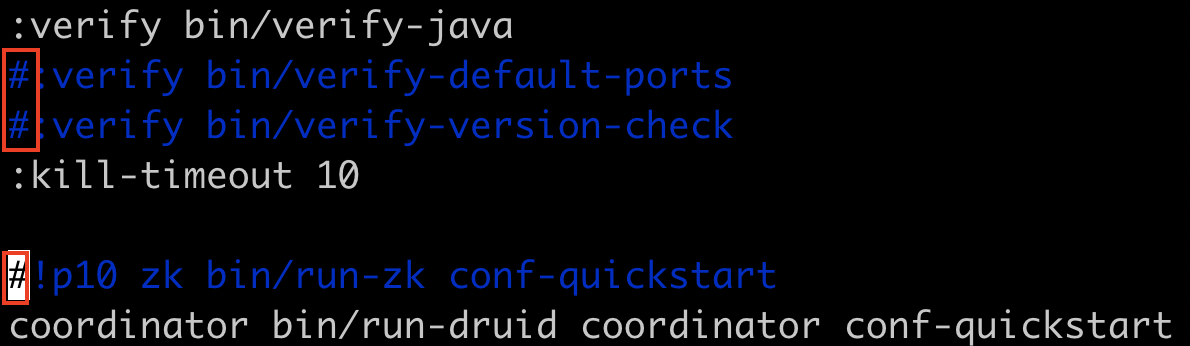
- 修改如下内容
|
1 2 3 4 5 6 7 8 9 |
:verify bin/verify-java #:verify bin/verify-default-ports #:verify bin/verify-version-check :kill-timeout 10 #!p10 zk bin/run-zk conf-quickstart |
4. 启动druid
- 3个节点分别运行命令,启动Zookeeper
|
1 |
zkServer.sh start |
- node0启动imply,先进入imply目录
|
1 |
bin/supervise -c conf/supervise/quickstart.conf |
每启动一个服务均会打印出一条日志。可以通过/kkb/install/imply-2.7.10/var/sv/查看服务启动时的日志信息
5. 使用web界面
node01内存调整为8G
需求:在kafka集群中,创建一个topic,名字叫wikipedia
然后,让druid从此topic中获得数据,并对topic数据做分析
- 启动kafka集群,3个节点运行
|
1 2 3 |
[hadoop@node01 kafka_2.11-1.1.0]$ pwd /kkb/install/kafka_2.11-1.1.0 [hadoop@node01 kafka_2.11-1.1.0]$ nohup bin/kafka-server-start.sh config/server.properties 2>&1 & |
- 创建topic wikipedia
|
1 |
bin/kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --partitions 1 --replication-factor 1 --topic wikipedia |
- 确保topic创建成功
|
1 |
bin/kafka-topics.sh --zookeeper node01:2181,node02:2181,node03:2181 --list |
-
使druid能够获得kafka数据
-
我们将使用Druid的Kafka索引服务druid-kafka-indexing-service,从kafka中创建的wikipedia主题中提取消息。要启动kafka索引服务,在Imply目录下运行命令,以向Druid的overlord提交supervisor spec
-
http://druid.io/docs/0.12.3/development/extensions-core/kafka-ingestion.html
-
|
1 2 3 4 5 |
[hadoop@node01 imply-2.7.10]$ pwd /kkb/install/imply-2.7.10 curl -XPOST -H'Content-Type: application/json' -d @quickstart/wikipedia-kafka-supervisor.json http://node01:8090/druid/indexer/v1/supervisor 返回{"id":"wikipedia-kafka"} |

说明:
curl是一个利用URL规则在命令行下的文件传输工具。它支持文件的上传和下载
-X 为 HTTP 数据包指定一个方法,比如 PUT、DELETE。默认的方法是 GET
-H 为 HTTP 数据包指定 Header 字段内容
-d 为 POST 数据包指定要向 HTTP 服务器发送的数据,如果的内容以符号 @ 开头,其后的字符串将被解析为文件名,curl 命令会从这个文件中读取数据发送
执行成功,则返回:{"id":"wikipedia-kafka"}
-
加载历史数据
目录
/kkb/install/imply-2.7.10/quickstart中有wikipedia的json格式的样本数据;现在将样本数据加载进wikipedia主题中
|
1 2 |
export KAFKA_OPTS="-Dfile.encoding=UTF-8" bin/kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic wikipedia < /kkb/install/imply-2.7.10/quickstart/wikipedia-2016-06-27-sampled.json |
确认数据已经进入wikipedia主题中
|
1 |
bin/kafka-console-consumer.sh --zookeeper node01:2181,node02:2181,node03:2181 --topic wikipedia --from-beginning | head -2 |
-
那么kafka的wikipedia主题的数据,被druid的kafka indexing service加载进入druid,那么接下来,就可以在druid中对接入的数据做查询
-
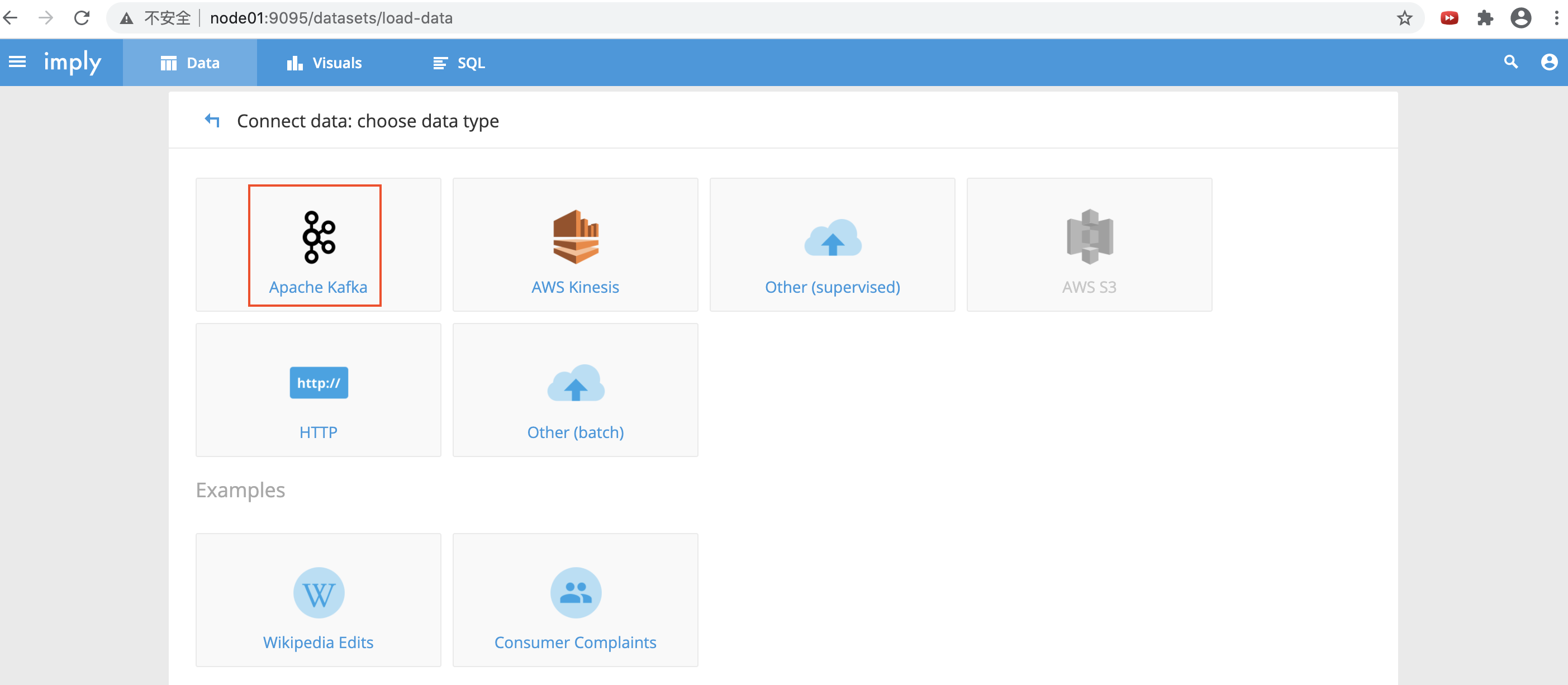
登录node01:9095查看;点击“Load data”,选择加载的数据源
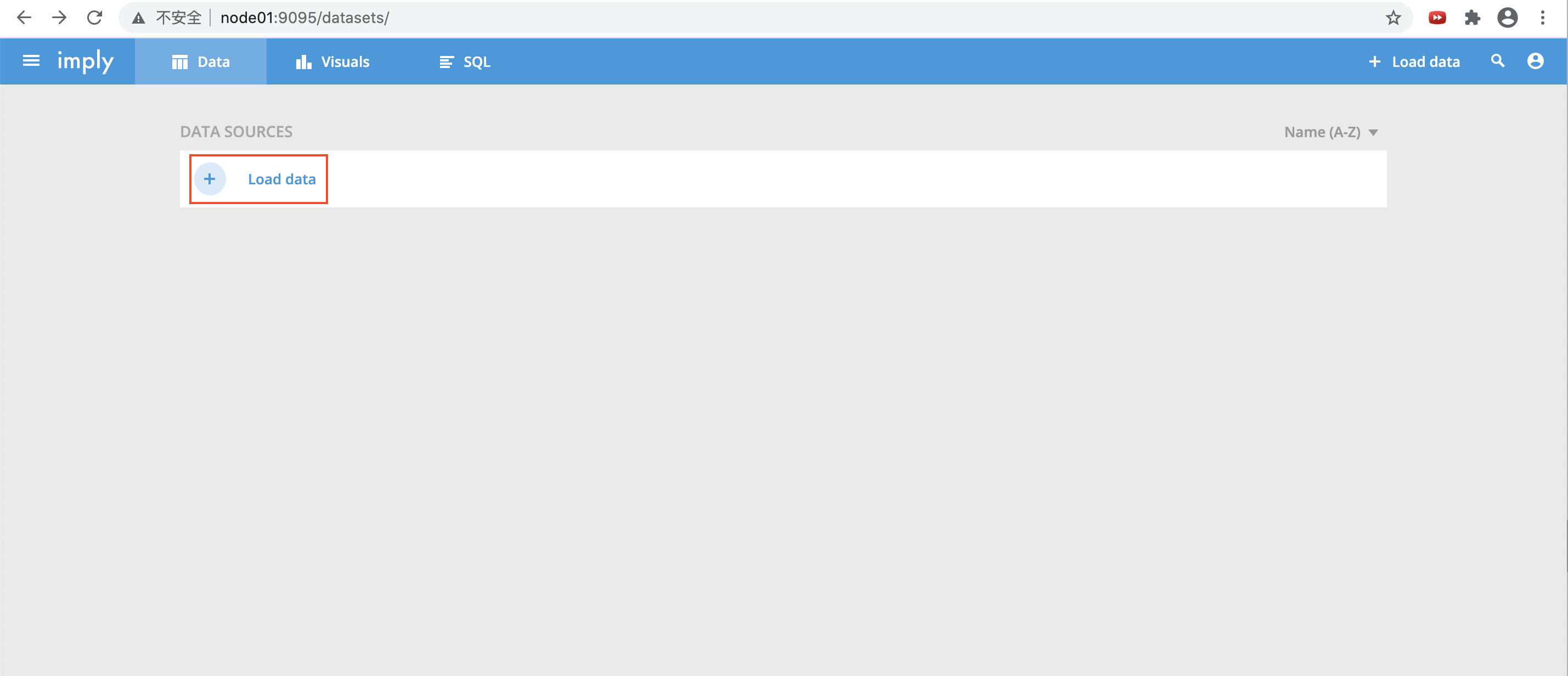
- 选择从apache kafka ingest接入数据
-
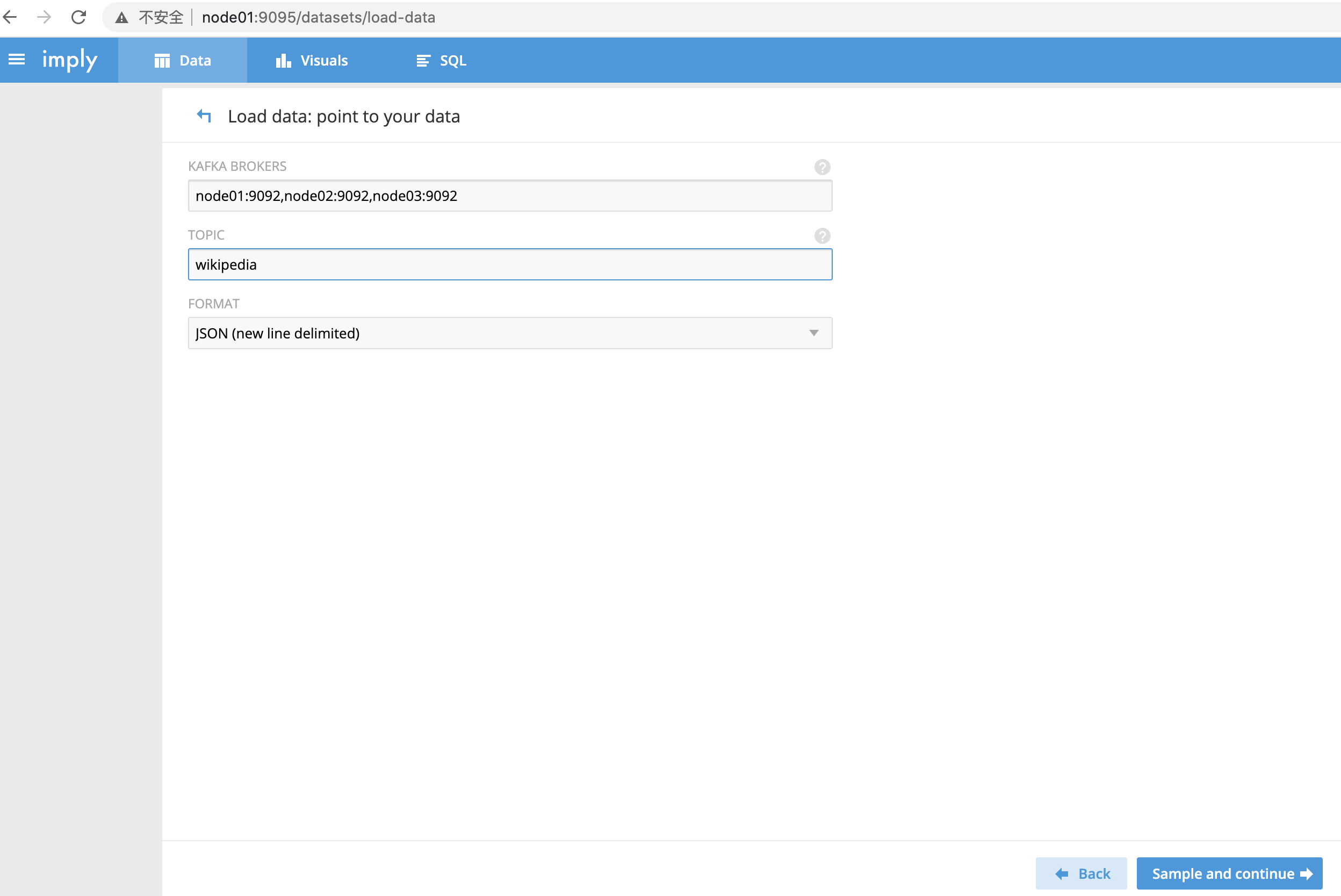
配置kafka相关参数
KAFKA BROKERS 指定要连接的kafka集群
TOPIC 指定要读取的topic数据
FORMAT 指定读取的数据的格式,此处选择JSON
然后,点击“Sample And Continue”
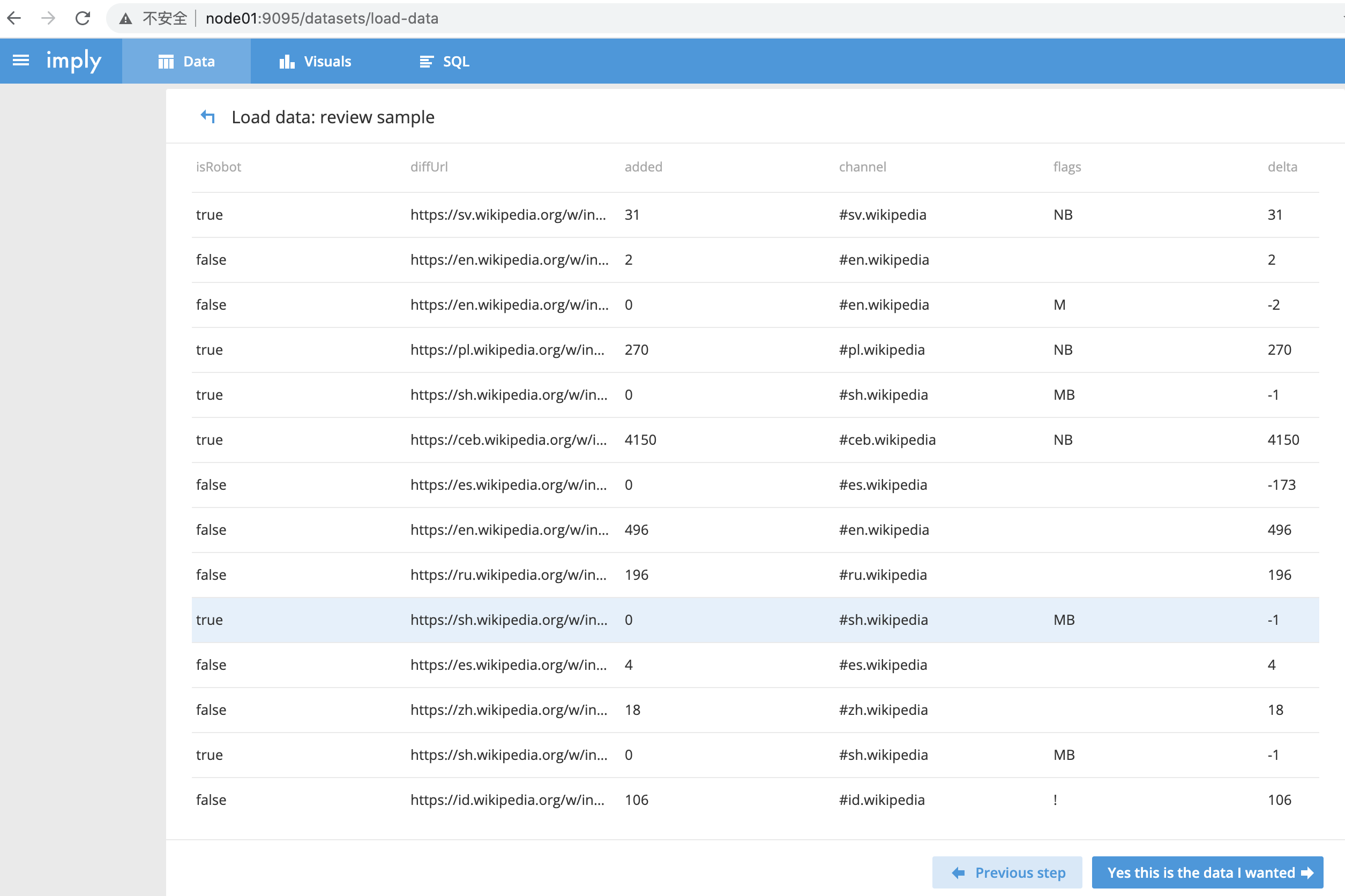
- 加载的数据显示如下
-
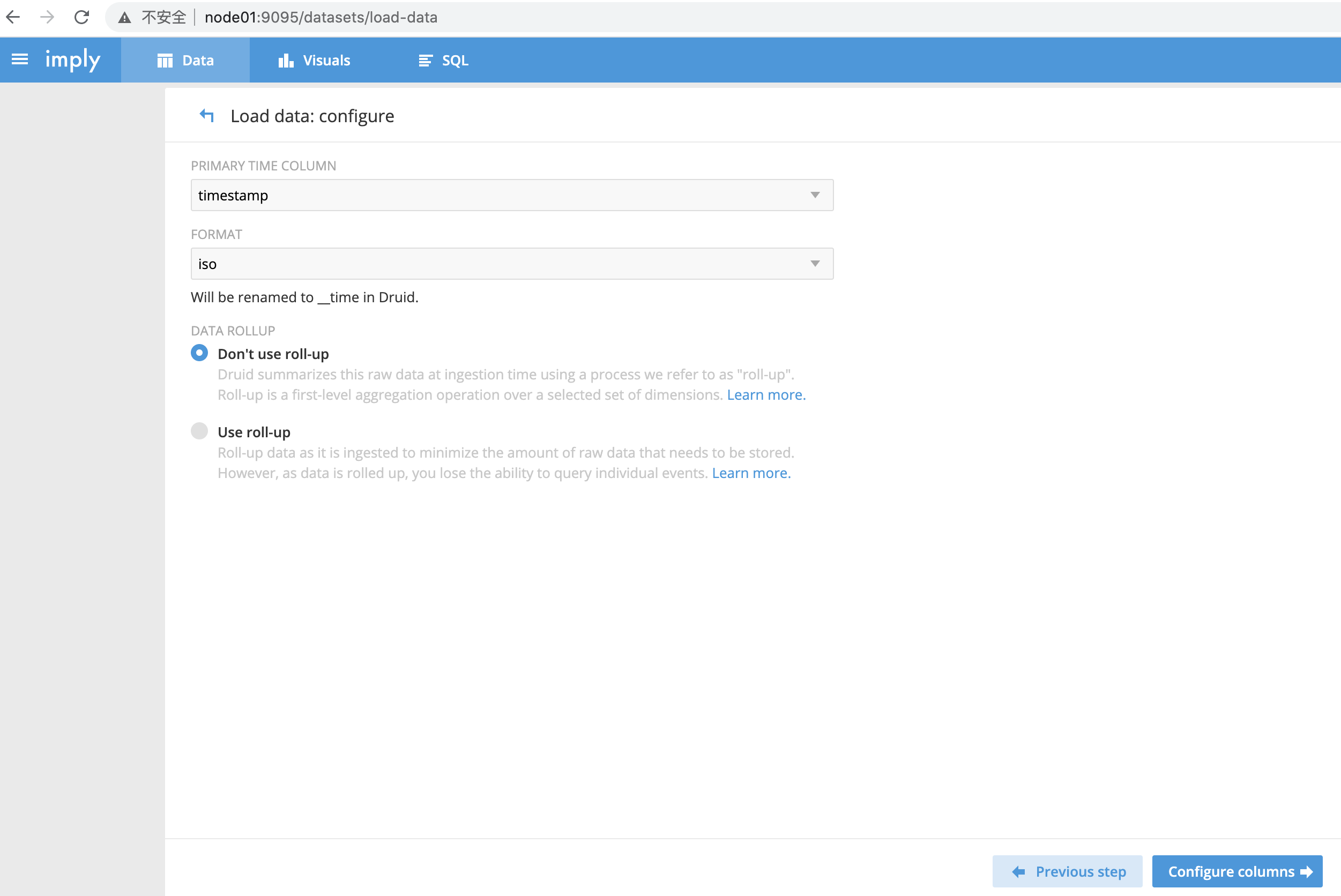
根据之前讲的druid的数据结构,我们知道,druid的segment包含三种数据:时间列、维度列、指标列
指定按照哪个列进行划分segment,此处选择使用名字为timestamp,类型为时间的列,即下图的“PRIMARY TIME COLUMN”
FORMAT选择时间的格式,此处选择iso格式
点击“Configure columns”
- 指定加载哪些列;不需要的列,可以点击右侧的X按钮删除
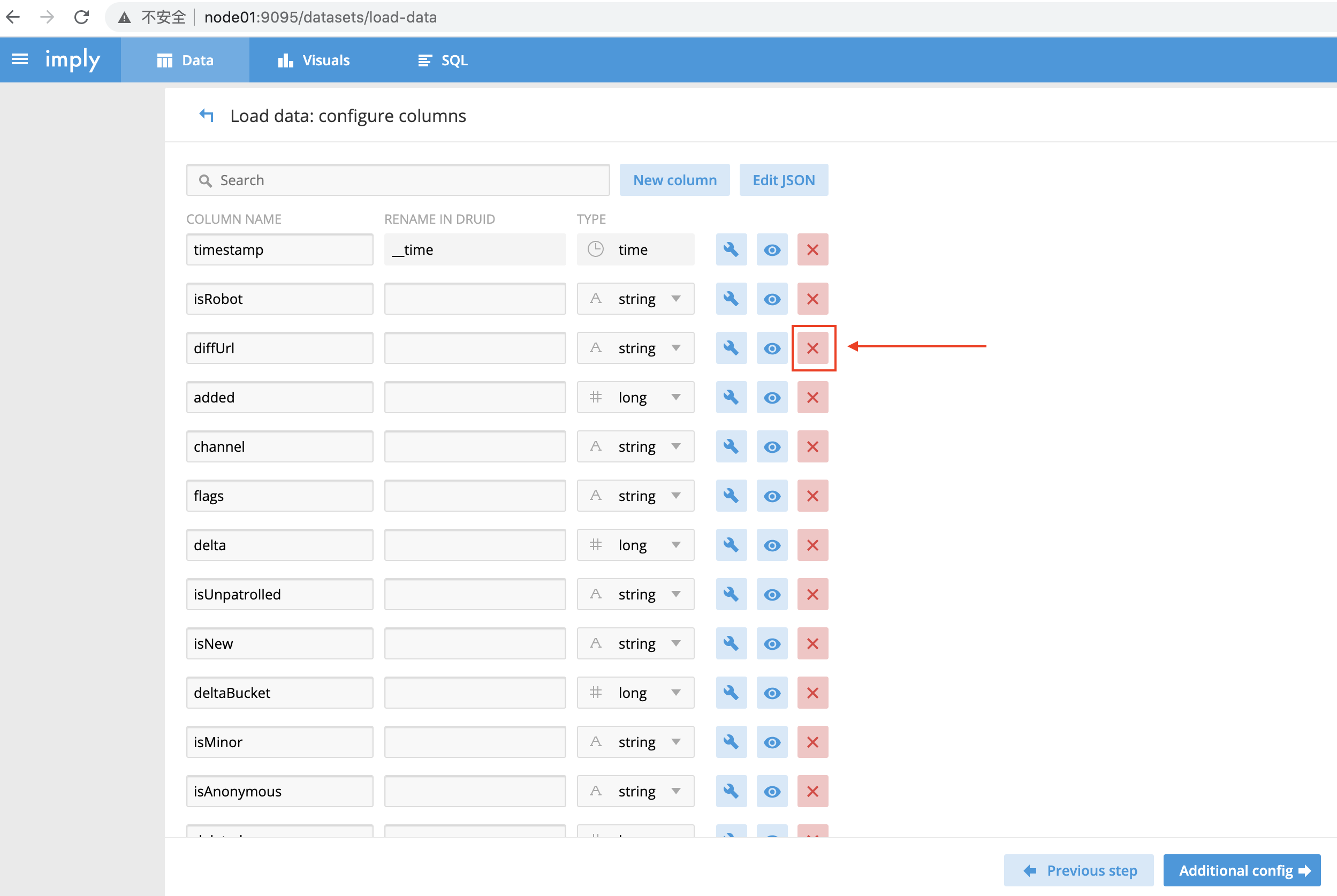
-
设置datasource名称,此处指定为wikipedia
勾选“Automatically create a data cube for this dataset”
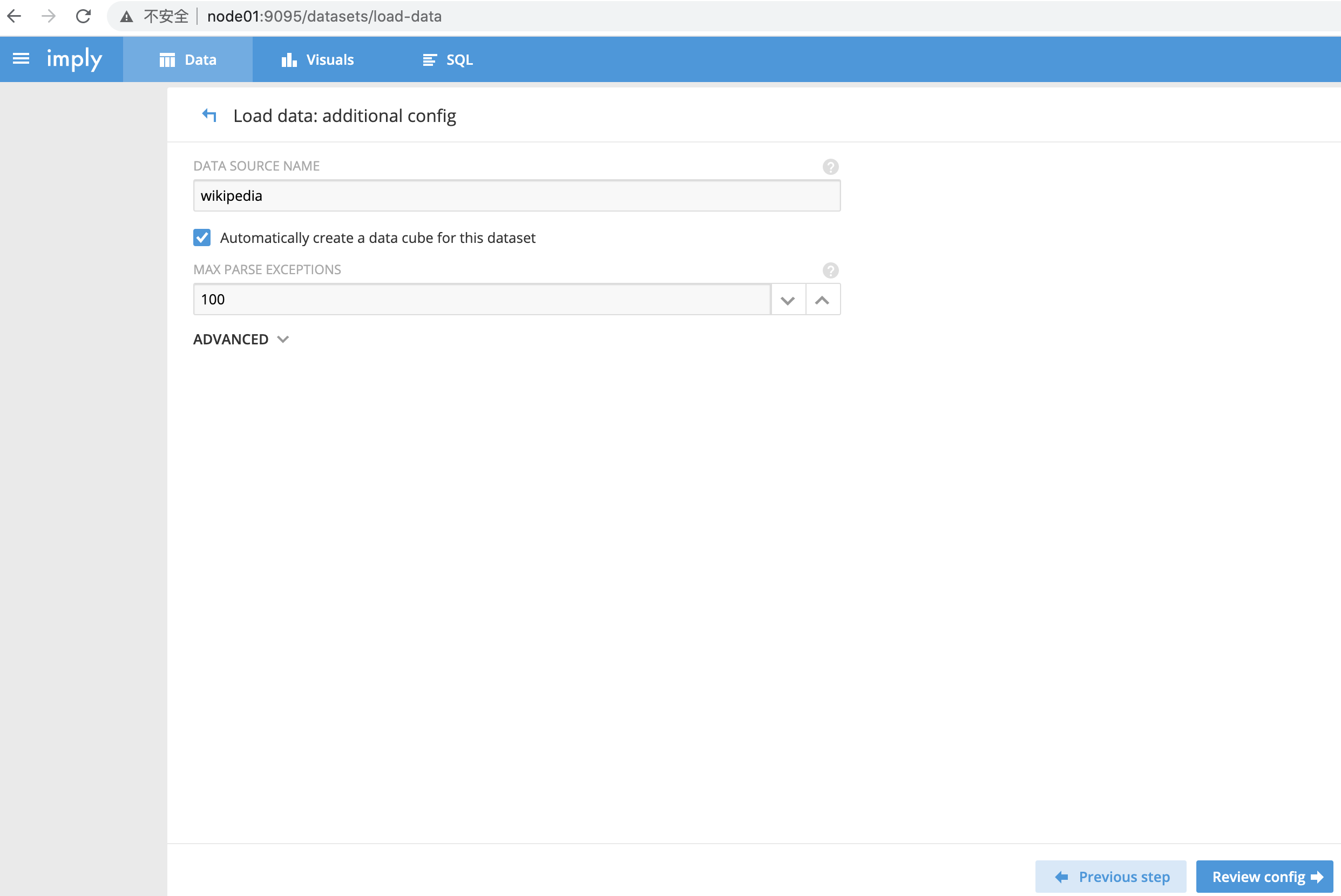
-
此界面用于review回顾配置项是否无误
点击“Start loading data”
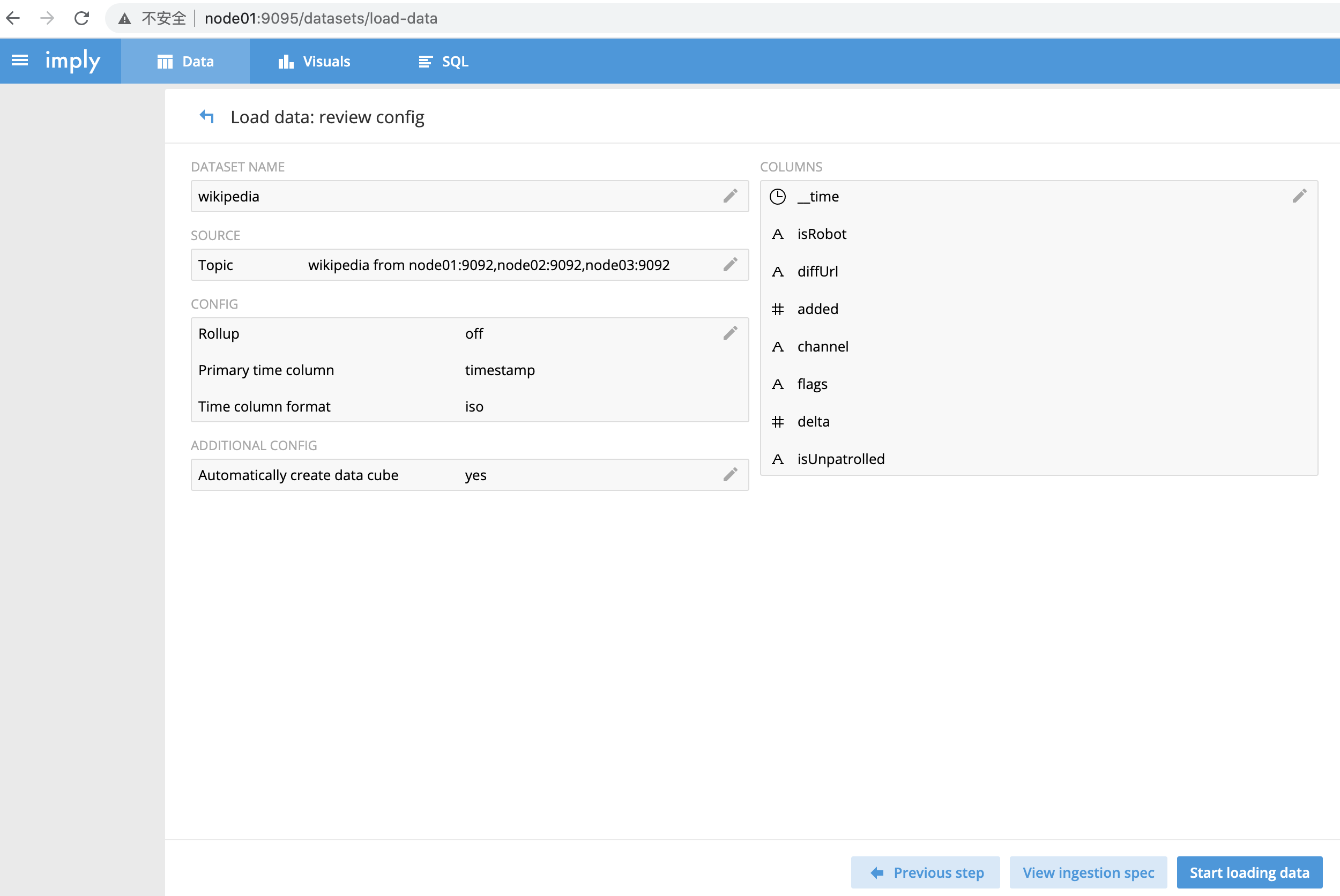
-
进入如下界面,显示“Connecting to topic: wikipedia”
稍等片刻
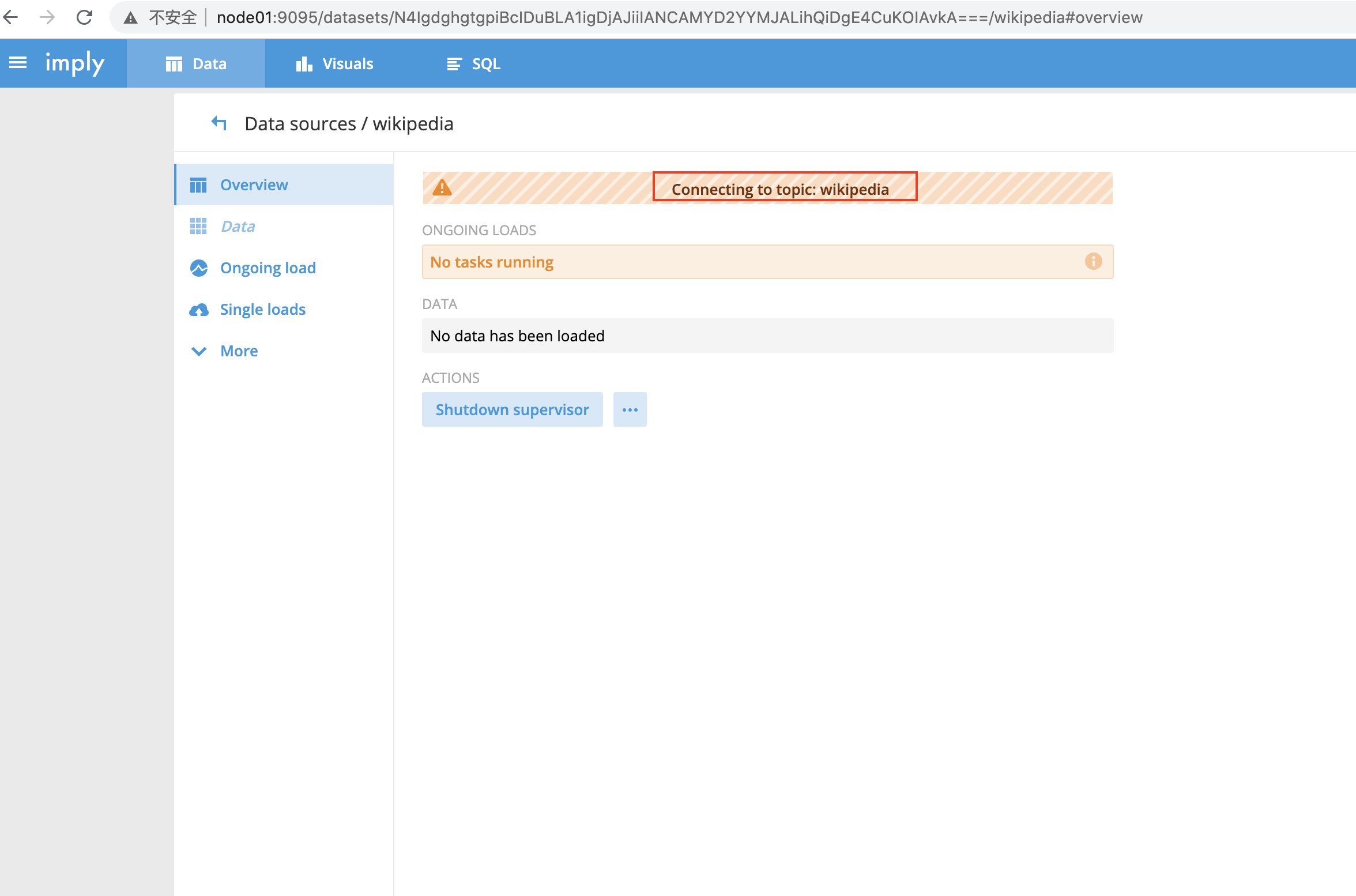
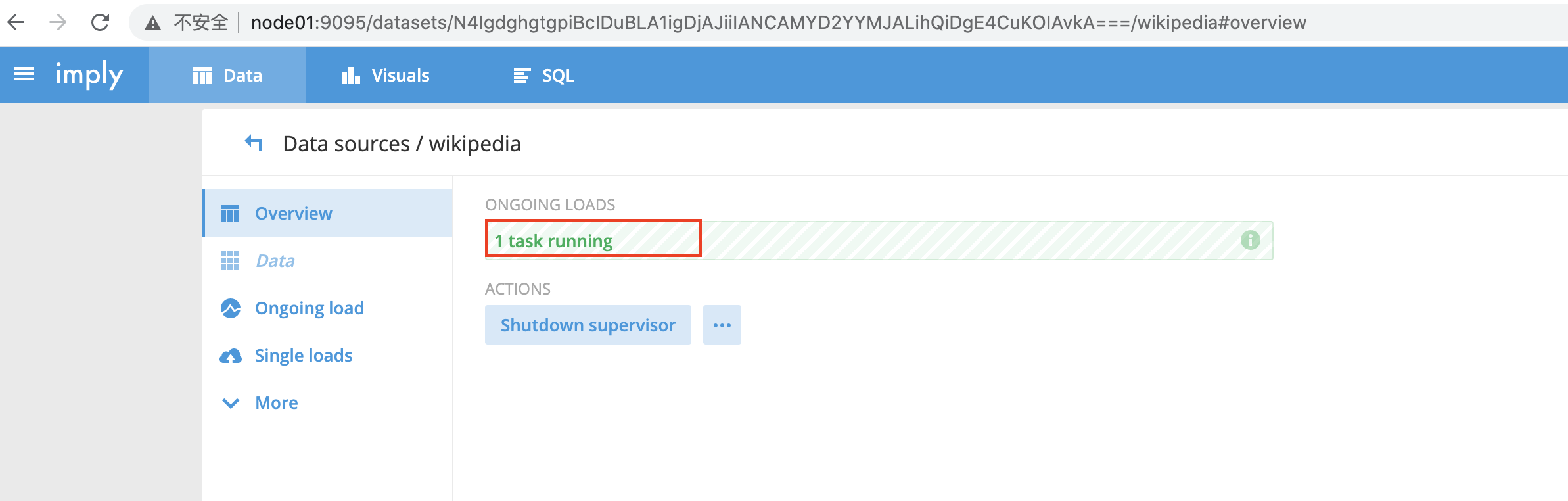
- 进入如下视图,“1 task running”表示,druid开始从kafka的wikipedia主题获得数据
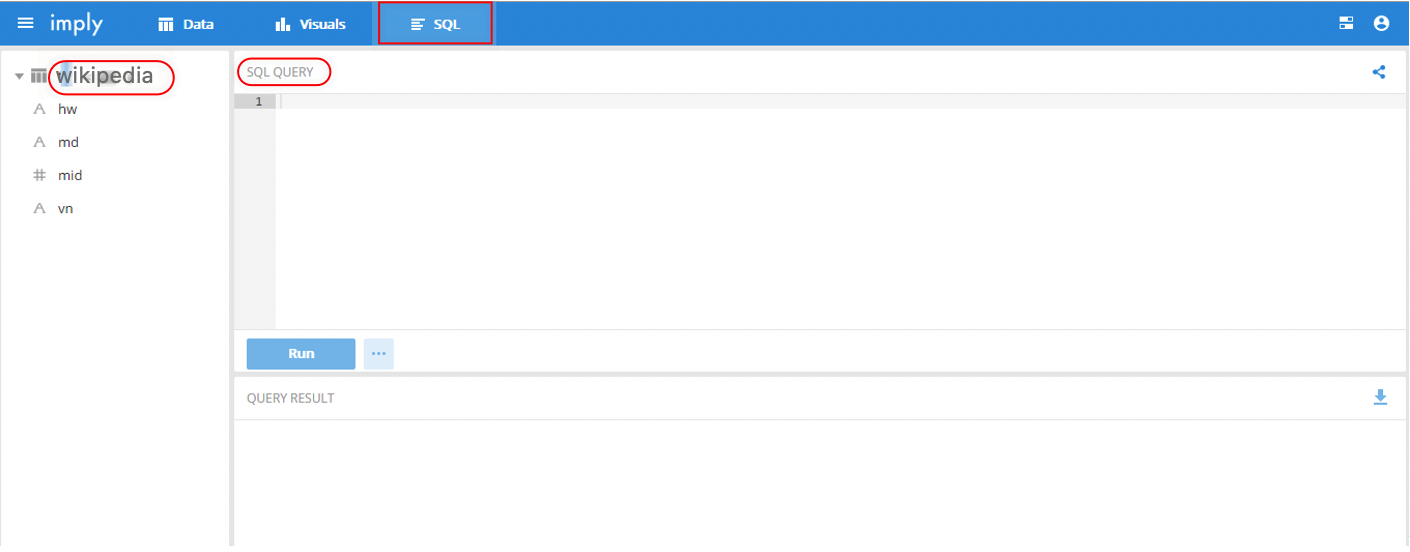
- 上边步骤完成后,可以点击导航栏的“SQL”,左侧列表除可以看到
-
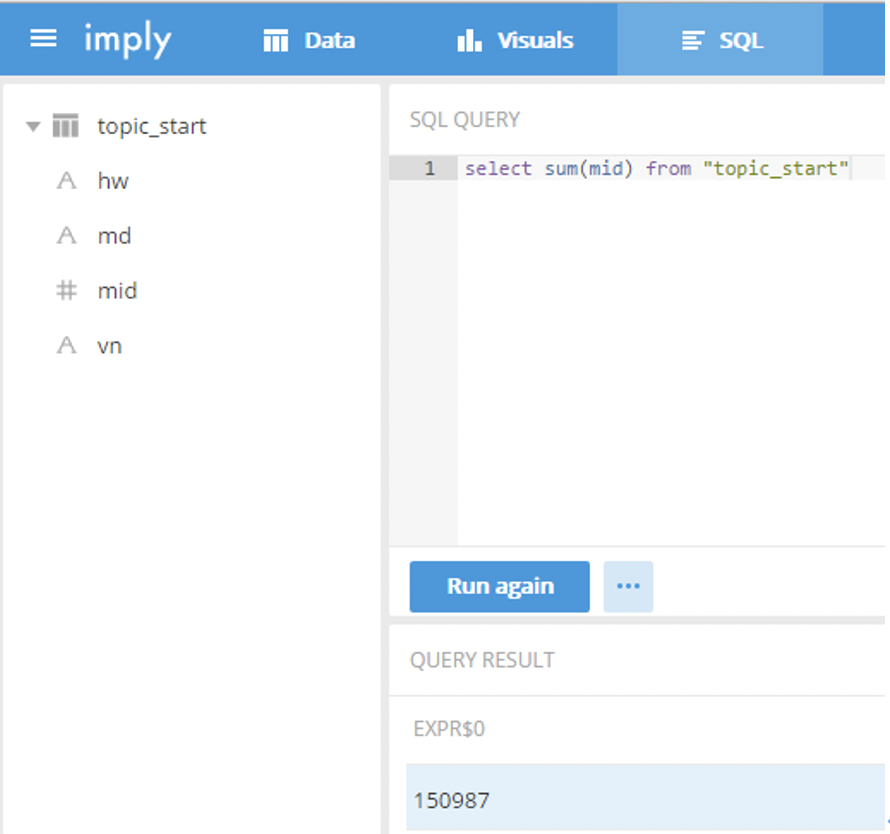
查询指标
下图的SQL QUERY中输入sql语句,对dataset wikipedia进行查询
select sum(mid) from "wikipedia"
6. 停止druid
- 按Ctrl + c中断监督进程
- 如果想中断服务后进行干净的启动,请删除/opt/module/imply/var/目录。
Views: 103